AuX sources du fun N° 1 : retrouver le fun dans les inutilitaires graphiques
Après un épisode 000 sur les logiciels inutiles et donc indispensables autour de l'ASCII art, cette dépêche entre dans la fin du XX° siècle avec les inutilitaires ayant des interfaces graphiques.
- lien nᵒ 1 : Episode 000
- lien nᵒ 2 : Journal à l’origine de la dépêche
Sommaire
-
Introduction : poétique de l’inutile et regard de Xeyes
- Les décoratifs graphiques
- Les animaux virtuels et autres éléments virtuels de companies
- Les inutilitaires liés à l’actualité et à l’histoire de l’informatique
- Assistant virtuel
- Les écrans de veille : XScreensaver
- Les inutilitaires de « Passage »
- Le voyage de Neko et la retraite de Kodo
- Gource en guise de conclusion pour 2025 et de Passage en 2026
- Conclusion
- Pour aller plus loin ensemble en traineau
Introduction : poétique de l’inutile et regard de Xeyes
En ce passage vers une nouvelle année, c’est l’occasion d’inviter à de nouveaux regards, notamment à travers les inutilitaires avec interface graphique dans le domaine du libre, de la même manière que l’interface graphique a étendu leurs possibilités. Il s’agit d’une revisite de ces logiciels qui ont marqué, qui constituent les traces de l’histoire informatique et qui ouvrent à une perception renouvelée, traversés par des souffles multiples, à la fois historiques, poétiques, ludiques et philosophiques, et étendus dans le village global de 2026. Ainsi, nous les aborderons sous ces différentes modalités, à l’aune de ces différentes lumières.
Pour inviter à porter ce regard sur ces angles multiples, nous présenterons les inutilitaires graphiques dans une perspective plurielle, à la fois ludique, poétique et philosophique. En effet, ces équivalents dotés d’une interface graphique (GUI) de leurs homologues en ASCII ART, loin de toute logique de consommation, offrent un espace où le regard peut vagabonder, où l’expérience naît aussi de l’inattendu et de la contemplation. Ce changement de point de vue se manifeste notamment dans des exemples comme le petit programme Xeyes. Aussi inutile soit-il, il est installé par défaut dans la plupart des distributions : il se contente d’afficher des yeux qui suivent la souris, participant ainsi, à son échelle, au déplacement de la perception dans le logiciel libre. Il ne s’agit pas d’affirmer que Xeyes est intrinsèquement dépourvu d’usages utiles possibles, mais de le considérer ici dans une poétique du just for fun à l’instar de Linus Torvalds qui proclamait à Amsterdam que « The most important design issue… is the fact that Linux is supposed to be fun… ». Ainsi Xeyes est vu comme un objet ludique et réflexif, en outre sa page de manuel elle-même adopte un ton d’humour noir explicite : « Xeyes watches what you do and reports to the Boss. »
Bien entendu, Xeyes ne contient aucune backdoor destinée à transmettre des données à un quelconque supérieur — d’où son inutilité revendiquée (OUF). Avec le recul, on pourrait néanmoins y voir une préfiguration ironique des révélations de Snowden, infiniment plus utiles, quant à elles, pour dénoncer des pratiques bien réelles de surveillance. Là où Xeyes se contente d’en proposer une parodie, il rappelle, par le jeu et le décalage, que le logiciel libre sait aussi penser le regard et l’interface autrement que sous l’angle de l’efficacité, participant ainsi, à sa façon, à cette autre poétique. Les yeux malicieux de Xeyes ont aussi été transportés sur d'autres OS
De cette contemplation découle également une autre réflexion. Dans son essai « Sauvons le Beau : L’esthétique à l’ère numérique », le philosopheByung-Chul Han (Pyŏng-ch’ŏl Han 한병전) regarde le monde d’aujourd’hui, saturé d’images lisses et parfaites, façonnées par un productivisme qui aplanit l’expérience personnelle. Tout est policé, séduisant, immédiatement consommable, mais dépourvu de profondeur. L’expérience esthétique se consomme comme un fruit sans chair, et le regard se laisse séduire sans se laisser transformer.
À travers Jeff Koons et le corps pornographié, il montre que l’expérience esthétique perd sa rugosité, son mystère, sa personnalisation et sa capacité à surprendre et à bouleverser. Elle devient un reflet étincelant dont l’intérieur sonne creux. Face à cet appauvrissement, Han appelle à se tourner vers l’altérité. Il invite à arracher l’individu à son narcissisme, à le détourner du miroir aux alouettes trop lisse, mais qui ne renvoie qu’une image vide. Voir l’altérité, c’est ramener le spectateur hors de lui-même, le confronter à une expérience esthétique qui change son regard, née de l’inattendu, de la divergence, de ce qui déstabilise. Dans cette rencontre, l’expérience esthétique cesse d’être un simple objet de consommation et redevient un souffle qui questionne, qui surprend et qui bouleverse.
Cette attention au surprenant trouve un écho pour le moins inattendu dans le monde du logiciel libre. Dans The Cathedral and the Bazaar, Eric S. Raymond écrit : « Every good work of software starts by scratching a developer’s personal itch. » Ainsi, chaque programme, chaque création naît d’un désir ou d’un besoin vécu, d’une singularité que l’on cherche à exprimer et à explorer. Ensuite, il ajoute également : « The next best thing to having good ideas is recognizing good ideas from your users. Sometimes the latter is better. » Parfois, ce n’est pas l’idée initiale, mais la rencontre avec ce qui vient d’ailleurs, qui enrichit et change la perception. Le logiciel libre, via la rencontre avec l’altérité et de par ses pratiques open source, amènent une approche mêlant une esthétique de la participation, qui constitue une proposition à la critique esthétique d’Han, laquelle, de manière tout à fait surprenante, s’incarne dans le processus de participation à travers le projet libre Gource, intégrant l’approche décrite par Eric S. Raymond et une esthétique du libre dans une danse poétique lumineuse sous forme de constellation spatiale globale.
Entre Xeyes et Gource s’étale une certaine diversité d’inutilitaires que nous parcourons comme une mini-rétrospective, mêlant parfois la grande histoire de l’actualité informatique avec la petite histoire des inutilitaires, souvent inattendue, encourageante, conviviale et poétique. De cette mosaïque émergeront certaines réflexions sur les inutilitaires sous forme d’abandonware, notamment à travers « le voyage de Necko et la retraite de Kodo ». Ces réflexions sont aussi l’occasion de redécouvrir des inutilitaires abandonnés à explorer, véritables parties prenantes de la grande aventure du logiciel libre, de son processus participatif en open source et de son invitation à une ouverture d’esprit et du code.

Les décoratifs graphiques
Xjokes
MxIco
Xtacy
Cette quête de l’émerveillement et de la profondeur, au cœur du quotidien hypermoderne, nous mène aussi vers un autre temps, hors de l’aliénante productivité : celui d’un second Han, l’ermite Han Shan 寒山, sur les monts froids de la Chine des Mings. Là, dans la solitude et l’oisiveté attentive, l’expérience ne se cherche pas, elle advient. La légende dit que ses poèmes surgissaient sur les murs, les rochers, les arbres. Poète ch’an, ancêtre du zen japonais, Han Shan demeurait sous les pins, au bord d’un torrent, oublieux de lui-même, contemplant un papillon sans savoir s’il rêvait le papillon ou si le papillon le rêvait, comme chez Zhuang Zi. Puis, puis, dans un élan soudain, il grave quelques vers dans la pierre et s’en retourne en riant vers son ermitage comme tout maitre ch’an , énigmatique et joyeux.
une fois à Han Shan les dix mille affaires cessent
plus aucune pensée fugace ne s’accroche au cœur
oisif, sur un rocher j’inscris des poèmes,
accordé au flux, comme une barque sans amarre.
一住寒山萬事休
更無雜念掛心頭
閑書石壁題詩句
任運還同不繫舟


Dans le logiciel libre, Xjokes se fait l’écho de cette suspension de l’utilité. Ainsi, un trou noir engloutit l’écran, des figures clignent de l’œil, l’écran peut disparaître tout entier. Comme le Boing Ball de l’Amiga ou MxIco fait tourner de simples polyèdres , ces logiciels laissent le regard vagabonder. Oisifs, ces logiciels offrent un espace où le temps semble suspendu, accordé au flux du geste, comme un souffle qui traverse l’espace simplement.

Un autre poète inconnu sous Xtacy (ecstasy) écrira lui aussi sur le même thème :
Retrouve dans ta tête
Ton âme de poète
Souviens-toi comme c´est chouette
La parfum des violettes
Un soir de pâquerettes

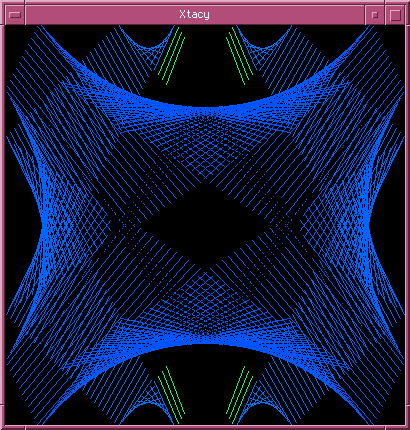
Ainsi Xtacy le fera chanter avec ses couleurs changeantes, ses fractales, ses quadrilatères rebondissants et ses vagues sinusoïdales décalées, invite au vertige .
Les animaux virtuels et autres éléments virtuels de companies
gkrellm-bfm
Ce programme de monitoring dispose d'un canard qui sert… de compagnon?
Un plugin de monitoring de charge pour GKrellM, inspiré de wmfishtime et bubblemon. Il met en scène des poissons pour illustrer le trafic réseau, des bulles pour l’utilisation du processeur et un canard… pour représenter un canard.
Xteddy
Xteddy, en tant qu’inutilitaire, a eu des usages inattendus, allant bien au‑delà de sa fonction de simple peluche virtuelle de premier abord.L’auteur originel de Xteddy, Stefan Gustavson, raconte sur le site archivé :
« I created Xteddy way back in 1994 as a spare time hack for fun. The reception I got from my colleagues was so heart-warming I was encouraged to distribute him world-wide. Much to my surprise, the response was overwhelming. By now, I have received hundreds of friendly messages of appreciation from all over the world, and they keep dropping in even this long after the release. To all of you teddy bear lovers out there: thanks! »
Ce simple projet ludique, conçu pour le plaisir, a rapidement touché et fédéré une communauté internationale. Un utilisateur raconte sur le site xteddy.org :
« Ever since I found out about the Xteddy Unix program, I ran it on my workstations when I was doing my University assignments, as it helped me think. »
Pour certains utilisateurs, dont celui qui a partagé son expérience et mis a disposition le site Xteddy.org, Xteddy a eu un impact bien au‑delà du divertissement : il a servi de soutien émotionnel et d’aide à la réflexion, apportant réconfort et motivation dans des périodes marquées par l’anxiété sociale ou les troubles paniques. Touché par l’influence positive de ce logiciel, cet utilisateur a pris contact et a ensuite créé le site xteddy.org, à la fois espace de témoignage personnel et lieu de mémoire pour la communauté.
« I still get feedback at least once a year thanking me for what I’ve written here, so it > shall remain. I hope others find this interesting and helpful. »
Son engagement s’inscrit également dans une démarche plus large de contribution au logiciel libre, puisqu’il participe activement à divers projets open source, prolongeant ainsi l’esprit collaboratif et de soutien qui entoure Xteddy.
Aujourd’hui, bien que le site de l’auteur original ne soit plus accessible, l’héritage de ce programme se perpétue grâce aux nombreuses distributions

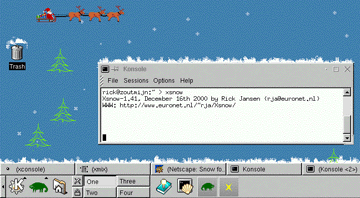
XSnow
La neige, avec son blanc immaculé et sa douceur fragile, a inspiré le poète coréen Kim Sowol dans son célèbre poème 눈 오는 저녁 (Snowy Evening). Comme lui, certains pensent à leur amour lointain en observant la neige tomber, tandis que d’autres n’ont pas eu la chance de voir le Père Noël. Cette neige qui s’éparpille au vent mais ne fond qu’au contact des flammes rappelle la fragilité et la profondeur du cœur humain. Aujourd’hui, même ceux qui n’ont pas la chance de contempler la neige réelle peuvent retrouver cette magie grâce à XSnow, un programme qui fait tomber la neige virtuelle sur le bureau, recréant une mini ambiance hivernale dans le silence d’un monde immobile. Sous le ciel pâle, les pensées s’immobilisent, lentes et blanches, tandis que la nuit écoute le pas léger de l’hiver, et que la neige continue de transformer le quotidien en souvenir poétique, et observer par intermittence le traineau du Père Noël defiler sur son ecran. Un classique qui ajoute une touche de fraîcheur aux sessions de travail.
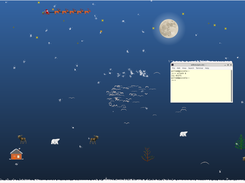
XPenguins : La Marche des Rêveurs Polaires
Dans le paysage immaculé de votre écran, là où ne règnent que l'ordre et la logique, une troupe inattendue fait son apparition. XPenguins, œuvre de l'esprit créatif de Robin Hogan, est une douce folie, un souffle d'air vif des terres australes. Inspirés des graphismes espiègles du jeu Pingus, ces petits pingouins pixelisés arpentent l'impossible. Ils cheminent le long des précipices de vos fenêtres, se faufilent entre les barres de menus comme entre des séracs de glace, transformant votre bureau en un iceberg numérique où règne une joyeuse absurdité. Ils défilent, pattent, courts et déterminés, dans une marche tranquille et hypnotique, offrant un ballet burlesque contre la rigueur austère de l'interface. Mais leur magie ne s'arrête pas aux confins de votre moniteur. Avec un clin d’œil à XBill, il se poursuit dans le jeu Pingus.

Doggo
Doggo est une IA de chien, développée en Python avec Pygame. Le chien se déplace aléatoirement sur l’écran, change de direction et d’état, et sa couleur de pelage varie de manière aléatoire. Les changements d’état suivent une chaîne de Markov. Ce projet est né de l’envie d’un collègue de l’auteur, qui ne pouvait pas avoir de chien, de créer un compagnon virtuel tout en explorant les chaînes de Markov.

Xroach
Xroach est un jeu classique qui consiste à afficher des cafards répugnants sur votre fenêtre principale. Ces petites créatures se déplacent frénétiquement jusqu'à trouver une fenêtre sous laquelle se cacher. À chaque fois que vous déplacez ou réduisez une fenêtre, les cafards se précipitent à nouveau pour se mettre à l'abri.
Xfishtank
Un vieil étang (haïku)
Un vieil étang
Une grenouille saute
Des sons d’eau
Aussi bref que ce célèbre haïku de Matsuo Bashō, et rapide qu’un « plouf » dans l’étang, Xfishtank nous transporte directement devant un aquarium où l’on peut contempler la diversité de la faune et de la flore marines, comme on contemple le poème de Bashō.

Les inutilitaires liés à l’actualité et à l’histoire de l’informatique
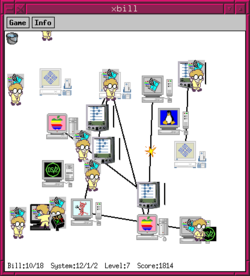
Est-ce que Windows est un virus ? XBill
Dans les années 1990, le procès USA Department of Justice (DOJ) vs Microsoft a largement dominé les médias, révélant au grand public les pratiques monopolistiques jugées déloyales de diffusion du système d’exploitation de la firme de Redmond sur les marchés mondiaux. L’accord conclu entre Microsoft et le DOJ n’ayant pas été respecté, de nouvelles poursuites ont été engagées. Ces événements ont nourri les réflexions des autorités européennes de la concurrence et préparé le terrain pour le futur procès contre Microsoft, qui interviendra plus tard, dans les années 2000, au sein de l’Union européenne.
Le mini-jeu XBill, créé dans ces années 1990, illustre ces pratiques de diffusion de manière caricaturale et a suscité des réflexions humoristiques sur une question récurrente : Microsoft Windows n’est-il pas un virus finalement ?
Ainsi, le livre PC GAGS, qui réunit les perles humoristiques de l’époque frappant les plateformes MS-DOS, Windows 3.1 et Windows 95, nous donne à voir cet état d’esprit décalé.
“ Une rumeur persistante circule dans les milieux informatiques, selon laquelle Windows lui-même ne serait rien d’autre qu'un virus plus ou moins bien camouflé (leitmotiv : pour les uns, c’est un système d’exploitation, pour les autres, c’est le plus long virus du monde).
Quelques spécialistes d’Internet ont examiné à la loupe cette théorie. Voici leurs conclusions :
1. Les virus se répandent rapidement. Okay, Windows en fait autant
2. Les virus consomment de précieuses ressources du système et ralentissent ainsi le travail de l’ordinateur. Okay, Windows fait la même chose.
3. Les virus anéantissent parfois le disque dur. Okay, Windows est également connu par certains utilisateurs comme se livrant à ce genre d'exaction.
4. Les virus sont souvent glissés dans un ensemble de programmes utiles sans que l’utilisateur le sache, ou bien sont transmis directement avec l’ordinateur. Okay, Windows se propage également de cette manière.
5. Les virus sont parfois responsables de ce que l’utilisateur trouve son système trop lent et s’en achète un autre. Okay, cela arrive aussi avec Windows.
Jusqu’ici, il semble bien que Windows soit effectivement un virus !Mais il existe trois différences fondamentales :
1. Les virus fonctionnent sur presque tous les ordinateurs.
2. Leur programmation est efficace et leur taille petite.
3. Plus ils se développent, plus ils font des progrès.
Windows ne satisfaisant pas à ces conditions de base, il faut se rendre l’évidence : Windows n’est pas un virus ! ”
Dans ce contexte, XBill s’inspire de cette critique pour caricaturer la propension de Bill Gates à installer Windows partout. Cette caricature interactive montre, d’une part, le CEO de Microsoft, qui installe Windows sur tous les ordinateurs qu’il rencontre, et, d’autre part, Windows lui-même se répandre via les réseaux se multiplier à l’instar d’un virus informatique, infectant les ordinateurs et supprimant les autres systèmes d’exploitation et en s y installant confortablement à leurs places.
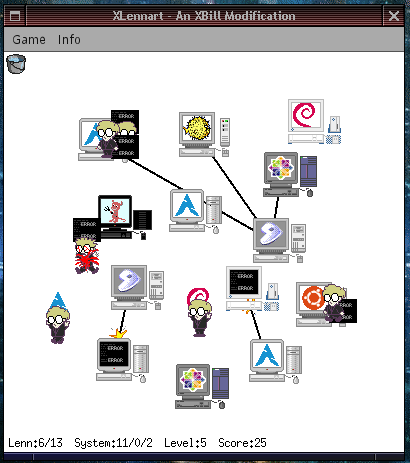
XLennart
Une version dérivée de ce jeu, XLennart, reprend le concept pour caricaturer la controverse autour de Lennart et son init, en montrant son installation remplaçant tous les init des autres systèmes sur les machines Unix-like, poursuivant ainsi l’esprit satirique de XBill appliqué à l’univers des systèmes libres. (N.D.R. : pour éviter de nourrir les trolls, on constate l’existence de cet inutilitaire sans prendre position sur la question de fond.)

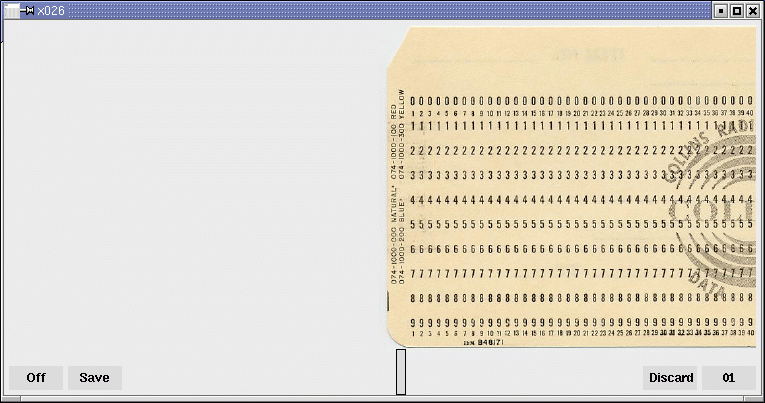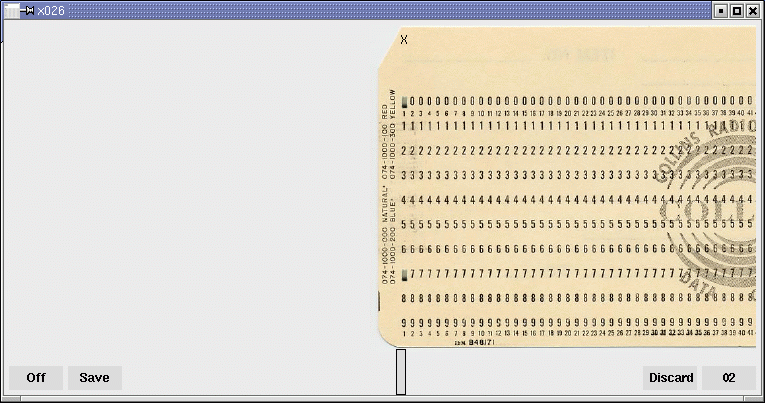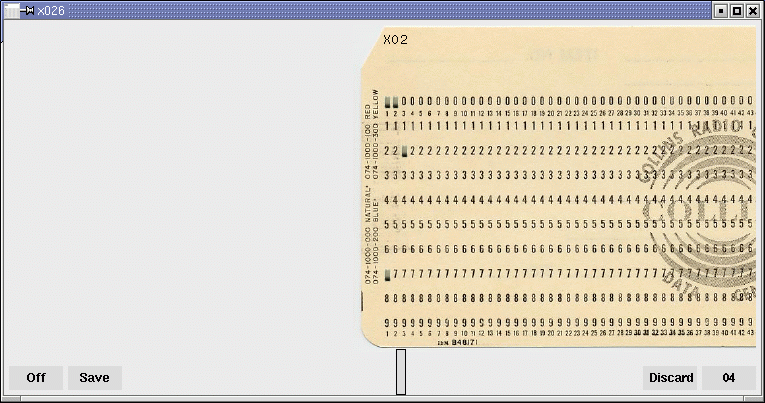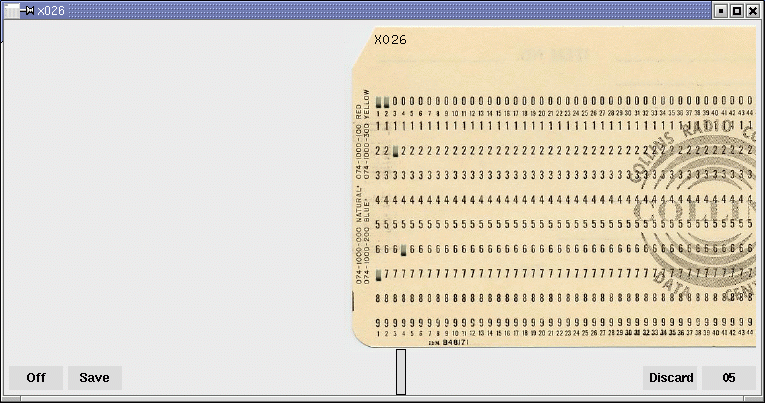
X026 : l’héritage des cartes perforées Hollerith
Bien avant les claviers et les écrans, l’informatique reposait sur des cartes perforées Hollerith, inventées à la fin du XIXᵉ siècle par Herman Hollerith. D’abord utilisées pour accélérer le recensement américain de 1890, elles sont devenues pendant des décennies le support central du stockage des données et des programmes. Dans les années 1950 à 1970, des machines comme le poinçon IBM 026 permettaient de transformer texte et chiffres en trous soigneusement alignés sur des cartes de 80 colonnes. Chaque caractère était codé en BCD-H, un système directement lisible par les ordinateurs de l’époque. Programmer en FORTRAN signifiait alors saisir chaque ligne sur une carte distincte : la moindre erreur impliquait de refaire la carte au format binaire BCD, ce qui imposait une grande rigueur. Le langage herita de ces syntaxes et exigeait ses règles strictes à cause du support physique : colonnes, indentation, numéros de lignes… bref, le code avait autant de contraintes que les joueurs de Tetris les plus acharnés !
L’émulateur X026 redonne vie à cette pratique. En simulant fidèlement l’IBM 026, il permet d’expérimenter concrètement la lenteur, la précision et la discipline qu’exigeait la saisie des données à l’ère des cartes perforées. Plus qu’un simple outil, X026 est une plongée dans l’histoire de l’informatique.
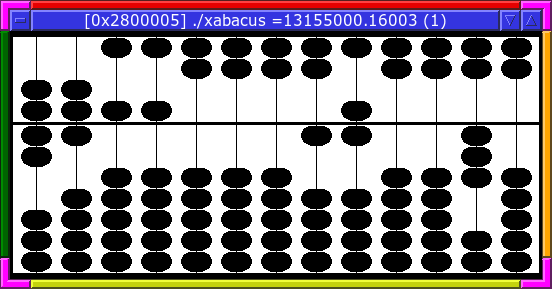
Xabacus
Xabacus est un émulateur de boulier qui illustre les origines du calcul manuel. Il complète bien des inutilitaires comme X026 en experimentant avec ce qui existait avant même l’ère des cartes perforées. Il reproduit le fonctionnement d’un boulier (souvent de type chinois suanpan 算盤 ou japonais soroban 算盤(そろばん) .
Assistant virtuel
Les assistants virtuels sont des personnages qui sont l'équivalent humain ou anthropomorphe des animaux virtuels et qui ont soit une fonction esthétique, soit parfois une fonction anecdotique.
Macopix
MaCoPiX (Mascot Constructive Pilot for X) est l'application de mascottes ultime pour les systèmes UNIX et X Window. Vous pouvez y créer des petites créatures qui se posent sur vos fenêtres, des mascottes fixes qui s'installent confortablement sur votre bureau, et même des mascottes horloges pour vous tenir compagnie tout en affichant l'heure. De quoi rendre votre bureau un peu plus vivant et amusant !

XClock Cat
Issu d’un imaginaire ancien du chat souriant, malicieux et légèrement surréaliste, popularisé dès 1865 par Lewis Carroll avec le Chat du Cheshire dans Alice au pays des merveilles, puis codifié visuellement par l’animation et le design américains des années 1920–1930 (grands yeux expressifs, sourire exagéré, animation souple de type rubber hose), cet archétype trouve une incarnation emblématique avec le Kit-Cat Klock au début des années 1930, célèbre horloge animée aux yeux roulants et à la queue oscillante, avant d’être réinterprété par Disney en 1951 dans Alice in Wonderland ; c’est dans cette continuité culturelle et graphique que s’inscrit Xclock catclock, une variante à base de motifs (motif-based) du programme xclock du X Window System, développée à la fin des années 1980 par des ingénieurs issus du MIT, de DEC, de BBN et de l’université de Berkeley, et remise en ligne sur GitHub à l’occasion du 30ᵉ anniversaire de X10 : cette version ajoute un mode animant yeux et queue à l’écran avec une option de suivi du tempo musical permettant de synchroniser les mouvements du chat avec la musique, Ce chat de Cheshire des temps moderne illustre la rencontre entre histoire de l’informatique, culture visuelle du cartoon et design ludique rétro.

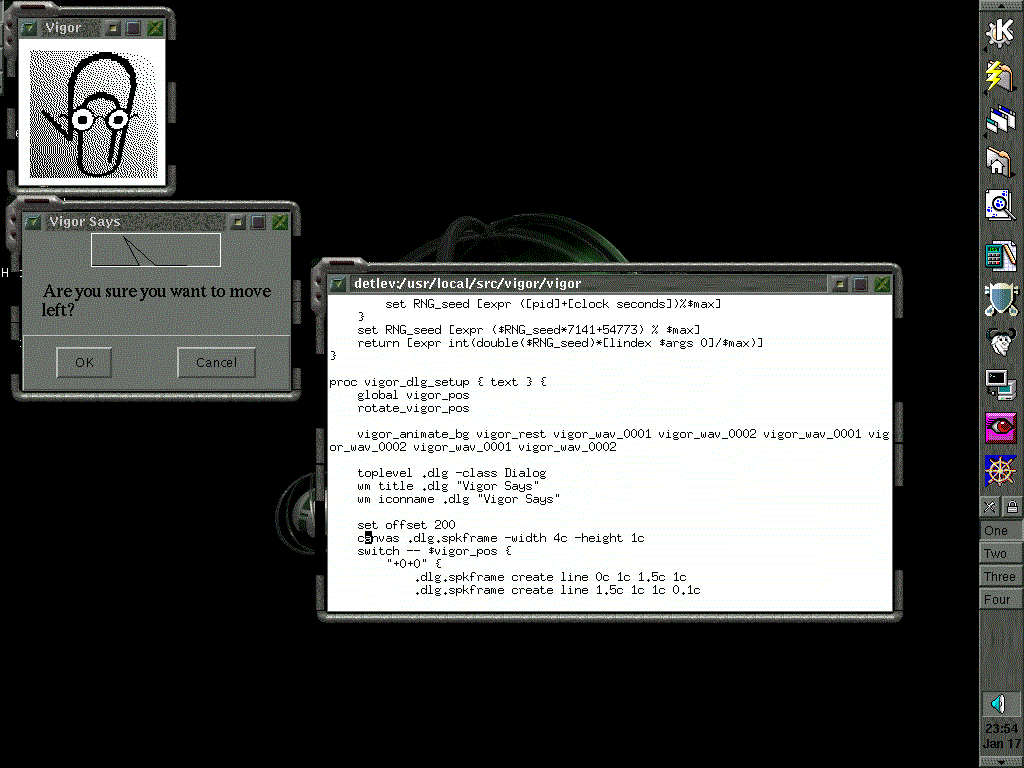
Viguor : le Clippy qui agace… encore plus que Clippy
Pour ceux qui ont connu la torture du traitement de texte Microsoft Word et de son assistant Clippy dans les années 90, Viguor, sur le ton de l’humour noir, permet de retrouver cette expérience frustrante… mais en pire. Cette caricature de l’assistant agaçant n’a qu’un seul objectif : vous faire sourire… ou doucement sombrer dans le désespoir numérique. Bien sûr, il vous demandera ironiquement de signer un impossible EULA/CLUF avant d’interagir avec lui.
KDE Amor
Amor est une interface permettant de gérer des animations virtuelles sous KDE. Cette application permet d'interagir avec différents personnages de bureau, ajoutant un peu de vie et d’interactivité à l’environnement de travail. Le store KDE fournie de nouvelles versions en ligne

Les écrans de veille : XScreensaver
Dans les temps anciens, lorsque les écrans affichaient une image fixe trop longtemps, ils pouvaient être endommagés par un phénomène appelé combustion interne du phosphore. Pour prévenir ce problème, des utilitaires appelés « économiseurs d'écran » ont été créés. Bien que cette fonction soit aujourd'hui obsolète, les écrans de veille sont devenus des artefacts artistiques en soi, souvent appréciés pour leur côté créatif. Aujourd'hui, tous les bons environnements de bureau en proposent, tandis que les mauvais ont tendance à les retirer de leur offre.
Ainsi, malgré leur origine pratique, les économiseurs d’écran ont évolué et continuent d’offrir une valeur ajoutée au-delà de leur utilité initiale. C’est précisément dans ce contexte que XScreenSaver s'inscrit comme un exemple parfait de réinvention. En 2022, il a célébré son trentième anniversaire, prouvant qu'un bon logiciel peut traverser le temps et les générations. Lancé en 1992, il est rapidement devenu un incontournable pour les systèmes Linux et Unix utilisant le système de fenêtres X11. En plus de proposer une vaste collection d’économiseurs d’écran, XScreenSaver devient une sorte de musée de l’informatique montrant les screensaver les plus vieux (comme la boule rouge et blanche d’Amiga) jusqu’aux effets de demos récentes, offrant une rétrospective de ce qui s'est fait aux différents âges de l’informatique. En somme, XScreenSaver est bien plus qu’une simple collection d’écrans de veille : c’est une courte contemplation, rétrospective esthétique de l’évolution de l’informatique comme peinture animée.


Les inutilitaires de « Passage »
Les inutilitaires suivants nous permettent de percevoir le passage, la spatialité et la transition entre les espaces et dimensions sous des angles multiples.
Passage du pixel art au jeu poétique
Poète symboliste influencé par Verlaine et Rimbaud, Antonio Machado privilégie la suggestion, le souffle du rythme et l’émotion intérieure plutôt que la description réaliste. Cette sensibilité se retrouve aussi dans Passage, qui n’est pas un simple jeu libre mais un jeu-art à forte dimension poétique. Comme dans la poésie symboliste, le sens n’est jamais donné explicitement : il se construit à travers des images simples, presque abstraites, et une atmosphère mélancolique. Le pixel art, volontairement épuré, agit comme un symbole, à l’image des paysages intérieurs de Machado, où le temps, le souvenir et le chemin de la vie sont suggérés plus que racontés. À la manière d’Antonio Machado, qui cherchaient à « faire sentir » plutôt qu’à expliquer, Passage invite le joueur à une expérience sensorielle et méditative, proche d’un poème visuel en mouvement.
Divulgachage / Spoiler Alert / Des vidéos de spoiler de Passage existent sur YouTube, mais nous ne vous déconseillons de les regarder avant d’y jouer. Comme dans la poésie symboliste d’Antonio Machado, le sens de l’œuvre naît de l’expérience personnelle et de la découverte progressive. Regarder le jeu à l’avance enlèverait une grande partie de son impact émotionnel, car Passage repose sur la surprise, le temps vécu et l’interprétation intime. À l’image d’un poème que l’on doit lire et ressentir soi-même, ce jeu-art ne se comprend pleinement qu’en étant parcouru, pas observé de l’extérieur

Du réalisme logiciel au réalisme magique… en labyrinthe
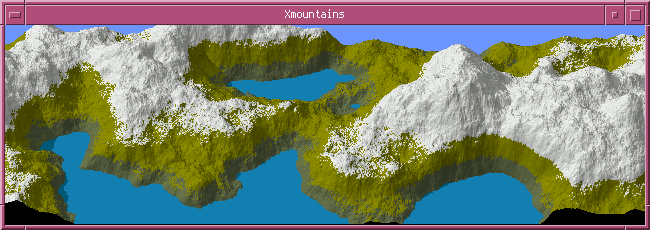
XEarth, XMountains et XWorld
Dans la cité-monde numérique, XEarth, XMountains et XWorld, véritables ancêtres de Google Earth et OpenStreetMap, incarnent une approche réaliste de l’exploration. XEarth reproduit la topographie et les climats d’une planète tangible, XMountains offre des chaînes de reliefs et de vallées à arpenter, et XWorld articule ces espaces en un réseau interconnecté reflétant un village global cohérent. Dans ces univers, la navigation est ordonnée et structurée : chaque élément a sa place, chaque espace peut être cartographié et compris, malgré leur grandeur presque infinie, rappelant la logique combinatoire finie mais immense décrite dans la Bibliothèque de Babel de Borges. Ces environnements offrent une immersion classique, vue extérieure, où l’utilisateur agit comme un arpenteur rationnel dans un monde cartographié et cohérent.
FSV2 et GopherVR
Dans FSV2 et GopherVR, chaque déplacement transforme l’espace en un labyrinthe vivant. En parcourant répertoires et sites, l’utilisateur croise des chemins qui se multiplient, se bifurquent et se recroisent, révélant des angles inattendus et des perspectives surprenantes à chaque pas. On ne se contente plus de « voir » : on ressent l’infini et l’ordre simultanément, chaque choix de parcours offrant un condensé d’informations et de points de vue au-delà de la perception 2D habituelle. Explorer ses fichiers dans FSV2 devient un acte poétique et intellectuel, presque rituel. GopherVR, quant à lui, transforme l’accès à la base de données en une exploration tridimensionnelle digne du Gibson dans le film Hackers
Pour ceux qui souhaitent une simulation du voyage dans le Gibson, XScreenSaver, cité précédemment, en offre cette expérience immersive. Comme dans La Demeure d’Astérion, chaque couloir, chaque recoin est à la fois familier et mystérieux, invitant l’utilisateur à se perdre pour mieux se retrouver, à savourer la surprise de chaque bifurcation et à redécouvrir l’ordinateur comme un espace à la fois tangible et imaginaire.

Le voyage de Neko et la retraite de Kodo
Réflexion sur les inutilitaires en tant qu’abandonwares libres et sur ceux sans équivalents libres
Dans notre exploration des inutilitaires graphiques libres, nous avons remarqué un contraste frappant entre deux situations. Cela nous a conduits à une réflexion sur le rapport entre abandonware et logiciel libre, que nous appellerons « le voyage de Neko et la retraite de Kodo », comme un conte philosophique oriental illustrant certains paradoxes numériques.
Le voyage de Neko
Il hante nos écrans d’un pas de velours numérique, ce petit chat blanc échappé des brumes des années 80. Neko… Son nom, qui signifie simplement « chat » en japonais, est bien plus qu’un mot : c’est une présence tranquille dans le paysage froid de la machine. Ce félin graphique est né sur les NEC PC-9801 en 1988 par Naoshi Watanabe (若田部 直), un programme propriétaire mais doté d’une grâce qui franchirait les décennies. Il a été le compagnon discret de nos révolutions numériques, suivant la danse des curseurs à travers les âges du silicium. Son ballet est hypnotique : il poursuit le pointeur avec la grâce d’un félin mythique, s’arrête parfois pour une pause, s’enroule sur lui-même, et succombe à un sommeil paisible, un sphinx pixelisé attendant le prochain mouvement.
1989 : Sur Macintosh, Neko devient un accessoire de bureau signé Kenji Gotoh, toujours propriétaire mais distribué gratuitement, avec ses fameuses animations de sommeil.
Années 90 : Il parcourt Windows 3.x (WNEKO et Neko Runs Free), IBM OS/2 et NEXTSTEP, restant à chaque fois propriétaire et distribué, mais non modifiable.
1991 (System 7) : Sur Mac, la version System 7 permet de modifier le pointeur avec divers jouets pour chat, ajoutant un charme ludique aux interactions.
1991 (Xneko) : Masayuki Koba (古場正行) réécrit Neko pour Unix/X11, lui donnant la liberté du code. Il devient alors un logiciel libre, partageable et modifiable.
Toujours em 1991 : Oneko par Tatsuya Kato transpose Xneko sur Linux et BSD, introduisant d’autres animaux. Son esprit libre pénètre les jardins de GNU/Linux
1997 : Sur Amiga, Neko devient Ameko, adaptation freeware mais sans code source ouvert. Pas encore de port pour Aros. Fin des années 90, un port fermé existe pour BeOS (Replicat).
Des années 2000 à aujourd’hui : Neko continue de danser sur nos écrans, que ce soit dans Tux Paint. On le retrouve notamment avec Neko on Desktop (Mac, 2000), webneko en JavaScript (2004), Neko in Java (2010), une version tactile sur Arduino (2010), Neko x64 pour Windows (2010) et enfin sur Android via le repot libre F-Droid avec Aneko
Ainsi, le voyage de Neko s’écrit des contrées privatives aux archipels du libre : un petit chat de pixels, doux fantôme du passé, qui rappelle que la magie réside parfois dans les choses les plus simples.
Cependant, ce voyage soulève une question : combien d’autres fantômes numériques, d’inutilitaires propriétaires, sont restés prisonniers de leurs époques et de systèmes fermés, incapables de franchir le miroir ? De nombreux petits programmes sur Amiga, Atari ST,Amstrad CPC, OS/2, Acorn, Sinclair QL, Commodore 64, ZxSpectrum, MS-DOS, DR DOS Windows 3.1 Windows 95 et toutes les familles Unix proprietaires… ont disparu avec les systèmes d’exploitation qui les portaient, abandonnés à jamais.

La retraite de Kodo
En parallèle, on trouve Kodo ou Kodometer, né libre mais ayant connu un retrait de parcours.Kodomètre était une application KDE qui mesurait la distance parcourue par le curseur de la souris sur le bureau. Son interface imitait un compteur kilométrique et permettait de suivre la distance totale ainsi que des trajets précis, en unités métriques ou américaines.À l’origine basé sur le programme VMS/Motif Xodometer de Mark H. Granoff, il a été porté vers KDE/C++ par Armen Nakashian, qui l’a découvert sur le bureau d’un collègue. L’application restait surtout ludique, permettant d’observer ses habitudes d’utilisation. Avec le temps, Kodomètre a été abandonné : il ne figurait plus dans les paquets KDE.
Abandonware et logiciel libre : fragilité des inutilitaires
Ainsi, certains inutilitaires propriétaires ont été définitivement abandonnés, tandis que d’autres, semblent glisser progressivement vers ce statut. D’autres encore n’ont jamais franchi « l’autre côté du miroir », à l’image du voyage de Neko, c’est-à-dire le passage d’un modèle propriétaire vers une version libre. Bien que cela n’altère pas leur valeur ludique, artistique ou philosophique, cela compromet leur avenir : privés de sources accessibles, ils perdent toute possibilité d’évolution et de renouvellement. Pour ceux qui ne sont pas passés de l’autre côté du miroir, l’émulation ou la virtualisation restent souvent les seuls moyens de les préserver de l’oubli. Toutefois, en tant qu’inutilitaires peu connus, ils risquent de disparaître lentement de la mémoire collective. L’approche préservation d’abandonware tente d’apporter une réponse, mais elle demeure contraignante : rares sont ceux qui installeront un système complet, en dual-boot ou en machine virtuelle, au seul fin de retrouver la poésie singulière de ces inutilitaires obscures. Dans le cas de la mise en retrait de Kodo, ou de l’abandonware dans le logiciel libre, Eric S. Raymond rappelait un principe fondamental :
« When you lose interest in a program, your last duty to it is to hand it off to a competent successor. »
Comme il le souligne dans The Cathedral and the Bazaar, la vitalité d’un logiciel dépend non seulement de l’engagement de ses créateurs initiaux, mais aussi de leur capacité à le transmettre à ceux qui sauront le faire vivre et évoluer.
Cette dualité met en lumière la fragilité des « inutilitaires » numériques : les logiciels propriétaires abandonnés demeurent prisonniers de leur époque, tandis que certains logiciels libres sombrent également dans l’oubli faute de suivi ou de communauté active.
Nous en arrivons désormais à Gource, afin de percevoir ce que représente une communauté vivante, participative et active : la face la plus connue du logiciel libre, celle que tous les community managers aspirent à montrer et que tous les participants souhaitent expérimenter, à l’inverse des logiciels abandonnés.
Gource en guise de conclusion pour 2025 et de Passage en 2026
Gource ou la danse du libre dans le village global contemporain
En passant à la nouvelle année 2026, notre ère actuelle de la participation collaborative, portée par les projets libres et open source, Gource déploie l’histoire d’un projet logiciel comme un poème en mouvement : des points de lumière naissent, se rapprochent, se séparent, traçant dans l’obscurité la mémoire vivante du code. Chaque commit devient une bifurcation du temps, et l’écran se fait constellation où l’effort collectif palpite. À la manière d’Octavio Paz, cette visualisation n’explique pas : elle révèle. Elle suspend le regard entre le flux et la forme, entre l’instant et la durée, rappelant le mouvement circulaire de son texte Piedra de sol (1957), où le temps n’avance pas en ligne droite mais revient, se replie et se réinvente. De la même façon, Gource ne raconte pas le développement comme une simple succession de versions, mais comme un présent perpétuel où passé et devenir coexistent à l’écran.
Chaque apparition de fichier ou de contributeur agit comme un « instant éclair », où le flux se condense et devient visible. La visualisation devient alors un espace de dialogue — entre individus, entre traces, entre silence et action — faisant écho à Blanco (1967), poème de l’espace et de la relation, ouvert à des lectures multiples, sans centre unique. Comme chez Paz, le sens ne naît pas de la juxtaposition de signes, mais de leur mise en relation.
Cette pluralité en mouvement rejoint la vision cosmopolite de Himno entre ruinas, où les voix du monde se croisent sans se dissoudre. Gource matérialise cette dynamique en montrant le développement comme une constellation d’acteurs dispersés sur la planète, unis par un même espace symbolique. Ici, l’interconnexion n’est pas un simple outil technique : elle est la condition même de l’existence du projet. C’est en cela que Gource rejoint la pensée de Marshall McLuhan, pour qui le « village global » ne désigne pas une uniformisation du monde, mais une intensification des relations, où chaque geste local résonne immédiatement à l’échelle planétaire.
Enfin, à l’image de Viento entero, où le présent se construit à partir de fragments hérités et réassemblés, Gource fait émerger une œuvre collective à partir de traces, de modifications successives, de strates de mémoire. Dans cette cité-monde interconnectée que McLuhan entrevoyait, la réflexion ne commence plus à partir d’un centre stable, mais du réseau lui-même. Gource en offre une figuration sensible : un village global de code et de lumière, où la création naît du passage, de l’échange et de la rencontre, et où l’interconnexion devient le point de départ de toute pensée commune.
Chaque contribution devient un souffle, chaque fichier une étoile, et le code collectif se déploie comme un poème en mouvement, où passé et présent, technique et humain, local et global s’entrelacent. C’est ainsi que nous sommes invités à percevoir nos vies numériques au cœur de nos interactions et de nos commits au sein de ce projet planétaire.
Ainsi, à travers Gource, l’esthétique du processus de collaboration globale propre au logiciel libre apporte une réponse concrète au questionnement du philosophe Byung-Chul Han (Pyŏng-ch’ŏl Han 한병전), qui déplorait la perte de profondeur au profit de surfaces lisses, brillantes et réflexives, mais fondamentalement creuses. Gource, par sa cartographie en constellations des processus collaboratifs du logiciel libre, démontre qu’il est possible d’évoluer au sein d’une constellation scintillante sans renoncer à la profondeur, celle-ci étant incarnée par le code source, l’historique des contributions et le processus open source d’élaboration collective du logiciel libre.
Contrairement aux œuvres de Jeff Koons, dont la brillance tend à masquer le vide, la visualisation proposée par Gource repose sur un socle profond, multiple et participatif. La surface lumineuse n’y est jamais autonome : elle renvoie toujours à une réalité sous-jacente faite de travail, de temporalité, de négociations, et de coopérations. En ce sens, Gource peut être considéré comme un exemple paradigmatique d’un reflet brillant issu d’un modèle profondément structuré, à l’exact opposé de l’esthétique lisse et creuse dénoncée par Han.
Par ailleurs, Gource incarne de manière exemplaire un espace de l’altérité, rendu visible par la contribution de chacun. Chaque contributeur y apporte sa perspective singulière, sa sensibilité propre et sa touche personnelle, participant ainsi à une œuvre collective en perpétuel devenir. Cette dynamique rejoint l’analyse d’Eric S. Raymond dans The Cathedral and the Bazaar, lorsqu’il souligne que « The next best thing to having good ideas is recognizing good ideas from your users », rappelant que la richesse du logiciel libre réside précisément dans la reconnaissance et l’intégration des apports de l’autre.
Enfin, à l’instar des poèmes de Han Shan surgissant sur les rochers ou les murs, Gource fait apparaître un ciel constellé, où chaque contribution éclaire fugitivement la galaxie vivante du projet, révélant la fluidité d’un processus créatif libre et en mouvement.


Conclusion
L’histoire des inutilitaires se déploie comme une poésie vivante, du calcul solitaire à l’intelligence collective. Sur son chemin, des instants inattendus surgissent : Xteddy, simple peluche virtuelle, montre que l’inutile peut étonner, émerveiller et tisser des liens, éveillant réflexion et imagination.
Les communautés libres insufflent vie à ces créations, leur offrant la force de survivre, d’évoluer et de voyager librement de plateforme en plateforme, à l’instar de Neko.
Dans un monde de codes et de réseaux, chaque contribution devient une étoile dans le « village global » de McLuhan, où frontières et distances s’effacent. Gource, FSV2 et GopherVR transforment l’exploration numérique en chorégraphie de lumière et de mémoire, révélant l’élan vivant et créatif des communautés du logiciel libre. L’informatique cesse alors d’être purement utilitaire : elle devient poésie, labyrinthe et voyage.
Mais la survie d’un logiciel ne repose pas seulement sur l’ouverture de son code : elle exige transmission, engagement communautaire et capacité à évoluer. Nous espérons que de plus en plus d’abandonwares et d’inutilitaires suivront le voyage de Neko, passant de l’ombre à la lumière du libre, enrichissant sans cesse l’espace vivant du logiciel. Il est tout aussi crucial que les logiciels déjà libres ne soient pas abandonnés, afin que l’histoire de l’informatique continue de s’écrire dans une dynamique collective et créative, où chacun reste acteur de son informatique, à l’inverse des monopoles évoqués dans XBill.
Et qu’un jour, nous puissions nous voir dans une de ces constellations cartographiques telle que Gource nous le montre, pour contempler, émerveillés, que dans cette poésie numérique, nous y avons tous participé.
Bonne année 2026 !
Pour aller plus loin ensemble en traineau
Il existe peu de livres consacrés aux inutilitaires, car, comme le pensait IBM (à l’inverse, par exemple, de l’Amiga) et sous son influence sur le domaine, l’informatique était considérée comme une affaire sérieuse. Pourtant, certains ouvrages ont documenté et inspiré ces créations décalées et humoristiques, notamment :
- PC Gags, Paperback, 27 août 1997, Mark Torben Rudolph
- The Best of Verity Stob: Highlights of Verity Stob's Famous Columns from .EXE, Dr. Dobb's Journal, and The Register,
- UNIX®–Haters Handbook, Garfinkel, Paperback, 1 juin 1994 (English edition)
- La Philosophie des Systèmes d’Exploitation (Linux and the Unix Philosophy, 2ᵉ édition)
- et les anciens magazines d’informatique comme outil de préservation de l’abandonware ludique.
Commentaires : voir le flux Atom ouvrir dans le navigateur