Disclaimer, vu le sujet : cet article représente mon opinion toute personnelle rien qu'à moi sur le sujet, et n'a évidemment rien à voir avec celle de mon employeur actuel (que j'ignore, d'ailleurs). D'ailleurs vous savez ce qu'on dit des opinions : si cet article vous contrarie, je vous invite à le considérer comme du jetable, plutôt que comme quelque chose auquel il faut nécessairement réagir.
Il y a quelques années (déjà !), je vous bassinais avec les tests ADN à la mode – ce merveilleux cadeau de Noël qui permet à votre cousin de découvrir qu’il est à 2%, viking, et à votre assureur de découvrir qu’il ne vous assurera plus jamais. Je l'ai retrouvé sous une couche de poussière à la faveur de l'annonce de la revente de la base de données de 23andme (que je prenais comme exemple à l'époque) à un labo pharmaceutique, ancrant dans la réalité le pire scénario que j'esquissais à l'époque.
Mais aujourd’hui, on va parler d’un nouveau joujou : les analyses sanguines « deep health », comme celles proposées par Lucis (ex-ZeroHealth). Non pas que cette entreprise en particulier me pose problème : c'est celle dont on m'a parlé, et la seule que je connaisse. Rien de ciblé, donc. Leur promesse : grâce à des « biomarqueurs avancés », vous allez tout savoir sur votre santé (« et même ce que votre médecin n’ose pas vous dire ! »). On vous vend des tableaux de bord colorés, des « insights » personnalisés, et une impression de contrôle total sur votre corps. Mais ce qu’on ne vous explique pas, c’est que la vraie valeur, ce n’est pas votre cholestérol – c’est votre data. En vrai, c’est surtout un nouveau business model : la monétisation de votre biologie.
Science ou science-fiction ?
Vous pensiez que la médecine avait raté quelque chose ? Rassurez-vous, non.
Commençons par la base (et vous qui me connaissez savez que je suis très attaché à cet aspect particulier) : est-ce que ces tests sont reconnus par la communauté médicale ?Spoiler : non, pas tellement.
Les sociétés savantes comme l’American Medical Association (AMA) ou la European Society of Cardiology (ESC) ne recommandent pas ce genre de panels XXL pour Monsieur et Madame Tout-le-Monde. À moins d’avoir une pathologie précise ou un contexte clinique solide, on considère que ces tests relèvent plus du marketing que de la médecine fondée sur les preuves. La plupart des « plages optimales » de ces biomarqueurs sortent de l’imagination fertile des boîtes qui les vendent, pas de grandes études randomisées ou de méta-analyses. Et puis, tester 50 trucs à la fois, ça augmente surtout les fausses alertes et l’anxiété (sans parler du surdiagnostic et de ses conséquences), pas la santé publique.
D'aileurs, on n'a aucune preuve d’amélioration de quoi que ce soit. L’ESC précise même que le dépistage large chez les personnes à faible risque n’a que peu d’impact, voire aucun, sur la prévention réelle ! (source : ESC)
🥑 Aparté : les tests d’allergies et d’intolérances alimentaires… à 500 € la désillusion
Vous avez probablement déjà vu passer ces publicités pour des tests « révolutionnaires » d’allergies et d’intolérances alimentaires, proposés en direct, parfois à plus de 500 €. Promis, avec une goutte de sang ou un prélèvement de cheveux, vous saurez enfin pourquoi les brocolis vous font gonfler ou pourquoi la pizza vous rend « bizarre ». Petit rappel scientifique :
Ces tests ne reposent sur aucun consensus médical sérieux. La Haute Autorité de Santé, l’Académie de Médecine ou encore la Société Française d’Allergologie déconseillent formellement ces pratiques.
Les tests IgG, par exemple, n’ont aucune valeur diagnostique pour les intolérances alimentaires. Pire, ils peuvent pousser à des régimes d’éviction inutiles et parfois dangereux.
Ce que disent les allergologues : Seuls les tests validés (prick-tests, dosages IgE spécifiques, etc.), prescrits par un médecin, ont une réelle utilité.
Le vrai risque : dépenser une fortune pour des résultats fantaisistes, culpabiliser sans raison, et finir carencé parce qu’un algorithme vous interdit le pain, le lait et la tomate.
En résumé : Mieux vaut garder vos 500 €, consulter un vrai allergologue… et ne pas vous priver de raclette sur la foi d’un test acheté sur Internet.
« Ils disent que l’information, c’est le pouvoir. Apparemment, mon sang aussi. »
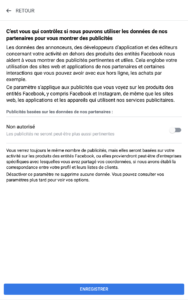
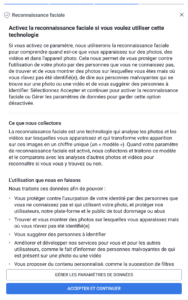
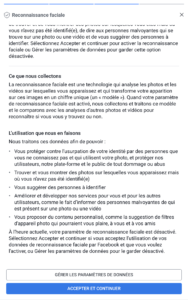
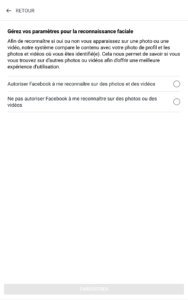
Et la vie privée dans tout ça ?
Bon, maintenant, parlons de ce qui nous intéresse encore plus que la validité scientifique de la chose : vos données. Quand on me dit : « T’inquiète, c’est pas comme l’ADN, tu ne donnes que tes résultats de prise de sang », j’ai envie de répondre : « Oui, et alors ? »
L’ensemble des marqueurs, croisés avec d’autres infos (âge, sexe, antécédents…), ça devient très parlant. Et surtout, ça se revend très bien.
Le labo analyse votre sang, OK, mais qui récupère le PDF final ? La startup, évidemment. Le labo est souvent certifié, mais vos résultats transitent ensuite vers une plateforme qui, elle, n’est pas soumise aux mêmes obligations que votre médecin ou votre hôpital.
Que fait-elle de ces données ? Bien malin qui peut répondre à cette question. Parfois, l'entreprise annonce tout bien comme il faut : conformité RGPD, stockage sécurisé, anonymisation (parfois même “pseudonymisation”, le mot préféré du RGPD bingo). Mais souvent, elle se réserve le droit d’utiliser vos données pour la recherche, l’amélioration du service, voire pour les vendre anonymisées à des partenaires. (Et entre nous, la ré-identification, c’est pas si compliqué quand on a des jeux de données croisés.)
Et demain ? Les CGU changent, les startups pivotent, les rachats arrivent. Un jour, c’est 23andme. Le lendemain, c’est BigPharma qui rachète la base. Bonne chance pour faire valoir votre droit à l’oubli. Et ça c'est sans compter les éventuelles bases bases de données et autres buckets S3 mal protégés et autres joyeusetés. Finalement, votre sang circule plus que vous ne le pensez.
Quelques conseils de vieux parano :
Lisez les CGU et la politique de confidentialité. (Oui, c’est chiant. Mais c’est pire de se faire siphonner ses données.) Sur celle de Lucis par exemple, pas de liste de tiers ou sous-traitants, un mauvais point.
N’utilisez que le strict minimum d’infos personnelles. Si le service accepte les pseudonymes, profitez-en. Si vous pouvez utiliser un email dédié, faites-le.
Posez-vous la question : ai-je vraiment besoin de ce test ? Ou est-ce juste pour avoir un joli dashboard ?
Ce test est-il validé par une société savante ? (Indice : si ce n’est pas le cas, méfiance.)
Restez critique sur les recommandations données. L’avis de votre médecin, c’est pas mal aussi. Lui, au moins, il n’a pas de stock options sur votre ferritine (normalement).
En résumé
Les tests sanguins « next-gen » promettent de révolutionner votre santé, mais n’ont pas de validation scientifique solide et posent de vraies questions de privacy. Vos données valent cher, alors ne les bradez pas pour un graphique coloré. Et surtout, gardez votre sang-froid (désolé).
Bref, on nous refait le coup du « quantified self » : plus de chiffres, plus de dashboards, mais pas forcément plus de santé. L’illusion du contrôle, la réalité du data mining.
Retrouvez-moi dans quelques années pour le billet « Pourquoi j’ai refusé de faire analyser mes ongles par une app IoT connectée à TikTok ». En attendant, prenez soin de vous… et de vos données.
Vous le savez peut-être déjà, mais on a récemment (ou pas, finalement) vu arriver un premier amendement à notre chère norme ISO 27001 version 2022 (et à un autre paquet de normes ISO, puisqu'elles sont 31 à être affectées par ce changement), intitulé "Changements concernant les actions en lien avec le climat".
Voyons concrètement de quoi il retourne ! 🕵️
Concrètement, ça change quoi ?
C'est là qu'on rigole : la liste des changements est minime. Bon, c'est un amendement aussi, pas une annexe, mais quand même. 😄
Les changements sont au nombre de deux :
4.1 - Compréhension de l’organisme et de son contexte
On ajoute ici la mention:
L’organisme doit déterminer si de tels enjeux découlent des changements climatiques.
4.2 - Compréhension des besoins et attentes des parties intéressées
Cette fois, on ajoute :
NOTE 2 : Les parties intéressées concernées peuvent avoir des exigences relatives aux changements climatiques.
Et c'est tout.
Comment implémenter ça ?
En 2024, il est fort probable que ce qui touche au changement climatique figure déjà ici ou là dans un document, une politique... de l'entreprise. Et je ne parle même pas du cas de la norme ISO 14001 😅
Pour la clause 4.1, concrètement, si vous prenez déjà ces enjeux en compte par ailleurs, vous n'avez rien à faire. Voilà. De rien.
Dans le cas contraire, et sur la base des premiers retours que j'ai pu avoir d'auditeurs et audités, vous devez mettre à jour le contexte de l'organisation dans votre manuel SMSI, en ajoutant un petit laïus indiquant que vous avez considéré le changement climatique et qu'il a été conclu qu'il n'est pas un risque pertinent pour vous ou pour le SMSI, et que cela a été validé par les instances de gouvernance du SMSI. C'est probablement le moyen le plus simple et le plus rapide pour satisfaire à cette nouvelle exigence.
Mon opinion personnelle, c'est que vous pouvez en profiter pour pointer vers votre PCA/PRA, lequel inclut probablement déjà des évènements en liens avec (ou assimilables) les changements climatiques : vagues de chaleur plus longues et qui nécessiteraient de climatiser vos serveurs, inondations plus fréquentes pouvant vous pousser à envisager des backups sur des sites physiques distincts...
Évidemment, il y a des entreprises pour lesquelles ça ne se limite pas à ça : si les changements climatiques constituent un risque important pour vous, vous devez l'ajouter au registre des risques et le gérer comme vos autres risques.
Pour la clause 4.2, vous devez demander aux parties intéressées si le changement climatique les concerne et, le cas échéant, de quelle manière, afin d'inclure cette exigence dans la mise en œuvre de votre SMSI. Comme toujours, gardez une trace de ces questions pour vos auditeurs, histoire de démontrer que ce n'était pas pertinent ou, si c'est le cas pour une partie prenante, de prouver que vous avez fait ou prévu de faire quelque chose pour satisfaire à cette attente.
Illustration générée par ChatGPT (on s'amuse comme on peut)
Conclusion : ne vous prenez pas trop la tête !
Disons qu'au pire, vous risquez une observation durant votre prochain audit, et que vous aurez à prendre cet amendement en compte d'ici la prochaine fois. Après, comme pour le contrôle technique automobile, moins on a d'observations, mieux c'est, et vu la quantité de travail réduite induite par cet amendement, on aurait tort de faire l'impasse dessus. Et n'allez pas payer un consultant pour ça : ça n'en vaut pas la peine selon moi (mais vous faites bien ce que vous voulez après tout !).
💡Note importante : cet amendement n'a aucun impact sur vos certifications actuelles, sur le domaine d'application de votre système de management certifié, ou encore sur votre planning d'audits. Relax !
Pensée personnelle : vous connaissez probablement (surtout si vous traînez dans le coin depuis un moment) mon fort intérêt pour le développement durable. Malgré ça, je me pose la question de la pertinence d'un tel amendement pour la norme ISO 27001 spécifiquement : ça me donne plus l'impression de faire du boxticking qu'autre chose, et c'est quelque chose qui me déplaît, alors que c'est une des raisons qui me font préférer l'ISO 27001 à SOC2 par exemple. Allez, disons que ça participe de la prise de conscience collective à propos de l'urgence climatique ! 😊
Prenons quelques minutes en ce début d'année pour sortir ce modeste blog des limbes du Web et discuter d'un sujet problématique depuis trop longtemps : l'envoi de données de santé à une pharmacie.
Contexte
Prenons un cas réel : ma compagne et moi-même. Il nous arrive d'être malades, et/ou de devoir faire un test PCR/antigénique. Problème : on vit dans un quasi-désert médical, et notre médecin traitant est à plus d'une heure de voiture. On utilise donc, quand c'est possible ou pour des sujets où la connaissance/confiance liée au médecin traitant est importante, la télé-consultation. De plus, madame a perdu sa carte d'assurance santé complémentaire il y a plusieurs mois, et se contente de la version numérique, sur smartphone donc. Autant de raisons qui nous poussent donc, et ce d'autant qu'on ne possède pas d'imprimante, à partager les ordonnances (et, selon où nous sommes, la carte d'assurance santé complémentaires de ma compagne) avec la pharmacie par voie électronique.
C'est là qu'est le drame. Alors oui, pas mal de pharmacies ne proposent ce service que depuis le début de la crise sanitaire, pour limiter le temps passé par le malade dans la pharmacie, et aussi parce que les malades Covid-19 avaient massivement recours à la téléconsultation (je crois même me souvenir que dans pas mal de cas, en cas de suspicion de Covid, c'était requis par certains médecins) et que tous ne disposent pas d'une imprimante à la maison (comme votre serviteur). Mais la pratique elle-même est je pense amenée à perdurer, et c'est tant mieux. Même si au final, beaucoup de pharmaciens impriment l'ordonnance pour la re-numériser ensuite, et la donner au client.
Passons sur l'aspect écologique de la chose et venons-en au partage du document lui-même, et surtout à la confidentialité requise pour l'envoi et le stockage de données de santé. Car oui, on est en présence de telles données : - une carte de "mutuelle" est évidemment considérée comme donnée de santé ne serait-ce que parce qu'elle contient le NIR (le "numéro de Sécu"), considéré comme "donnée sensible" d'après le RGPD / la loi "Informatique & Libertés" ; - une ordonnance est rattachée au dossier du malade, et contient nom/prénom/date de naissance, en plus des prescriptions pouvant assez clairement indiquer le mal dont souffre la personne concernée.
Sans même aborder le sujet du côté du patient, qui ne dispose probablement pas d'une solution offrant la sécurité et la confidentialité adaptées à ces données, intéressons-nous à ce que proposent les pharmacies. La liste n'est évidemment pas exhaustive, mais ce sont les cas de figures auxquels j'ai été personnellement confrontés.
Certaines officines proposent une solution "clé en main" : l'interfaçage avec Doctolib, solution très répandue (quoi qu'on en dise, ou quoi qu'on pense du fait que ce ne serait pas à une société privée de tenir un tel rôle, tout ça tout ça) et certifiée pour l'hébergement de données de santé (HDS) depuis fin 2021, et certifiée ISO 27001 (une norme internationale relative à la sécurité des systèmes d'information). Cela permet au patient, directement depuis son appli Doctolib, de partager les documents qui y sont stockés avec des pharmacies ou d'autres professionnels de santé, de façon sécurisée. Seul bémol : ces fonctions, si elles sont gratuites pour nous autres patients, sont payantes pour les professionnels de santé. On va y revenir.
D'autres officines, la majorité de celles que j'ai pu visiter depuis 2020, passent tout simplement par... mail. Oui. Des données de santé, en clair, par courriel, quand même la CNIL demande de ne pas envoyer de copies de cartes nationales d'identité par ce même canal, trop peu sécurisé, trop souvent sujet aux intrusions, "piratages"... et avec pour conséquence de nombreuses usurpations d'identité, entre autres joyeusetés.
On n'envoie pas de données personnelles par mail en clair, non non ! Source : Légifrance, sanction CNIL vs. Groupe Accor
Dites bonjour à pharmacieduboulevard.codepostal@gmail.com, à pharmaciedusoleil@hotmail.fr et autres adresses hébergées par des services gratuits à destination (principalement) des particuliers.
Voilà pour le décor. Maintenant, les questions, et les réponses qui vont avec.
*mail est-il compatible avec le RGPD ?
La question pourrait être posée de façon plus complète, parce que le RGPD n'est pas le seul texte de loi intervenant ici : il y en a d'autres, à commencer par le Code de la Santé Publique. Mes excuses aux puristes, la vulgarisation implique comme bien souvent des raccourcis, au détriment de la précision.
Mais la réponse est pourtant simple et courte : que ce soit un compte GMail, Hotmail, Laposte.net ou autre, ces solutions n'offrent pas de garanties suffisantes pour respecter les obligations liées aux données de santé, aussi bien du côté du RGPD que du côté HDS.
Qui est responsable de quoi ?
Une pharmacie qui utilise un compte mail gratuit (disons "grand public") porte la responsabilité juridique des pertes ou vols de données, et plus largement c'est à elle de démontrer sa conformité au RGPD, ce qui en l'espèce est tout simplement impossible. En cas de plainte d'un client, la CNIL pourrait décider d'une sanction pécuniaire pouvant s'élever à 4% du chiffre d’affaires mondial de l’année d’exercice précédent.
Du point de vue "risques", le fournisseur ne porte ici pas grand chose (pour ne pas dire rien), contrairement à ce qu'aurait pu définir un contrat pour un service "fait pour" (et même Google Workspace propose une variante HDS de ses services de messagerie électronique).
La pratique visant à faire des économies de bouts de chandelle et à préférer un compte de messagerie gratuit n'est pas simplement à déconseiller ou à éviter. Elle est totalement illégale, et à bannir. Elle met à risque les données personnelles des patients, déjà bien trop souvent exposées, et notamment dans les pharmacies utilisant la solution d'Iqvia, comme révélé dans un reportage "Cash Investigations" il y a quelques années.
Oui mais...
Certes, le patient utilise probablement la boîte de messagerie de son fournisseur d'accès à Internet, ou une quelconque boîte gratuite.
La problématique n'est pas vraiment la même : il ne manipule a priori que les données le concernant et fait le choix de la simplicité, souvent faute de connaissances/compétences. Le pharmacien, lui, centralise les données de nombreux malades.
Et on peut tout à fait lui proposer des solutions accessibles et répondant à notre enjeu. C'est ce que font notamment Doctolib et Mon Espace Santé (mais pas que). Et oui, parfois, un tel outil se paie. À vous, pharmaciens, de proposer et d'orienter vos clients vers ces services, plutôt que de tout offrir à Google ou Microsoft (hors environnement sécurisé).
La suite
Là aussi, je vais faire court.
À quand une obligation, pour toutes les professions de santé, d'utiliser une messagerie sécurisée ? C'est le cas pour les médecins depuis plusieurs années. Étendons cela !
Et puisqu'on parle de données de santé, de leur stockage, de la confiance qu'on accorde tant au professionnel de santé en face de nous qu'à ses pratiques informatiques : réfléchissez aux données de santé que vous fournissez à des charl... à des "non-professionnels de santé" comme des naturopathes, magnétiseurs, ostéopathes "exclusifs"... Comment communiquez-vous avec eux ? Comment stockent-ils votre dossier médical, puisqu'ils n'ont pas accès aux outils habituellement utilisés par les médecins, pharmaciens... ?
Vous seriez surpris de savoir combien gardent ça dans des OneDrive ou Google Drive personnels, ou prennent des notes sur Dropbox.
2021 étant l’année de tous les changements (non), mais sans aller jusqu’à fonder une civilisation sous-marine coupée du monde, on va tout de même essayer de se faire une petite bulle de protection face à tous les pisteurs qui peuplent notre quotidien numérique.
Bien évidemment, tous les outils dont je vais parler ne sont pas parfaits, ne garantiront pas un anonymat complet quel qu’il soit, et ne sont peut-être pas les meilleurs. Simplement, ils sont ceux que j’utilise et recommande pour assainir un peu la navigation sur le net, tout en restant utilisables par tout le monde. On reviendra sur ce point spécifique qui n’est finalement pas du détail.
Je vais donc essayer de lister ici, par « grandes thématiques », des outils, des logiciels, des extensions… qui devraient vous aider à rendre votre écosystème numérique de tous les jours un peu plus sain pour tout le monde. De la même façon, pour de rares outils, je vous conseillerai de ne pas les utiliser (et j’expliquerai pourquoi, quand bien même ça n’engage que moi). Je ne peux évidemment pas être exhaustif : ne soyez pas contrarié(e) si l’outil top-moumoute que vous utilisez ne figure pas dans la liste, prenez plutôt 2 minutes pour passer sur Twitter ou Matrix et me suggérer de l’ajouter. Oh, et sauf indication contraire, tous ces outils seront libres et gratuits. Et je pars du principe que vous utilisez un navigateur décent (genre Firefox).
Blocage de la publicité, des pisteurs, du suivi…
Dans un navigateur Web
La façon la plus simple et courante de faire, c’est de passer par une extension qui gérera cela pour vous. Citons (et je mets en gras ce que j'utilise) :
uBlock Origin, qui est à mon sens le plus simple et le plus efficace. Il bloque la plupart des nuisances et fonctionne via « liste noire », permettant si nécessaire de débloquer une ressource spécifique qui « casserait » le site que vous visitez.
AdNauseam, qui est un « fork » (comprenez « dérivé de » ) uBlock Origin. Concrètement, il utilise la même liste de blocage et fonctionne de la même façon, à la différence qu’il simule une forme d’interaction avec chaque publicité affichée avant de la masquer. De ce fait, vous ne la voyez pas, mais en plus AdNauseam « pourrit » le profil publicitaire associé, qui ne vaut pour ainsi dire plus rien. Il a également le bon goût de montrer une estimation du coût (en $) qu’il a fait perdre aux régies publicitaires.
Decentraleyes, qui répond à une autre forme de pisteurs. Outre les habituels réseaux sociaux et régies pub, le Web moderne souffre d’une autre plaie, les CDN (pour « Content Delivery Network »). Pour faire très simple, plusieurs sites utilisant la librairie jQuery par exemple, plutôt que de l’héberger eux-mêmes, vont directement l’appeler depuis le CDN tiers. Lequel CDN sait, via cet appel, qui consulte la page, et peut tracer votre navigation au travers des multiples sites que vous visitez et qui feraient appel à ses services. Decentraleyes intercepte cet appel, et le remplace par le même fichier, mais stocké localement, sur votre machine.
ClearURLs, qui sert à « nettoyer » les liens des pages que vous visitez/partagez. C’est extrêmement pénible (et moche) de recevoir un lien vers un article de presse, au bout duquel figure un ensemble de tags utm (Google), un tag fbclid (Facebook)… et de devoir le nettoyer manuellement pour ne pas renvoyer d’infos aux vilains qui vous pistent. ClearURLs fait ça pour vous, en plus d’autres fonctionnalités plus récentes mais tout aussi utiles.
Redirect AMP to HTML, qui fait ce que son nom indique. Autre plaie numérique, AMP (pour « Accelerated Mobile Pages ») est une technologie ouverte mais principalement poussée/utilisée par Google, notamment sur les sites de presse. Lorsque vous cliquez sur un lien depuis la recherche Google (ou qu’on vous partage un lien AMP), sous prétexte d’accélérer/alléger la navigation, vous ne tombez pas sur le site réel mais sur une copie hébergée directement par Google. Au top pour suivre ce qui est fait ! Cette extension réécrit donc l’adresse visitée pour que vous atterrissiez sur le site original, d’autant qu’AMP ne fait pas vraiment sens sur un navigateur de bureau.
Privacy Badger, publié par l’Electronic Frontier Foundation, qui bloque des pisteurs et cookies. Moins efficace que d’autres, il a aussi l’avantage d’occasionner moins de « faux-positifs », et peut donc être recommandé sans souci aux débutants.
Disconnect, qui bloque une bonne partie des nuisances également, peut faire partiellement doublon avec uBlock. Il a perdu un peu de son intérêt depuis que Firefox intègre la liste de Disconnect à sa propre protection contre le pistage.
Facebook Container, qui isole les pages liées à Facebook (donc Facebook, Messenger, Instagram…) du reste de votre navigation. Moins ils en savent, mieux vous vous porterez, et ils en savent déjà bien assez.
HTTPS Everywhere, qui force le passage en HTTPS lorsque c’est possible.
Consent-O-Matic, qui reconnaît bon nombre de "bandeaux cookies" et va le remplir à votre place pour tout refuser, vous épargnant des clics supplémentaires et la recherche d'éventuels boutons "Continuer sans accepter" bien planqués par tous les éditeurs qui ne savent (toujours) pas lire les règles de la CNIL.
I don't care about cookies, qui vire les bandeaux cookies. Théoriquement, rien n'est déposé dans le navigateur avant consentement explicite, donc ça ne devrait pas être dérangeant de juste masquer le bandeau. Théoriquement.
Bypass Paywalls Clean, qui comme son nom l'indique vous permet de naviguer sur les sites qui affichent un paywall. Mais si, vous en avez forcément vu un : on vous laisse la possibilité de refuser les cookies, mais il faut payer. La fourberie à son paroxysme, plutôt que d'interroger un business model basé sur le pillage et la revente de données à l'insu des internautes.
Vous trouverez ces extensions dans le "store" de votre navigateur.
A contrario, quelques extensions à éviter : Ghostery, AdBlock, AdBlock Plus… qui ont une fâcheuse tendance à ne pas être totalement libre, à appartenir à des sociétés dont le revenu est basé sur la revente de données personnelles, ou à avoir un mode de fonctionnement douteux basé notamment sur ce qui est « intrusif mais acceptable quand même ». Outre le fait que toi et moi, lecteur fidèle, n’avons potentiellement pas la même notion que les éditeurs de ces outils de ce qui est acceptable ou non eu égard à l’intimité numérique, le problème majeur réside dans le fait qu’un tiers décide à notre place. En très gros : une régie qui paie est une régie acceptable. Voilà.
Dans le même goût, on m'a suggéré Ninja Cookie en alternative à Consent-O-Matic. Il fonctionne sûrement très bien, mais n'est pas libre/open-source, pas totalement gratuit, et avec une politique de confidentialité et un EULA dans lesquels je ne me retrouve pas. Je ne peux donc pas le recommander.
De façon générale : privilégiez Firefox pour surfer, et n’hésitez surtout pas à activer sa fonction de blocage appelée « Protection renforcée contre le pistage ». Il n'est pas parfait, mais c'est le "moins pire" actuellement côté protection des données.
Sur un téléphone
Côté Android, il y a pas mal de façons de faire. La plupart nécessitent d’être administrateur (root) sur le système, ce qui n’est non seulement pas le cas de tout le monde, mais en plus pas recommandé au vu des risques que cela peut faire courir au terminal et aux données s’y trouvant. C’est un choix qui doit être fait avec toutes les cartes en main. D’autant qu’aujourd’hui on perd un temps phénoménal à essayer de masquer au système qu’on est administrateur, puisque devant ce risque, certaines applications refusent de fonctionner : banques en ligne, streaming vidéo, jeux…
L’autre solution, c’est de simuler un VPN, local, sur le téléphone. Dans ce VPN, on applique des filtres, comme le ferait uBlock dans un navigateur.
L’avantage à utiliser une solution « à l’échelle du système » plutôt qu’à celle du navigateur, c’est que les publicités et pisteurs seront également bloqués au sein de toutes les autres applications.
On peut donc citer Blokada, et AdGuard. Le dernier dispose de fonctionnalités payantes et n’est plus open-source, mais une version un peu plus ancienne reste disponible sur F-Droid, et on peut raisonnablement penser qu’à terme l’app sera libérée. Cela peut faire sens de l’utiliser surtout si ça permet d’unifier des interfaces entre personnes du foyer (un peu d’Android, un iOS par-là…).
Quoi qu’il en soit, ces deux applications ne se trouveront que par F-Droid, ou leurs sites officiels respectifs, pour la bonne et simple raison que Google, qui contrôle ce qui figure (ou non) sur son Play Store, voit d’un assez mauvais œil les bloqueurs de publicités, dont on rappelle qu’elle constitue la majorité de son revenu.
Les utilisateurs plus avancés trouveront probablement leur bonheur avec DNSFilter. Un guide très bien fait est mis à disposition par SebSauvage.
Côté iOS maintenant, même combat. AdGuard et Blokada sont dispo. Ici, AdGuard est également open-source (oui, c’est libre sur iPhone, non-libre sur Android, c’est rigolo).
Point d’attention super important pour iOS : tous deux fonctionnent vraiment différemment.
Blokada utilise un serveur tiers pour la résolution de nom (DNS), le mécanisme dont on a parlé dans l’épisode 2. Il agit en tant que DNS menteur pour bloquer les nuisances. Pour autant, de fait, Blokada connaît votre navigation, et tout est question de lui faire confiance ou non.
AdGuard peut utiliser le DNS (mais c’est payant). Sinon, il se limitera à fournir une fonctionnalité de blocage de contenu pour Safari. Les pubs en-dehors de Safari (in-app par exemple) ne seront pas bloquées.
Pour Android comme iOS, on peut citer dans le monde de la navigation Firefox Focus, qui ne conserve pas d’historique et bloque pas mal de choses par défaut, et (pour iOS) fournit également la fonction de blocage de nuisances pour Safari.
Il existe également des services comme NextDNS, qui permettent un filtrage à l’échelle de tout le téléphone. Cela semble prometteur, mais je n’ai personnellement pas testé NextDNS (pas encore du moins). D’autres en parlent mieux que moi, à commencer par Stanislas et PixelDeTracking.
A la maison, pour tout le monde
Il existe des solutions pour nettoyer un peu le trafic réseau à la maison, bloquer telle ou telle catégorie de pisteurs, voire bloquer certains services complets.
Vous l’aurez compris, le principal souci de cette solution, c’est qu’on est pas toujours à la maison (même si en ce moment… ;) ). Et donc, dès qu’on en sort (sauf à avoir un VPN qui connecte le téléphone à la maison, ou à écouter depuis l'extérieur), la protection saute.
Mais un des avantages, c’est que vous filtrez pour tout le monde. Y compris pour des appareils qui, sans ça, ne pourraient pas disposer de filtres, par exemple une clé Chromecast, une AppleTV (et il paraît qu’elles sont bien bavardes), ou une console de jeux. Et que vous pouvez ajouter des listes, voire appliquer différents réglages en fonction de l’appareil (bloquer Instagram pour les enfants, mais pas pour vous, par exemple).
Les 2 solutions les plus simples à utiliser sont Pi-Hole et AdGuard Home. Pour autant, elles ne sont pas encore à la portée de tout le monde, malheureusement… N’hésitez pas à demander un coup de main à votre entourage « geek » si ce sujet vous intéresse.
Pour ma part, j’ai testé les deux, et le prochain article portera sur ces essais. Stay tuned.
Du point de vue de la "culture" du pistage que j'essaie de développer ici, je ne peux que vous recommander TRÈS chaudement à regarder le reportage France 2 "Vos données personnelles valent de l'or", disponible en replay sur France.tv .
Note : cet article sera mis à jour (ir)régulièrement selon mes "découvertes" d'extensions, bonnes pratiques... j'indiquerai alors la date de dernière mise à jour :)
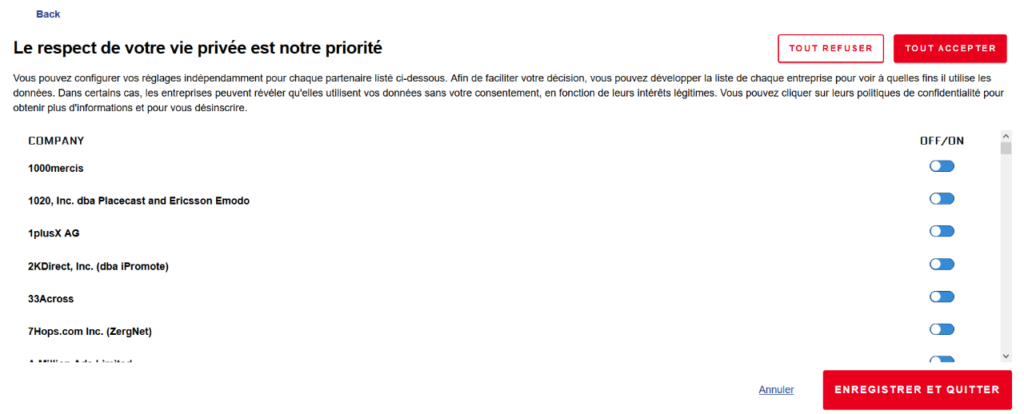
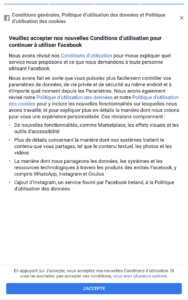
Depuis quelques semaines, les éditeurs de sites web (notamment la presse mais pas que) s'agitent pour prendre en compte la dernière version des recommandations de la CNIL relatives aux pisteurs en ligne, dont les fameux cookies. Ces recommandations viennent durcir une position qui ennuyait déjà fortement les publicitaires et n'était que partiellement appliquée la plupart du temps.
Au menu des changements, la CNIL insiste fortement sur une possibilité de refuser les cookies de façon aussi simple et claire que ne l'était déjà l'acceptation. En théorie, fini le "Tout accepter" en un clic et mis en avant, et le "Paramétrer vos choix" qui demande 15 clics et un massacre de molette de souris. On aurait dû voir apparaître un bouton "Tout refuser", quoi.
Sauf que la publicité en ligne, ça rapporte. C'est même tout le modèle économique de nombreux sites. Vous connaissez déjà l'avis de votre serviteur sur le sujet : "HELL". Pour moi, un modèle économique basé uniquement sur la publicité, c'est un mauvais modèle. Cela pouvait fonctionner avec la presse papier (notamment la presse quotidienne et régionale -PQR pour la suite), mais en ligne c'est plus compliqué, puisque (là encore, en théorie...) :
le visiteur peut refuser la publicité ciblée (et on retombe sur de la publicité classique, qui rapporte moins -on y revient ensuite) ;
le visiteur peut utiliser un bloqueur de publicités (et il ne rapporte plus rien), voire même un bloqueur comme AdNauseam qui en plus pourrit le profil qu'on pourrait dresser de lui.
De ce bref exposé découle un constat simple : les brouzoufs sont proportionnels au taux de consentement. Or le GESTE, qui regroupe beaucoup d'éditeurs et régies pub (de Deezer à Google en passant par M6 ou encore Mediapart, voir ici), ne voyait clairement pas d'un bon oeil les nouvelles recommandations de la CNIL et estimait que les taux de consentement, si les "bandeaux cookies" respectaient à la lettre les instructions du gendarme des données personnelles, risquaient de chuter des 95-98% de moyenne de l'époque sous la barre des 50%. Et c'était le scénario optimiste. D'où une "presque nécessité" de s'arranger avec le texte. Le GESTE meurt, mais ne se rend pas.
Après, GESTE ou pas, c'est la même musique, hein. Je cite le GESTE uniquement parce qu'il représente le secteur en France, pas parce qu'il ferait pire qu'un autre, ni parce que j'aurais une hypothétique dent contre lui.
Le Conseil d'Etat tacle la CNIL
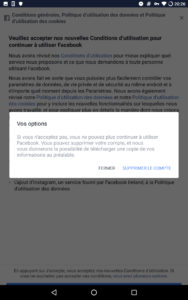
Saisie, l'instance a eu à se prononcer sur les "cookie walls", qui existaient déjà (mais étaient cependant très minoritaires) mais ont été perçus comme la meilleure façon de maintenir un revenu publicitaire "décent" en incitant à consentir au suivi de la navigation. Ben oui : le bandeau classique ne peut pas prendre moitié de l'écran, et cliquer sur un lien ou poursuivre sa navigation n'est pas une action positive valant consentement. Il faut donc l'obtenir, ce consentement ! Un message qui empêche de lire, c'est frustrant, on s'en débarrasse au plus vite...
Par le passé, on a usé et abusé du "si vous voulez refuser les cookies, paramétrez votre navigateur". Pour pas mal de raison (notamment le fait que le réglage n'est pas spécifique à un site : on peut légitimement vouloir refuser les publicités ciblées de JeuxVideo.com sans pour autant se faire jeter de sa banque en ligne parce qu'on rejette les cookies), cela fait aussi partie des dispositifs qu'on ne peut plus utiliser depuis la décision du Conseil d'Etat (toujours lui) dans l'affaire opposant la CNIL aux Editions Croque Futur.
Bref, le cookie wall, c'est la solution. Sauf que la CNIL (et d'autres autorités européennes), suivant l'avis du CEPD sur ce point, l'a explicitement interdit. Des dents ont grincé, le Conseil d'Etat a été saisi de la question, et il a estimé que la CNIL ne pouvait pas interdire systématiquement cette pratique : elle devra faire du cas par cas.
Et comme souvent, ce qui n'est pas explicitement interdit est considéré comme autorisé. Donc on se retrouve avec ça :
Le cookie wall de JeuxVideo.com, proposant d'accepter le suivi publicitaire, ou de payer.
Les exemples sont nombreux, j'en ai pris un au hasard, mais @PixelDeTracking en a fait une liste plus complète.
Est-ce légal ?
Réponse courte : oui et non.
Pour être valable, un consentement doit respecter 4 critères :
être libre : le visiteur doit avoir le choix, sans que ce choix ne soit contraint ou influencé ;
être éclairé : on doit savoir à quoi on consent ;
être univoque : le choix doit se manifester par une action "positive", voulue. Typiquement, scroller ne vaut pas consentement, tout comme cliquer sur un lien vers une autre page du site. Ces procédés, connus sous le nom de "soft consent", ne sont plus autorisés ;
être spécifique : on consent à un traitement, une finalité à la fois. Pas à un gros gloubi-boulga de traitements.
Dans le cas qui nous occupe, c'est globalement bon sur les aspects éclairé/univoque/spécifique. La question réside dans le caractère libre ou non du consentement face à un cookie wall vous demandant de payer ou d'accepter le suivi.
Et plutôt que de refaire le très bon travail fait par les copains, je vous invite à vous rendre chez Numendil, qui a abordé le sujet avec force détails tout en restant comme à son habitude clair et accessible. C'est par ici.
A la place, on va parler de ce qu'il se passe "derrière nos écrans" quand vous acceptez le suivi.
Les cookies analytics, cancer du Web
C'est principalement là que se trouve le nerf de la guerre, celle qui rapporte à l'éditeur (et à toute la chaîne derrière, que vous allez découvrir dans cette partie). A quoi servent donc ces cookies ?
A déterminer vos centres d'intérêts et comportements, votre localisation ;
A suivre votre parcours sur le site / l'application mobile que vous visitez ;
A mesurer la fréquentation de telle ou telle partie du site / de l'appli ;
A personnaliser les contenus des sites et applications mobiles ;
A suivre les campagnes de publicité, pour mesurer le nombre d'affichages d'une pub, le nombre de clics dessus et in fine les sommes dues à la régie.
En gros, à mieux vous connaître, pour "proposer du contenu adapté", souvent en liant vos identités "navigateur Web" et "smartphone".
Ces cookies sont très majoritairement déposés par des tiers, notamment par l'omniprésent Google Analytics, qui lie aussi votre profil sur le Site A avec ce que vous avez vu sur le Site B, puis l'appli C. On a donc une partie de vos centres d'intérêts et habitudes, mais pas seulement sur un site isolé : on parle bien de l'ensemble de votre navigation. Et je ne parle même pas des cookies liés aux réseaux sociaux...
Comment est "ciblée" la publicité ?
Dans mon métier, on parle plus souvent de "publicité programmatique" voire d' "achat programmatique". L'idée du processus, c'est de faciliter la mise en relation entre acheteur et vendeur. Il faut donc que ce soit rapide, automatisé, et précis. Donc plus on vous connaît, mieux c'est, et plus la probabilité que vous cliquiez sur une pub est grande.
Quand je dis "rapide", je ne plaisante pas. On appelle ça des enchères en temps réel, ou Real-Time Bidding (RTB).
Le RTB en un coup de crayon - Source : inconnue, mais le dessin est cool, si c'est le vôtre signalez-vous :)
Voilà comment ça se passe :
Vous arrivez sur une page Web
L'impression publicitaire (l'emplacement, de taille déterminée) est mis au enchères auprès des annonceurs
Les acheteurs intéressés par ce que vous représentez (profil, historique de navigation...) font une offre
Le meilleur enchérisseur remporte l'impression
La bannière publicitaire est affichée sur la page où vous êtes
Oh, et le tout se fait nécessairement dans une fenêtre de... 120 millisecondes max.
L'écosystème de la publicité est énorme
Avant d'arriver dans votre navigateur, la publicité peut transiter par une grande variété d'acteurs : des agences média et des "trading desks" (spécialistes de l'achat d'espaces publicitaires), des plate-formes d'échange (un genre de Tinder de la pub : on trouve des espaces en vente, et des acheteurs ; la plate-forme fait et facture la mise en relation)... et les bien trop défavorablement connus "courtiers en données personnelles" (data brokers).
Et ça en fait du monde, vous pensez ? Eh bien oui. C'est la jungle. La société LUMA a d'ailleurs travailler à cartographier cet écosystème :
Un tel écosystème est-il compatible avec le RGPD ? Pas certain. Les précédentes mises en demeure de la CNIL, notamment à l'encontre de Teemo, Fidzup, Singlespot ou Vectaury (des acteurs de cet écosystème) mettent à mal son modèle.
La société Brave Software, qui édite le navigateur Brave, a également saisi les autorités de protection des données personnelles irlandaise et britannique sur ces thématiques de RTB. La chronologie est dispo ici.
Et le partage social ?
Oh, tant qu'à faire long et flippant, hein. Prenons quelques minutes pour parler de ça aussi. Parce que si le RTB est un des cancers du Web, là on tape dans l'AVC.
Comme pour le RTB, à part les acteurs incontournables dont forcément Twitter et Facebook, il y a qui ? Eh bien... moitié de la planète :
Oui, ça picote hein ? Et encore, à l'époque on ne parlait pas des "nouveaux" RS comme TikTok ou autres ClubHouse.
Rappelons au passage le son de cloche côté CJUE : si vous ajoutez un lien actif avec un réseau social, vous êtes responsable conjoint de cette phase du traitement de données personnelles. Pas toujours simple à gérer/assumer.
Des centaines de tiers, donc ?
Vu l'écosystème, quand vous cliquez sur "tout accepter", avec qui partagez-vous des données ? Tout l'écosystème ? Une sous-partie ?
C'est là qu'arrive l'IAB (pour Interactive Advertising Bureau), une organisation internationale qui vise à structurer et normer le marché de la publicité (et uniquement de la publicité) en ligne. Parmi ses nombreux travaux, on retiendra :
le développement du TCF (pour Transparency and Consent Framework), en version 2 à ce jour ;
la "certification" des outils de recueil du consentement (CMP, pour Consent Management Platform) comme étant conformes au TCFv2. Le listing est public.
Disons que sans ça, l'éditeur va galérer à mort pour avoir un consentement qui fonctionne avec l'ensemble des régies partenaires. Là, au moins, on fait le truc une fois, proprement, et ça fonctionnera avec tous les partenaires sans se poser de questions. Charge à l'éditeur de sélectionner les siens et d'en constituer une liste (la "vendorslist").
L'avantage pour les annonceurs : un éditeur qui utilise le TCF, c'est la presque garantie d'un consentement valablement obtenu. Si l'éditeur fait trop n'importe quoi avec le recueil et ses modalités, l'IAB ferme le robinet, et le revenu publicitaire chute tout net. C'est arrivé à un client, et dans ces cas-là on débloque tout de suite.
Autre avantage pour l'éditeur, au-delà des "connecteurs" clé-en-main : l'information propre à chaque finalité, les textes descriptifs pour chaque tiers, les liens vers la politique de confidentialité... Tout est fourni. D'ailleurs, ne pas utiliser lesdits textes descriptifs est un motif de fermeture du robinet, là aussi. Testé et approuvé ;)
Le vrai souci, c'est que par flemme, inattention ou juste parce qu'ils y voient une possibilité de maximiser le revenu publicitaire, de nombreux éditeurs intègrent l'intégralité des vendors, et ça fait du monde ! Au moment de l'écriture, la liste comprend 720 entrées.
Un exemple au hasard d'éditeur qui a intégré toute la liste (regardez la taille de l'ascenseur...) :
En effet, belle priorité.
Alors certes, le consentement est valablement obtenu (ou presque : même si la CMP est théoriquement compatible avec le RGPD, on peut aussi la configurer pour ne pas le respecter, évidemment), mais on perd nettement en contrôle. J'ai déjà croisé des vendorslists avec tout pré-activé, et sans bouton "tout désactiver". Qui décocherait 720 tiers avant de naviguer ? Personne. Vraiment.
Note importante aux éditeurs, histoire que ce soit posé noir sur blanc (ou l'inverse selon vos paramètres) : ce n'est pas parce que vous utilisez une CMP "du commerce" conforme (ou pas) au TCFv2 que cela garantit la conformité au RGPD. C'est un élément essentiel pour atteindre une conformité satisfaisante, soit, mais ce n'est pas suffisant. Si vos choix de configuration sont en contradiction avec le RGPD, il ne faudra pas blâmer Didomi, Chandago ou autre OneTrust.
Le mot de la fin
Voilà, on en a terminé avec cette excursion derrière nos écrans, dans le monde finalement assez secret de l'adtech, que j'ai pu pratiquer tant côté éditeurs que côté autorité de contrôle. Vous comprenez (je l'espère) un peu mieux pourquoi se pose la question de trouver un compromis entre vie privée et revenu publicitaire. Les dernières recos de la CNIL (et au global, le RGPD et ePrivacy) sont venues chambouler une situation figée qui était au désavantage (clairement) de l'internaute. Chercher un revenu similaire à la PQR papier, mais sur Internet, c'est compliqué, et quand on a pas mieux on est prêt à toutes les cochonneries pour maintenir cette manne qui, effectivement, permet à certains titres d'exister.
Certains éditeurs m'ont confié il y a plusieurs mois chercher à pousser à la création de compte sur leurs sites, l'idée étant de se passer du consentement, en basculant la base légale de ces traitements sur la fourniture d'un contrat (vous auriez de fait accepté des CGU-CGV en créant un compte), que ce soit gratuit ou non. C'est ce qu'a fait France Télévisions, service public, qui conditionne le visionnage de ses chaînes en direct à la création d'un tel compte, et que je désapprouve.
Et c'est ce que font certains avec des cookie walls incitant à payer, en espérant que même après paiement, on ne soit pas pistés, ce qui est loin d'être garanti comme l'expérience nous l'a montré.
Rappelez-vous que c'est en partie vos choix qui font le monde, même numérique. Bonne navigation !
La dernière fois, nous avons parlé de pistage en ligne, de cookies, et du fait que tout un tas de tiers savent de façon plus ou moins détaillée ce que vous faites sur le net ou sur votre ordiphone. Aujourd’hui, on va parler de votre box Internet, de votre fournisseur d’accès (fixe ou mobile) et de ce dont il a potentiellement connaissance ou non.
Il y a quelques semaines, pour le travail (j’essaie de sensibiliser mes collaborateurs aux menaces et risques sur le net, pour faire simple), j’ai fait une petite expérience. J’ai ressorti un vieux Raspberry Pi (un nano-ordinateur, voir photo ci-dessous) d’un placard et j’y ai installé un programme spécifique : Pi-Hole, dont le but initial est de bloquer sur tout le réseau domestique les publicités en ligne et les pisteurs connus.
Le Raspberry Pi, au premier plan
Pour comprendre l’expérience, je vais (tenter de) vous expliquer une des bases du fonctionnement de l’Internet : comment on arrive à joindre un site. Bien évidemment, c’est pour rendre la chose compréhensible : que ceux qui en savent davantage me pardonnent les raccourcis et approximations.
Sur Internet, tout n’est qu’adresses IP (IP pour Internet Protocol, jusque-là rien d’illogique). C’est l’équivalent numérique de l’adresse postale. Et aussi sûr que retenir les adresses de tout le monde est délicat, retenir toutes les adresses IP correspondant aux serveurs qui hébergent les sites que l’on visite, c’est impossible (pour moi, du moins ! 🙂 ).
Donc, comme pour la « vraie vie », on a créé un annuaire : le DNS, pour Domain Name System. En gros, quand vous cherchez à joindre https://open-freax.fr , votre navigateur interroge l’un des annuaires qu’il connaît et demande quelle adresse IP correspond au domaine (ici, open-freax.fr) que l’on demande. C’est totalement transparent pour nous.
A la maison, c’est votre box ADSL/fibre qui sert de DNS, et elle-même interroge les annuaires du fournisseur. Et pour diverses raisons (de fiabilité et de simplicité notamment), il est impossible (au moins chez Orange et Bouygues pour ce que j’ai vu récemment) de changer ce comportement au niveau de la box.
Pi-Hole inclue un serveur DNS, et c’est par ce biais qu’il « filtre » la publicité : si une page Web que vous visitez cherche à joindre un domaine connu pour servir des publicités, il répond à votre navigateur que ce site (qui est dans sa liste noire) n’existe pas. C’est faux, évidemment : c’est ce qu’on appelle un « DNS menteur », et c’est en soi une atteinte au principe de neutralité du net. Ici, c’est pour une bonne raison. Les DNS des fournisseurs français sont également menteurs : c’est par ce mécanisme que lorsque la justice demande le blocage d’un site Web, les opérateurs répondent en pratique. Et que des sites connus pour héberger des virus sont bloqués, pour ne citer qu’un cas.
Donc, par un peu de technique et un soupçon de magie (en résumé : les box opérateurs sont très lentes et je me suis débrouillé pour que mon système réponde plus rapidement que celui de la box), j’utilise mon propre annuaire, et cela me permet de voir ce que mon fournisseur sait (ou peut savoir, du moins) de ma navigation. Alors, on y trouve quoi ?
Allez, on commence simplement. Ici, on observe l’activité sur mon réseau, cela correspond au nombre de requêtes DNS faites par heure. On observe donc très simplement qu’il y a 2 week-ends où j’ai été absent, donc un sans aucune activité (en fait, pour cause d’orages, j’avais coupé le courant avant de partir).
On devine également à partir du 8 juin la reprise du travail sur site chez mon employeur : l’activité est bien moindre en semaine comparé à la précédente.
Augmentons un peu le niveau de détail.
Ici, on observe très nettement que personne n’était chez moi (c’était un dimanche) et que quelqu’un (on ne sait pas qui) est revenu peu après 20 heures. Chaque couleur correspond ici à un périphérique : un ordinateur, un smartphone…). Avant 9h le lendemain, l’activité se renforce et quelqu’un s’est mis au travail. Au travail, c’est sûr ?
Creusons. La box assigne également à chaque périphérique une adresse IP interne, pour son propre usage et surtout pour arriver à fournir la bonne page au bon appareil qui l’a demandée. A ce moment, le périphérique lui communique également son petit nom, puisqu’une entrée d’annuaire c’est un couple « adresse IP / nom commun ».
Logiquement, pour la box, ce n’est pas juste « quelqu’un s’est connecté » mais « tel appareil s’est connecté ».
Et si on descend au niveau le plus détaillé, on a les demandes faites par chaque appareil.
Ici, on constate que mon ordinateur de travail est sous Windows (requêtes vers Microsoft, dont une bloquée car elle correspond aux « sondes » que Microsoft a placées dans son système et contre lesquelles plusieurs CNIL européennes bataillent) et quelle solution antivirus est installée sur nos postes (masqué ici, tout de même).
On pourrait aussi, en écoutant plus longtemps, connaître tout mon historique de navigation (donc mes centres d’intérêt), et savoir quels services sont utilisés par le foyer. Lorsque je regarde le détail de mes propres requêtes, on y trouve des demandes en lien avec Netflix (j’utilise donc le service, quand bien même je ne me suis pas abonné via mon opérateur), Spotify et Bose (j’ai effectivement une enceinte –sans assistant vocal, faut pas déconner, déformation professionnelle oblige– dans le salon), et plus encore.
Et surtout, on peut supposer assez simplement (à tort ou à raison) que si « iphonedeXXX » n’est pas connecté alors son propriétaire est absent, ou que si « ertYYY » est allumé ET que des requêtes sont faites vers les serveurs Xbox Live à 15h30 alors c’est que ça ne bosse pas dur…
Et de façon plus pragmatique pour la publicité ciblée, que si je visite des sites de vendeurs de voitures et de comparateurs de crédits, il est tout à fait pertinent de me montrer des publicités en lien. Du moins et d’une certaine façon, probablement plus pertinent que des publicités pour de la nourriture pour chien (je n’en ai pas) ou pour des fauteuils Stannah.
Voilà, j’espère que cette petite expérience vous aura permis de mieux comprendre le fonctionnement de votre box domestique. Pour ma part, cela m’aura permis de voir que même la nuit, certaines applications de smartphone sont très bavardes ! Finalement, mon Linky n’en sait pas autant alors qu’il est très critiqué 😀
Petite précision pour celles et ceux qui utiliseraient un VPN commercial quelconque : en l’utilisant, vous « déplacez » cette connaissance de votre activité en ligne (et même plus, mais ça devient technique et ce n’est pas l’objet de cet article) vers l’opérateur VPN. Posez-vous la question malgré tout : est-il au moins aussi digne de confiance qu’un opérateur régi par les lois nationales ?
Enfin, gardez en tête que ces données que nous émettons, nous y sommes en partie contraints par la conception-même du réseau Internet : cela n’a rien d’anormal et chercher à « anonymiser » totalement sa navigation ne se fera qu’au prix de drastiques baisses de performance, de configurations maison souvent bancales (j’ai moi-même crashé 2 fois mon Pi-Hole avant de comprendre pourquoi ma box lui envoyait des millions de requêtes par minute) et par rebond plus risquées, et du renoncement à certaines technologies (notamment le décodeur TV, qui repose sur les DNS de l’opérateur) ou à certains services.
En bref, pas de crainte particulière à avoir, simplement lorsque votre décodeur TV vous demandera si vous acceptez la publicité ciblée, vous saurez précisément évaluer la balance « service / intimité numérique » 😉
Petite précision tout de même : l’idée derrière cet article n’est absolument pas de vous précipiter dans les bras d’un opérateur VPN au hasard, de forcer du DNS sécurisé partout (et de tout refiler à Cloudflare ou autre), mais simplement d’avoir en tête « qui sait quoi ». Cela pourrait vous éviter de mauvaises surprises, qui sait.
L’épisode 3 parlera de quelques moyens de limiter ces fuites de données. On fera le tour d’extensions Firefox/Chrome sympa, des moyens de se protéger un peu sur smartphone, et sûrement plein d’autres choses. D’ici là, prenez soin de vous !
Il n’aura sans doute pas échappé au lecteur (même distrait) que votre serviteur œuvre dans l’ombre pour contribuer à protéger les données (souvent personnelles, mais pas que) d’entreprises et d’individus, comme RSSI et/ou DPO. J’en vis depuis 2014, et j’y contribue bénévolement depuis 2006. Et quand bien même j’aime ce que je fais, quand bien même je pense que c’est indispensable, ce n’est pas simple, ni rose, tous les jours. Je vais tenter de vous expliquer pourquoi. C’est donc un billet très personnel et subjectif, mais qui devrait refléter assez fidèlement mon regard actuel sur mon métier et le sens qu’il porte, ou devrait porter.
Et aussi sûr qu’un article de blog n’est pas le moyen le plus adapté pour échanger, je reste disponible par courriel (passez par le formulaire de contact 🙂 ), Riot Element (@maxauvy:matrix.drycat.fr), ou éventuellement le compte Twitter de ce blog (@openfreax). Oh, et je suis régulièrement de passage sur #fediverse de Geeknode. Au pire, invoquez-moi.
Je pense que ça résume bien la vision du RSSI / DPO de la part du quidam. J’y ai mis des guillemets car c’est une citation : c’est ce que j’entends souvent aux réunions de famille, à la maison, et parfois même au travail.
Et parfois, je ne sais pas répondre. Parce que toutes mes tâches du quotidien, elles sont invisibles au sein de l’entreprise, et absolument pas ancrées dans la réalité de M. Tout-le-monde. Parce que la « culture cybersécurité » est loin d’être répandue, et qu’on ose rien demander de peur d’un refus ou de conditions. Parce que quand on sait qu’il existe, le RSSI / DPO est un frein, un empêcheur de tourner en rond.
Et quand je pourrais répondre, je n’ose pas. Parce que le métier a changé. Parce que le cadre dans lequel il s’exerce a changé. Parce que j’ai aussi des valeurs et des convictions sur lesquelles je ne transigerai pas et qui font qu’aujourd’hui, je patauge en pleine dissonance cognitive. Parce que depuis que je suis passé du côté organisationnel de la Force, non seulement je n’ai pas plus le sentiment de faire quelque chose d’utile, de tangible/mesurable et de reconnu, mais je perds même le lien avec « la technique ». Mon quotidien depuis 2-3 ans, c’est Word, PowerPoint et Outlook. Et vaguement Excel pour les grands jours, ceux où je suis au max du fun et fais des macros. Ah, et des réunions en visio. Mais pas sur Zoom, faut pas déconner quand même.
True story, bro.
Sensibiliser n’est pas une réponse suffisante
C’est une condition nécessaire, certes, mais pas suffisante. Je vois au moins 3 étapes essentielles : sensibiliser (expliquer simplement les risques et menaces), proposer des solutions (qui soient utilisables et adaptées : forcer un KeePass moche et en anglais, sans ateliers de découverte et sans extension pour le navigateur, c’est le meilleur moyen de braquer l’utilisateur, surtout quand on a un KeePassXC ou un Buttercup en face), et abolir la frontière pro/perso dans l’hygiène numérique.
Pour ce dernier point, je vais préciser un petit peu. Le confinement et le télétravail forcé qu’il a induit ont mis en exergue un comportement connu mais négligé : les gens ne sont pas des machines qui segmentent à 100% les activités professionnelles et personnelles. L’ordinateur professionnel sert aussi à des tâches personnelles à la maison (car souvent plus rapide que le PC familial, et déjà allumé), et au travail on fait tous un « drive » de temps en temps, ou un tour sur un réseau social, bref un truc où on connecte un compte pas contrôlé par l’entreprise.
Et puisqu’on mélange le tout, qu’on connecte son téléphone pro au Wi-Fi de la maison, qu’on ouvre des documents perso au travail, il faut arrêter le discours « au travail c’est comme ça, à la maison démerdez-vous ». C’est aussi stupide que de justifier d’écrire comme un demeuré sur un forum parce que « On ER pAs A LekOl ». Ce n’est pas la comparaison la plus heureuse mais vous saisissez l’idée générale.
On doit donner des règles d’hygiène numérique communes. Sinon, on ne fait qu’augmenter l’écart entre les deux : plus c’est contraint au boulot, plus il y aura de relâchement à la maison. Mais est-ce à l’entreprise de donner ces connaissances ? Ne devrait-on pas le faire plus tôt, à l’école ?
Par ailleurs, pour insister sur l’aspect indispensable de la sensibilisation, on sait tous qu’imposer sans expliquer, c’est foncer tête baissée dans le mur. On entend régulièrement que l’opposition à telle ou telle loi/réforme c’est dû au manque d’explication, parce que si les gens comprenaient, ils approuveraient. Ben en cybersécurité c’est pareil. (Et le résultat final est à peu près le même, notez : tout le monde s’en cogne toujours autant)
Ce qu’il manque, aussi, c’est de l’engagement.Après 20 ans à dire que c’est l’utilisateur le problème et qu’il ne comprend rien, on commence à essayer de le responsabiliser, ou plutôt de lui faire comprendre qu’il a un rôle important à jouer, qu’il est acteur de tout ça et pas juste un boulet ou un maillon faible. Je suis à titre personnel très peu fan de « la sécurité malgré lui », où l’essentiel des choses se ferait dans le dos de l’utilisateur. Le faux sentiment de sécurité que cela peut donner est contre-productif. Et comme il ne ferait pas la distinction entre un environnement sécurisé et un qui ne le serait pas, le comportement ne changerait pas entre l’un et l’autre. D’où soucis. L’éducation et l’implication sont essentielles, et ces missions sont nobles.
D’ailleurs, les sessions de sensibilisation/formation, les ateliers, campagnes de phishing… et les cours que je donne sont sans nul doute les activités que je préfère. Viennent ensuite les audits et conseils aux TPE-PME, parce que ça s’en approche beaucoup, et que je crois qu’elles méritent d’être accompagnées par des passionnés plutôt que par une ESN (qui voudra aller vite parce que bon, le potentiel de renouvellement est pas foufou et plus vite on ira, plus on margera sur le forfait).
« Mais pourquoi tu parles de blues…
…si tu es convaincu que ce que tu fais est nécessaire ? »
Pour pas mal de raisons. Déjà, parce que si je fais ce métier, c’est par passion et pour un ensemble de convictions et valeurs qui me sont chères. J’ai exploré les différents volets de mon métier en cherchant celui qui me permettrait de concilier le tout, et je ne l’ai je crois pas encore trouvé.
Je suis intimement persuadé que « les gens » doivent récupérer du contrôle sur leur intimité numérique, de l’indépendance vis-à-vis des sociétés auxquelles ils confient leurs données, du respect aussi, et du choix. Vous allez me dire, le RGPD, c’est pile ça, en somme. Sauf que non.
Le RGPD (ou la loi Informatique et Libertés, c’est la même chose), c’est récent, c’est perçu comme une contrainte, on ne le fait pas par choix mais par peur de l’amende. Conséquence principale : il n’est appliqué que partiellement, et surtout, surtout, son but originel qui était de se poser des questions qu’on aurait déjà dû se poser est totalement dévoyé. Exit les « est-ce que j’ai vraiment besoin du numéro de sécu ? », « est-ce que garder ces infos 10 ans est pertinent alors que 2 ans suffiraient ». Aujourd’hui, dans la très grande majorité des entreprises que j’ai pu visiter, cette loi est perçu comme une épine dans le pied (donc on s’en affranchit assez largement), ou alors on l’intègre (et on nomme même un DPO) mais on cherche davantage à donner un cadre aux crasses qu’on faisait avant pour pouvoir continuer à les faire.
A gauche, la Direction, le Métier… et à droite, le RSSI.
On a voulu responsabiliser les entreprises, c’est un lamentable échec. Moi-même, je sais que l’entreprise au sein de laquelle je travaille ne sera jamais conforme à 100%, qu’il y aura toujours à redire, et que je découvrirai toujours des manquements cachés sous un tapis. Ce n’est pas un problème en soi, c’est juste que le régulateur aurait dû faire autrement, et plus tôt.
Tant que toute la chaîne ne disposera pas de cette culture « intimité numérique et sécurité », on lutte contre le vent. Et j’y inclus une dimension morale/éthique. Quand je vois le business model de certaines entreprises, ou de startups que j’ai eu l’occasion de conseiller, je me pose sérieusement la question : suis-je le seul à ne pas trouver ça moral vis-à-vis de l’utilisateur ? Suivi du comportement, publicité ciblée, géolocalisation, remontées d’infos personnelles, des contacts, et j’en passe. Personne ne voit le souci ? Est-ce que parce que ça n’a pas encore été fait, alors c’est une bonne idée de le faire (et de le monétiser) ?
Bref.
Il reste quand même un petit socle sur lequel m’appuyer, je crois.
Je crois…
Plus j’échange avec mes congénères sur mon métier et les convictions qui le sous-tendent, plus je me rends compte que les retours font mal.En fait, si on a responsabilisé les entreprises, c’est peut-être aussi, un peu, parce que le quidam s’en cogne royalement. Quand on lui laisse le choix, quand il a la possibilité de se protéger avec un investissement de temps et d’énergie proche du néant, il refuse.
Le bandeau cookies, qui permet normalement de refuser une forme de pistage en ligne ? « C’est pénible, je clique sur oui, il est gênant ce bandeau il prend de la place, t’as pas une extension Firefox pour le masquer ? »
Les mots de passe ? Stockés dans une note sur son iPhone, dans un carnet papier, parfois enregistrés dans Firefox, et dans 80% des cas « ah j’avais un mot de passe pour ça ? Mais c’est quoi ? Ah bah oui le même que partout ». Les 20% restants, c’est 18% de « je le réinitialise à chaque fois que je dois me connecter » et 2% de « j’y ai pas accès parce que c’est partagé avec Maxime et il veut pas me l’envoyer par mail, il veut que j’utilise un gestionnaire de mots de passe et je veux pas, quel pénible. »
Les applis sur smartphone ? « Si c’est sur le store, c’est que c’est OK ». Parler de F-Droid, ou d’Exodus, c’est déjà trop, alors que ça n’engage à rien. Une appli pour scanner un document via l’appareil photo du téléphone ? Oui c’est pratique, mais c’est souvent pour scanner des documents confidentiels. Pour ma part, si je ne dois prendre que mes 3 derniers scans, c’est un lot de factures acquittées pour des examens médicaux, un bulletin de salaire, et un acte de décès. Que des choses que j’aime autant garder pour moi. Croyez-le ou pas, même pour des amis avec une culture plutôt développée sur ces aspects, une fois sortis du contexte boulot, c’est la foire à la saucisse, et hop on installe une application de « scan » truffée de pisteurs qui remontent on ne sait pas trop quoi à des tiers.
Sans parler des services utilisés. De Dropbox à Facebook en passant par TikTok ou WhatsApp. J’ai beau proposer des alternatives tout aussi utilisables et simples, on n’en veut pas. Prenons Signal, la messagerie sécurisée, que je propose comme alternative à WhatsApp. Ben ça ne va pas. Parce que dans la balance « habitudes vs. intimité numérique », pouvoir changer un fond d’écran de conversation pèse plus lourd que ce que Signal apporte en termes de confidentialité des échanges.
Même des copains pro-libre et qui ont lutté avec moi contre les GAFAM pendant longtemps ont baissé les bras et abandonné Linux au profit de Windows (pour jouer initialement, puis pour tout parce que c’est pénible de redémarrer), abandonné le chiffrement des courriels parce que trop contraignant, abandonné IRC au profit de Discord, refusent « tes trucs chiffrés de hippie » comme Matrix/Element, résumé à « IRC avec une interface en NodeJS de merde » (même si on peut difficilement nier le tout dernier point). Et ce n’est pas le Fédiverse (Mastodon, tout ça) et son extrême toxicité qui risque de réconcilier M. Michu avec les réseaux « hors gros silos de données ».
En très très résumé : on ne sait ou ne voit pas ce que je fais, et quand on en est conscient, on l’ignore sciemment parce que ça demande un peu d’investissement personnel. Mais il paraît que les Français sont de plus en plus conscients des problématiques liées à la vie privée en ligne. Vous croyez ça, vous, dans un pays sur-équipé en smartphones disposant de « OK Google » et Siri, en Amazon Alexa et en Google Home ?
Navigation sur Internet, allégorie.
Mais côté boulot ?
Côté boulot, j’ai fait le choix de tester un peu tous les aspects du métier, en me disant que je pourrais ensuite rester sur la formule qui me convient le mieux. Spoiler : je ne crois pas avoir trouvé.
La CNIL, c’était franchement top, mais fatigant, à Paris uniquement (même pas de référents en région comme l’ANSSI), et très limité pour un profil « informaticien ». Comprendre par là que les postes de direction sont réservés aux juristes. L’institution a du mal à évoluer aussi vite que les usages, notamment sur les contrôles. Contrôles qui font assez rapidement tout voir en noir et donnent réellement l’impression que la protection des données est un truc totalement accessoire. Je ne parle même pas du contrôle du blocage administratif (contenu terroriste mais pas seulement). Il y aurait eu de quoi faire « en régions », je serais resté, mais cela a été jugé non rentable.
Les ESN. J’ai rapidement compris pourquoi on en parlait comme des « marchands de barbaque ». Grosse ou petite, en régie ou pas, spécialisée ou non, c’est du pareil au même. Et c’est pas un babyfoot, une salle de sieste ou un label « chouette endroit où travailler » qui y changera quoi que ce soit. Tout ce qui compte c’est d’être rentable, quitte à tirer dans les pattes, placarder, mentir au consultant. J’ai parfois été facturé à plus de 900€/jour, ce qui m’a mis assez mal à l’aise (et pas seulement parce que je n’en voyais même pas le tiers sur ma fiche de paie).
Le conseil. Je le distingue des ESN parce que le fonctionnement n’est pas tout à fait le même. Quoiqu’un peu plus propice à l’épanouissement (fonction du manager évidemment), la rentabilité reste le maître mot. C’est globalement là que mon intitulé de poste aurait pu devenir « expert Microsoft Office », vu qu’on n’y fait globalement que ça sur des missions qu’on ne choisit pas souvent.
RSSI / DPO interne. C’est assurément le plus confortable, à condition que l’entreprise elle-même choisisse d’aller dans le bon sens et s’en donne les moyens. Cela implique un peu plus que recruter quelqu’un et en déléguer la responsabilité au DSI parce qu’on « comprend rien à ces sujets ». Selon l’entreprise et sa culture, on peut se retrouver très très isolé à ce type de poste.
En indépendant. Du point de vue de l’activité et des valeurs, c’est là que je me suis le plus épanoui. J’ai toujours une petite activité en indep’, d’ailleurs. Cela me permet de donner des cours (j’adore) ou d’intervenir dans de petites structures à un coût franchement raisonnable, par choix de ma part : c’est aussi ça qui compte pour moi, rendre ce genre de prestations et d’audits accessibles à un laboratoire de biologie médicale par exemple, ou à un journal local, à un lycée… une approche plus personnalisée, plus « circuit court », et une organisation que je choisis. Le but c’est d’en vivre correctement, pas de changer de bagnole tous les ans, et pour ça j’ai pas besoin de 20 000€/mois (ce que j’étais facturé à un client fut un temps). Et franchement, mes meilleurs souvenirs sont effectivement dans la santé, l’éducation ou la presse. Ah, et aussi les experts-comptables et les avocats.
Mais aujourd’hui, j’en suis là. A me demander si la cause n’est pas perdue. Si aborder la sécurité et l’hygiène numérique côté entreprise est utile. Si impliquer l’utilisateur lambda est possible. A me dire que « la conformité de ma boîte » comme but ultime, ça ne porte pas de sens. Qu’on soit clair, ce que j’attends c’est pas des « merci c’est cool », mais plutôt des « ah je savais pas », « tu m’as appris un truc », « je vais changer telle habitude maintenant », qui sont non seulement plus gratifiants mais qui permettent de mieux percevoir l’impact que mon travail peut avoir. C’est ça qui me manque, observer un effet de mon boulot sur le quotidien d’humains. Pas un % d’avancement dans un tableur.Remettre de l’humain dans un milieu trop spécialisé, et pour lequel la seule ouverture semble être le bullshit commercialo-corporate sur LinkedIn(mais si, vous savez, le TikTok du lectorat des Echos).
Des fois que vous manquiez d’inspiration.
Enfin voilà : à quoi bon faire tout ça par choix et conviction, si personne n’en veut ? Mais si, ce fameux « j’ai rien à cacher »… Avouez que ça complète bien mon éternel syndrome de l’imposteur.
Ne serais-je pas mieux ailleurs ? En indépendant ? Ou carrément dans un autre secteur d’activité ? On rigole souvent à dire qu’on va aller élever 3 chèvres dans le Larzac, mais finalement, est-ce une si mauvaise idée ? Moi, je me pose la question.
Aujourd’hui commence une (courte ?) série d’articles concernant le pistage en ligne, la publicité, les cookies… L’objectif est double : permettre à « M./Mme Tout-le-monde » de découvrir cet écosystème, et (mais plus tard) de se doter d’un premier kit d’outils pour limiter ce suivi. C’est parti pour le premier volet.
Pourquoi ce sujet, pourquoi maintenant ?
Pas compliqué : le confinement qui se « termine » aura vu le télétravail exploser, mélangeant souvent les usages pro et perso sur une même machine. Avec aussi plus de temps à la maison, plus de navigation personnelle souvent sur smartphone, plus d’utilisation d’applications, du média social au site d’information en passant par le streaming vidéo et la visioconférence.
Certain(e)s ont donc remarqué que de façon surprenante (non) les recommandations publicitaires apparaissant sur smartphone ou dans un navigateur s’étaient affinées, et se posent la question du pourquoi. On va tenter d’y répondre, sans rentrer dans une idéologie qui pourrait effrayer, sans présumer d’un niveau de connaissance élevé du lecteur qui s’en trouverait largué dès les premières lignes, comme c’est trop souvent le cas sur ces sujets. Allons-y.
Parce qu’on « essaime » des données même sans le savoir
Lorsqu’on utilise un service en ligne quel qu’il soit, on émet plus ou moins volontairement des données, personnelles ou non, qu’on peut classer dans 3 grandes familles :
Celles qui sont nécessaires à l’utilisation du service : si je m’inscris à Twitter, je dois fournir une adresse mail valide, par exemple. C’est un pré-requis et sans ça je ne peux pas l’utiliser. De la même façon, si je veux créer un compte Améli (Sécurité Sociale), je dois lier le compte à mon numéro de sécu.
Celles que le service collecte pour ses propres usages, quels qu’ils soient. GMail « lit » vos courriels pour mieux cibler la publicité, Facebook analyse votre activité pour proposer du contenu allant dans le sens de vos centres d’intérêt et convictions, ce blog compte grossièrement le nombre de visiteurs. Utile ou non, la collecte a lieu, et vous n’êtes pas toujours au courant.
Celles que le service collecte pour d’autres, très souvent sans vous prévenir formellement : un jeu sur smartphone qui analyse vos usages pour alimenter votre profil chez une régie publicitaire, votre application bancaire aussi, VeePee ou Showroom qui font la même…
Ces données en révèlent pourtant beaucoup sur votre comportement, sur vos orientations (politique, sexuelles, religieuses…) ou sur votre santé. De façon très générale, sur vos habitudes quotidiennes.
Historiquement (j’emploie ce terme non pas pour dire que la pratique n’existe plus, mais parce qu’elle a évolué tout en restant la première et principale mise en œuvre), le meilleur moyen « connecté » d’avoir ce genre d’informations, c’était via votre navigateur internet (Internet Explorer, Safari, Chrome, Firefox…) et le mécanisme des cookies. Vous savez, ce petit fichier déposé sur votre ordinateur par presque tous les sites visités, et grâce auxquels depuis 2013 on a un bandeau plus ou moins pénible un peu partout qu’on s’empresse d’accepter,sans lire le pourquoi du comment… Bandeau qui, en théorie du moins, « retient » les cookies superflus dans l’attente d’un choix de votre part. Un bandeau utile, donc.
Un cookie, c’est un petit fichier texte. Il ne contient pas grand-chose, souvent simplement un identifiant. Si ce cookie est déposé par, mettons, Ouest-France pour son propre site, il n’y a pas réellement de problème : c’est probablement pour gérer votre compte en ligne, ou proposer des contenus plus adaptés, même si on peut légitimement vouloir refuser cela.
Ici, les cookies déposés en arrivant sur YouTube. A gauche, leur nom, à droite, ce qu’ils contiennent.
Par contre, un site qui intégrerait des boutons de partage/like tiers dans un article, permettrait à ce tiers de déposer un cookie lié à votre « vrai » compte, si vous vous êtes connecté ne serait-ce qu’une fois dans votre navigateur. Et donc de vous « suivre » sur chaque site autorisant le cookie en question. C’est notamment le cas de Facebook.
Le fonctionnement est le même pour les régies de publicité : c’est pour cela que si vous cherchez des chaussures sympa sur Sarenza, 10min plus tard sur Doctissimo il y aura un encart avec le même type de chaussures. On y reviendra dans un article dédié.
Cette pratique, intrusive, tend à évoluer : d’une part parce que les grosses régies et annonceurs se sont regroupés (et sont en mesure d’imposer leurs choix à de nombreux sites dépendant du revenu publicitaire pour vivre), et d’autre part parce qu’en réponse, des navigateurs comme Firefox ou Brave ont intégré un bloqueur de publicités et de pisteurs (dont les cookies de tiers).
Les réglages de Firefox. Le navigateur permet de bloquer les pisteurs, dont les cookies.
Alors, comment remplacer ces cookies, tout en évitant que l’utilisateur ou un tiers ne vienne les bloquer ?
En passant par nos smartphones, pardi !
Bon, en vrai c’est pas si simple, et il y a plein de façons de suivre un internaute sans cookies. Sauf que de plus en plus, on accède au contenu via une application mobile plutôt que par un site « classique ». Les régies ont logiquement suivi la masse et ont infiltré les applications de façon bien plus intrusive, et c’est pour ça qu’on va en parler.
Et finalement, en installant une application comme Doctolib ou Clash of Clans, que savons-nous réellement du fonctionnement de l’application ? Pas grand-chose. Que fait-elle de façon « invisible », peut-être même en arrière-plan ou pendant votre sommeil ?
C’est la question que s’est posée l’association Exodus-Privacy en 2017. Elle a développé un outil d’analyse des applications Android, qui s’appelle εxodus et qui a vocation à permettre à « M. et Mme Tout-le-monde » de comprendre en un coup d’œil ce que fait probablement telle ou telle appli et éventuellement d’exercer les droits que confère le RGPD (ou de vérifier que celui-ci est respecté, à savoir que ces pisteurs ne sont pas activés de base).
Un pisteur, c’est quoi ? La réponse en 3 minutes sur cette vidéo :
Prenons quelques applications au hasard parmi celles « du quotidien » :
20 minutes (presse) : 16 pisteurs
TikTok (média social, très utilisé des enfants et ados) : 7 pisteurs
Clash Royale (jeu en ligne) : 12 pisteurs
Discord (messagerie instantanée, utilisé durant le confinement par certains établissements scolaires malgré une interdiction émise par le Ministère et différents rectorats) : 5 pisteurs
Pinterest (média social) : 10 pisteurs
Boursorama Banque (banque) : 5 pisteurs
Fitbit (fitness/santé) : 12 pisteurs
Dès lors, si un pisteur est commun à toutes ces applications, le tiers (l’annonceur, la régie…) peut faire directement le lien entre un compte Pinterest et un compte Facebook par exemple, permettant à Facebook d’afficher de la publicité en lien avec ce que vous avez recherché sur Pinterest alors que ces 2 applis ne communiquent normalement pas entre elles. En cause : l’identifiant publicitaire unique du téléphone, notamment.
L’intérêt pour l’éditeur (la « marque » qui produit l’appli, Fitbit sur la capture ci-dessus) n’est pas forcément d’afficher de la publicité (même si ça rapporte) mais aussi et surtout d’enrichir le profil vous concernant auprès de la régie pub, qui paie pour ça. Mieux une publicité est ciblée, plus la probabilité que vous alliez jusqu’à un achat est grande.
Privilégiez donc les applications sans pisteurs, si possible. Si non, passez de préférence par le site web « classique », idéalement avec une extension comme uBlock Origin ou AdNauseam pour bloquer publicité et pisteurs. Évitez également AdBlock Plus, connu pour ne pas filtrer les régies publicitaires qui lui donnent de l’argent. On reviendra sur les outils plus tard dans la série.
Pour les utilisateurs d’Android à la maison, vous pouvez regarder du côté de F-Droid, un « store » d’applications gratuites, libres, et sans aucun pisteur.
A bientôt pour la suite ! Spoiler : ce sera sur ce que votre fournisseur d’accès à Internet sait de votre navigation (peut-être pour cibler la publicité dont je parle juste au-dessus, allez savoir). Spoiler bis : si vous voyez le Linky comme une atteinte grave à votre vie privée, commencez par résilier votre accès à Internet.
Hop, à la corbeille le brouillon sur NIS commencé il y a quelques mois. Finalement, à l’époque, ça se résumait en « les ESN et sociétés de conseil veulent taper dedans » et « tout le monde cherche dans quelle case se ranger pour ne pas être concerné par NIS ». Je change mon fusil d’épaule et on va juste parler de ce qu’est NIS (et gare au premier qui me sort à nouveau du Brice ou de la salade… 😀 ).
NIS (pour Network and Information Security), c’est une directive européenne qui traite de… cybersécurité. (Vous vous attendiez à quoi, ici ?). Voyons d’où elle sort, pourquoi elle existe…
NIS est donc une directive, pour commencer à poser les bases. C’est-à-dire (rappel de ce que je disais concernant le RGPD) qu’elle nécessite une transposition dans le droit des différents États membres pour être applicable, contrairement au règlement. Une partie est également publiée sous forme de règlement. Le délai pour cette transposition nous menait gentiment à mai 2018.
Aujourd’hui, elle s’applique donc de plein droit, car transposée en France (Loi n°2018-133 du 26 février 2018, à laquelle on ajoute pour faire bonne mesure trois arrêtés et un décret).
Pourquoi une directive de ce genre ?
Comme bien d’autres thématiques, la prise en compte de la cybersécurité varie d’un pays à l’autre, et d’une entreprise à l’autre.
Certaines organisations sont plus vitales que d’autres pour le fonctionnement d’un État. Elles doivent donc être mieux protégées, car souvent plus exposées à des risques et menaces cyber.
NIS a pour objectif de contribuer à cette protection, en définissant deux types d’organisations concernées et en y appliquant un socle commun (et élevé) concernant la sécurité des réseaux et des systèmes d’information, tant en termes de réduction/mitigation des risques qu’en termes de réponse en cas d’attaque.
Aux origines : la LPM
Contrairement à ce que je lis/entends souvent, non, NIS n’est pas la LPM (la Loi de Programmation Militaire). Oui, de la même façon que la Loi « Informatique et Libertés » a inspiré le RGPD, on peut dire que la LPM française a été en partie reprise par la directive NIS. Mais ce sont deux textes distincts.
Au travers de la LPM, la France avait défini une entité spécifique : l’OIV, pour Opérateur d’Importance Vitale. Eh bien indépendamment de ces OIV, NIS implique une transposition en droit français de deux nouveaux types d’organisations :
Les OSE, pour Opérateurs de Services Essentiels, qui sont publics ou privés, et offrent des services essentiels (si si) au fonctionnement de la société ou de l’économie (au hasard : ce qui touche à la fourniture d’énergie, aux banques, aux établissements de santé…) ;
Les FSN, pour Fournisseurs de Services Numériques qui comprennent dans le cas présent toute personne morale (de plus de 50 salariés, ou dont le CA est supérieur à 10M€) qui fournit…
une place de marché en ligne ;
un moteur de recherche en ligne ;
un service d’informatique en nuage.
Dans les 2 cas, c’est l’ANSSI qui peut être amenée à contrôler le respect de NIS.
Des implications concrètes pour OSE et FSN
Côté OSE :
Analyses les risques de haut niveau ;
Identifier les Systèmes d’Information Essentiels (SIE) ;
Déterminer leur périmètre ;
Déclarer les SIE et leurs évolutions ;
Notifier les incidents à l’ANSSI ;
Mettre en œuvre les mesures de sécurité définies par les services du Premier Ministre (23 règles) ;
Gérer les risques, piloter la sécurité du système d’information, prévenir les incidents… ‘fin désigner un RSSI quoi !
Une OSE qui ne respecterait pas ce « contrat » s’expose à des sanctions pénales : 125 000€ en cas d’opposition à un contrôle de l’ANSSI, 75 000€ pour non-déclaration d’incidents, et 100 000€ en cas de non-respect des 23 règles de sécurité qu’on évoquait un peu plus haut.
Côté FSN, c’est un peu plus léger :
Cartographier ses systèmes d’information ;
Introduire une notion de gestion des risques IT dans son activité ;
Notifier les incidents « significatifs » à l’ANSSI ;
Mettre en place des mesures de sécurité (même liste que pour les OSE) alignées sur les risques identifiés (de la nécessité de faire une analyse propre). On doit retrouver au minimum :
le respect des normes internationales ;
la sécurité des systèmes et des installations ;
la gestion de la continuité des activités (le fameux PCA/PRA) ;
le suivi, l’audit et le contrôle de cette activité « SSI » ;
et évidemment la gestion des incidents.
Les amendes sont réduites, comparées aux OSE, mais selon la taille de la structure, cela peut rester largement dissuasif : 75 000€ pour les manquements de sécurité, 50 000€ pour la non-déclaration d’incidents, et 100 000€ pour l’opposition à un contrôle de l’ANSSI.
Je le précise tout de même, et c’est valable pour les OSE comme pour les FSN : les amendes sont à la charge des dirigeants.
Il faut voir ce texte comme une façon de pousser une partie des entreprises françaises vers un socle commun « standardisé », notamment parce que NIS implémente clairement une partie de la norme ISO 27001. Ainsi, la marche à gravir pour une certification n’en sera que plus petite ! 🙂
Si votre entreprise dispose déjà d’une gestion de la sécurité informatique structurée, les coûts de mise en conformité sont plus que raisonnables.
Comme je ne sais pas vraiment comment conclure sur un sujet qui n’appelle aucun commentaire spécifique, on va faire simple : à la lecture des textes, NIS est une sacrée salade (NISoise, comme on me l’a dit sur Mastodon), mais au final pas particulièrement complexe à appréhender.
Si vous avez besoin d’éclaircissements spécifiques sur tel ou tel aspect (j’ai voulu faire succinct ici, et c’est déjà trop long, comme souvent), un petit message via le formulaire de contact, et j’essaierai de compléter ici au plus tôt.
Si des questions plus spécifiques/contextuelles et confidentielles se posaient, ne décrivez pas tout dans le formulaire, mais mettons-nous d’accord sur un canal plus approprié, type mail+GPG ou Signal.
Et merci à la team Masto pour le titre, parce que pour le coup je n’étais pas franchement inspiré ! 😉
Aaah les normes ISO… toujours difficile d’entrer dans cet univers lorsqu’on est juste curieux et que les attendus ne valent pas instinctivement l’investissement. Investissement de temps et de concentration, d’une part, et financier d’autre part, ces documents étant plutôt chers. Barrières supplémentaires pour le néophyte : le vocabulaire utilisé est souvent bien spécifique à l’activité visée par la norme… quand il est traduit. Dans le cas de l’ISO 27701, elle n’est disponible qu’en anglais à ce jour.
Votre serviteur a donc pris le temps de lire (3 fois) cette norme et de vous offrir une porte d’entrée vers cet univers. Vous venez ?
Introduction pour les non-techniciens
ISO 27701 ? Tu pousses trop, ça va être trop bruité.
KazukyAkayashi
Donc, l’ami @KazukyAkayashi à qui je faisais part du besoin de motivation pour passer d’un plan détaillé à un article publiable, m’a répondu par une vanne de photographe. Voilà. Passons aux choses sérieuses. 😀
La norme ISO 27701 n’est pas une norme à prendre seule. D’ailleurs, son nom complet nous le confirme, car il faut appeler un chat un chat.
ISO/IEC 27701:2019 – Techniques de sécurité — Extension d’ISO/IEC 27001 et ISO/IEC 27002 au management de la protection de la vie privée — Exigences et lignes directrices
Cette norme fait donc partie de la série des normes ISO 27000 traitant de sécurité de l’information. Plus exactement, il s’agit d’un « complément » à la 27001 (qui traite des SMSI – Systèmes de Management de la Sécurité de l’Information), souvent directement associée à la 27002 qui regroupe un ensemble de bonnes pratiques pour la bonne gestion de la sécurité de l’information. On peut voir cette dernière comme une base de connaissance de règles à mettre en place, dans laquelle piocher.
Seulement voilà. On aborde toujours ce sujet sous un angle particulier : la donnée, l’information, a de la valeur pour l’entreprise qui la possède. L’information peut éventuellement être une donnée à caractère personnel, mais pas seulement. Quid des aspects particuliers liés à la protection des données personnelles (on va utiliser le terme « DCP » pour la suite, pour Données à Caractère Personnel) ?
Vous me direz, « oui mais le RGPD », et vous n’aurez pas fondamentalement tort. La conformité au RGPD telle qu’elle est présentée dans 90% des cas, c’est de la conformité règlementaire, de la « paperasse », des procédures. Genre un registre des traitements et une cartographie, et c’est bon la CNIL nous gonflera pas. Faux.
Il y a un aspect important qui est occulté par la quasi-totalité des cabinets de conseil : l’aspect technique. C’est souvent un choix de leur part, dans la mesure où ils sont majoritairement juristes ou avocats et n’ont pas les éléments permettant de « traduire » l’obligation de sécurité (article 32 du RGPD / article 121 de la loi « Informatique & Libertés ») en mesures techniques.
Le responsable du traitement est tenu de prendre toutes précautions utiles, au regard de la nature des données et des risques présentés par le traitement, pour préserver la sécurité des données et, notamment, empêcher qu’elles soient déformées, endommagées, ou que des tiers non autorisés y aient accès.
Article 121 de la Loi « Informatique et Libertés »
C’est nickel : on se retrouve en tant que responsable de traitement avec une obligation de sécurité (obligation de moyens, pas de résultats) qu’on ne sait pas comment appliquer et à quel moment estimer que les « moyens » sont suffisants.
Concrètement, à part un (ex-)contrôleur de la CNIL, personne ne saurait vous répondre de façon fiable. Reste à chercher un hypothétique référentiel sectoriel à transposer à son propre cas, en y ajoutant des soucis d’échelle (taille de l’entreprise, budget…).
Et bim ! Deus ex machina. L’ISO 27701 est là.
Son rôle est en réalité d’unifier les pratiques et cadre de la sécurité de l’information « classiques », et la protection des DCP (et donc de traiter proprement ce fameux article 32 du RGPD). En se basant sur le cadre robuste et éprouvé posé par l’ISO 27001, et en y ajoutant les éléments qui manquaient, notamment ce second prisme « vie privée » qui inclut une notion de risque que l’organisme fait peser sur la personne concernée par les données. Vous. Moi. Les gosses. Tout le monde.
Elle reste une norme « volontaire », évidemment : libre à vous de vous en inspirer (sans forcément viser une quelconque certification, juste pour faire bien/mieux), mais rien ne vous y oblige.
Qui veut des PIMS ?
(Meilleur gâteau ever — et il n’y a qu’un « m » donc rangez-moi ces verres)
On va rentrer un peu plus dans l’aspect métier maintenant. Lecteur, si tu ne te sens pas concerné, si c’est trop compliqué à ton goût, si tu décroches, c’est « normal », mais si tu veux creuser et qu’il manque quelques clés de lecture pour passer le cap, n’hésite pas à m’envoyer un message via le formulaire de contact.
Dans l’intro, j’ai parlé des SMSI qui sont tout l’objet de l’ISO 27001. La 27701 qui nous occupe ici définit quant à elle les PIMS : Privacy Information Management System. Plus qu’un recueil de règles à mettre en œuvre, on y aborde aussi des notions d’amélioration continue d’un tel système de « management de la vie privée » (oui, il semblerait que la traduction française de PIMS s’oriente vers SMVP).
Peu importe où vous vous trouvez sur le globe, peu importe la taille de votre organisation, en tant que responsable de traitement de DCP (ça vaut aussi pour les sous-traitants, je vous vois dans le fond de la salle, restez attentifs), vous devez appliquer un minimum de cadre. Ce n’est pas forcément votre métier. Vous ne savez pas toujours comment aborder le sujet, comment prioriser les chantiers. La norme vous y aide assez fortement, de par sa structure.
Globalement, on trouve 2 formes de clauses : les exigences, et les directives. Si vous décidez d’appliquer cette norme, les exigences constituent le socle de départ, non-négociable. Les directives, disons que c’est un peu plus « au feeling ».
En termes de structure « avec du contenu » (on exclut donc les clauses génériques type définition, tout ça, qu’on retrouve dans toutes les normes ISO ou presque), on obtient à peu près ça (désolé pour le tableau, j’aime pas les tableurs et j’ai fait ça avec la méthode RACHE) :
Dans ce tableau, RT correspond à « Responsable de traitement », et ST à « Sous-traitant ». On y voit bien que chaque profil a un tronc commun et une partie dédiée. Rien de très sorcier pour élaborer ce tableau : il est facile à appréhender, mais son contenu se déduit quasi-intégralement du sommaire de la norme (et d’une lecture de surface pour quiconque connaît ISO 27001).
Quelques annexes sont également de la partie, et s’avèrent fort utiles. On y trouve entre autres :
une correspondance entre la présente norme et le RGPD ;
une correspondance avec la norme ISO 29100 ( « Technologies de l’information — Techniques de sécurité — Cadre privé » ), qui traite de nombreux aspects relatifs à la protection des données personnelles, mais disons à un « haut niveau » ;
une correspondance avec la norme ISO 27018 (attention nom à rallonge : « Technologies de l’information — Techniques de sécurité — Code de bonnes pratiques pour la protection des informations personnelles identifiables (PII) dans l’informatique en nuage public agissant comme processeur de PII » ) ;
une correspondance avec l’ISO 29151 ( « Technologies de l’information — Techniques de sécurité — Code de bonne pratique pour la protection des données à caractère personnel » ).
Est-ce que je dois m’y mettre ?
Si on prend en compte le nombre d’entreprises qui traitent des DCP, qu’elles le fassent seules ou qu’elles soient contraintes pour diverses raisons de sous-traiter tout ou partie de cette activité, on entrevois facilement l’intérêt d’un tel cadre. Plutôt que de rester dans une posture « je sais pas par où commencer » : suivez cette norme ! Elle vous aidera à identifier, évaluer, puis traiter les risques liés aux traitements que vous opérez, et à assurer en partie votre conformité au RGPD. Cela peut aussi être une première bonne occasion pour vous frotter à une démarche d’amélioration continue ! 🙂
Du point de vue « relations clients-fournisseurs », on peut distinguer deux aspects bénéfiques : une telle démarche renforce nécessairement la confiance des parties prenantes (et encore plus si vous obtenez la certification officielle !), et vous pouvez même utiliser cette certification comme un critère de sélection pour vos différents fournisseurs et sous-traitants, notamment ceux qui ne seraient pas directement soumis au RGPD.
Je parle de certification, aussi j’en profite pour éclaircir un point qui n’est pas nécessairement trivial : on ne peut pas être certifié « seulement » ISO 27701. Concrètement, comme dit au tout début de cet article, cette norme est une extension de l’ISO 27001, avec une implication importante : pour prétendre à la certification ISO 27701, vous devez préalablement être certifié ISO 27001. Dans ce cas, l’adaptation nécessaire pour couvrir ce nouveau périmètre « étendu » ne devrait théoriquement pas représenter une charge délirante.
Quoi qu’il en soit, tout comme pour ISO 27001 et 27002, il n’est pas nécessaire de viser une certification pour s’inspirer de la norme. D’une part parce que cela vous permettra d’adopter des bonnes méthodes de travail, et de bonnes pratiques de gestion des données personnelles. D’autre part parce que cela permet d’avoir un bon « guide » pour couvrir l’aspect sécurité posé par le RGPD. Enfin, parce que si vous vous sentez un jour d’obtenir la certification, vous ne partirez pas de zéro, loin de là. Et en attendant, vous aurez fait mieux qu’avant.
Les normes ISO, quoi qu’on en pense, c’est bon, mangez-en.
Petite râlerie rapide (ou pas) en ce début de semaine après avoir lu un article d’Usbek & Rica sur les tests ADN « récréatifs » (cay rigodrôle de savoir qu’on va finir obèse) et surtout la conclusion de l’auteur (à la suite d’un article finalement assez creux mais rendant presque hype les tests génétiques) :
En tout cas, j’ai toujours du mal à admettre qu’une telle démarche puisse être interdite dans un pays réputé « libre ».
Cyril Fiévet
On va donc avoir ensemble un début de réflexion sur le « pourquoi » d’une telle interdiction dans un pays libre.
Interdiction, donc ?
C’est le mot juste. En France, c’est une loi de 1994 (sur la bioéthique) qui s’applique au cas qui nous occupe, à savoir les tests génétiques « pour le lol ». Concrètement, je vous cite 2 articles « qui vont bien » pour résumer la chose :
L’examen des caractéristiques génétiques d’une personne ne peut être entrepris qu’à des fins médicales ou de recherche scientifique. (…)
Article 16-10 du Code Civil
Le fait, pour une personne, de solliciter l’examen de ses caractéristiques génétiques ou de celles d’un tiers ou l’identification d’une personne par ses empreintes génétiques en dehors des conditions prévues par la loi est puni de 3 750 € d’amende.
Article 226-28-1 du Code Pénal
On va dire qu’on a fait le tour, un peu. La finalité d’un test comme celui utilisé par le journaliste n’est ni un diagnostic médical, ni la recherche. C’est donc proscrit (et ça peut coûter cher).
Dans le détail, le cadre législatif autour des tests génétiques est fort précis et bien plus riche que ce que j’expose ici, mais qui suffit à amorcer la réflexion. Si le lecteur souhaite des détails sur ledit cadre, alors cet article de Numerama devrait répondre à cette attente.
Retenez également (et aussi curieux que ça puisse paraître à certains) que si le RGPD fait bien entrer les données génétiques dans la catégorie des données dites « sensibles », ce n’est pas lui qui a le fin mot en ce qui concerne le traitement de telles données.
De l’usage de ces tests
Entamons notre réflexion par cette voie. Pourquoi les gens font-ils des tests génétiques ?
La réponse est en apparence simple : pour voir. Par curiosité. Qui sont mes ancêtres ? Suis-je l’enfant de mes deux parents ? D’où viens-je ? A quelles maladies dois-je me préparer dans les prochaines années (la crainte de la mort est paraît-il très présente chez mes congénères) ?
Il est courant que l’individu sollicitant un test ne souhaite répondre qu’à l’une des questions auxquelles répond une analyse génétique. Il est probable que d’autres réponses le choquent, le dérangent, voire remettent son existence en question. Est-ce que c’est bien ça, que l’on veut ? Ignorance is bliss, comme on dit.
Bon, et au global, il nous dit quoi, ce test ?
Twilight 4 : Révélation
Prenons ce qui est probablement le leader sur ce marché bien établi : 23andMe, qui propose moyennant 99$ un test salivaire.
Il s’agit ici de déterminer… ses ancêtres. Son « héritage », quoi. Par où la lignée est passée.
Et de partager ça avec les copains, la famille… au sein du réseau social qui va avec et permet même la mise en relation avec des parents plus ou moins éloignés.
Note, lecteur, que 23andMe ne fait pas d’analyses « de santé » parce que pas forcément autorisé sur tous les marchés auquel la société s’adresse. Elle a par exemple reçu l’interdiction de continuer cette branche de son activité par les autorités américaines, car l’approche était réputée peu fiable et surtout pouvait porter à conséquences en cas de mauvaise interprétation des résultats par le client.
Quitte à gruger encore plus la législation, donc, direction GenomeBuddy !
On nous vend ici du « military-grade encryption DNA test » dans la blockchain. Rien que ça. Le faux sentiment de sécurité (puisque rien ne l’étaie, on va dire que c’est du vent, la base quoi) a un coût : 179$. Quoi qu’on a, à ce prix ?
Un kit de collecte, et des résultats directement dans une application pour ordiphone. Cette fois, on a au programme :
Là comme ça, vous allez me dire… rien de méchant, rien de risqué. Vous en êtes si sûrs ?
Et alors, où est l’blem ?
La réponse est en réalité multiple.
Inquiétudes relatives à la vie privée
Le premier élément qui doit attirer l’attention de l’utilisateur potentiel, c’est la société elle-même. Prenons 23andMe, par exemple. Pour prendre sereinement la décision d’avoir recours à ses services, il faut avoir quelques éléments à l’esprit… Comme le fait que cette société créée en 2006 a pour actionnaires… Google, et Genentech (filiale du groupe pharmaceutique Roche). Ou encore le fait que GSK (oui oui, le laboratoire GlaxoSmithKline) est entré au capital mi-2018, moyennant 300 millions de dollars, et a depuis accès à la base de données des analyses ADN effectuées via 23andMe. Tout comme Pfizer. On peut alors légitimement se poser des questions quant au respect de la vie privée du propriétaire de la salive analysée. Je ne tenterais pas d’exercer mes droits tels que décrits par le RGPD, personnellement : vous vous voyez demander à la CNIL d’intervenir pour faire supprimer hors UE des données relatives à une infraction commise ? 😀
La vie privée, donc. Je n’ai pas (encore) pris le temps d’éplucher les CGU et autres politiques de confidentialité des principaux services. Mais quid de la liste des tiers ayant accès aux analyses ? En voilà, une autre question. Prenons déjà les applications pour ordiphone et passons-les au scanner d’Exodus Privacy.
On constate donc que certains tiers ont accès à vos informations génétiques. Et à partir de là, ils en font un peu ce qu’ils veulent, dans les faits. Notamment les croiser avec d’autres données issues d’autres applications auxquelles ils sont également intégrés. Vous commencez à entrevoir le gros problème ?
Mention spéciale à Genomapp, cité avec les applications juste au-dessus, qui ne permet « que » d’importer les données brutes issues de 23andMe et autres afin de faire parler votre ADN de façon plus complète. Genomapp se fait fort de vous informer qu’il ne stocke pas vos données génétiques, ce qui est vrai. Il est cependant fort probable que les interprétations qui en sont faites, elles, le soient : ce ne sont pas des données génétiques à proprement parler. Les mots ont un sens.
La CNIL relève par ailleurs dans son Point CNIL consacré aux données génétiques que 23andMe demande (en plus du prélèvement salivaire) une foultitude de données de santé à ses clients à travers « des questionnaires très précis et intrusifs concernant la sexualité, l’apparence physique, les maladies, les allergies, etc. » .
Hou le vilain mot que voilà ! Et pourtant : les données génétiques, en plus de vous être propres à vous et de vous définir de façon unique et inaltérable (changer de pseudo, d’adresse de courriel… ça se fait, mais pour l’ADN, c’est un poil compliqué), sont aussi partagées et transmissibles. Détaillons un peu.
L’ADN d’un individu est construit à partir de l’ADN de ses parents, je ne vous l’apprend pas. Conséquence : plus on est proche dans l’arbre généalogique d’une personne, plus nos ADN se ressemblent. C’est en partant de cette base scientifique que MyHeritage ou 23andMe annoncent pouvoir retrouver les origines de leurs clients, voire même des noms de personnes qui font partie de leur famille et ont elles aussi eu recours aux services de ces sociétés.
De la même façon, des enfants nés du don de sperme ou gamètes, adoptés ou que sais-je, ont aussi recours à ces services pour tenter de retrouver leurs origines.
Parlons santé, maintenant : un test qui révèlerait une anomalie génétique et le risque de maladie associée pour un individu pourrait donner des indications sur les risques pesant sur les parents, enfants et proches de cette même personne. Vient alors une question bien plus profonde qu’il n’y paraît : qu’est-ce qui prime ? Le respect du secret médical ? La volonté (nécessité ?) de protéger la santé des membres de sa famille ? Le droit de ne pas savoir ? Je ne répondrai pas à cette question, évidemment.
Anecdote intéressante : le « tueur du Golden State » a été retrouvé par les forces de l’ordre américaines en envoyant un échantillon d’ADN collecté sur la scène de crime à GEDMatch, qui leur a renvoyé un cousin éloigné, suffisant pour remonter au tueur par la suite. Si dans le cas précis on peut difficilement critiquer la finalité de la démarche (un tueur arrêté, c’est pas si mauvais que ça, quand même !), ça ouvre la porte à pas mal de dérives potentielles. Laissez vagabonder votre imagination.
…et partagées (aka « rends l’argent »)
On trouve ici un mix astucieux entre le « si c’est gratuit, c’est vous le produit » et le fait que (surtout dans le domaine de la santé) plus c’est cher, plus c’est fiable (coucou l’homéopathie). Sauf qu’il faut quand même que ça reste accessible, pour vendre en masse.
Historiquement, 23andMe (désolé, c’est le leader, donc le cas le mieux documenté) vend ses tests à 99$, bien en-dessous du coût réel d’une telle analyse. Pourquoi et comment vendre à perte ? En récupérant les sous ailleurs. En faisant raquer quiconque veut accéder à la base de données.
Toujours dans le « Point CNIL » cité plus haut, on apprend que cet écart de prix est « la preuve qu’un second marché lui permet de valoriser les résultats des tests et les données associées. L’entreprise propose ainsi à ses clients de communiquer leurs données à leurs partenaires sous une forme non directement identifiante pour qu’ils les utilisent à des fins tant médicales que commerciales. Les deux tiers des 800 000 personnes testées [en 2016] en ont accepté le principe. »
Il y a un an environ, CNBC annonçait la fermeture d’une API proposée aux développeurs par 23andMe. Ce genre de considérations n’intéresse pas le client final moyen. Pourtant, ce type d’information est digne d’intérêt. A la lecture de cet article, on apprend que cette API ouverte en 2012 permettait de développer ses propres services sur une base de données annoncée comme anonymisée (on parle de données génétiques, par natue impossibles à anonymiser). Les développeurs et tiers avaient donc accès aux données brutes. 23andMe annonçait donc fermer cet accès et n’offrir qu’une version « agrégée » par ses soins, sans clairement nommer les problématiques liées à la vie privée probablement à l’origine de ce revirement.
Et dans l’coup, on fait quoi ?
Cet article n’a pas vocation à répondre à toutes les interrogations qui ont pu naître à sa lecture, mais à vous donner quelques clés pour y répondre vous-mêmes.
Un choix avec de telles implications doit être mûrement réfléchi, avec autant d’arguments que possible dans la balance, et en sachant que toute machine arrière est impossible : on ne change pas d’empreinte génétique.
Libre à vous d’envoyer un échantillon de salive à 23andMe et ses copains, ou non, et ce nonobstant les choix (éclairés ?) que d’autres ont fait pour vous et qui ont conduit à l’interdiction de telles pratiques sur notre sol. Un test génétique n’a rien de banal.
Gardez également dans un coin de votre tête que l’avenir c’est peut-être des contrats-type d’assurances, de complémentaires santé… basés sur tout ça. Aujourd’hui, on n’a légalement pas le droit de traiter ça au niveau de l’individu (et encore heureux), c’est discriminatoire. Mais qu’est-ce qui empêche d’ajuster ses tarifs de base en fonction de vrais individus qui ont innocemment contribué à remplir une base mondiale de millions d’échantillons ADN ? Pas grand chose.
Instruits, vous l’êtes maintenant davantage, hors-la-loi, à vous de décider.
Et pour ceux qui aiment les devoirs à la maison, vous pouvez lire cet article du Laboratoire d’Innovation Numérique de la CNIL (qui va plus loin que ces quelques lignes quand bien même il en partage quelques informations et sources), et son cahier IP « Le corps, nouvel objet connecté ».
La majeure partie de la communication autour du RGPD se résume en 2 axes : « vous avez des droits renforcés, utilisez-les » vers les particuliers, et « coucou, tu veux voir ma sanction de 20 millions ? » à destination des entreprises. Il en résulte un biais majeur auquel j’ai été confronté à maintes reprises, notamment au travers des commerciaux de quelques ESN : le RGPD concernerait les particuliers, donc le B2C, et absolument pas le B2B.
Raisonnement validé par le marquis Constant d’Anlayreur (et que celles et ceux qui ont la référence lèvent la main). Traduction : c’est juste faux — comment ce genre de choses peut sembler crédible, même pour un commercial ?
Allez, on développe un peu tout ça.
Est-ce que le RGPD s’applique en B2B ?
TL;DR : oui, la plupart du temps. Pour autant, rien de forcément nouveau sous le soleil, puisque les règles applicables à la partie « démarchage » sont inchangées ou définies par ailleurs dans le Code des Postes et des communications électroniques (cf. article L.34-5). Souvent, le RGPD permet simplement de se (re)poser les bonnes questions.
Une donnée personnelle (pour rappel, tout ce qui permet d’identifier, directement ou indirectement, une personne physique), qu’elle soit utilisée dans un contexte « professionnel à professionnel » (exemple : votre contact chez l’un ou l’autre de vos fournisseurs, clients…) ou non, reste une donnée personnelle. Généralement, Martin Dupond, VRP de son état, quand il débauche le soir, il ne change pas d’identité. Il pose juste sa casquette VRP le temps d’un match de foot, mais voilà, tout ça l’identifie toujours.
Il paraît donc évident que votre listing de contacts, votre roulette à cartes de visite… constitue un « traitement » de données personnelles tel que défini par le RGPD. Donc oui, il s’applique.
Et de la même façon, si l’adresse de courriel de votre contact est de la forme initiale.nom@client.tld ou prénom.nom@fournisseur.tld, le RGPD s’applique également.
C’est un exemple qui était quasi-systématiquement utilisé par la CNIL quand j’y travaillais et je suppose que c’est toujours le cas, parce qu’il se « matérialise » bien dans l’esprit du public : les cartes de visites. En vrac dans un tiroir, pas triées ni rien ? Pas de RGPD. Rangées, triées, organisées, classées ? RGPD, parce que c’est un traitement.
(Source : Daymedia)
Quid du consentement ?
Le consentement n’est pas systématiquement nécessaire pour autant. Les bases « alternatives » (je pense notamment à l’intérêt légitime, qui s’il a des allures de joker ultime n’en reste pas moins à prouver, hein) continuent à potentiellement s’appliquer.
Là où les choses se corsent quand on invoque l’intérêt légitime, c’est qu’il faut démontrer que votre utilisation particulière des données des « prospects » est proportionnée, a un impact très faible sur leur vie privée, et évidemment qu’ils ont été informés de la collecte et des finalités en amont (typiquement, s’assurer qu’ils ne seront pas surpris du démarchage et qu’ils ne vont pas s’y opposer trop violemment).
Je ne vais pas faire ici un grand rappel sur le consentement, j’ai déjà abordé ces aspects dans un autre post. Rappelons simplement qu’il doit être libre et éclairé, avec tout ce que cela implique.
C’est quoi les règles pour le démarchage ?
La plupart du temps, les questions que je peux avoir sur le lien B2B / RGPD concernent en réalité la thématique du démarchage. C’est donc là-dessus que l’on va creuser ensemble aujourd’hui, quand bien même (j’insiste) ce n’est pas spécifiquement lié au règlement européen, quand bien même il a des implications sur ces traitements.
On va distinguer 2 cas différents : le démarchage par voie électronique (courriels, SMS…), et le démarchage téléphonique (tout aussi pénible, mais soumis à des règles différentes). Je précise à nouveau qu’on se place ici dans un cas « B2B » et donc souvent non pertinent du point de vue d’un citoyen « lambda » qui chercherait sur cette page des informations pour cesser d’être démarché. Pour ces éventuels lecteurs, je vous renvoie plutôt par ici et par là.
(Source : iStock)
Démarchage électronique
Le principe « de base » pour les professionnels reste l’information préalable et le droit d’opposition ( « opt-out » ). Cela suppose une collecte loyale avec une information adaptée à ce moment-là… et un mécanisme d’opposition gratuit et (ça paraît bête, mais pourtant croyez-moi il est nécessaire de le préciser) qui fonctionne.
L’objet de la sollicitation doit être « adapté », du moins en lien direct avec la fonction de la personne que vous contactez. Pas la peine d’arroser une assistante de gestion avec vos tarifs sur tel logiciel ou tel lot de SSD.
Qui dit information préalable, dit aussi plusieurs points à traiter absolument :
La personne cible doit pouvoir identifier clairement les partenaires auxquels vous allez communiquer ses coordonnées. Pas de « et nos partenaires commerciaux » ! On les liste, et c’est marre. Et on tient la liste à jour.
Si la liste des partenaires évolue, on en informe les personnes et on leur rappelle leurs droits.
(Source : signal.org) – Installez Signal ! 😉
Démarchage téléphonique
Le télémarketing, ce fléau des temps modernes. Là, c’est la foire. Pas de réelle distinction B2B / B2C au programme.
Le principe général est le même que pour le démarchage par courriel en B2B : information préalable, droit d’opposition dès la collecte (par exemple via une case à cocher).
Un mécanisme d’opposition simple existe : Bloctel. Cette liste est pour autant insuffisante : libre à chaque professionnel du marketing direct de la prendre en compte… ou non. Au risque qu’une personne démarchée s’en plaigne, comme toujours.
Un code de déontologie existe au sein de la profession, mais là encore il n’a rien de contraignant. Il a au moins le mérite d’exister.
Pour terminer…
…ben c’est comme dans bien des cas (basiques) avec tout ce qui touche aux données personnelles : du bon sens, un minimum de respect, et des règles de base à respecter.
Après tout, vos prospects même professionnels, vous les contactez également dans votre propre intérêt. Chouchoutez-les et soyez réglo.
Aujourd’hui on va causer un peu « cybersécurité ». Au diable la technique et le détail, oubliez un instant « La Casa de Papel » et rangez votre pare-feu OpenOffice. Le but de cet article est juste de vous parler de ce qu’est la sécurité informatique et du pourquoi de son existence, simplement, et en quoi consiste (en partie) mon métier. Pourquoi ? Tout simplement parce que je me rends compte qu’à chaque fois qu’on me demande « mais tu fais quoi exactement dans ton travail ? » (que ce soit auprès de débutants ou non hein, c’est pareil avec les développeurs souvent, d’où le titre « troll »), la réponse qui vient est ou trop technique, ou trop vague, et dans tous les cas je ne récolte qu’un « ah d’accord » accompagné d’un regard vide et fuyant.
Mon métier, donc, consiste à assurer/superviser la sécurité de l’information au sein d’entreprises. Cela comporte plein de facettes, mais voyons les choses dans l’ordre. Le poste s’intitule « RSSI », pour « Responsable de la Sécurité des Systèmes d’Information » (ou « CISO » pour « Chief Information Security Officier » typiquement si vous êtes un parisien nourri au Feed qui roule en trottinette électrique). Avant de parler « sécurité », on va donc parler « système d’information ».
L’utilisateur de trottinette électrique moyen
Un « Système d’Information », quoi que c’est ?
Au sein de votre entreprise, vous avez sans doute un « service informatique », un « SI interne », tout ça. Des appellations un peu datées pour ce qui est plus couramment désigné par : « la DSI ».
*silence mystérieux*
La DSI, ou « Direction des Systèmes d’Information », c’est l’entité qui gère tout ce qui touche à l’information et à ses canaux de transit, qu’il s’agisse de matériel (ordinateurs, équipements réseaux, impression…) ou logiciel (licences MS Office, choix de tel ou tel outil métier, etc.). Gardez en tête comme je l’ai déjà rappelé à maintes reprises dans ces pages que l’information n’est pas toujours numérique (le premier qui dit « digital » va devoir raser les murs) mais également papier. Techniquement, les modalités de stockage, d’archivage, de destruction… de l’information « matérialisée » sont aussi de la responsabilité de la DSI.
Ce n’est pas la seule fonction de la DSI, c’est même assez réducteur, mais l’idée est que vous puissiez positionner l’entité et son rôle dans une entreprise.
Le SI interne, quand un dev se plaint que sa VM freeze parce que 8Go de RAM c’est pas assez
La DSI gère donc (à la surprise générale) le Système d’Information. Le SI, c’est l’ensemble des composants qui permet de collecter, stocker, traiter et distribuer l’information, quel qu’en soit le format encore une fois, et que ces données soient personnelles ou non.
Passons à la sécurité
La sécurité aussi porte bien des noms. « Sécurité informatique », « cyber-sécurité », « INFOSEC »… tous ces termes désignent une seule et même chose (et avec encore une fois un biais régulier qui laisse à penser qu’on parle seulement d’informatique, alors que non, j’insiste, vos armoires font partie du SI 😀 ) : tous les procédés, toutes les méthodes en place au sein de votre organisation et visant à protéger lesdites informations. Comme l’humain aime bien les cases, on peut ranger ça dans plusieurs domaines principaux :
La sécurité applicative : en gros, tout ce qui tourne autour du développement de logiciels (applis mobiles, sites web, logiciels…)
La sécurité des infrastructures : là, on parle plutôt de ce qui touche aux réseaux, et au matériel (routeurs, par exemple, qui sont un peu les aiguilleurs du réseau informatique de votre entreprise)
La sécurité « dans le cloud », parce que vu que les DSI sont de plus en plus dans la facilité, on a souvent recours aux services de tiers pour tout gérer. Je parle pas de prestas super spécialisés hein (le conseil a toujours existé), je parle bien d’externaliser des choses auparavant faites en internes pour pas avoir à se prendre la tête avec (ce qui est souvent un échec). Comme le « klaoude » c’est juste l’ordinateur de quelqu’un d’autre et pas vraiment un nuage, il faut gérer sa sécurité aussi.
La gestion des vulnérabilités. Souvent, cela consiste à scanner et essayer de s’introduire dans un SI, dans une application… « comme si on était malveillant ». Inutile de préciser que c’est une prestation bien définie, et qu’on ne fait pas des tests d’intrusion comme on a le pif fait sans avoir de contrat avec le propriétaire du service audité. On entend souvent parler dans ce cas de « ethical hacker » (appellation bullshit s’il en est) ou de « pentest » (penetration testing / tests d’intrusion). Si ces tests mettent en lumière une vulnérabilité, l’idée c’est de la corriger, et avant qu’elle ne soit exploitée.
La réponse à incident. On lui donne bien des noms : CERT, CSIRT, SOC… Tous ces termes désignent des équipes de spécialistes auxquelles on fait appel en cas de pépin. Ils sont à même d’identifier, confiner une menace, et d’assainir un système d’information compromis. C’est très souvent externalisé, car compliqué et coûteux à mettre en place.
Enfin, la cryptographie. Cette discipline n’est pas limitée à la sécurité mais elle y est intimement liée car c’est grâce à elle que la confidentialité de l’information est souvent assurée, via le chiffrement (si j’entends « cryptage » c’est direct au pilori). Je vous invite si ça vous intéresse à parcourir les autres articles ici qui parlent de chiffrement, de hachage, etc.
En quoi c’est important ?
Imaginez un instant que votre banque se fasse pirater et que certaines données soient exfiltrées et publiées. On appelle ça une « fuite de données » (et les juristes ont choisi d’appeler ça « violation de données », ce qui fait moins sens, puisque l’exposition de données n’est pas forcément intentionnelle mais est parfois simplement le résultat d’une négligence, et que sauf exception, un viol n’est pas involontaire).
Votre banque, donc, dispose de pas mal d’infos sur vous : adresse perso, diverses informations personnelles qui pourraient servir à usurper votre identité, données bancaires (qui a dit « vider les comptes » ?), données de carte de paiement (et hop, une commande Amazon avec votre carte).
Et ce n’est qu’un seul des services auxquels vous avez recours au quotidien. Imaginez un peu la quantité de données que cela peut représenter au global, tous services confondus.
Et ces pirates, c’est qui, en fait ?
Quand bien même on observe souvent des « attaques » de proximité (des gens que vous connaissez et que vous auriez passablement contrariés ; ça arrive même aux meilleurs), on va dire que les attaquants de tous poils se rangent là encore dans 3 cases standardisées :
Les « white hats » (je traduis pas, pitié), qui sont les plus sympas. Ils cherchent activement des vulnérabilités, et quand ils en trouvent, les font corriger. Ce sont les « ethical hackers » de tout à l’heure, quoi.
les « black hats », aka « les vilains pas beaux ». Peu importe la motivation sous-jacente, ils ne sont pas là pour rendre service à votre DSI. L’idée est de nuire, ou de rapporter des brouzoufs via la revente d’infos. Et de flatter son égo, hein, on a souvent sa petite réputation à asseoir, son petit « hall of fame » personnel.
les « grey hats », un peu entre les deux. Ils cherchent des vulnérabilités, mais quand ils les trouvent, avertissent l’organisation en cause (souvent avec un délai imparti pour la correction, avant publication des détails). D’autres ne s’embarrassent pas et publient directement les détails, ce qui peut mener à l’effet inverse, une exploitation massive de la faille dans un premier temps. C’est difficile de reprocher ce mode d’action, certains éditeurs mettant des mois voire des années à corriger une faille qui leur aurait été remontée…
BONUS : les script kiddies. C’est un peu cliché mais pas totalement faux. On parle de Jean-Kévin, ado au teint blafard, qui utilise des outils conçus par de vrais pirates pour être simples d’utilisation. On peut citer par exemple LOIC, développé et utilisé dans le cadre d’opérations menées par Anonymous il y a quelques années, pour multiplier les sources d’attaques par déni de service distribué (DDoS). Il y avait 2-3 bricoles à remplir à la portée de tout le monde, et un gros bouton d’attaque. De quoi passer pour un gros caïd du hack sans connaissance aucune. Y’a des taquets qui se perdent.
Un souci d’exposition…
…qui paraît évident, pourtant. Que ce soit sur mobile (fausses applis, pisteurs, points d’accès Wi-Fi compromis), ordinateur (virus et autres vacheries), « drives », courriel (phishing, propagation de malwares), matériel (clés USB, disques durs externes), les vecteurs d’attaque et de transmission de logiciels malveillants sont nombreux. Une clé USB trouvée sur un parking, statistiquement, est branchée à un ordinateur dans les minutes qui suivent, souvent dans l’idée d’en identifier le propriétaire et de la lui remettre. Elle peut aussi avoir été déposée là à dessein, pour introduire un programme néfaste…
Allez, rajoutons-en un peu : l’IdO, l’internet des objets, « IoT » pour les anglophones. Vas-y que j’me promène avec une montre connectée à mon smartphone et à un fabricant (dans le meilleur des cas) H24, que j’ai l’assistant vocal de l’ordiphone dans ma poche (« OK GOOGLE, commande-moi un pack de PQ stp »), que j’ai installé un micro chez moi qui me place sur écoute en permanence (et ça devient même difficile de trouver une enceinte correcte mais NON équipée d’Alexa et ses potes)…
Les serrures connectées ? Une réalité. Les clés de voiture « partagées » via smartphone ? Aussi. Ouais, c’est cool et technologiquement impressionnant. Mais les risques associés sont là, et la plupart de ces choses ne sont pas matures, et de nombreuses marques notamment asiatiques ne prennent absolument pas la sécurité en compte. Même dans des jouets connectés pour (très) jeunes enfants.
Tout ça pour dire : l’hyper-connectivité accroît forcément les convoitises, et les risques qui pèsent sur l’information, qu’elle soit dans un contexte professionnel, ou personnel (ou les deux).
D’où la nécessité de prendre en compte la sécurité de l’information, « priorité pour cette année » ou pas.
Et c’est ça, finalement, mon métier. Prendre tous ces paramètres, toutes ces technologies, tous ces nouveaux usages qu’il ne faut pas forcément juste empêcher mais plutôt accompagner, et aider tout ce petit monde (DSI, décideurs, usagers…) à intégrer cet écosystème en bonne intelligence.
Ça demande beaucoup de patience et de pédagogie, beaucoup d’investissement et de rigueur aussi, de la fermeté parfois (non on branche pas n’importe quoi, non Docker en prod c’est pas une bonne idée, non on arrête de collecter les bulletins de casier judiciaire, et j’en passe), de l’imagination souvent (scenarii d’attaque, par exemple). Mais ça demande surtout beaucoup d’interactions avec tous les corps de métier, et ça c’est génial (si on aime ça). Sensibiliser les gens et faire évoluer les usages dans le bon sens, c’est extrêmement gratifiant pour moi. Même si souvent, en tant que RSSI, on a l’impression d’avoir une tâche ingrate et frustrante qui consiste à parler dans le vide et à essayer d’imposer des choses contre la volonté des usagers du système d’information.
Alors que l’idée derrière tout ça, c’est pas de freiner l’innovation ou le progrès, mais de faire mieux (et idéalement, faire bien) pour aller plus loin.
Je vous laisse avec une interprétation « non-IT » de ma fiche de poste, qui a eu le mérite de faire rire toute l’équipe sécu ce midi :
Je vous envoie des mails de phishing et j’vois si vous êtes suffisamment con pour cliquer. Je vous rappelle les règles de bien vivre en open-space en vous chocoblastant à la moindre occasion. Et de temps à autres je vous rappelle à quel point vous pouvez prendre cher à votre benef’ en faisant n’imp avec les données de vos utilisateurs/collaborateurs/clients, bisou, Maskim
Une webdesigner future dev anonyme
Et en passant : soyez mignons avec vos RSSI, un peu quand même.
Si vous avez le temps et la curiosité, n’hésitez pas à regarder l’Instant Technique que j’ai donné chez Conserto il y a quelques semaines, où je parle de la sécurité « de base du quotidien » (on a tous à ré-apprendre des trucs) :
(Merci tout plein à @valere qui me fournit gentiment un peu d’espace pour ça sur son serveur PeerTube, une alternative à YouTube plus éthique !)
Chose promise, chose due, il paraît, et pour Nextcloud je l’ai promise plusieurs fois cette chose. Après un bon moment de silence, la faute à pas mal de taf, à un déménagement, à une nouvelle vie qui commence… je vais reprendre si tout va bien un rythme de publication plus régulier.
Et pour fêter ça, on va commencer par quelque chose de pas mal demandé par ici : une mise à jour du tutoriel d’installation de Nextcloud / ownCloud sur un hébergement mutualisé OVH. J’y fusionne les retours qui m’ont été faits dans les commentaires de l’ancien article, et d’autres infos plus ou moins liées (genre la synchro avec DAVdroid cassée, c’est pas un pré-requis pour que Nextcloud fonctionne, mais c’est quand même cool d’avoir la solution sous la main ! 😉 ). On ajoutera également une partie sur la synchro des tâches et notes. Allons-y !
Pré-requis
Pas de changements majeurs dans les pré-requis, PHP 5.6+ est toujours supporté, même si PHP version 7.0 ou plus récent est recommandé. Pour ma part, j’ai fait l’installation test avec PHP 7.0. Si un changement de version se fait sans souci avant une installation propre (en repartant de zéro — ça fait du bien de temps en temps !), gardez en tête que se borner à changer la version de PHP dans votre fichier .ovhconfig ou via le Manager OVH peut précipiter le recours à l’installation propre parce que ça aurait tout pété. Pas mal de logiciels digèrent mal la chose, j’en ai fait l’expérience ici même (ouais, j’suis comme ça, j’ai pété Open-Freax en testant, heureusement il a suffi de rebasculer en PHP 5.6 pour réparer).
Je vous conseille également d’utiliser MySQL et pas SQLite, si vous avez pas mal de fichiers et/ou de comptes, sinon, bonjour les dégâts et la base corrompue à mort (testé et désapprouvé). Au final, ma base ne prend pas énormément de place, pour un Nextcloud partagé avec madame, et avec pas mal d’applications.
Il vous faut donc simplement un client FTP(S de préférence) et l’archive d’installation officielle. Il existe aussi un script PHP justement fait pour ne pas se cogner des centaines de fichiers à téléverser via FileZilla (par exemple), mais je ne l’ai pas testé avec Nextcloud (je suis passé de la v11 à la v12, puis de la v12 à la V13, et là de la V13 à V14 sans installation fraîche –c’est mal, mais comme quoi).
On va commencer par l’essentiel, le (sous-)domaine. Dans mon cas, plutôt que d’utiliser une URL de la forme https://mon-domaine.fr/nextcloud/, je préfère un sous-domaine, type https://nextcloud.mon-domaine.fr. C’est affaire de goût, principalement.
Pour le créer, direction le manager OVH, ajoutez votre sous-domaine en prenant bien soin de cocher que vous voulez y accéder en https, pour qu’il ajoute ce sous-domaine à la liste de ceux couverts par votre certificat TLS gratuit Let’s Encrypt. Ensuite, cliquez simplement sur le bouton pour régénérer votre certificat. Patientez quelques minutes (allez prendre un café, ça peut être un poil long), le temps que tout ça se fasse. Pendant ce temps-là, passez à l’étape 1 (du moins le début).
Étape 1 : installation de Nextcloud
Simplissime : téléversez l’archive extraite via FileZilla (par exemple). Une fois que le sous-domaine est bien créé et le certificat mis à jour, pointez votre navigateur web vers la page d’installation, et suivez les instructions. C’est tout bon ! Vous pouvez vous y connecter et activer d’autres applications fournies (Agenda, Contacts), tout ça tout ça.
Mais si vous vous rendez dans la partie « Administration » de votre instance fraîchement installée, vous verrez une flopée d’erreurs. Notez que ça n’empêche pas Nextcloud de fonctionner, du moins pas totalement, mais ça peut vous poser souci dans certains cas d’usage, ou causer un risque d’un point de vue sécurité. On va y remédier.
Étape 2 : se débarrasser des erreurs
Étape 2a : les headers
Pour cela, ouvrez le fichier .htaccess à la racine du répertoire contenant Nextcloud et repérez le pavé qui cause des headers.
Modifiez chaque ligne commençant par Header set en Header always set, et ajoutez ces lignes au bloc en question :
Header always set Strict-Transport-Security "max-age=15768000; includeSubDomains; preload"
Header always set Referrer-Policy "strict-origin"
Étape 2b : activer le cache
Modifiez le fichier config/config.php et ajoutez la ligne :
'memcache.local' => '\\OC\\Memcache\\ArrayCache',
Puis rechargez la page d’administration, et c’est tout bon. Une erreur de moins, qui peut également causer l’apparition d’un nouveau message comme quoi OPCache serait mal configuré. Je n’ai pas encore pris le temps de regarder ça.
Étape 2c : la vérification de code
Puisque nous avons modifié des fichiers propres à Nextcloud, et que depuis quelques temps maintenant un mécanisme vérifie que l’empreinte du fichier en place correspond bien à l’empreinte du fichier fourni par Nextcloud, il paraît logique que ce mécanisme puisse détecter nos modifications et nous en avertir (c’est le but, à la base). Deux options : vivre avec ce bandeau jaune (visible seulement par les administrateurs), ou désactiver la vérification (pas super recommandé, mais ça dépanne).
Dans ce 2e cas, il vous faut ouvrir le fichier config/config.php et ajouter : 'integrity.check.disabled' => true puis relancer la vérification d’intégrité. Le message va disparaître.
Étapes restantes…
Restent 2 « soucis » : une erreur concernant la configuration de php-fpm, côté serveur donc, pour laquelle je ne sais pas s’il est possible de faire quelque chose sans passer par OVH. Enfin, l’espace disponible n’est pas renvoyé, même avec ma manip’ « habituelle » : il faut creuser là-dessus ! Rien de bloquant pour le moment, sauf certaines extensions comme celle pour les « gros fichiers » de Thunderbird qui vérifient l’espace disponible… et illimité ne lui convient pas 😛
Étape 3 : installer le client sans péter sa synchro
Ça parait couillon dit comme ça, hein. Et pourtant…
Techniquement, l’équipe de développement de Nextcloud (un héritage d’ownCloud, techniquement) a décidé que les gros fichiers devaient être découpés en morceaux de 10Mo. Ça se défend, je ne le remet pas en cause. Simplement, sur nos connexion ADSL classiques, ça prend un peu de temps à envoyer, des bouts de 10Mo. Conséquence : le serveur MySQL d’OVH, qui attend les infos sur le fichier tout au long du process, finit par se lasser et fermer la connexion… entraînant l’arrêt de la synchronisation dudit fichier, et une erreur type « MySQL has gone away ». Encore une fois, « on y travaille »… ou pas ? Depuis le temps (genre été 2015), ce n’est pas résolu…
J’ai donc décidé, pour régler le problème côté client, de découper mes « gros » fichiers en morceaux de 1Mo. Plus petit, donc plus rapide à envoyer, donc de multiples connexions à MySQL mais d’une durée plus courte. Et ça passe.
Pour ça c’est simple, il faut modifier le fichier de configuration du client. Déjà, installez-le en suivant les instructions officielles, connectez-vous, puis fermez le client.
Il faut ensuite ajouter la ligne chunkSize=1000000 sous la section [General] du fichier de configuration ($HOME/.local/share/data/Nextcloud/nextcloud.cfg sous Linux).
Il existe aussi une autre façon de faire, qui permet d’étendre le changement à tout le système, utile si c’est l’ordinateur familial avec 5 utilisateurs. Pour ça, sous Linux, c’est simple, ajoutez à vos variables d’environnement la suivante : export OWNCLOUD_CHUNK_SIZE=1000000 . Concrètement, vous pouvez soit l’ajouter à votre propre fichier .profile (situé à la racine de votre dossier personnel, ce qui n’affectera que votre utilisateur), soit la propager à tout le système en l’ajoutant au fichier /etc/profile (il vous faudra les droits superutilisateur, dans ce cas).
Pour OS X: c’est la même commande que celle indiquée ci-dessus, puis vérifier dans le fichier de log situé dans: « /Applications/nextcloud.app/Contents/MacOS/nextcloud »
Sous Windows : Panneau de configuration > Système > Paramètres système avancés, puis créer une nouvelle variable soit pour l’utilisateur en cours, soit pour l’entièreté du système :
Nom de la variable: OWNCLOUD_CHUNK_SIZE
Valeur de la variable: 1000000
Étape 4 : installer/configurer les différentes synchronisations avec Nextcloud sous Android
On va traiter plusieurs choses ici : le client pour les fichiers (qui nous servira également à téléverser automagiquement nos photos, comme le fait Google avec son propre service, sauf que là ça reste chez nous), un client contacts/agenda qui nous permettra de stocker nos contacts et RDV ailleurs que sur un compte Google, un client de synchronisation des tâches et enfin un client pour les notes (façon Google Keep, si on veut et si ça existe encore).
Étape 4a : installer les clients
Plusieurs options s’offrent à vous : passer par le Google Play Store ou par le dépôt de logiciels libres F-Droid. Nextcloud a fait un choix différent d’ownCloud, et bienvenu : l’application officielle est gratuite sur le Play Store (ownCloud vous facture la sienne 0,79€, ce n’est pas excessif mais c’est un choix discutable). Si vous souhaitez passer par F-Droid, la procédure est simple : dans les paramètres de sécurité du téléphone, activez temporairement l’installation d’applications provenant de sources inconnues (au sens de Google, « inconnue » signifie hors Play Store… ce n’est pas forcément dangereux), rendez-vous via le téléphone sur f-droid.org fpour télécharger le fichier APK d’installation. Installez-le. C’est fait !
Petit récapitulatif des logiciels que je vais utiliser ici :
Alors, je ne dis pas que ce sont les meilleurs, ou les seuls, simplement ils répondent à mes critères : simples à utiliser, savent se faire oublier (genre la sauvegarde automatique des photos prises, ou même DAVdroid qui une fois configurer ne demande plus rien et fait son job), gratuits (sur F-Droid du moins, et de toutes façons je n’ai pas les services Google Play sur mon smartphone), et surtout libres.
Mais libre à vous d’utiliser autre chose et, pourquoi pas, de me suggérer des outils dans les commentaires : je suis toujours preneur d’infos ! 😀
Certaines de ces applications sont à ajouter à la main côté serveur évidemment. Au pire, il vous suffit de vous rendre sur Nextcloud Apps, de prendre le fichier zip qui correspond à votre version de Nextcloud (a priori, la 12 😉 ) et de le décompresser dans le dossier apps/ de votre instance, toujours via votre client FTP(S), ou même via l’interface web (net2ftp) proposée par OVH. Ensuite, il suffit de les activer dans le menu « Applications » !
Étape 4b : activer l’authentification à 2 facteurs pour Nextcloud
C’est facultatif, bien évidemment, MAIS je le recommande très fortement. Concrètement, vous ajoutez une couche de protection à votre instance : lors de votre connexion, Nextcloud vous demandera un code en plus de votre mot de passe, et vous devrez utiliser votre smartphone pour l’obtenir (ou un des codes de secours sur papier, au pire).
C’est ce qu’on appelle l’authentification forte : vous cumulez 2 facteurs d’authentification (« ce que vous savez » : le mot de passe de votre compte, et « ce que vous possédez » : votre smartphone. En théorie, vous êtes le seul à pouvoir réunir ces deux éléments).
Vous avez pour cela besoin de deux éléments :
installer l’application « Two Factor TOTP Provider » côté serveur (la télécharger)et l’activer ;
installer et configurer une application permettant de générer les codes sur votre téléphone. Beaucoup de gens utilisent Google Authenticator, mais je vous recommande quelque chose de plus sérieux comme OneTimePad. Il stocke les secrets permettant de générer des codes de manière sécurisée, c’est un atout indéniable, et il est libre, sous licence MIT (le code de Google Authenticator a été refermé il y a quelques années, alors qu’il était initialement ouvert). Bref, choisissez un outil qiu vous convient, tant qu’il respecte la RFC 6238 qui décrit l’implémentation de TOTP.
Une fois que tout cela est fait, il vous suffit de vous rendre sur la page « Personnel » (via le menu en haut à droite), d’activer TOTP, et de générer des codes de secours. Vous aurez un QRCode à « scanner » dans l’application mobile, pour permettre la génération de codes. C’est pas plus compliqué que ça !
Étape 4c : configurer l’application officielle
Rien de bien compliqué : au lancement, il faut simplement remplir 3 champs : l’adresse URL de votre serveur, votre login, et votre mot de passe (en cas d’OTP, voir juste au-dessus).
Et c’est parti.
Pour ajouter la fonctionnalité « InstantUpload » allez dans les paramètres, puis « Téléversement automatique ». Les dossiers contenant des photos apparaissent, et vous pouvez pour ceux de votre choix tapoter le petit nuage, qui virera au bleu : les nouvelles photos seront envoyées directement dans votre cloud. Il y a également davantage d’options, comme l’emplacement de stockage, le téléversement par Wi-Fi uniquement, ce genre de choses.
Étape 4d : configurer DAVdroid/DAVx⁵ (et le reste)
Alors là c’est la magie. Il vous suffit d’ouvrir l’application Nextcloud officielle, d’aller dans les paramètres, et y’a un bouton… « Configurer DAVdroid pour le compte actuel ». 😀
Cela va ouvrir DAVdroid avec tout pré-remplir, sauf votre mot de passe évidemment. Il ne vous reste plus qu’à le saisir et vous connecter.
Si pour une raison X ou Y cela ne fonctionne pas, remplacez l’URL fournie par celle accessible dans l’agenda ( https://nextcloud.mon-domaine.fr/remote.php/dav/principals/users/mon_login ). Il trouvera quand même les contacts, rassurez-vous !
Bonus : mot de passe de mise à jour
Lorsque vous utilisez l’outil de mise à jour intégré, via l’interface web, il est fort probable qu’il vous demande un mot de passe. Qui n’est pas le votre. Il demande la version en clair de ce qui correspond à updater.secret contenu dans votre fichier de configuration serveur. Et évidemment, puisque c’est un hash, ce n’est pas réversible.
La seule solution est donc de générer un nouveau updater.secret et de le remplacer dans config.php, en notant au passage la valeur en clair ! 🙂
Pour ce faire, créez un fichier PHP vierge quelque part sur votre mutu, et placez-y le contenu suivant :
<?php $password = trim(shell_exec("openssl rand -base64 48"));if(strlen($password) === 64) {$hash = password_hash($password, PASSWORD_DEFAULT) . "\n"; echo "Insert as updater.secret: ".$hash; echo "The plaintext value is: ".$password."\n";}else{echo "Could not execute OpenSSL.\n";}; ?>
Accédez à ce fichier depuis votre navigateur, notez les deux valeurs renvoyées, et c’est tout bon, vous pourrez mettre à jour après remplacement du hash et validation de sa valeur en clair !
Vous l’avez sûrement remarqué, que ce soit pour exprimer vos préférences vis-à-vis des cookies sur d’innombrables sites web, ou au travers de diverses applications mobiles, réseaux sociaux… Quand bien même on vous demande de « revoir vos paramètres », il y a des dizaines (voire des centaines dans certains cas, coucou Yahoo) de cases à décocher, alors que c’est pénible et que c’est supposé être un véritable « opt-in » (à savoir, une inscription qui nécessite une véritable action positive de votre part, comme un clic dans une case).
Du côté des gros affamés de données (Google, Facebook), c’est la même, en plus chafouin. Tout est pensé pour que la collecte de données personnelles puisse continuer à avoir lieu. Le tout bien caché derrière un petit assistant en 4-5 écrans qui vous explique que olala le RGPD on l’a bien pris en compte. Et quand vous creusez… C’est la cata.
Toutes ces techniques, on les appelle les « dark patterns » (eux-même partie intégrante de la « captologie »), et l’équivalent norvégien de l’UFC Que Choisir (le CCN, pour Consumer Council of Norway) les a documentées, fort précisément (mais en anglais). Du coup, je vais vous résumer leur rapport, qui se concentrait sur 3 acteurs : Facebook, Google, et Microsoft (au travers de Windows 10).
Vous le savez tous si vous traînez un peu ici ou si la thématique « données personnelles » vous intéresse : dans le « digital », la valeur, c’est souvent la donnée (et tout ce qu’on peut en tirer, en analyse, en revente…). « Si c’est gratuit, c’est vous le produit » ! En fonction des données que vous fournissez, pas toujours consciemment d’ailleurs, on peut notamment mieux cibler les publicités, et donc les vendre plus cher aux annonceurs. Un profil plus rempli, avec parfois des milliers de paramètres différents, ça vaut un peu de brouzoufs, et ça, les requins de la donnée ne l’oublient pas. Et donc, le RGPD, ça les contrarie : redonner du pouvoir aux utilisateurs, devoir leur expliquer ce qu’on collecte et pourquoi, avec qui on partage ça, et en plus leur laisser la possibilité de dire qu’ils sont pas d’accord ? Mais on marche sur la tête.
Le scandale Cambridge Analytica nous a montré, s’il fallait encore s’en convaincre, que des données pourtant parfois sensibles pouvaient être détournées de leur usage initial, pour des tâches aussi nobles que… influencer le vote des gens.
La « fuite » Grindr ? Top aussi : retrouver des informations comme son « statut VIH » sur le net, ça a de quoi faire flipper. Et des bricoles comme ça, on en voit passer toutes les semaines. Si c’est pas tous les jours.
On comprendra aisément qu’une entreprise qui base son business model sur le traitement et la vente de données personnelles va miser gros sur la collecte de ces données, qui doit être la plus efficace et large possible : plus il y en a et plus elles sont exactes, plus on en fait des profils précis qu’on peut monnayer cher. Pourquoi pensez vous que les CGU Facebook vous imposent de garder vos données à jour, et vous interdisent l’emploi de pseudonymes ?
Idéalement, si j’étais Tronchelivre Facebook, je m’arrangerais pour vous en révéler le moins possible sur cette collecte. Histoire de ne pas éveiller les soupçons. De fait, cela va créer une relation totalement asymétrique entre l’utilisateur (vous) et le fournisseur de service (Facebook, Google, tout ça). Au seul bénéfice dudit fournisseur.
Et l’une des façons de maximiser cette collecte, c’est d’utiliser les fameux « dark patterns » dont nous allons parler : des choix d’interface, d’options, de vocabulaire, faits volontairement pour tromper, leurrer l’utilisateur. On entretient le flou, on complexifie l’accès aux options vous permettant de sauvegarder un petit peu de vie privée.
Des choix douteux mais réfléchis
Dans le cas « normal » (qu’on attend, en tout cas), le design d’une application est centré sur l’utilisateur : faciliter l’accès aux éléments importants, comment répondre à son besoin le plus efficacement possible.
Dans les cas qui nous occupent aujourd’hui, on n’est pas vraiment dans la même démarche. On va y ajouter un soupçon (un bon gros, quand même) d’analyse comportementale et de psychologie. L’idée : exploiter des biais cognitifs et psychologiques pour amener l’utilisateur à faire des choix qui « arrangent » l’éditeur, sans soulever trop d’opposition. L’utilisateur va, à cause des biais exploités, faire des choix non rationnels, sans même en être conscient.
Un exemple : en général, un individu va avoir tendance à préférer une récompense immédiate mais sans grande valeur, plutôt qu’une récompense de grande valeur mais plus longue à obtenir.
Un autre biais très souvent exploité est le « biais de confirmation » : on se tourne plus facilement vers des contenus qui correspondent à nos idées (notamment pré-conçues) que vers des contenus qui bousculent nos « valeurs ». Un anti-vaccin, par exemple, va directement accorder plus de confiance à un article qui tape sur les vaccins (sans même l’avoir lu, juste d’après le titre ou le résumé) qu’à un autre qui irait à l’encontre de sa pensée (ici pré-conçue, puisque non-étayée scientifiquement). Parce que ça le conforte dans son opinion, parce que ça le rassure. Et on peut facilement exploiter ce genre de biais.
Donc, les biais. Un concepteur d’interface, s’il les connaît et les prend en compte, peut tout à fait pousser l’utilisateur à effectuer un choix plutôt qu’un autre. Et l’interface a nettement plus d’importance que les mots employés.
Allez, illustrons notre propos avec un des « modules » de configuration des cookies que j’ai croisés début juin, une fois le RGPD « appliqué ».
Observez les « curseurs » OFF/ON. Alors, oui : du point de vue strictement « RGPD », tout est sur OFF. C’est bien de l’opt-in, rien à redire. Mais ces curseurs… ils sont particuliers : vous avez déjà vu ce genre de switchs sur un iPhone ? Quand ils sont sur OFF, ils sont gris/blancs. Et bleus sur ON.
Ici, ils sont inversés : bleu, c’est OFF. L’utilisateur va avoir tendance (s’il souhaite protéger sa vie privée) à penser que tout est activé d’office, et à re-cliquer pour les désactiver… les rendant, finalement, réellement activés.
Techniquement, en proposant un bouton « Tout désactiver » et une liste de tiers longue comme un jour sans bacon, il est évident que personne ne va s’amuser à cliquer sur les boutons un à un. Cela s’explique par le fait que l’éditeur de la solution de « gestion du consentement » n’est pas l’éditeur du site : ce n’était probablement pas prévu pour proposer 400 tiers.
Bref : tromper volontairement l’utilisateur en mettant en œuvre ce genre de techniques, qui vont finalement à l’encontre de l’intérêt de l’utilisateur, c’est ça, un « dark pattern ».
L’utilisation de dark patterns pose notamment un souci éthique. Déjà que la relation utilisateur/fournisseur est déséquilibrée, en plus on vient faire pencher la balance avec des éléments trompeurs. D’autant plus grave quand l’utilisateur a placé sa confiance dans le fournisseur de service : lui, il sait sûrement mieux que moi ce qui est bien pour utiliser le service de façon optimale. Alors quand il vous dit que tel réglage (pourtant plus respectueux de votre vie privée) risque d’affecter assez fortement votre expérience sur le service concerné… le doute s’installe. Puis arrive l’hérésie suprême : la rémunération même pas dissimulée de vos données personnelles.
Et le RGPD dans tout ça ?
Pour l’Union Européenne, le droit à la vie privée et la protection des données à caractère personnel sont fondamentaux. En conséquence, l’UE a revu l’ancienne directive et a adopté le Règlement Général sur la Protection des Données, entré en application ce 25 mai 2018 en renforçant les droit des individus et les obligations des entreprises utilisant les données personnelles. Ce Règlement s’applique dès lors qu’un service est fourni à un utilisateur se trouvant sur le sol européen. On ne va pas refaire le tour du propriétaire en ce qui concerne le RGPD, je l’ai déjà fait en long, en large et en travers. Retenons simplement que parmi ce qu’introduit/renforce le règlement, on trouve deux notions potentiellement liées aux « dark patterns » : privacy by design, et privacy by default.
Le « Privacy by default » correspond lui au fait que par défaut (de base, sans intervention de l’utilisateur) les réglages propres à la confidentialité et à l’utilisation faite des données personnelles par le fournisseur de service, doivent garantir la protection de la vie privée. C’est par exemple ce qui fait que le suivi publicitaire (via les cookies, mais pas seulement) doit être de l’opt-in (sur inscription volontaire) et non en opt-out (on participe de base, mais on peut demander à sortir du mécanisme).
Selon ce dernier principe, lorsque Facebook ou Google vous présentent leur nouvelle politique de confidentialité, ils devraient pré-cocher l’option la plus protectrice pour vos données. Il se trouve que c’est également celle qui leur rapporte le moins et les contraint le plus en termes d’utilisation effective des données qu’ils collectent pour pouvoir rendre le service pour lequel ils existent. Toutes les données « bonus » dont ils n’ont pas strictement besoin pour vous rendre le service vendu (gratuit, c’est une illusion) mais qu’ils demandent à traiter quand même, requièrent pour être traitées légalement votre consentement libre et éclairé. Éclairé, cela sous-entend qu’une information sur leur utilisation vous a été fournie dans tes termes compréhensibles. Libre, parce que puisque ces données ne sont pas strictement nécessaires à la fourniture du service, vous êtes en droit de ne pas accepter de les fournir. On ne peut pas (j’insiste) vous interdire l’accès au service parce que vous refusez de fournir des données personnelles non-nécessaires à la fourniture dudit service.
Avant le RGPD, la plupart de ces services demandaient un consentement générique. Vous consentez à ce qu’on utilise vos données, point.
Aujourd’hui, non seulement l’éditeur doit préciser ce qu’il fait de vos données, mais en plus le consentement doit être distinct/spécifique à chaque finalité. Je peux consentir à ce que Facebook utilise mon adresse mail pour m’envoyer des notifications. Mais je peux ne pas vouloir qu’il la transfère à Midas pour me spammer de promos sur la révision d’un véhicule.
Ce qui explique la terachiée de mails que vous avez reçus fin-mai début-juin, pour renouveler/donner/retirer votre consentement.
Source : Daymedia
Concrètement, qui a fait quoi ?
Déjà, il est important de souligner que les 3 exemples pris par le Consumer Council of Norway ont un rapport différent aux données. Google et Facebook ont un business model basé sur la monétisation des données, ce qui leur permet de fournir un service « gratuitement » aux utilisateurs. Microsoft, pour sa part, se repose moins sur la monétisation pour survivre.
Le CCN a basé son analyse sur les informations reçues en mai 2018 au travers de Windows 10, et des applications mobiles Facebook et Google. Ce choix est lié au fait que c’est principalement via ces modes de consultation respectifs que l’utilisateur y est confronté.
C’est tellement facile et efficace que l’UE a décidé, dans le RGPD, d’imposer un réglage par défaut réglé sur « préserver la vie privée ».
Et puisque ce mode n’est que difficilement compatible avec les activités de certains, toute la difficulté réside là : comment pousser gentiment l’utilisateur à modifier ce réglage par défaut, tout en lui donnant bonne conscience ?
Les géants du net (mais sûrement pas qu’eux) ne s’y sont pas trompés : Google et Facebook proposent tous les deux des options par défaut qui ne sont pas celles qu’on attendait. Pour Facebook, d’ailleurs, on commence par un choix « Accepter et continuer » ou « Configuration avancée », en gros. Le truc qui fait peur et où personne ne va cliquer. On notera au passage que Facebook en profite pour réintroduire la reconnaissance faciale, désactivée depuis quelques années. Et côté Microsoft ? C’est bien géré : pas de choix par défaut, pour continuer l’utilisateur n’a d’autre choix que de choisir l’une ou l’autre des options présentées pour chaque fonctionnalité.
Graphiquement, on notera que pour Facebook, les cases « par défaut » (donc moins respectueuses de la vie privée) sont bleues, contrairement aux paramétrages « avancés », qui sont des cases grisées, moins engageantes.
Chez Google également, bien que l’écart soit moins flagrant, on observe la charte habituelle pour ce genre de formulaire : un bouton bleu, et un lien qui ressemble moins à un bouton. Je vous laisse deviner lequel correspond à quoi.
On notera au passage que le « parcours » chez Microsoft compte autant de clics dans tous les cas : pas de « raccourci » type « Tout accepter », de ce côté personne n’a cherché à dissuader l’utilisateur via un nombre de clics supérieur.
Côté formulation : vous connaissez le truc. On met des termes cool et positifs sur l’option qu’on veut voir choisie, et sur le reste on met du négatif, en insistant sur le fait que ça peut priver de certaines fonctionnalités, voire nuire à la qualité de service (quand bien même c’est faux).
Ainsi, on pourra lire chez Facebook que si on désactive la reconnaissance faciale, Facebook ne pourra pas nous prévenir si un autre profil utilise une photo de nous, potentiellement dans un cadre d’usurpation d’identité. C’est un argument recevable, en soi. Simplement, la reconnaissance faciale ne sert pas qu’à cela, et Facebook ne dit pas tout à ce moment-là.
Chez nos amis Google, on observe le même mécanisme, et on apprend que désactiver la publicité ciblée n’est pas vraiment utile, puisque nous verrons toujours de la publicité, mais « moins utile ». (il y aurait donc de la publicité utile ?)
Idem chez Microsoft, ou la remontée d’informations « complètes » chez Microsoft est apparemment une fonction génialissime.
Un autre biais très bien connu : la balance récompense/punition. On préfère tous un chocolat-récompense plutôt qu’un coup de fouet. Bon OK pas tous, mais la majorité, dirons-nous. Bref. C’est toujours assez subjectif, la notion du bien/mal étant au choix de l’arbitre.
Ce biais peut très souvent s’observer en liberté dans son habitat naturel (les GAFAM) : c’est le « take it or leave it », vous acceptez les nouvelles conditions, ou bien voilà la procédure pour fermer votre compte. Qu’on trouvait ici chez Facebook, Twitter… une technique roublarde et ressemblant pour le moins à une prise d’otage. On l’appelle souvent le « take it or leave it ».
Chez Google, on voit le même type de mécanismes : désactiver la publicité ciblée empêche par la suite de masquer, bloquer certaines publicités, ou d’en couper le son sur YouTube.
Vous avez dit « punition » ?
Et pour terminer sur ce sujet : on remarquera que ces 3 acteurs ont fait le choix non pas d’une communication anticipée, ou par courriel, avec un délai pour choisir, tout ça. Non. Tout ça apparaît à un moment où l’utilisateur veut utiliser le service, et où il n’a pas forcément l’envie ou le temps de tout lire et de cliquer partout pendant 5 minutes. Tout en laissant assez d’éléments visibles pour motiver l’utilisateur : sur son interface web, Facebook laissait visible le nombre de notifications, par exemple.
Alors, que faire ?
Take it, or leave it ? Si dans l’absolu la réponse est évidente (cesser d’utiliser ces services), en pratique il reste délicat pour pas mal de personnes de quitter l’un ou l’autre (ou davantage) de ces écosystèmes dont le but n’est définitivement pas de nous rendre service. Reste à espérer voir émerger des alternatives sérieuses, et profiter du droit à la portabilité nouvellement introduit par le RGPD…
Pour ce qui est des pistes : je vous encourage à « auto-héberger » vos courriels loin de ces plate-formes (sans forcément galérer, pourquoi pas en achetant un nom de domaine chez Gandi, OVH…), à quitter les réseaux sociaux privateurs (et à migrer sur une alternative chouette comme Mastodon — les oubliettes, c’est la vie #CeuxQuiSaventSavent ), à utiliser les services de Framasoft (par exemple) pour remplacer ceux de Google, ou encore à tester une distribution GNU/Linux de votre choix (pourquoi pas Linux Mint, très simple d’usage ?) en remplacement de Microsoft Windows. C’est un début.
On reparlera évidemment de tout ça par la suite ! 😉
L’application, après avoir été « épinglée » par Exodus Privacy pour ses 20 pisteurs (20, quoi…), avait en gros 2 options : virer purement et simplement les pisteurs (c’est tout de même un établissement public, hein, l’idée n’est pas de blinder une application de pubs et de revendre les données pour faire de la thune), ou se conformer au RGPD en fournissant une information répondant aux critères que je mentionnais plus haut.
Le progrès, c’est qu’il y a de l’information, pour peu qu’on se donne la peine de fouiner. Si elle est complète, on en sait bien plus sur ce que fait l’application.
Le gros hic, c’est que côté RGPD, on est encore loin de la conformité. Voyons ça en images, sur une installation fraîche de la dernière version en date du 5 août 2018.
On retrouve évidemment l’éternel pop-up d’information « préalable ». Que remarque-t-on ? Deux choses : l’information intervient après l’installation et le premier lancement de l’application, pour commencer, or l’information doit être préalable à toute utilisation donnant lieu à un traitement de données personnelles. Ensuite, premier « dark pattern » : quand bien même l’écran permet d’afficher un pop-up plus grand, Météo-France fait le choix d’une petite boîte de dialogue. Bingo : tout le texte n’est pas affiché, et… encore moins le lien bien trop discret permettant de choisir ce qu’on autorise ou non.
La pop-up initiale, trop petite
Le lien de paramétrage, discret et caché au premier regard
Les autorisations de l’application, telles que proposées par défaut (tout activé…)
Liste des partenaires à qui les données sont transférées, configuration par défaut 1/4
Liste des partenaires à qui les données sont transférées, configuration par défaut 2/4
Liste des partenaires à qui les données sont transférées, configuration par défaut 3/4
Liste des partenaires à qui les données sont transférées, configuration par défaut 4/4
Pour décocher un tiers, c’est à la main via un bouton quasi-invisible
Le bouton blanc, une fois désactivé, est gris
Comme précisé dans les légendes, le privacy by default n’est qu’une vague idée, puisque toutes les utilisations sont activées, ainsi que la transmissions vers de nombreux tiers (et la liste est tout de même remarquablement longue). On peut désactiver ces tiers, évidemment, mais un par un, avec pas moins de 3 « clics » par tiers. Et évidemment, le premier écran de la liste ne contient que des tiers « Désactivé », ce qui laisse à penser que tout serait désactivé… à moins de faire défiler.
Un bon résumé des mauvaises pratiques croisées dans cet article, en somme. Regrettable, surtout quand on sait que le site mobile est tout à fait fonctionnel, plus simple à utiliser, et fournit parfois davantage d’informations.
Cet article, probablement le dernier de notre petite série sur le RGPD à paraître avant le 25 mai, va traiter d’un point essentiel : les contrôles de l’autorité de protection des données (DPA, pour Data Protection Authority), chez nous : la CNIL (sauf en cas de contrôle transfrontalier, avec une autorité chef-de-file différente, évidemment.
On va donc voir comment ça se passe, quelle attitude adopter, et surtout quels sont les manquements les plus souvent constatés.
Un certain nombre d’entre vous connaissent un peu mon parcours : ex-consultant spécialisé dans les audits SSI, formateur pour DPOs en devenir, aujourd’hui RSSI, mais surtout, ex-contrôleur de la CNIL. En quelques années, j’ai vu des systèmes d’information dans tous les secteurs d’activité, de toutes les tailles, avec toutes les technologies du monde, et pourtant… les mêmes erreurs. Celles qui leur ont valu au mieux une clôture avec observations (un genre de rappel à la loi, si on veut), au pire une sanction publique.
Dans un souci de respect des organismes contrôlés (quand bien même la mise en demeure ou la sanction a été rendue publique, elle sera à terme anonymisée), je n’associerai aucun manquement à la loi « Informatique et Libertés » à telle ou telle entreprise. Et par respect pour certaines règles propres à la CNIL, quand bien même j’en désapprouve une partie, je ne mentionnerai pas avoir participé ou non à telle ou telle mission de contrôle.
Idée reçue n°42 : les contrôleurs sont des êtres abjects
On va casser un mythe : les contrôleurs de la CNIL ne sont pas là pour tout retourner, avec en ligne de mire une sanction publique pour faire les pieds de la boîte contrôlée. Ils passent la journée avec vous (en atomisant votre agenda de la journée au passage, certes), mais sans « chercher » la sanction. L’idée d’un contrôle, selon le contexte, c’est :
de faire un état des lieux de tel ou tel traitement de données à caractère personnel ;
d’observer, au travers de plusieurs contrôles dans des entreprises différentes, les pratiques d’un secteur d’activité peut-être nouveau (comme ça a pu être le cas avec les services de livraison de bouffe commandée dans des restos), pour éventuellement sanctionner, mais surtout éditer des guides sectoriels de conformité, et éventuellement faire évoluer la doctrine de la CNIL ;
de traiter une plainte…
A propos des plaintes, sachez que les équipes de contrôle abordent la chose en toute impartialité. Ce n’est pas forcément l’accusé qui est en tort. Oui, c’est souvent un salarié qui dépose une plainte contre son patron (j’ai passé pas mal de temps sur des contrôles côté RH), mais puisqu’en pratique on ne connaît pas le contexte du litige (la plainte de la CNIL n’est souvent pas le cœur du problème, plutôt un moyen d’intensifier la pression)… Retenez malgré tout qu’environ 50% des plaintes donnant lieu à contrôle dans un contexte « salarié/patron » sont juste infondées : le souci est autre. J’ai souvenir d’un chef de PME qui m’a accueilli, las, m’expliquant qu’il était en conflit avec une salariée, et juste pas surpris de me voir : la salariée, licenciée pour fautes, a déposé plainte auprès de la Police, lui valant un déplacement en Alsace alors que le siège est en Île de France. La semaine suivante, il a reçu la visite de l’Inspection du Travail, de la Police, de l’URSSAF, des Impôts… et quelques jours après, de la CNIL. Et une convocation aux prud’hommes. La salariée avait saisi toutes les autorités de contrôles qu’elle connaissait, simplement pour lui mettre la pression et le faire suer. Ce contrôle, d’un point de vue CNIL, n’a rien donné : aucun élément tangible n’a pu être collecté, du moins en restant dans nos missions, les compléments ayant été effectués par la Police (notamment la recherche d’un disque dur, objet de la plainte).
Bref : tout ça pour dire, les contrôleurs sont adorables, à condition qu’on ne leur vole pas dans les plumes.
A éviter : casser les noix du contrôleur
Gonfler le contrôleur, c’est le meilleur moyen que la journée se passe mal pour le contrôlé. Trois courts exemples de trucs à ne pas faire :
faire poireauter la délégation à l’accueil pendant 3 plombes. C’est énervant, et de toutes façons elle ne partira pas. Au mieux ça met des doutes sur votre sincérité, et sur le fait que vous soyez potentiellement en train de cacher des dossiers sous le tapis, de supprimer des données (on arrive généralement à les avoir quand même), ou de briefer vos collaborateurs pour mentir (c’est mal). Au pire, la délégation en aura ras-le-bol et va dresser un PV d’opposition : si vous ne voulez pas nous recevoir, c’est que vous refusez le contrôle, et ça ne fonctionne pas comme ça. Rappelons que la non-coopération avec la CNIL vaut régulièrement des sanctions, et que le contrôle sera fait tôt ou tard, dans la douleur.
être agressif lors de l’accueil. Quand une délégation de la CNIL se présente, vous pouvez légitimement avoir des doutes : est-ce une vraie délégation ? Pour ça, nous présentons un ordre de mission qui indique les noms des agents habilités à procéder à ce contrôle précis. Et une décision de la Présidente. Et nos cartes professionnelles, pour les agents qui en ont une, sur le même modèle que les cartes de Police (Marianne, bandeau tricolore, tout ça). Sinon, nous avons un badge « générique », et surtout une copie du JORF qui liste tous les agents habilités par la CNIL à prendre part à une mission de contrôle. Informations qui peuvent être confirmées d’un simple coup de téléphone à la CNIL, ou sur son site web.
Or, dans certains cas, et j’ai en tête un chef de police municipale, qui a refusé de nous croire malgré les documents et la carte professionnelle identique à la sienne, et demandait d’autres documents d’identité, etc. Ça commençait mal.
insulter, frapper les agents de la CNIL. Effacez ce sourire, c’est une réalité. Je ne citerai qu’un cas où des agents, insultés, ont été « raccompagnés » de force à la porte, parce que le gérant refusait le contrôle (plaintes multiples au sujet de caméras de surveillance dans des… vestiaires). Ben, ça a mal fini : la délégation est revenue, plus nombreuse, accompagnée du chef de service. Sur 2 ou 3 des sites de l’entreprise simultané, avec une ordonnance du Juge des Libertés et de la Détention qui fait que l’organisme ne dispose plus du droit d’opposition (on va en parler juste après). Et surtout, dommage pour le gérant qui ne voulait pas de la CNIL « à cause de l’image que ça renvoie à ses clients », devant son attitude violente, les délégations sont venues accompagnées d’équipages de policiers, en uniforme. Niveau discrétion, c’est pas gagné pour lui.
L’opposition : un droit encadré
J’ai mentionné quelques fois le terme « opposition ». Le contrôlé a effectivement ce droit, mais précisons de quoi il retourne : il peut s’opposer à la présence des agents de la CNIL dans ses locaux, mais pas au contrôle. Ce qui se traduit quasi-systématiquement par une seconde visite, avec une ordonnance du juge des libertés et de la détention du TGI local, et éventuellement les forces de l’ordre, qui s’assureront que la délégation peut bien effectuer ses constatations. Selon l’urgence, l’ordonnance peut arriver *très* vite, donc ne comptez pas forcément sur un répit d’une semaine… Sachez qu’en tout état de cause, le Procureur de la République territorialement compétent a été averti de la mission de contrôle.
Si, malgré l’ordonnance du juge, vous décidez d’empêcher le contrôle par quelque moyen que ce soit, notamment en dissimulant des documents, en les détruisant… ou simplement qu’il vous prend la mauvaise idée de faire votre possible pour mettre des bâtons dans les roues de la CNIL, on passe alors au délit d’entrave, puni d’un an d’emprisonnement et de 15 000€ d’amende.
Opposition préalable ou pas, le délit d’entrave à l’action de la CNIL peut être constitué. Vous pouvez très bien laisser le contrôle se faire (lorsque la délégation mentionne l’opposition et l’ordonnance du JLD, la plupart des organismes font machine arrière) et volontairement cacher des informations, des fichiers, détruire des preuves… Je me souviens notamment d’un responsable de traitement qui avait fait attendre la délégation, laquelle avait fini par demander à une autre personne de l’entreprise de l’emmener là où était piloté le système de vidéosurveillance de la société… pour constater que le gérant avait profité de l’attente pour arracher l’enregistreur et partir avec, en laissant tous les câbles pendants, l’écran en place… et prétendre que non, il n’y a jamais eu de dispositif vidéo !
En résumé, et pour le bien de tout le monde (les contrôleurs sont des humains sensibles aussi, et personne n’aime être « brutalisé » même verbalement), faites preuve à l’égard des contrôleurs du même respect qu’ils ont pour vous. Et s’ils refusent un « cadeau » en fin de journée, s’ils déclinent votre invitation à déjeuner le midi, ce n’est pas par défiance, c’est simplement parce qu’ils ont des règles de déontologie à respecter, et le besoin de discuter seuls le midi de ce qui a été vu le matin, des constatations à effectuer l’après-midi… ou simplement envie de décompresser et parler d’autre chose !
A propos du secret professionnel
Alors celui-là… C’est le joker de tellement d’entreprises ! Aux questions de la délégation, vient souvent la réponse « je ne peux pas répondre, c’est couvert par le secret des affaires », « je ne peux pas vous communiquer ce document, secret professionnel oblige »…
Sachez que cet argument n’est pas opposable (à lui seul) à une demande de communication d’informations/documents émanant de la délégation. Il appartient alors à l’organisme contrôlé de se justifier, de préciser quelles informations sont couvertes, et surtout le fondement légal sur lequel elle s’appuie. Pas de fondement ? Pas de secret.
Donc voilà : en gros, la délégation parle à tout le monde, demande toute information dont elle a besoin, accède à tout local professionnel, et c’est comme ça.
Et pour faire bonne mesure… elle ne prévient pas forcément de sa venue. Les données numériques sont par nature volatile, je ne vous l’apprends pas. Prévenir 3 jours avant le contrôle, c’est laisser le temps de faire le ménage. Un peu.
Notez qu’en cas d’urgence, la CNIL peut tout à fait saisir le JLD et obtenir une ordonnance préalablement au premier contrôle : plus d’opposition possible, dans ce cas.
Principaux manquements constatés
Enfin la partie qui vous intéresse ! 😉
Au cours de mes différentes missions, j’ai pu relever un certain nombre de manquements, ayant donné lieu à pas mal de mises en demeures et/ou sanctions. Et étonnamment, ce n’est pas forcément pour des usages détournés, malveillants… mais par contre reviennent très souvent des manquements à la sécurité (article 34 de la Loi de 1978, repris dans l’article 32 du RGPD, avec globalement les mêmes implications et attentes). Faisons le tour ensemble.
La liste des points que nous allons passer en revue est assez simple :
mises à jour logicielles ;
stockage et robustesse des mots de passe ;
dépôt de cookies/traceurs ;
identifiants/mots de passe par défaut ;
fuite de données ;
configuration SSL/TLS ;
mots de passe des salariés (robustesse, enregistrement dans le navigateur…) et prestataires ;
caméras : implantation/information/masques ;
sécurité des postes nomades et ordiphones
Mises à jour logicielles
Votre amour de Microsoft Windows XP ou de RedHat 3 risque de vous causer du tracas, et surtout une mise en demeure de la commission de migrer vos postes de travail et serveurs vers des systèmes encore maintenus par l’éditeur, qu’il s’agisse du système d’exploitation, des logiciels serveurs (qui utilise encore Apache 2.2 + PHP 5.4 ?) ou de middlewares divers et variés. Plus maintenu, ça veut dire plus de correctifs de sécurité, or on découvre des vulnérabilités régulièrement, qui exposent d’autant vos utilisateurs à une perte de vie privée en cas de vol de leurs données.
Stockage et robustesse des mots de passe
Nous sommes, lorsque j’écris ces lignes, en 2018. Eh bien, en 2018, il y a encore des développeurs qui conçoivent des applications, des services web… qui stockent les mots de passe des utilisateurs en clair dans une base de données. Si si.
Et d’autres qui les « encryptent » en MD5. Pour rappel, MD5 est un algorithme de hachage et non de chiffrement.
Pour rappel, on ne stocke jamais un mot de passe en clair : on le sale, et on le hache. Avec un algorithme un peu robuste quand même. SHA-256, c’est bien.
Toujours à propos du mot de passe, bon, on constate du grand classique : trop court, trop simple, trop « kevin2004 ».
La CNIL a mis à jour début 2017 sa « recommandation mots de passe« , qui n’a de recommandation que le nom politiquement correct. C’est sur cette base que sera jugée la conformité de votre application. Et ce ne sont pas 8 caractères alphanumériques qui vont satisfaire la délégation.
Il est assez curieux de constater que plus d’un an après sa dernière mise à jour, peu d’éditeurs respectent ces lignes directrices…
Dépôt de cookies et traceurs
Récemment, un des RSSI avec qui je travaillais m’a contacté, m’expliquant que la CNIL l’avait « aligné » sur 2 sites web de la société (contrôles en ligne). Notamment, sur le recueil du consentement avant dépôt des cookies.
Faites une information simple et lisible, pas 850 petites lignes
On va donc rappeler des règles pourtant supra-basiques :
on demande le consentement *avant* le dépôt, pas après. On ne dépose strictement aucun cookie non-technique avant le consentement du visiteur ;
l’information, bordel ! On explique quels cookies sont déposés, et pourquoi ! Quel besoin aussi vous avez de déposer 35 cookies tiers…
le consentement doit être *valable* : c’est une action positive. J’insiste ! « Poursuivre sa navigation » n’en est pas une, en particulier parce qu’ainsi vous conditionnez l’utilisation du service au dépôt de pisteurs. Donc non, le petit bandeau en mode « si vous continuez votre visite, c’est que vous acceptez les cookies », c’est non, re-non, et au bûcher.
vous devez fournir un moyen de refuser les cookies. Je dis bien, *vous*. Renvoyer l’utilisateur à une obscure page qui lui dit qu’il n’a qu’à configurer son navigateur pour refuser les cookies, c’est niet, et pas conforme à ce qu’attend la CNIL. Pourquoi ? (oui je vous sens tendus là) Ben, parce que déjà la plupart des gens ne savent pas le faire et ne voudront pas chercher. Ensuite, parce que le blocage via le navigateur, c’est un bouton ON/OFF. Global. Pas simplement pour votre site, mais pour tous ceux que visite l’internaute. C’est un peu facile. Je vous recommande l’excellent tarteaucitron.js pour gérer ça comme des éditeurs civilisés. C’est lui que vous pouvez voir sur le site de la CNIL.
internalisez ! Notamment l’analytics. Matomo (ex-Piwik) est très bien pour la plupart des cas d’usage, et peut même être configuré proprement, vous dispensant alors du recueil de consentement pour son cookie. C’est sûr que ça demande un poil plus de temps qu’un snippet Google à balancer dans une source de page web, mais c’est mieux pour tout le monde, et Google et ses potes se gavent bien assez par ailleurs.
Et ça, c’est simplement pour le web.
Attendez-vous également à la même chose pour vos applications Android qui grouillent littéralement de traqueurs. On remerciera au passage l’association Exodus-Privacy pour son travail sur la question. D’ailleurs, vos applications figurent peut-être déjà dans la liste des applis analysées 😀
Je vous encourage très fortement à utiliser εxodus, dans la mesure où la CNIL s’y intéresse de près. Si c’est aussi votre cas, n’hésitez pas à nous rejoindre, à contribuer, à nous soutenir, peu importe la manière, il y a plein de choses à faire. Vous pouvez également faire un don, si le cœur vous en dit.
Identifiants et mots de passe par défaut
Allez, je vous raconte 2 histoires.
La première : contrôle du dispositif de vidéosurveillance d’une moyenne surface. Évidemment, le poste qui gère les caméras et l’enregistrement est à l’accueil du magasin, écran visible des clients.Et la gérante est un peu paniquée : elle ne connaît pas le mot de passe du logiciel d’enregistrement. C’est une solution connue, je lui demande la permission d’essayer le couple login/mot de passe par défaut. Banco. Je vous laisse méditer sur les conséquences potentielles.
En fait non. Ménageons-nous. Les conséquences, les voici via la seconde histoire.
On prend maintenant un théâtre, comme il y en a dans toutes les villes. Avec de la vidéosurveillance également. La patronne me montre, assez fière, qu’elle peut même accéder aux images en direct et enregistrements depuis son iPhone, via une appli dédiée. Et le midi, j’ai eu un doute. De retour au théâtre, test : je sors mon ordiphone, j’installe l’application depuis le Play Store, je l’ouvre et entre comme cible le nom de domaine du site du théâtre. Tout le reste, c’est de la configuration par défaut, pré-rempli par l’appli : identifiant, mot de passe, port réseau… Et le miracle se produisit : accès aux images. Extractions et effacements à portée. La madame comprend alors comment s’est passé son cambriolage quelques semaines auparavant : les malfrats restaient dans les angles morts, et n’étaient jamais visibles de face, au début. L’un d’eux avait son smartphone en main tout le long Pour la suite du cambriolage, c’est bien simple : pas d’images. Le système n’a rien enregistré pendant 20 minutes. Maintenant, l’explication est là : les images ont été effacées.
La madame, disons… relativement contrariée… appelle séance tenante son prestataire, le met sur haut-parleur, et lui explique la manipulation que je venais de faire.
Ma première insulte en contrôle. Je venais de gagner mon badge de « fouille-merde », attribué par le monsieur presta.
Ces deux histoires pour vous dire que si il y a un mécanisme d’authentification, c’est probablement pour une bonne raison. Laisser des identifiants par défaut, genre admin/admin, c’est donner le bâton pour se faire allègrement molester.
La délégation n’est pas dupe. Quand on croise une authentification, on voit l’identifiant, on compte les petites étoiles pour avoir la longueur du mot de passe (on ne vous les demande jamais, bien entendu), et on vous demande de quoi il est constitué (lettres, chiffres, majuscules/minuscules…). Quand la réponse c’est « 5 caractères, que des lettres » alors que l’identifiant est « admin », pas besoin d’être grand druide pour voir ce qu’il se passe.
Fuites de données
Ouais, parce que la « violation de données » c’est tellement nul comme terme… on avait eu un débat en interne, mais comme ce sont les juristes qui tranchent (ça a clashé plusieurs fois entre « informaticiens » et juristes parce qu’ils bricolent nos termes techniques jusqu’à en dénaturer le sens), « violation » ce sera. C’est dans l’air du temps, niveau répertoire.
On ne compte plus les exemples de mises en demeure et sanctions relatives à des fuites. Et ne vous plaignez pas : la CNIL est gentille et se place « dans la peau d’un internaute bienveillant », et ne retient que des modes opératoires accessibles sans compétences particulières. Pour le moment. Donc exit les injections SQL et ce genre de trucs rigolos : s’il en croise, l’auditeur peut éventuellement contacter le propriétaire du site et l’informer, au conditionnel, que potentiellement il serait envisageable que potentiellement son site soit tout troué. Cela m’est arrivé une fois, et le RSSI ne m’avait pas cru. « On est sécurisé nous monsieur, je ne remets pas en question vos compétences, mais… ». Puis je lui ai listé les tables dans sa base de données. Il a changé d’avis.
Donc, les violations. Très souvent, elles se matérialisent par une partie de l’URL qu’on fait varier : un compteur dans le chemin, une variable GET qui ressemble à un identifiant… et on aspire les pages concernées, histoire d’avoir des éléments de volumétrie.
Sans dec’, à quel moment vous vous dites « on va faire un site qui facilite le dépôt de plainte et l’envoi de courriers au Proc’, on va donc recueillir les détails des infractions, les coordonnées du plaignant, de l’accusé, et tout ça sans créer de compte ou protéger le dossier pour qu’il le complète facilement plus tard si besoin » ?
Bah ouais, du coup, suffit de commencer la démarche, de faire varier l’identifiant dans l’URL (un nombre, qui s’incrémente de 1 à chaque nouveau dossier)… et de constater qu’on accède à tous les dossiers de gens qu’on ne connaît pas.
C’est juste de la « négligence caractérisée » (semi-private joke, coucou Hadopi), et une sanction pour ça est donc méritée. N’en déplaise à un avocat qui avait plaidé contre la publicité d’une sanction dans cette catégorie peu glorieuse, refusant qu’on « mette son client au banc de l’Internet, qui n’oublie jamais, même si Legifrance anonymise derrière ». Surtout que dans certains cas, on parle de données sensibles, et de choses comme 250 000 personnes.
Configuration HTTPS
Aaaah, le fameux https. « S’il y a un cadenas vert, c’est sécurisé ». Non. Encore non.
Chiffré, oui, assurément. Mais la question reste : comment ? Potentiellement avec des algorithmes dépassés, via un protocole obsolète, le tout vulnérable à plusieurs vulnérabilités connues, documentées, exploitables.
Deux collègues et moi avons établi des lignes directrices, qui ont été validées par la CNIL, sur ce qui était considéré comme correct, tolérable, inacceptable. Quand bien même ce document n’est pas encore public, vous pouvez vous faire une idée en scannant votre site avec CryptCheck, ou via testssl.sh. Oubliez le scanner de Qualys : son échelle de notation est scandaleusement mauvaise.
Et à l’occasion, je publierai probablement un guide sur le sujet. Voilà.
Utilisez des standards reconnus, pas un voile de fumée vendue par un éditeur peu scrupuleux
Mots de passes « en interne »
On a parlé plus haut des mots de passe de vos utilisateurs. OK. Mais en interne ? Les sessions Windows ? Les applis, le back-office, l’ERP, toutes ces choses « invisibles » de l’extérieur ?
Même chanson. Mêmes mesures. Un presta qui fait de la maintenance sur une énorme base de données nationale, avec en login « tma » (tierce maintenance applicative) et en mot de passe « tma » ? C’est possible. Et je suis convaincu que ce qui a été constaté chez ce presta n’est pas un cas isolé.
Les politiques de gestion des mots de passe, c’est pas juste pour faire joli, il faut les appliquer. Sinon le couperet tombe, et fort de surcroît.
La CNIL retiendra aussi l’enregistrement des mots de passe dans un navigateur, notamment parce qu’il suffit de se tirer avec votre profil Firefox pour tout récupérer en clair, ou au pire prendre 10 minutes pour péter le mot de passe maître. Privilégiez les coffre-forts comme KeePass.
Les caméras
Qu’on soit pour ou contre, qu’on conchie le terme « vidéo-protection » ou non, c’est un fait : y’en a partout, le principal effet étant de déplacer la délinquance là où elles sont encore absentes, ou de faire de la levée de doute quand une étudiante mythomane invente un blessé grave dans une évacuation de fac.
Et force est de constater que tout ça laisse à désirer : enregistreur un peu trop accessible, accès à distance non sécurisé, autorisation préfectorale inexistante ou non renouvelée, information incomplète des personnes… et surtout, implantation hasardeuse.
Ce n’est pas forcément l’exploitant qui est en cause, notez, mais plutôt le prestataire dont c’est supposé être le métier. On a donc au menu :
des caméras qui filment des postes de travail fixe, alors que c’est interdit ;
des caméras qui filment le parking mais aussi le jardin du voisin (grosse rigolade dans une usine où j’ai soi-disant fait découvrir aux agents de sécu que le joystick sert à bouger le dôme du coin du bâtiment et à zoomer : le PV contient une photo du voisin dans son canapé en train de se gratter le bide –un des plus beaux PV de ma carrière), la rue… C’est dommage, mais c’est comme ça : on peut filmer chez soi, mais pas l’espace public, et pas les domaines privés qui ne sont pas les nôtres.
c’est aussi valable pour la « vidéo-protection » : la Police ne doit pas filmer votre jardin, votre restaurant, votre hall d’immeuble. Je comprends que certains lieux leurs soient utiles, mais c’est la Loi. Pour ça, on demande l’application de masques : un gros carré gris ou de flou sur des zones de l’image.
le souci des masques, c’est que ça demande une revue régulière : avec le vent notamment, les petits crans de l’arbre qui fait tourner la caméra se décalent, et les masques sont placés par rapport à ce crantage. On observe donc souvent des masques décalés : ils masquent en partie une zone autorisée, mais laissent aussi visible une partie de zone interdite.
si la caméra a été implantée à un emplacement réfléchi, peu de masques sont nécessaires
si la caméra a été implantée « là ça a l’air bien » par un presta pas très pro, quand vous ajouterez un masque, la caméra perdra toute son utilité. Par exemple : votre caméra filme une rue, et on voit la vitrine et la porte d’un supermarché. Il faut un masque. Mais le masque est appliqué au niveau de la caméra, pas du magasin : toute personne passant sur le trottoir, dans la rue… sera couverte par le masque. Et la caméra ne vous sert plus qu’à regarder un immense rectangle gris. C’est cher du rectangle.
La CNIL contrôle tous les dispositifs vidéo. La vidéo-protection (espaces accessibles au public sans restriction : les rues, les gares, les supermarchés, tout ça) nécessite une autorisation préfectorale préalablement à la mise en service du dispositif (notamment parce qu’elle demande à fournir le schéma d’implantation : ce serait couillon de poser les caméras pour s’entendre dire qu’il faut les déplacer), et c’est la préfecture qui sanctionne en cas de manquements à la loi (informatique et liberté, mais surtout code de la sécurité intérieure [le CSI]). La vidéo-surveillance, elle (lieux privés, réserves de magasin, zones à accès restreint comme un club de sport sur abonnement…), se déclare directement à la CNIL, qui contrôle et sanctionne.
Postes nomades et ordiphones
(j’aime bien ce mot, « ordiphone » 😀 )
Des données personnelles en local, des identifiants permettant d’accéder aux données personnelles que vous traitez à distance, les clés de vos VPN et autres accès SSH, vos courriels… Tout ça, on le retrouve sur votre PC portable, et sur votre téléphone intelligent. Ce n’est pas fondamentalement un problème en soi. Mais si on le vole, si vous le perdez ?
La CNIL attend donc que les postes nomades (PC portables, en gros) et les tablettes/téléphones soient protégés : chiffrés, en gros. Idéalement, pas avec du BitLocker dégueu.
Vos smartphones doivent aussi disposer d’un écran de verrouillage, avec un schéma ou un PIN assez long. Une empreinte digitale fera le job aussi.
Pas d’excuses : tous les téléphones iOS/Android supportent le chiffrement, voire le sont déjà par défaut. Reste à mettre un code pour protéger l’accès au contenu.
Pour les ordinateurs, c’est un chouille plus complexe, mais pensez VeraCrypt, ou regardez du côté des solutions labellisées par l’ANSSI, comme CryHod (qui fonctionne très bien, d’ailleurs).
Le procès-verbal
Pour finir cet article, on va causer un petit peu du PV. Tout au long du contrôle, les agents de la CNIL notent ce qu’on leur dit (« sommes informés » : on peut revenir sur ce qu’on dit par la suite) et ce qu’ils voient (dont ils prennent copie, comme pièce ajoutée au PV : ce sont des « constatons », et là ce sont des preuves, pas simple de revenir dessus).
Il est contradictoire : la délégation le rédige, le relit, ça prend approximativement beaucoup trop de temps (chamailleries de juristes pour qui la position de la virgule change tout, qui voudraient réécrire la partie de l’informaticien, et puis parce qu’une phrase indirecte de moins de 300 mots n’est pas satisfaisante : on risquerait de comprendre à la première lecture) — sans rire, quand la délégation vous demande à s’isoler pour « relire le PV », comptez facilement 3 heures, en pratique je dirais même (selon le contrôle) 4-5 heures. La délégation imprime ensuite le PV : autonome, elle se balade avec une petite imprimante sur batterie et avec du papier.
Ensuite tout le monde de votre côté relit, discute, on se met d’accord, on reformule ce qui semble poser problème ou les erreurs de compréhension/transcription, on réimprime, tout le monde signe et repart content, tandis que le vigile qui fermait le bâtiment fait le pied de grue depuis 21h.
Et pour le mot de la fin : pensez à la délégation qui, à l’heure où elle sort, va devoir se contenter d’un Big Mac dégueu parce qu’il ne restera que les fast-food d’ouverts. L’expérience qui parle.
Vous voilà avec toutes les billes en votre possession : vous savez comment se passe un contrôle, ce qu’il faut faire/pas faire, et ce que la Commission vérifie dans un premier temps, sur un contrôle « classique » d’une journée.
Vous savez donc par où commencer votre mise en conformité, si c’est la sanction du RGPD qui vous fait peur. Bon courage !
Sur cette bonne blague d’introduction, on va causer cette fois de PIA. Article un peu long et pas forcément fun je vous l’accorde, mais nécessaire (on est quand même fin avril).
Les DPIA (Data Protection Impact Assessment), auparavant appelés PIA (Privacy Impact Assessment) ou ÉIVP par chez nous (Étude d’Impact sur la Vie Privée) sont une des nouveautés introduites par le RGPD. Décrivons un peu la bestiole, pour se préparer au jour fatidique où on vous demandera de réaliser ce genre d’étude.
Les PIA (on va garder cet acronyme, c’est le plus court, tout le monde sait qu’un bon informaticien est un informaticien fainéant, et même la CNIL dit « PIA » donc voilà, discutez pas) sont donc une partie intégrante du principe de Privacy by design posé par le RGPD.
Petit rappel au passage : on dit « LE RGPD ». Pas « la RGPD ». C’est un Règlement, avec un « R » majuscule et tout ce que ça comporte comme valeur légale. Pas juste une règlementation qui désignerait on ne sait pas quel genre de texte. Un Règlement, le truc de droit européen qui fait que nonobstant le fait que ledit règlement vous ennuie, il s’applique par sa simple existence. Et je veux encore moins entendre de « la GDPR ». Si j’entends ça, je vous assomme avec mon gros classeur rouge « Dispositions particulières de la Loi Informatique & Libertés » (et croyez-moi, vous ne voulez pas subir ça).
D’un point de vue entreprise (souvent et hélas le seul retenu), cette démarche permet de réduire drastiquement les risques associés, d’intégrer ces problématiques en amont et de réduire les coûts. Et, in fine, d’éviter certaines atteintes à son image, en cas de pépin.
Introduction
« Grosse maille » (je m’adapte : tout le monde dit ça sur Nantes alors que je n’ai jamais entendu ça à Troyes qui est pourtant, elle, la Cité de la maille), un PIA sert à identifier et réduire les risques associés à la vie privée sur un projet. L’aspect « nouveauté » réside dans le fait que pour la première fois, on se place du point de vue de l’utilisateur final. De la personne concernée par la perte potentielle de vie privée. C’est quand même nettement plus sain, dans la démarche, que de raisonner simplement sur le mode « faut pas que je perde de brouzoufs ».
Le PIA est bien souvent à utiliser en amont de la réalisation d’un projet, le but étant de faciliter la prise en compte des points soulevés par l’étude. Pour autant, il ne faut pas penser que parce que le projet existe déjà, il ne mérite pas une telle analyse : typiquement, si une entreprise envisage de changer de solution technique pour répondre à un besoin existant, cela peut être le bon moment pour conduire une telle étude. A condition, évidemment, que l’entreprise soit prête à intégrer les résultats. Mener un PIA pour ne rien en faire, ben… autant ne pas le faire tout court. Se donner bonne conscience, à un moment, ça ne suffit plus.
Donc, le PIA prend en compte ces deux visions souvent opposées : l’intérêt des personnes (en particulier sur la protection de leur vie privée), et l’intérêt de l’entreprise (risques de perte de confidentialité réduits pour les utilisateurs, donc moins de risque de perte financière ou d’image pour elle). Gagnant-gagnant. Et évidemment, un projet qui traite davantage de données personnelles, voire de données sensibles (santé par exemple), sera probablement associé à un risque de perte de confidentialité plus élevé.
Mener une étude d’impact sur la vie privée n’est pas nécessairement une tâche longue et complexe : il faut « simplement » adopter une rigueur méthodologique proportionnelle aux risques découverts au fur et à mesure de son avancée.
Un PIA, c’est un processus qui vous permet d’identifier et de réduire les risques relatifs à la vie privée pour vos projets.
Mener une étude PIA implique de travailler avec des personnes de plusieurs entités au sein de votre organisation, avec des partenaires/prestataires, et également avec les personnes concernées par le traitement.
Le PIA permet également de s’assurer que les problèmes potentiels sont identifiés tôt dans le cycle de vie du projet : souvent, traiter ces risques de bonne heure est plus facile et surtout moins coûteux !
La démarche PIA est bénéfique pour tout le monde, mais notamment pour votre entreprise : vous produirez des systèmes de plus grande qualité, et vous renforcerez votre relation (de confiance, notamment) avec vos usagers, clients…
Un PIA, oui, mais pour quels projets ?
La méthodologie PIA « officielle » parle de… projets. Au sens large. Du coup, les cas de figures sont nombreux :
nouveau projet info qui va permettre de stocker ou d’accéder à des données personnelles ;
un entrepôt de données ou plusieurs (ça commence à 2, « plusieurs », hein) entités/entreprises/organisations vont partager, croiser… plusieurs jeux de données personnelles ;
une nouvelle base de données qui va réunir des jeux de données auparavant séparés ;
utilisation de données existantes, mais pour une nouvelle finalité, ou pour la même que celle initialement définie, mais de façon plus intrusive ;
nouveau système de surveillance (vidéo-protection, vidéosurveillance, LAPI… et j’en passe) ou évolution d’un système de surveillance existant (typiquement, ajouter la LAPI ou la détection de mouvement de foule à un système de caméras existant)
…
L’idée, c’est d’appliquer la démarche PIA à des projets spécifiques et identifiés, et idéalement à un stade d’avancement du projet qui permet de prendre en compte ce que vous aurez identifié. Le but, c’est d’agir, pas de se dire « j’ai identifié un risque mais bon je peux pas toucher au système ».
C’est à votre entreprise de décider de qui sera le plus à même de mener telle ou telle étude PIA, et ce n’est pas forcément le DPO, quand bien même il dispose d’une position souvent idéale pour se charger de ces études (ou du moins y tenir un rôle important). Mais bon, toutes les entreprises n’ont (n’auront) pas de Délégué à la Protection des Données. Et selon la structure, un seul DPO n’aura matériellement pas le temps de mener 4, 10, 35… PIA en parallèle.
Je suis en charge des PIA, komankechfè ?
Le PIA est un processus « flexible » tout à fait apte à être intégré dans votre process de management de projet (et/ou de gestion du risque) habituel. Le temps et les ressources nécessaires sont à adapter au projet étudié.
Un PIA doit débuter très tôt dans le cycle de vie du projet, mais peut/doit suivre le projet tout au long de ses évolutions.
Les principales étapes d’un PIA sont :
identifier si une étude PIA est nécessaire ;
lister et décrire les flux d’informations ;
identifier les risques liés à la vie privée ;
identifier et évaluer les solutions potentielles ;
consigner le résultats de l’étude PIA ;
intégrer ces résultats dans le développement du projet ;
consulter les différentes parties-prenantes tout au long de l’étude.
Le plus grand bénéfice que vous puissiez retirer de la mise en place au sein de votre entreprise de la démarche PIA, c’est… de créer votre propre process, et pas d’utiliser l’outil tout préparé de la CNIL, pratique pour les TPE/PME (notamment parce qu’il contient une base partiellement pré-remplie couvrant quelques cas de figure), pas du tout pensé pour les grandes entreprises comme j’ai pu le constater au cours de mes pérégrinations protection-des-données-personellesques, notamment chez SNCF. Plus exactement il peut servir de support, à condition de créer un modèle personnalisé.
Les guides sont suffisants, et les utiliser pour élaborer une méthodologie maîtrisée, adaptée, et surtout que l’on comprend totalement, c’est bien mieux. L’idéal aurait été de s’y prendre plus tôt, et j’imagine que si vous lisez cet article début mai 2018 (publication initiale) c’est que vous n’êtes pas forcément prêts.
Donc, déroulons ensemble les points-clé cités plus haut.
Identifier si un PIA est nécessaire
Il s’agit de répondre à des questions génériques, pour déterminer si votre projet présente un risque potentiel quant à la vie privée des personnes concernées. Si un risque est identifié comme important, alors hop, on continue. Pour ça, jetez un œil à l’outil PIA de la CNIL dont on parlait, il est bien fichu.
Décrire les flux d’informations
Maintenant, l’idée est de comprendre comment est collectée l’information, qui l’utilise, la transfère, la stocke…
C’est souvent là qu’on se rend compte de transferts possibles mais non-prévus, d’utilisations détournées des données… que du bon, en somme.
Les utilisations futures des données collectées doivent être envisagées (pis ça évitera de devoir repartir de zéro à la prochaine évolution).
Si vous avez déjà des rapports d’audit interne, une cartographie des traitements, un DAT/DAL pour votre traitement… C’est là que ça va se révéler utile !
Identifier les risques
Le risque est surtout à apprécier du point de vue de l’individu. L’intrusion dans la vie privée est absolument à prendre en compte. Évidemment, cela ne veut pas dire qu’il faut oublier l’aspect entreprise : atteinte à l’image, sanction pécuniaire, pénales… sont bien dans le scope du PIA.
Les risques identifiés doivent être clairement listés.
Attention avec les identifiants uniques parfois collectés même si l’utilisateur ne fournit pas « activement » de données. Typiquement, les adresses IP, les adresses matérielles des cartes réseau (y compris de vos téléphones), les numéros IMEI… sont identifiantes, et on ne joue pas avec comme on a le nez fait.
Identifier et choisir des solutions
Identifier un risque c’est bien, mais le traiter c’est tout de même mieux. On cherche évidemment à réduire les risques identifiés précédemment. Le pied, ce serait un risque qui disparaît, bien sûr, mais on peut aussi parfois se contenter d’un risque accepté, parce qu’on ne peut pas le réduire davantage, ou parce qu’on choisit de ne pas le réduire (ça arrive, souvent pour des raisons de coûts).
Pour chaque solution, évaluez le rapport coûts/bénéfices, comparez-le à l’effet produit sur le risque et aux éventuels effets de bord sur le reste du projet étudié.
Il faut apporter des solutions à chaque risque identifié, jusqu’à ce que vous soyez « satisfait » du risque global résiduel en ce qui touche à la vie privée des personnes.
Quelques solutions que j’ai pu voir retenues dans plusieurs entreprises :
ne pas collecter (ou stocker) certains types de données (notamment les identifiants supposés uniques comme les IMEI des téléphones portables) ;
revoir les délais de conservation des données à la baisse, prévoir un mécanisme de purge efficace ;
implémenter des mesures de sécurité adaptées ;
s’assurer que le personnel est sensibilisé aux enjeux de sécurité / vie privée ;
développer un processus d’anonymisation robuste (j’insiste sur le *robuste*, c’est réellement compliqué. J’ai beaucoup bossé dessus –mes apprenants de la formation DU DPO de l’UTT en sont témoins, désolé pour eux– et ça pourrait faire l’objet d’un article dédié, mais j’ai cru comprendre quand je parlais de cryptographie que vous n’étiez pas forcément des matheux) ;
produire des guides, une documentation, pour les utilisateurs : on pourrait y aborder l’envoi de documents à des tiers (données, mots de passe… oui, je vois souvent des données personnelles dans un zip sur WeTransfer, oui je vois souvent des mots de passe être envoyé par mail en clair…) ;
concevoir les systèmes de façon à ce que les individus puissent exercer leurs droits (accès, rectification…) simplement et par eux-mêmes : ça vous évitera de nombreuses demandes à traiter !
informer correctement les individus (détail, simplicité) ;
s’assurer que les sous-traitants présentent des garanties suffisantes quant à la sécurité des données qu’ils pourraient traiter, héberger…
Résultats de l’étude PIA
Une fois l’étude menée à terme, listez ce qui a été identifié, ce qui a été fait, et ce qu’il « reste ». Chaque mesure a dû être validée par tel ou tel référent/responsable/marketeux digital : formalisez tout ça, hop, une petite signature en face valant « conformité » et on passe à la suite.
Idéalement, produisez un petit rapport à propos de cette étude, et si vous jugez cela opportun (pour une application destinée au grand public par exemple), publiez ce dernier. Les utilisateurs aiment bien la transparence, quand il s’agit réellement de décrire les engrenages dans lesquels passent leurs données (donc, pas comme chez Facebook qui empapaoute de plus en plus les gens sous couvert de « on fait des efforts t’as vu »).
Prendre en compte les résultats
C’est un peu une redite, mais bon : s’assurer que les points soulevés par le PIA sont traités, c’est important. Et ne pas oublier le PIA dans un tiroir, idem : il doit suivre le projet sur tout son cycle de vie, et être actualisé si nécessaire.
Un process consultatif
La consultation, c’est un concept clé dans le PIA. C’est ce qui permet aux parties prenantes de soulever des problématiques touchant à la vie privée, aux données personnelles, en fonction de leurs propres points de vue et domaines d’expertise.
Se réunir autour d’une table (ou d’une visio, soyons fous), ça se fait autant de fois que souhaité, à toutes les étapes du PIA.
La consultation est à la fois interne (histoire de s’assurer que toutes les perspectives et enjeux sont pris en compte, et qu’on n’oublie rien) et externe (auprès des personnes concernées par le traitement).
Quelques ressources
On ne va pas réinventer la roue. Vous avez maintenant je l’espère une vue un peu plus claire de ce qu’implique un PIA, en terme de « to-do list » et de charge de travail (ça, ce n’est pas moi qui peut l’estimer, mais vous, qui connaissez vos traitements).
Pour autant, s’il y a quelques ressources à réutiliser, ce sont bien les guides de la CNIL, et en particulier le guide numéro 3, « bases de connaissance » (qui sont reprises dans le petit logiciel). Vous y trouverez une liste assez fournie de mesures à vérifier, classées par thèmes (typologies de données à caractère personnel, anonymisation, chiffrement…), et de solutions génériques.
J’insiste *vraiment* sur l’aspect générique. Le lien n’est pas forcément fait entre ce qui est décrit et d’éventuelles instructions « strictes » de configuration. Par exemple, dans le cadre du chiffrement des disques durs, la CNIL cite VeraCrypt, mais ne décrit ni le fonctionnement, ni le paramétrage recommandé. Idem, pour ce qui est de forcer HTTPS sur le parcours de vente ou de collecte/utilisation de données personnelles, la recommandation est « utiliser un certificat RGS » et « utiliser TLS, et non SSL ». Ce n’est pas suffisant, et il vous faudra fouiner dans la littérature pour trouver une configuration qui va bien. Le cas échéant, je peux aussi fournir des ressources.
C’est dommage, notamment parce que les lignes directrices à respecter sont globalement connues : les contrôleurs de la CNIL savent très bien le niveau réellement attendu, qui est loin d’être aussi binaire que « SSL c’est pas bien et TLS c’est OK ».
Et j’insiste également sur le fait que ces bases, aussi fournies soient-elles, ne doivent en aucun cas être vues comme complètes ! Si un item est manquant par rapport à votre étude, ce n’est pas qu’il n’est pas à prendre en compte, c’est qu’il est à ajouter. Et je dis ça parce que je l’ai constaté…
Le guide numéro 2, les modèles, peut aussi être une source d’inspiration bien utile, puisque vous y trouverez des exemples (là aussi, très génériques) de tableaux, de questions à poser, de points à vérifier/décrire pour vos PIA.
Vous voilà donc à peu près équipés pour mener votre première étude PIA. Je vous souhaite bon courage dans la dernière ligne droite avant le 25 mai, « force et honneur », et on reparle de tout ça très vite !










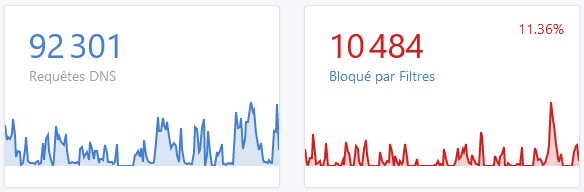


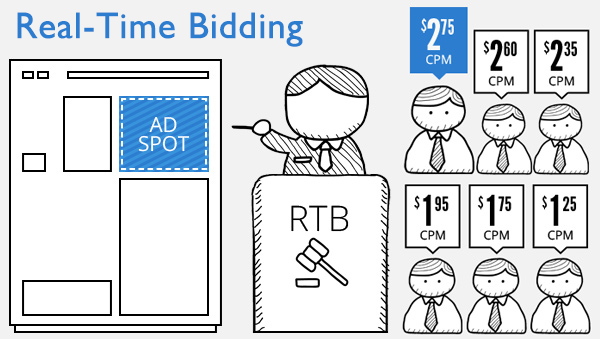
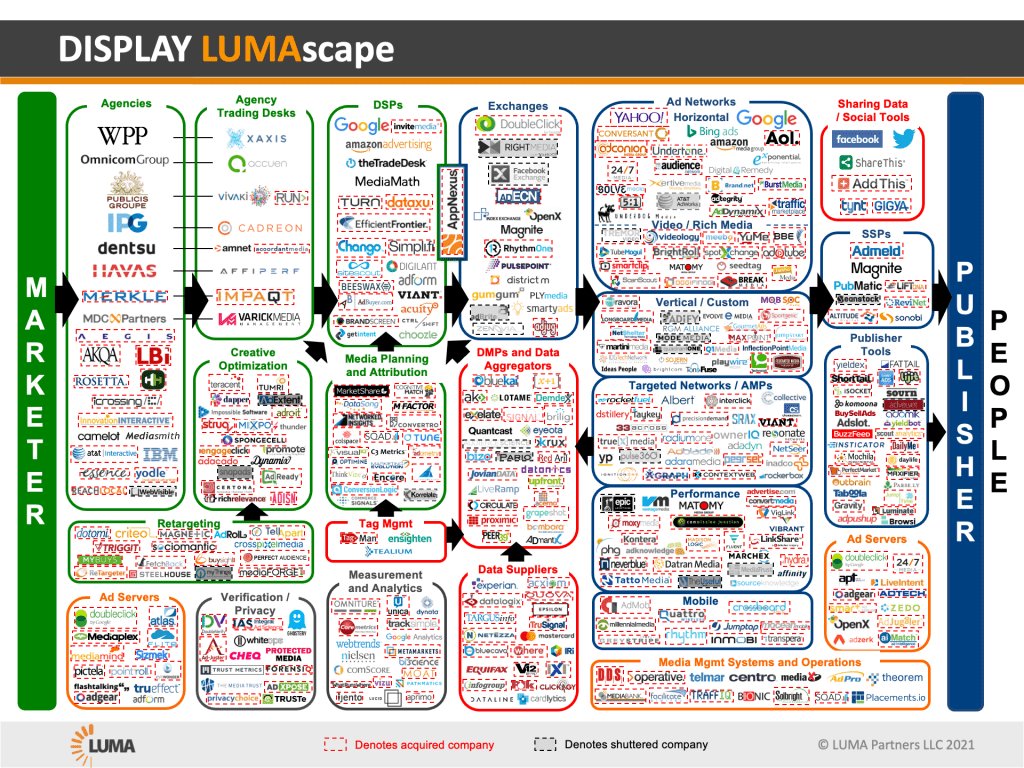





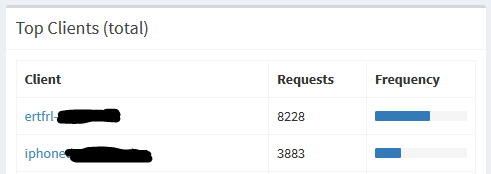














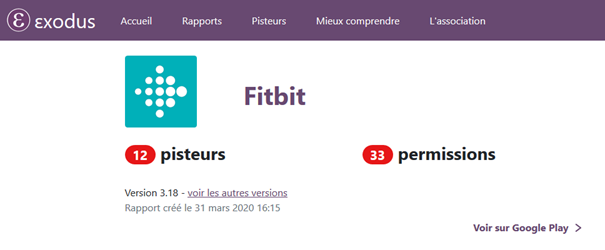





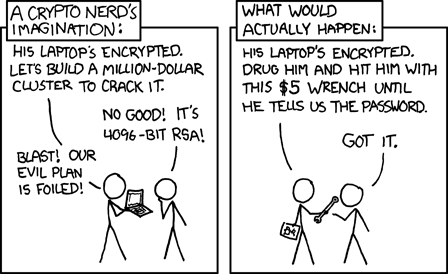


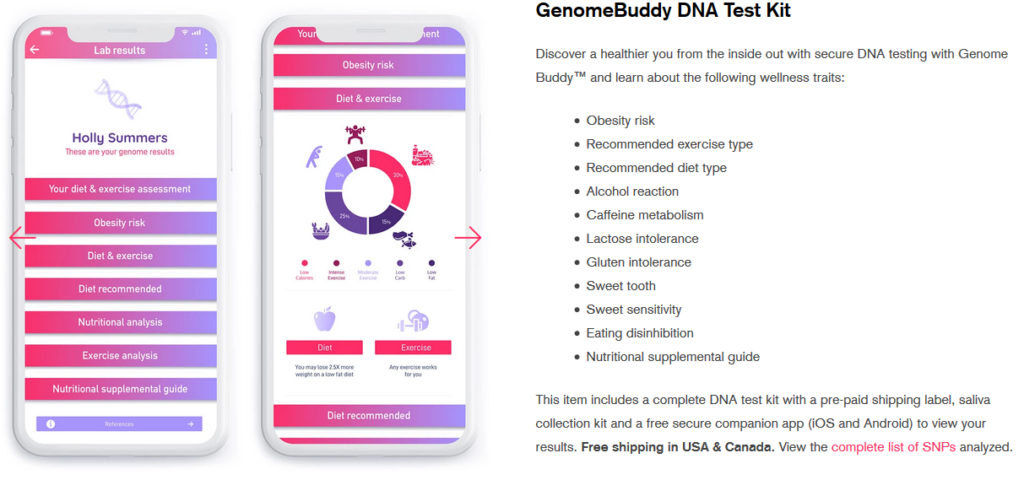










![[MàJ] Nextcloud 12 à 15 sur un mutualisé OVH](https://open-freax.fr/content/images/wordpress/2017/09/Capture-1024x329.png)
![[MàJ] Nextcloud 12 à 15 sur un mutualisé OVH](https://open-freax.fr/wp-content/uploads/2017/09/totp1.png)
![[MàJ] Nextcloud 12 à 15 sur un mutualisé OVH](https://open-freax.fr/wp-content/uploads/2017/09/Screenshot_20170912-094524.png)