Quid de la sécurité du rôle Windows Deployment Services – WDS ?
Note liminaire : Depuis le temps que je n’avais pas pondu un article sur ce blog, je suis très heureux de faire paraître enfin celui-ci. Un grand merci à tous ceux qui continuent à s’abonner et à visiter le site malgré le fait que je publie moins que les années passées, du fait de mes différents projets pro (et perso).
Rappel : L’article qui va suivre contient des techniques et méthodes qui peuvent s’avérer être illégales et dangereuses si elles sont utilisées à mauvais escient. Ce tutoriel ne doit en aucun cas être utilisé contre un particulier, une entreprise, une organisation à but non lucratif ou une administration publique de quelconque pays. Je me dédouane de toute responsabilité en cas de problèmes ou d’incidents de quelque nature que ce soit après le visionnage de cet article.
I. Introduction
Le rôle WDS (Windows Deployment Services) est une fonctionnalité clé de l’écosystème Windows Server, encore largement utilisée par de nombreuses entreprises pour déployer des systèmes d’exploitation sur des postes de travail ou des serveurs. Bien qu’il ne rivalise pas avec des solutions plus complètes (payante) comme MECM, ex SCCM, il reste très répandu, notamment car il peut s’interfacer avec MDT*. Il permet de simplifier, d’automatiser et de suivre les déploiements. Cependant, mal configuré ou insuffisamment protégé, le rôle WDS peut constituer une porte d’entrée pour un attaquant, qui pourrait s’en servir pour progresser au sein du réseau.
* MDT (Microsoft Deployment Toolkit) est un outil gratuit proposé par Microsoft, qui permet de créer des séquences de tâches personnalisées pour automatiser les déploiements de systèmes d’exploitation. Il vient enrichir WDS avec de nombreuses fonctionnalités sans surcoût.
Cet article examine donc la sécurité du rôle WDS en explorant les principales menaces auxquelles il est confronté, ainsi que des recommandations pour renforcer sa sécurité.
Avant toute chose, voici un petit récap afin d’éviter de vous mélanger entre les différents termes et acronymes qui vont être abordés tout au long de l’article.
II. Rappels : WDS vs MDT vs MECM ?
- WDS est principalement utilisé pour déployer des « images systèmes » / master à travers un réseau local. Il est simple à configurer mais reste limité, car il se concentre uniquement sur l’installation d’images. MDT, en revanche, va plus loin en permettant l’automatisation et la personnalisation des images elles-mêmes grâce à des séquences de tâches (installation de logiciels, scripts, etc.), mais il demande une configuration plus complexe. Si vous souhaitez en savoir plus sur le fonctionnement de MDT et WDS, je vous recommande cet article.
Pour mettre en place un lab complet et tester les points abordés ci-dessous, voici une collection d’articles issus de (l’excellent) site it-connect !
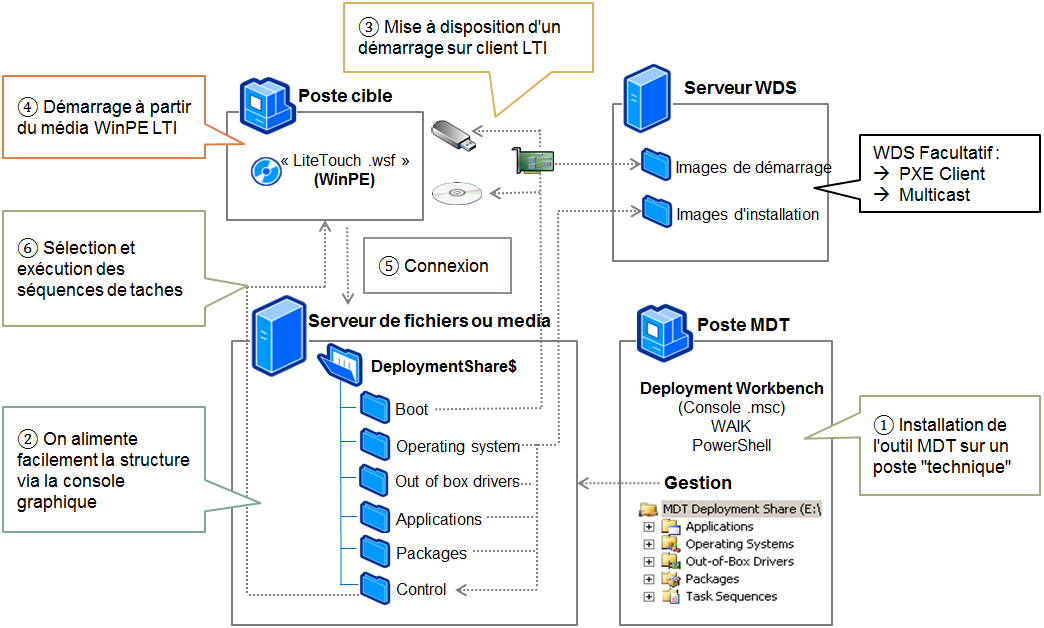
Processus détaillés du déploiement d’un OS via « PXE » avec WDS et MDT – source
Méconnu dans le monde de la sécurité offensive imho, les serveurs de déploiement sont pourtant une source d’informations importante pour un attaquant (légitime ou non). Ci-dessous, je vous présente les différentes approches pour que vous soyez en mesure de détecter un service WDS sur le réseau lors de votre audit (uniquement :))
III. D’un point de vu attaquant, qu’est-ce qu’on peut faire ?
A. Comment détecter un service WDS sur le réseau ?
Il y a plusieurs manières d’identifier si un service WDS fonctionne sur le réseau.
- Sans identifiant : Essayer de booter sur le réseau avec un PC ou une VM « bridgé » sur la carte réseau utilisé. (Ceci est valable uniquement si le réseau n’est pas ou mal segmenté.)
- Avec des identifiants du domaine Active Directory valides : Consulter le partage réseau SMB associé au rôle WDS en recherchant le nom du partage réseau ou sa description « générique » (Ils ne sont pas customizable !) :
- Nom du partage réseau : REMINST
- Description du partage réseau SMB : Windows Deployment Services Share
B. Sans identifiant valide – « Press F12 for loot »
Rappel du prérequis : Évoluer dans un réseau d’entreprise sans/peu de cloisonnement (ce qui existe encore ^) ou être dans un VLAN d’administration où il est possible d’atteindre le serveur de déploiement PXE.
1. Préparer votre machine
- Assurez-vous que le poste physique ou la machine virtuelle (VM) est configuré pour être connecté au réseau local en question.
- Pour un poste physique, cela implique une connexion via un câble Ethernet branché sur le réseau cible.
- Pour une VM, configurez la carte réseau en mode « bridged » (ponté), ce qui permet à la VM d’accéder au réseau comme si elle était un appareil physique sur le réseau local.
2. Accéder au « boot PXE* »
- Redémarrez votre poste ou initialisez la machine virtuelle.
- Pendant la phase de démarrage, appuyez sur la touche pour « démarrer en mode PXE » (La touche varie selon les fabricants de matériel, mais F12 est une des plus courantes pour initier un déploiement PXE.)
Pour rappel, le PXE* (Preboot Execution Environment) est un protocole processus de démarrage réseau qui permet à un ordinateur de démarrer et « charger » un OS au travers du réseau, sans support de stockage local comme un disque dur ou une clé USB. Lors d’un démarrage PXE, la machine utilise mon microsologiciel (BIOS, EFI, UEFI**) pour réaliser cette tâche.
*PXE n’est pas un protocole à proprement parler, mais plutôt un ensemble de spécifications qui permet à un ordinateur de démarrer (boot) via le réseau.
Concrètement, PXE « chapotes » les deux protocoles réseaux :
- DHCP : pour obtenir une adresse IP et localiser le serveur de déploiement.
- TFTP : pour télécharger les fichiers nécessaires au démarrage. (fichier au format .wim)
Plus bas, deux schémas vous permettent de visualiser plus en détail comment cela fonctionne.
Et oui, je sais, encore une note… ^^, mais je trouve important de détailler la différence entre les trois termes suivants, car leur distinction est souvent méconnue, elle aussi.
**BIOS, EFI, UEFI : Ce sont trois types de firmware (en français : micrologiciel) utilisés pour démarrer un ordinateur et « charger » un système d’exploitation.
- BIOS : ancien (1980-2010) et limité, fonctionne en mode 16 bits avec une interface textuelle simple. Il ne prend en charge que des disques jusqu’à 2 To via le schéma MBR, ce qui limite la capacité de stockage et les fonctionnalités modernes.
- EFI : apparu vers 2002 pour moderniser le BIOS, introduit un mode 32 ou 64 bits, des interfaces graphiques plus évoluées, ainsi que le support du partitionnement GPT, permettant de dépasser la limite des 2 To et d’améliorer la gestion des disques.
- UEFI : standardisé vers 2005 comme successeur de l’EFI, apporte des fonctionnalités avancées telles que le Secure Boot pour renforcer la sécurité au démarrage, une meilleure modularité et une compatibilité étendue avec les systèmes d’exploitation modernes. C’est désormais la norme sur la majorité des machines actuelles.
Pour aller plus loin : Quelle est la différence entre le format GPT et MBR pour un disque dur ?
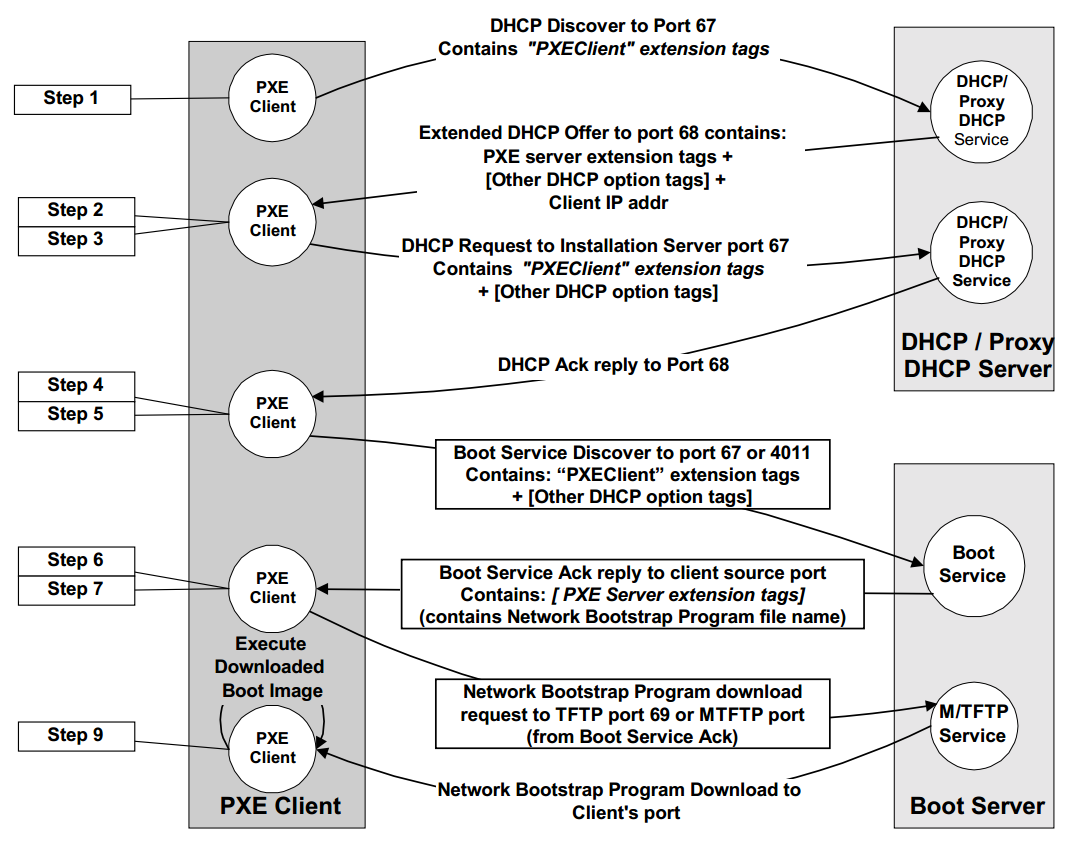

3. Network boot
- Une fois dans le menu de démarrage, sélectionnez l’option correspondante au démarrage réseau, généralement intitulée « Network Boot », « PXE Boot ».
- Cette action déclenche une requête au serveur DHCP du réseau pour obtenir une adresse IP ainsi que les informations nécessaires pour localiser le serveur de déploiement.
WDS permet de diffuser sur le réseau deux types d’images essentiels au déploiement d’un système Windows :
- Une image de démarrage
boot.wim, basée sur WinPE (Windows Preinstallation Environment), qui fournit un environnement (OS) minimal pour initier le processus de déploiement. - Une image d’installation
install.wim, contenant l’ensemble des fichiers nécessaires à l’installation du système d’exploitation.
WinPE permet d’effectuer des tâches initiales comme :
- L’établissement de la connexion réseau pour accéder dans un second temps à l’image
install.wim.
- La détection des périphériques et des disques et le chargement des pilotes nécessaires.
Une fois l’image de démarrage correctement chargée, vous arrivez sur l’interface WinPE. Il est alors possible d’ouvrir une invite de commande en appuyant sur la touche F8.
Pourquoi est-ce utile ? Cela permet d’explorer les fichiers contenus dans boot.wim « à chaud ».
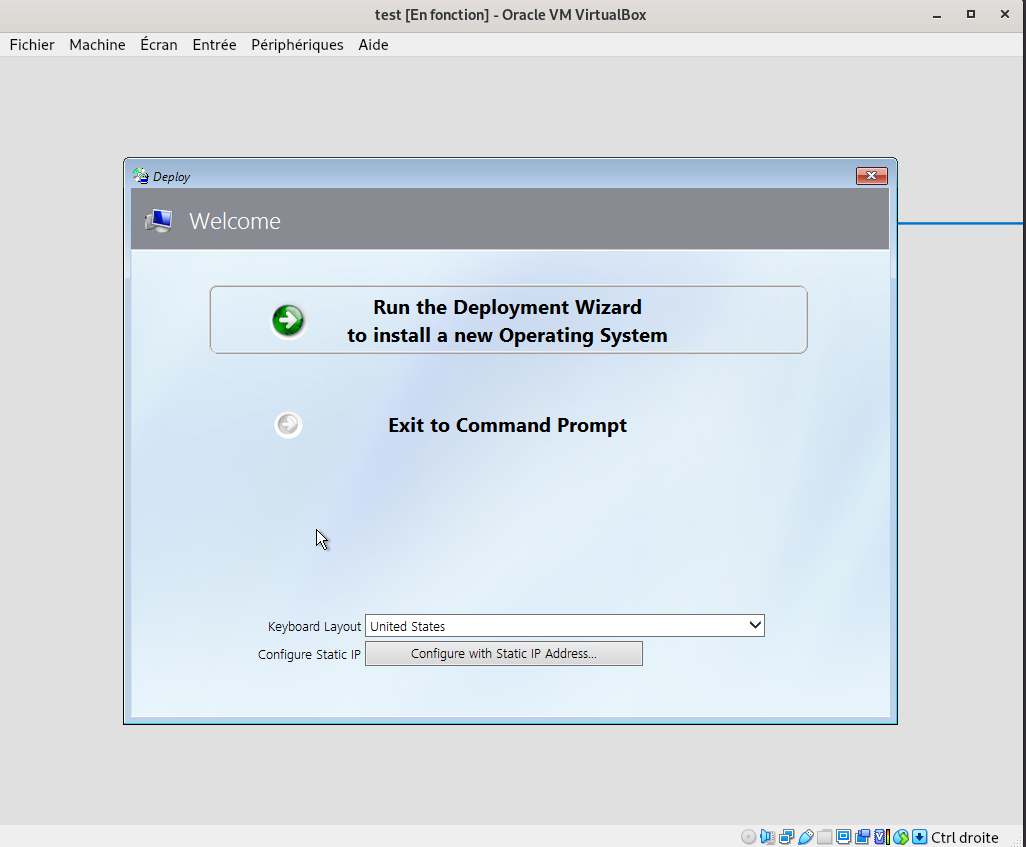
En explorant les fichiers de ce « mini » système d’exploitation, on remarque la présence d’un dossier nommé Deploy (ou d’un nom équivalent) à la racine du système de fichiers. Ce dossier contient principalement des éléments de configuration, notamment des fichiers qui permettent de personnaliser le futur système d’exploitation en fonction des règles définies dans le master de déploiement.
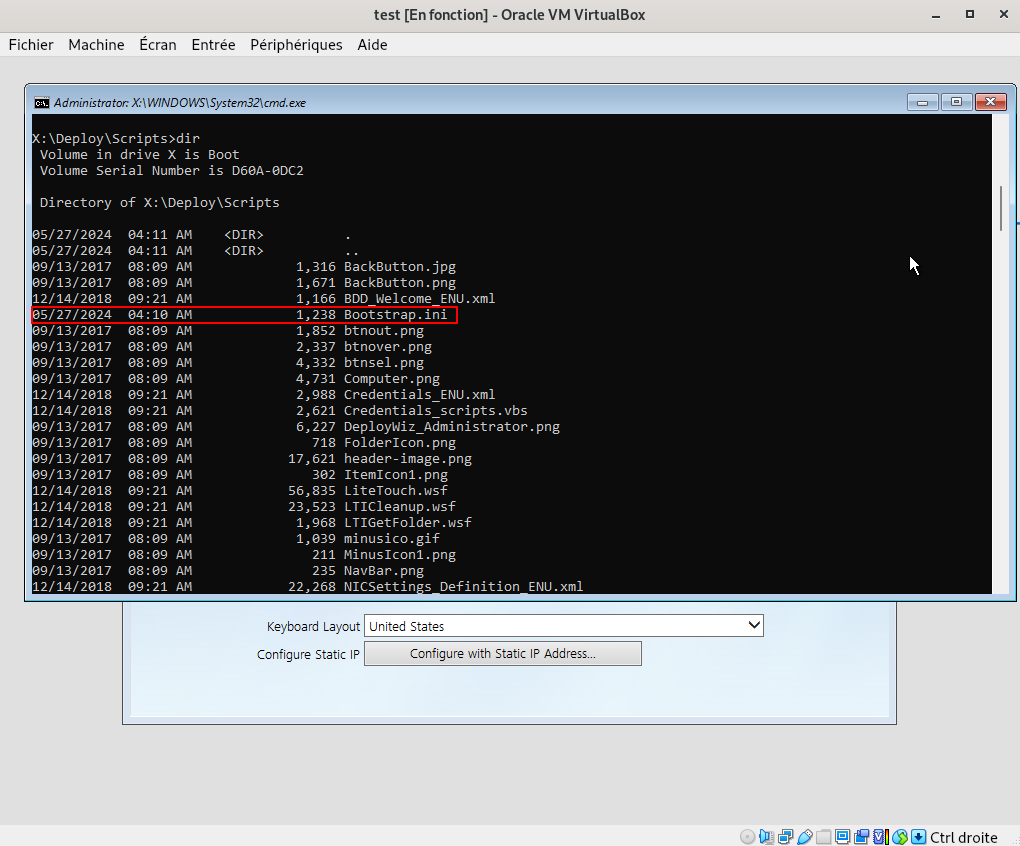
Un des fichiers de configuration utilisés par MDT est le fameux Bootstrap.ini. Ce fichier joue un rôle crucial dans le démarrage du processus de déploiement. Il contient des paramètres de configuration qui permettent de définir les éléments nécessaires pour établir la connexion initiale entre le client et le serveur de déploiement.
On y trouve très souvent des identifiants de connexion : un compte du domaine Active Directory permettant d’auto-enrôler l’ordinateur au sein de l’AD. C’est cette information qui va fortement intéresser un attaquant, car ce compte est malheureusement encore trop souvent un compte à fort privilège (et même parfois administrateur du domaine… SANS COMMENTAIRE).
more Boostrap.iniEn examinant ce fichier de configuration utilisé par MDT, on constate qu’il peut contenir un compte Active Directory ainsi qu’un mot de passe en clair. Ces informations sont intégrées afin d’automatiser le processus de déploiement et l’enrôlement des machines dans l’Active Directory. Toutefois, cette méthode implique de stocker des identifiants sensibles en clair dans un fichier accessible à toute machine capable de démarrer sur l’image de déploiement, qu’elle soit légitime ou non. À ce jour, il n’existe aucune solution officielle permettant de chiffrer ces identifiants dans le cadre de MDT, ce qui en fait un point de faiblesse connu, mais encore souvent ignoré. (source)
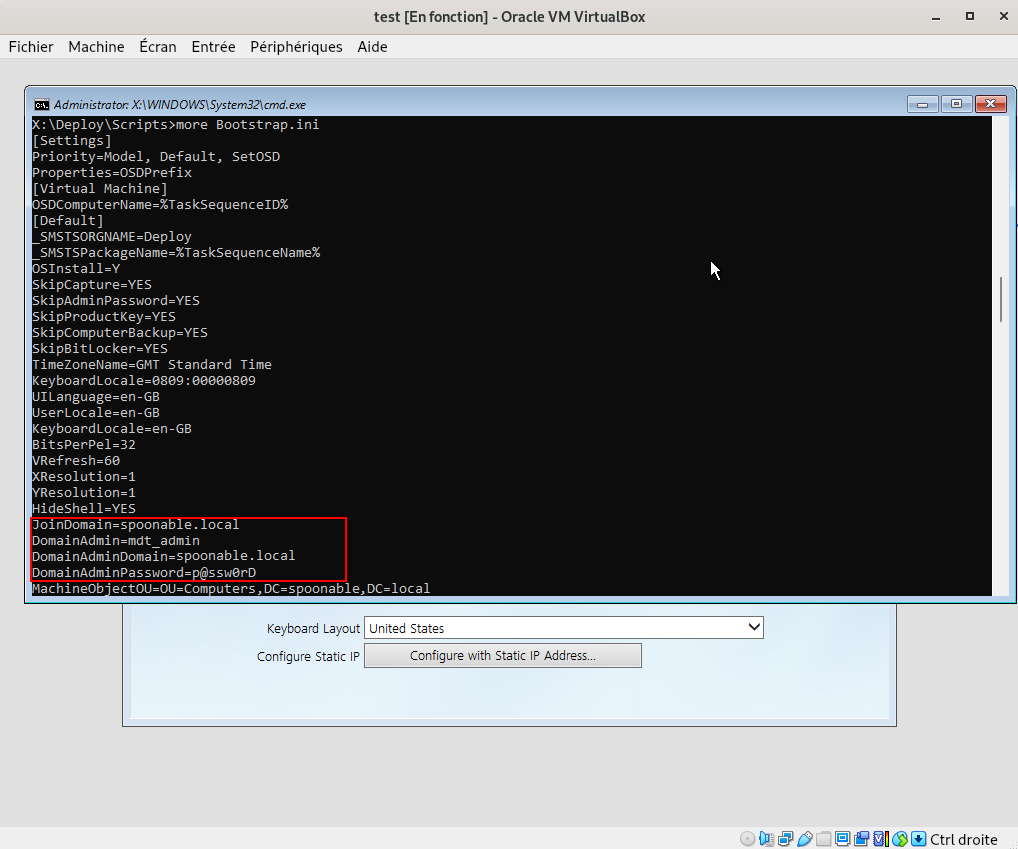
Note : La variable
DomainAdmindans MDT peut prêter à confusion : malgré son nom, elle ne désigne pas nécessairement un administrateur du domaine. Elle doit simplement contenir un compte disposant des droits suffisants pour joindre un poste à Active Directory. Il est donc recommandé d’utiliser un compte dédié avec des privilèges strictement limités à cette tâche. Pourtant, de nombreux tutoriels en ligne préconisent l’usage de comptes à privilèges élevés, voire d’un administrateur du domaine… ce qui accroît considérablement les risques de compromission du domaine ou de mouvements latéraux en cas d’incident.
Pour vérifier la possibilité de connexion et, surtout, si ces identifiants sont encore valides (car ils peuvent avoir été désactivés si le serveur WDS de déploiement n’est plus utilisé), il suffit de tester l’accès via SMB, LDAP ou RDP à l’aide d’un outil comme NetExec.
nxc smb $DC_IP -u 'admin_mdt' -p '@dm1n_mdt'C. Avec des identifiants valide : Comment trouver le partage réseau utilisé par le rôle WDS
Avec des identifiants valides, il devient possible d’accéder au partage réseau SMB REMINST utilisé par le rôle WDS, et ainsi de récupérer les mêmes fichiers que ceux transmis à une machine lors de la phase de déploiement via l’image boot.wim (WinPE). Ce scénario reste d’autant plus plausible qu’en 2025, même si le cloisonnement réseau tend à se généraliser au sein des entreprises ces dernières années… quoi que 
Pour procéder, commencez par énumérer tous les objets ordinateurs Windows enrôlés dans l’Active Directory (cela peut être fait avec BloodHound ou encore avec ldapsearch (un compte utilisateur standard suffit)).
Ensuite, effectuez une recherche rapide (Ctrl + Maj +F pour un terminal standard) dans les résultats à l’aide du terme « REMINST » pour repérer facilement le(s) partage(s) concerné(s). Par exemple, avec l’outil NetExec, la commande suivante permet d’énumérer les partages :
nxc smb computers.txt -u $USER -p $PASSWORD --sharesHistoriquement, sur les anciennes versions de Windows Server, l’accès au partage
REMINSTse faisait parfois sans authentification, ce qui facilitait le processus PXE mais exposait potentiellement le serveur à des accès non autorisés. D’un point de vue attaquant, cela permettait de passer d’une approche « black box » à une « gray box ». Depuis Windows Server 2016, les configurations par défaut restreignent ces accès anonymes en exigeant une authentification. Toutefois, si les partages invités ou les « null sessions » sont toujours activés, un attaquant peut encore identifier et accéder au partage sans disposer d’un compte valide dans le domaine. (source)
Cette méthode est très bruyante et risque fortement de déclencher de nombreuses alertes réseau si un système de surveillance est en place (XDR…). Toutefois, elle permet, lors d’un pentest, de vérifier facilement l’existence de ce partage réseau, contrairement à une approche Red Team où la discrétion et la furtivité sont prioritaires.

Une fois que l’on repère un partage nommé REMINST avec la description Windows Deployment Services shares, il convient d’utiliser SMB pour y accéder. Comme vous pouvez le constater, par défaut, l’utilisateur que je possède dispose bien des droits de lecture (READ) sur ce partage.
Pour cela, vous pouver utiliser une machine windows, ou bien passer par un outil en ligne de commande comme smbclient-ng.
mkdir REMINST_DUMP && cd REMINST_DUMP
smbng -d "$DOMAIN" -u "$USER" -p "$PASSWORD" --host "$WDS_TARGET_IP"Une fois connecté à la racine du partage SMB, il faut indiquer à smbclient-ng (ou smbng) le partage spécifique que l’on souhaite consulter en le sélectionnant explicitement.
use REMINST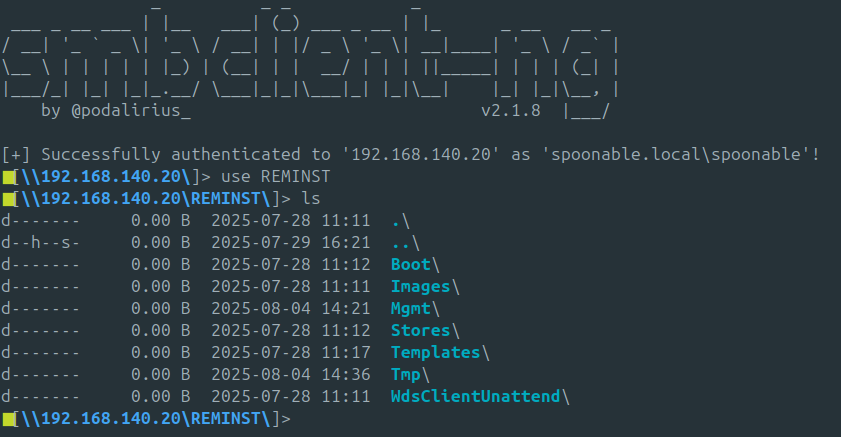
Deux cas de figure peuvent se présenter : soit des scripts d’administration comme Bootstrap.ini, CustomSettings.ini ou Unattend.xml sont encore présents ; soit, si les administrateurs réseau ont correctement nettoyé le répertoire, vous ne trouverez rien, ou presque… C’est d’ailleurs une situation que j’ai rencontrée récemment lors d’un audit : aucun de ces scripts n’était encore présent, car les administrateurs les avaient supprimés. En revanche, les images master restaient accessibles, alors même que le service WDS n’était plus utilisé depuis un certain temps — et l’utilisateur référencé dans Bootstrap.ini était encore actif.
Pour vous en assurer, vous pouvez par exemple télécharger l’ensemble du contenu de ce répertoire afin de l’analyser ultérieurement (comme un bourrin ^^). On constate qu’au sein des fichiers récupérés, il est possible d’obtenir une image WinPE nommée LiteTouchPE_x64.wim. Cette image, qui constitue un environnement WinPE, est chargée de mettre en place l’environnement de préexécution destiné à accueillir le futur système.

Comme le format de l’image est un fichier .wim, il est possible de l’explorer à l’aide d’un outil de décompression comme 7-Zip, qui prend en charge ce type de fichier. En effet, un fichier .wim (Windows Imaging Format) est un format développé par Microsoft permettant de stocker une ou plusieurs images de système d’exploitation dans un seul conteneur. Il fonctionne de manière similaire à une archive, ce qui permet d’en parcourir le contenu sans avoir à le monter ni l’exécuter.
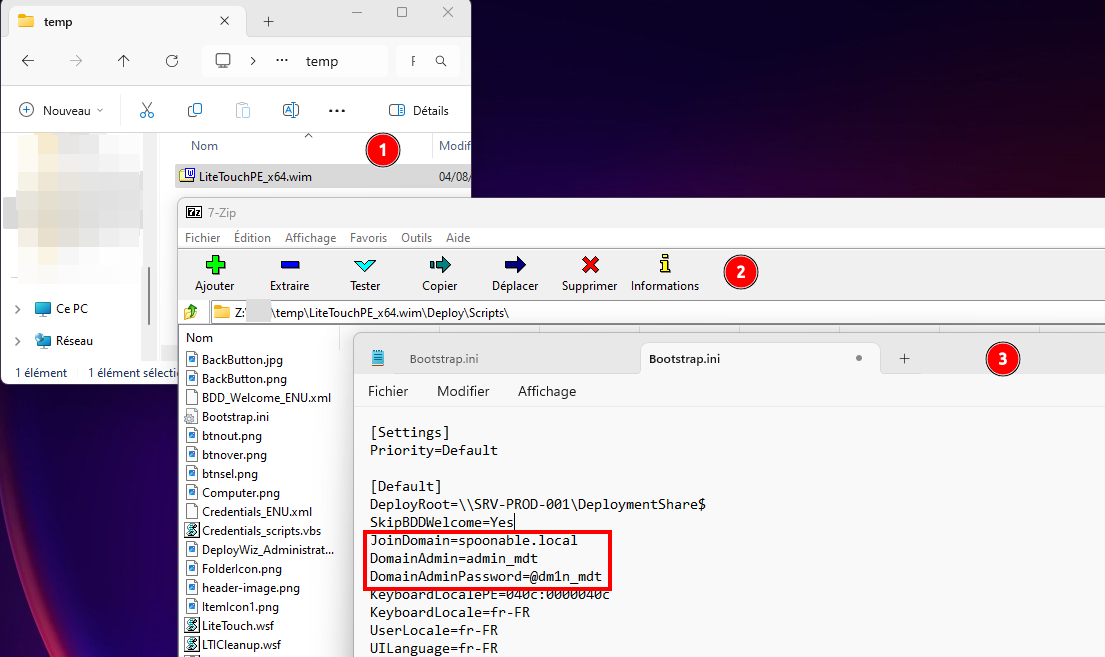
Il ne vous reste plus qu’à tester si les identifiants sont bien valides sur le domaine.
nxc smb $DC -u 'admin_mdt' -p '@dm1n_mdt'
Si la réponse est oui, alors il sera très pertinent de vérifier le niveau des droits de cet utilisateur fraîchement « pwned ».
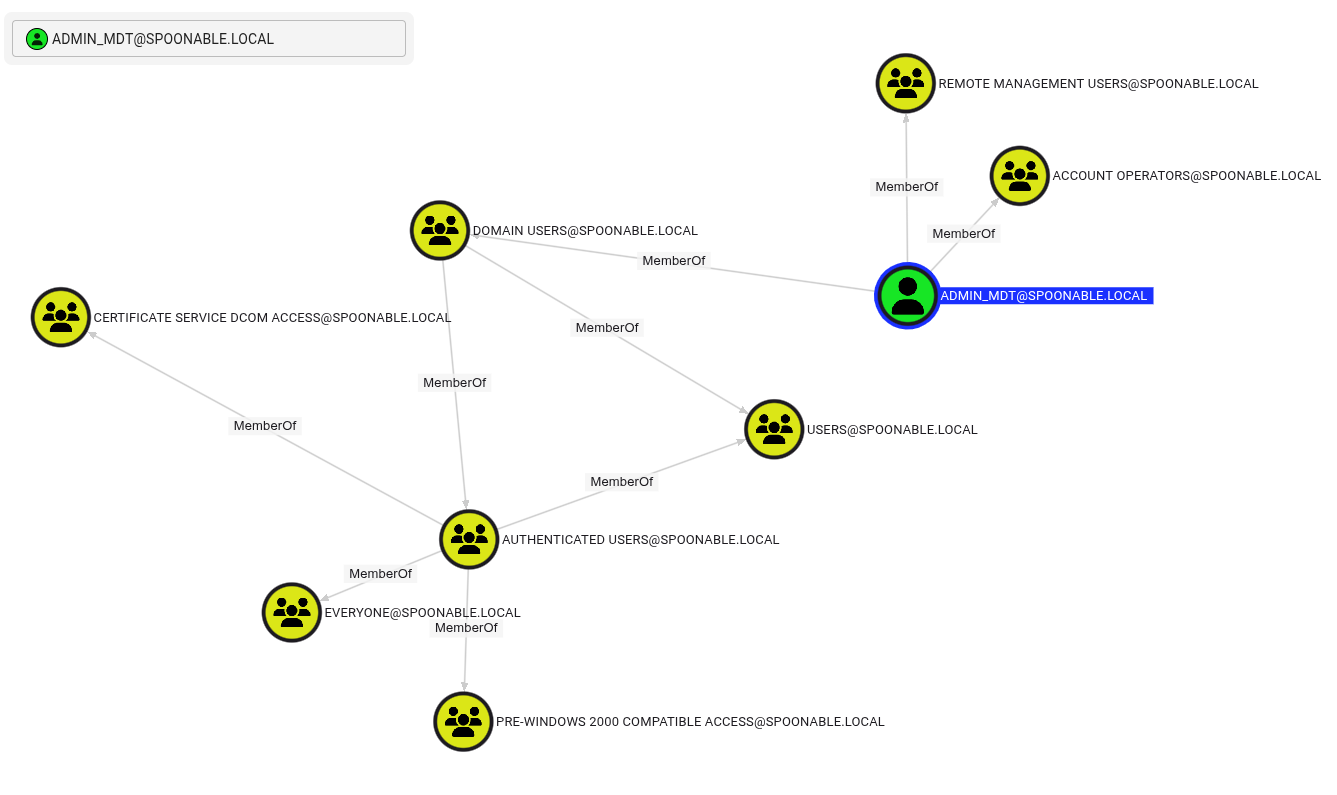
En analysant les droits de l’utilisateur ADMIN_MDT, on constate qu’il est membre de deux groupes, et non des moindres : Remote Management Users et Account Operators. Le premier lui permet d’exécuter des actions d’administration à distance sur les machines du domaine, tandis que le second lui confère des actions de gestion étendus sur les comptes utilisateurs du domaine, notamment la création, la modification ou la suppression de comptes standards. Ce niveau d’accès représente un vecteur d’escalade de privilèges particulièrement critique dans un environnement Active Directory.
IV. Recommandations
Les recommandations suivantes peuvent être mises en œuvre afin de renforcer la configuration du service WDS :
- Limiter l’exposition du serveur en l’isolant dans un sous-réseau (VLAN) dédié. Si cela n’est pas entièrement possible pour des raisons « métier », il est recommandé a minima de désactiver le flux SMB au niveau du pare-feu pour les zones réseau qui n’en ont typiquement pas besoin.
- Nettoyer les images WinPE en supprimant tout mot de passe présent dans les scripts d’automatisation, notamment dans les fichiers
Bootstrap.ini,CustomSettings.ini,Unattend.xml, ainsi que dans les scripts de séquence de tâches MDT (.vbs,.cmd,.ps1). - Appliquer le principe du moindre privilège au compte utilisé pour l’enrôlement des postes dans l’Active Directory, en privilégiant la saisie manuelle du mot de passe lors du déploiement afin d’éviter son enregistrement dans des fichiers de configuration en clair.
Enfin, c’est tout bête, mais si aucune de ces options ne vous convient et que le serveur de déploiement n’est pas utilisé régulièrement, il est recommandé de ne l’allumer qu’en cas de besoin. Parfois, cela peut être la meilleure des sécurités… tout en permettant d’économiser de l’électricité.
V. Conclusion
Le rôle WDS, combiné à MDT, est un outil efficace et très utilisé pour déployer des systèmes Windows. Pourtant, il reste souvent sous-estimé en termes de risques. Une mauvaise configuration peut exposer des infos sensibles, comme des identifiants Active Directory, et ouvrir une porte d’entrée à un attaquant. En appliquant les bonnes pratiques décrites plus haut, vous réduirez largement les risques liés à WDS et protégerez mieux votre infrastructure.
Merci à @scam pour leur relecture
++
GSB // @archidoté
L’article Quid de la sécurité du rôle Windows Deployment Services – WDS ? est apparu en premier sur Le Guide Du SecOps • LGDS.