La recherche de Jellyfin fonctionne bien mais on peut la booster en termes de vitesse et de precision. Par exemple utile quand on commence à indexer des 100aines de To de contenus ou qu’on fait des fautes dans les noms de contenus, acteurs etc.
Meilisearch est un moteur de recherche ultra-rapide qui s’intègre sans effort dans des applications, sites Web et flux de travail.
Pour le coupler à Jellyfin il existe le projet JellySearch mais là je présente l’installation séparée de Meilisearch et l’utilisation du plugin d’arnesacnussem.
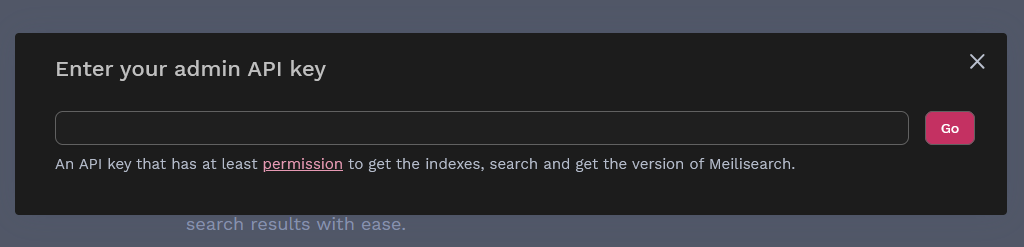
Pour commencer il faut installer Meilisearch. La master_key est une clé à définir soi-même.
services:
meilisearch:
image: getmeili/meilisearch:latest
container_name: jellyfin-meilisearch
restart: always
stdin_open: true
tty: true
ports:
- 7700:7700
environment:
- MEILI_MASTER_KEY=xpQvJwcLTxsdnx0P7oJMZ1f3LwIUcF
volumes:
- /home/aerya/docker/jellyfin-meilisearch:/meili_data
labels:
- com.centurylinklabs.watchtower.enable=true
On se rend ensuite sur la WebUI pour y entre la master_key en confirmation d’installation
Puis on installe le plugin sous Jellyfin
https://raw.githubusercontent.com/arnesacnussem/jellyfin-plugin-meilisearch/refs/heads/master/manifest.json
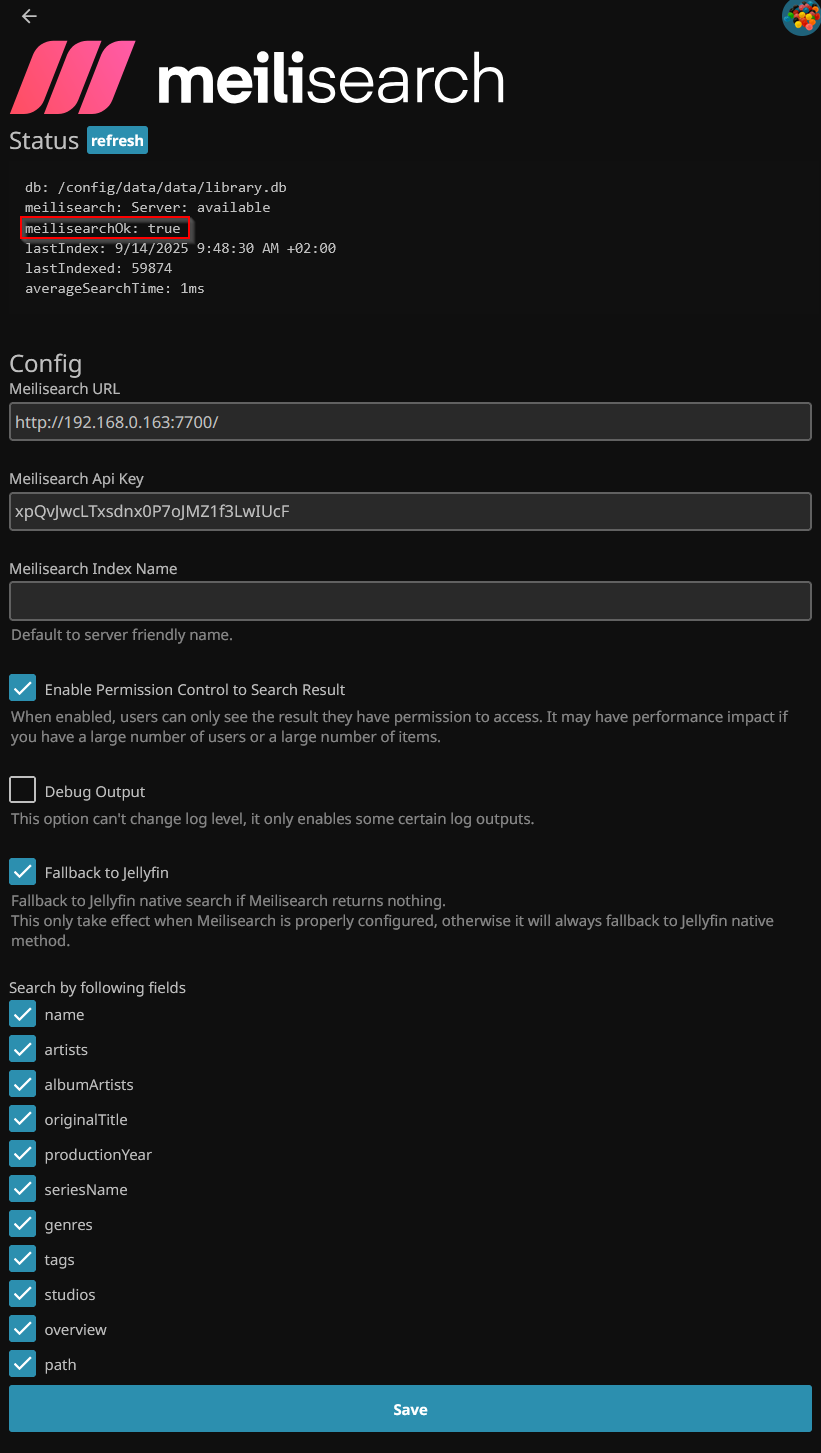
Après reboot on peut le configurer avec l’URL de Meilisearch, la master_key. Tout en haut, cliquer sur Connect et s’assurer que meilisearchOk passe bien en true, ce qui confirme la bonne connexion.
Et on utilise la recherche classique de Jellyfin, qui est plus complète et rapide.