Deep dive into AI world : Mise en place d’une pipeline RAG avec Kotaemon
The future is now ! Bonjour à tous, après quelques mois d’absence dus à de nombreux side projects, je suis de retour sur le blog avec un nouvel article qui, j’espère, va plaire au plus grand nombre d’entre vous. Dans celui-ci, je vous propose de plonger au cœur du fonctionnement d’un système RAG (Retrieval-Augmented Generation) afin que vous puissiez en créer un vous-même chez vous sur un serveur Linux. Je n’épilogue pas plus, place à la technique !
I. Environnement des tests et prérequis
- Ubuntu 24.04.1 – Version du noyau : 6.8.0-49-generic
- Docker (27.3.1 dans mon cas)
- Pour ceux qui n’auraient pas encore Docker installé sur leurs postes, je vous encourage vivement à utiliser le script d’autoconfiguration proposé par Docker. En effet, la version disponible dans le référentiel apt d’ubuntu n’est pas à jour.
- Voici, comment installer docker
curl https://get.docker.com/ | sh
- LLMs utilisés :
- nomic-rmbed-text
- llama3.1:8b
- « Orchestrateur » : Kotaemon
II. Qu’est-ce qu’une pipeline RAG ?
Une pipeline RAG (Retrieval-Augmented Generation) est une architecture utilisée en intelligence artificielle pour combiner des capacités de recherche « documentaire » et de génération de texte afin de répondre à des questions se basant sur un contenu externes (fichiers). L’idée principale est de compléter un modèle génératif « classique » en l’aidant à puiser dans une base de connaissances « externe » pour produire des réponses plus précises, à jour et fiables.
Une pipeline RAG regroupe donc deux grandes étapes :
- Recherche d’informations (« retrieval« ).
- Assuré par le LLM nomic-embed-text dans cet article
- Génération de la réponse (« generation« ).
- Assuré par le LLM Llama dans cet article

Une fois les documents indexés, voici à quoi ressemble le workflow d’une requête d’un point de vu utilisateur.
a) Ingestion et préparation des données
- Les documents qu’on souhaite indexer pour former notre base documentaire sont indexés dans une base de données adaptée à la recherche rapide, souvent sous forme de vecteurs.
- Cette étape convertit les données en représentations numériques compréhensibles par les modèles d’IA.
b) Recherche d’information (retrieval)
- Lorsqu’une question est posée, un module de recherche trouve les documents ou passages les plus pertinents à partir de la base indexée (C’est en quelque sorte un « giga » Ctrl +F). Ce module utilise des embeddings* générés par des modèles comme nomic-embed-text pour effectuer des correspondances sémantiques.
Cliquez ici pour plus d’information sur la notion d’embeddings…
Les embeddings sont des représentations vectorielles de données, telles que des mots, phrases transformées en vecteurs numériques. Ces vecteurs capturent les relations sémantiques, permettant aux modèles de comparer des éléments similaires plus facilement. Ils sont utilisés pour simplifier et améliorer des tâches comme la recherche d’information connexes. Voici un exemple concret d’un embedding sous forme de vecteur pour le mot « chat ». Imaginons que nous utilisons un modèle de langage qui transforme des mots en vecteurs à 3 dimensions :
Mot : « chat »
Vecteur d’embedding :
[0.2,−0.3,0.8]
Chaque composant du vecteur représente une caractéristique du mot, comme sa relation avec d’autres mots ou son contexte. Par exemple :
- 0.2 pourrait représenter l’association avec des animaux domestiques.
- -0.3 pourrait représenter son lien avec des animaux féroces (moins fort).
- 0.8 pourrait être lié à des concepts comme « mignon », « poils », ou « ronronner ».
Les mots ayant un sens similaire, comme « felin » ou « animal », auraient des vecteurs proches de « chat ».
c) Consolidation des informations récupérées
- Les informations pertinentes (passages trouvés) extraites grâce à nomic-embed-text sont regroupées par l’intermédiaire d’un « orchestrateur » (ici Kotaemon) et transmises au modèle génératif (Llama) comme contexte.
d) Génération de la réponse (generation)
- Le modèle LLM (Llama) prend ensuite le relais et utilise les informations fournies par la recherche précédente pour générer une réponse complète, concise et contextuelle.
Voici le resumé des étapes : B,C,D en un schéma :

source : https://www.aproductstory.com/p/retrieval-augmented-generationrag
Comme toute avancée technologique, une architecture RAG n’offre pas que des avantages. Voici un tableau des principaux pros/cons :
| Aspect | Description |
|---|---|
| Avantages d’une pipeline RAG | |
| Améliore la précision | Les LLM sont souvent limités par leur date de mise à jour. En combinant une recherche dynamique, on pallie cette limite. |
| Réduit les hallucinations | Le LLM est « guidé » par des données précises, ce qui diminue les risques de réponses inventées. |
| Personnalisation | La recherche peut être configurée pour fonctionner sur des données spécifiques (ex : documentations interne). |
| Limitations d’une pipeline RAG | |
| Complexité de mise en œuvre | Nécessite de configurer un système de recherche performant (indexation, embeddings, types de fichiers supportés) et de le connecter aux LLMs sous-jacent. |
| Performances dépendantes des données | Si les données sont mal structurées ou absentes, la qualité du pipeline s’effrite |
| Coûts en calcul | L’étape d’embedding et de recherche est gourmande en ressources. Cela dépend de la taille des fichiers à indexer. |
Maintenant que nous avons vu en quoi consiste une architecture RAG, passons à sa construction.
III. Installation et configuration d’Ollama
Warning : La différence entre Ollama et Llama est importante, car ces deux termes désignent des outils distincts, même si, syntaxiquement, ils sont proches. Llama (Large Language Model Meta AI) est une famille de modèles de langage développée par Meta, conçue pour la génération et la compréhension de texte. En revanche, Ollama est une plateforme qui facilite l’utilisation et le déploiement de modèles comme Llama. Ollama agit comme un cadre pratique, permettant d’installer, gérer et interagir avec des modèles de langage, tout en offrant des outils supplémentaires pour simplifier leur intégration dans des applications, notamment les architectures RAG.
Voici les points essentiels de son fonctionnement :
- Exécution locale : Ollama permet d’héberger et d’exécuter des modèles de langage directement sur ton ordinateur, ce qui garantit la confidentialité des données.
- « Catalogue » de modèles : La plateforme propose un « hub » de modèles préentraînés qu’on peut télécharger et utiliser facilement. (même principe que le docker hub / vagrant hub)
- Facilité d’utilisation : Une interface en ligne de commande « docker like* » simple pour charger et interagir avec les modèles.
- Optimisation : Compatible avec du matériel grand public, comme des GPU et CPU** standards, grâce à l’optimisation des modèles pour les environnements locaux.
- Confidentialité : Idéal pour la souveraineté des données, car Ollama peut être installé « on-premise ».
*Ollama utilise Docker comme sous-couche pour isoler et gérer les environnements nécessaires à l’exécution des modèles de langage.
**Pour rappel, Ollama peut fonctionner en mode CPU-only, c’est-à-dire sans recourir à une carte graphique dédiée. Bien que ce mode soit plus lent, car toutes les ressources de calcul reposent sur le CPU, il rend possible l’exécution locale d’un LLM sur un ordinateur standard, accessible à presque tout le monde.
Un script d’autosetup est fourni par le site officiel, prenant en charge la plupart des distributions connues. Pour ceux qui préfèrent une solution entièrement basée sur Docker, il est également possible d’utiliser Docker pour installer Ollama. Cependant, cela ajoute une couche d’abstraction supplémentaire, qui peut parfois être contre-productive, notamment lorsqu’il s’agit d’intégrer des ressources externes dans une architecture RAG, car ces dernières ne sont pas toujours conçues pour fonctionner de cette manière.
curl -fsSL https://ollama.com/install.sh | shDès lors, il faut démarrer le service Ollama :
sudo systemctl start ollamaSi-vous souhaitez qu’Ollama s’instancie dès que votre ordinateur/serveur démarre (optionnel) :
sudo systemctl enable ollamaPour vous assurer que votre installation d’Ollama fonctionne correctement, il est recommandé de vérifier son statut et d’instancier un LLM simple pour effectuer un test rapide.

ollama run gemma:2bprompt : Bonjour, qui est-tu ?

IV. Installation et configuration de Kotaemon
Kotaemon est une plateforme open source conçue pour créer une architecture RAG en interfaçant plusieurs LLM. Elle permet de structurer, interroger et extraire des informations à partir de grandes quantités de données textuelles. Elle simplifie l’indexation des documents (phase d’embedding), la recherche contextuelle sémantique (réalisée ici avec un LLM dédié, nomic-embed-text), ainsi que la génération de réponses pertinentes en fonction du contexte par le LLM principal, souvent qualifié de « penseur » (dans ce cas : llama3.1:8b).
Pour simplifier le déploiement de Kotaemon « on the fly », j’ai choisi d’instancier le conteneur de manière temporaire. Ainsi, dès que je quitte le terminal, le conteneur est automatiquement supprimé. De plus, par défaut, j’exécute ce conteneur sur le même réseau que ma machine hôte. Bien que ce ne soit pas recommandé pour un environnement de production « ASoA* », cette configuration me permet de faciliter le déploiement et l’interfaçage entre le socket de l’API Ollama qui n’utilise pas Docker (localhost:11434) et le système RAG porté par Kotaemon (localhost:7860).
*A State of Art
docker run -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 --net=host -it --rm ghcr.io/cinnamon/kotaemon:main-fullsource : https://github.com/Cinnamon/kotaemon/issues/224#issuecomment-2483136705
Dans un premier temps, et pour vous faciliter la vie en cas de troubleshooting, je vous conseille de ne pas exécuter le conteneur Kotaemon en arrière-plan. Ainsi, vous aurez les logs de l’application en direct, ce qui vous évitera de faire des appels intempestifs à la commande
docker logs.

Dans un autre terminal, executez les commandes suivantes :
docker ps Pour vérifier que Kotaemon fonctionne correctement avec Ollama, il est essentiel de s’assurer que ce dernier est en mesure d’accéder à l’API d’Ollama, qui utilise par défaut le port 11434. Pour ce faire, il suffit d’entrer à l’intérieur du conteneur :
docker exec -it <ID> bashPuis de saisir la commande suivante :
curl http://localhost:11434 -w '\n'
Dès lors, rendez-vous sur l’interface web de Kotaemon (http://localhost:7860), sélectionnez Ollama comme « model provider », puis cliquez sur Proceed.

Kotaemon, ayant accès à l’API d’Ollama, il va se charger du téléchargement des modèles nomic-embed-text et llama3.1:8b (modèles par défaut).
- llama3.1:8b (5go)
- Modèle Llama (de Meta), version 3.1, avec 8 milliards de paramètres*. Conçu pour accomplir des tâches complexes de traitement du langage naturel, telles que la génération de texte en fonction d’un contexte c.
- nomic-embed-text (300mo)
- Modèle spécialisé dans l’embedding de texte, c’est-à-dire la conversion de phrases en vecteurs numériques (représentations vectorielles). Conçu pour des tâches comme la recherche sémantique, la classification de texte ou la mise en cluster d’idées similaires.
*La notion de paramètre dans le contexte des modèles de langage comme LLaMA fait référence aux poids appris par le modèle pendant son entraînement. Ces poids sont des valeurs numériques ajustées pour capturer les relations entre les mots, phrases et concepts dans les données sur lesquelles le modèle a été entraîné. Plus il y a de paramètres, plus le modèle est complexe et capable de capturer des relations subtiles dans les données.

Une fois que les modèles ont été téléchargés, Kotaemon tente de dialoguer avec eux en envoyant un simple prompt « Hi ».

Pourquoi avons-nous besoin de deux modèles allez-vous me dire ?
Pour rappel, dans Kotaemon, LlamA 3.1:8B est utilisé pour ses capacités avancées de compréhension et de génération de texte en langage naturel. Ce modèle est essentiel pour analyser des contextes complexes, produire des réponses détaillées et interagir de manière intelligente avec l’utilisateur. Il joue un rôle central dans l’interprétation des requêtes et l’élaboration des réponses. En quelque sorte, c’est lui le « cerveau » qui établit les connexions entre les données extraites par nomic-embed-text. (ce dernier pouvant être comparé à un assistant chargé de consulter toutes les ressources documentaires, mais sans le recul nécessaire pour structurer et produire une réponse logiquement cohérente).
En parallèle, Nomic-Embed-Text:latest est dédié à l’indexation et à la recherche sémantique. Il convertit des textes issus de fichiers PDF, Markdown, etc., en représentations vectorielles, permettant de trouver des similarités ou des concepts connexes rapidement et efficacement.
V. Tests
Bien, une fois que vous avez accès à l’interface configurée de Kotaemon, il est temps de tester si notre pipeline RAG fonctionne correctement. Pour cela, il faut ajouter des fichiers à la base documentaire afin qu’ils soient « embedded » (indexé par nomic-embed-text). Pour ce faire, suivez ces étapes :
- Allez dans le menu suivant :
Files → Upload files - Sélectionnez les fichiers souhaités, puis cliquez sur Upload and index.
Le fichier que j’ai choisi est un document qui décrit en détail le fonctionnement du réseau Tor, que je vous recommande vivement de le consulter si ce sujet vous interesse.
P40 – Exploration du réseau Tor

Voilà ce qui se passe du côté backend :

En fonction de la puissance de votre ordinateur/serveur ainsi que de la taille du fichier à traiter, le document peut prendre beaucoup de temps à être indexé par nomic-embed-text. Comptez plusieurs minutes avec un ordinateur standard du marché. L’idée finale est évidemment d’utiliser un serveur dédié disposant de bien plus de ressources physiques (CPU, GPU, RAM).

Une fois que celui-ci est indexé, vous pouvez enfin essayer de requêter le RAG en posant des questions relatives au document indexé.
Prompt : Qui sont les auteurs du document ?

Ce premier prompt, en posant une question directement liée au document, permet de vérifier que notre pipeline RAG fonctionne correctement. Cela teste si l’IA fournit une réponse basée sur le document ou si elle « hallucine ». Lorsque des documents pertinents sont identifiés, ils s’affichent à droite dans l’interface.

Posons maintenant une question plus technique, toujours en nous basant sur le document téléversé précédemment.
Prompt : OK. Peux-tu m’expliquer ce que sont les serveurs d’annuaire au sein du réseau Tor ?

La réponse est en parfaite adéquation avec la notion abordée. Qui plus est, elle est techniquement correcte.
VI. Conclusion
En conclusion, les pipelines RAG représentent une avancée majeure pour la gestion et l’exploitation de l’information. En combinant la recherche sémantique et la puissance des modèles de langage, ils permettent un accès rapide et contextuel aux données, transformant ainsi des volumes d’informations brutes en réponses pertinentes et exploitables. C’est sans nul doute un avenir certain pour la gestion des procédures au sein de systèmes d’information, car ils éliminent le besoin de rechercher manuellement dans des wikis ou, pire encore, de parcourir des fichiers de procédure dispersés. Grâce à cette avancée, entreprises et particuliers peuvent, entre autres, optimiser leur productivité.
++
Archidote
L’article Deep dive into AI world : Mise en place d’une pipeline RAG avec Kotaemon est apparu en premier sur Le Guide Du SecOps • LGDS.




 ).
).

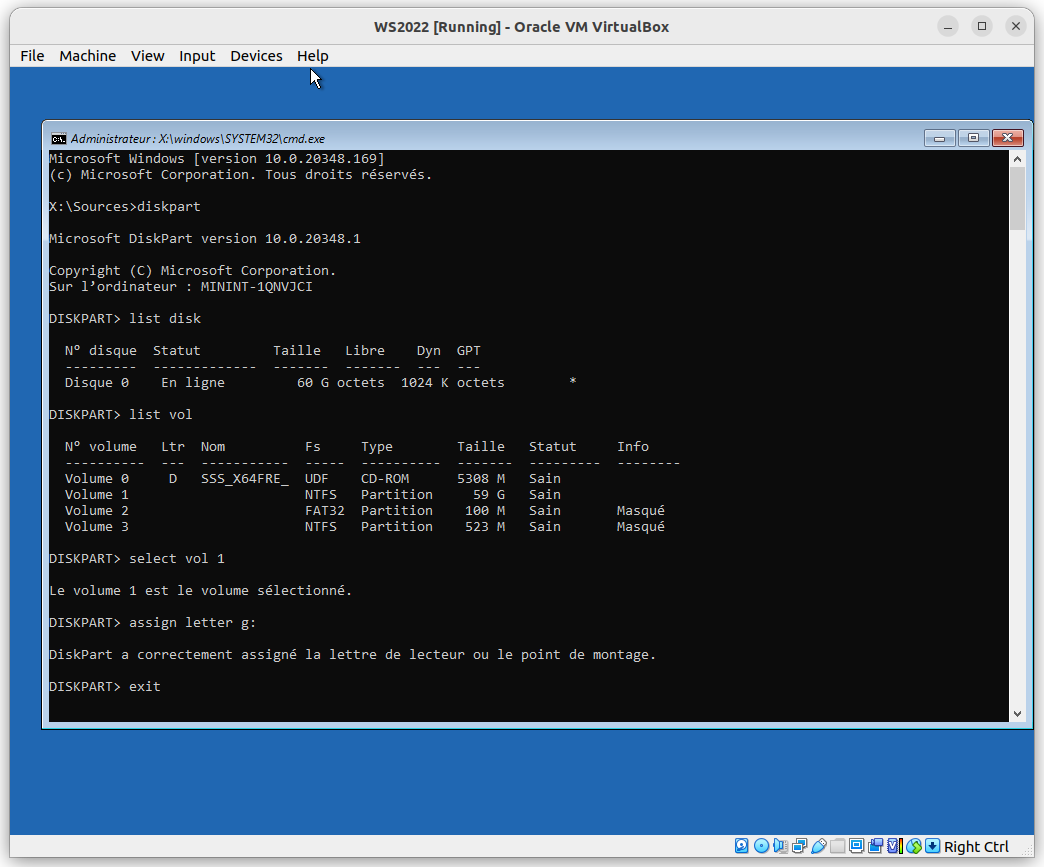
 Par défaut, même après une sécurisation (voir la dernière section), il est toujours possible de procéder à une énumération des volumes… Pas idéal, mais bon ^^
Par défaut, même après une sécurisation (voir la dernière section), il est toujours possible de procéder à une énumération des volumes… Pas idéal, mais bon ^^
































































{kind=link}