Le chat du stream s’est arrêté. Trente mille vies gelées dérivaient au-dessus de Tau Ceti IV. La voix de Ben Starr a résonné à travers le teaser, et ma peau s’est tendue comme une cathédrale rouillée. Je suis Marathon de Bungie depuis le début de l’ARG, et vous devriez également y prêter attention. Vous obtiendrez […]
Avis aux amateurs qui s’ennuient au crossfit ou qui ronronnent en salle de sport. Voici l’Hyrox, le fitness extrême qui repousse les limites physiques, en mêlant endurance et force à un rythme effréné. Popularisé en France lors d’une compétition internationale, l’Hyrox séduit par son mélange...
J’ai vu un trio se démener lorsqu’un Vault s’est scellé et que le minuteur a clignoté en rouge. On pouvait sentir le chat monter en flèche et les streamers se pencher en avant — leurs mains stables, leurs inventaires pas. Le vaisseau Marathon ressemblait à un coffre-fort vivant et aujourd’hui, tout le monde veut la […]
J’ai appuyé sur le bouton de mise à jour et les serveurs se sont éteints – le chat de mon équipe s’est rempli d’un mélange d’excitation et de panique contenue. Les fichiers contiennent désormais le nouvel Archive Cryo, qui laisse entrevoir des runs que seuls les plus astucieux atteindront. On sent déjà que le grind […]
Si vous avez touché à du Python ces deux dernières années, il y a de fortes chances qu'uv, le gestionnaire de paquets ultra-rapide écrit en Rust, se trouve quelque part dans votre setup. Mais aussi que Ruff vérifie votre code avant chaque commit. Ce jeudi 19 mars, OpenAI a annoncé l'acquisition d'Astral, la boîte derrière […]
🔩 Like builtins, but boltons. 250+ constructs, recipes, and snippets which extend (and rely on nothing but) the Python standard library. Nothing like Michael Bolton. - mahmoud/boltons
"Can it run DOOM?" est depuis les années 90 le test de Turing officieux de n'importe quel support informatique. Calculatrices, imprimantes, tondeuses à gazon, tests de grossesse, tout y est passé ! Cette semaine, une startup australienne a répondu à cette question ultime avec... des neurones humains vivants. Pong, c'était de l'échauffement Cortical Labs n'en […]
SunFounder m’a envoyé cette carte PiPower 5 pour la tester sur le Raspberry Pi. Il s’agit d’une UPS (Uninterruptible Power Supply), c’est-à-dire d’une alimentation secourue : en cas de coupure du secteur, la batterie prend le relais pour éviter un arrêt brutal du système. La PiPower 5 sert donc à protéger la carte, la carte […]
iCloud, c'est sympa pour stocker vos photos et vos documents... jusqu'au jour où comme moi, vous décidez de vous barrer. Parce que récupérer vos 200 Go de fichiers en masse depuis le cloud d'Apple (plusieurs To pour moi), c'est pas vraiment ce qu'il y a de plus simple (genre, y'a pas de bouton "tout télécharger"). J'ai bien essayé de demander un export de mes datas à Apple et pour la partie iCloud Drive, j'ai juste eu des espèces de CSV bizarres mais pas mes documents.
Heureusement, pour s'extraire des griffes de l'entreprise de Cupertino, y'a un outil Python parfait pour ça.
iFetch
, c'est un utilitaire en ligne de commande qui va se connecter à votre compte iCloud Drive et tout rapatrier en local. Le truc gère la 2FA (parce que bon, en 2026, si vous n'avez pas de 2FA activée quand c'est possible, vous méritez d'être envahi de puces de lit), les téléchargements parallèles avec 4 workers par défaut, et surtout les updates différentiels.
En gros, seuls les morceaux de fichiers qui ont changé sont re-téléchargés, du coup, sur un dossier de 50 Go déjà synchro, ça passe en quelques secondes au lieu de tout re-pomper. Et si ça plante au milieu, pas de panique, l'outil reprend là où il s'est arrêté grâce à un système de checkpointing.
Y'a aussi un truc malin, c'est le système de profils. Vous créez un fichier JSON avec des règles d'inclusion et d'exclusion, genre "tous les PDF du dossier Documents sauf ceux du dossier Private" et hop, en une commande et c'est plié.
Le support des dossiers partagés est aussi de la partie (le fameux --list-shared), y'a un système de plugins pour ceux qui veulent étendre le bazar, et même un historique de versions avec rollback automatique. Pas mal pour un outil libre !
Pour l'installer, après c'est du classique. Virtualenv Python, pip install pyicloud tqdm requests keyring, et vous stockez vos identifiants via icloud --username=votre@email.com qui balance tout ça dans le trousseau système (Keychain sur macOS, libsecret sur Linux). D'ailleurs, si vous êtes du genre à
sauvegarder vos dotfiles dans iCloud
, c'est l'outil parfait pour faire le chemin inverse.
...et ça mouline !! Vous pouvez même monter jusqu'à 8 workers pour aller plus vite (--max-workers=8), configurer les retries (--max-retries=5) ou juste lister le contenu sans rien télécharger avec --list. Attention, si vous avez des noms de fichiers avec des caractères spéciaux (genre des accents ou des espaces... merci macOS, groumpf), vérifiez bien que tout est passé après le transfert.
Alors oui, c'est CLI only, donc oubliez l'interface graphique. La doc mériterait un petit coup de polish et surtout, si votre session 2FA expire en plein transfert... faut relancer l'auth. Ça casse pas le téléchargement en cours, mais bon, c'est un peu "chiant".
Bon au final, pour un projet open source sous licence MIT, c'est plutôt du solide. Et si vous voulez
chiffrer vos sauvegardes
une fois récupérées en local, y'a des solutions pour ça aussi.
Bref, c'est simple, ça fait le job et c'est gratuit. Que demande le peuple à part du matos Apple moins cher, lool ?
Ansible, c'est bien. Mais du YAML à perte de vue pour configurer trois serveurs c'est pas non plus l'idéal. Hé bien ça tombe bien car y'a maintenant
pyinfra
, qui fait tout pareil sauf qu'on écrit du Python. En gros, votre script de déploiement c'est juste du code Python normal avec des imports, des boucles, des conditions... tout ça, tout ça...
Ce projet existe depuis 2014, il est sous licence MIT et côté perfs, c'est de ce que j'ai lu, jusqu'à 10 fois plus rapide qu'Ansible sur des déploiements massifs (genre plusieurs milliers de machines). Bon, sur le papier c'est bien, mais en fait ça dépend surtout de votre infra SSH et de la latence réseau.
Alors ça marche comment ?
Hé bien vous installez le bazar avec uv tool install pyinfra et hop, vous pouvez déjà lancer des commandes sur vos serveurs comme ceci :
Ça fonctionne en SSH sur le port 22, sur des conteneurs Docker, ou même en local. Le truc est complètement agentless, du coup pas besoin d'installer quoi que ce soit sur les machines cibles. Suffit d'un accès shell POSIX tout ce qu'il y a de plus classique et c'est réglé.
Bon, ça c'est pour l'ad-hoc mais en fait le vrai kiff, ce sont les opérations déclaratives. Je vous montre... Vous créez un fichier deploy.py et dedans, vous mettez ça :
from pyinfra.operations import apt, systemd
apt.packages(
name="Install nginx",
packages=["nginx"],
)
systemd.service(
name="Ensure nginx is running",
service="nginx.service",
running=True,
enabled=True,
)
C'est du bon vieux Python sans DSL bizarre (Domain-Specific Language), pas d'indentation YAML qui vous pète entre les doigts à 3h du mat parce qu'il manque un espace. Et si vous voulez une boucle ? bah for. Une condition ? bah if. Ou encore importer
boto3 pour causer avec AWS
depuis votre Debian 12 ? No problemo !
Et pour cibler vos machines, suffit de créer un fichier inventory.py comme ceci :
Puis ensuite un petit : pyinfra inventory.py deploy.py et c'est parti mon kiki. L'outil gère le parallélisme sur 50 serveurs, les diffs (pour voir ce qui va changer AVANT d'appliquer), et le mode dry-run pour les plus prudents.
Côté intégrations, ça cause avec Terraform, Docker, Vagrant... et comme c'est du Python, vous avez accès à tout l'écosystème. Genre, vous voulez checker l'état d'une API avant de déployer ? Un import requests et c'est plié. La doc sur
docs.pyinfra.com
est plutôt complète, et y'a même la gestion des secrets intégrée avec variables d'environnement, fichiers chiffrés, HashiCorp Vault ou AWS Secrets Manager.
Ça tourne depuis Linux et macOS (et Windows via WSL), mais les cibles doivent être des systèmes POSIX donc pas de déploiement natif sur Windows. Et si votre inventaire contient 3 000 machines avec des configs SSH différentes... bon courage pour le debug en cas de souci (le mode -vvv aide, mais bon...).
Bref, si vous en avez marre du YAML et que Python c'est votre truc, allez jeter un oeil.
Un canal présenté comme "CVE Exchange" diffuse vulnérabilités, PoC et contenus offensifs. Quand un malveillant ouvre un espace pour faciliter les attaques.
Tout récemment, je voulais utiliser un module RFM69 sur un Compute Module 5 (autrement dit l'équivalent d'un Raspberry-Pi 5) faisant fonctionner un logiciel écrit Python.
Une API MicroPython sous Python
Ecrivant de nombreux pilotes pour MicroPython (Python pour MicroContrôleur), je me suis dit qu'il devait être possible de réutiliser le code MicroPython du RFM69 sous Python sans devoir réécrire tout-ou-une-partie du code pour qu'il fonctionne sur Raspberry-Pi.
Le problème, c'est que Python n'a aucune idée de ce qu'est l'API MicroPython (celle utilisée par MicroPython pour accéder directement à la couche matérielle).
Il existe cependant des moyens d'accéder au matériel depuis Python mais c'est sans aucun rapport avec l'API exposée MicroPython.
L'idée c'est de recréer l'API MicroPython sous Python pour permettre l'utilisation du RFM69 depuis Python:
Ajouter les déclarations d'encodage (nécessaire à Python)
L'image ci-dessous se présente le module RFM69HCW 433MHz . Ce module permet de transmettre des données sur un réseau numérique utilisant le ondes-radios comme medium de transfert. C'est un peu le protocole internet appliqué à la radio.
Comme le Pilote est développé sous le précepte "Plateform Agnostic Driver" de sorte à pouvoir fonctionner indépendamment de la plateforme MicroPython cible.
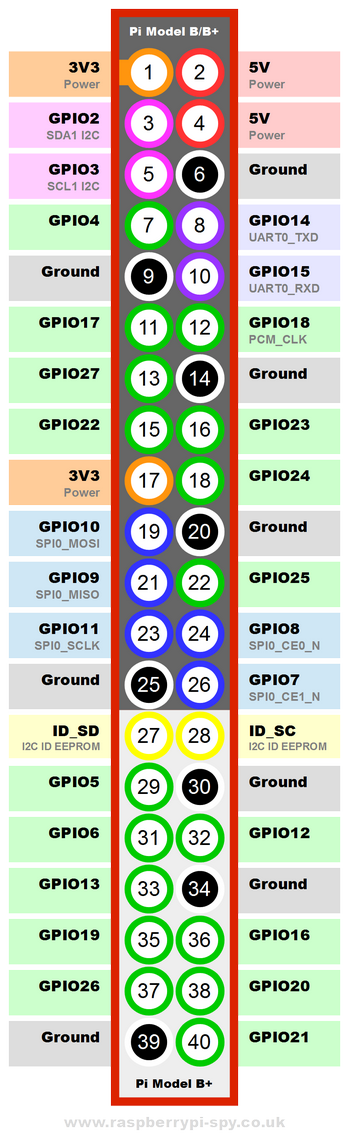
Les connexions suivantes sont établies entre le module RFM69 et le GPIO Raspberry-Pi.
La broche CS (chip select) est branchée sur le GPIO 25 alors qu'il existe les broches CE0 (GPIO8) et CE1 (GPIO7).
Le problème ici est que CE0 et CE1 sont automatiquement gérés par le système d'exploitation alors que sous MicroPython, c'est le code utilisateur qui gère l'état du signal CS.
Dans le cas présent, la gestion automatique de CE0 et CE1 empêche l'utilisation du burst_read sur le module RFM69 raison pour laquelle le GPIO25 est utilisé comme signal CS (ce signal étant contrôlé par le code utilisateur).
Récupérer l'exemple test_config.py utilisé pour tester la communication avec le module RFM69. Nous y ajoutons également l'information d'encodage dans le fichier.
Couche de compatibilité Python --> MicroPython
Création des fichiers machine.py et micropython.py pour accueillir les classes Pin & SPI ainsi que la déclaration de la fonction const()
Le script le plus intéressant est hack_time.py car celui-ci permet d'ajouter les fonctions MicroPython (ticks_ms, ticks_diff, sleep_ms, etc) manquantes dans Python.
Il ne reste plus qu'a adapter le script d'exemple pour créer l'instance du bus SPI (sur le RPi) et passer le tout à la bibliothèque MicroPython originale.
#!/usr/bin/python
# -*- coding: utf-8 -*-
from machine import SPI, Pin
import hack_time
from rfm69 import RFM69
# Machine.py for Raspberry-Pi 5
spi = SPI( 0 )
nss = Pin( 25, Pin.OUT, value=True ) # Do not use the RPI CE0/CE1, it is not compatible with the Burst_Read of RFM69
rst = Pin( 18, Pin.OUT, value=False )
rfm = RFM69( spi=spi, nss=nss, reset=rst )
rfm.frequency_mhz = 433.1
....
Le bus SPI est rattaché au bus matériel SPI0 & CE0.
Une broche Enabled (nss) alternative est utilisé avec le GPIO25 pour contrôler les transactions du bus SPI. La broche CE0 du GPIO est donc ignorée.
Enfin, le GPIO 10 est utilisé pour réinitialisé le module RFM69.
Au final, la création de l'instance RFM69 et le restant du code (y compris la bibliothèque RFM69) est identique entre MicroPython et Python (sur RPi5).
L'exécution de l'exemple sur le Raspberry-Pi 5 produit le résultat attendu (identique lorsqu'il est exécuté sur un Pico).
test_config.py : exécution de la bibliothèque MicroPython RFM69 sur Raspberry-Pi 5
Ressources
MicroPython-API-for-Python experiment is published on GitHub.
La SunFounder Fusion HAT+ ressemble à un simple HAT pour Raspberry Pi… jusqu’au moment où vous réalisez que c’est plutôt un couteau suisse pour robot “assisté par IA”. Elle ne “fait” pas l’IA toute seule : les neurones restent sur le Raspberry Pi (un Pi 5 dans mon cas), mais la carte apporte le muscle […]
L'optimisation est une activité connue de bien des développeurs, fouiller, chercher dans son code, pour, peut être, gagner un peu de performance (beaucoup, parfois). Dans cette tâche ardue, face à des codes grandissants, massifs, utilisant de nombreuses bibliothèques externes, un outil central dans ce travail de fourmi : le profileur.
Le profileur fait partie des outils importants pour le développeur qui se soucie des ressources qu'il utilise. Il lui permet de chercher les points chauds dans son code, comprendre le cout de chaque fonction, chaque ligne implémentée. Bien des outils s'intéressent à une chose : bien utiliser votre processeur.
Mais que se passe-t-il si vous rencontrez des difficultés avec l'utilisation de votre mémoire ? Si vous pensez mal utiliser la fonction malloc() du C ou l'opérateur new du C++ ? Si vous avez oublié qu'une de vos variables globales occupe 10 Go (surtout en Fortran) ?
Publié il y a quelques années MALT (licence CeCILL-C) permet de répondre à la question en cherchant toutes les allocations mémoires faites par votre code. Cet outil avait fait l'objet d'un article sur LinuxFR en 2018 lors de sa mise en open source : Profileurs mémoire MALT et NUMAPROF.
Depuis, cet outil fait son chemin avec l'ajout du support de Rust ainsi que nombreuses corrections et ajouts tels que la possibilité de dumper le profile mémoire juste avant que le système ne soit plein.
La possibilité de suivre les appels à mmap, mremap, munmap si vous les appelez directement dans votre code au lieu de laisser malloc faire son travail.
Support de python
MALT a initialement été développé dans le contexte du calcul à haute performance — HPC (High Performance Computing) donc surtout pour le C / C++ / Fortran / Rust.
Dans la communauté scientifique, nous voyons dans les laboratoires de plus en plus fleurir l'usage d'un langage à priori bien éloigné de nos prérogatives de performances : Python.
Dans un cadre de calcul scientifique, il est souvent utilisé plutôt comme un wrapper permettant d'appeler et d'orchestrer des bibliothèques en C /C++ / Fortran, elles, performantes. Quoi que l'usage amène aussi à l'écrire de certaines parties du code en Python grâce à Numpy ou Numba pour accéléré la partie calcule sur des tableaux ou autres frameworks d'exploitation des GPU.
La version 1.6.0 de MALT vient d'ajouter le support (encore quelque peu expérimental) natif de Python permettant d'analyser un code pur python ou mix Python / C / C++…. Il s'agit pour l'instant de la première version avec ce support, il reste donc du travail.
Sont supportés les versions Python supérieures à 3.11 ainsi que les environnements Conda / Anaconda / Venv. À l'heure de rédaction de cet article, cela comprend les versions 3.11 à 3.14.
MALT étant orienté C / C++, il ne supporte que Linux comme système d'exploitation. (NdM: la causalité évoquée ici devrait faire réagir des développeurs d'autres systèmes libres notamment :))
Utilisation sur Python
Si la commande malt fonctionne parfaitement, il est recommandé d'utiliser le wrapper malt-python qui adapte quelques configurations spécifiques à Python non encore automatiques.
malt-python ./script.py
# équivalent à
malt --profile python-default ./script.py
# liste des profiles
malt --profile help# Afficher le profile
malt-webview ./malt-script-py-6889.json
Profilage rapide
Notons que l'overhead de MALT est important en Python du fait du large nombre d'allocations générées par ce langage et de la méthode de résolution des piles d'appels pour retrouver les lignes dans votre code. Ces détails d'analyse peuvent être désactivés via :
# Désactivé complète de l'analyse des piles
malt-python -p python-no-stack ./my_script.py
# Analyse des piles par "sampling"
malt-python -p python-sampling ./my_script.py
Nouvelle interface
La version 1.6.0 arrive également avec une nouvelle interface graphique avec un code remis à jour
par rapport à sa version originale vieillissante.
Profil statique
Pour ceux qui voudraient échanger les profils avec d'autres sur d'autres OS, il est possible depuis la 1.6.0 de générer une version statique des pages de l'interface (hors annotation des sources et arbre d'appel navigable) via :
# Toues les pages possible en statique
malt-webview -static ./report malt-progr-123456.json
# Seulement la page de résumé.
malt-webview -static-summary ./report malt-progr-123456.json
Installation
MALT n'est pas encore disponible dans les distributions classiques, vous devez donc le compiler et l'installer à la main. Le nombre réduit de dépendances obligatoires en fait un outil relativement facile à installer.
On trouvera la procédure dans la documentation du projet.
Documentation
La documentation a été complètement ré-écrite et disponible sur le site officiel : documentation.
Outils similaires pour Python
Découvrir un outil est aussi l'occasion d'en découvrir d'autres. Restons dans le monde du Python, si MALT ne vous convient pas vous trouverez peut-être votre bonheur avec les outils suivants et complémentaires à MALT et eux totalement dédiés au Python toujours pour la mémoire :
MALT se positionne par rapport aux deux présentés en apportant une analyse fine en annotant tout le source code de l'application. Il offre également une analyse des variables globales et TLS coté C/C++/Fortran/Rust.
Aujourd’hui, je vous propose de découvrir Pimmich, un cadre photo connecté open source basé sur Raspberry Pi, pensé pour afficher vos souvenirs sans cloud ni abonnement, en restant 100% local. Avec les récents changements côté Google Photos, beaucoup d’entre vous ont dû revoir leurs habitudes… et Aurélien a eu le bon réflexe : s’appuyer sur […]




 Le nouveau shooter de Bungie, Marathon, pourrait finalement sortir sur les consoles de génération précédente (Xbox One et PlayStation 4)
Le nouveau shooter de Bungie, Marathon, pourrait finalement sortir sur les consoles de génération précédente (Xbox One et PlayStation 4)

 À l’approche du Server Slam de Marathon, Bungie détaille l’architecture réseau et les protections anti-triche de son shooter d’extraction.
À l’approche du Server Slam de Marathon, Bungie détaille l’architecture réseau et les protections anti-triche de son shooter d’extraction.










{kind=link}