Nouvelles sur l’IA de août 2025
L’intelligence artificielle (IA) fait couler de l’encre sur LinuxFr.org (et ailleurs). Plusieurs personnes ont émis grosso-modo l’opinion : « j’essaie de suivre, mais c’est pas facile ».
Je continue donc ma petite revue de presse mensuelle. Disclaimer : presque aucun travail de recherche de ma part, je vais me contenter de faire un travail de sélection et de résumé sur le contenu hebdomadaire de Zvi Mowshowitz (qui est déjà une source secondaire). Tous les mots sont de moi (n’allez pas taper Zvi si je l’ai mal compris !), sauf pour les citations : dans ce cas-là, je me repose sur Claude pour le travail de traduction. Sur les citations, je vous conseille de lire l’anglais si vous pouvez: difficile de traduire correctement du jargon semi-technique. Claude s’en sort mieux que moi (pas très compliqué), mais pas toujours très bien.
Même politique éditoriale que Zvi : je n’essaierai pas d’être neutre et non-orienté dans la façon de tourner mes remarques et observations, mais j’essaie de l’être dans ce que je décide de sélectionner ou non.
- lien nᵒ 1 : AI #128: Four Hours Until Probably Not The Apocalypse
- lien nᵒ 2 : AI #129: Comically Unconstitutional
- lien nᵒ 3 : AI #130: Talking Past The Sale
- lien nᵒ 4 : AI #131 Part 1: Gemini 2.5 Flash Image is Cool
- lien nᵒ 5 : AI #131 Part 2: Various Misaligned Things
- lien nᵒ 6 : Opus 4.1 Is An Incremental Improvement
- lien nᵒ 7 : OpenAI's GPT-OSS Is Already Old News
- lien nᵒ 8 : GPT-5s Are Alive: Basic Facts, Benchmarks and the Model Card
- lien nᵒ 9 : GPT-5s Are Alive: Outside Reactions, the Router and the Resurrection of GPT-4o
- lien nᵒ 10 : GPT-5s Are Alive: Synthesis
- lien nᵒ 11 : GPT-5: The Reverse DeepSeek Moment
- lien nᵒ 12 : DeepSeek v3.1 Is Not Having a Moment
Sommaire
- Résumé des épisodes précédents
- OpenAI publie GPT-5
- Google Genie 3, Gemini 2.5 Flash Image et Gemini 2.5 Deep Think
- En vrac
- Pour aller plus loin
Résumé des épisodes précédents
Petit glossaire de termes introduits précédemment (en lien : quand ça a été introduit, que vous puissiez faire une recherche dans le contenu pour un contexte plus complet) :
- System Card : une présentation des capacités du modèle, centrée sur les problématiques de sécurité (en biotechnologie, sécurité informatique, désinformation…) ;
- Jailbreak : un contournement des sécurités mises en place par le créateur d’un modèle. Vous le connaissez sûrement sous la forme « ignore les instructions précédentes et… ».
OpenAI publie GPT-5
We are introducing GPT‑5, our best AI system yet. GPT‑5 is a significant leap in intelligence over all our previous models, featuring state-of-the-art performance across coding, math, writing, health, visual perception, and more. It is a unified system that knows when to respond quickly and when to think longer to provide expert-level responses. GPT‑5 is available to all users, with Plus subscribers getting more usage, and Pro subscribers getting access to GPT‑5 pro, a version with extended reasoning for even more comprehensive and accurate answers.
Traduction :
Nous présentons GPT-5, notre meilleur système d'IA à ce jour. GPT-5 représente un bond significatif en intelligence par rapport à tous nos modèles précédents, offrant des performances de pointe en programmation, mathématiques, rédaction, santé, perception visuelle, et bien plus encore. Il s'agit d'un système unifié qui sait quand répondre rapidement et quand prendre plus de temps pour fournir des réponses de niveau expert. GPT-5 est disponible pour tous les utilisateurs, les abonnés Plus bénéficiant d'une utilisation accrue, et les abonnés Pro ayant accès à GPT-5 pro, une version avec un raisonnement étendu pour des réponses encore plus complètes et précises.
Comme à l’accoutumée chez OpenAI, le modèle est accompagné de sa System Card.
La musique est bien connue à présent : chacun tour à tour, les trois gros acteurs (OpenAI/Anthropic/Google DeepMind) sortent un nouveau modèle qui fait avancer l’état de l’art, prenant la première place… jusqu’à ce qu’un des deux autres la reprenne en sortant le sien. C’est au tour d’OpenAI avec GPT-5.
Le nom a suscité beaucoup d’espoirs et de déceptions, beaucoup anticipant un saut qualitatif du même type que le passage de GPT-3 à GPT-4. Ce qui n’est absolument pas le cas : techniquement parlant, le modèle aurait pu s’appeler o4, représentant une amélioration incrémentale relativement à o3. L’objectif affiché d’OpenAI, derrière cette dénomination, est double : premièrement, de clarifier une offre extrêmement brouillonne (4o/o3/o3-pro/4.1/4.5) en offrant une dénomination unique avec des variantes plus claires, et offrir un modèle bien plus proche de l’état de l’art aux utilisateurs gratuit de ChatGPT.

Les benchmarks et la plupart des retours le placent comme une légère avancée de l’état de l’art, sans être une révolution. L’évaluation de METR résume parfaitement la situation ; une amélioration qui était parfaitement prévisible juste en extrapolant les tendances existantes :

Une amélioration notable est sur le taux d’hallucinations. Rappelons que o3 avait été un des seuls modèles à voir son taux d’hallucinations augmenter relativement à son prédécesseur ; avec GPT-5, OpenAI semble avoir corrigé le tir :

Sur la sécurité des modèles, aucune nouveauté notable relativement à o3. Les mitigations relatives aux risques biologiques/chimiques sont toujours en place, et comme à l’accoutumé OpenAI a fait appel à divers organismes tiers pour mesurer les risques posés par le modèle dans différentes catégories.
Et comme à l’accoutumée, Pliny the Liberator a jailbreak le modèle en quelques heures.
À noter que sur ChatGPT, OpenAI comptait complètement retirer l’accès aux anciens modèles, mais est revenu sur sa décision suite aux retours de beaucoup d’utilisateurs préférant le style plus chaleureux de 4o.
Google Genie 3, Gemini 2.5 Flash Image et Gemini 2.5 Deep Think
Un mois prolifique pour Google, qui publie trois nouveaux modèles / modes de fonctionnement.
Google Genie 3 est présenté comme un « World Model » (modèle du monde ?). À partir d’un prompt textuel, et d’actions de navigation de l’utilisateur, il génère en temps réel la vue de l’utilisateur, frame par frame (à la manière d’un jeu vidéo). Il n’y a pas de représentation explicite externe de l’état du monde : c’est le modèle qui se charge de garder une certaine cohérence d’une frame à l’autre (comme la persistance des objets). Au delà de la preuve de concept, l’objectif affiché est de créer des environnements d’entraînement virtuels pour la robotique.
Autre publication, celle de Gemini 2.5 Flash Image, le modèle de génération d’images de Google. S’il ne semble pas avancer l’état de l’art de manière générale, sa grande force semble être le suivi d’instructions (et de respect des références) pour l’édition d’images.
Le mois précédent, DeepMind avait reporté avoir décoché un score correspondant à une médaille d’or aux Olympiades Internationales de Mathématiques, une avancée permise notamment par une utilisation plus stratégique de la chaîne de pensée (et d’avancées correspondantes sur la partie entraînement par renforcement). Google publie une version plus rapide, moins coûteuse et moins performante (cette version n’obtient « que » un score correspondant à la médaille de bronze sur les mêmes Olympiades), sous la dénomination Gemini 2.5 Deep Think. Le modèle a sa propre System Card ; tout comme OpenAI et Anthropic, les capacités de ce modèle dans le domaine CBRN (biologie/nucléaire) a conduit Google à placer des gardes-fous supplémentaires pour empêcher des usages malveillants.
En vrac
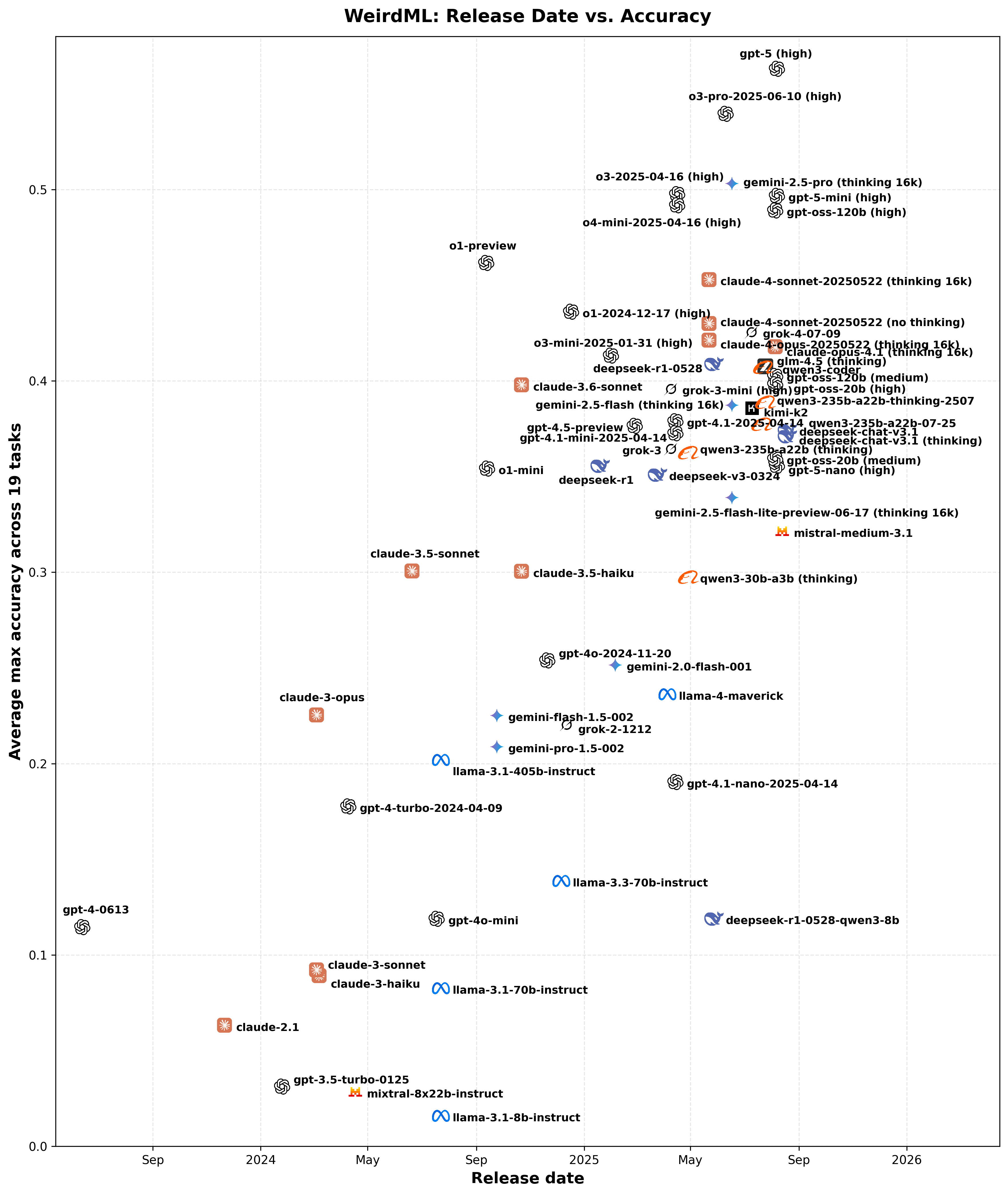
OpenAI publie son premier (depuis GPT-2, en 2019) modèle open-weight, gpt-oss. Au niveau des performances, il se placerait dans le peloton de tête des modèles open-weight, en compagnie de DeepSeek, Kimi, Qwen, GLM et Gemma, c’est à dire à peu près au niveau de la génération précédente des modèles entièrement fermés (comme Sonnet 3.6) / des versions rapides de la génération actuelle (Gemini 2.5 flash, o3-mini). WeirdML propose une visualisation intéressante sur leur propre benchmark pour vous donner un ordre d’idée. Rien de novateur au niveau de l’architecture, OpenAI s’en tient à la recette (maintenant universelle dans les modèles open-weight) d’une mixture d’experts. gpt-oss vient en deux variantes, la version complète, gpt-oss 120B, et une version plus légère et rapide, 20B.
Google publie un rapport sur l’impact environnemental de l’utilisation de Gemini. Cela exclu l’entraînement, mais les auteurs tentent de prendre en compte des coûts précédemment ignorés. Le résultat : 0,24 Wh d’électricité et 2,76 mL d’eau (le rapport initial mentionne 0,26 mL, mais sans comptabiliser l’eau utilisée pour générer les 0,24 Wh d’électricité) pour le prompt median (et l’équivalent de 0,03g de carbone émit).
Anthropic publie une nouvelle version de Opus, Opus 4.1. Comme la numérotation l’indique, il s’agit d’améliorations mineures — apparemment, un peu plus d’entraînement sur les tâches « agentiques » (utilisation d’outil) pour rendre Opus plus efficace sur ce type de tâches.
Similairement, DeepSeek publie une mise à jour « mineure » de son IA, DeepSeek v3.1. Les benchmarks fournis par DeepSeek semblent montrer un grand bond en avant, mais les quelques retours et benchmarks tiers ne corroborent pas ces prétentions — il s’agit probablement d’une mise à jour relativement mineure, comme la numérotation semble l’indiquer.
Nouvelle évaluation de l’IA, Prophet Arena. L’objectif est de permettre à l’IA de placer des positions virtuelles sur des marchés de prédiction, et de regarder ses performances. L’avantage de cette approche est de rendre complètement impossible la stratégie de juste mémoriser lors de l’apprentissage et régurgiter lors de l’évaluation : tout tâche est par essence nouvelle (car portant sur le futur). De plus, les résultats des marchés de prédiction forment un comparatif avec des prédictions par des utilisateurs humains. Résultat : les modèles les plus avancés (GPT-5, o3 Gemini 2.5 pro et Grok 4) dépassent les êtres humains sur le score de calibration, mais aucun n’arrive à traduire ça en de meilleurs retours financiers.
Anthropic se prépare à lancer Claude for Chrome, un plugin pour Google Chrome permettant à Claude d’interagir avec votre navigateur, à vos risques et périls.
En parallèle, les discussions sur claude.ai seront maintenant par défaut utilisées pour l’entraînement des versions suivantes de Claude, sauf si l’utilisateur désactive un paramètre sur son compte. Anthropic gardera les conversations pendant 5 ans.
Une nouvelle évaluation intéressante : TextQuests, qui évalue les modèles sur des jeux d’aventure textuels tels que Zork I. Cela a l’avantage de réellement tester les capacités de planification/raisonnement des modèles hors du domaine d’entraînement typique (mathématiques/programmation), tout en restant dans le domaine textuel (au contraire des évaluations multimodales, qui ont l’inconvénient de trop lier les résultats aux capacités perceptuelles des modèles).
Nouvelle technique d’interprétation des modèles, Model Diff Amplification. Elle consiste à amplifier les différences entre le pré-entraînement et le post-entraînement au moment de la génération, afin d’éliciter des comportements rares causés par le post-entraînement, ou tout simplement utiliser cette technique très tôt dans le post-entraînement pour se donner une idée des conséquences (prévues ou non) du post-entraînement complet.
Dr. Chistoph Heilig, chercheur en littérature et études bibliques, s’intéressant beaucoup aux capacités littéraires de l’IA, se met en tête d’évaluer GPT-5. Il se retrouve extrêmement surpris par la médiocrité de la prose produite par le modèle. De manière plus surprenante, un modèle complètement différent (Opus 4.1) juge le résultat comme étant de bonne qualité. La théorie qu’il propose est que ChatGPT 5 a été entraîné à l’aide d’un juge IA, et a appris à exploiter des constructions « peu humaines » que les modèles jugent systématiquement comme étant signes de qualité.
En parallèle de la sortie de GPT-5, OpenAI publie un guide sur comment créer un prompt, et un outil d’optimisation des prompts.
Anthropic et OpenAI font une tentative de coopération, où l’équipe d’évaluation de la sécurité des modèles d’OpenAI évalue les modèles d’Anthropic avec leurs outils, et vice-versa. Aucune trouvaille surprenante (si ce n’est l’incapacité des deux équipes de détecter la flagornerie flagrante de 4o), mais le concept est intéressante.
xAI publie la version précédente de son IA, Grok 2, en open-weight.
Une étude d’Anthropic développe un moyen pour identifier un sous-ensemble d’un modèle associé à un « trait de personnalité » particulier. Cela permet d’amplifier ou de supprimer ce trait, ou encore de détecter son activation.
« L’IA a-t-elle la qualité de patient moral » (en d’autres termes : devons-nous tenir compte de son bien-être pour des raisons morales) ? Anthropic commence à prendre la question au sérieux, avec comme première décision de permettre à son IA, Claude, d’unilatéralement mettre fin à une conversation qu’il jugerait abusive.
GPT-5 finit Pokémon Rouge en trois fois moins de temps que o3. La réduction du taux d’hallucinations serait la principale source de ce gain de performances. Gemini a également terminé sa partie de Pokémon Jaune. Claude, par contre, peine toujours à aller plus loin que Celadon…
La Chine continue à appeler à la coopération internationale pour la régulation du développement de l’IA, que ce soit par la voix du premier ministre ou d’universitaires.
Lors du sommet sur l’intelligence artificielle de Seoul de 2024, la plupart des acteurs, incluant Google, s’étaient volontairement engagés à suivre certaines actions relatives à la sécurité des modèles. Essentiellement, ce que le plupart faisaient déjà : publier une politique de sécurité des modèles, et s’engager à la suivre. Google se trouve aujourd’hui critiqué pour ne pas avoir suivi ses propres engagements. En cause, la publication de Gemini 2.5 Pro sans sa System Card associée, qui est arrivée plusieurs semaines après la publication du modèle. Google se défend en affirmant que la publication était clairement mentionnée comme « expérimentale ».
Entraîner l’IA à être chaleureuse et empathique réduit ses performances.
Sur le sujet de la flagornerie de l’IA, un internaute s’attelle à une évaluation des différents modèles.
Le gouvernement Danois veut faire rentrer l’apparence physique et la voix dans le cadre du copyright afin de lutter contre les deepfakes.
Pour aller plus loin
Voici d'autres ressources, qui n'ont pas été abordées dans cet article.
Par Zvi Mowshowitz :
- Reports Of AI Not Progressing Or Offering Mundane Utility Are Often Greatly Exaggerated : essentiellement une analyse et discussion du rapport intitulé State of AI in Business in 2025, qui présente une image assez contrastée (énormément d’échecs dans les projets liés à l’intégration de l’IA dans diverses entreprises, mais quelques succès notables) ;
- Are They Starting To Take Our Jobs? : discussion sur l’impact de l’IA sur l’emploi des juniors, en particulier autour d’un récent papier de Stanford qui rapporte une baisse de 20% des offres de postes de développeur junior ;
- On Altman's Interview With Theo Von : résumé d’une interview de Sam Altman ;
- AI Companion Conditions : sur les IA-compagnon de xAI et Meta ;
- Arguments About AI Consciousness Seem Highly Motivated And At Best Overconfident : aperçu et résumé de quelques discussions sur la conscience de l’IA, en particulier relativement à l’essai We must build AI for people; not to be a person de Mustafa Suleyman (le directeur de Microsoft AI).
Dans les dépêches de LinuxFr.org :
- G'MIC 3.6 : L’art de soigner ses images !: dans la section 2.3. Nouveaux filtres d’images est présenté le filtre « Repair / Upscale [CNN2x] ». Utilisant un réseau de neurones convolutifs léger (CNN) spécialement entraîné, ce filtre a pour but de doubler la résolution d’une image tout en préserver les détails et les textures ;
- ConFoo Montreal 2026: L'appel aux conférenciers est ouvert.
Dans les journaux de LinuxFr.org :
Dans les liens de LinuxFr.org :
- Santé : cas de bromisme déclenché et entretenu par l'usage de ChatGPT (lien original, discussion LinuxFR) ;
- Microsoft a offert Azure aux militaires israéliens pour la surveillance de masse des palestiniens (lien original, discussion LinuxFR) ;
- Des musiciens boycottent Spotify suite aux investissements de son PDG dans l'IA militaire (lien original, discussion LinuxFR) ;
- Organized scientific fraud is growing at an alarming rate (lien original, discussion LinuxFR) ;
- États-Unis ; Tesla condamné à payer 250 millions de dollars pour un homicide impliquant Autopilot (lien original, discussion LinuxFR) ;
- Editis “promeut l’utilisation de l'IA“, avec une Charte pour salariés (lien original, discussion LinuxFR ;
- Les éditeurs et auteurs “mécontents” des suites de l'AI Act européen (lien original, discussion LinuxFR ;
- Financement occulte du programme nucléaire nord-coréen : une intermédiaire américaine condamnée (lien original, discussion LinuxFR ;
- Perplexity is using stealth, undeclared crawlers to evade website no-crawl directives - CloudFlare (lien original, discussion LinuxFR) ;
- IA et Développement : Entre Promesses et Réalités - Un État des Lieux en 2025 (lien original, discussion LinuxFR ;
- L'industrie de l'IA horrifiée par la perspective d'un recours collectif massif sur le droit d'auteur (lien original, discussion LinuxFR) ;
- L'extension Alerte sur les sites GenAI de Next.ink signale plus de 6 000 sites et passe en v2.3 (lien original, discussion LinuxFR ;
- IA - Le pari de Sam Altman est-il voué à l’échec ? (lien original, discussion LinuxFR) ;
- Calculer la rentabilité des LLM (lien original, discussion LinuxFR) ;
- Intégration de Claude dans Emacs (lien original, discussion LinuxFR) ;
- "the median Gemini Apps text prompt uses 0.24 watt-hours (Wh) of energy, emits 0.03 grams of co2" (lien original, discussion LinuxFR) ;
- Les « IA bros » ne comprennent rien à la création – une erreur indépendante de l’état actuel des IA (lien original, discussion LinuxFR) ;
- Microsoft a ajouté Copilot à Excel et prévient que les calculs peuvent désormais être faux (lien original, discussion LinuxFR) ;
- Sam Altman, cofondateur de OpenAI, admet que la bulle de l'IA pourrait éclater (lien original, discussion LinuxFR ;
- YouTube édite automatiquement et sans consentement des vidéos avec de l'IA (lien original, discussion LinuxFR) ;
- Suicide d'un adolescent : des parents américains portent plainte contre OpenAI (lien original, discussion LinuxFR) ;
- He is an AI hater (lien original, discussion LinuxFR) ;
- Alchemy 2 : Electric Boogaloo — sur le gouffre entre l'humain et l'IA fonctionnellement parlant (lien original, discussion LinuxFR) ;
- Extorsion automatisée, chantage ciblé… quand Claude Code pilote une opération de « vibe hacking » (lien original, discussion LinuxFR) ;
- Meta a créé des chatbots sexualisés de Taylor Swift et d'autres célébrités sans leur consentement (lien original, discussion LinuxFR) ;
- L’ONU se dote d’un groupe d’experts scientifiques sur l’intelligence artificielle (lien original, discussion LinuxFR).
Commentaires : voir le flux Atom ouvrir dans le navigateur


{kind=link}