Utilisateurs de qBittorrent, combien de fois avons-nous vu un .torrent marqué « stalled » ? Un téléchargement bloqué pour X raison et Sonarr ou Radarr qui attend… attend… encore et toujours…
Les *arrs n’ont pas d’outil de détection des téléchargements bloqués.
Pour lancer le Docker, on met les instances qu’on souhaite, je teste avec les 2 que j’ai. J’ai mis les IP:port mais on peut mettre une URL sans le backslash de fin
J’ai tout laissé par défaut mais on peut régler les variables
Name
Default
Description
BASEURL
http://127.0.0.1:7878
The URL of a radarr, sonarr or other starr instance.
APIKEY
7f3a8..cbc07
The API key of a radarr, sonarr or other starr instance.
PLATFORM
radarr
Indicates the type of starr platform, either radarr, sonarr, lidarr, readarr or whisparr.
MAX_STRIKES
3
Maximum number of strikes a download can accumulate before it is removed.
SCAN_INTERVAL
10m
How often Swaparr checks for stalled downloads.
MAX_DOWNLOAD_TIME
2h
Maximum allowed download time before it’s considered stalled.
IGNORE_ABOVE_SIZE
25GB
Files larger than this size will be ignored and not monitored.
REMOVE_FROM_CLIENT
true
Remove from both queue and download client (default) OR false only the queue of a starr instance.
DRY_RUN
false
Sandbox mode; try Swaparr without it performing destructive actions on your instances.
Swaparr gère les clients de téléchargement BitTorrent liés aux *arrs, toute les 10 minutes avec cette configuration. Et l’instance *arr pourra donc aller chercher un autre .torrent
aerya@StreamBox:~$ sudo docker logs swaparr-radarr
── Swaparr ─────
╭─╮ Platform: radarr
│ │ Max strikes: 3
│ │ Scan interval: 10m
│ │ Max download time: 2h
│ │ Ignore above size: 25GB
╰─╯ Remove from client: true
╭─╮ Be part of Swaparr's journey ⭐ Star us on GitHub!
╰─╯ Your support strengthens the open-source community.
────────────────
╭──────────────────────────────────────────────────────────────────────────╮
│ No downloads found │
╰──────────────────────────────────────────────────────────────────────────╯
─ Checking again in 10m..
╭──────────────────────────────────────────────────────────────────────────╮
│ No downloads found │
╰──────────────────────────────────────────────────────────────────────────╯
─ Checking again in 10m..
╭──────────────────────────────────────────────────────────────────────────╮
│ No downloads found │
╰──────────────────────────────────────────────────────────────────────────╯
─ Checking again in 10m..
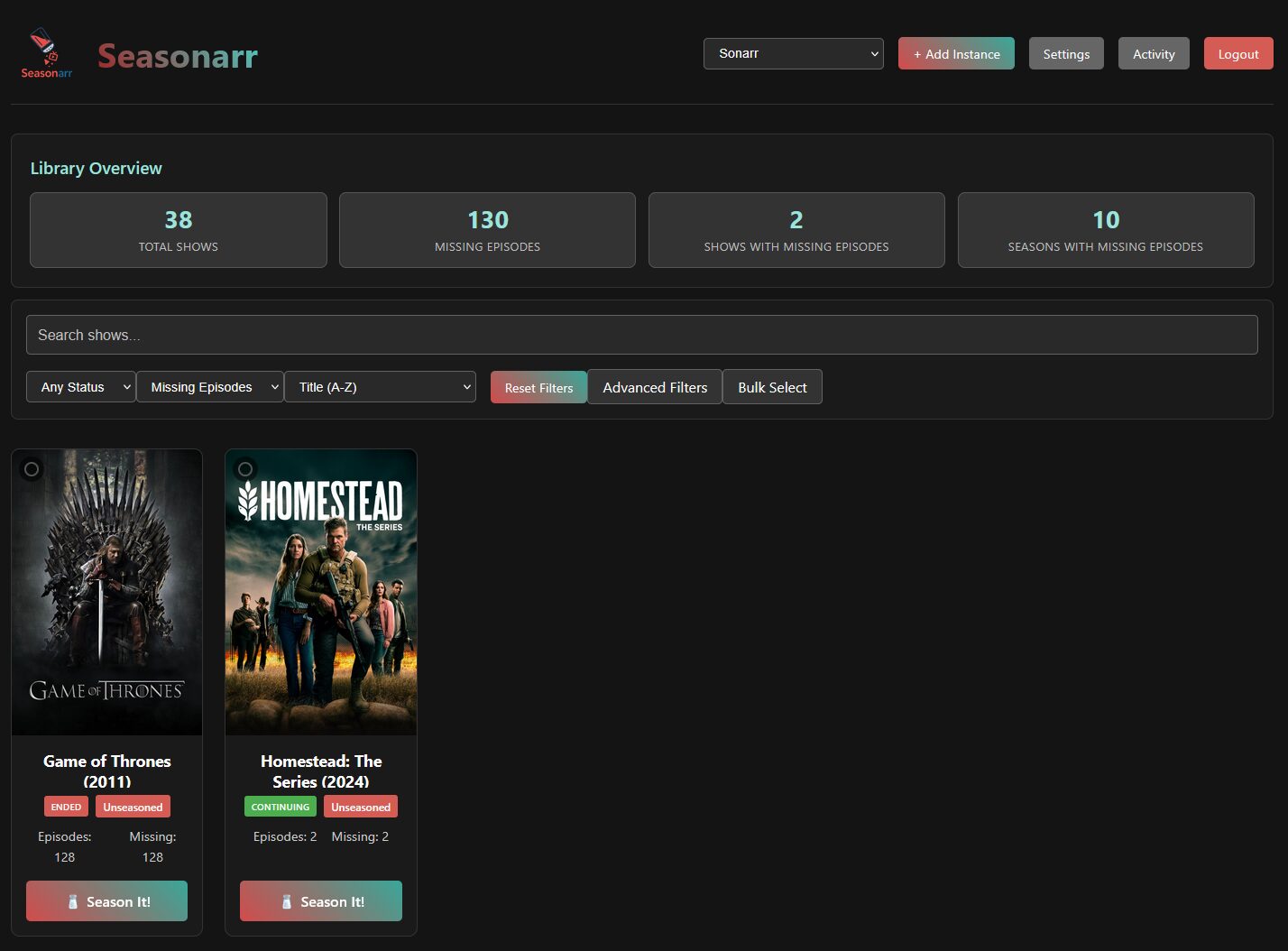
Sonarr est conçu pour chercher automatiquement des épisodes et non des packs. Il peut arriver qu’il manque au moins 1 épisode de saison et c’est… pénible de devoir aller chercher ça à la main. d3v1l1989 a créé SeasonArr qui règle ce problème en permettant de chercher un pack de saison puis remplacer les épisodes déjà télécharger. Cet outil, en 1 clic, remplace la recherche interactive de Sonarr.
Mon setup *arrs/Plex étant tout frais, pour ces séries d’articles, il ne me manque rien en dehors d’épisodes non parus en MULTi/VF donc mes screen ne seront pas révélateurs. « pas de bol »
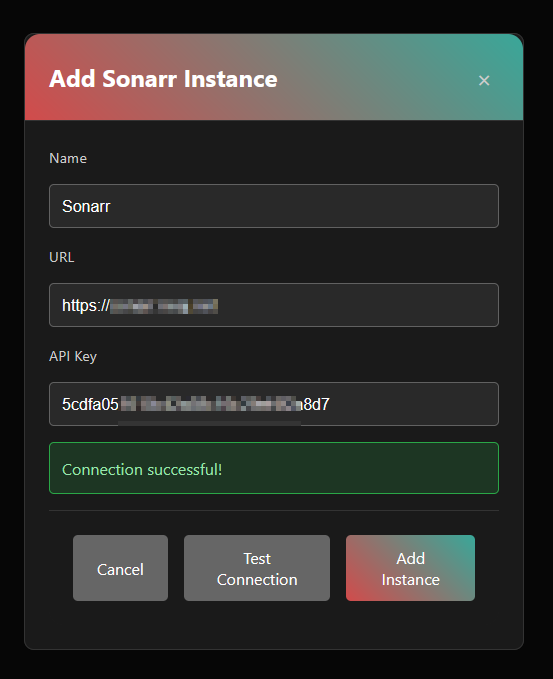
Il faut préalablement créer une clé JWT soit en console si nodejs est installé (sudo apt install nodejs) soit via ce site par exemple.
Une fois le compte créé on peut lier une ou plusieurs instances Sonarr
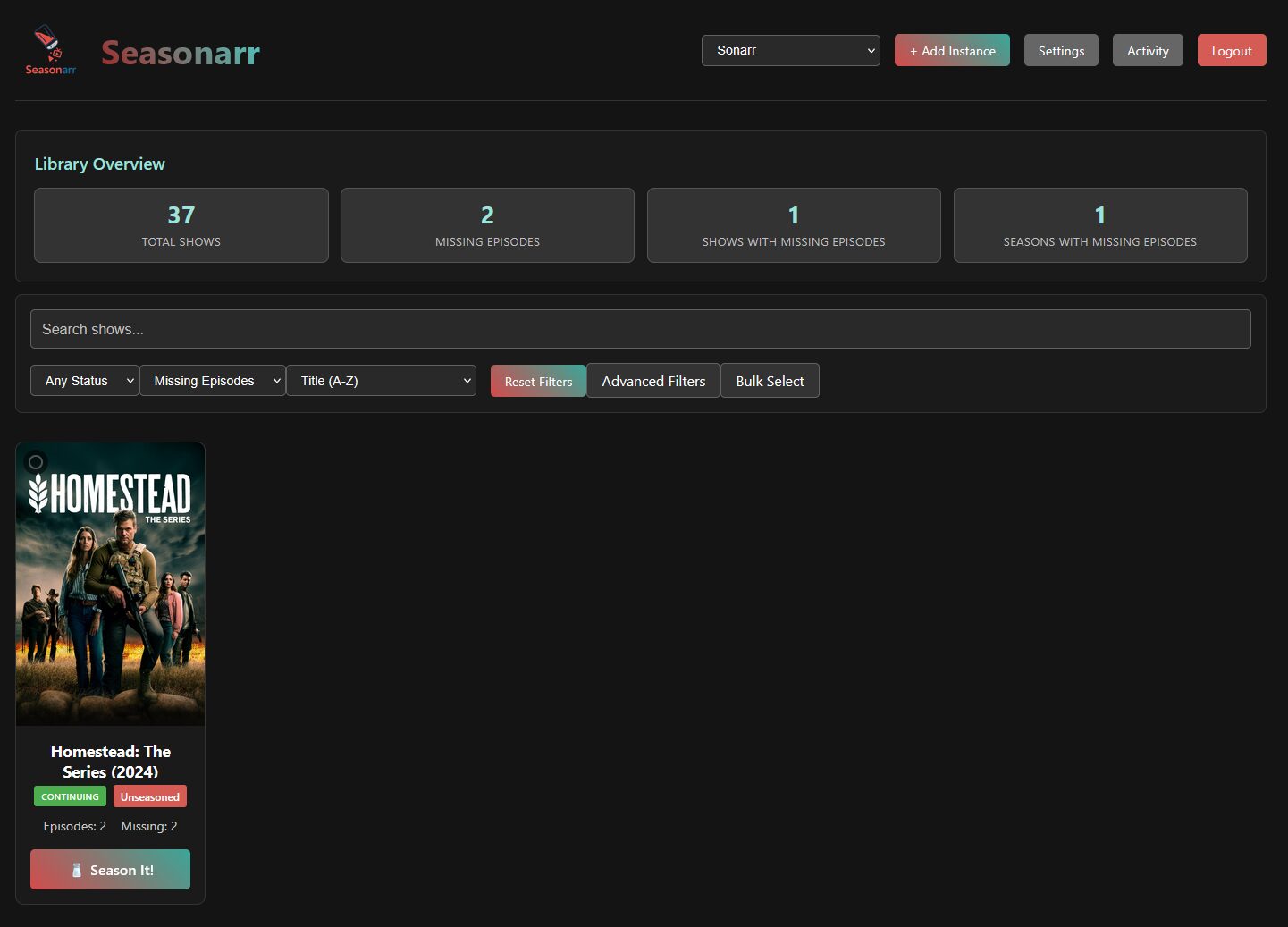
Seasonarr indexe alors les séries et on peut lister celles où il manque des épisodes. Comme indiqué plus haut, mon exemple n’est pas révélateur puisqu’il me manque seulement ces 2 épisodes qui existent en VOSTFR mais non en MULTi/VF comme je les veux.
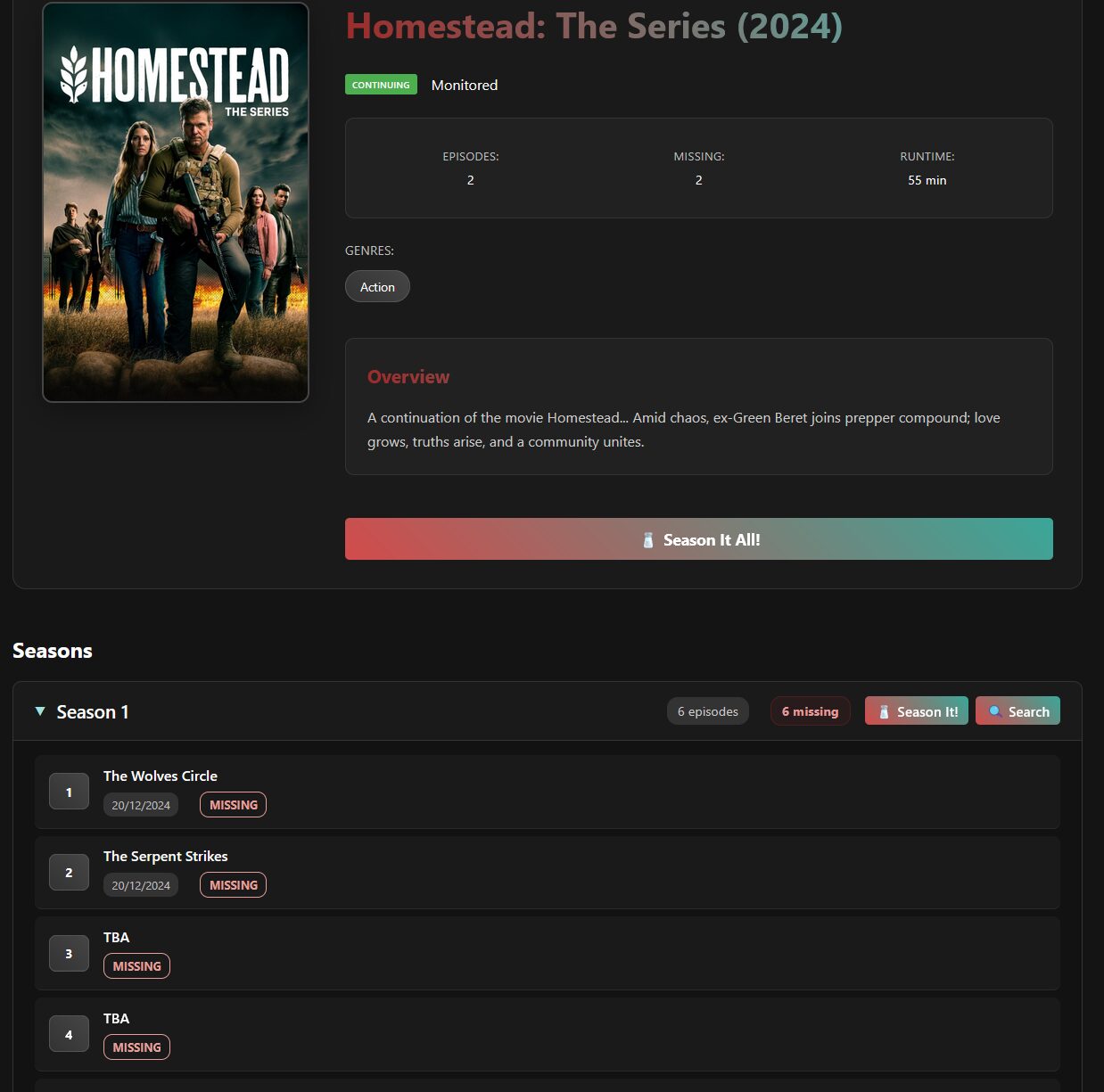
Mais si pour une série il manque des épisodes dans des saisons « parues », on peut alors cliquer sur Season It! et Seasonarr se servira des indexeurs de l’instance Sonarr pour aller chercher des packs complets et remplacer tous les épisodes individuels complétés et manquant pour les saisons sélectionnées. On peut le faire par saison ou pour la série complète.
Il n’y a pas d’automatisation du process vu que ce n’est à faire qu’une fois de temps en temps, en théorie. Les options sont sommaires mais suffisantes.
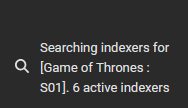
Je viens de faire le test avec Got, je n’ai pas demandé à Sonarr de chercher les épisodes pour passer directement par Seasonarr
Après avoir cliqué sur Season It! (global, pas apr saison), Sonarr s’est bien mis en recherche
J’aime bien avoir une idée des notes IMDB/TMDB des contenus répertoriés par Plex. Kometa, un script Python empaqueté dans un Docker pour plus de simplicité, permet de m’auditer les jaquettes des contenus indexés et créer celles de collections et playlists. On peut presque faire la même chose sur Emby/Jellyfin, avec Posterizarr qui fonctionne aussi pour Plex)
On peut y mettre les infos qu’on souhaite, à l’endroit qu’on veut et créer/afficher ou non les listes par diffuseur etc. Tout est configurable, pour peu qu’on prenne le temps de lire la documentation.
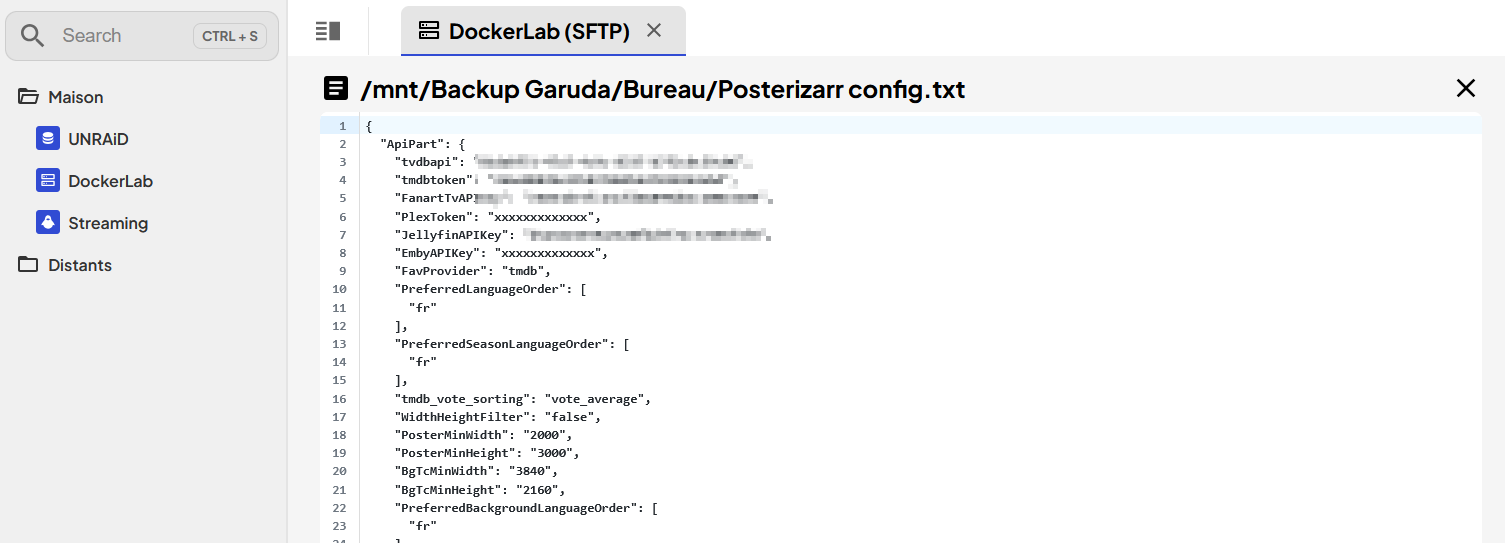
Je partage ma configuration actuelle, qu’il faudrait encore peaufiner, et vous pouvez en trouver d’autres ici ou là.
Voici un Docker qui fonctionne très bien. Au besoin, pour UNRAiD, Synology, QNAP, Kubernetes, la doc est complète.
Et voici mon config.yml Il faut le domaine Plex + token, les clés API TMDB, FanART et MDBlist. Je voulais tester les playlists, pas encore pris le temps…
Attention, dans la partie « libraries » les noms des librairies doivent être ceux de Plex, ici Films et Séries TV
Je continue mon tour d’horizon des solutions de streaming à la carte, légales ou non selon les pays, et qui permet de se créer et maintenir une bibliothèque multimédia sans stockage local.
Je n’aborderai pas publiquement les solutions de streaming depuis des .nzb directement.
Je vais détailler ici l’installation manuelle de Decypharr, Prowlarr et Radarr/Sonarr/Plex mais tout est notamment inclus dans le script SSDv2 (avec une grosse et belle nouveauté à venir).
J’en profite pour remercier Laster13 et Teal-C pour leurs réponses à mes questions.
La dernière mouture de Decypharr embarque rClone et sa configuration sera automatisée. Mes tests sont réalisés avec Prowlarr et des indexeurs FR publics dont YGG via « api.eu », le débrideur AllDebrid ; et je ne « tape » que dans le contenu en cache chez AD (donc aucun téléchargement). Verdict : RàS pour les films, quelques saisons de séries manquantes uniquement dans le cache, OK avec le téléchargement.
Le plus important est de bien comprendre que si on demande aux *arrs d’organiser les bibliothèques dans /mnt/Bibliothèques, ils ne vont y mettre que des symlinks vers le montage rClone d’AllDebrid (/mnt/decypharr). Les *arrs, pour traiter les fichiers, tout comme Plex (ou autre) pour leur lecture, doivent avoir accès à ce montage rClone. C’est pourquoi il est impératif de monter ce dossier en volume pour chaque Docker devant y avoir accès.
Bibliothèques : dossier racine pour les *arrs Data/rCloneCache : j’avais déjà le dossier pour autre chose, j’utilise le même
decypharr/alldebrid : montage de mon compte AD decypharr/qbit : dossier de téléchargement (simulé) des fichiers. Les sous-dossiers radarr/sonarr seront ajoutés automatiquement lors de la configuration de Decypharr (tags)
Il faut installer et lancer Decypharr avant le reste vu que tout dépend ensuite du montage du débrideur et des symlinks. Idem s’il faut relancer le Docker Decypharr, il faut relancer les autres ensuite.
/mnt/decypharr/qbit:/mnt/decypharr/qbit étant le montage qui sera commun aux *arrs et Plex.
La configuration n’est pas vraiment expliquée dans la doc, la mienne n’est peut-être pas optimale mais fonctionne.
Je n’ai rien modifié dans l’onglet général. J’ai testé les notifications Discord (attention on voit la passkey des trackers utilisés) mais y’a vraiment pas d’intérêt si on ne fait qu’utilise le cache du débrideur (pas de téléchargement).
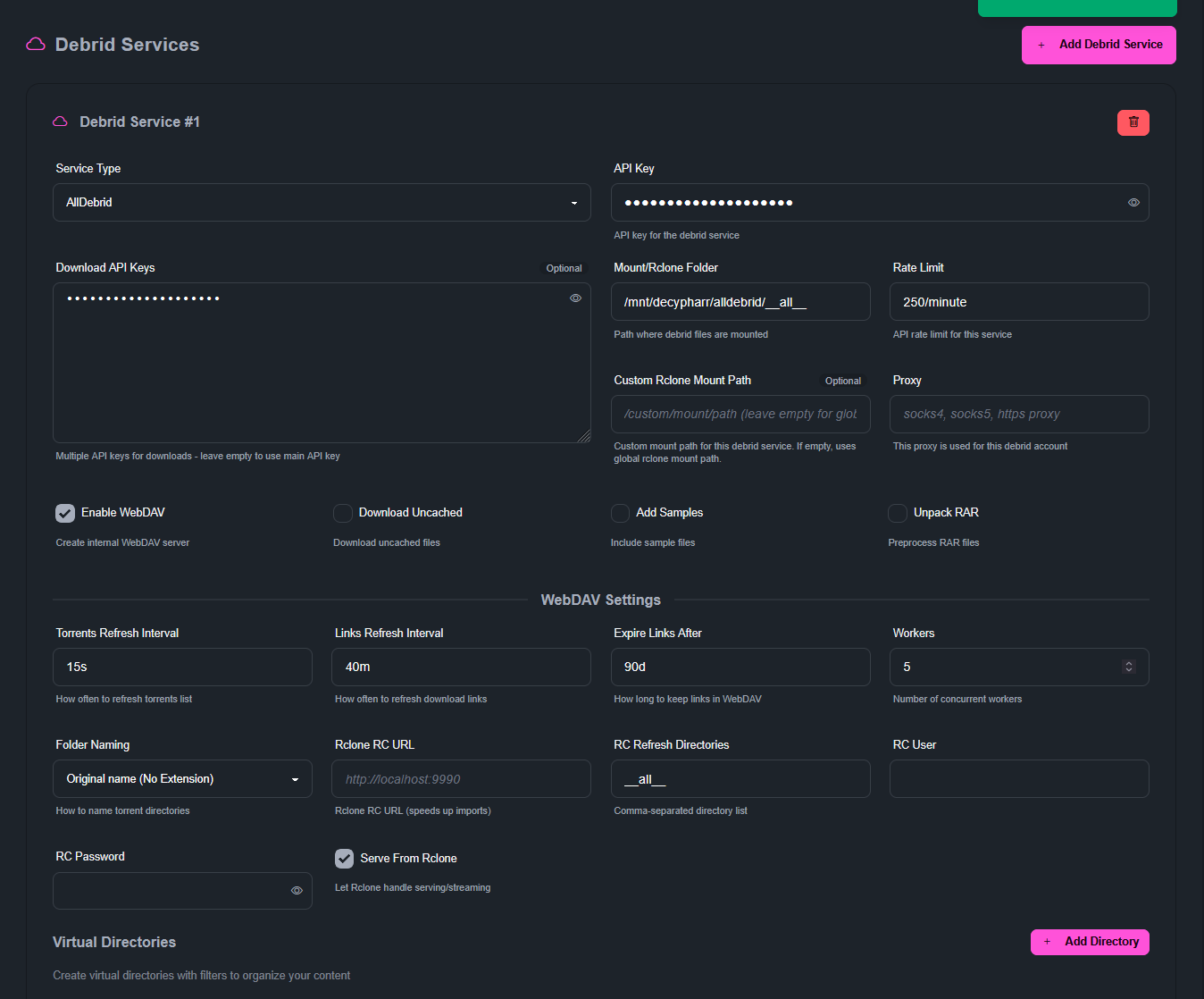
Pour la partie débrideur, on fait notre choix, on colle une clé API (ou plusieurs) et j’ai configuré le montage dans
/mnt/decypharr/alldebrid/__all__
On peut ajouter plusieurs débrideurs. On pourra les attribuer à un *arr lié à Decypharr et même les sélectionner lors de l’ajout manuel d’un .torrent
J’utilise le WebDav et je NE COCHE PAS la case Download Uncached pour qu’il ne télécharge aucun fichier (sur AD) mais n’utilise que son cache. Je fais ça parce que je voulais tester le cache d’AD et ne voulais pas télécharger des fichiers sans les partager. On peut tout à fait faire les 2 mais attention, il n’y aura pas de seed (donc ratio 0). A ne pas faire chez les Tier 1 sous peine de voir son compte banni ! Certains ont créé des scripts qui captent les .torrent utilisés pour les mettre en seed depuis un client local ou sur un serveur. Dans ce cas, Decypharr est utilisable sans crainte sur les trackers privés.
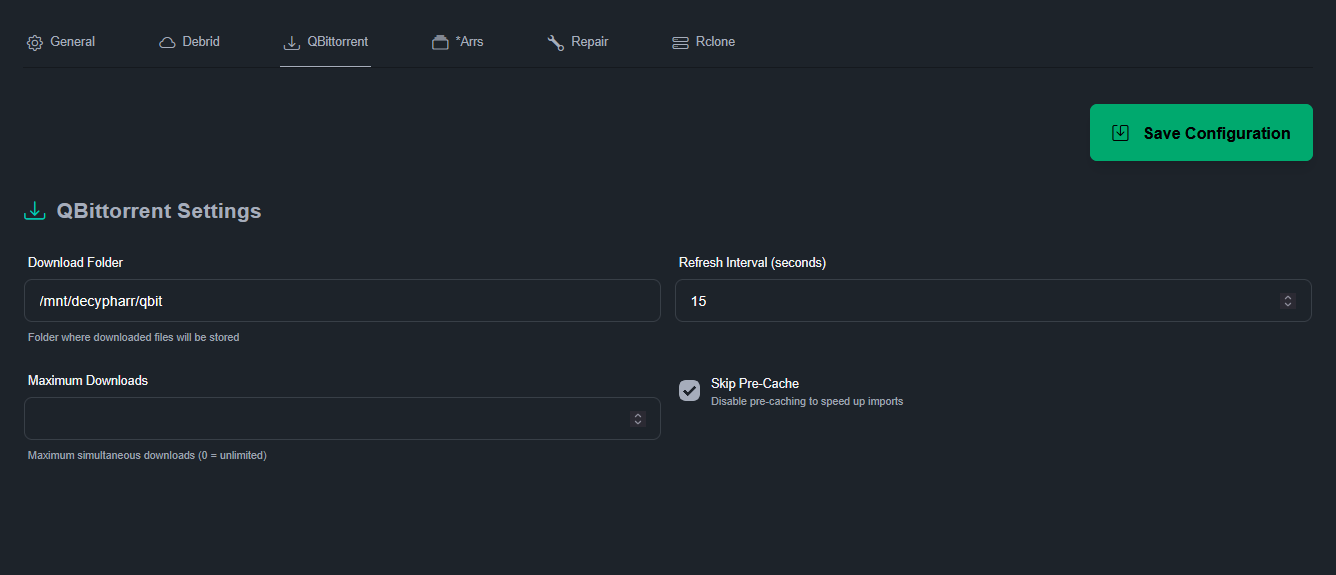
Configuration du client qBittorrent émulé. Je met le chemin qui correspond au volume local dont je parlais au début
/mnt/decypharr/qbit
On peut ajouter les *arrs soit depuis Decypharr soit depuis les *arrs eux-mêmes. Je n’ai qu’AD en débrideur j’ai donc laissé la sélection auto mais on peut choisir. Par exemple Radarr sur AD et Sonarr sur RD ou Sonarr4K sur TB etc. Selon les goût de chacun. Ce qui est certain, c’est que le cache de contenu MULTi/FRENCH est évidemment plus important sur AD et RD que sur TB, principalement utilisé par les anglophones pour Stremio.
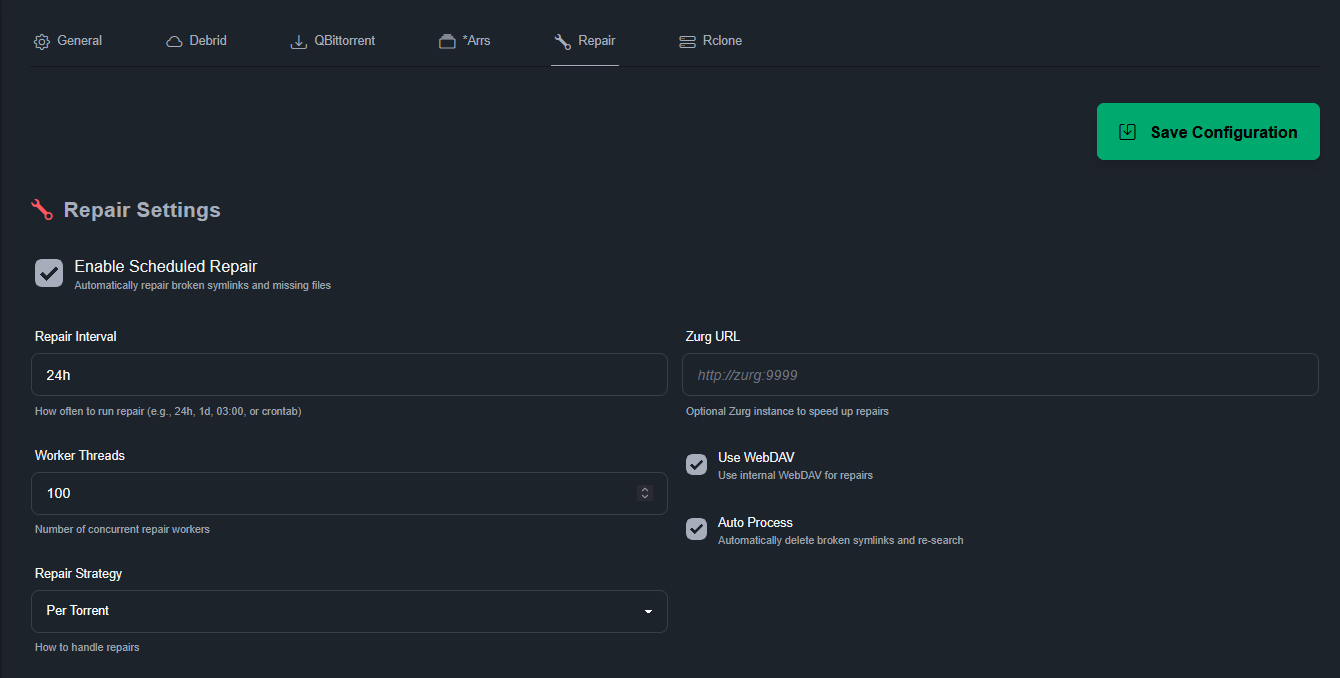
Le Repair est le contrôle et la réparation des symlinks. Qui peuvent être cassés si le contenu lié est effacé du débrideur. Dans ce cas, selon la config, ça peut soit rechercher sur le débrideur (si le fichier a été renommé, vu que ça fonctionne avec le hash et non le nom) soit ça ira chercher un autre .torrent via les *arrs. Pour l’instant je laisse l’option par défaut à savoir « per torrent » mais il est peut-être préférable d’utiliser « per file ». Dans le cas d’un .torrent de saison complètement, que ça ne recherche que l’épisode manquant (du cache) plutôt que de tout relancer. Je l’ai mis en autotmatique, toutes les 24h.
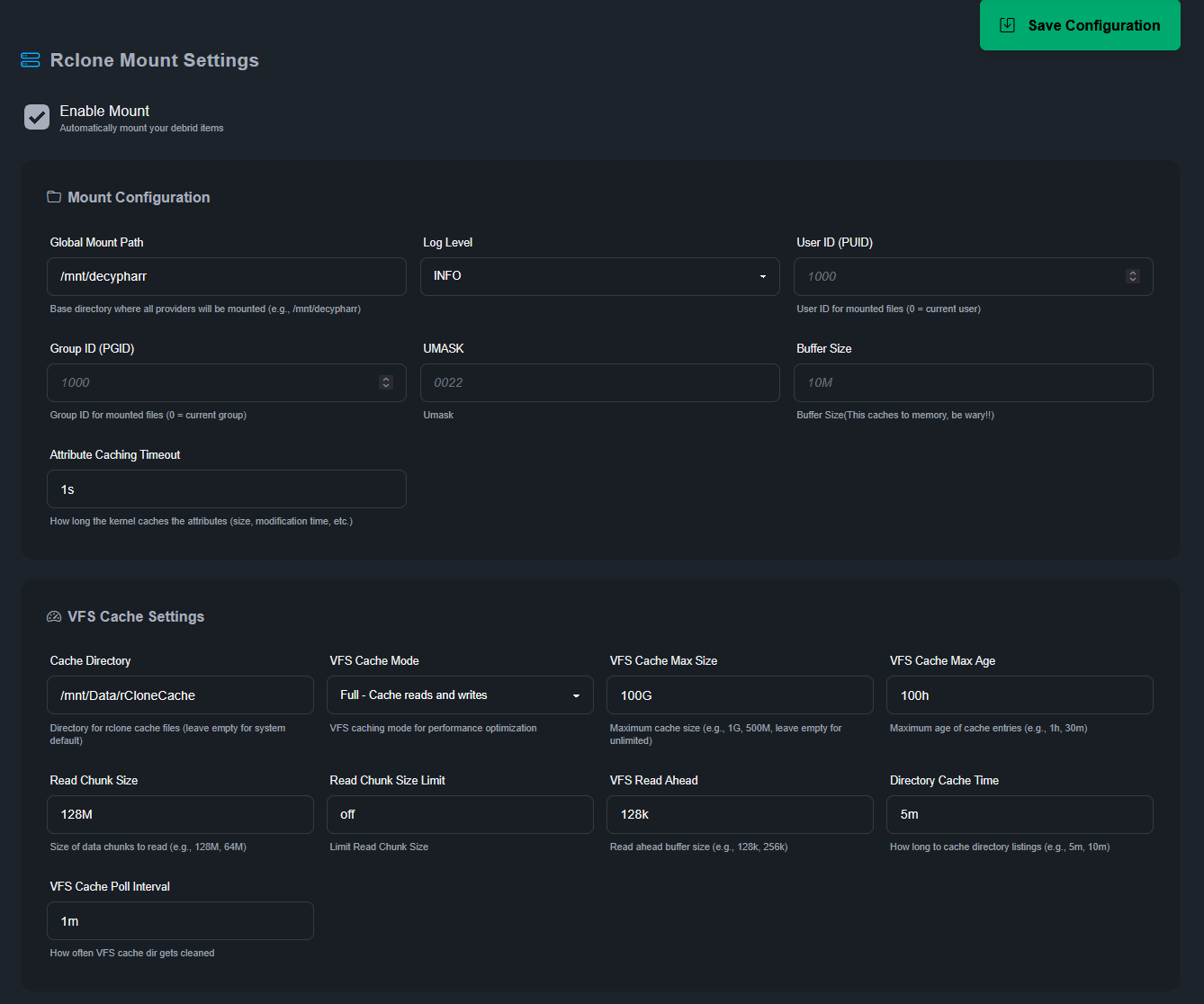
Et enfin la partie rClone. Le monte globalement dans /mnt/decypharr et souhaite utiliser un cache (100Go) dans un dossier (et disque) qui me sert déjà à ça : /mnt/Data/rCloneCache On peut sans doute améliorer cette configuration mais Plex lit un fichier de 94Go sans broncher…
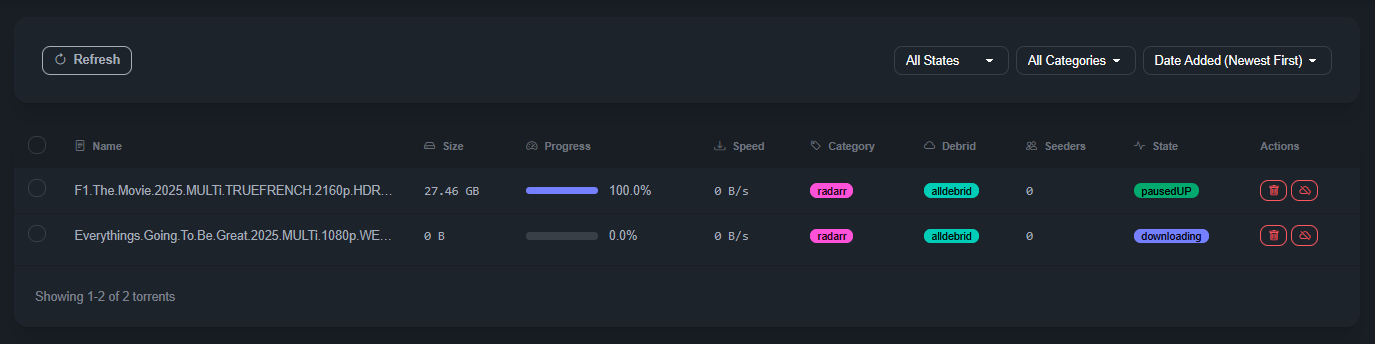
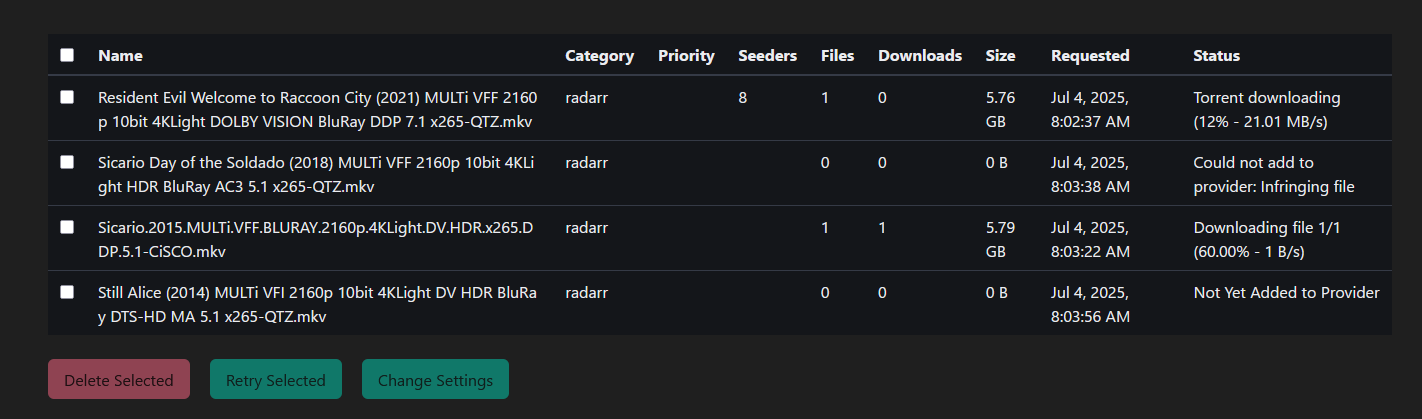
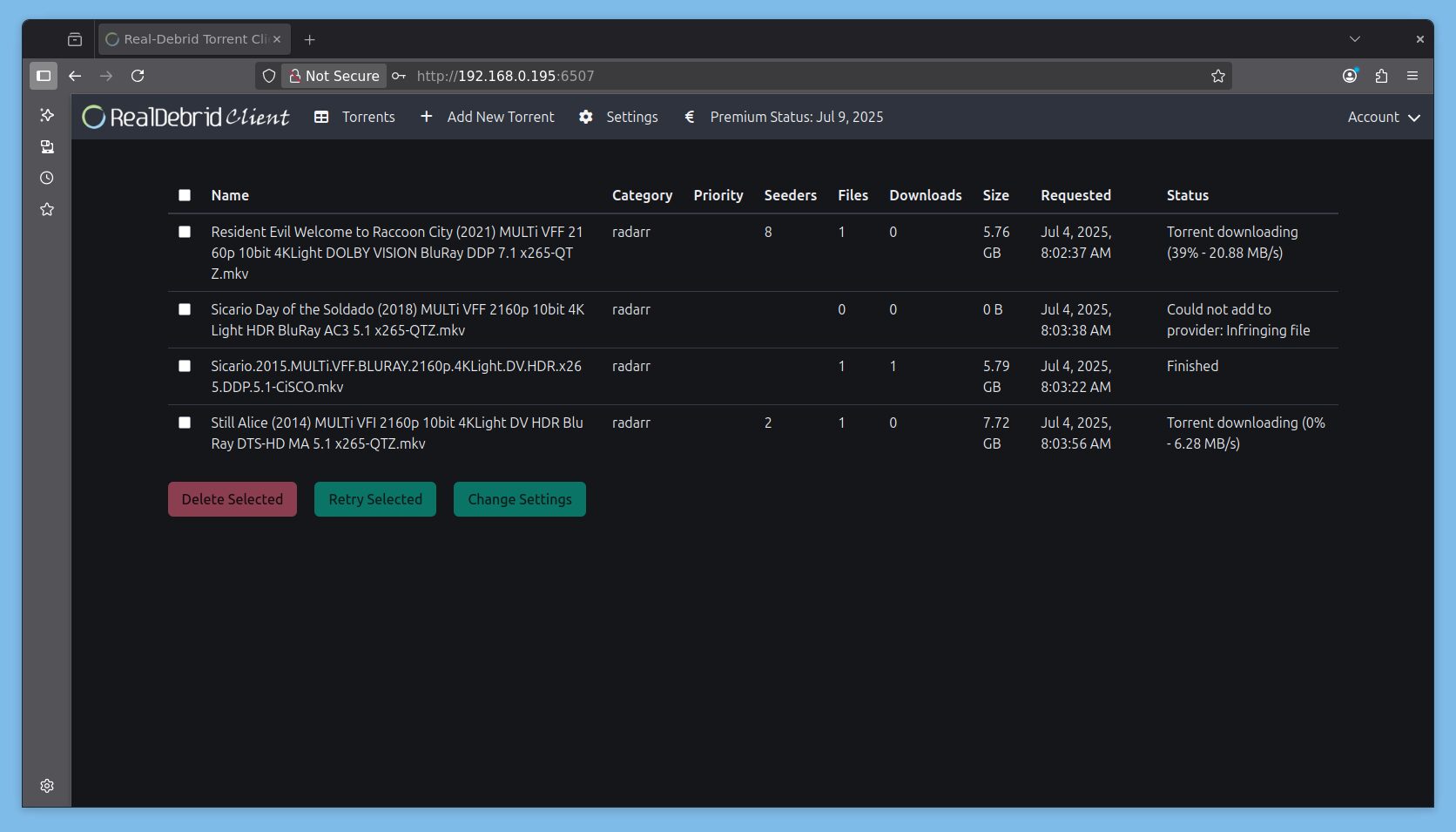
Avec le mode de téléchargement activé, voici le rendu. PausedUP signifie que le .torrent est complété (et de fait plus en seed).
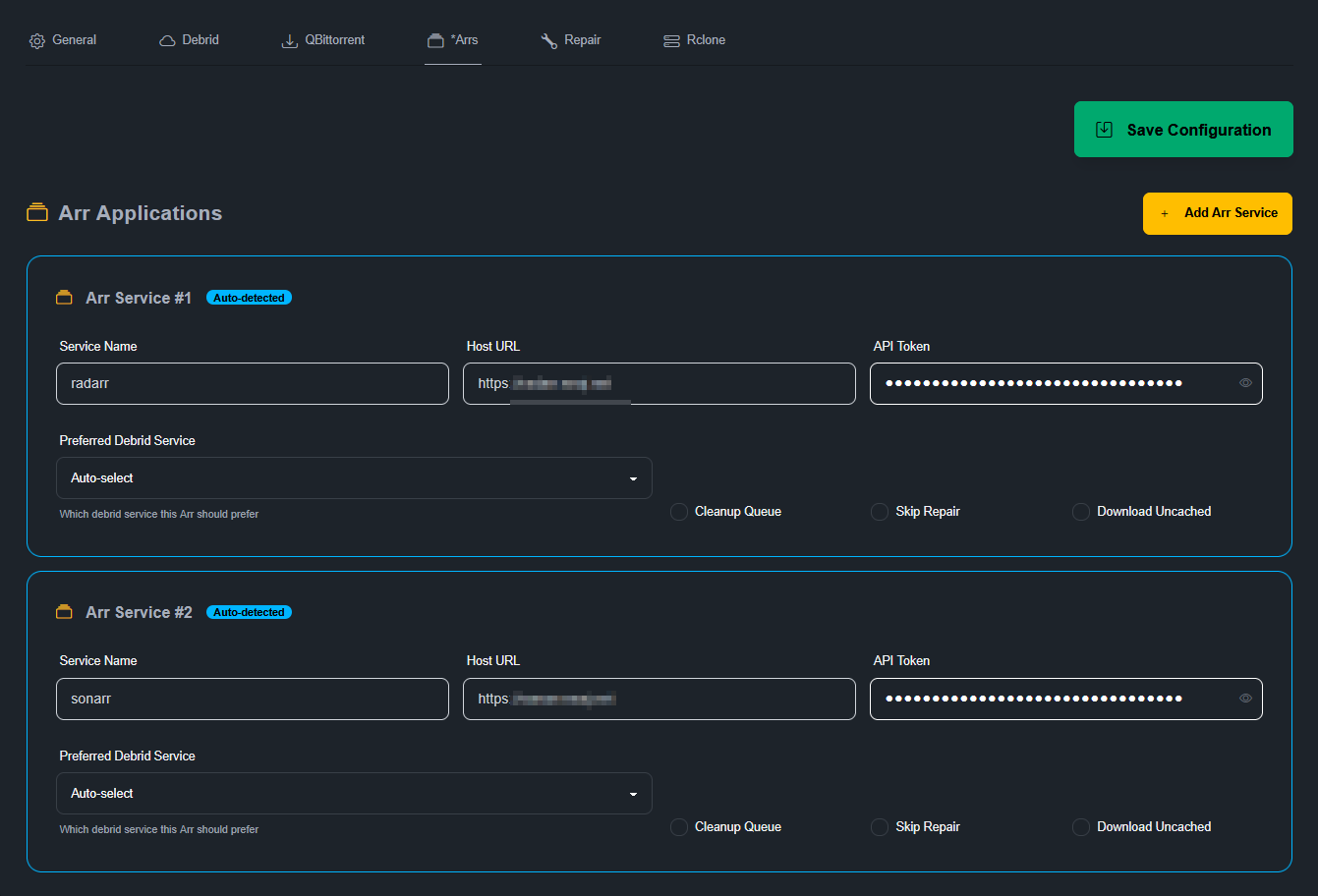
Je ne montre que l’exemple de configuration de Radarr. Pour Sonarr c’est la même logique. Chez moi c’est derrière un VPN pour des interrogations de sources hors Prowlarr et NZBHydra, il n’y a donc pas de port de publié. Je retire tous les volumes par défaut pour ne monter que /mnt/decypharr/qbit:/mnt/decypharr/qbit et /mnt:/mnt
Configuration du dossier racine : /mnt/Bibliothèques/Films
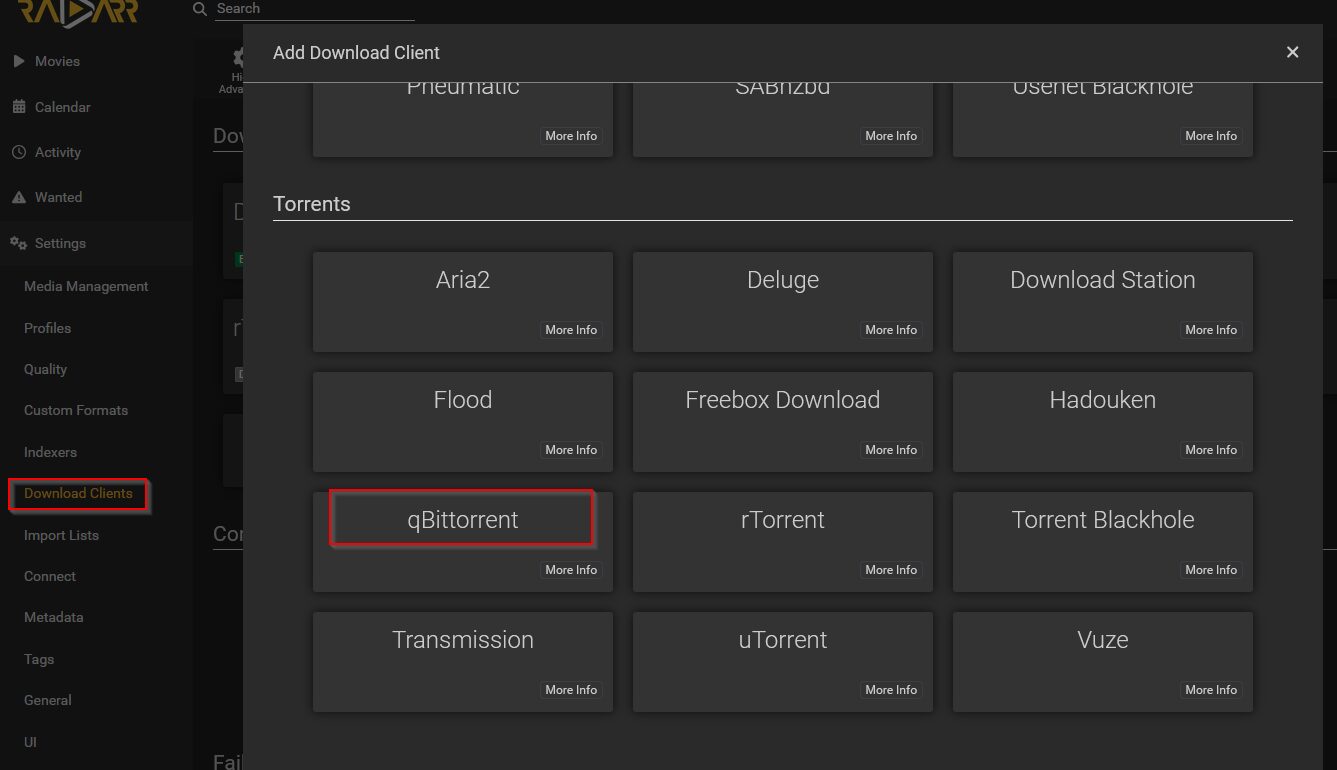
Configuration du client de téléchargement si on n’a pas ajouté Radarr depuis Decypharr. Il faut sélectionner qBittorrent
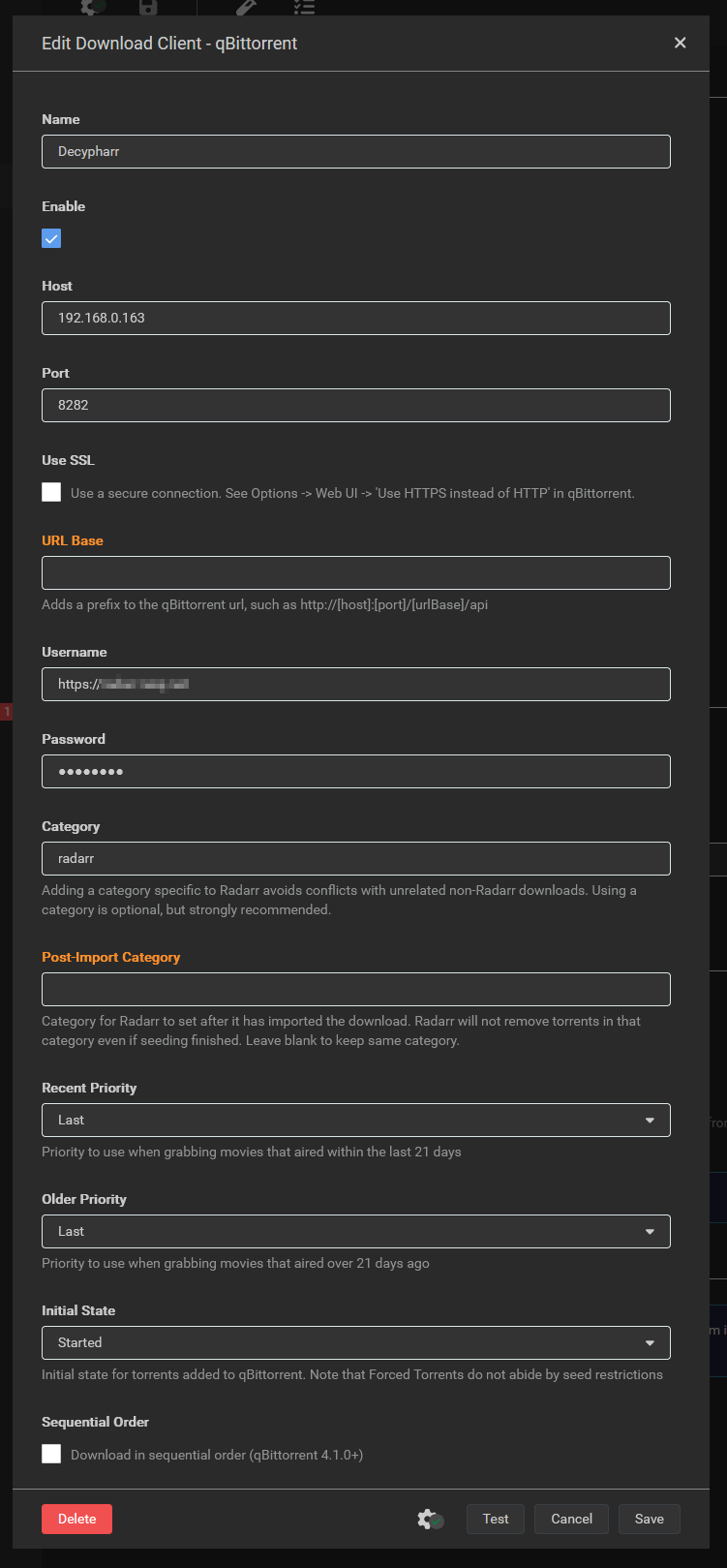
Et dans l’adresse il faut mettre l’URL (ou l’IP) de Decypharr et le port (et SSL si vous utilisez une URL et un reverse proxy). Le nom d’utilisateur et le mot de passe sont l’URL de Radarr et sa clé API. La catégorie : radarr (et donc sonarr pour Sonarr ofc!)
Ne surtout pas cocher la case Sequential Order (sinon ça DL localement)
Et comme le même chemin/volume est monté dans chaque Docker, il n’y a aucun Remote Path Mapping à mettre
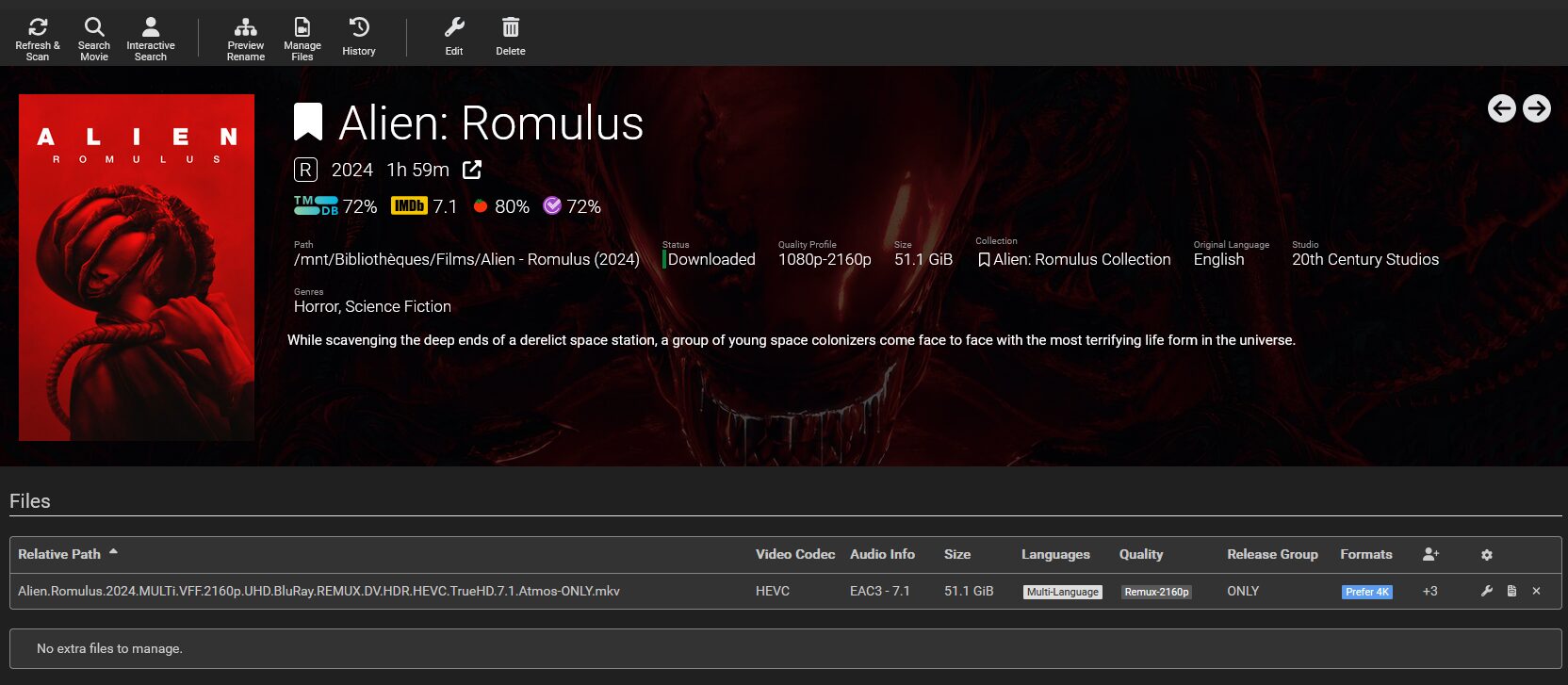
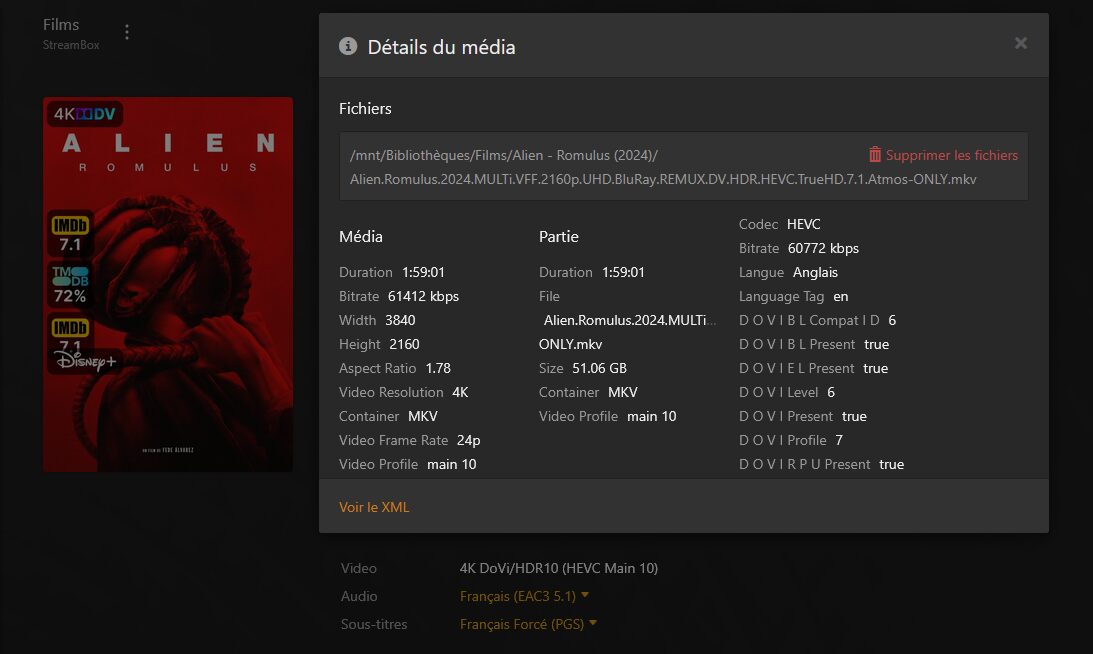
Lors de l’ajout d’un film, la complétion est quasi instantanée pour peu que le fichier cherché soit déjà dans le cache d’AllDebrid. Si vous activez le téléchargement des fichiers non encore en cache, ça peut prendre quelques minutes.
En regardant de plus près, on voit bien que c’est un symlink vers le cache d’AllDebrid
aerya@StreamBox:/mnt/Bibliothèques/Films$ ls -l Alien\ -\ Romulus\ \(2024\)/
total 4
lrwxrwxrwx 1 root root 208 Aug 25 18:55 Alien.Romulus.2024.MULTi.VFF.2160p.UHD.BluRay.REMUX.DV.HDR.HEVC.TrueHD.7.1.Atmos-ONLY.mkv -> /mnt/decypharr/alldebrid/__all__/Alien.Romulus.2024.MULTi.VFF.2160p.UHD.BluRay.REMUX.DV.HDR.HEVC.TrueHD.7.1.Atmos-ONLY/Alien.Romulus.2024.MULTi.VFF.2160p.UHD.BluRay.REMUX.DV.HDR.HEVC.TrueHD.7.1.Atmos-ONLY.mkv
ncdu 1.19 ~ Use the arrow keys to navigate, press ? for help
--- /mnt/Bibliothèques/Films/Alien - Romulus (2024)- ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
@ 4.0 KiB [###################################################] Alien.Romulus.2024.MULTi.VFF.2160p.UHD.BluRay.REMUX.DV.HDR.HEVC.TrueHD.7.1.Atmos-ONLY.mkv
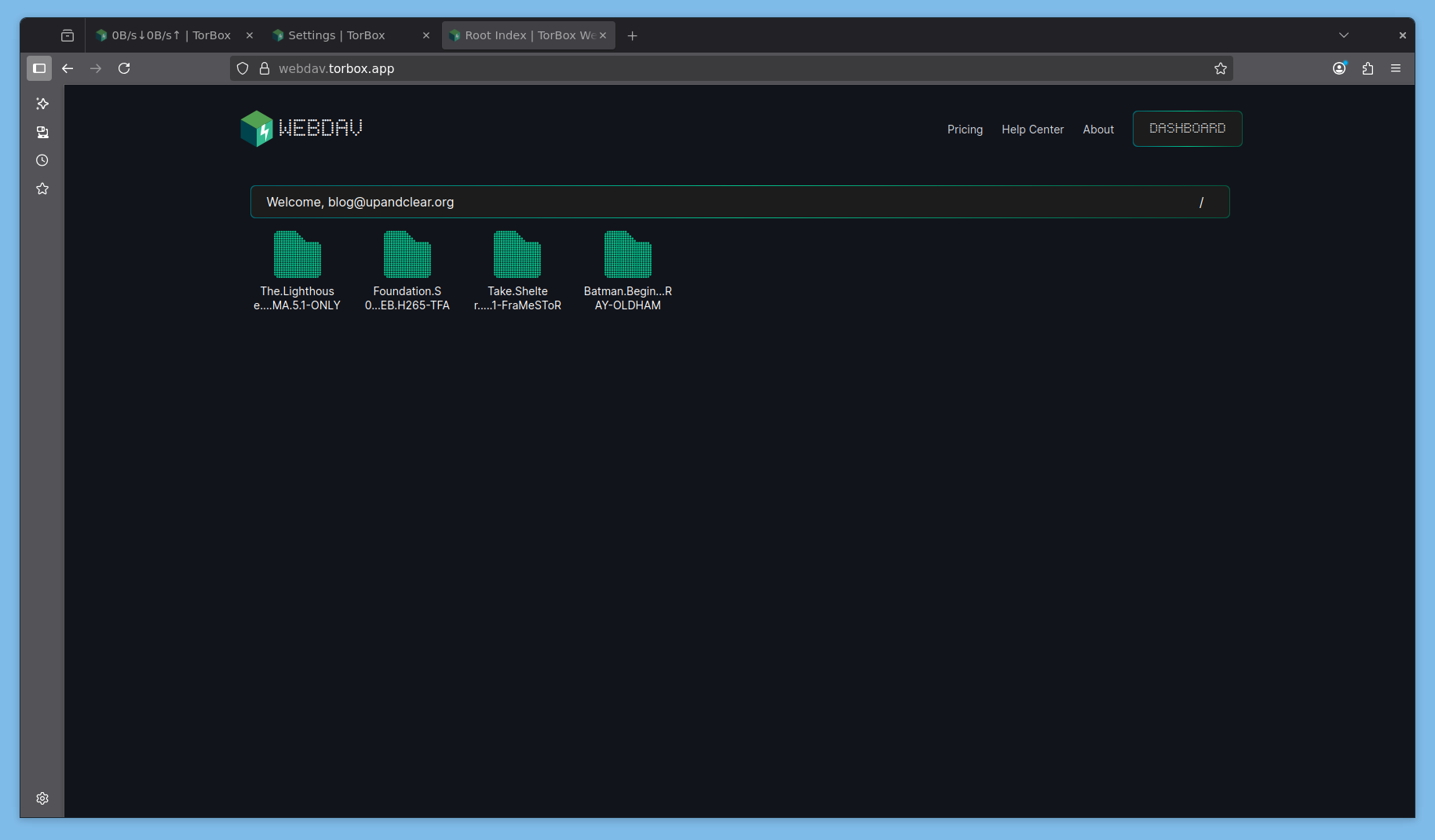
Plus globalement, tous les fichiers sont bien chez AllDebrid, monté via WebDav/rClone et je n’ai localement que des symlinks qui ne prennent aucune place. En théorie, on pourrait se faire cette installation sur une Carte MicroSD de quelques Go
ncdu 1.19 ~ Use the arrow keys to navigate, press ? for help
--- /mnt ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
15.9 TiB [###################################################] /decypharr
4.0 MiB [ ] /Bibliothèques
Pour terminer, la configuration de Plex. Toujours avec /mnt:/mnt de monté pour garantir l’accès aux symlinks.
Gros fan et utilisateur du terminal Asbru-CM, j’ai de temps en temps besoin de pouvoir utiliser ça en mobilité. Je m’étais équipé d’une instance de SSHwifty. Cherchant un terminal, gratuit, à héberger et avec plus de fonctionnalités, mon choix s’est arrêté sur Nexterm qui ne manque pas d’options !
CAUTION Nexterm is currently in early development and subject to change. It is not recommended to use it in a production environment.
Identifiants user:pwd ou clés
2FA
Gestion d’utilisateurs
Gestionnaire de sessions et d’identifiants
SSH, sFTP, VNC, RDP, Proxmox (LXC et Qemu)
Gestion de « snippets », raccourcis de commandes à utiliser en terminal
Gestion de scripts avec raccourcis
Possibilité de déployer des Dockers
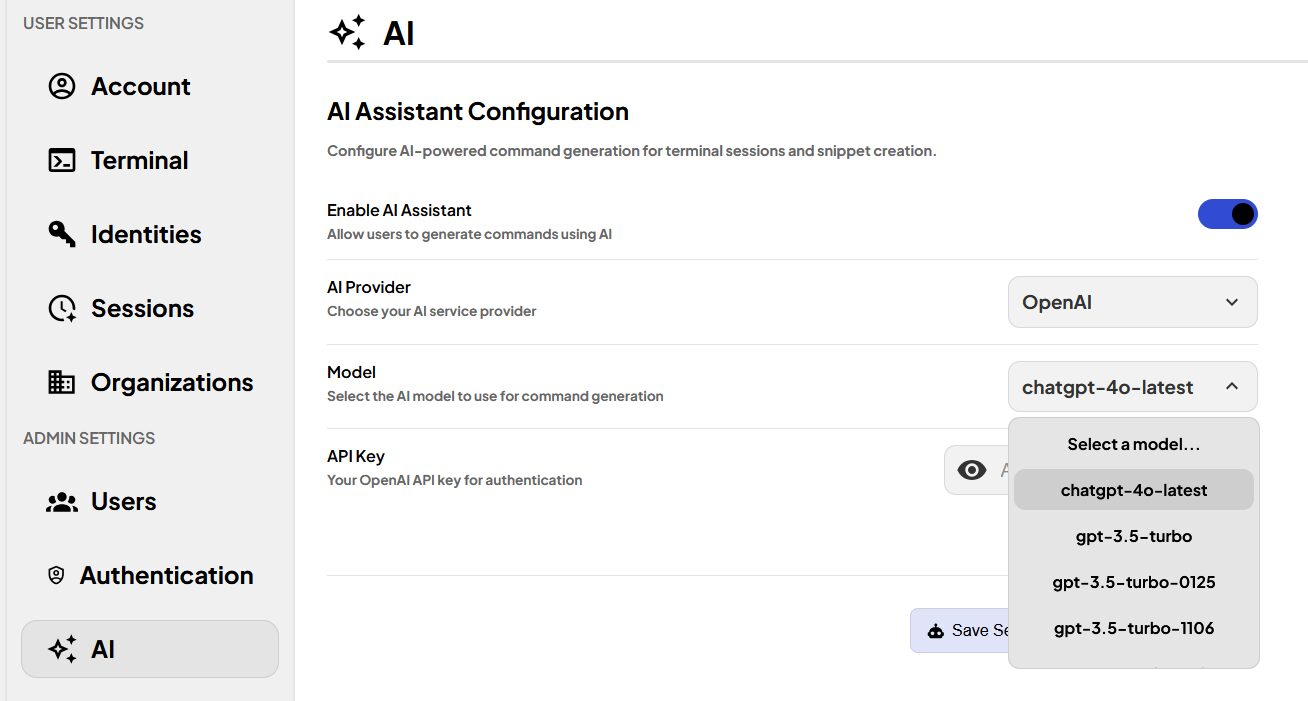
Intégration de l’IA, par exemple via un compte OpenAI pour avoir de l’aide dans un terminal
Options esthétiques…
Ok, tout n’est pas utile évidemment.
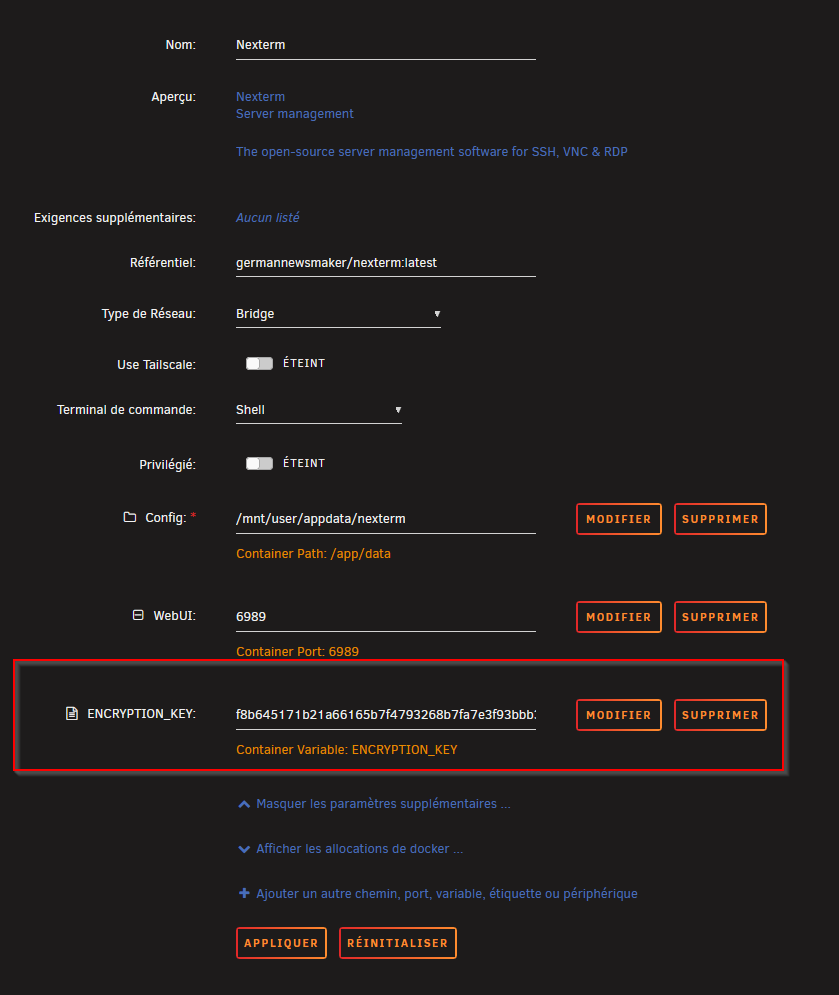
Pour l’installer, il faudra avant générer une clé de chiffrement via openssl rand -hex 32
Aussi disponible via template sous UNRAiD, attention, il manque la variable de clé de chiffrement… Je doute que ça se lance sans d’ailleurs. Il faut ajouter la variable ENCRYPTION_KEY et sa valeur
Une fois un compte créée, on peut paramétrer l’interface
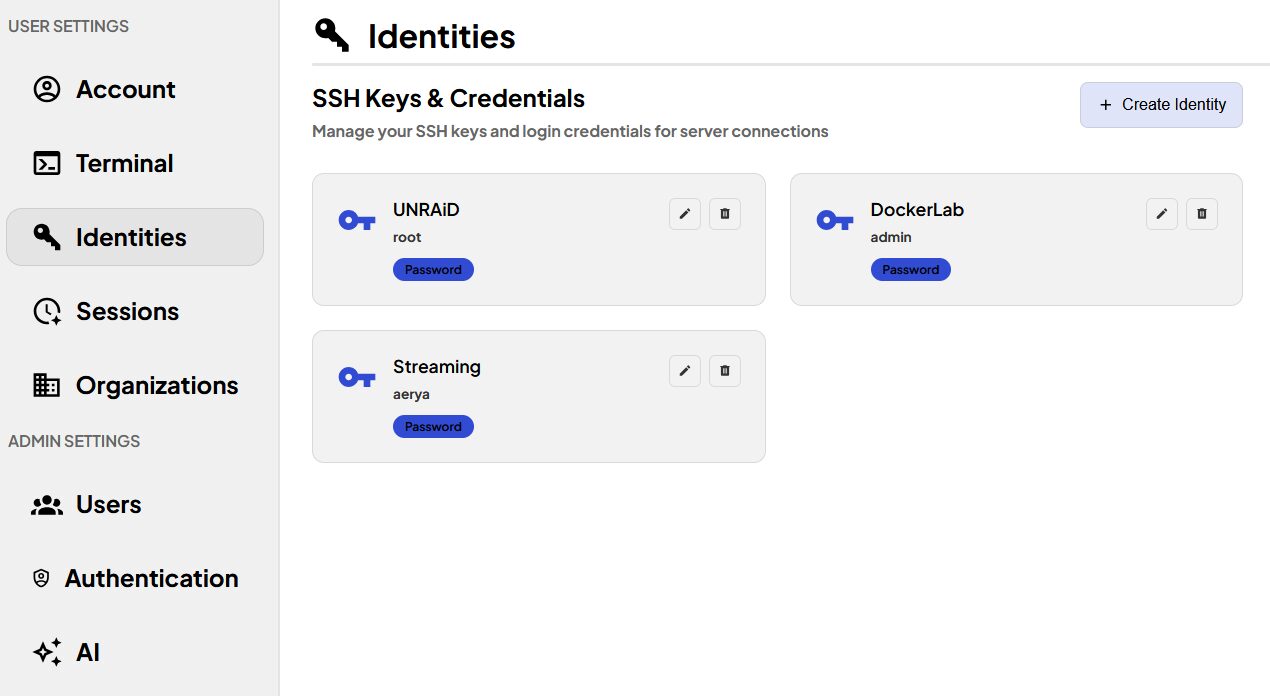
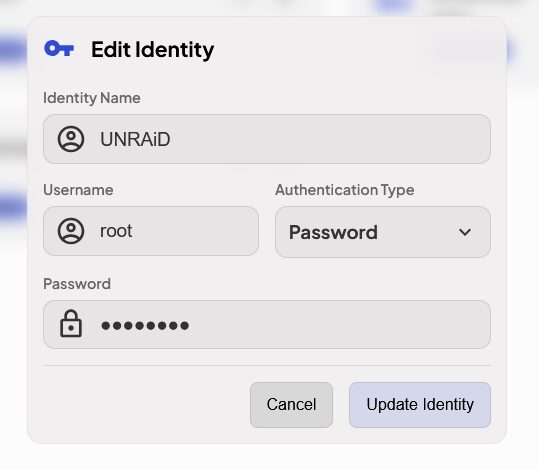
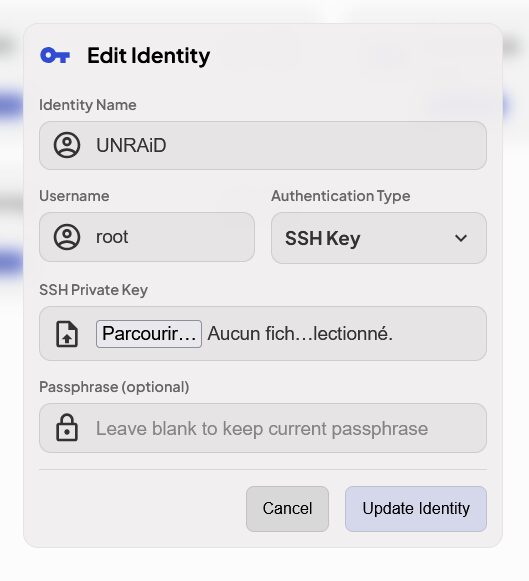
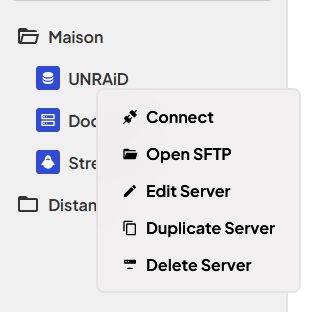
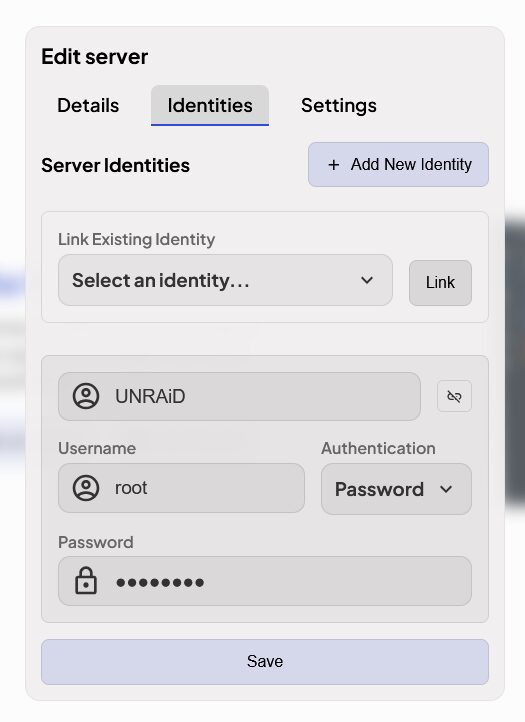
Créer des identités qu’il faudra ensuite lier aux serveurs ajoutés. On peut donc utiliser soit un mot de passe soit une clé SSH.
Comme je l’écrivais, on peut ajouter de l’IA. J’ai testé rapidement, je vous montre ça ensuite.
La partie serveurs, qu’on peut organiser en dossiers, est simple et intuitive.
Choisir ou créer une identité liée
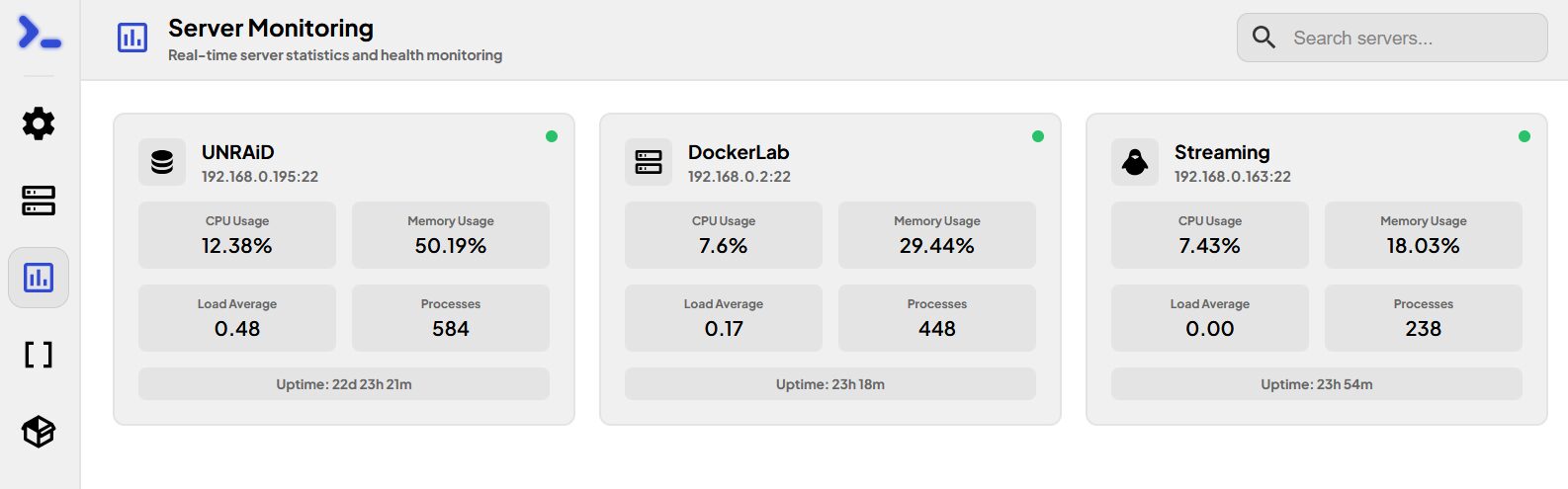
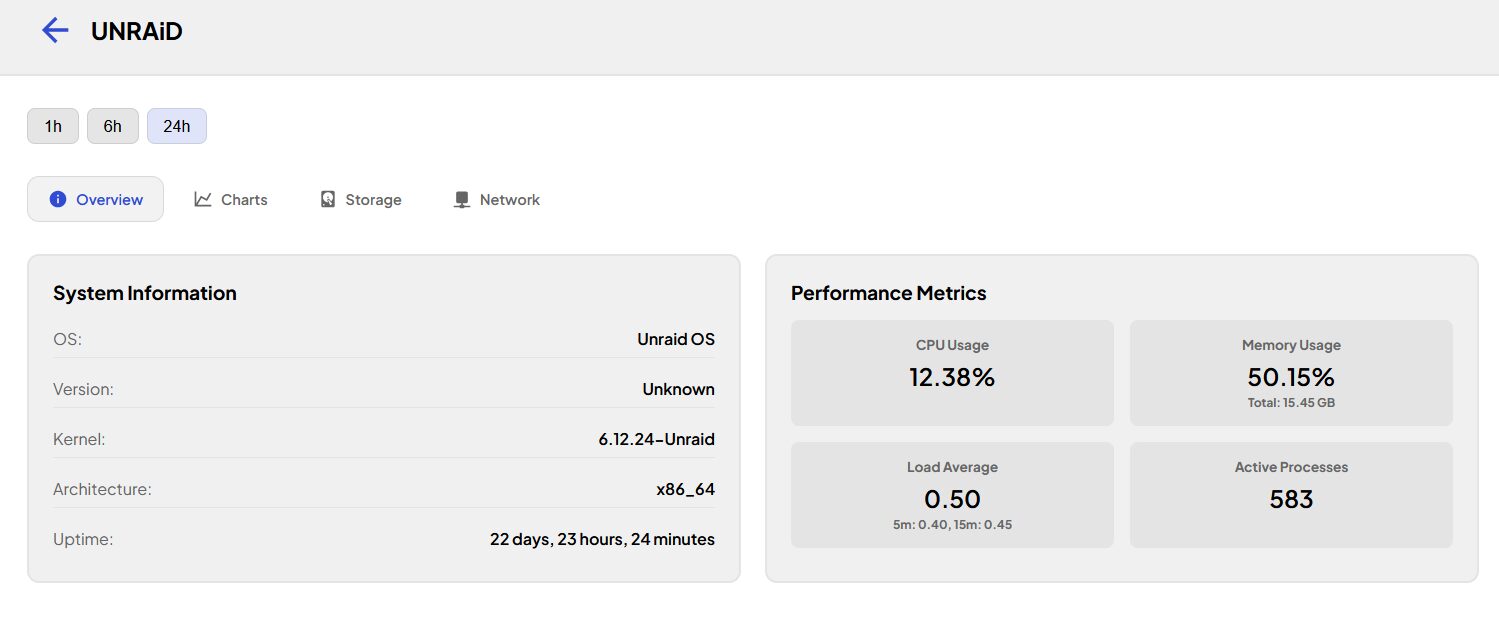
Si on active le monitoring, on l’a sur le panel homonyme avec des infos basiques mais suffisantes. A noter que ça ne me retourne jamais de version de l’OS. Je ne suis pas surpris pour UNRAiD ou Synology mais c’est plus étonnant pour Debian, Garuda (Arch) et Ubuntu. Comme indiqué sur le site, l’outil est encore à un stade de développement peu avancé.
On peut accéder à chaque serveur en même temps, dans un onglet séparé. En revanche attention si un travail est en cours, cliquer sur un autre menu dans le même onglet (du navigateur) ferme toutes les sessions.
Version sFTP, avec téléchargement, création de dossiers, édition/renommage.
On ne peut en revanche pas (encore ?) visualiser de photo ou vidéo. D’un autre côté c’est pas le but d’un FTP…
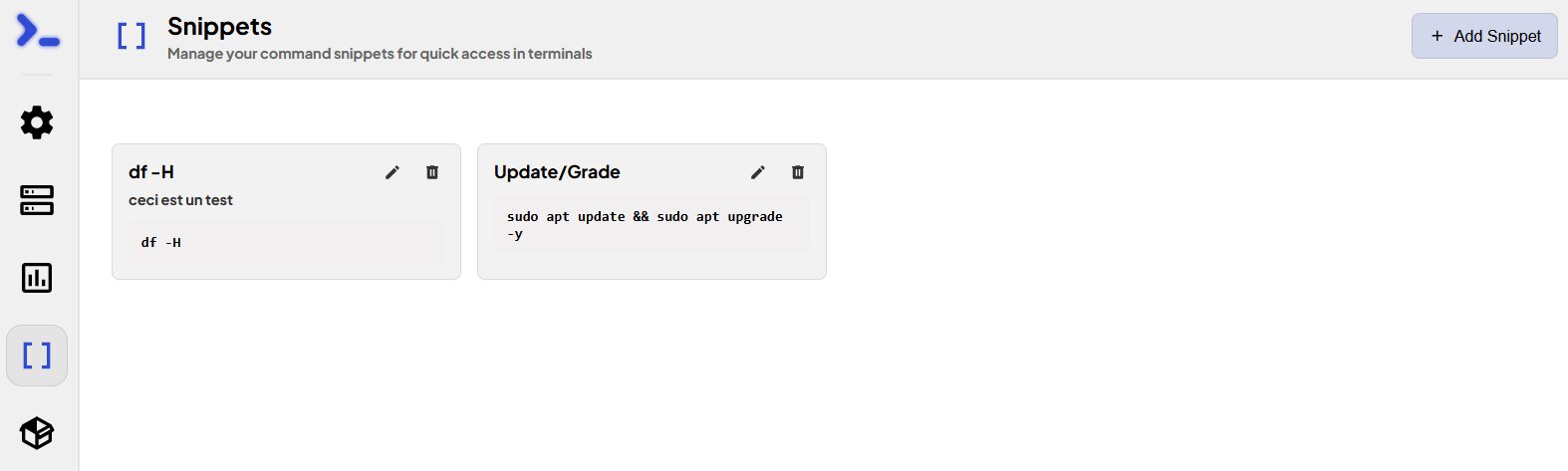
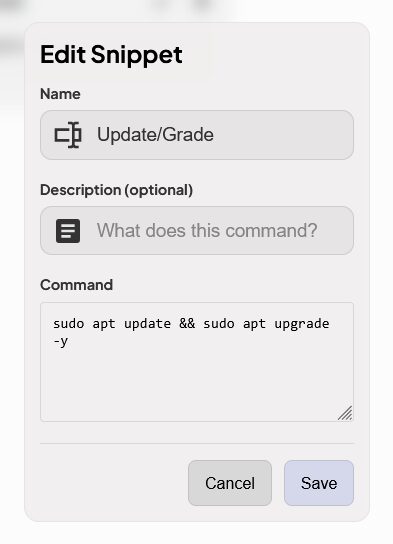
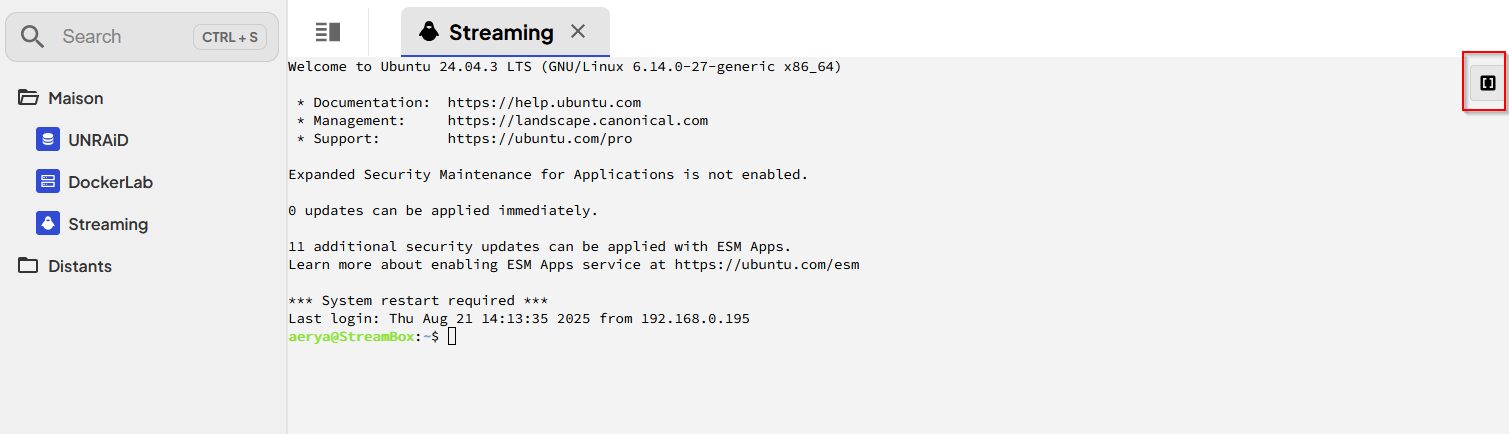
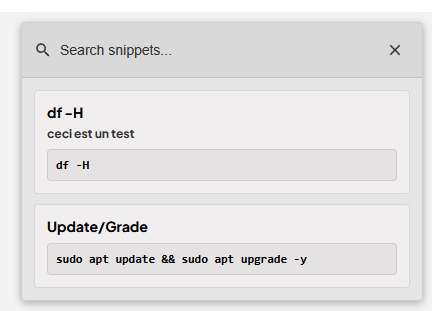
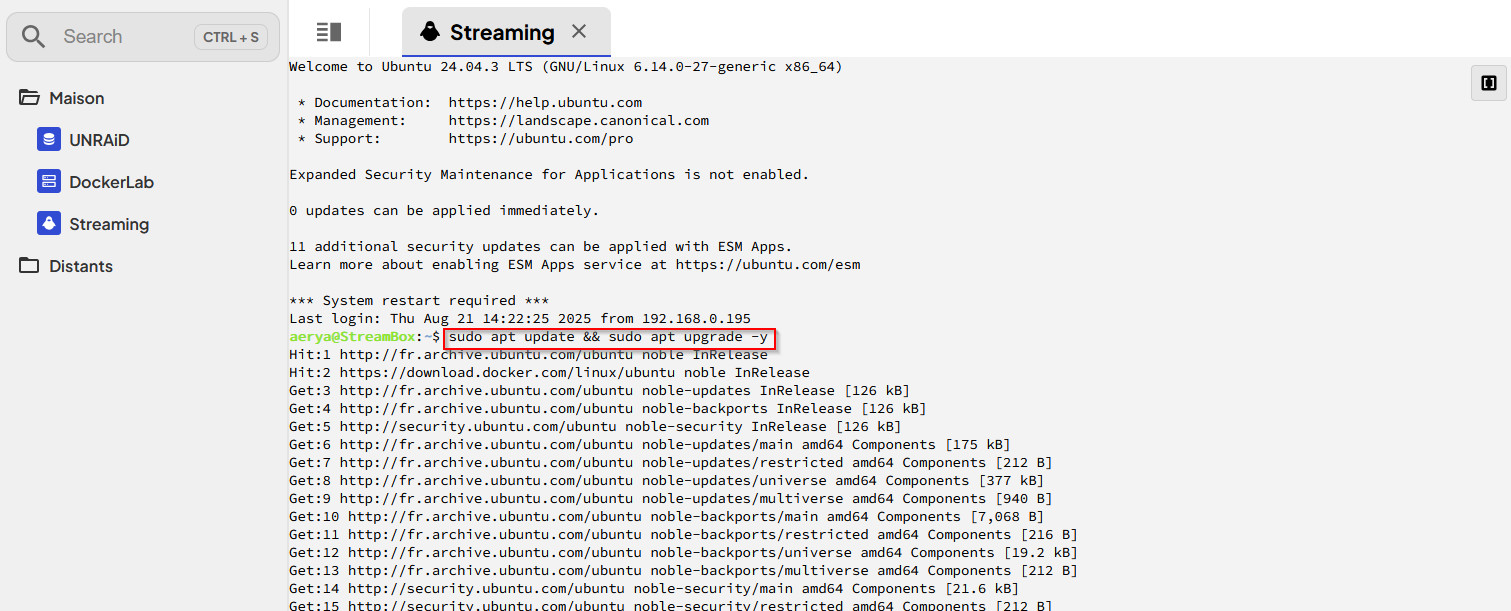
Après les clés SSH, l’une des options que je cherchais absolument était la possibilité de créer des raccourcis (alias) de commandes, qui soient globaux pour chaque terminal (et non ajouter des alias sur chaque machine). Par exemple taper « upgrade » ou cliquer un bouton (cette option avec Nextrem) qui envoie la commande sudo apt update && sudo apt upgrade -y On peut créer les snippets via le menu et ensuite les utiliser avec l’icône en haut à droite du terminal (qui se voit plus ou moins bien selon le thème…). J’ai pris des exemples basiques pour l’instant, j’ai plus testé qu’utilisé.
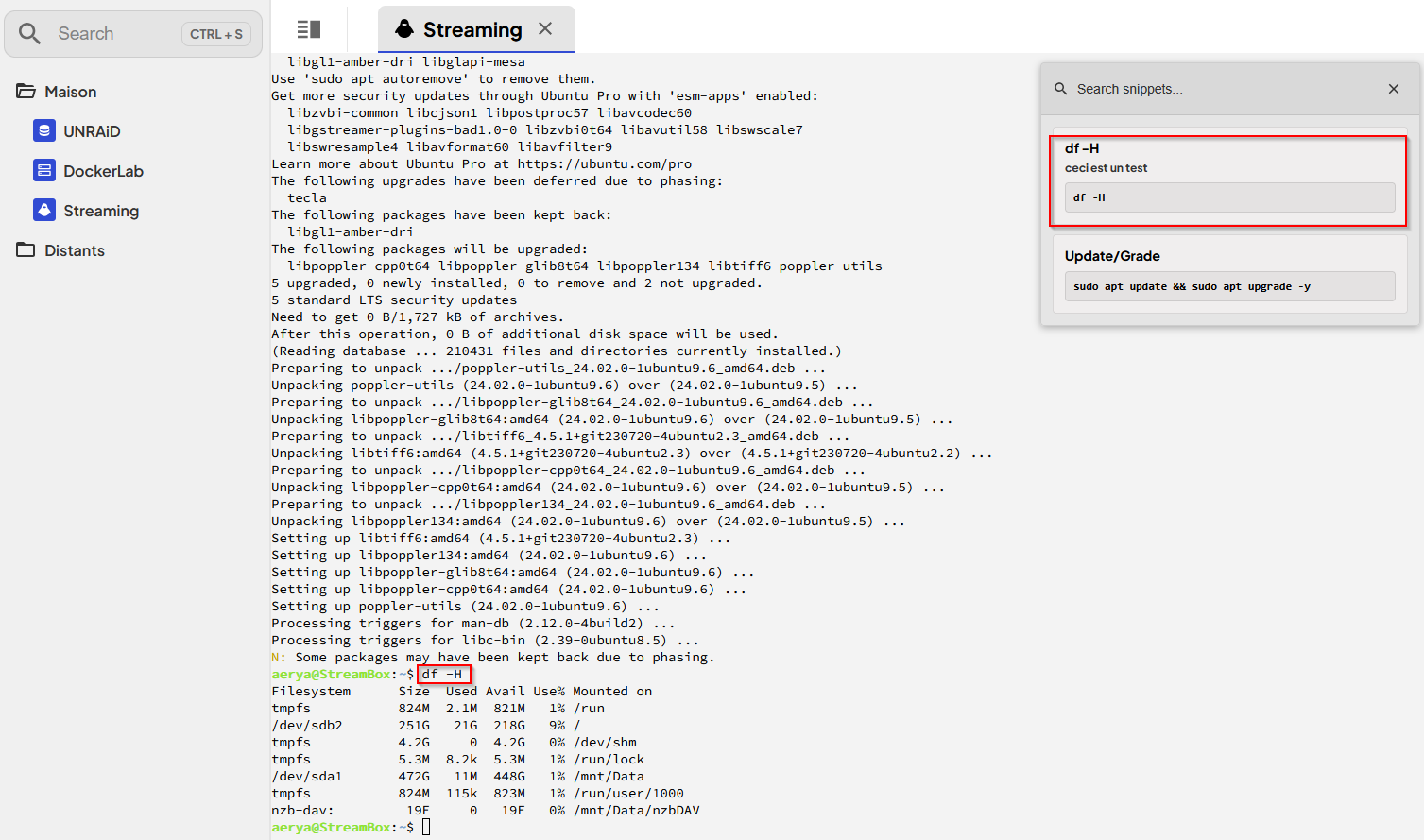
Cliquer sur l’icône des snippets et sur celui qu’on souhaite utiliser
Selon les configurations des users et sudoers, il faut évidemment taper le mot de passe
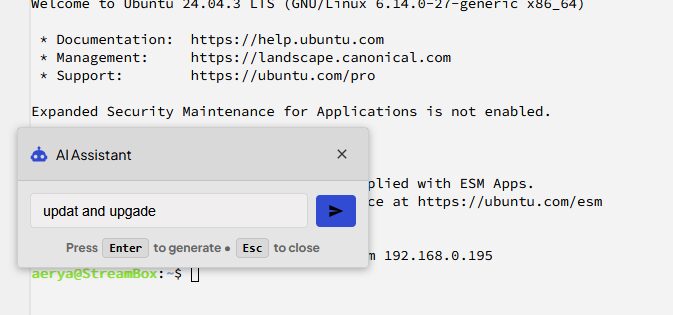
Si l’option d’intégration de l’IA est activée, on y accède depuis un terminal via Ctrl + k. Aucune commande n’est exécutée par l’IA, elles sont juste tapées dans le terminal et l’utilisateur doit l’exécuter.
Je ne suis ni fan ni, du coup, connaisseur, donc j’ai pas testé de demande très compliquée. Même en faisant des fautes dans la demande, elle s’en sort du du basique
Idem pour des installations basiques. Testé sur Arch aussi, c’était bon. Mais je reste sur du très simple.
Semble également fonctionner en français (vu que c’est ChatGPT dans mon test) et l’installation de Docker est correcte. Même si c’est pas optimisé (serveur Apache2n mysql de base etc)
Pour que ce soit « parfait », il faut lui indiquer quels dossiers monter etc. Bref, autant le faire à la main as usual! Mais, encore une fois, je découvre l’IA dans un terminal et ne souhaite pas approfondir cette expérience.
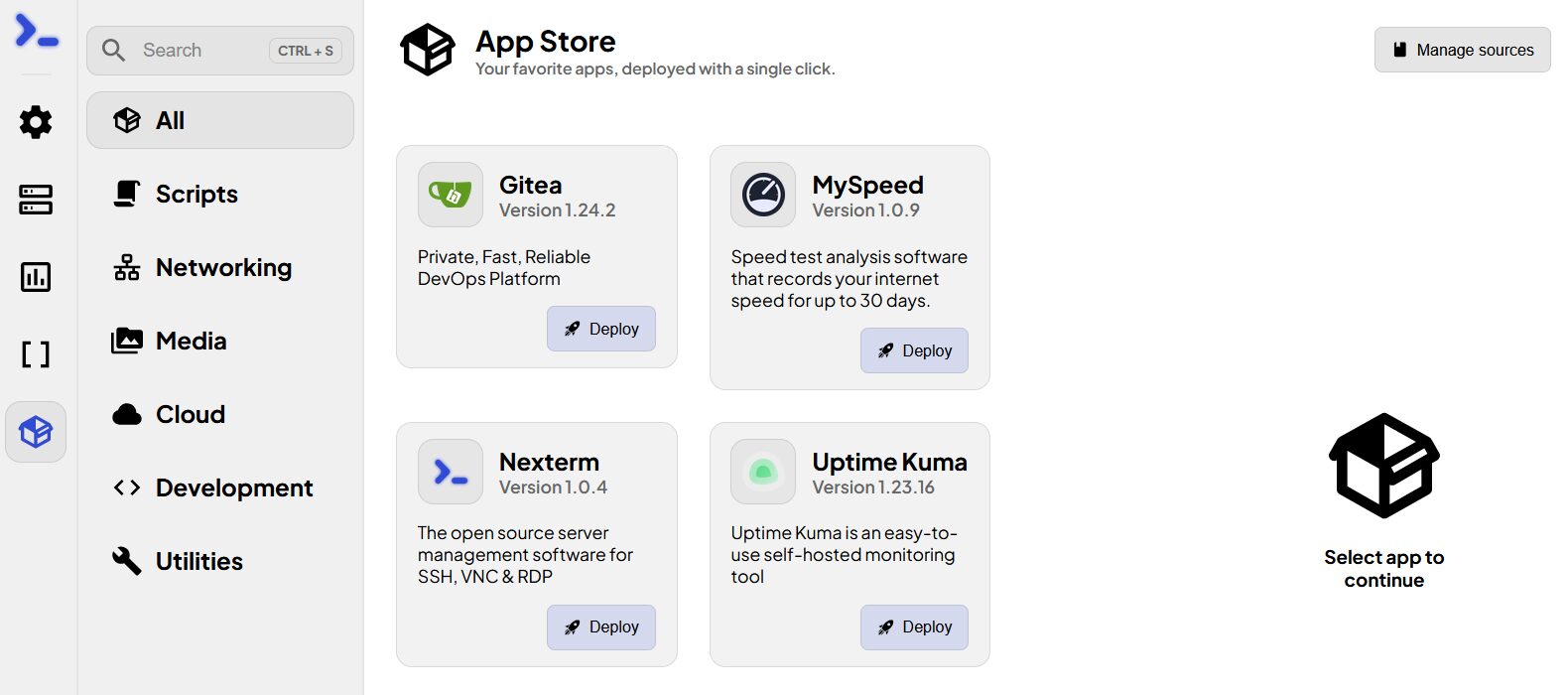
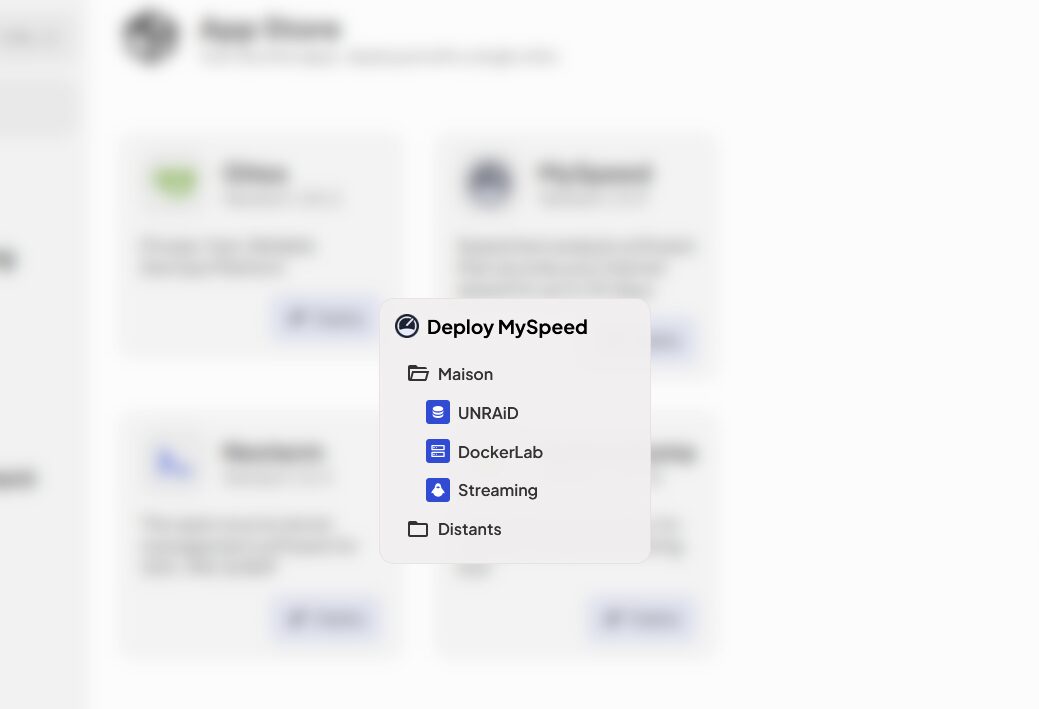
Autre point intéressant, enfin qui le sera dans le futur je suppose, est le déploiement de Dockers. Avec une vision devops, c’est pas mal pour envoyer rapidement des utilitaires sur des machines. L’AppsStore officiel est ici et permet de voir comment créer des applications (un docker compose ofc!). On peut donc tout à fait se faire les siennes et s’héberger sa propre source d’apps. Je ne me vois pas déployer Plex ou Nextcloud comme ça mais pour des utilitaires… Avec un Authelia en sus de tout ça…
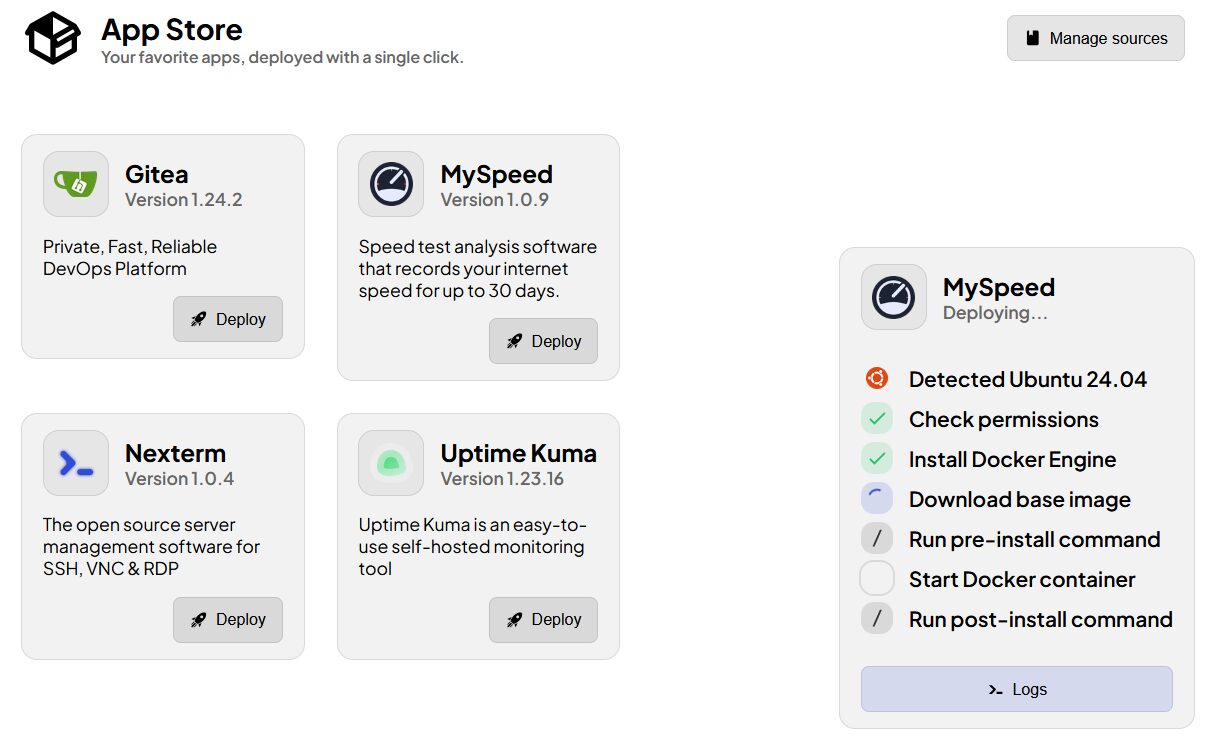
Je devrais renommer « Streaming » en « Testing », pauvre machine… Le process est entièrement détaillé en temps réel
On peut visualiser les logs
Et j’y accède bien à la fin. Alors évidemment, aucune auth, aucune sécurité. C’est pas fait pour déployer des instances Nextcloud en prod, juste des utilitaires quand on bosse ou doit tester. Enfin à mon sens c’est le but.
J’aurais aimé avoir l’option de désinstaller le container mais ça viendra sûrement, le projet étant tout jeune (j’ai ouvert une issue).
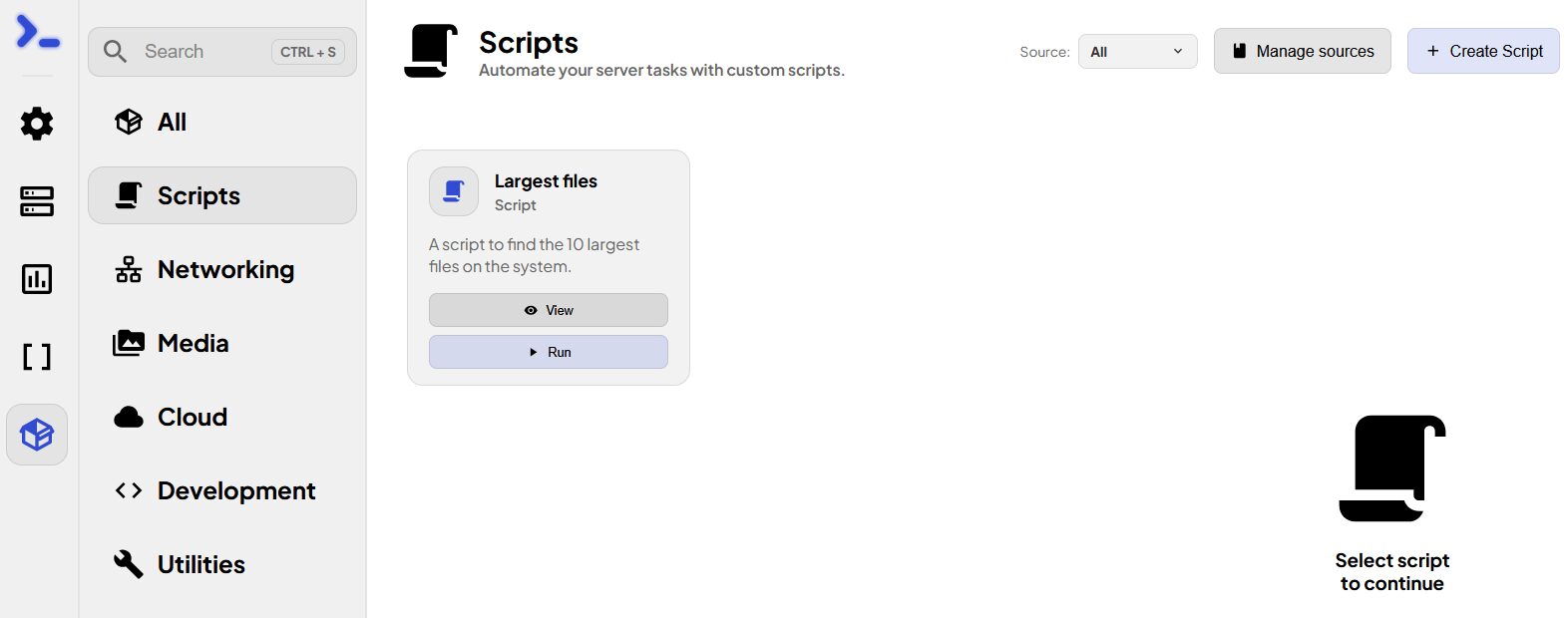
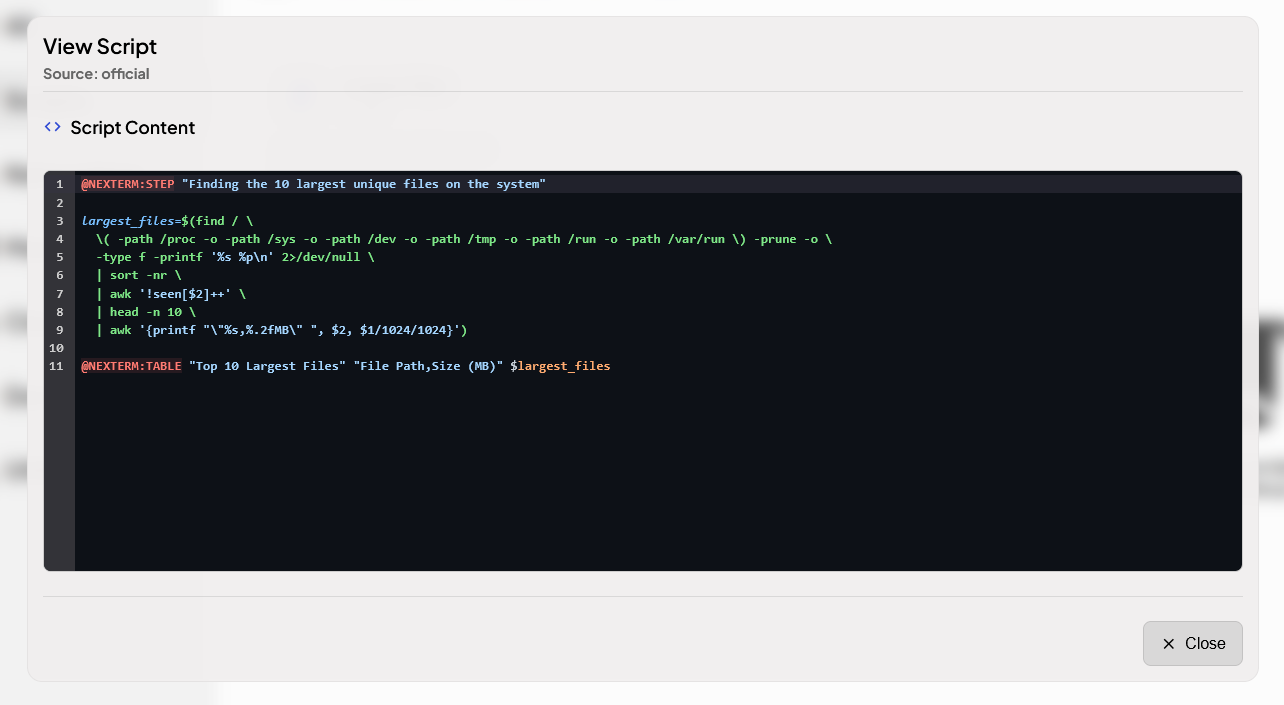
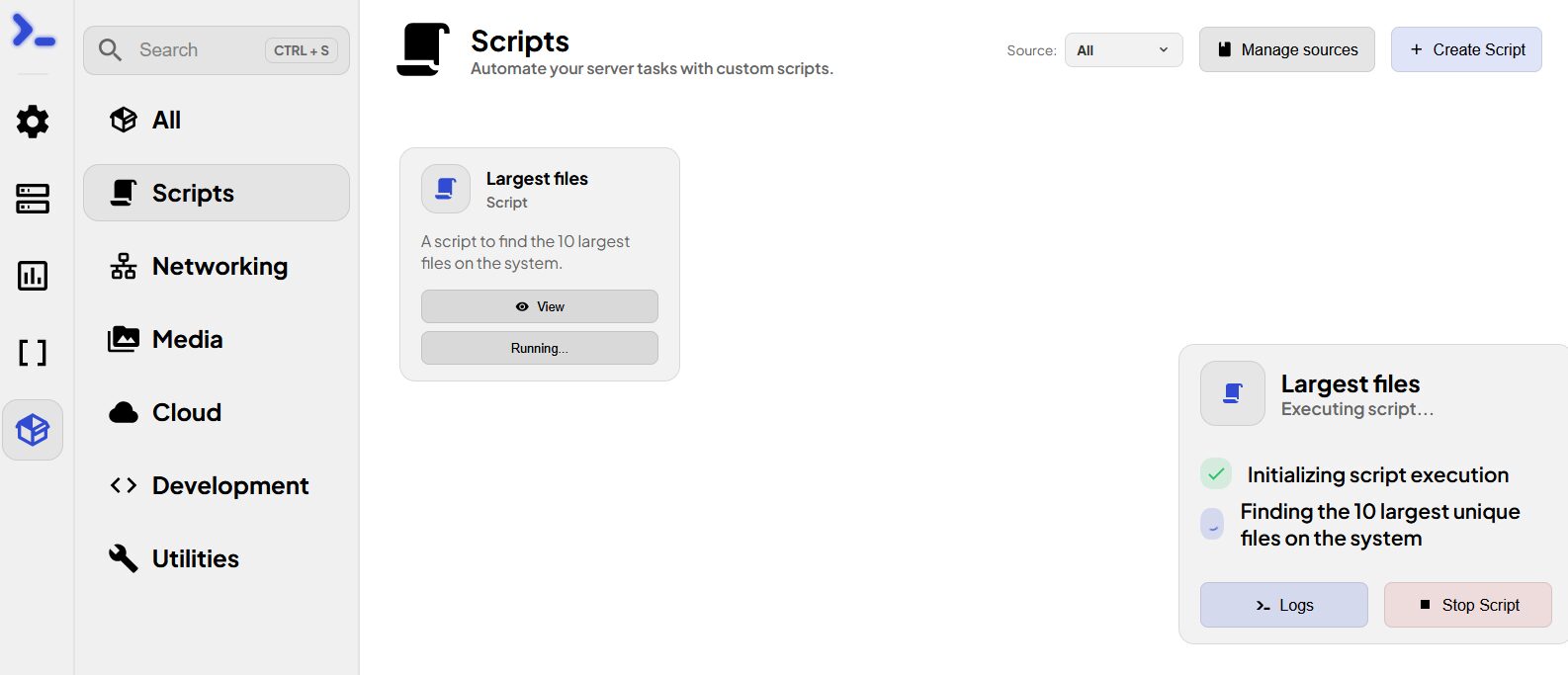
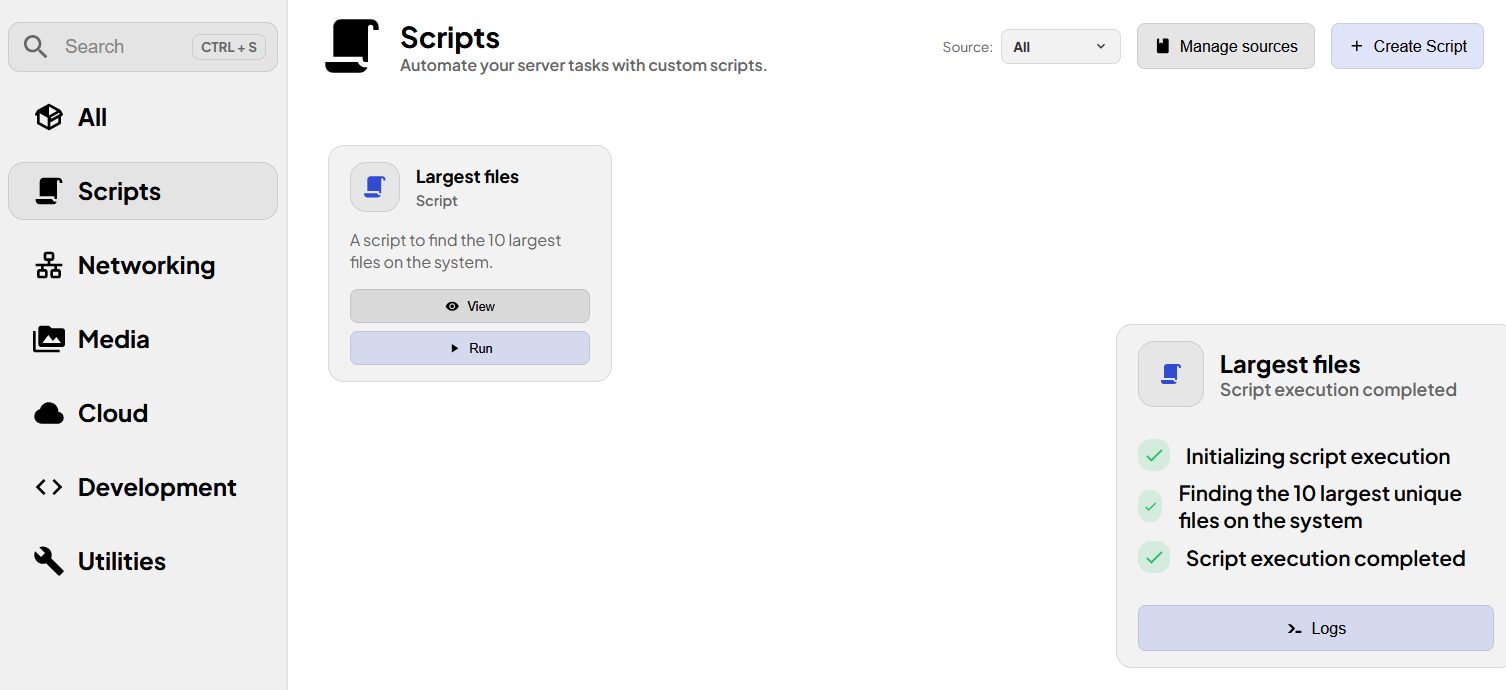
Dans le même registre, nous avons la possibilité d’ajouter des scripts (Bash) soit via une source comme pour les apps soit directement en WebUI. Ils pourront alors être exécutés sur un serveur.
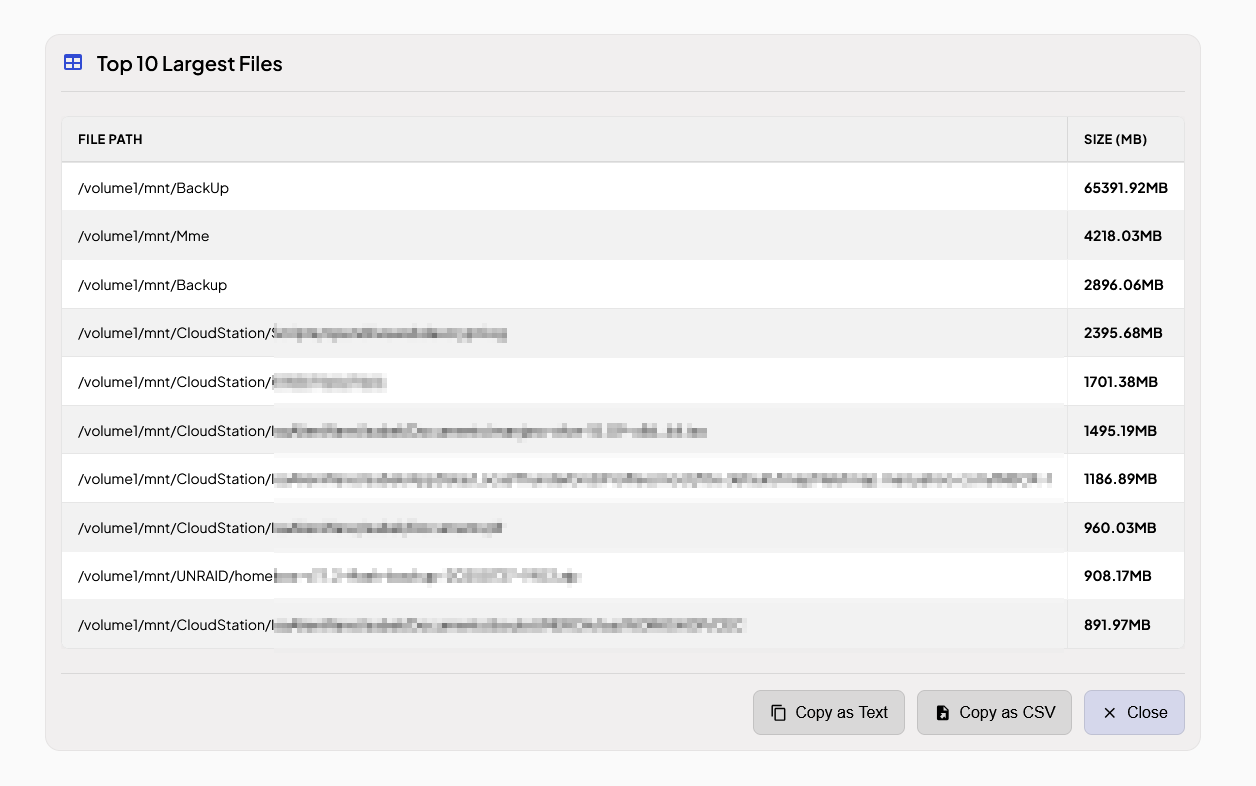
Celui d’inclus permet de lister les plus gros fichiers sur la machine où il est exécuté.
Pour l’instant on ne peut l’exécuter que sur une machine à la fois.
Pour l’instant je suis fan de l’outil ! Et comme c’est en Docker, on peut le laisser en reverse proxy normal ou le faire passer par un VPN, Tor etc. Très pratique.
Il y a quelques années, j’utilisais un plugin pour Plex pour synchroniser les visionnages. L’intérêt étant surtout de pouvoir ajouter/retirer des contenus, voire réinstaller un serveur Plex, tout en ne perdant pas le chemin parcouru
On peut synchroniser de Plex vers Trakt et/ou Trakt vers Plex, par bibliothèque et utilisateur.
Voici un exemple d’installation et de configuration, sans prise en compte de Watchlists (que je n’ai pas vu qu’ici on passe par Overseerr uniquement). Il faut une application Trakt.tv vérifiée (gratuit) pour récupérer ses clés d’accès. Et si vous voulez les notifications Discord, l’OS hôte (mon script est externe) doit avoir curl et jq.
Installation du Docker. Ofelia étant un cron qui permet de lancer la synchronisation selon nos préférences, je le lance toutes les 6h (0 */6 * * *). Pour paramétrer, aidez-vous de Cron Guru au besoin.
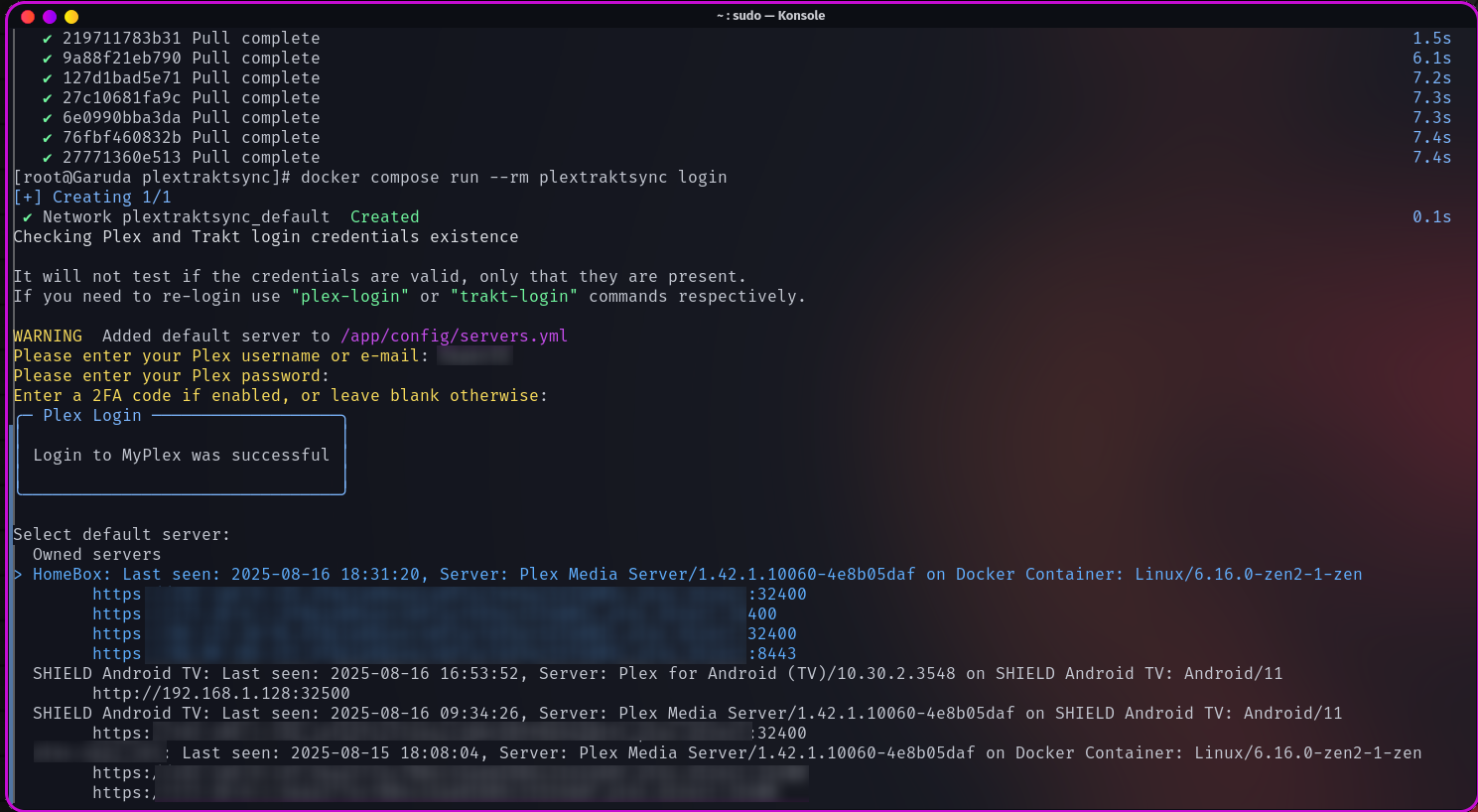
En suivant le ReadMe, lancer le Docker la 1ère fois créera le fichier de configuration config.yml. Mais on peut aussi l’éditer à la main, tout comme servers.yml. Pour sélectionner le serveur, utiliser les flèches du clavier.
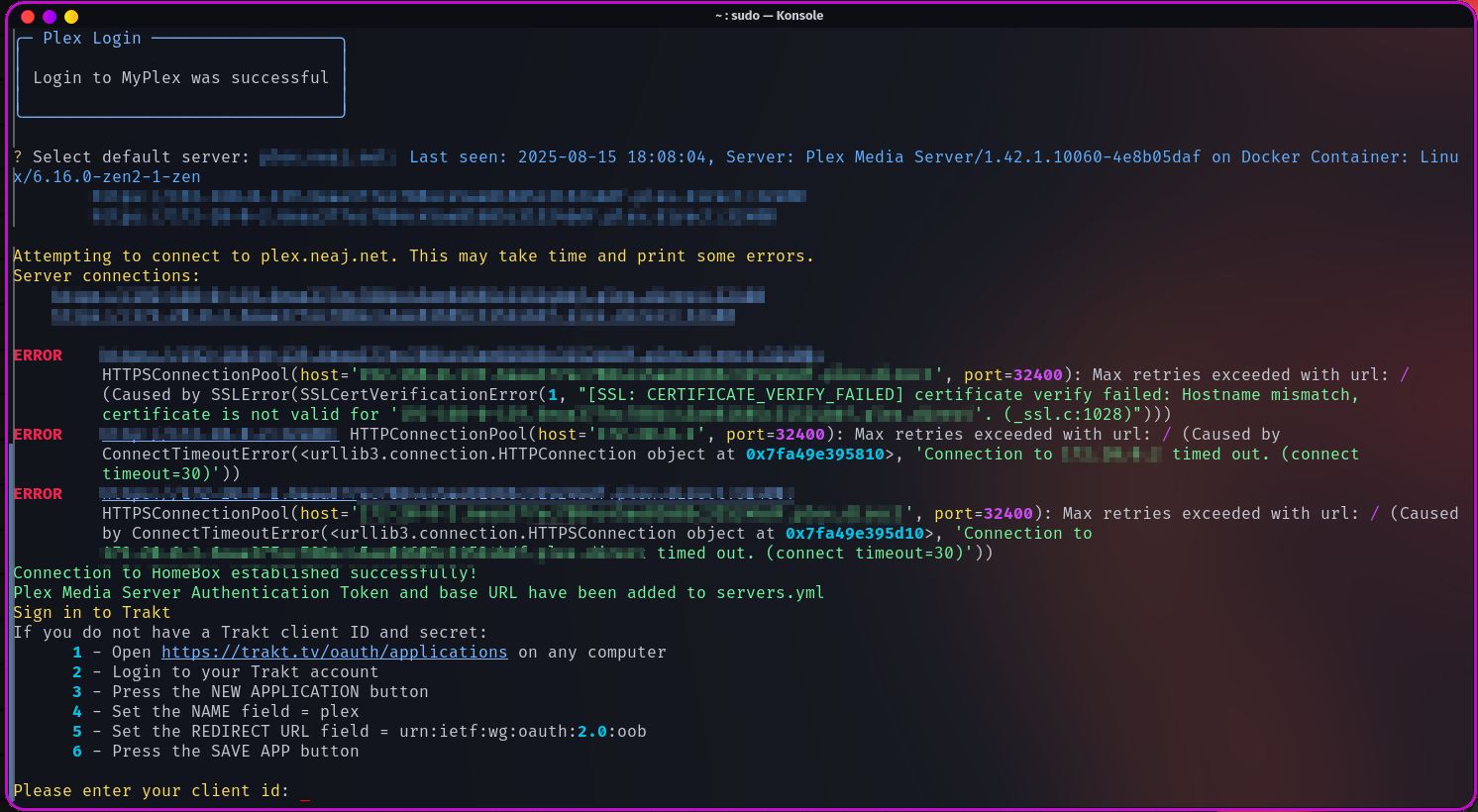
Je me suis trompé de serveur, j’ai édité la conf à la main ensuite, du coup il cherchait à valider un SSL alors que j’avais mis un serveur en IP locale. Il faut lui laisser un peu le temps mais ensuite c’est bon.
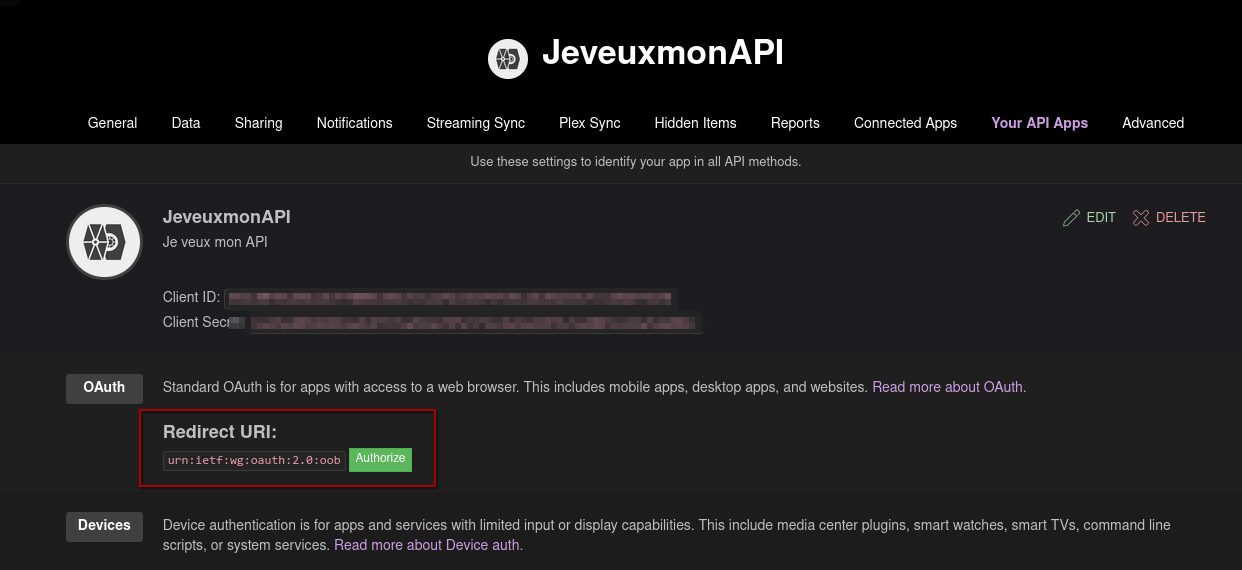
Si ce n’est pas déjà fait, il explique la marche à suivre pour se faire une application Trakt.tv
Quand je vois SickGear dans mes applications… ça rappelle de sacrés souvenirs !
Il convient tout de même d’éditer un peu la configuration à la main, notamment si on veut exclure des bibliothèques ou watchlists. Ici c’est basique, je n’ai qu’un utilisateur et synchronise tout mais pour aller plus dans le détail je vous recommande de suivre son ReadMe. C’est config.yml dans /home/aerya/docker/plextraktsync/config
cache:
path: $PTS_CACHE_DIR/trakt_cache
# You may want to use per server libraries config instead:
# - https://github.com/Taxel/PlexTraktSync#libraries
excluded-libraries:
- Private
config:
dotenv_override: true
plex:
timeout: 30
logging:
append: true
# Whether to show timestamps in console messages
console_time: false
debug: false
filename: plextraktsync.log
# Additional logger names to apply filtering
filter_loggers:
# - plexapi
# - requests_cache.backends
# - requests_cache.backends.base
# - requests_cache.backends.sqlite
# - requests_cache.policy.actions
# - requests_cache.session
# - trakt.core
# - urllib3.connectionpool
filter:
# # Filter out all messages with level WARNING
# - level: WARNING
# # Filter out message with level WARNING and containing a text
# - level: WARNING
# message: "not found on Trakt"
# - message: "because provider local has no external Id"
# - message: "because provider none has no external Id"
# - message: "Retry using search for specific Plex Episode"
# # Filter out messages by requests_cache
# - name: requests_cache.backends
# - name: requests_cache.backends.base
# - name: requests_cache.backends.sqlite
# - name: requests_cache.policy.actions
# - name: requests_cache.session
# settings for 'sync' command
sync:
# Setting for whether ratings from one platform should have priority.
# Valid values are trakt, plex or none. (default: plex)
# none - No rating priority. Existing ratings are not overwritten.
# trakt - Trakt ratings have priority. Existing Plex ratings are overwritten.
# plex - Plex ratings have priority. Existing Trakt ratings are overwritten.
rating_priority: plex
plex_to_trakt:
collection: false
# Clear collected state of items not present in Plex
clear_collected: false
ratings: true
watched_status: true
# If plex_to_trakt watchlist=false and trakt_to_plex watchlist=true
# the Plex watchlist will be overwritten by Trakt watchlist
watchlist: false
trakt_to_plex:
liked_lists: true
ratings: true
watched_status: true
# If trakt_to_plex watchlist=false and plex_to_trakt watchlist=true
# the Trakt watchlist will be overwritten by Plex watchlist
watchlist: false
# If you prefer to fetch trakt watchlist as a playlist instead of
# plex watchlist, toggle this to true (is read only if watchlist=true)
watchlist_as_playlist: false
# Sync Play Progress from Trakt to Plex
playback_status: false
# Configuration for liked lists
liked_lists:
# Whether to keep watched items in the list
keep_watched: true
# Configuration override for specific lists
#liked_list:
# "Saw Collection":
# keep_watched: true
# settings for 'watch' command
watch:
add_collection: false
remove_collection: false
# what video watched percentage (0 to 100) triggers the watched status
scrobble_threshold: 80
# true to scrobble only what's watched by you, false for all your PMS users
username_filter: true
# Show the progress bar of played media in terminal
media_progressbar: true
# Clients to ignore when listening Play events
ignore_clients: ~
xbmc-providers:
movies: imdb
shows: tvdb
De même, on peut venir éditer le fichier du ou des serveurs Plex à synchroniser : servers.yml
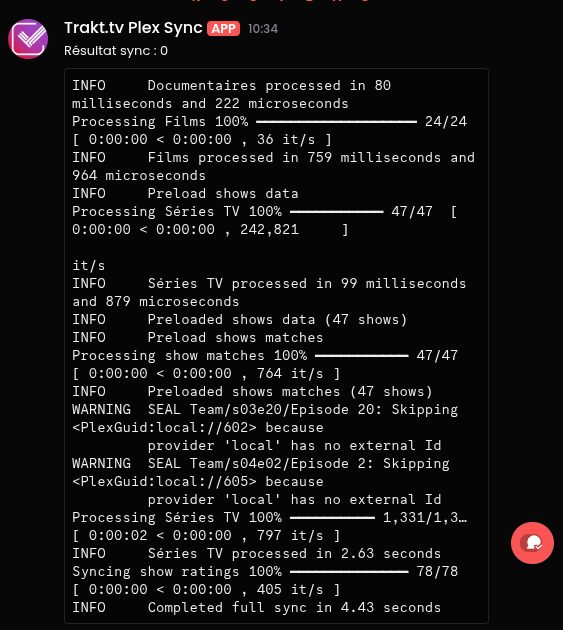
Et donc, toutes les 6h, le Docker se lance et synchronise Plex et Trakt.tv pour mettre à jour les films et séries lus/non lus. La 1ère fois peut prendre un peu de temps selon le nombre de fichiers.
Je voulais les notifications sur Discord, j’ai donc créé un script qui lance le Docker et envoie la récap en notification :
Nécessite curl et jq. Pour l’icône, ici comme pour Heimdall, j’utilise dashboardicons.com Et il faut retirer Ofelia et les labels inhérents du compose plus haut puisque c’est maintenant l’hôte, via crontab par exemple, qui va exécuter le script qui va lui-même lancer le Docker de plextraktsync.
On a tellement l’habitude de se le faire becter par les oiseaux, guêpes et frelons que je me suis emballé hier et avons récolté du raisin un peu tôt.
D’un autre côté, on a regardé les prunes pousser, on ne les a pas mangées. Idem pour un des noisetiers.
Donc, entre mon raisin rouge encore à 80% vert et un reste de pommes (du commerce, ici elles sont encore bien vertes), j’ai préparé un crumble aux pommes et raisin !
Et les poules vont pouvoir s’amuser avec les déchets des deux
Ma recette (y’en a sans doute autant que de personnes qui en font) :
130Gr de sucre ; je mets de la cassonade par préférence et « beaucoup » pour contrer l’acidité du raisin,
100 + 20Gr de beurre,
140Gr de farine de blé,
80Gr de poudre d’amandes,
4-500Gr de raisin,
4 à 5 pommes, dépend de leur taille.
Le plus long étant de trier les grains les plus mûrs… Les laver rapidement, réserver.
S’occuper des pommes : les peler et couper grossièrement. Merci à la personne qui a inventé l’épluche pommes !
Mélanger sucre, farine et poudre d’amandes. Ajouter ensuite 100Gr de beurre et malaxer pour obtenir une pâte homogène. Vive les gants !
Si comme moi le beurre sort juste du réfrigérateur, le passer 20 secondes au micro-ondes. Et réserver.
A la pôele, 20Gr de beurre, pour que ça n’accroche pas ici et moins dans le plat au four.
Faire revenir le raisin à feu doux, qu’il se colore. 8 minutes au gaz par exemple.
Quand il change couleur, ajouter les pommes, mélanger et couvrir pour laisser couffiner 5/6 minutes jusqu’à prendre la couleur du raisin.
Une fois prêt, mettre dans un plat (non beurré vu que les fruits le sont) et couvrir avec la pâte.
Enfourner 30-35 minutes à 180°.
Et ne faites pas comme moi : pensez à étaler correctement la pâte
Au tout début, dès que je devais sélectionner des redirections de ports je faisais ça proprement, ça se suivait. Puis… j’ai glissé.
Alors que ce soit dans une optique de faire du propre, dans celle de vérifier si tous les ports ouverts sont bien utiles, quelle application utilise quoi ou quels ports traiter via un firewall/port-forward, il peut être utile d’en avoir une liste.
Si c’est simple à faire en console, c’est pas sexy, encore moins pratique.
Merci à Mostafa Wahied qui a mis en ligne l’outil Portracker Et merci à demonangex pour la découverte.
Ça s’installe en 2-2 en Docker, on peut utiliser le Dashboard pour monitorer plusieurs machines, on peut lister les ports Docker et/ou de l’hôte, c’est beau. On peut chercher par numéro de port, nom d’applciation etc.
L’intérêt d’un container Docker basé sur Alpine est de gagner de la place, beaucoup de place parfois, en partant d’une base très légère, dépourvue du superflu. Sauf que de temps en temps, c’est pas pratique. J’ai migré mon AdGuardHome vers la version avec Redis et Unbound d’imTAIH.
Avantages d’Unbound avec la prélecture (prefetching) :
Résolution DNS plus rapide : les enregistrements DNS fréquemment consultés sont résolus et mis en cache à l’avance.
Latence réduite : moins de délais liés aux requêtes DNS, idéal pour les applications sensibles au temps de réponse.
Meilleures performances réseau : les réponses étant déjà en cache, elles sont disponibles instantanément.
Avantages de l’utilisation de Redis :
Cache fiable : assure une réponse rapide même sous forte sollicitation.
Vitesse mémoire : Redis stocke les résultats DNS en mémoire pour un accès quasi instantané.
Débit optimisé : réduit la charge sur les serveurs DNS en évitant les requêtes répétitives.
Charge allégée : limite le nombre de requêtes vers l’extérieur.
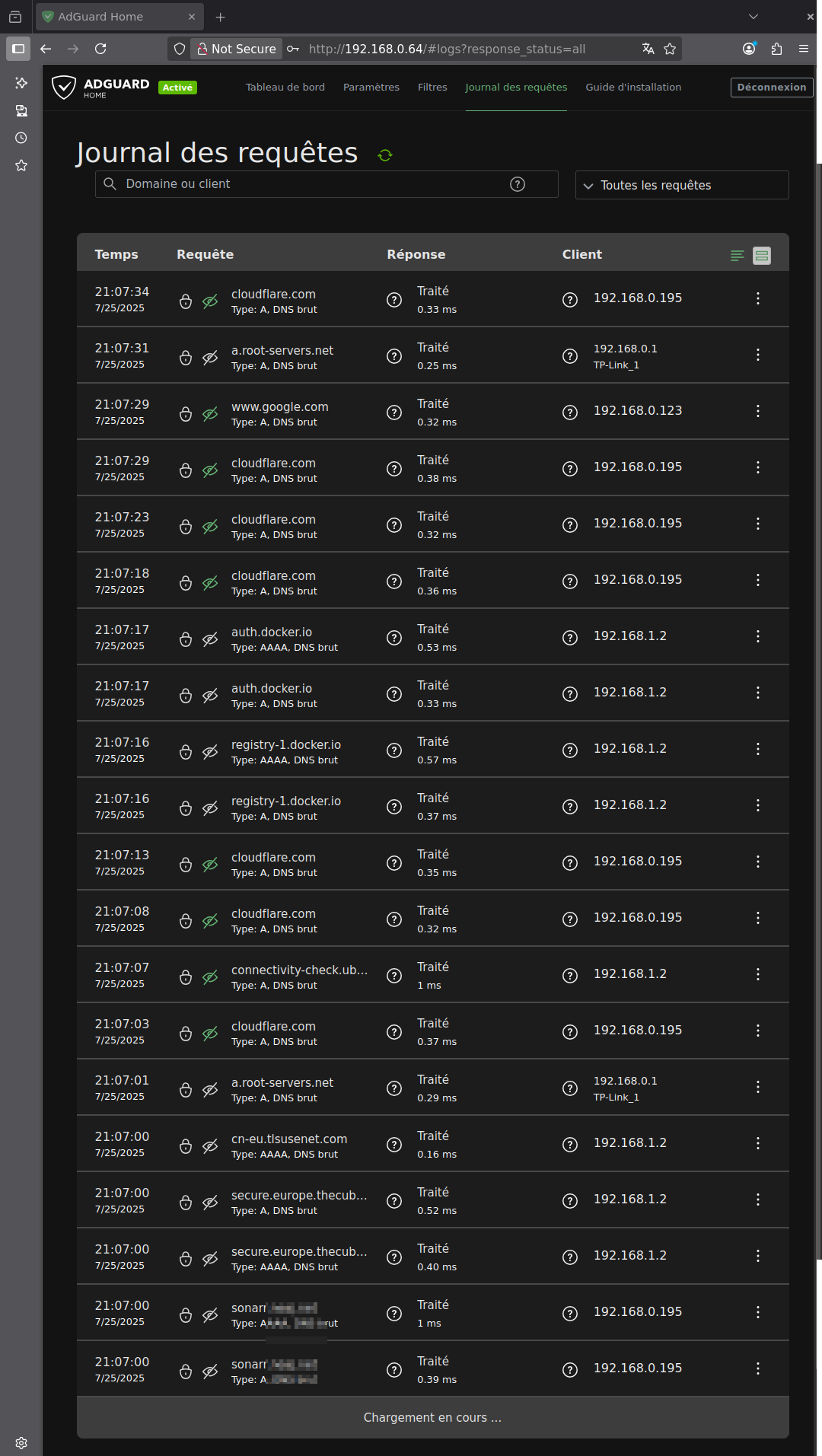
Et donc c’est basé sur Alpine, qui n’embarque pas en standard tzdata
Ce qui ne m’arrange pas vu que je voudrais des logs d’AdGuardHome sur le bon fuseau horaire
Avec les Dockers de Linux Server, on peut ajouter des DOCKER_MODS. Là non. J’ai donc ajouté un script « AGH-tzdata » dans user-scripts qui installe tzdata et crée les dossiers nécessaires au boot de l’array et/ou à la MàJ du Docker que j’ai nommé AGH-Unbound-Redis. Plus précisément, comme je tiens à passer par users-scripts et que du coup le script ne peut pas être relancé dès que le Docker est mis à jour, je fais en sorte que le script contrôle le Docker (tzdata installé etc) et si ce n’est pas le cas, il le fait. Le tout avec un log.
Le script : (mon fuseau est en dans le code directement : Europe/Paris)
#!/bin/bash
# Variables
CONTAINER="AGH-Unbound-Redis"
LOG_FILE="/var/log/agh-tz.log"
NOW=$(date "+%Y-%m-%d %H:%M:%S")
echo "[$NOW] Vérification du fuseau horaire dans $CONTAINER..." >> "$LOG_FILE"
# Vérifier si le Docker tourne
if ! docker ps --format '{{.Names}}' | grep -q "^${CONTAINER}$"; then
echo "[$NOW] Le Docker $CONTAINER n'est pas lancé. Abandon." >> "$LOG_FILE"
exit 0
fi
# Tester si tzdata installé
if docker exec "$CONTAINER" sh -c 'apk info tzdata >/dev/null 2>&1'; then
echo "[$NOW]tzdata déjà installé." >> "$LOG_FILE"
else
echo "[$NOW]Installation de tzdata..." >> "$LOG_FILE"
docker exec "$CONTAINER" apk add --no-cache tzdata >> "$LOG_FILE" 2>&1
fi
# Configurer le fuseau horaire si incorrect
CURRENT_TZ=$(docker exec "$CONTAINER" date +"%Z")
if [ "$CURRENT_TZ" != "CEST" ] && [ "$CURRENT_TZ" != "CET" ]; then
echo "[$NOW]Configuration du fuseau horaire Europe/Paris" >> "$LOG_FILE"
docker exec "$CONTAINER" cp /usr/share/zoneinfo/Europe/Paris /etc/localtime
docker exec "$CONTAINER" sh -c 'echo "Europe/Paris" > /etc/timezone'
else
echo "[$NOW]Fuseau horaire déjà correct ($CURRENT_TZ)." >> "$LOG_FILE"
fi
# Reporter l'heure dans le log
CURRENT_DATE=$(docker exec "$CONTAINER" date)
echo "[$NOW]Heure actuelle dans le Docker : $CURRENT_DATE" >> "$LOG_FILE"
echo "----------------------------------------------------------" >> "$LOG_FILE"
Le rendu d’exécution dans le log :
[2025-07-25 19:44:01] Vérification du fuseau horaire dans AGH-Unbound-Redis...
[2025-07-25 19:44:01]tzdata déjà installé.
[2025-07-25 19:44:01]Fuseau horaire déjà correct (CEST).
[2025-07-25 19:44:01]Heure actuelle dans le Docker : Fri Jul 25 19:44:02 CEST 2025
Et contrôle de la date via la console :
root@HomeBox:/mnt/user/appdata# docker exec -it AGH-Unbound-Redis date
Fri Jul 25 19:46:45 CEST 2025
Je me remets sur l’article après le repas. Les logs affichent toujours 2h de retard.
Et… c’est là que je percute ! J’ai visiblement « digéré » avant de manger…
Sous un navigateur « propre », ça marche en effet impeccablement.
Bon, je laisse quand même mon script dont je suis content (avec sans doute trop de log d’ailleurs). Il me servira peut-être de base pour un autre souci avec un Docker basé sur Alpine ^^’
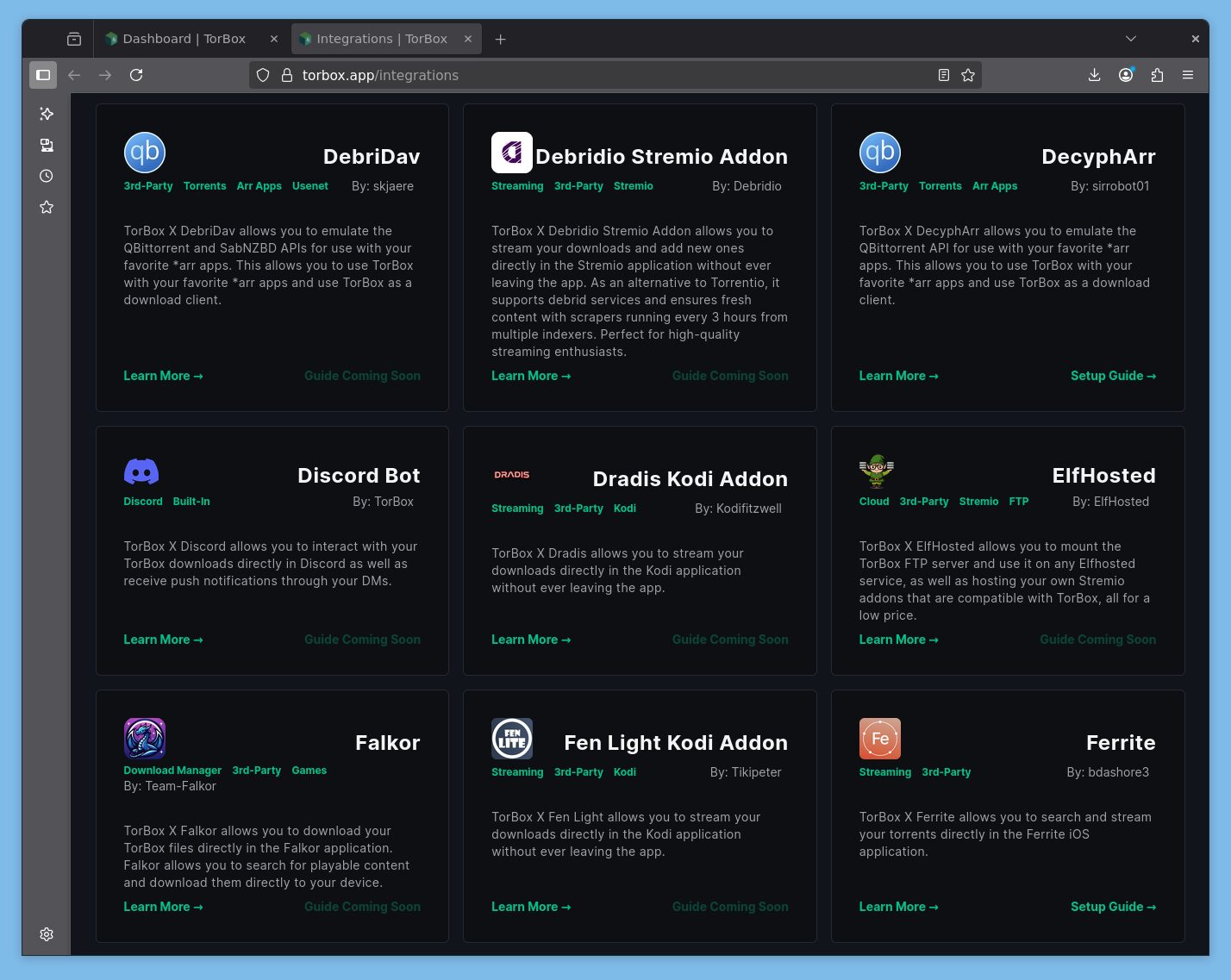
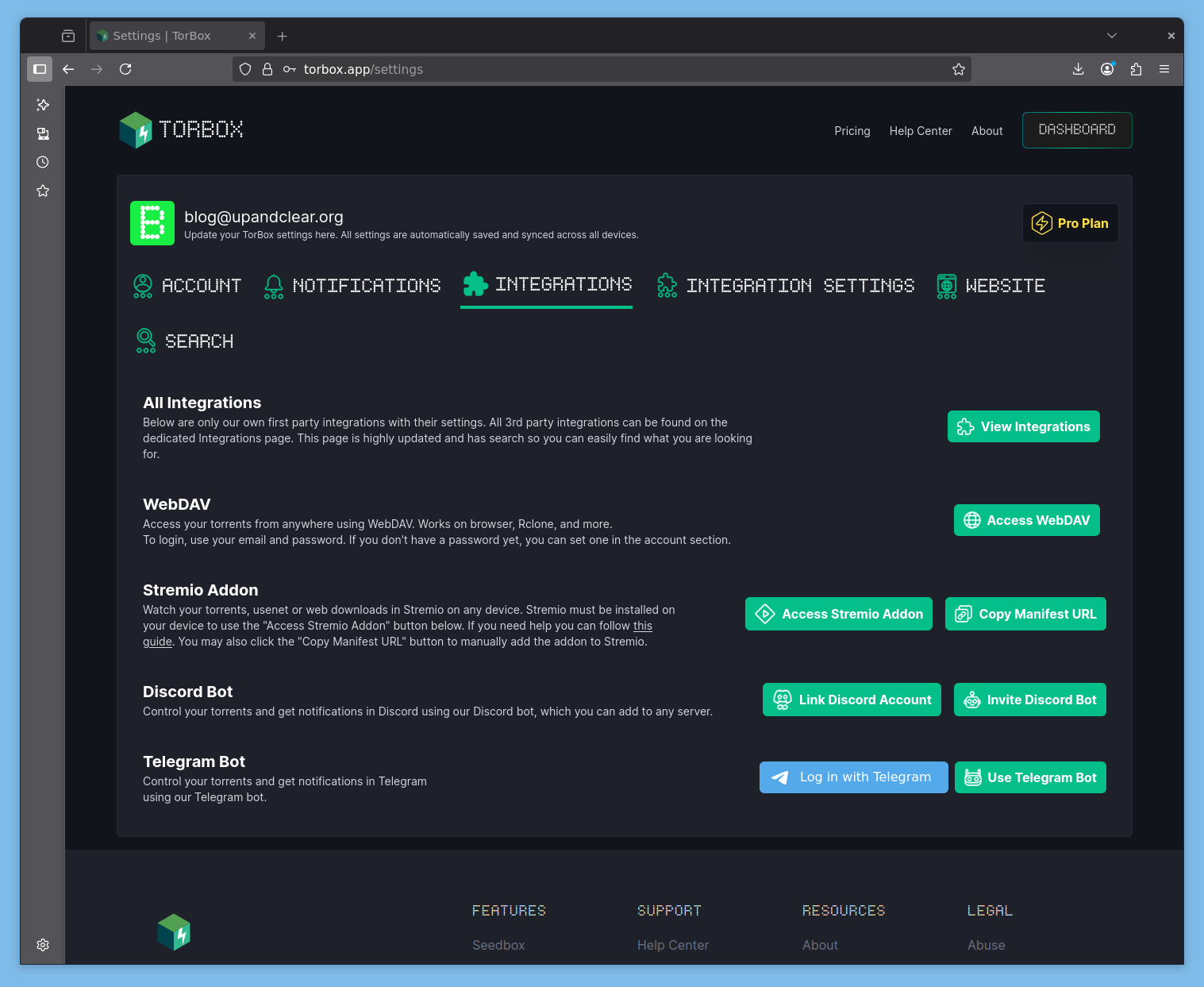
Je connaissais torbox.ch et quand j’ai vu passer « TorBox » j’étais intrigué au sujet du streaming.
TorBox.app est de ces projets qui naissent de passionnés comme Ultra.cc ou Feral Hosting. Voire TPB ou Mininova, précurseurs en leur temps et qui ont pris les tournures qu’on leur connaît. Les liens vers TorBox.app dans cet article contiennent mon lien d’affiliation. Article non sponsorisé. J’ai souscrit à une offre Pro à 12.50€ TTC/mois.
TorBox.app se présente comme un service de seedbox moderne, Freemium et très porté sur, et par, sa communauté. Comptez 12.50€ TTC en souscription mensuelle via Patreon pour un compte Pro, qui donne donc accès au téléchargement de .nzb (potentiellement plus besoin de FAU donc). Tout est Open Source et disponible sur GitHub.
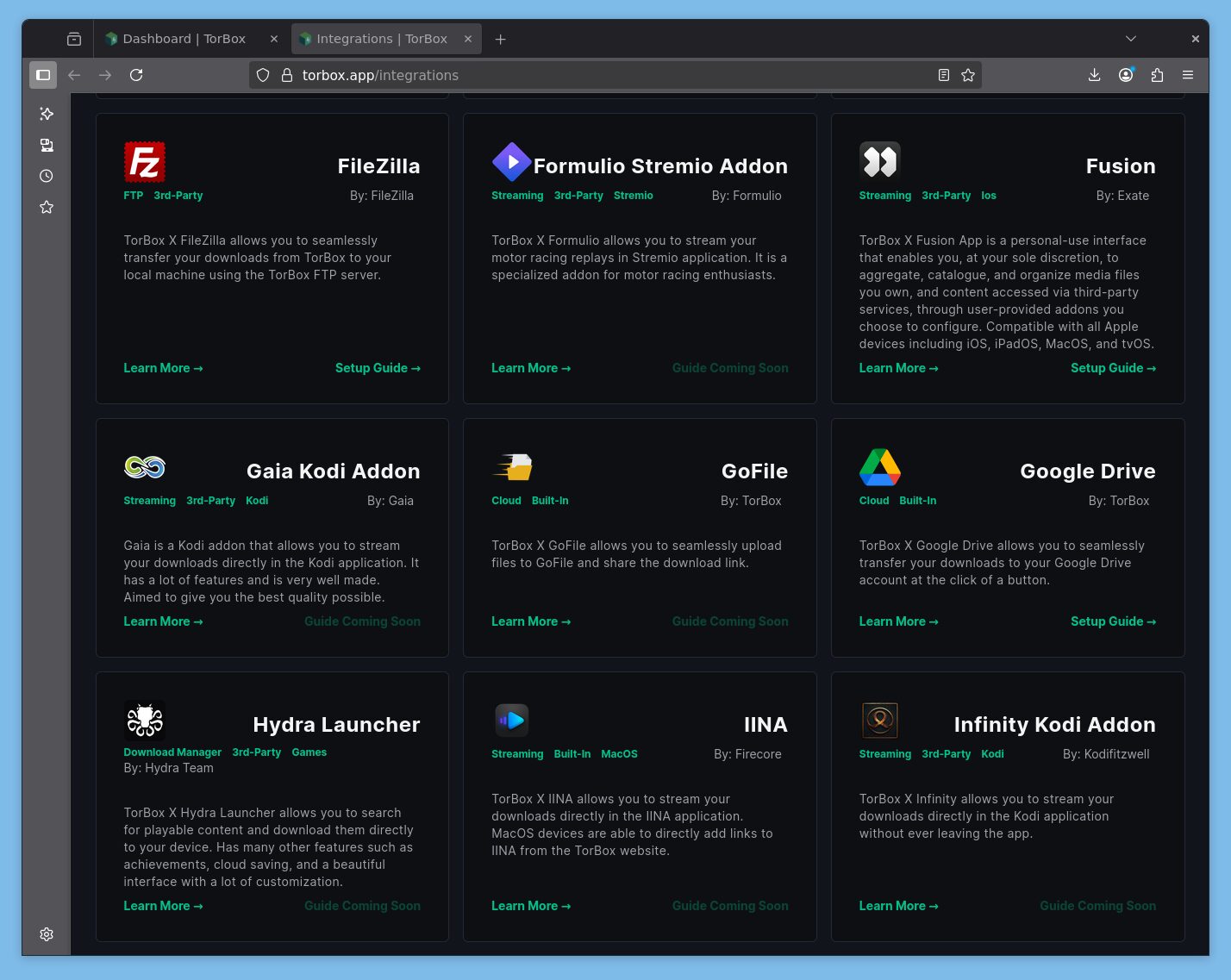
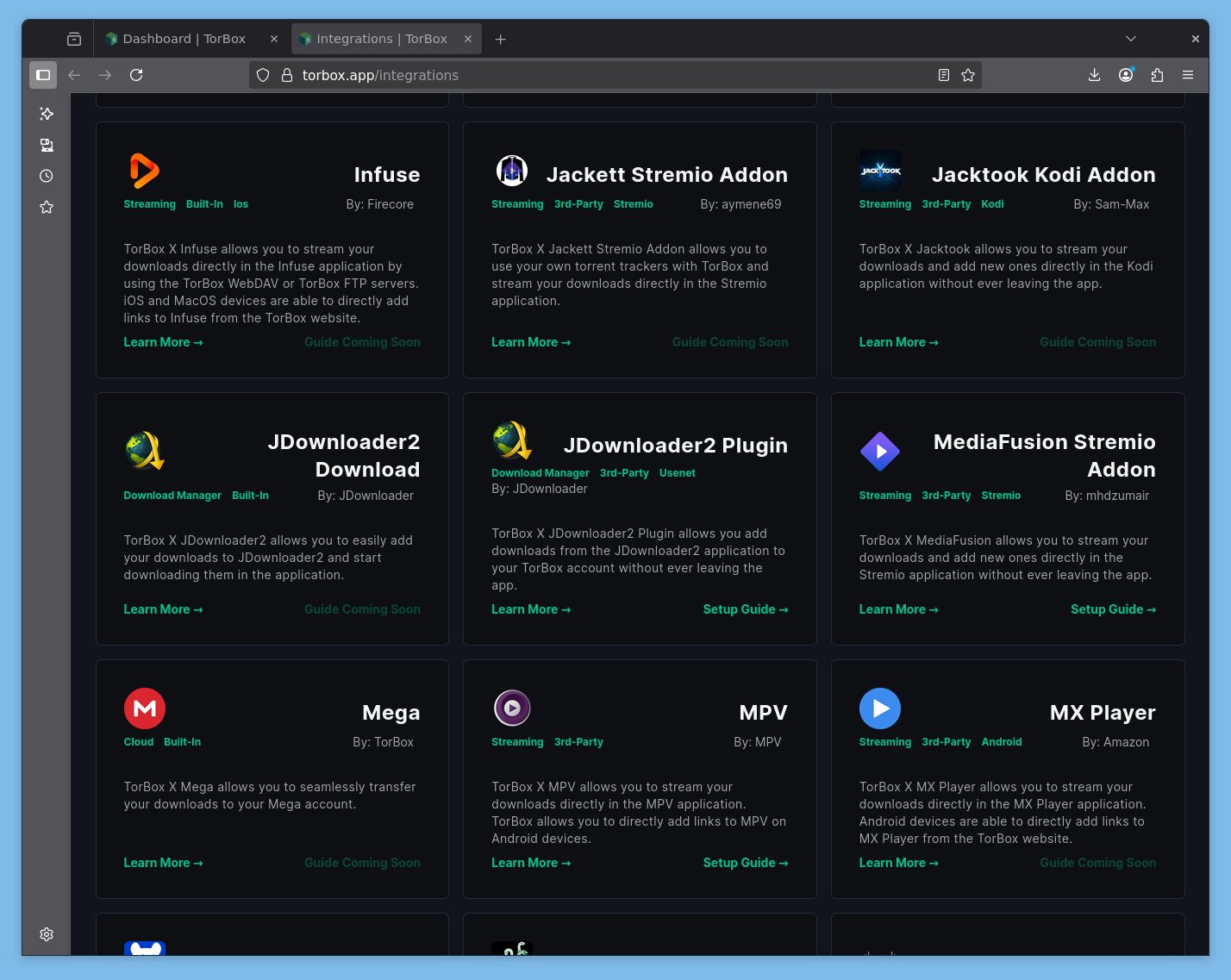
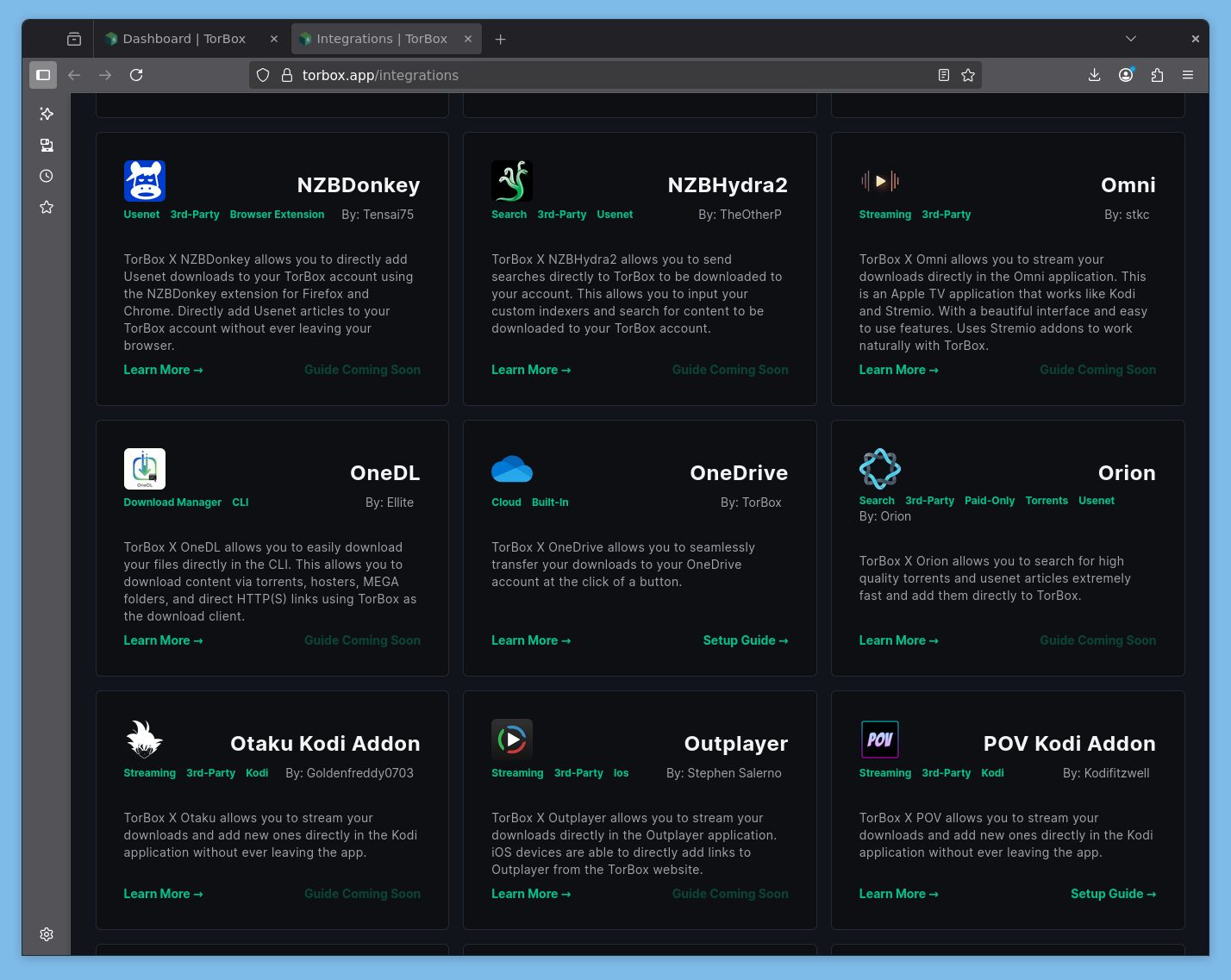
Ce service est conçu pour fonctionner comme source pour Stremio mais fonctionne également de base avec Kodi, Infuse et VLC ou MPV, ils expliquent comment utiliser leurs services avec Google Drive, OneDrive et Stremio, d’ailleurs leurs FAQs sont bien faites (pour qui parle anglais, mais on est en 2025), ils ont une communauté importante (Reddit, Discord), et ça fonctionne comme AllDebrid, RealDebrid etc pour le téléchargement et la mise en cache.
Ils ne sont pas en reste niveau fonctionnalités notamment liées au streaming via Stremio et se démarquent de la concurrence ou des autres services tels qu’Ultra.cc, Feral, AD, RD etc. Pour les geeks, Whamy propose une API complète.
While TorBox is built specifically for torrents, TorBox has also expanded as well, meaning there are all sorts of new things in store for the users of TorBox.
Downloads
Torrents
Web Downloads/Debrid
RSS Scheduled Torrents
Queued Downloads
Usenet Downloads
High Speed Downloads
Add to Download Manager
Add to Google Drive
Add to Dropbox
Add to GoFile
Add to 1Fichier
Add to Mega
Services
Mobile Companion App
API
WebDAV
FTP
Stremio Addon
Discord Bot
Telegram Bot
Notifications
Email Notifications
Web Notifications
Mobile Push Notifications
RSS Notifications
Discord Notifications
Telegram Notifications
JDownloader2 Notifications
Webhook Notifications
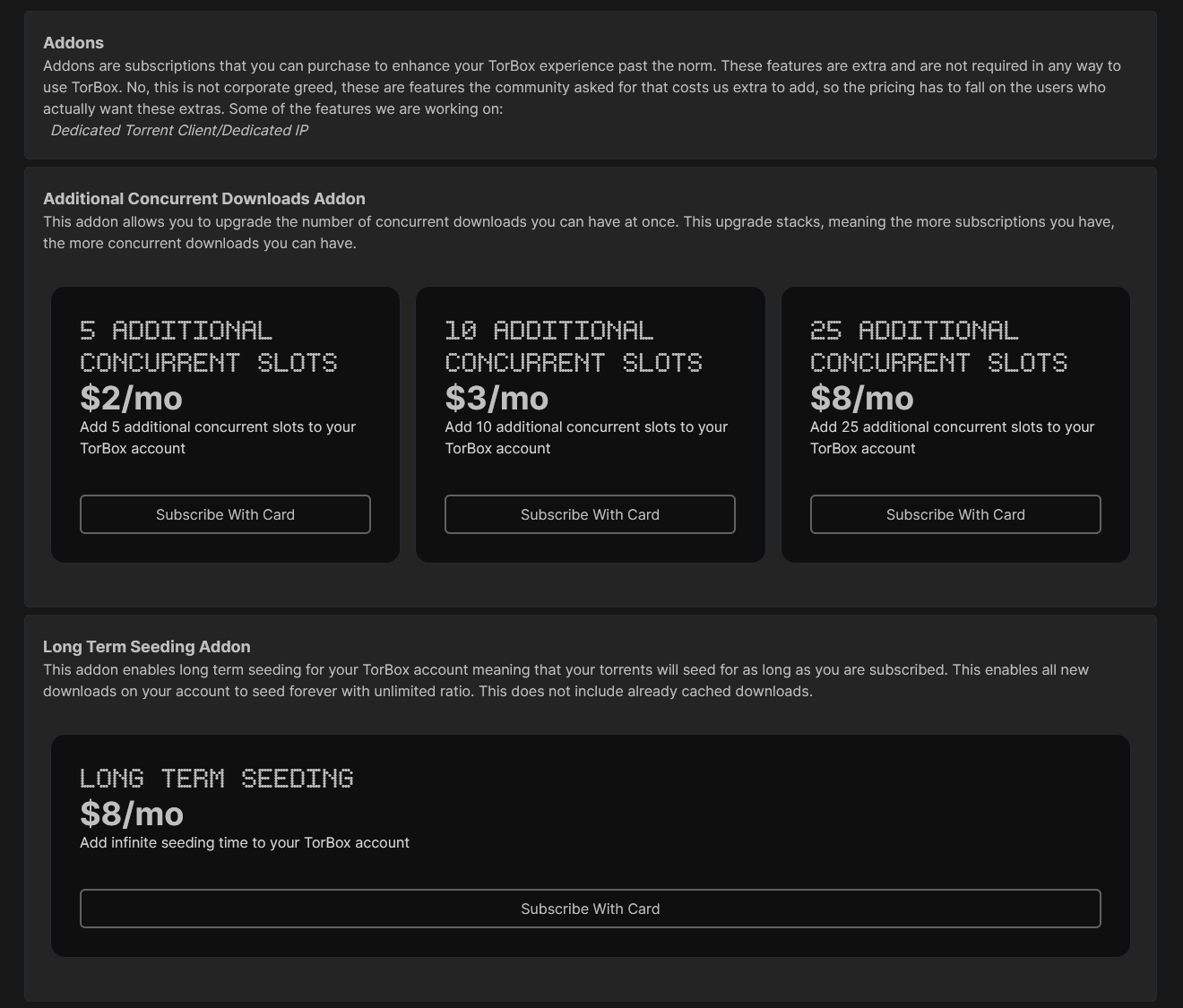
Bon, rien de magique non plus, pour maintenir leur qualité de services et leurs prix, ils ont mis en place certaines limites notamment de transferts mensuels.
Quels sont les seuils ?
Nous ne communiquerons pas les seuils absolus, et il n’est pas réaliste d’annoncer les seuils dynamiques, car ils évoluent selon l’usage global des utilisateurs. Si plus d’utilisateurs consomment davantage de bande passante, alors le seuil dynamique augmentera, permettant à chacun d’utiliser davantage. À l’inverse, si beaucoup d’utilisateurs réduisent leurs téléchargements (au profit, par exemple, d’un cache de plus en plus efficace), alors le seuil dynamique baissera.
Les seuils ne descendront jamais en dessous des niveaux suivants :
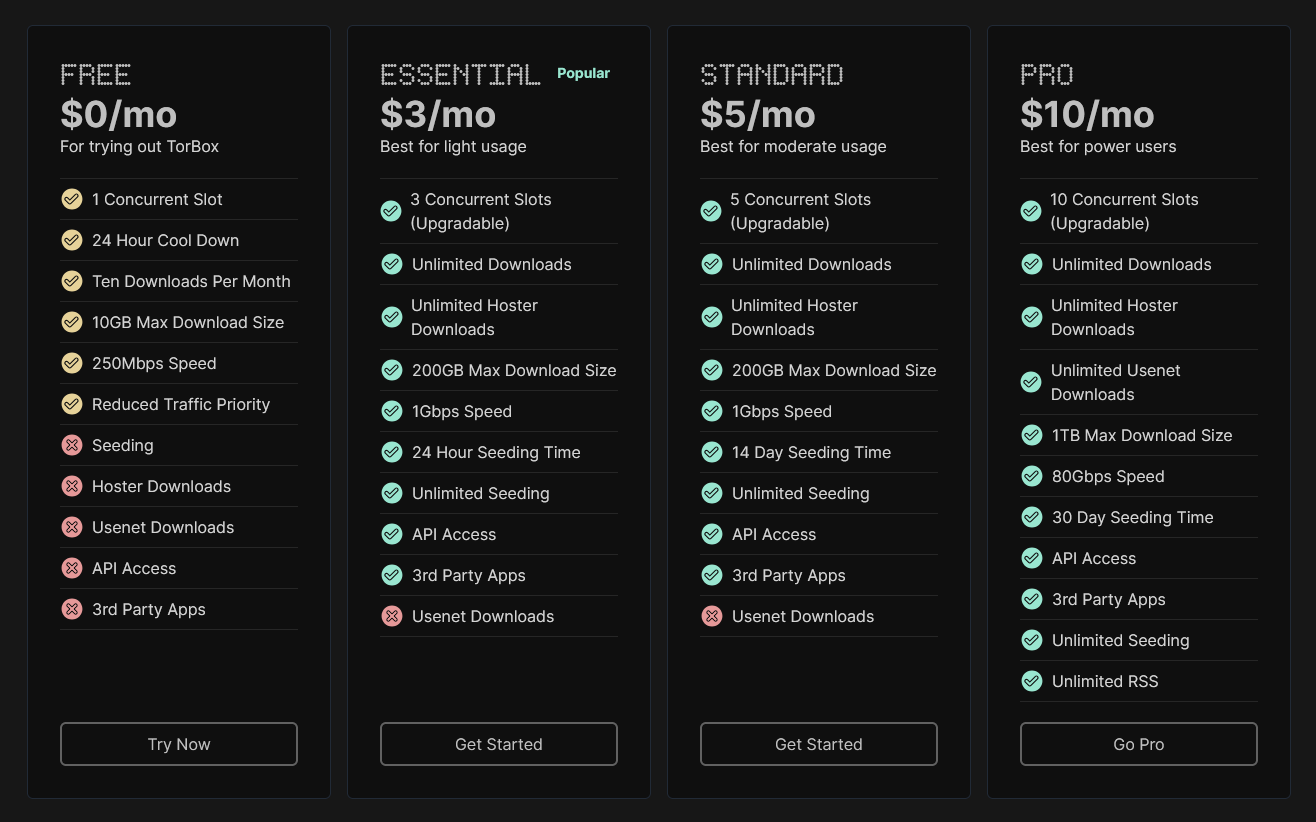
Offre gratuite (Free) : 5 To par mois
Offre Essential : 10 To par mois
Offre Standard : 20 To par mois
Offre Pro : 30 To par mois
Ces valeurs ne représentent ni un plafond autorisé, ni une représentation précise du seuil dynamique. Ce sont simplement les valeurs minimales garanties : tant que vous restez en dessous de ces niveaux, vous êtes assuré de ne jamais recevoir d’avertissement.
Grâce au seuil dynamique, vous pouvez largement dépasser ces niveaux sans souci, mais ce sont les limites minimales en dessous desquelles vous ne risquez jamais rien.
Le seuil dynamique a été conçu pour que l’utilisateur moyen, voire l’utilisateur intensif, ne le rencontre jamais.
Ils ont été un peu échaudés par des hoarders pour Plex/Jellyfin. Ces limites restent toutefois très convenables même pour ceux qui « dépannent » leurs familles et amis (moyennant finance) avec des flux vidéos.
L’interface est sommaire mais efficace.
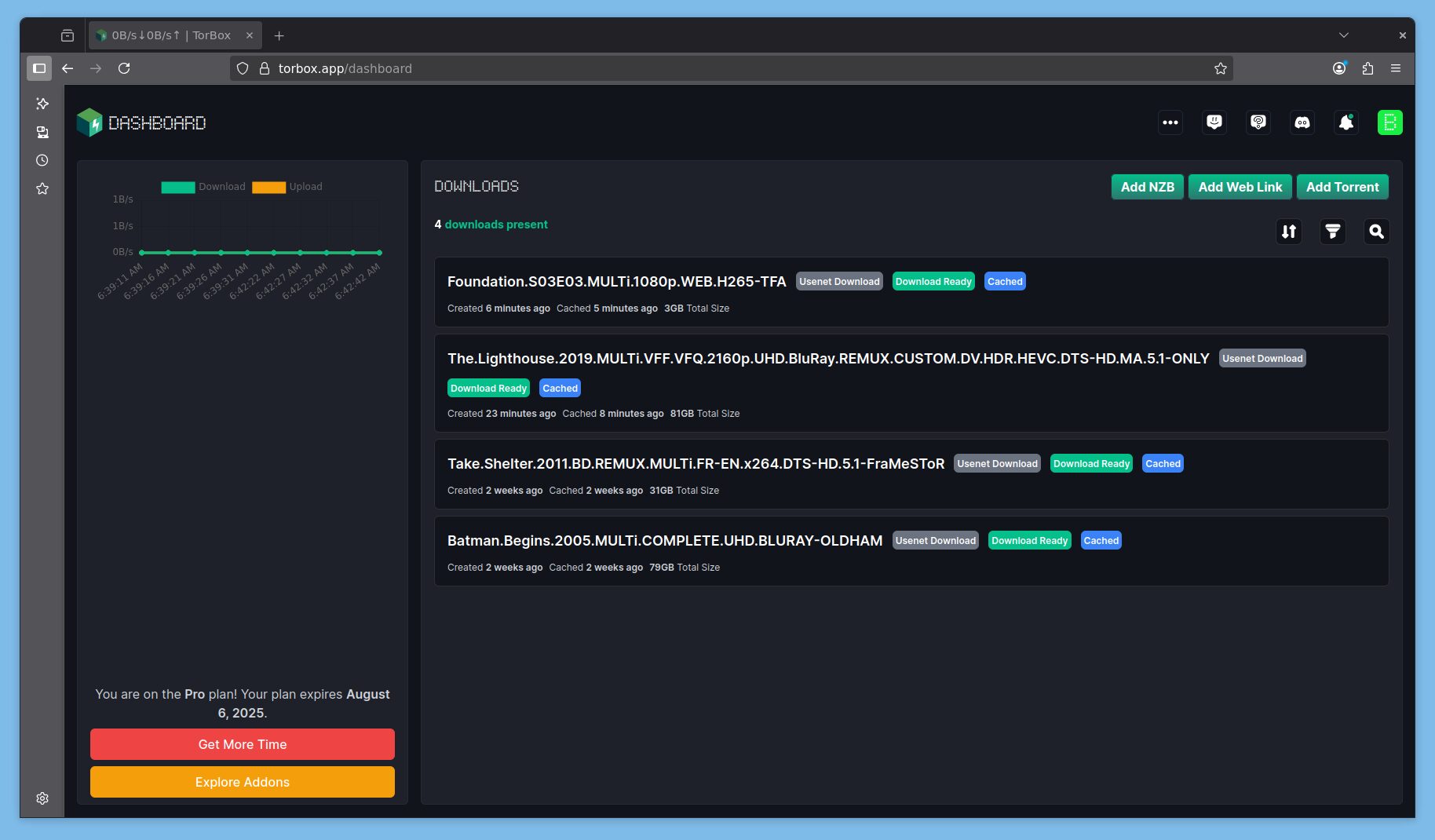
Ici, pas d’installation d’applications, c’est une pure seedbox qui permet de télécharger et stocker du .torrent et du .nzb pour les utiliser avec nos applications auto-hébergées ou des services tiers.
Moi ce qui m’intéresse là-dedans c’est DebriDav, qui fera l’objet d’un autre article. C’est comme RDT-Client » mais pour BitTorrent et Usenet. Et je veux utiliser TorBox avec Plex ou Jellyfin pour Usenet, avec un fallback BitTorrent au cas où.
Comme je le disais plus haut, ils ont un centre de support très complet, un bot de SAV sur Discord, en sus des utilisateurs qui aident tous les jours.
On peut également utiliser les liens magnets y compris avec leurs extensions pour navigateurs, comme par exemple pour Firefox (aperçu Reddit).
Il existe aussi une application TorBox Manager à auto-héberger : GitHub / Reddit.
Très bien pourvu en options
Et franchement, c’est top !
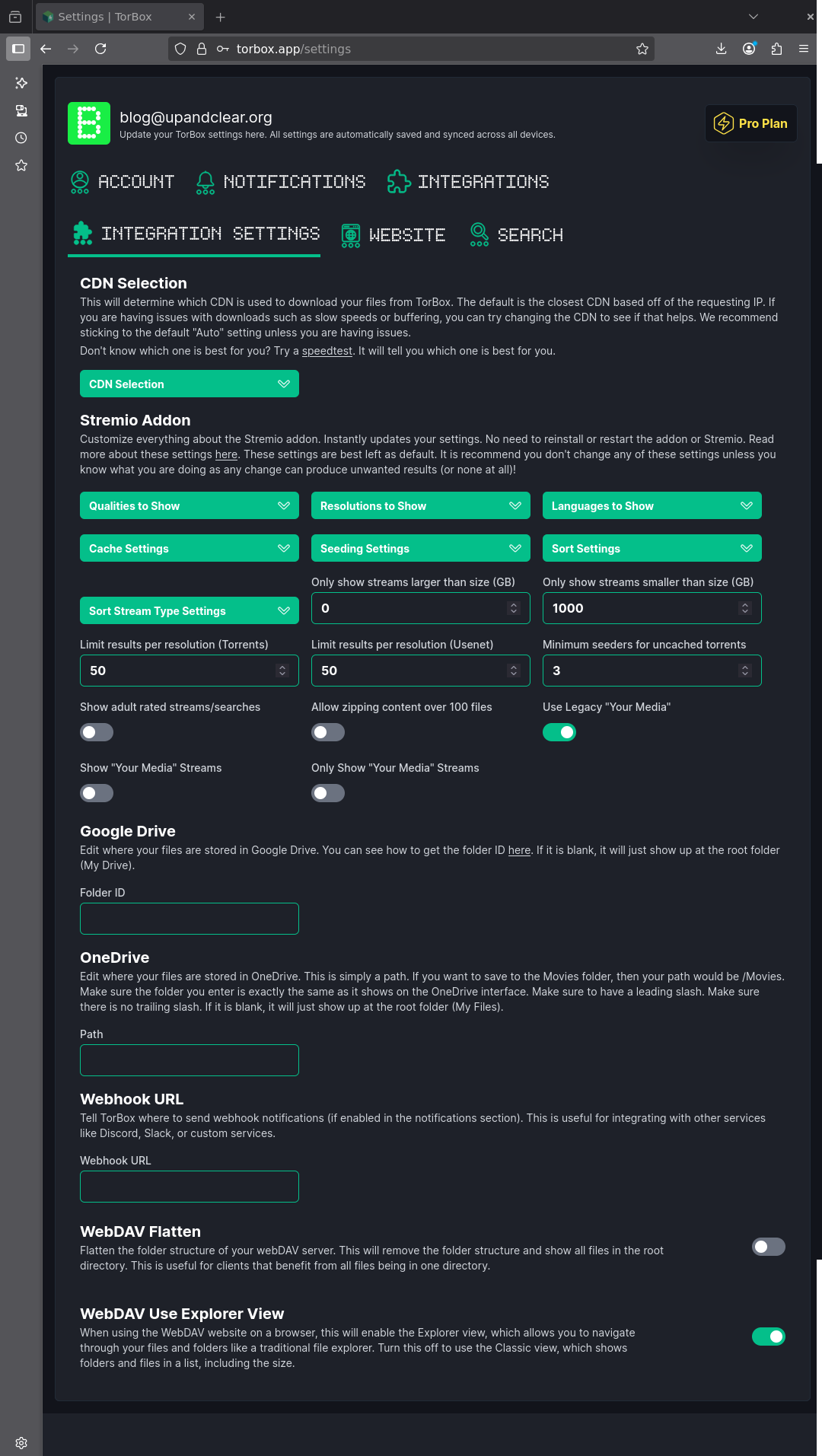
Ils proposent plusieurs CDN (US, EU, APAC) pour qu’on dispose du meilleur accès aux fichiers. Nous avons aussi les options pour Stremio.
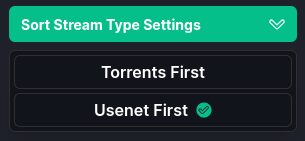
Outre les options de base (résolution, langue), on peut sélectionner si l’on veut des fichiers uniquement en cache ou aussi en téléchargement, si on veut seeder ou non les .torrents qu’on ajouterait (pourquoi pas ?!), si on privilégie Usenet ou BitTorrent.
Pour se faire sa VOD personnelle façon IPTV, Stremio suffirait bien. Et avec ses options, c’est simple !
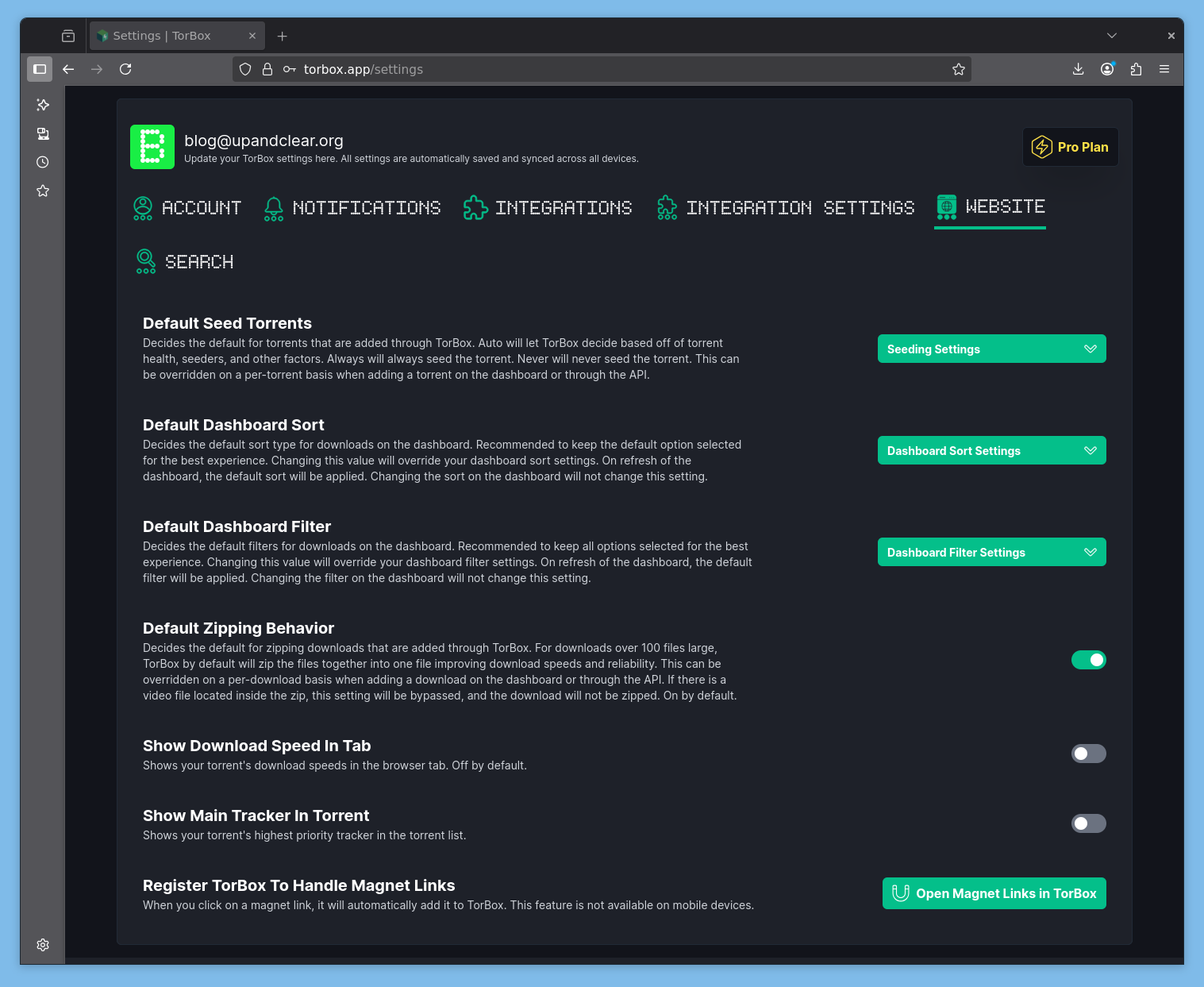
Et on peut ajouter des instances Jackett, Prowlarr et NZBHydra. Ils font la pub pour ElfHosted mais on peut aussi ajouter ses propres instances pour utiliser TB comme outil de téléchargement et stockage avec ses sources.
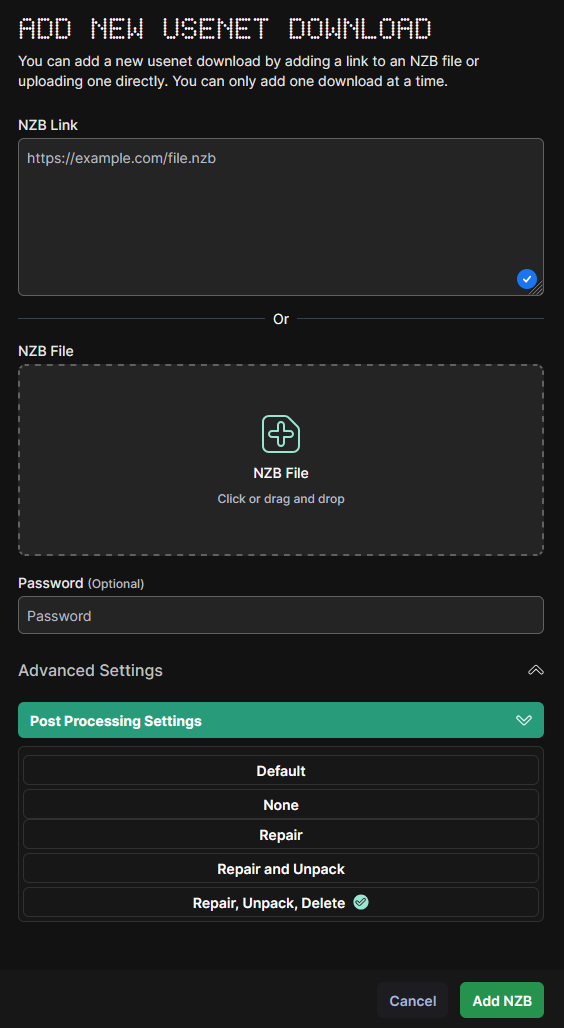
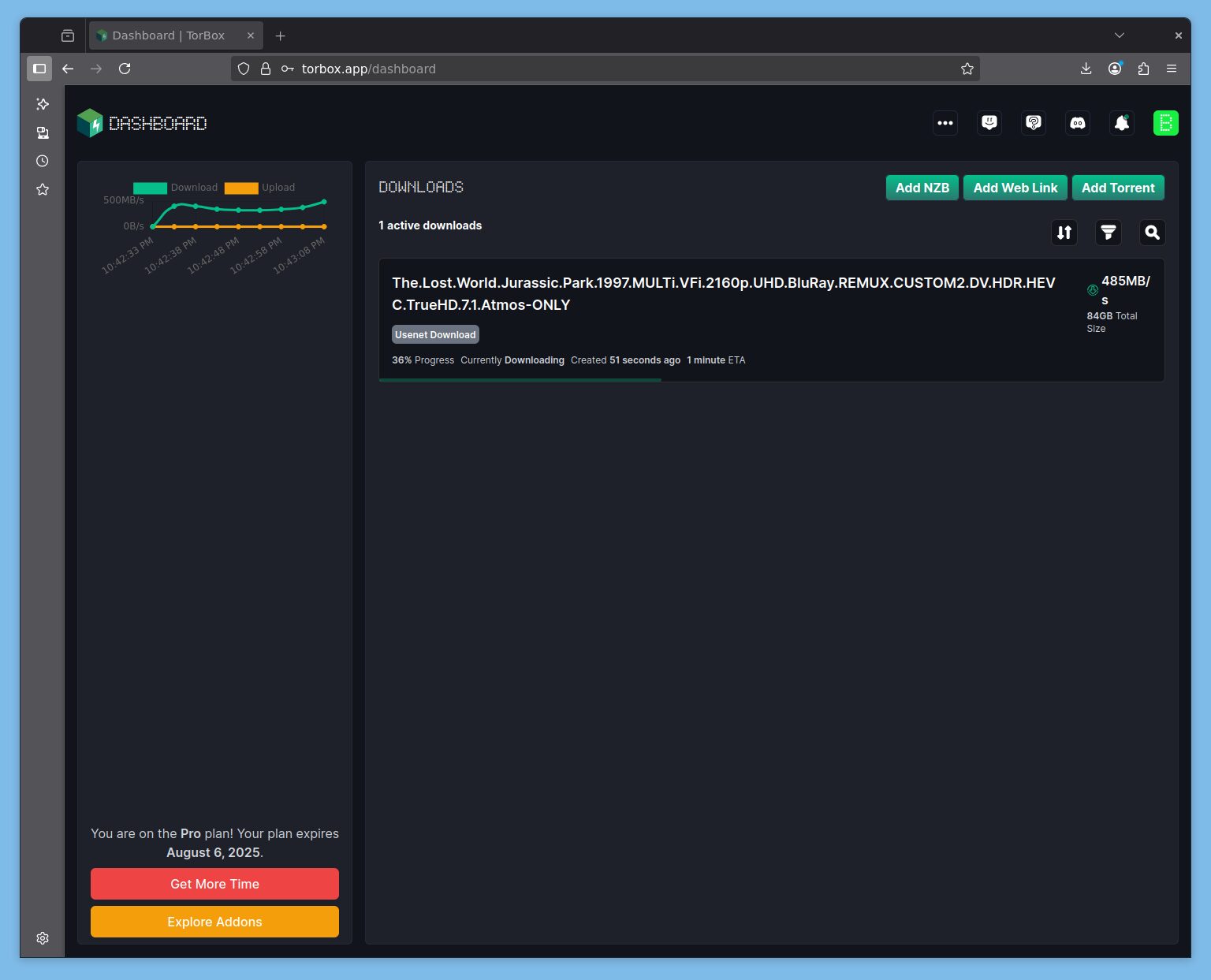
Test avec un .nzb. On peut soit envoyer le fichier soit coller son URL (et ça marche avec « YGG »)
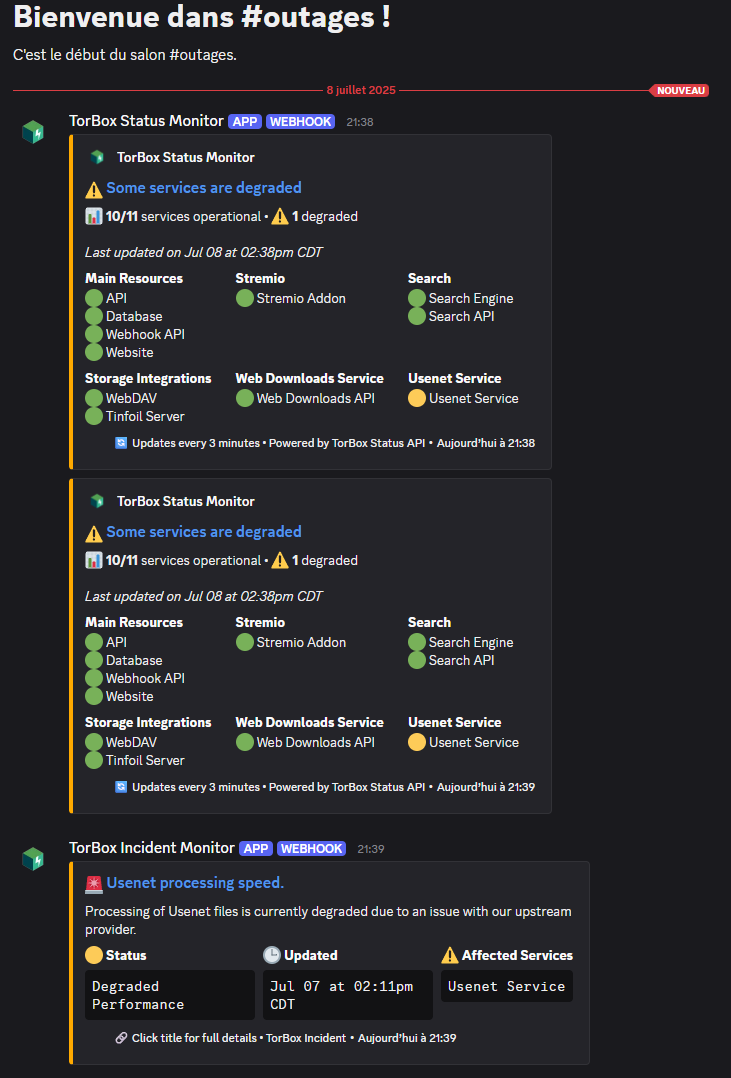
Il a dépassé les 500MBs en téléchargement. J’avais demandé le post-processing classique de réparation/décompression/suppression.
Je me fais confirmer par le support que les serveurs sont en cours d’upgrade, sans délai, et que pour l’instant ça peut en effet ramer pour des .nzb de près de 100Go.
large files like 84 gb files take a bit of time to process unfortunately. The Servers are actually being upgraded, and soon it’ll be a lot faster (no eta though)
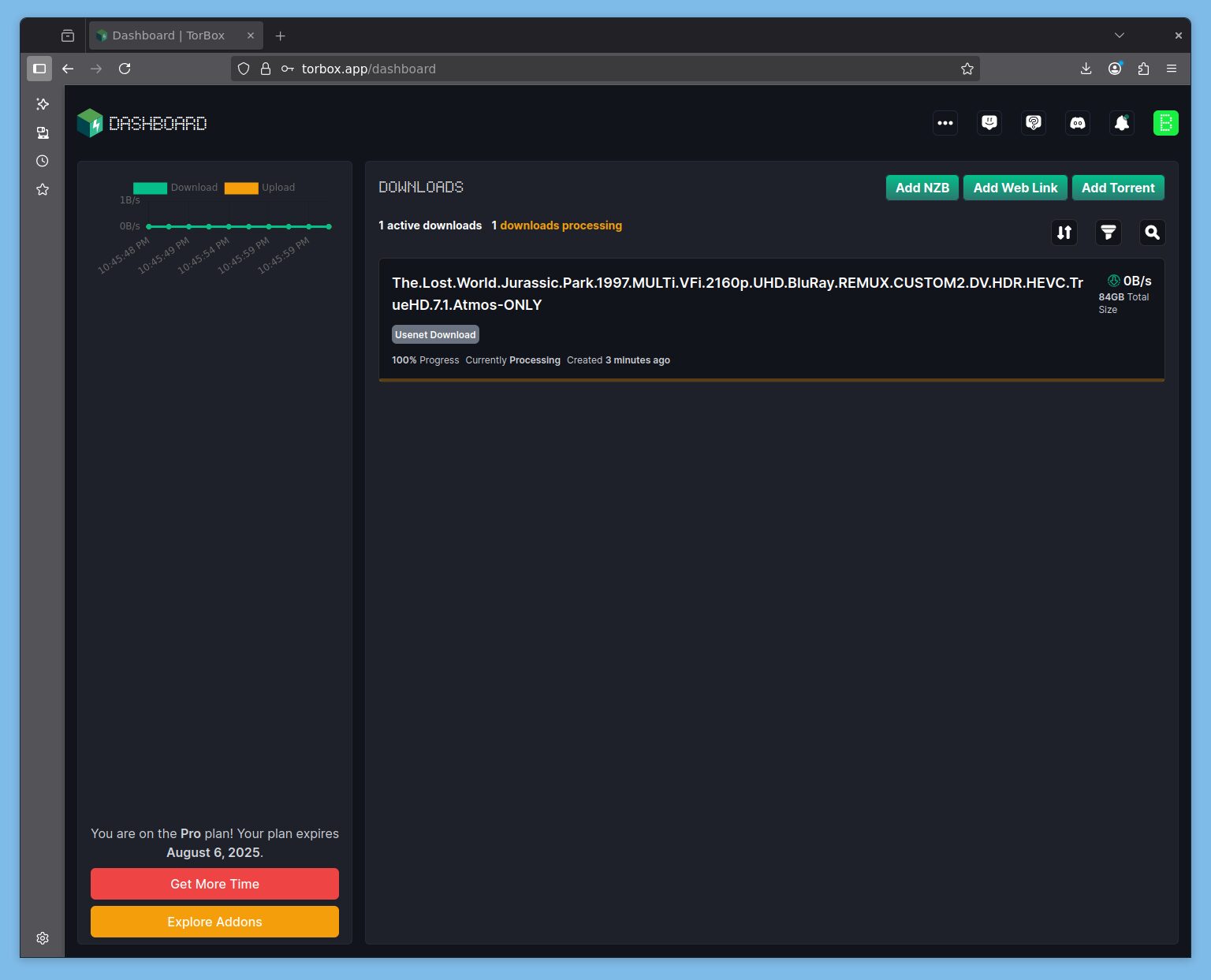
Ça fait maintenant plus de 15 jours que cet article est en rédaction et c’est bon, les serveurs ont été upgradés, les services revus.
Malgré un SAV géré notamment via un bot, en sus du Staff, TB rencontrait pas mal de soucis
On peut d’ailleurs suivre les incidents et leurs résolutions via la page dédiée.
Torbox me permet de télécharger un .nzb de 79Go en moins de 10 minutes, avec un débit moyen de téléchargement de 160MBps, auxquels il faut ajouter 4 minutes de post-traitement (il était posté avec archives, ce qui est de moins en moins le cas). C’est bien plus rapide qu’à l’époque ! Malgré une vitesse de DL plus faible.
Je viens de lancer un petit fichier de 4GB postés sans compression. DL à 1GBps et post-traitement en quelques secondes !
Et le changelog du moment fait la part belle aux animes notamment et ajoute TB comme source de recherche de contenus pour les *arrs. Faut pas s’attendre à trouver de suite beaucoup de contenus FRENCH/MULTi cependant, les francophones étant plus sur AllDebrid/RealDebrid.
In v7.4 we introduce: Kitsu compatibility (among other popular catalogs compatibility), Better Voyager Search API metadata (for developers), Nyaa and Animetosho trackers built in for better anime stream results, Much faster stream searches with BYOI, Torznab and Newznab endpoint for searching via Arrs or NZBHydra2, Over a dozen new filehosters to download from, Optimized API endpoints with some savings resulting in more than 300% faster start times, Faster stream start times ^, More Stremio settings, More performant dashboard, Seemingly infinite amount of bug fixes and minor changes.
Au final, TorBox est un beau projet. Dans la gamme de prix des seedboxes complètes typées Ultra.cc, FeralHosting etc, TB propose un service différenciant et complètement clés en mains pour le streaming facile via Stremio avant tout. Certes, on ne peut y installer d’application contrairement à certains concurrents mais le service comprend tous les outils pour chercher, télécharger, partager, stocker et consommer des contenus numériques, qu’on soit amateurs de Stremio, Kodi, Jellyfin, Plex… et avec ses propres indexeurs ! Avec une communauté élargie et dynamique, un support réactif et sympathique, TorBox est une belle découverte et j’espère leur voir un avenir au niveau, justement, d’Ultra et Feral.
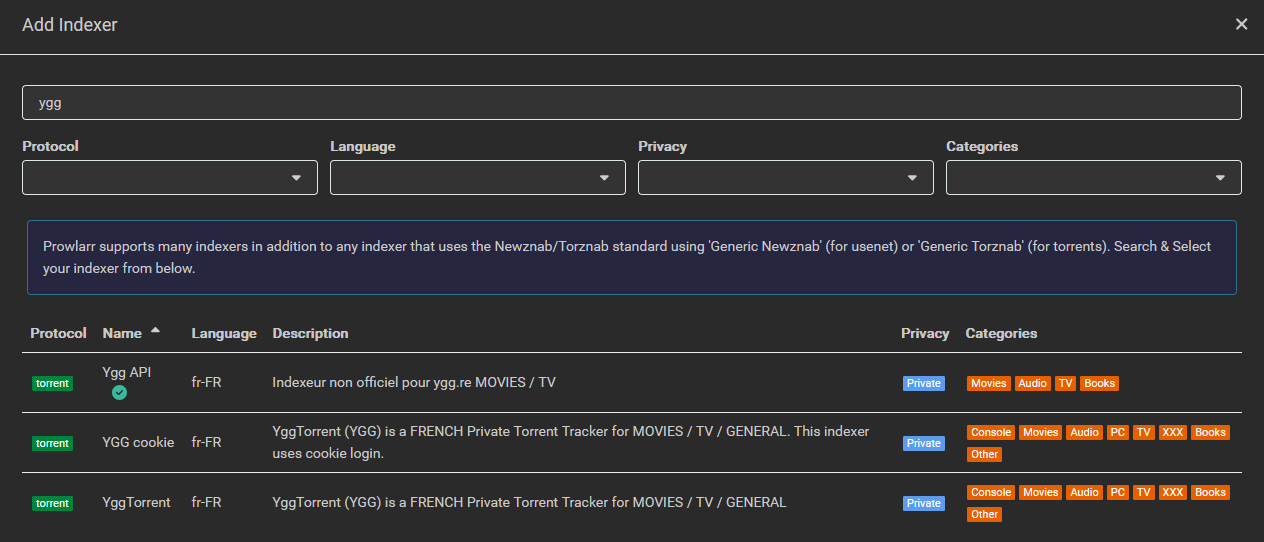
Prowlarr permet de mixer plusieurs indexeurs (BitTorrent/Usenet) pour faire des recherches et téléchargements. Il existe des indexeurs pour YGGtorrent mais ils sont souvent dans les choux du fait de la protection CloudFlare du site. Certes on trouve des outils annexes pour tenter de passer outre mais sinon on peut faire plus simple avec ygg-api (yggapi.eu dont le code n’est pas publié pour ne pas être contré).
Merci à Clemv95 pour le fichier de configuration. Je le poste aussi sur mon blog au cas où.
EDIT du 25.07.25 : Glira fait une remarque qu’il semble bon de transmettre aux néophytes ou à ceux pour qui YGG est quasi leur unique source. Je suppose cependant que la personne derrière ce site n’a absolument pas besoin de nos passkeys pour ce site où il est si facile de se faire un compte et du ratio (sans Joal), tout comme je présume qu’elle est sur les trackers privés francophones…
Attention ce pendant, cette solution envoie votre passkey sur le serveur de yggapi.eu. Et il est extrêmement facile pour lui de les enregistrer. Utilisez ce service que si vous êtes prêt à perdre votre compte ygg en cas d’exploitation de votre passkey. Ou renseignez une fausse passkey, et modifiez le fichier torrent après téléchargement.
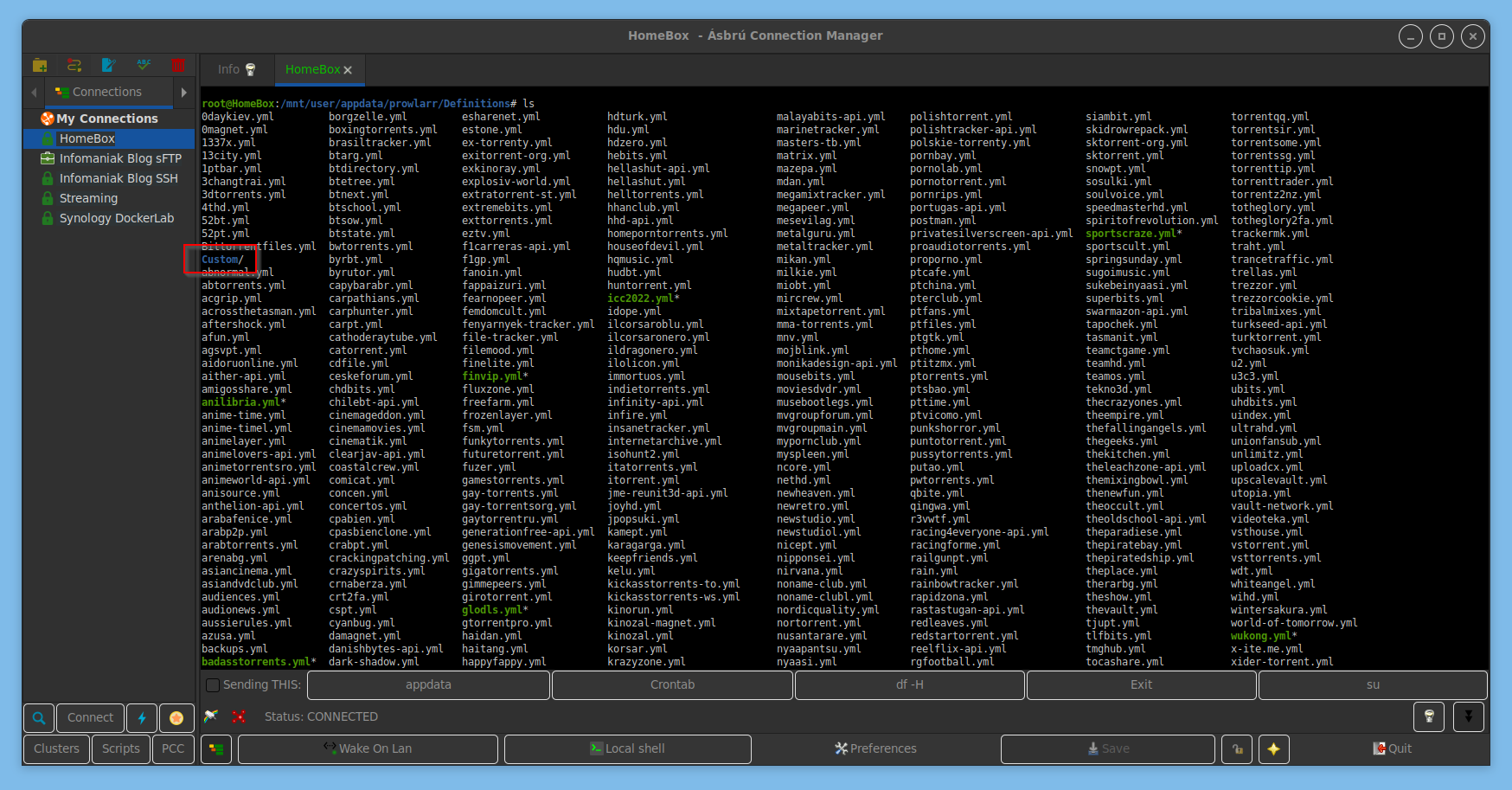
Dans l’installation de Prowlarr, aller dans le dossier Definitions et créer le dossier Custom.
Puis créer/mettre dedans le fichier ygg-api.yml et relancer Prowlarr. Ygg-API est maintenant disponible dans la liste des indexeurs.
Pour le configurer, il suffira d’ajouter une passkey. Trouvable sur son compte YGG ou dans l’URL d’annonce du tracker si vous avez déjà des .torrents de chargés.
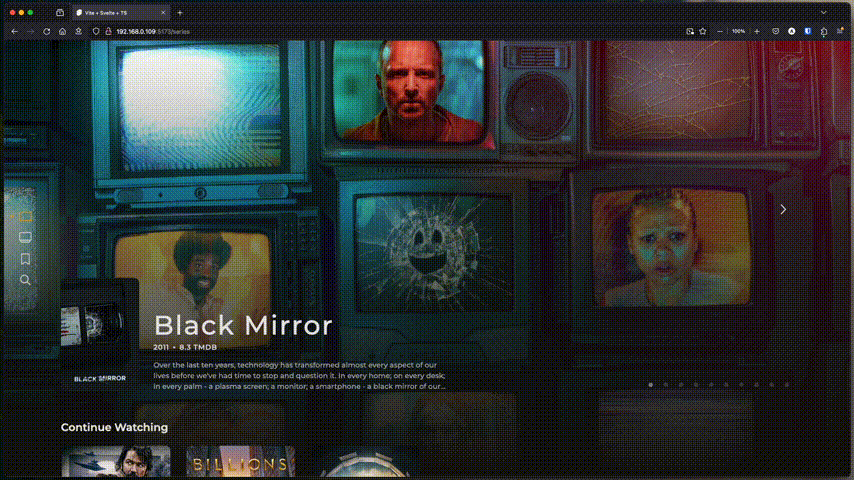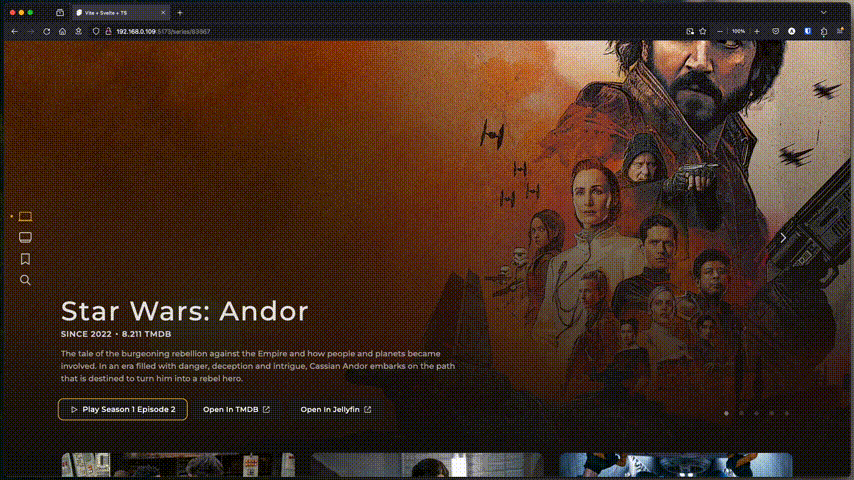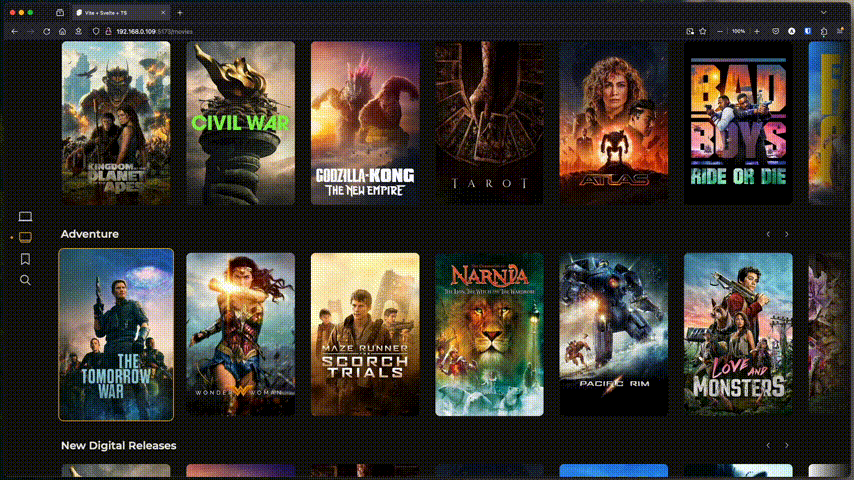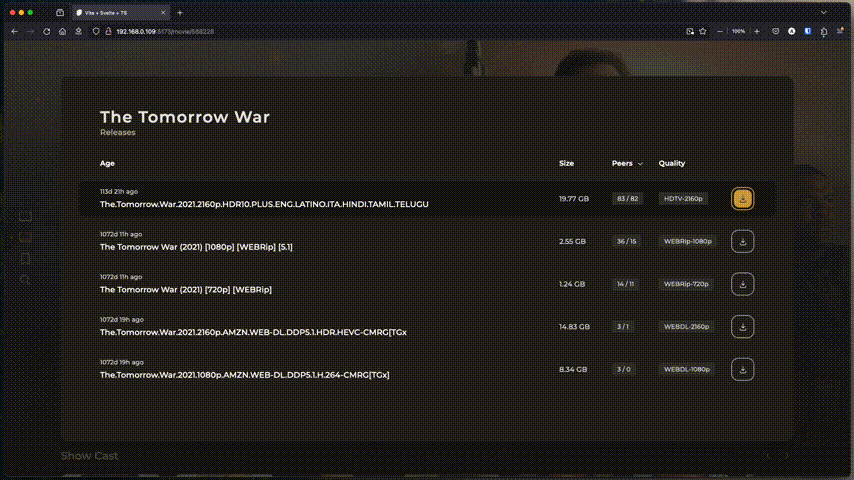
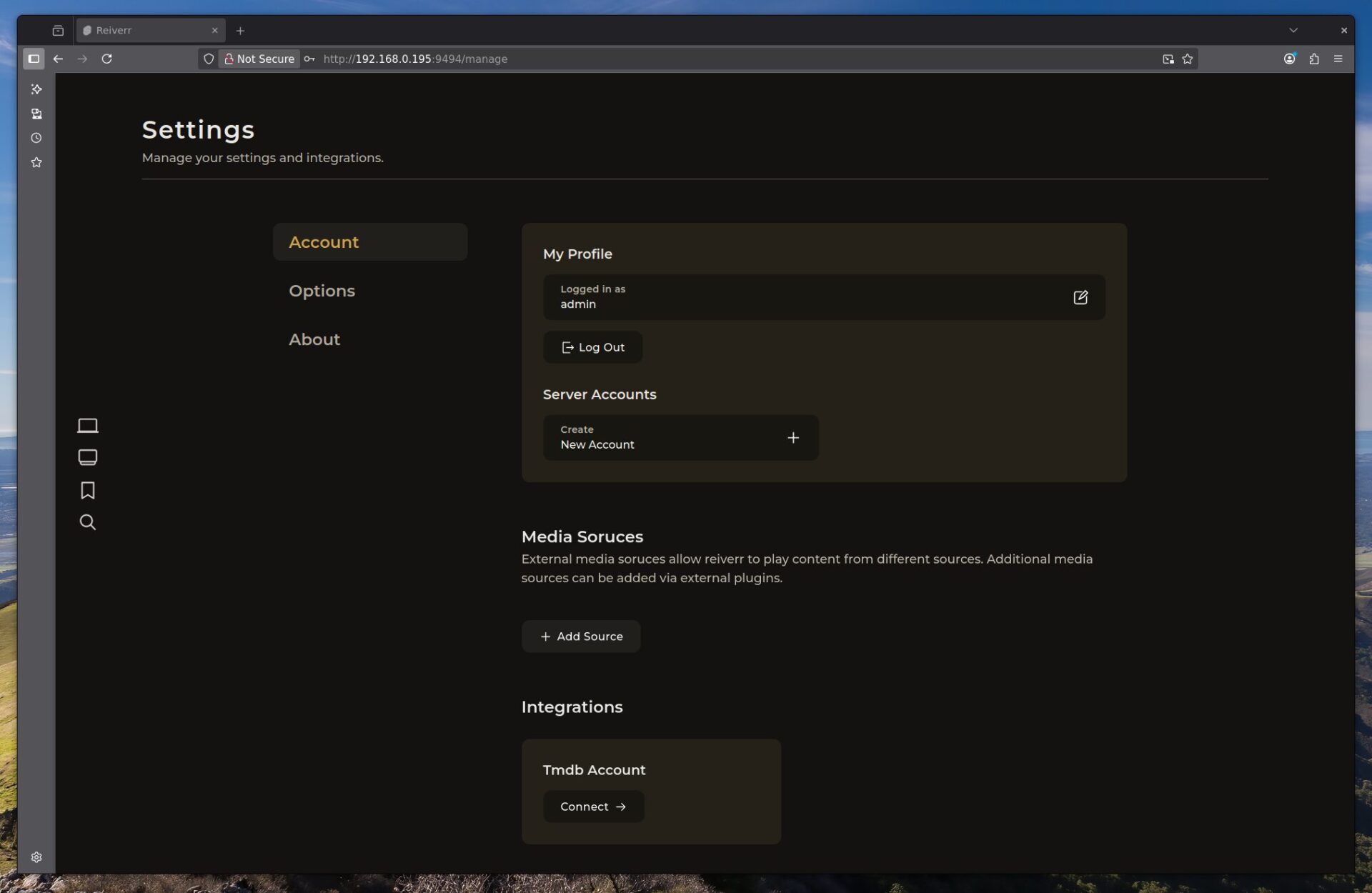
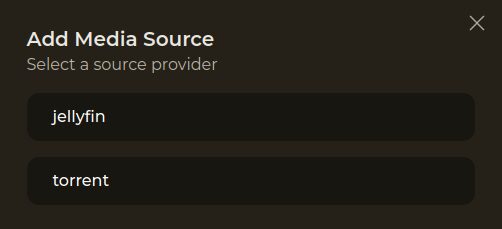
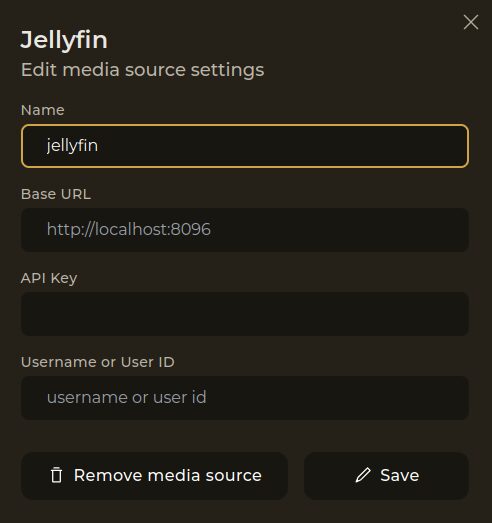
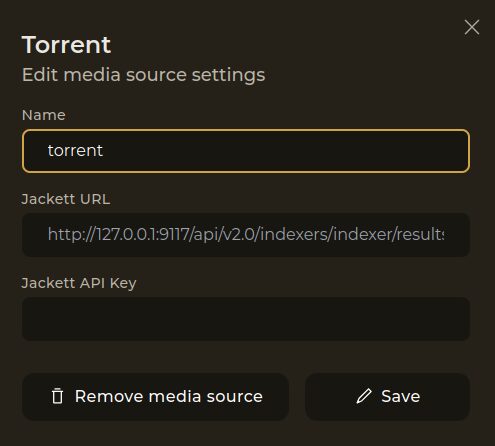
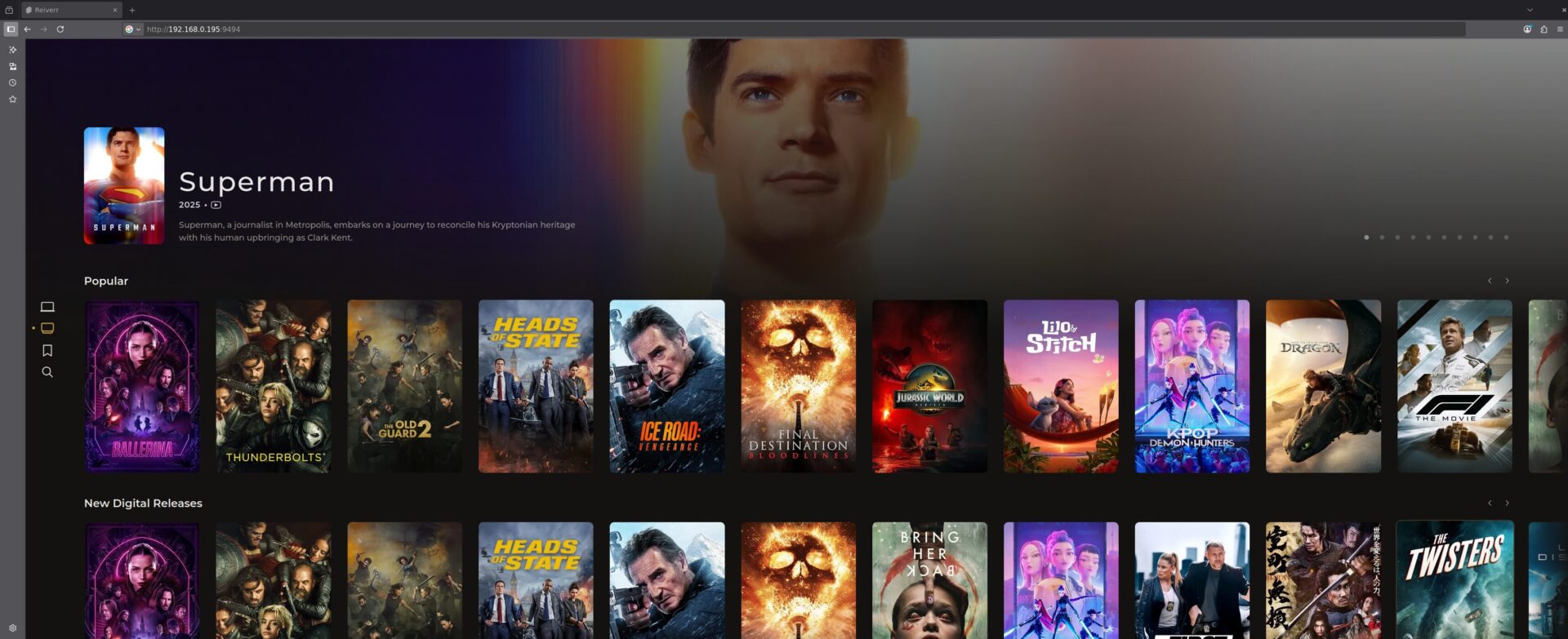
J’en avais parlé rapidement sur un forum il y a un peu plus d’un an, Reiverr se veut être une interface globale pour l’indexation et la recherche/découverte de contenus audio/vidéo.
C’est une alternative à Overseerr, qui englobe plusieurs fonctionnalités de parcours de librairies Jellyfin, recherche de contenus avec les *arrs, découverte via TMDB et qui permet la lecture directement via Jellyfin et en Torrent-Streaming (donc à faire passer par un VPN).
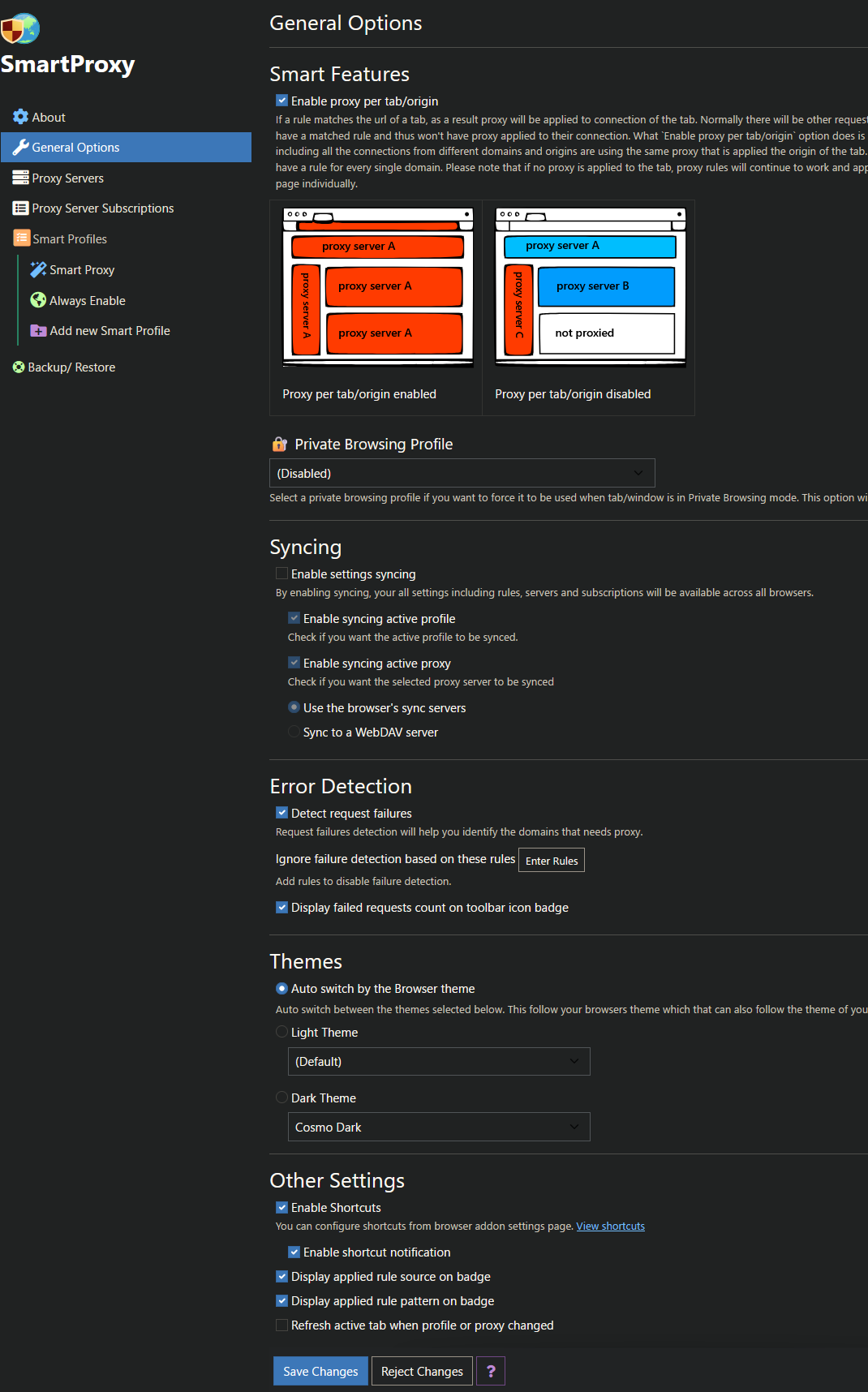
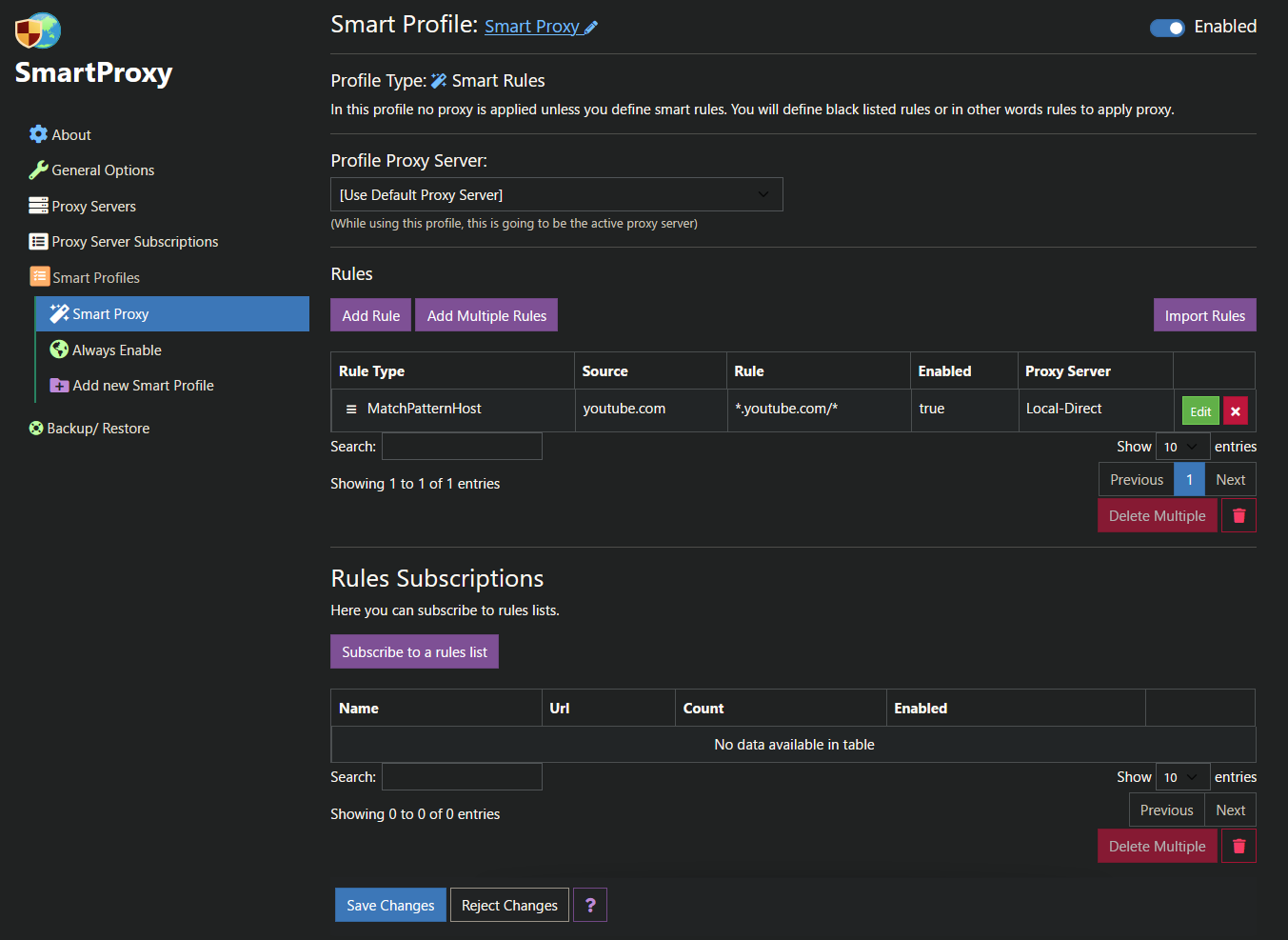
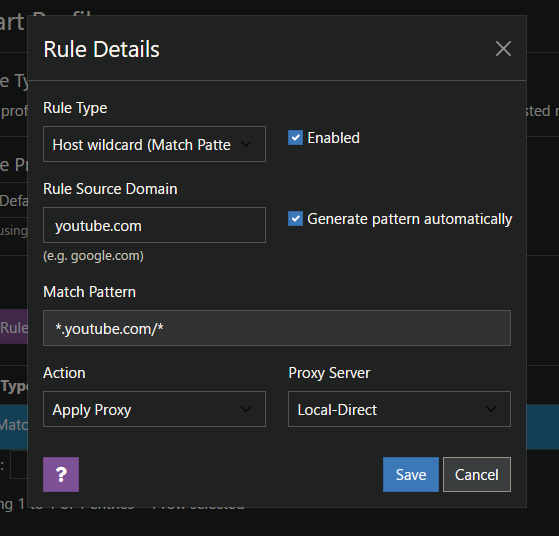
Je navigue tout le temps sous VPN et il arrive que certains sites soient bloqués du fait de l’IP utilisée. C’est par exemple le cas de YouTube qui veut donc que je me connecte pour vérifier mon droit d’accès. SmartProxy est un plugin Firefox (tous OS, Android), Chrome & Edge (…) qui permet d’ajouter des proxies personnels ou via liste et surtout de créer des règles d’utilisation. Je le trouve plus simple (et « moderne ») que FoxyProxy que j’ai utilisé des années.
Je me remets doucement dans l’univers des *arrs & médiathèques et je dois dire qu’en 2 ans, des solutions ont poussé comme les champignons en Corrèze en plein automne !
J’en étais resté aux *arrs + Plex/Emby/Jellyfin et le stockage sur NAS, serveurs ou en Cloud via rClone et Dropbox/Telegram (abus). Les hébergeurs du moment sont Uloz, Quotaless et Pikpak. Seulement, depuis 2014/2015 avec rClone + Amazone, on sait bien qu’aucune solution de hoarding de ce genre n’est pérenne. Ou reste au même prix. Ou les deux, coucou Google Workspace.
Il y a toujours la solution des serveurs dédiés type OneProvider, Hetzner ou encore SeedHost mais les prix montent toujours petit à petit et on reste très loin des Po de stockage nécessaires à ce que j’appelle en bon vieux crouton : le P4S.
J’ai aussi profité du streaming depuis Usenet (via rClone) mais ce projet n’est pas abouti, non pas du fait du développeur, mais tout simplement parce que la purge se fait de plus en plus présente sur les newsgroups. Là où on pouvait archiver le contenu de trackers BitTorrent y’a 10-15 ans, on sait maintenant que tout peut être effacé sans prévenir. Faut dire… vu les prix des abonnements et la place nécessaire, y’a un choix à faire.
L’eldorado du moment ce sont les débrideurs. Ce qui était avant plutôt exploité en streaming pour l’IPTV est maintenant « mainstream ». Les *arrs ou autres solutions envoient les fichiers .torrents (AllDebrid, RealDebrid etc) ou .nzb (TorBox notamment) chez un débrideur qui télécharge et met en cache les fichiers cibles. On utilise ensuite Stremio ou un montage (rClone ou autre) pour en profiter via son lecteur favori Plex/Emby/Jellyfin.
Et c’est là que c’est la foire d’empoigne niveau outils… L’un remplaçant l’autre, certaines versions sous abonnement (Patreon), outils compatibles uniquement avec certains hébergeurs etc. Les 2 Discord en vue pour tous ses sujets sont celui de SSDv2 (francophone) et Ragnarok (EN). Et je vous glisse également celui de Whamy qui a monté TorBox chez qui je suis client et que je vais pérenniser vu qu’ils permettent d’utiliser Usenet. Ce sera sans doute mon prochain article.
Ici je teste RealDebrid et RDT-Client. RD étant monté avec rClone et Zurg pour une lecture sur Plex. Un grand MERCI à Wassabi qui m’a bien aidé quant aux foutus méandres des droits sous UNRAID Niveau arborescence, tout va se passer dans /mnt/user/RealDebrid
root@HomeBox:/mnt/user/appdata/zurg/scripts# tree /mnt/user/RealDebrid/
/mnt/user/RealDebrid/
├── Medias
│ ├── Concerts
│ ├── Docs
│ ├── Films
│ ├── Series
│ └── Spectacles
├── local
├── rdt
├── seedtime
└── zurg
├── __all__
├── __unplayable__
└── version.txt
Medias : stockage des médias symlinkés depuis RD
local : dossier de téléchargement des symlinks pour RDT-Client, où les *arrs viendront les prendre pour les traiter
rdt : dossier de téléchargement des .torrents ajoutés sur RD par RDT afin de les seeder depuis chez moi (via VPN)
seedtime : le dossier de téléchargement/seed des .torrents. Je seed 1 mois via qBitTorrent (44000 minutes)
Zurg : montage de RD en WebDav. C’est de là que seront faits les symlinks pour /Medias
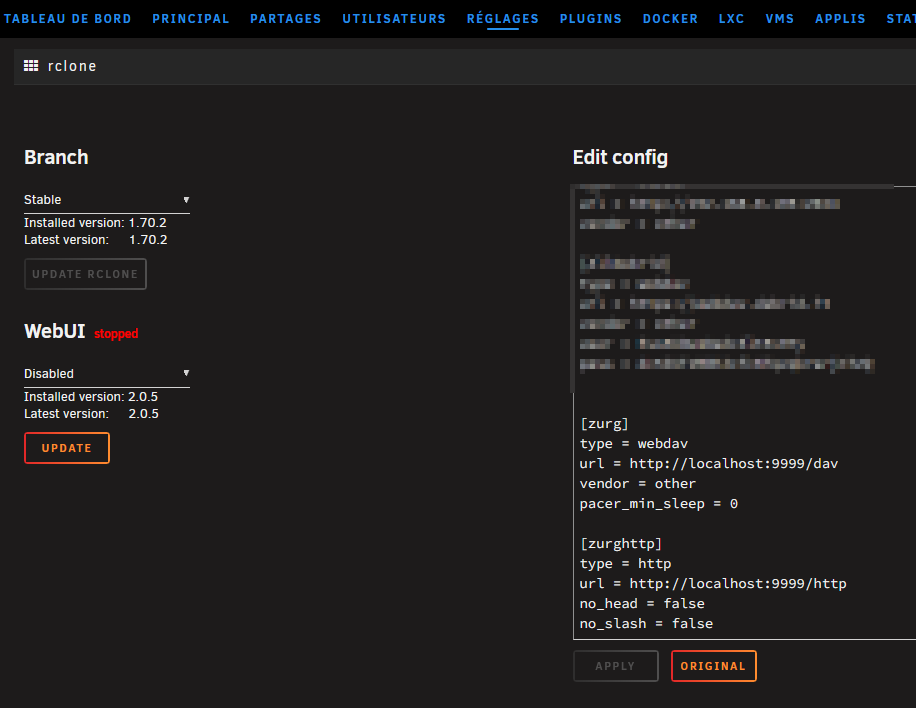
Commençons par rClone. Je suis sur UNRAID mais ça marche bien entendu sur tout Linux/Unix et j’utilise le plugin de Waseh qu’on trouve dans les Applis. Testé avec rClone normal et en BETA, RàS. Édifier le fichier de configuration et y placer les remotes pour Zurg.
[zurg]
type = webdav
url = http://localhost:9999/dav
vendor = other
pacer_min_sleep = 0
[zurghttp]
type = http
url = http://localhost:9999/http
no_head = false
no_slash = false
On peut ensuite monter RD avec un petit script rClone dans user-scripts (ou systemd sur un autre OS) : Comme je suis sur UNRAID, que user-script lance les scripts en root mais que mes Dockers tournent avec l’UID 99 et le GID 100, je les force pour ce script rClone (merci Wassabi).
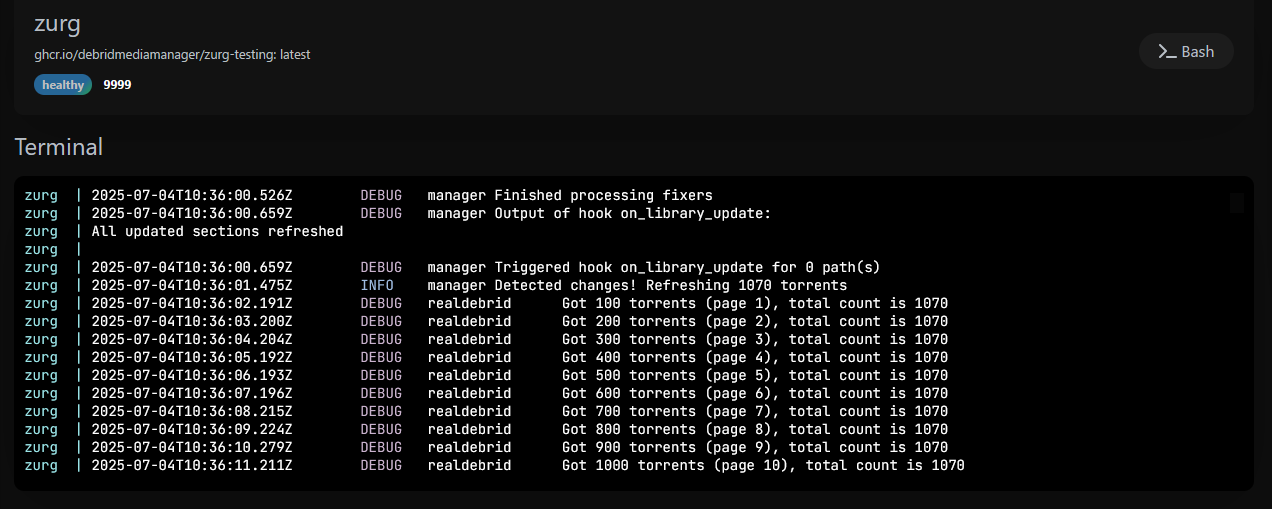
Passons à Zurg(-testing) : J’utilise la version gratuite (sans DMM). C’est un WebDav pour RealDebrid qui n’en propose pas et qui permet de le monter dans rClone. AllDebrid par exemple dispose d’un WebDav en standard, c’est pourquoi on peut le monter directement dans rClone. Si c’était simple…
Si vous devez mapper d’autres ports pensez à les changer dans la configuration de rClone.
Le script d’update de Plex (en cas de changement de symlinks) : Il faut y mettre l’URL du serveur Plex et son token ainsi que le dossier de montage de RealDebrid.
#!/bin/bash
# PLEX PARTIAL SCAN script or PLEX UPDATE script
# When zurg detects changes, it can trigger this script IF your config.yml contains
# on_library_update: sh plex_update.sh "$@"
# docker compose exec zurg apk add libxml2-utils
# sudo apt install libxml2-utils
plex_url="https://plex.domain.tld"
token="***"
zurg_mount="/mnt/user/RealDebrid"
# Get the list of section IDs
section_ids=$(curl -sLX GET "$plex_url/library/sections" -H "X-Plex-Token: $token" | xmllint --xpath "//Directory/@key" - | grep -o 'key="[^"]*"' | awk -F'"' '{print $2}')
for arg in "$@"
do
parsed_arg="${arg//\\}"
echo $parsed_arg
modified_arg="$zurg_mount/$parsed_arg"
echo "Detected update on: $arg"
echo "Absolute path: $modified_arg"
for section_id in $section_ids
do
echo "Section ID: $section_id"
curl -G -H "X-Plex-Token: $token" --data-urlencode "path=$modified_arg" $plex_url/library/sections/$section_id/refresh
done
done
echo "All updated sections refreshed"
# credits to godver3, wasabipls
Son fichier de configuration : Pour la version gratuite. Très épuré, selon les recommandations de Wassabi. Y ajouter son token RealDebrid.
RDT-Client est un outil qui se fait passer pour qBitTorrent auprès des *arrs et permet de télécharger des .torrents via un débrideur, d’en télécharger le symlinks pour que les *arrs puissent faire leur travail et enfin, sur option, de télécharger le .torrent localement afin de le seeder pour respecter à la fois les règles du P2P mais aussi des trackers.
RDT est compatible avec AllDebrid, RealDebrid, TorBox, Premiumize et DebridLink. Il ne peut cependant utiliser qu’un débrideur à la fois. Si vous avez plusieurs comptes il faudra lancer autant d’instances et répartir leur utilisation avec les tags. Plutôt que d’avoir les classiques radarr, sonarr on peut imaginer radarr, sonarr, radarr4k, sonarr4k, radarranimes, sonarranimes etc.
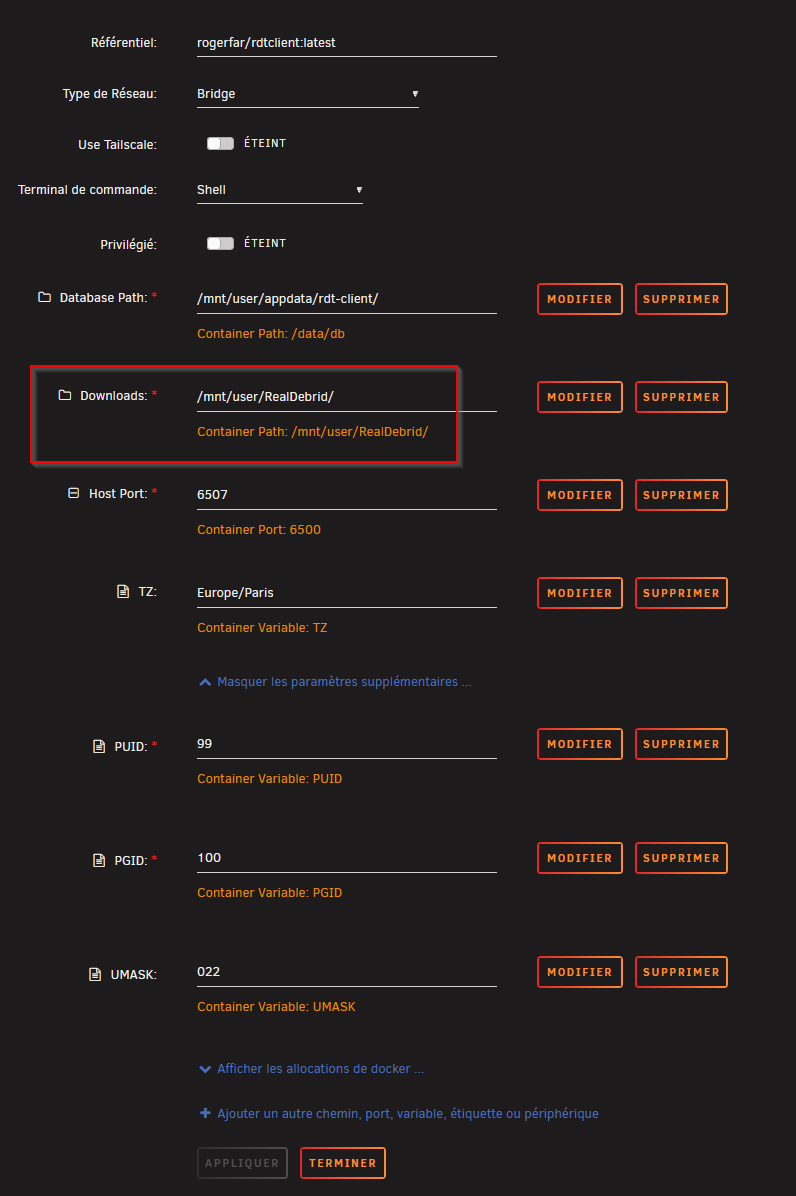
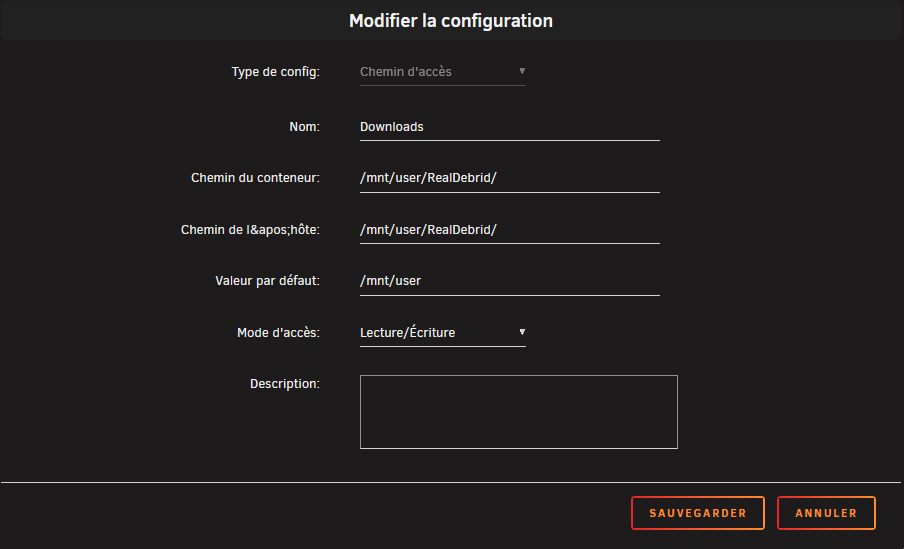
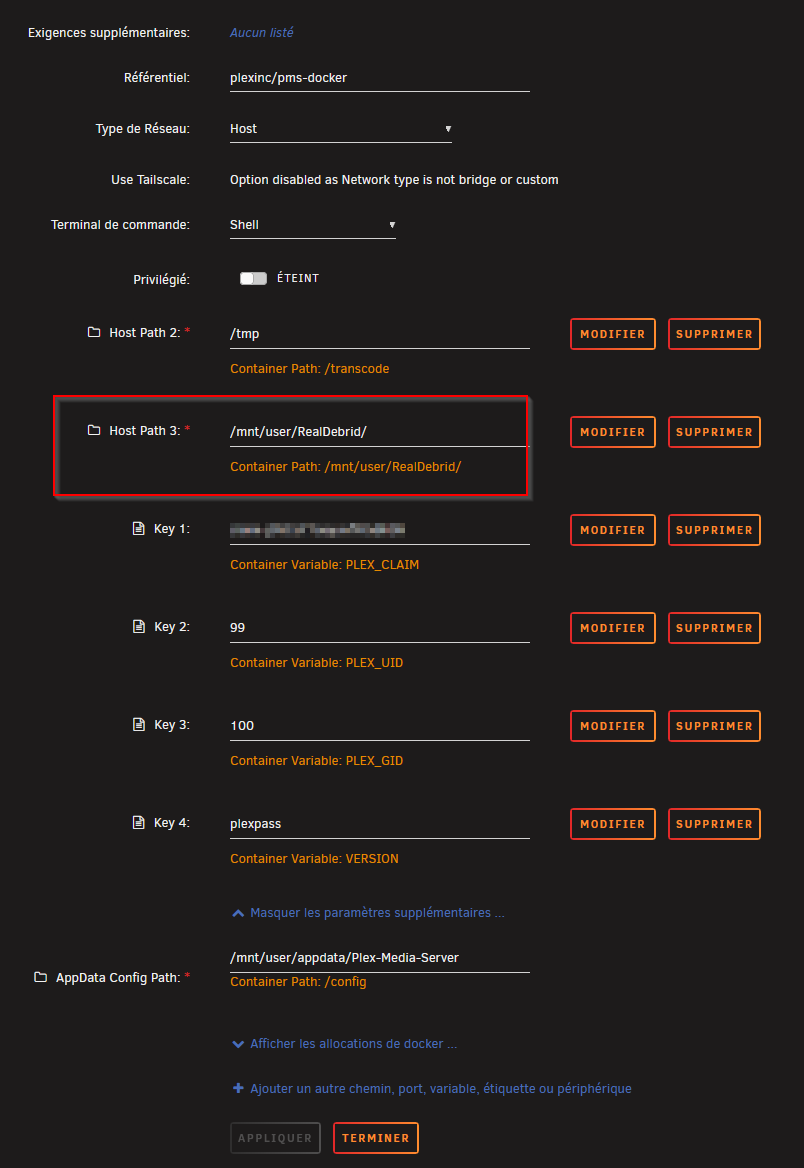
Afin de prévenir tout couac lié aux droits d’accès entre RDT, les *arrs et Plex, remplacer le volume par défaut du Docker pour Downloads et mettre en local comme en container /mnt/user/RealDebrid/
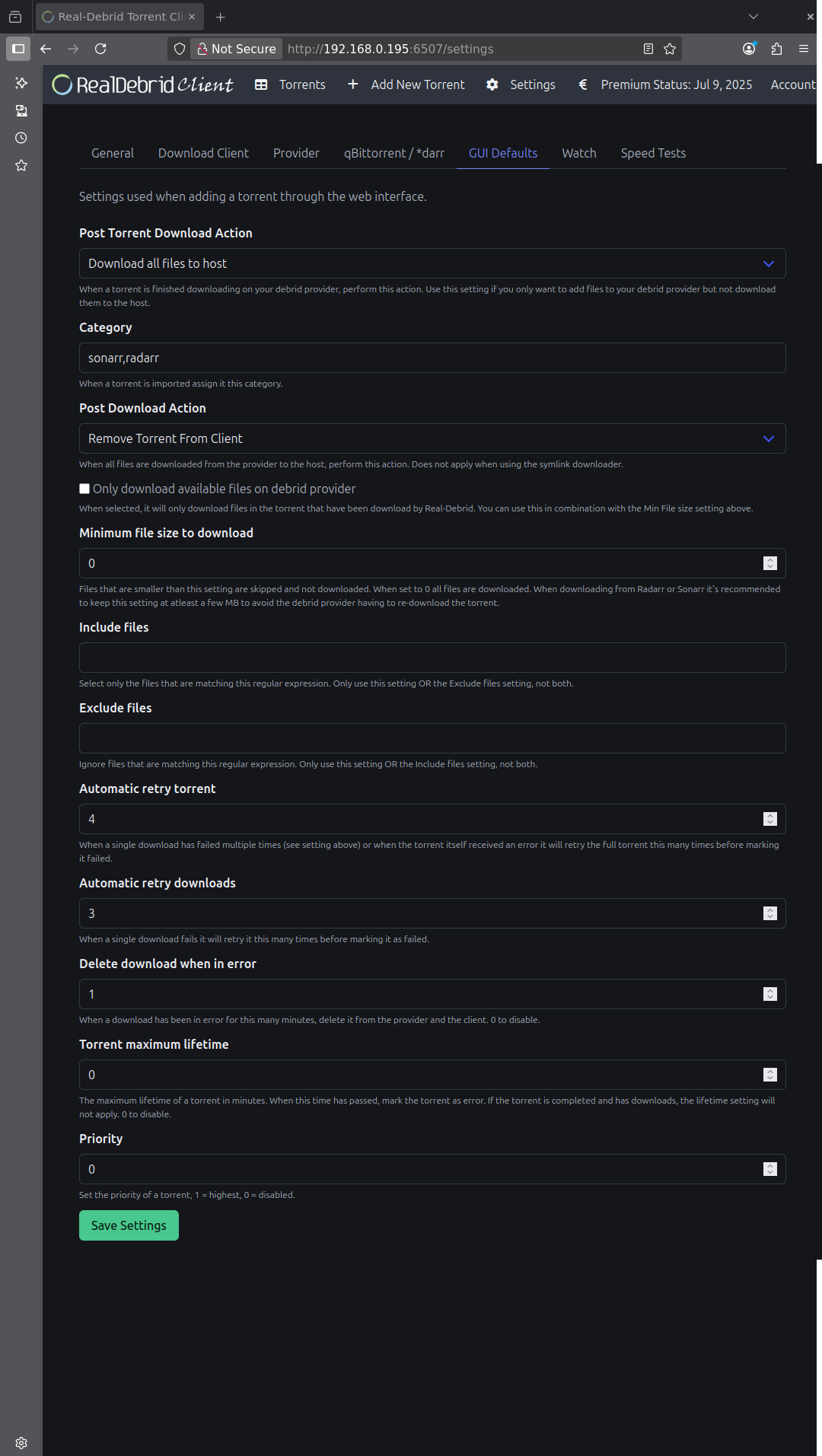
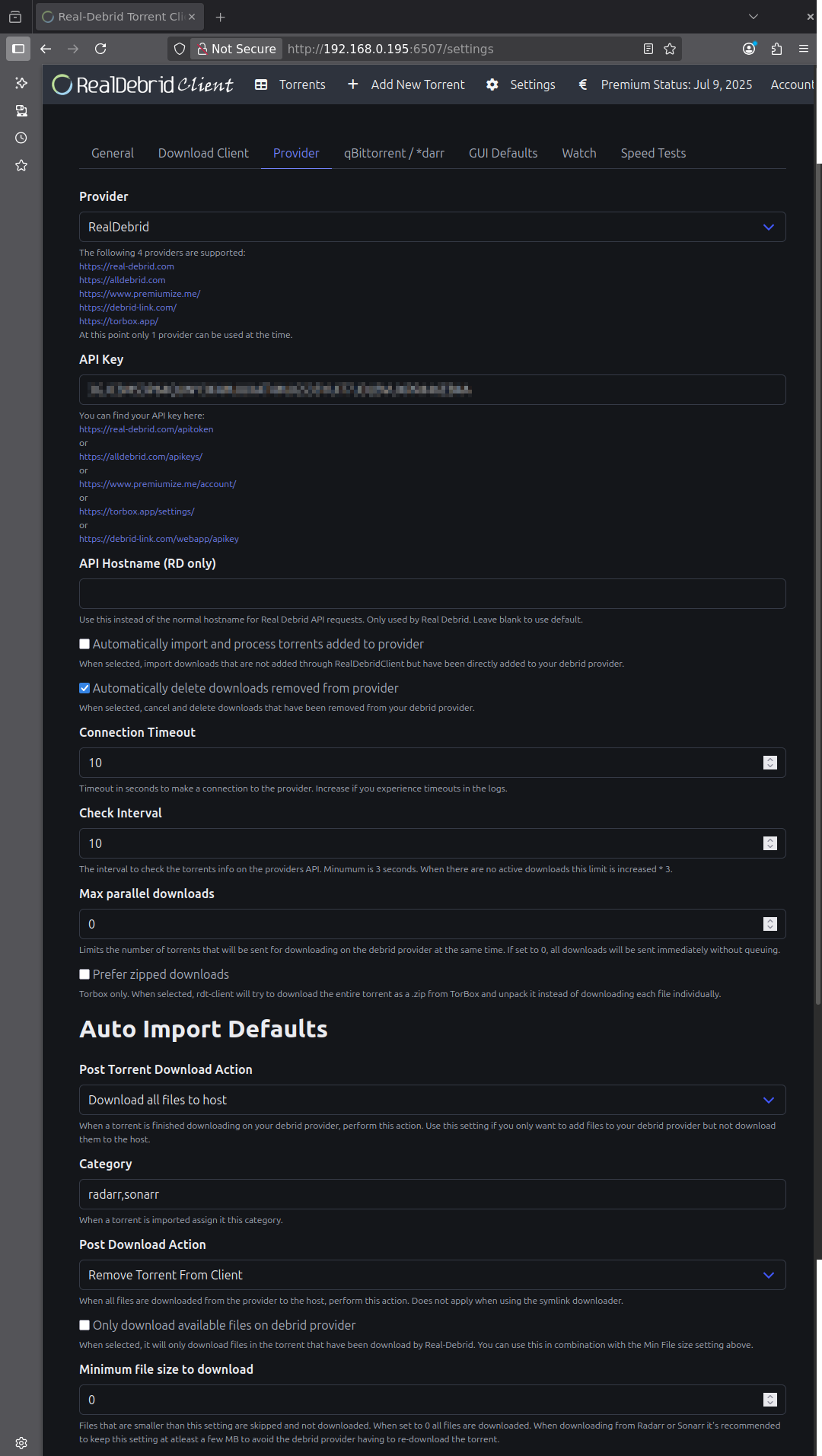
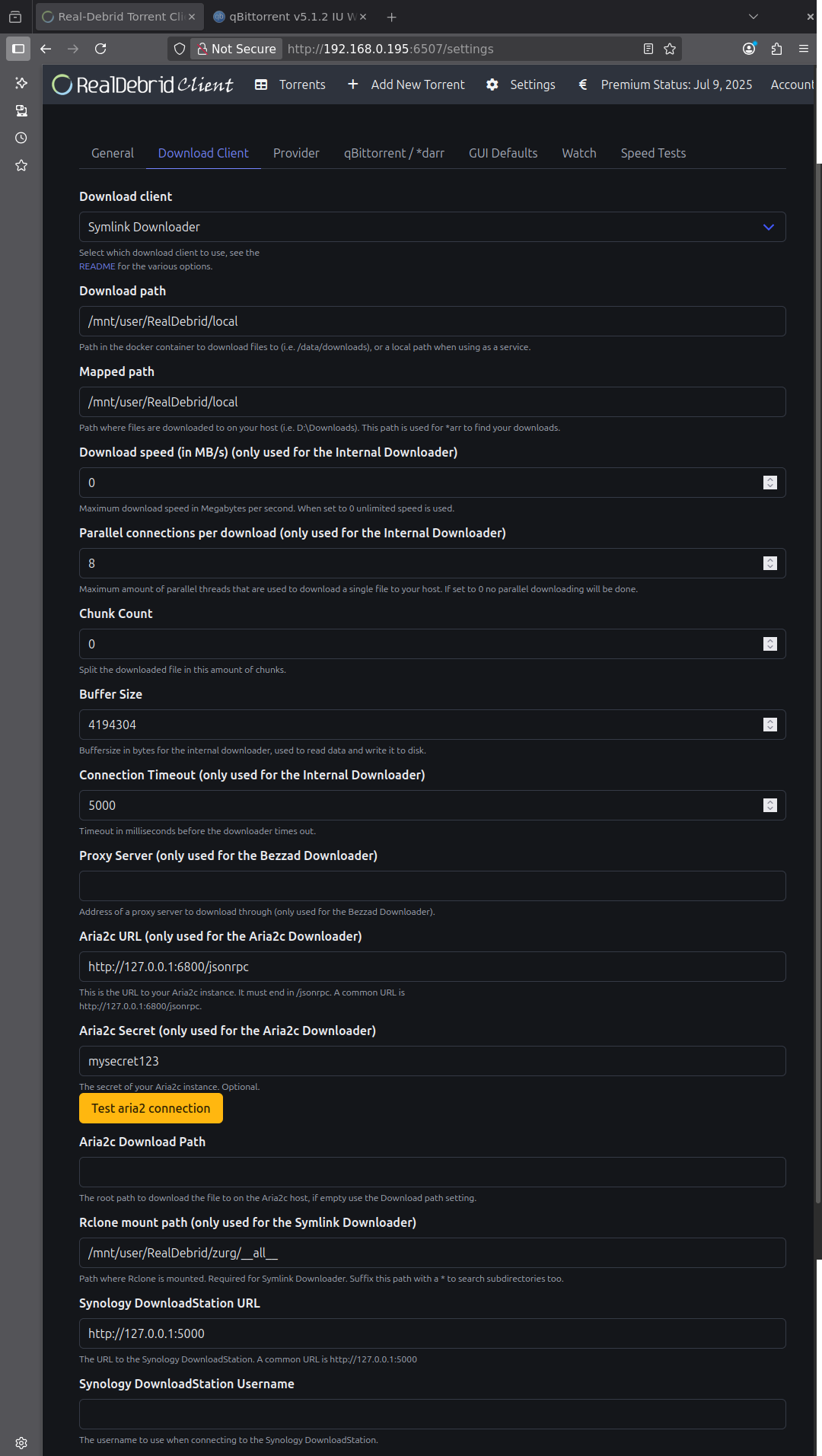
En se rendant sur la WebUI, créer un user:pwd et commencer à configurer en se rendant sur l’onglet GUI Defaults.
Sélectionner Download all files to host. Vu qu’on va utiliser le client de téléchargement « Symlink Downloader », ça va bien rapatrier les symlinks dans le dossier /mnt/user/RealDebrid/local où les *arrs iront les chercher pour les ranger correctement dans les bibliothèques qui sont dans /mnt/user/RealDebrid/Medias
Indiquer les catégories radarr,sonarr qui seront utilisées par les applications éponymes. Et en rajouter selon vos besoins et le nombre d’instances de RDT que vous voulez.
En Post Download Action, choisir de retirer le .torrent du client
Activer (remplacer 0 par 1) Delete download when in error. De cette manière RDT supprimer tout .torrent foireux (pas de téléchargement, blacklisté par RD etc) et donc les *arrs sauront qu’il faut en chercher un autre
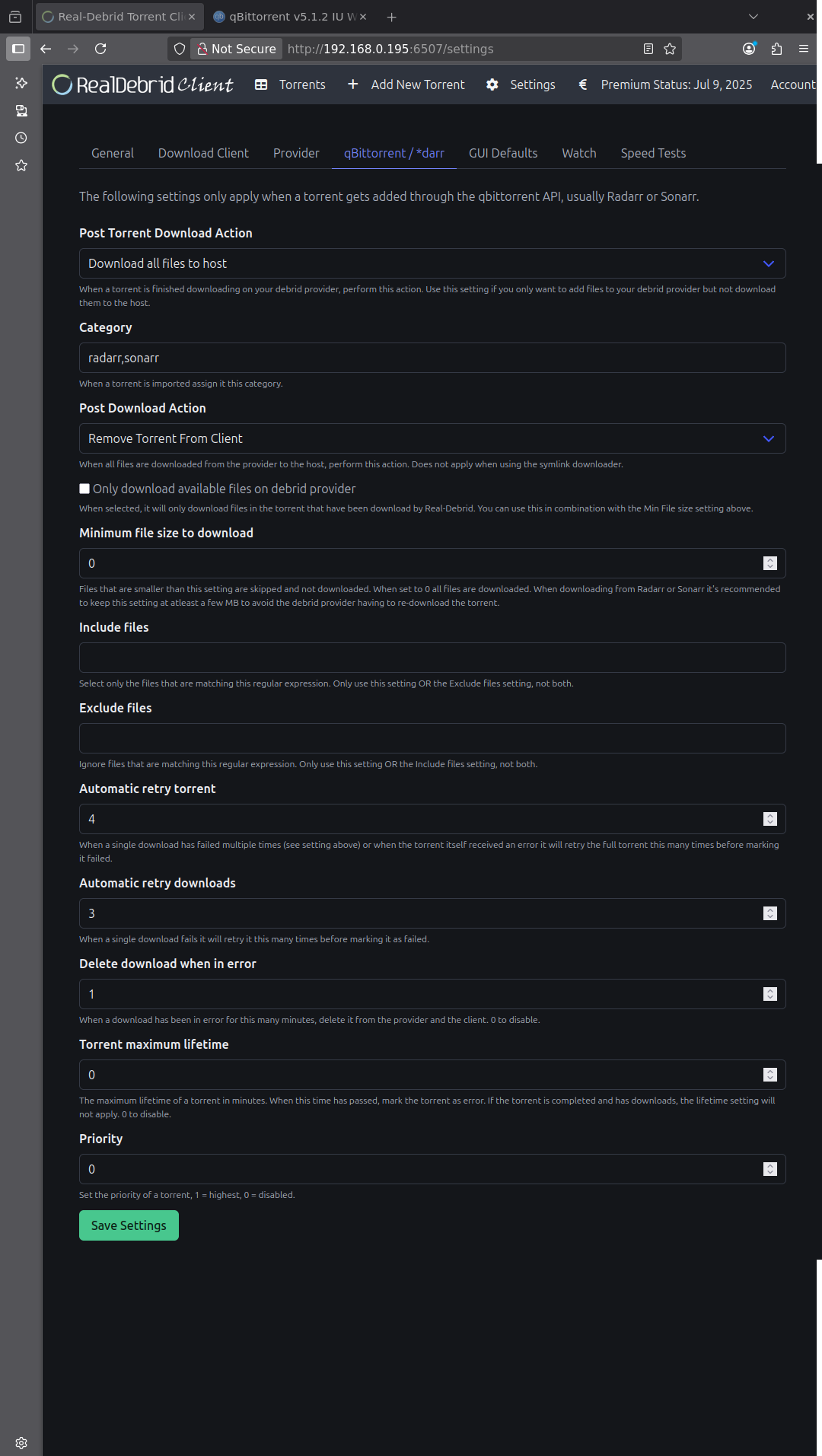
Onglet Provider : choisir un débrideur et sa clé API.
Cocher Automatically delete downloads removed from provider pour ne pas avoir de symlink orphelin. Si Radarr ou Sonarr voient un fichier manquant ils le remettront en téléchargement.
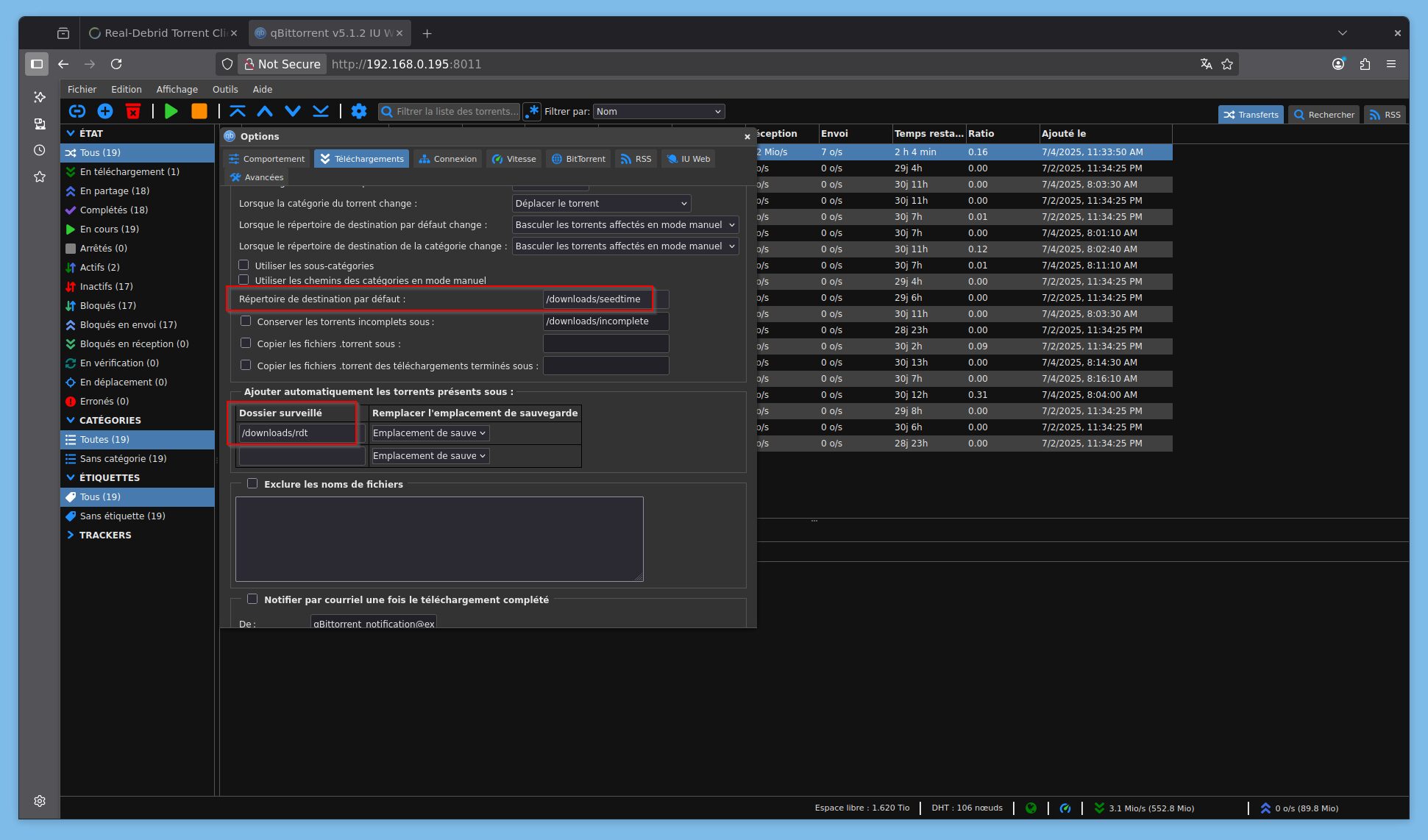
Onglet General, vous pouvez désactiver l’authentification en passant si c’est qu’un local chez vous, il faut indiquer le chemin de sauvegarde des .torrents que RDT envoie sur le provider. Comme expliqué plus haut, chez moi c’est /mnt/user/RealDebrid/rdt
Le but étant de seeder correctement ces derniers. Sans parler des 7-8 sites FR/QC privés qu’on quasi tous dans nos Prowlarr/Jackett, même si on ne se sert que de YGGtorrent, ne pas seeder est contre l’esprit du P2P et surtout hors règles des dits trackers BitTorrent et on s’expose à un bannissement en ne jouant pas le jeu.
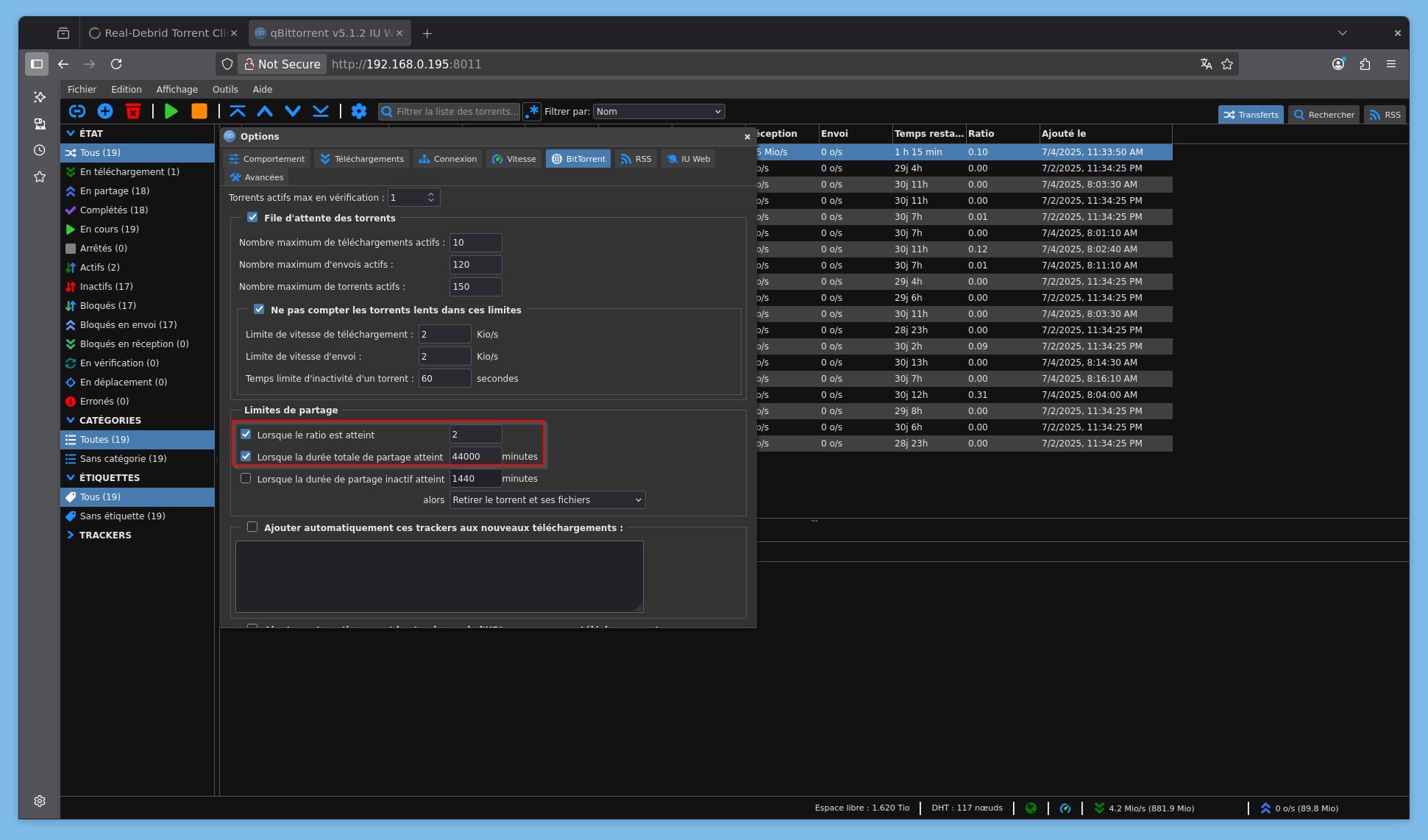
Si certains utilisent ruTorrent et ses plugins pour gérer finement le seedtime selon la source, je suis venu avec mes gros sabots et utilise qBitTorrent avec un seedtime unique d’1 mois (44000 minutes). Attention en passant, la dernière version de qBit déraille pour la WebUI, restez au max sur la 5.1.2
On continue avec l’onglet Download Client de RDT : sélectionner le Symlink Downloader.
Dans le dossier local /mnt/user/RealDebrid/local et le même en chemin mappé pour les *arrs, comme ça on n’a rien à configurer de leur côté
Et viser aussi le Rclone mount path (only used for the Symlink Downloader) : /mnt/user/RealDebrid/zurg/_all_ (y’a 2 underscores de chaque côté de all, vive le markdown qui transforme all en gras…)
Normalement rien à configurer dans l’onglet qBitTorrent / *darr qui reprend les informations enregistrées dans GUI Defaults.
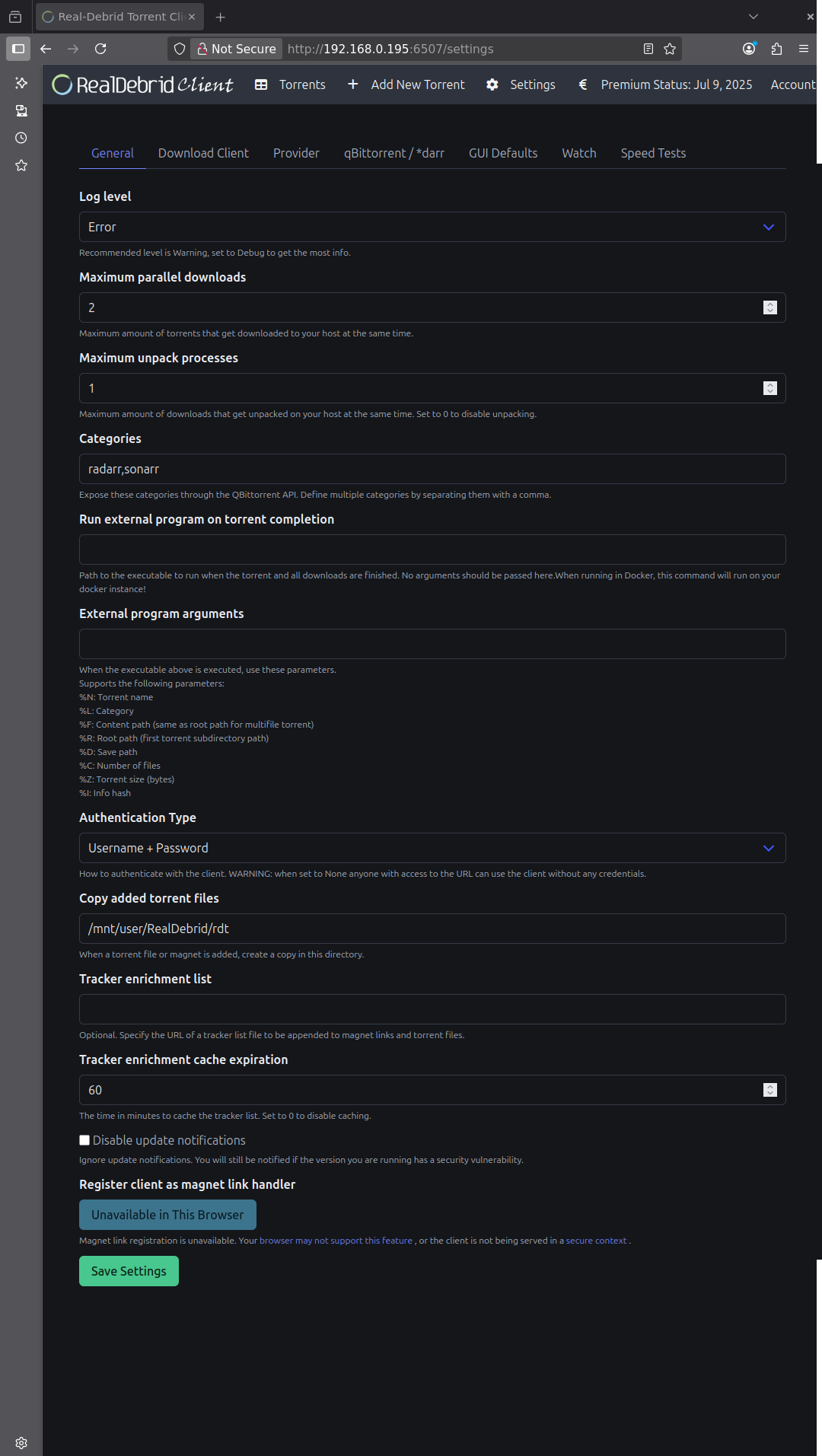
Je ne me sers pas de Watch, les *arrs s’occupant des films et séries mais ça pourrait pas exemple servir pour des documentaires, qu’on doit souvent récupérer à la main ou via un RSS/API et un REGEX.
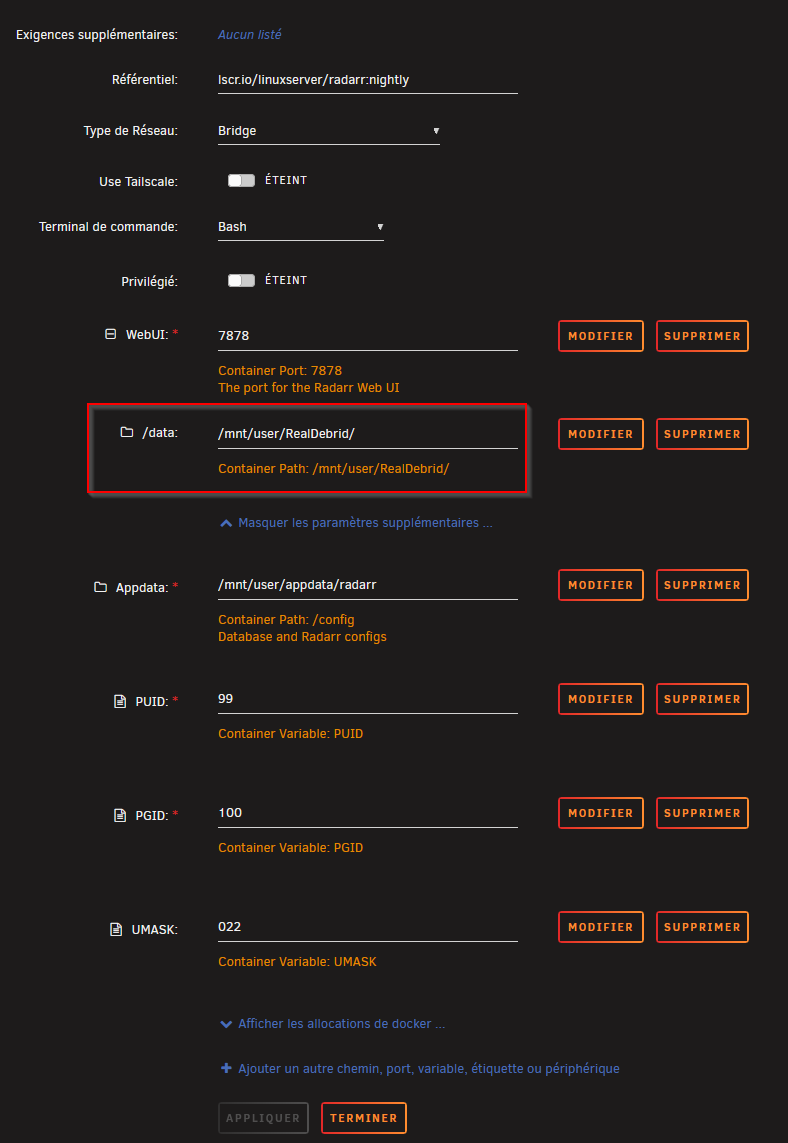
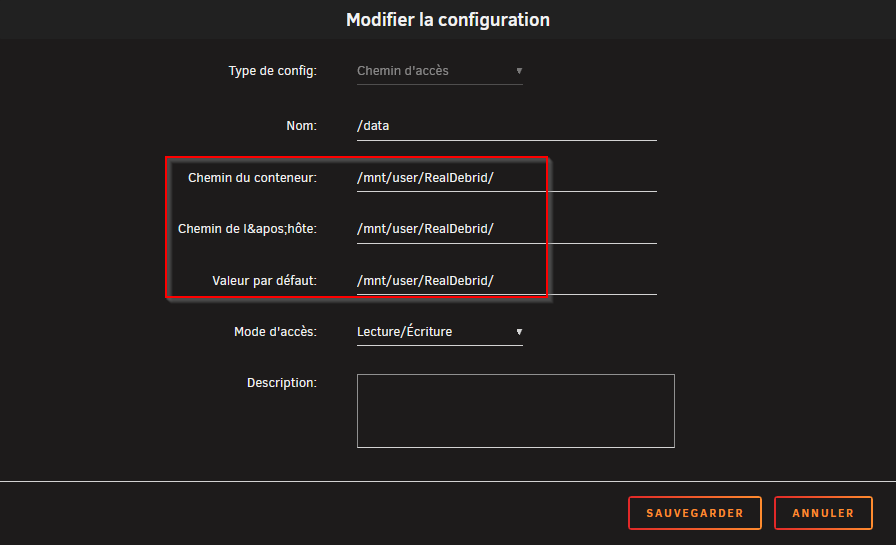
Bien que je me doute que vous savez installer Radarr, Sonarr et Plex en 2025, attention encore une fois à bien mettre /mnt/user/RealDebrid/ comme volume local et container.
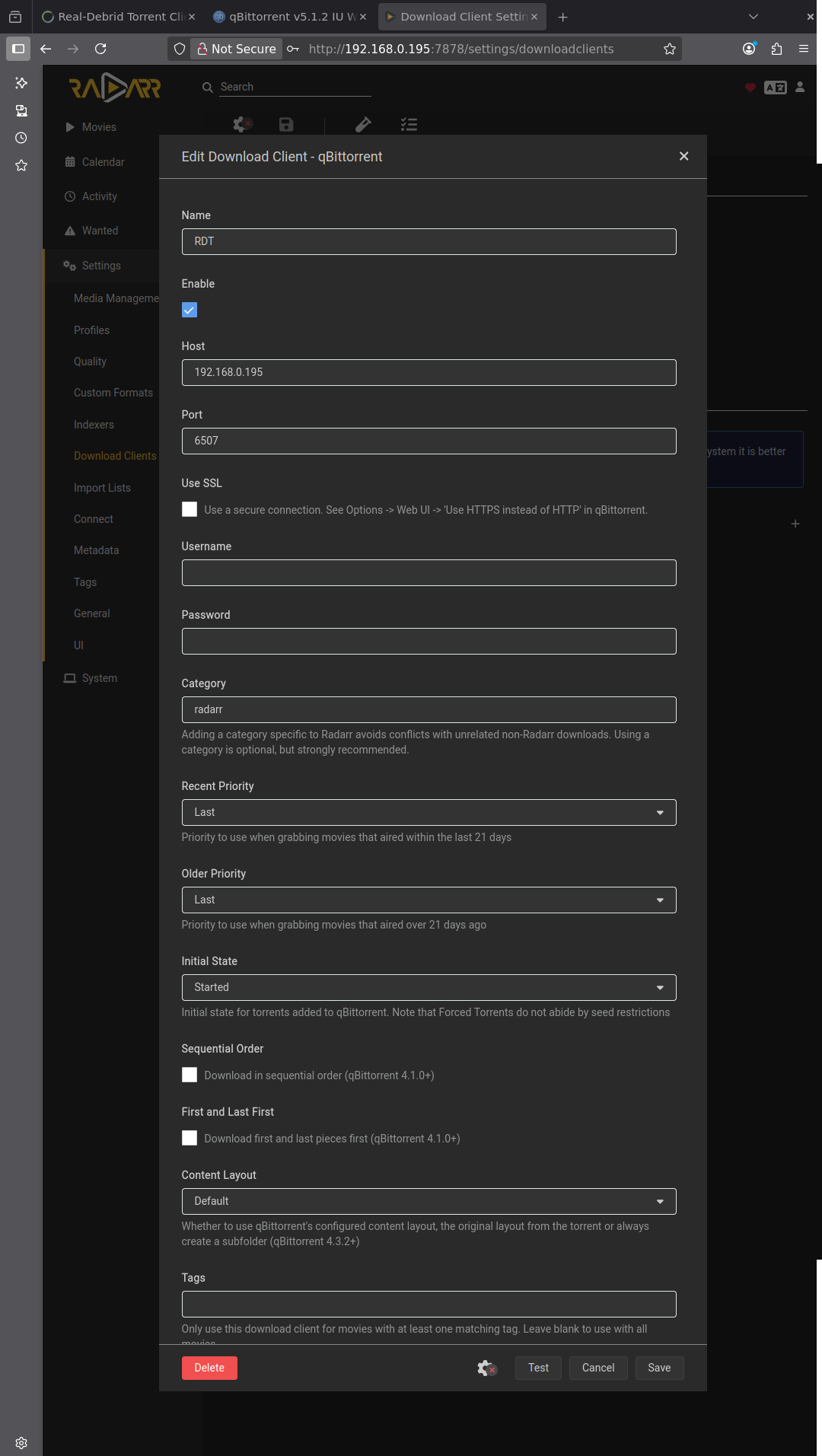
Pour ajouter RDT-Client comme client de téléchargement aux *arrs, passer par l’ajout du client émulé : qBitTorrent.
Je vous laisse configurer comme vous voulez les profils, tags, qualités etc.
Attention, le root folder est /mnt/user/RealDebrid/Medias/Films et ce sera d’ailleurs là aussi qu’il faudra aller chercher les bibliothèques dans Plex.
Plex indexe tout dès que le téléchargement est signalé complété par un *arrs.
Niveau consommation de ressources c’est peanuts, ça passe très bien sur mon petit NAS UNRAiD LincStation N1 et son CPU… « basse consommation »
Alors ? Où est le loup ?! Bah y’en n’a pas vraiment. Y’a de tous les avis sur chaque débrideur, encore en plus en cas de panne, sur qui a le plus de contenu VF en cache etc.
De mon côté, très petit consommateur, qui va de toute manière se concentrer sur TorBox parce qu’ils permettent d’utiliser des .nzb, j’ai pas constaté de pépin. Quelques .torrents bogues mais ils sont retirés automatiquement par RDT et un *arr en envoie un autre. J’ai juste dû le faire manuellement pour 1 film où aucune version 20160p ne passait. Mais attention, je n’ai utilisé quasi que YGG pour ce test, avec des trackers privés il n’y a aucun raison que les .torrents soient blacklisté par RealDebrid.
Après… fibré, amateur de Usenet… j’ai un peu tiqué en voyant les vitesses de téléchargement côté RD ^^
Bon, je vous rassure, c’est comme sur son propre serveur, ça fluctue selon les peers, la charge des serveurs du débrideur et le sens du vent. C’est du P2P !
Au final le système est très pratique et RDT-Client s’intègre facilement dans une stack déjà établie. Et utiliser les *arrs permet d’affiner la qualité et les sources, en comparaison avec une solution comme Stremio (en passant par les services mis à disposition publiquement).
Là j’ai testé avec Plex mais c’est aussi fonctionnel avec Emby/Jellyfin puisque si un fichier disparaît de RealDebrid, les *arrs l’identifieront comme manquant et le remettrons en téléchargement.
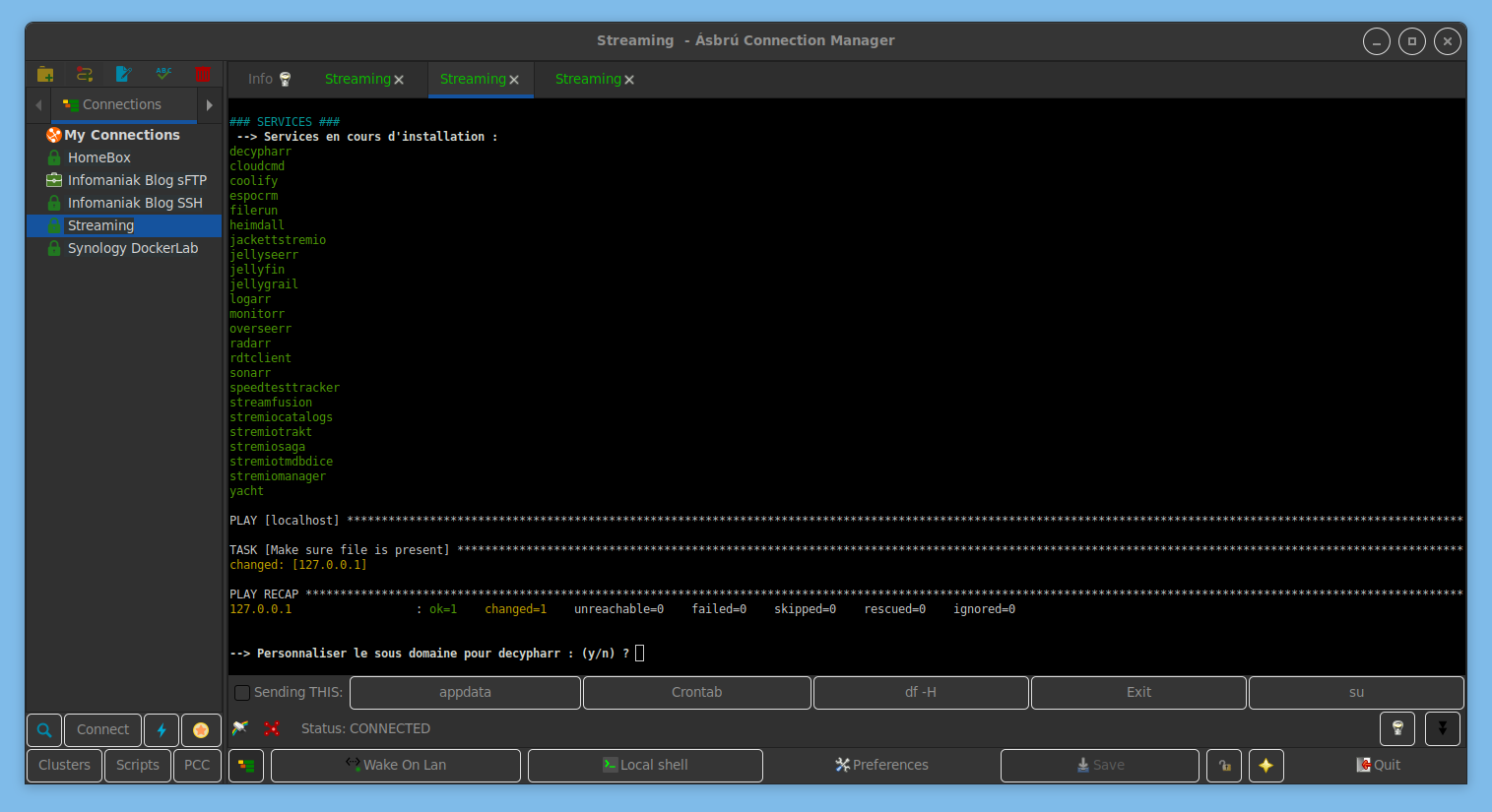
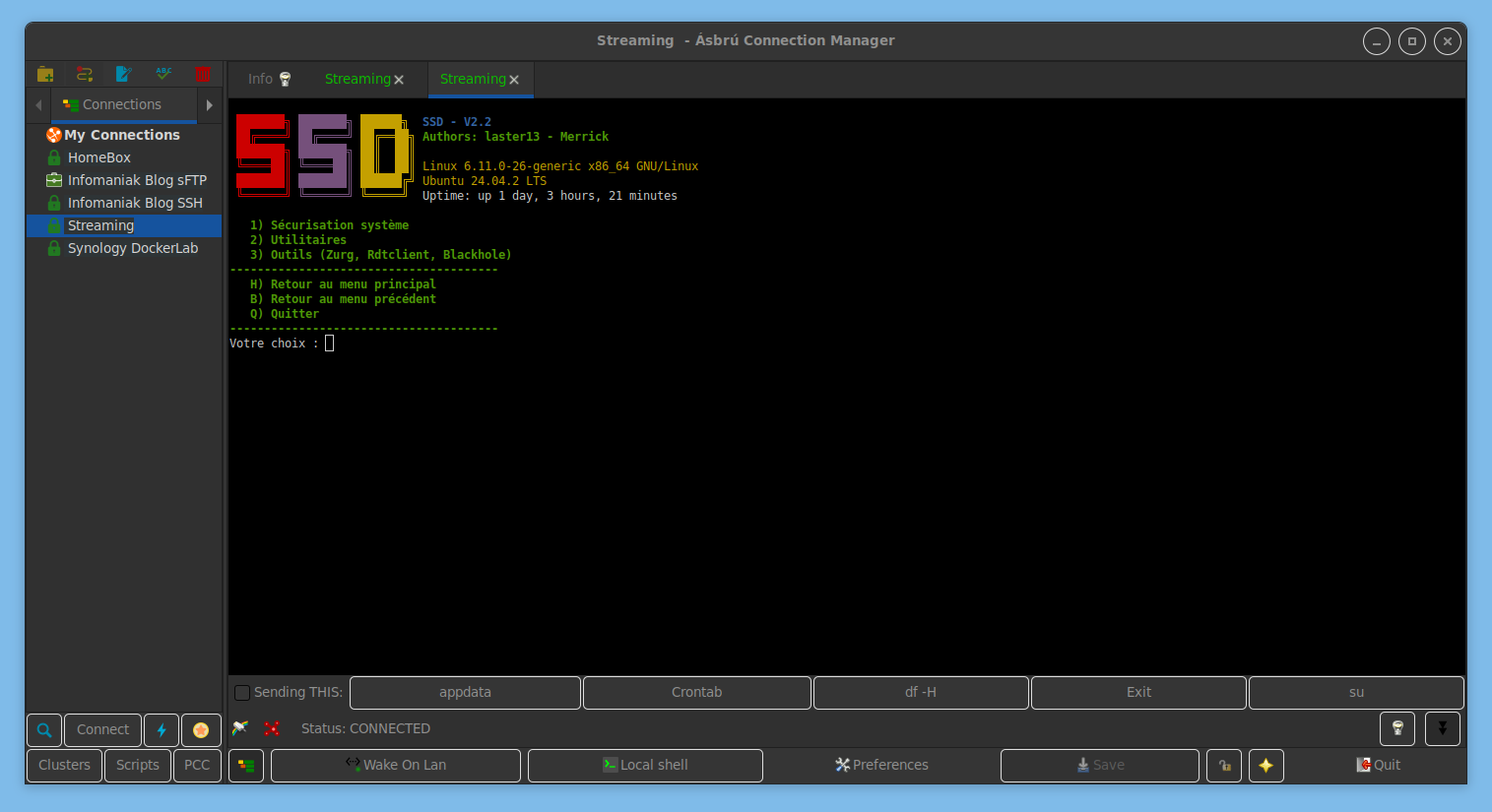
Ça fait maintenant quelques années que je suis et parle de « SSDv2 », mené notamment par Laster13 & Merrick puis rejoints au fil du temps par de nombreux développeurs francophones de l’univers du DL/streaming.
Ce script installe de manière assez simple, et pourtant complète, tout un tas d’outils en format Docker, derrière un proxy Traefik, pour créer, gérer et profiter d’une librairie de contenus numériques. Les configurations restent à charge de l’utilisateur bien évidemment. Je pense confirme que le WiKi n’est pas à jour, mais voici un aperçu de ce qu’il permet d’installer, « c’est pas mal » La liste est quasi sans fin puisqu’en plus de pouvoir installer des applications de son choix en parallèle du script, il est très souvent mis à jour. Il y a des commits très fréquents, les développeurs (staffiens ou non) sont hyper présents et réactifs aux questions, remarques et suggestions. Il n’est pas rare de croiser une demande d’applicatif avec une réponse testée voire envoyée en prod dans les quelques heures. Ça sent la passion et la bienveillance ! Le Discord est très clair et très bien catégorisé et on peut y discuter de tout du moment qu’on ne poste pas d’accès direct à du contenu non autorisé.
Ce script s’adresse d’une part aux débutants sur serveurs Linux, mais qui ont déjà des notions liées aux univers de l’auto-hébergement, du téléchargement et du streaming (ou savent utiliser Google/Reddit) pour savoir ce que sont Traefik, PlexPatrol, Decypharr, RDT-Client, Radarr, Jellyfin etc. Mais ce script est également destiné aux geeks qui souhaitent juste installer des applications simplement, testées, avec un support, en quelques choix dans un terminal. Sans se prendre le chou.
De mon point de vue, sans compter les applications « tierces » qui servent à faire ses comptes, héberger ses photos ou des serveurs de jeux, ce script couvre les 3 tendances de ces dernières années : – La création d’une bibliothèque multimédia locale via les *arr, selon son stockage disponible, – La création d’une bibliothèque distante via les *arr et des débrideurs (leur cache plus précisément), – L’hébergement d’outils dédiés à Stremio pour se faire sa plateforme personnalisée de streaming.
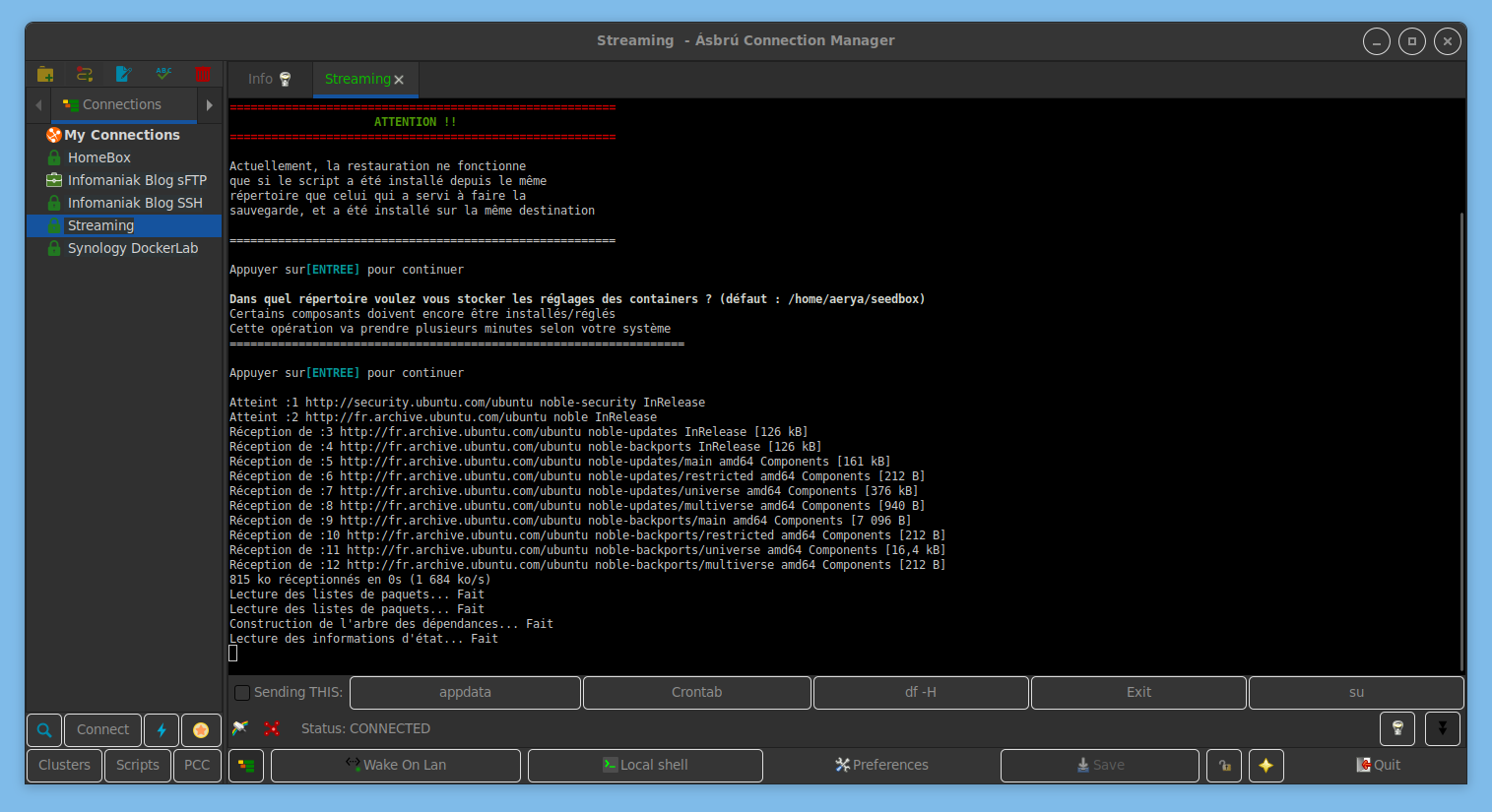
Les incontournables pour l’installer : savoir lire, un nom de domaine ajouté à Cloudflare et une machine dédiée en fresh install Ubuntu 24 (à date) : VPS, VM, serveur baremetal, vieux PC/portable… Tout est indiqué dans les prérequis. Et si Linux = martien pour vous, vous êtes guidés tout au long de l’installation, c’est vraiment bien expliqué.
J’installe ça sur un vieux PC avec un i3-6100 @3.70GHz, 8GB de RAM et Ubuntu serveur 24, ce qui correspond au minimum requis.
Si vous hébergez la machine chez vous, le script va interroger ip-api.com qui est bloqué par une liste de filtrage DNS (AdGuardHome, Pi-Hole), anticipez son déblocage. De même, pensez à rediriger les ports 80 et 443 vers la machine depuis votre box FAI/routeur, pour que le reverse proxy puisse fonctionner. Si vous avez déjà un reverse proxy, comme moi j’ai NPM, soit vous le coupez le temps de tester soit vous migrez vers Traefik soit vous faites tourner les 2 en parallèle (je dois tester ça).
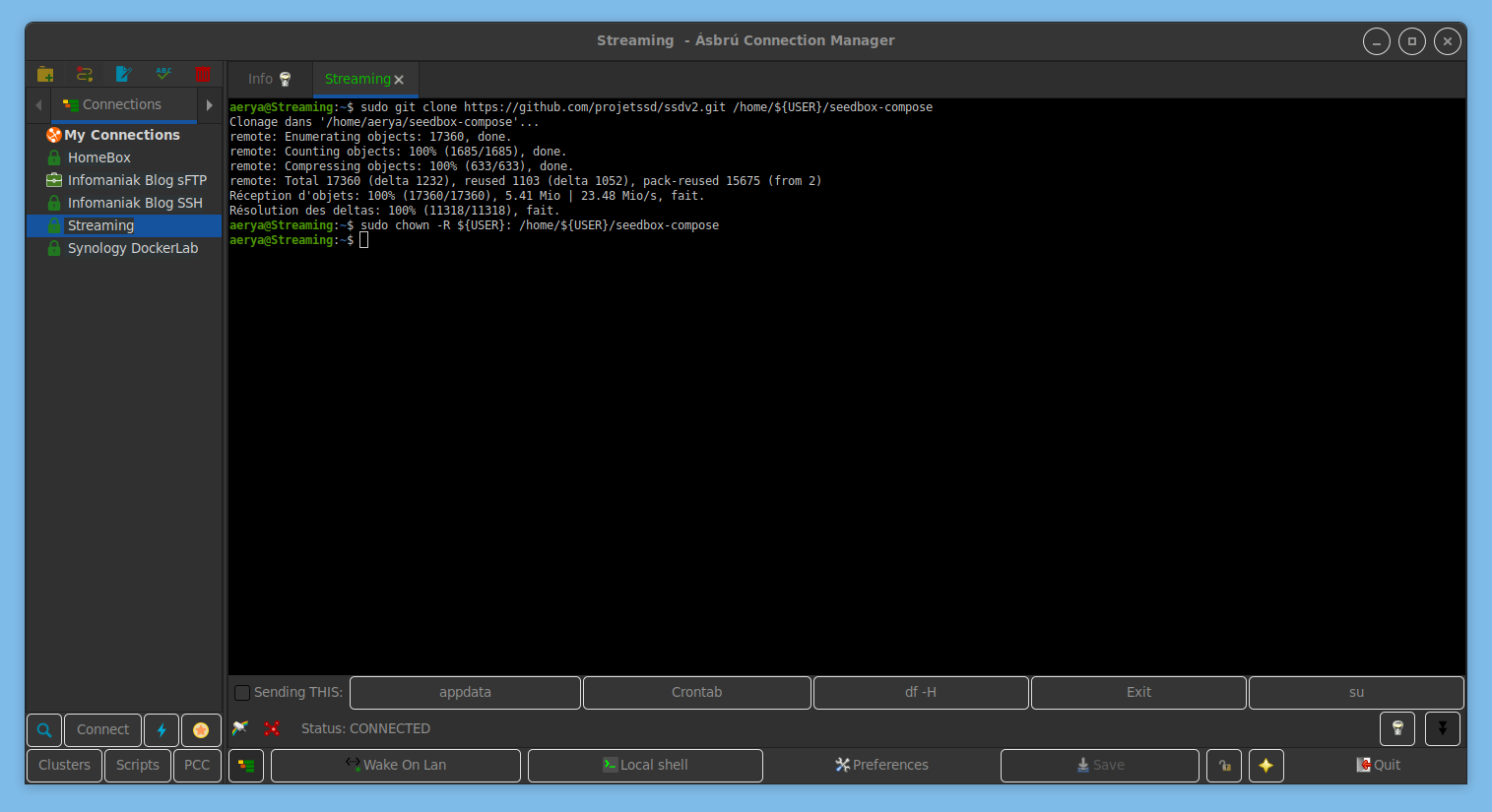
Après MàJ de l’OS et installation de git, cloner le repo SSDv2 dans son /home
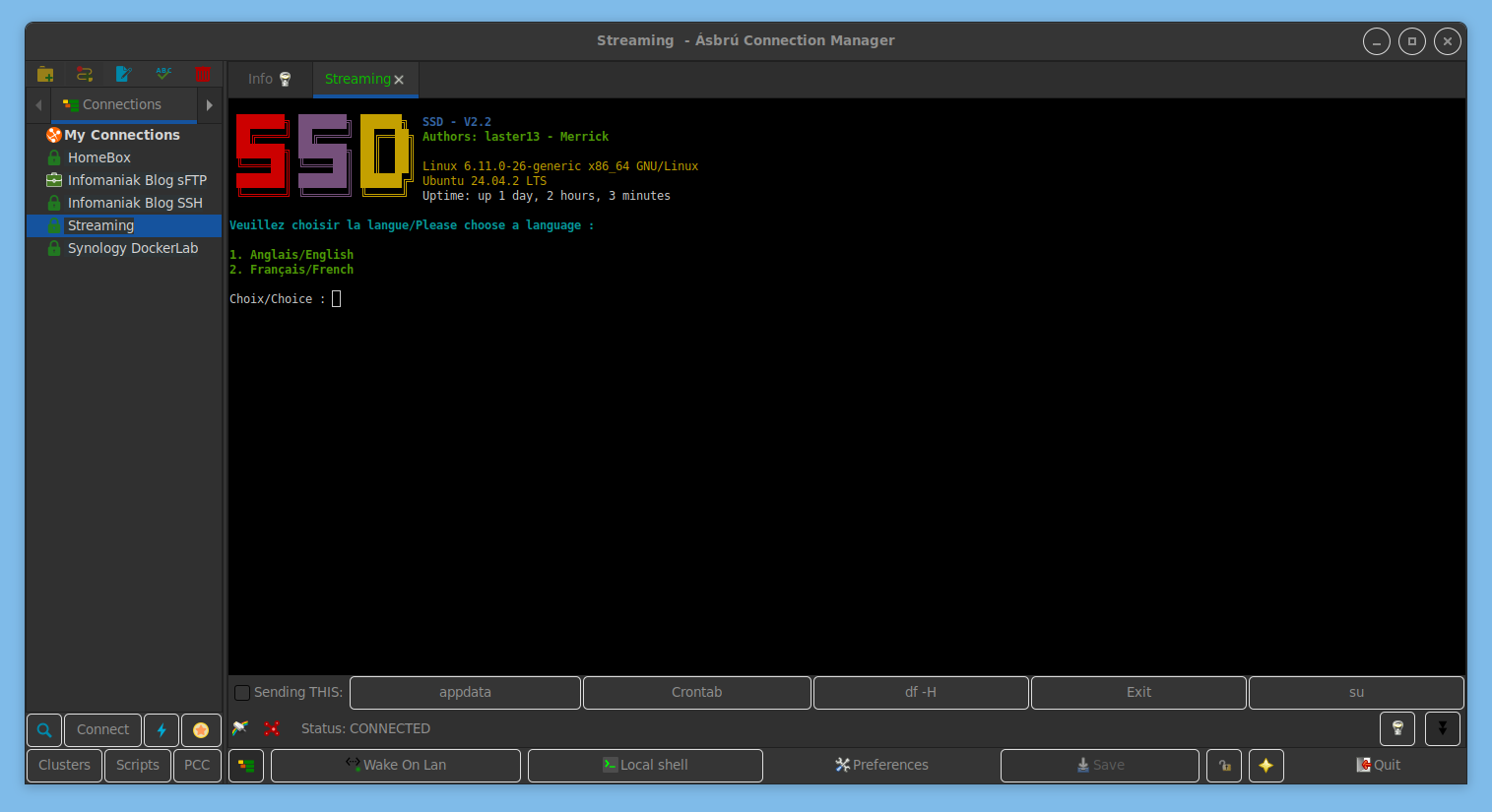
Puis lancement du script
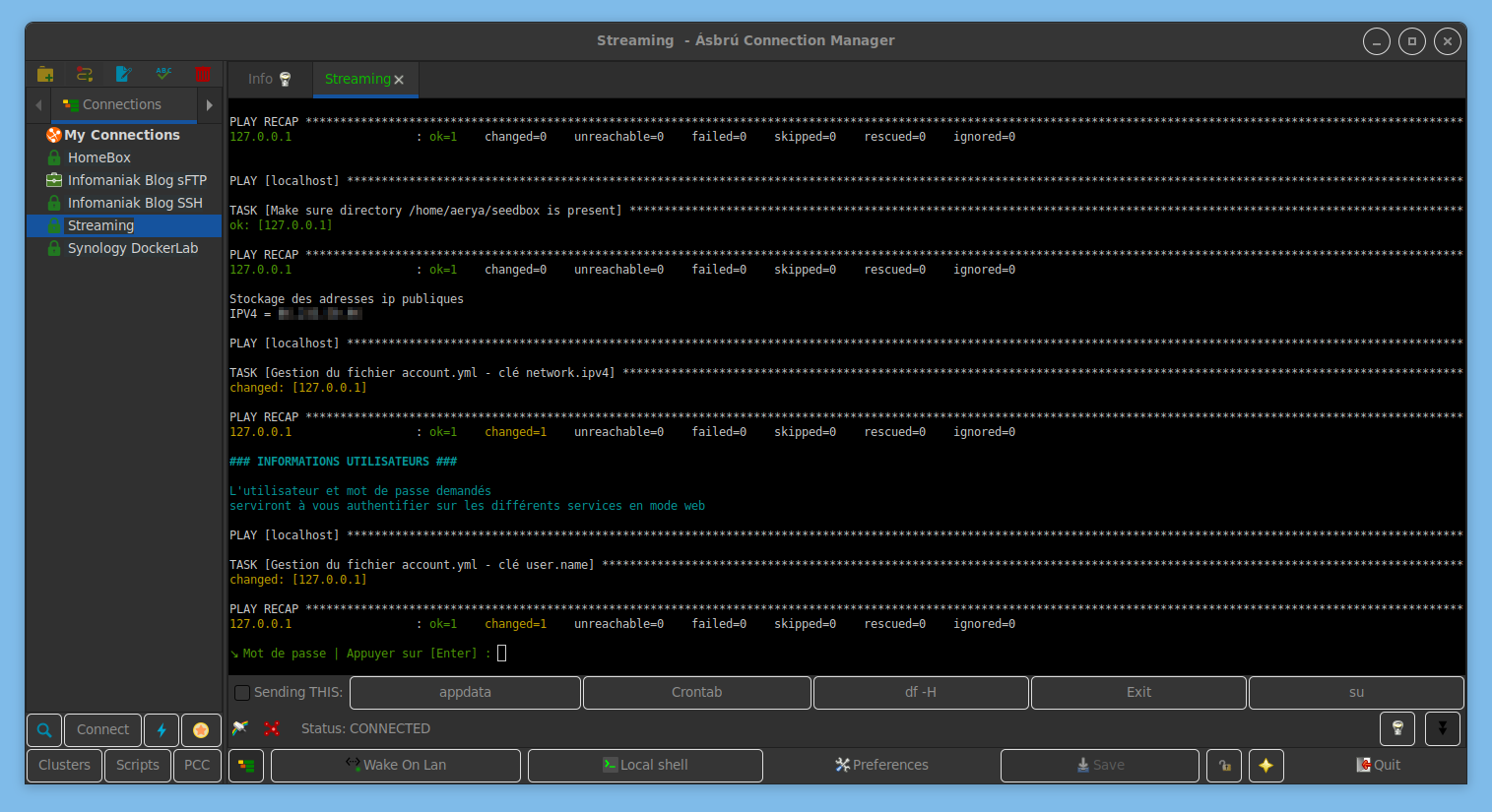
On répond à quelques questions pour la configuration : définir un mot de passe, renseigner un email, un nom de domaine
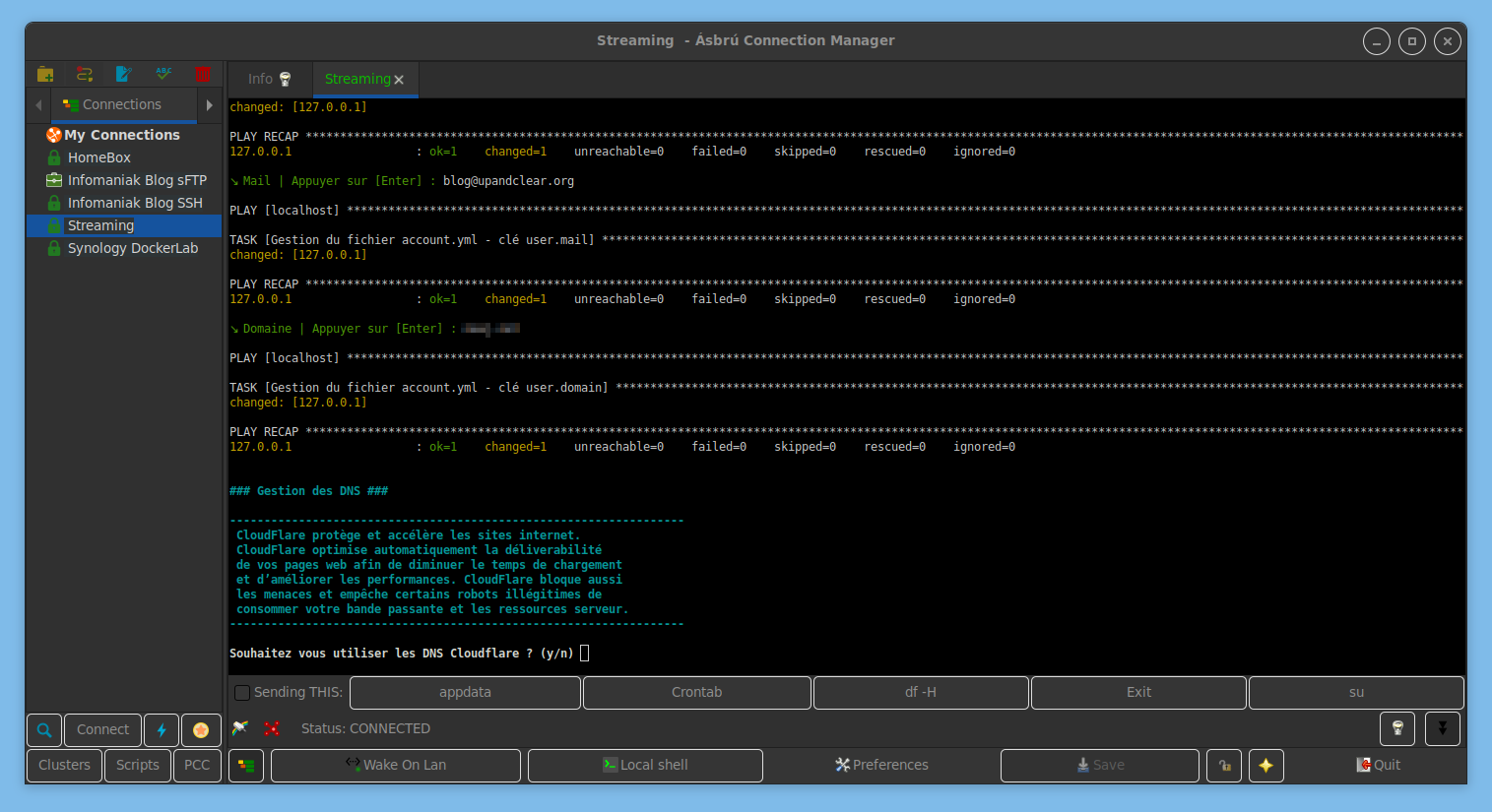
Indiquer si on souhaite utiliser Cloudflare. Comme dit au début de cet article, c’est bien plus pratique, notamment pour la création des sous-domaines utilisés pour les différents services, mais également pour masquer son IP privée (si serveur à la maison) des personnes qui auront accès auxdits services.
On indique alors email et clé API. Là encore, si vous ne savez pas faire, suivre la procédure du WiKi (prérequis).
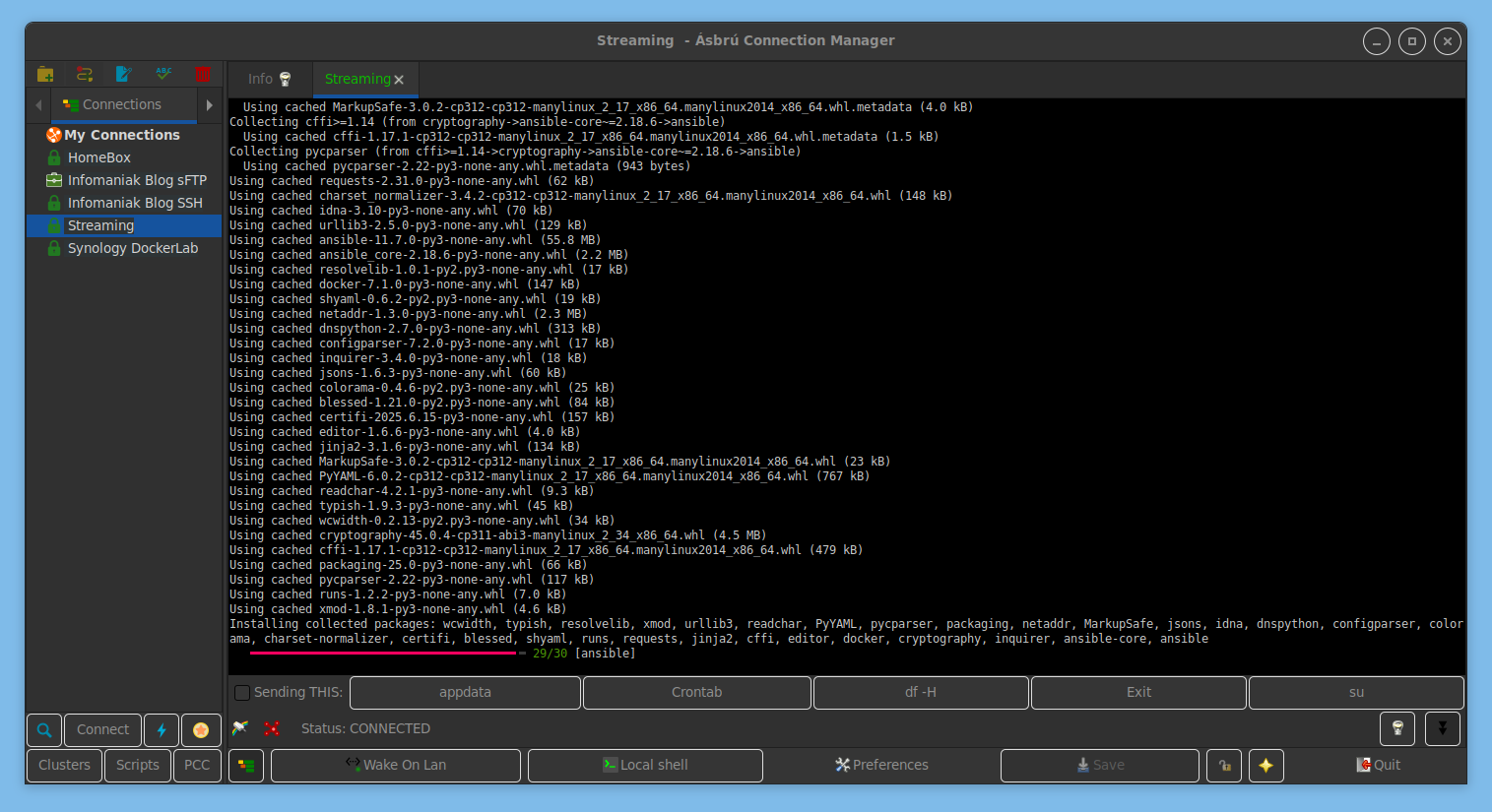
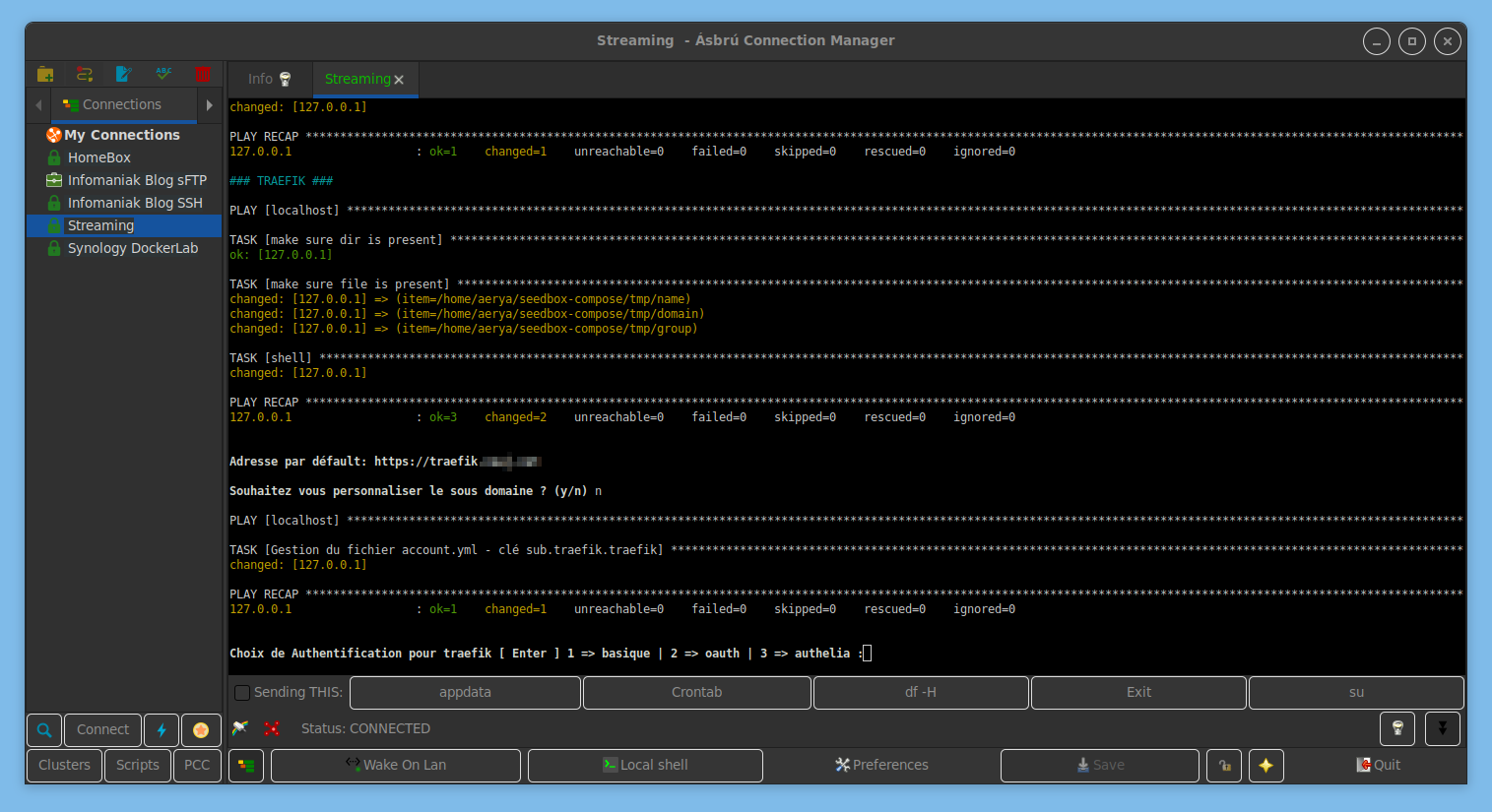
Puis l’installation suit son cours
À l’installation de Traefik, le reverse proxy Nginx, on peut modifier le sous-domaine par défaut et définir le type d’authentification : basique, oauth ou Authelia (application tierce, renforcée, mais qui fait aussi plus « pro »). Tout est là encore indiqué dans le WiKi.
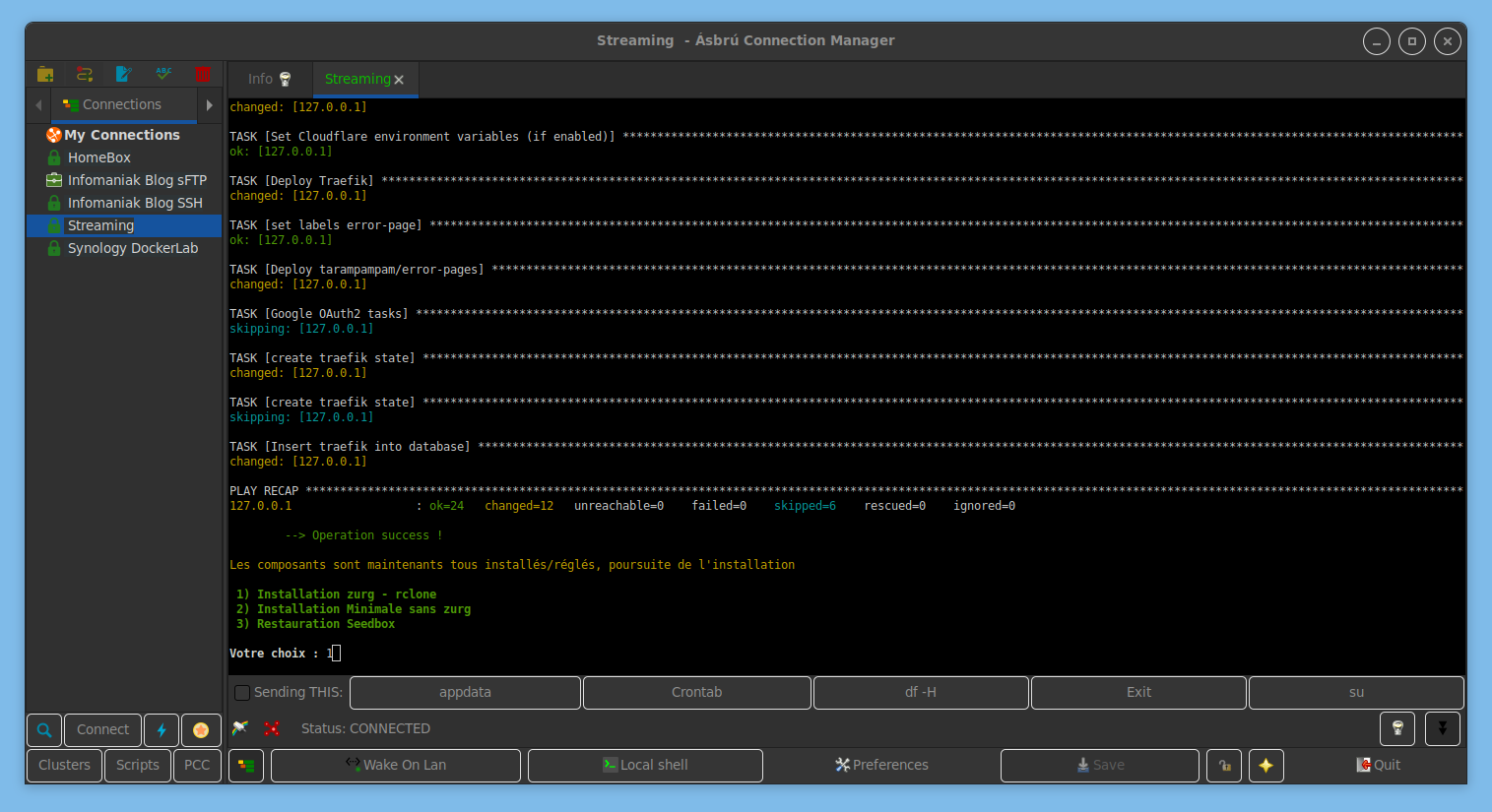
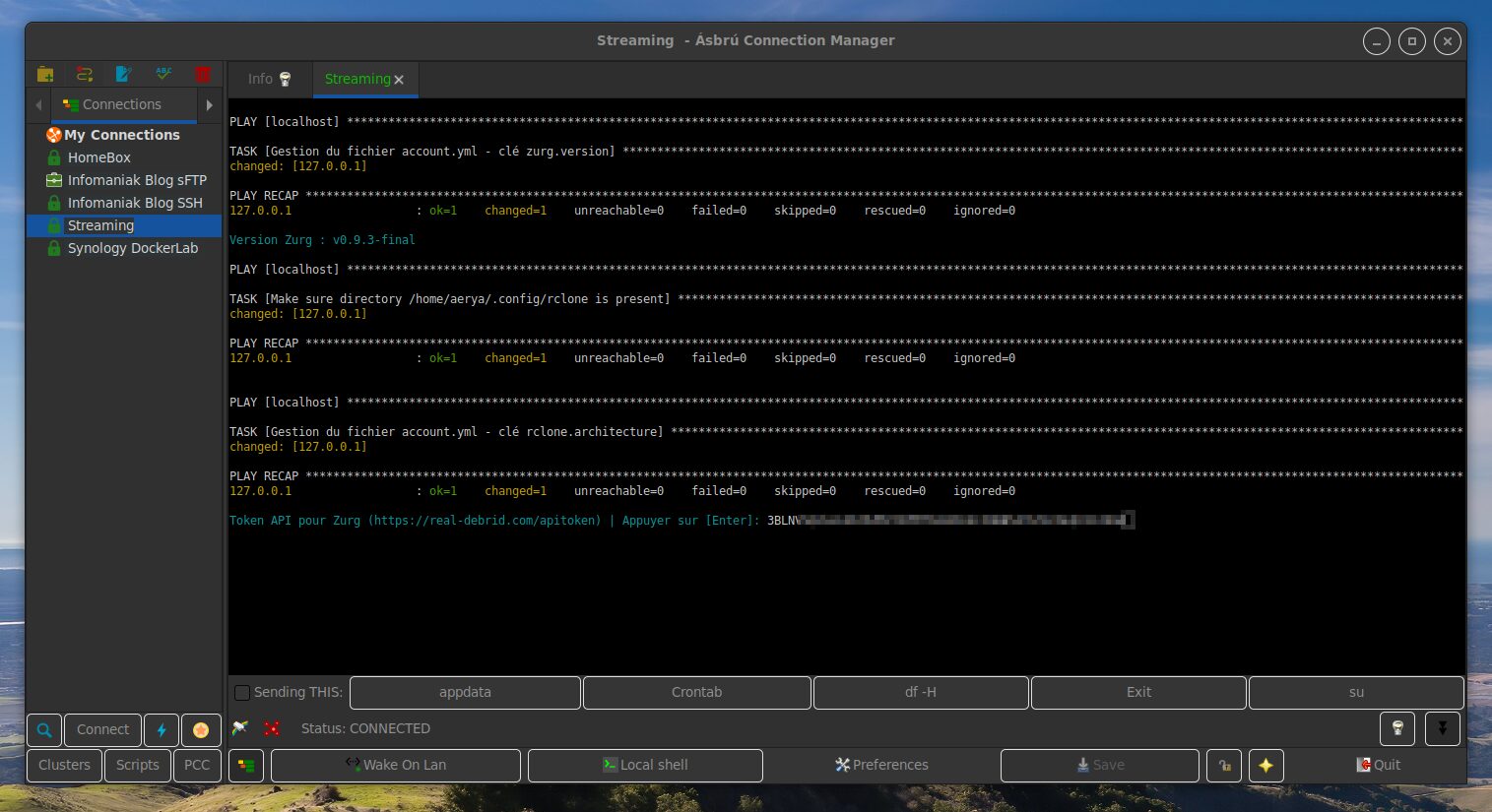
Et nous arrivons au choix d’installation ou non de Zurg. C’est particulièrement là que le WiKi n’est plus à jour, Zurg et tout cet univers du streaming via les débrideurs étant assez récent.
Car il s’agit en fait d’installer une version modifiée de rClone qui permet d’utiliser RealDebrid via un WebDav pour accéder/indexer/lire leur contenu en cache plutôt que de le télécharger sur son serveur, de manière « classique », que ce soit en BitTorrent ou Usenet. Attention, comme toujours, cette méthode n’est pas sans risque pour les comptes utilisés sur les trackers BitTorrent (assimilé à de la triche) et non plus infaillible puisque de nombreux utilisateurs se rendent par exemple compte ce matin que beaucoup de contenu en cache sur AllDebrid a été vidé (tout se reDL de manière automatisée, mais ça met un coup à l’instant T aux bibliothèques Emby/JellyFin). Et il se dit également qu’il y a plus de contenu VF en cache chez AD que RD. Bien entendu, ça suppose d’avoir un compte Real-Debrid et la clé API qui va bien.
On pourra par la suite installer RDT-Client qui permet d’utiliser, entre autres, AllDebrid.
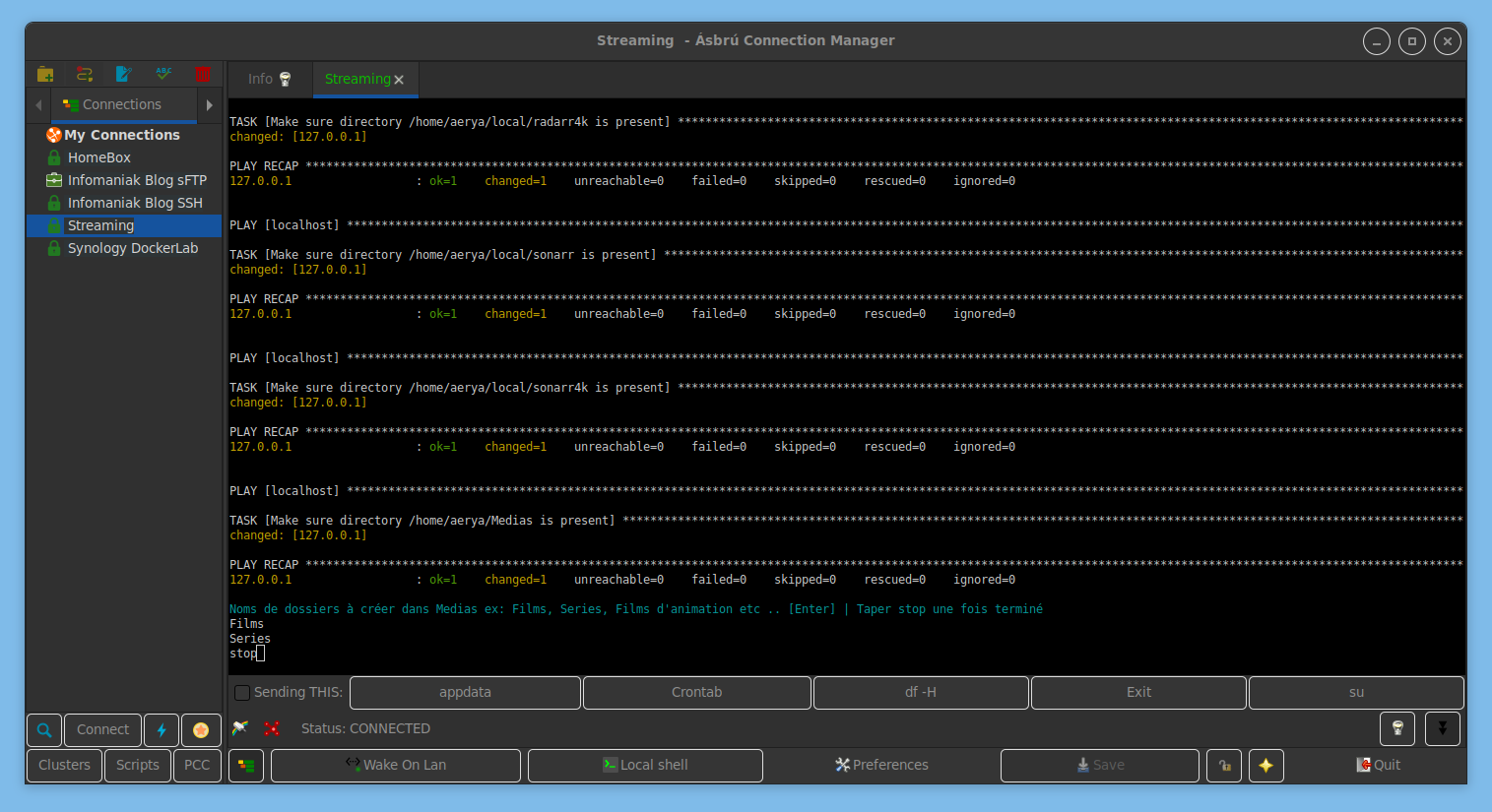
S’ensuit la création des dossiers pour la bibliothèque, je fais simple et me contente de Films et Series
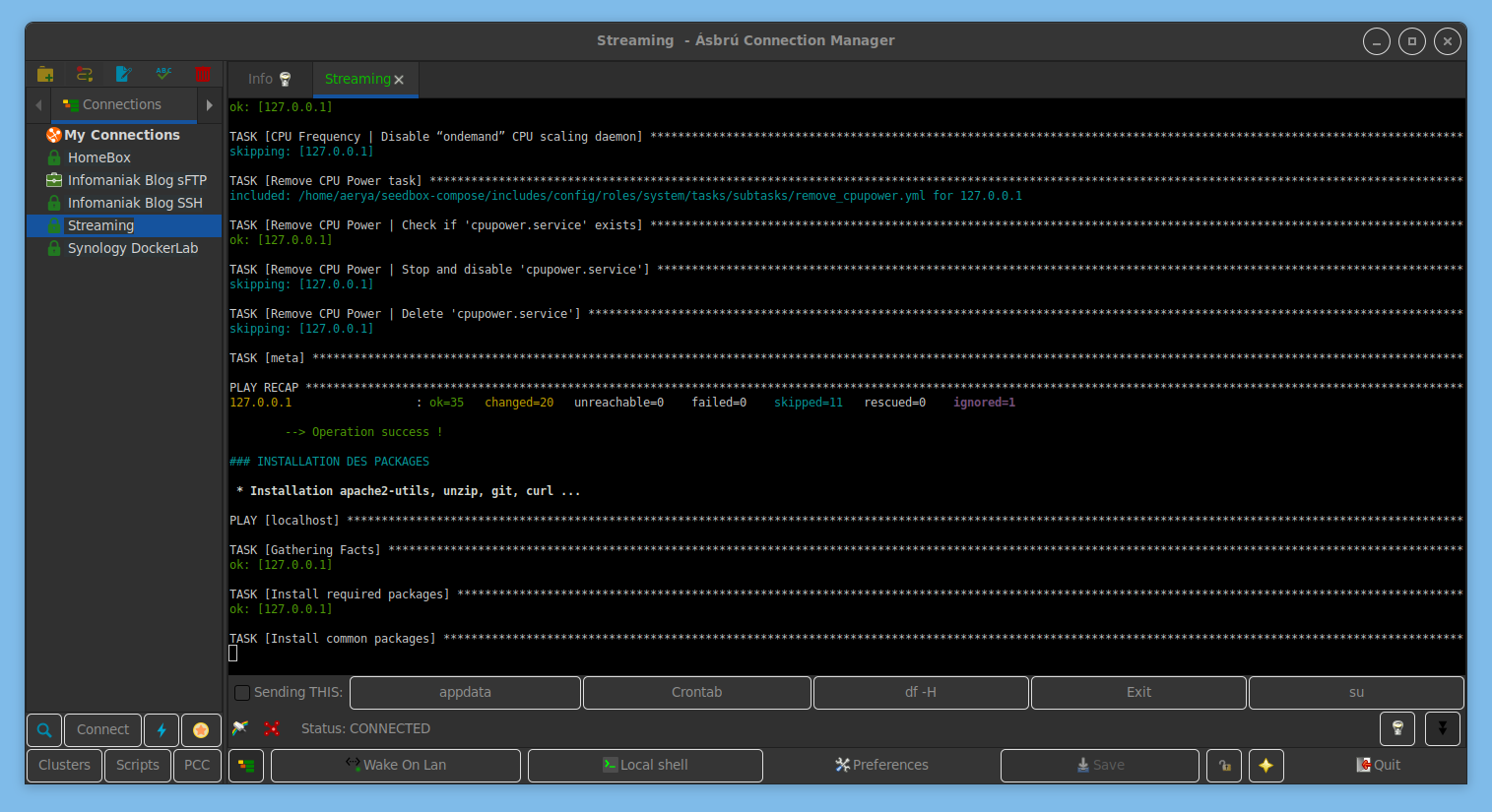
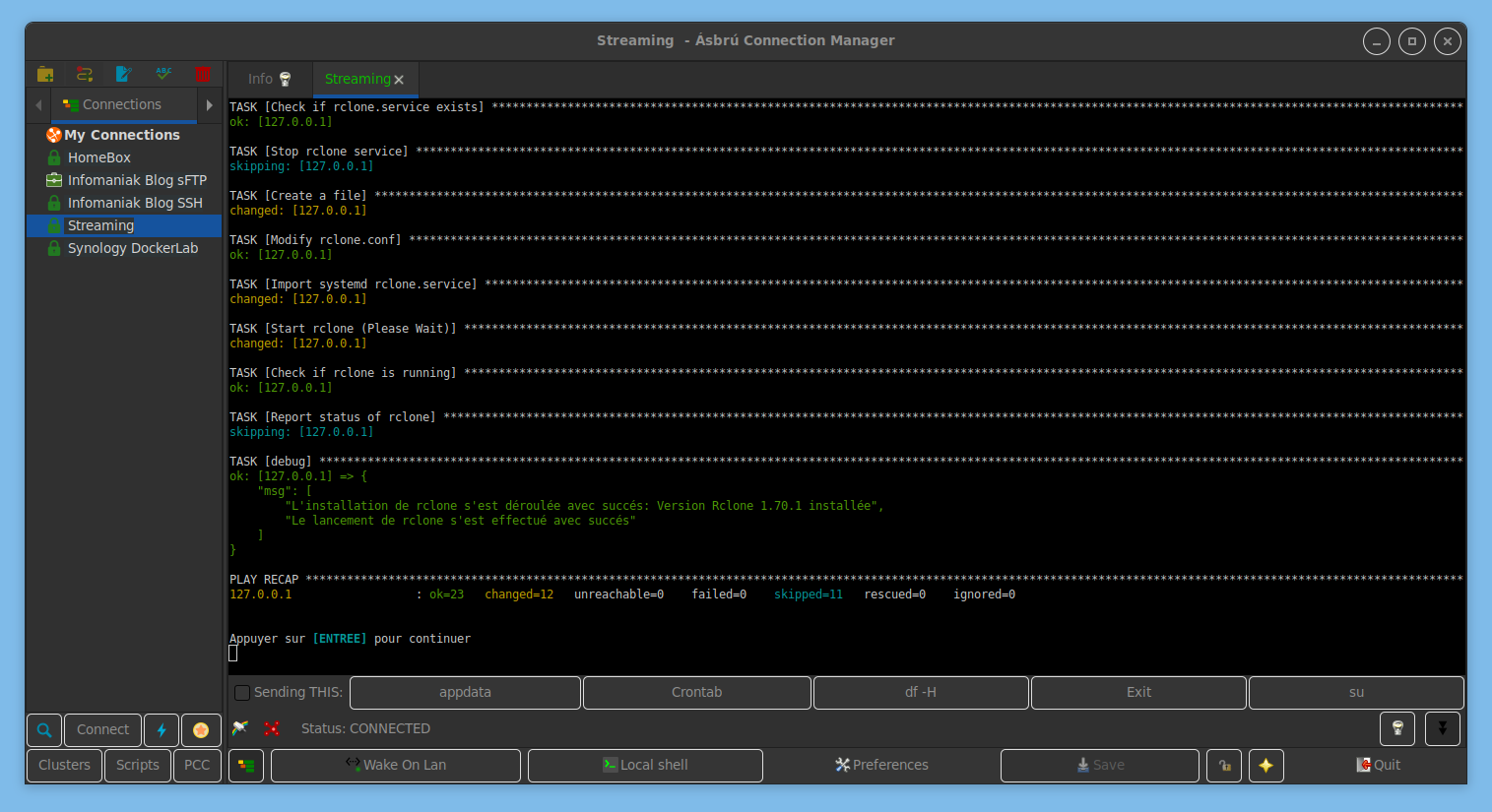
Et l’installation de base est terminée !
Tadaaaaa !!!
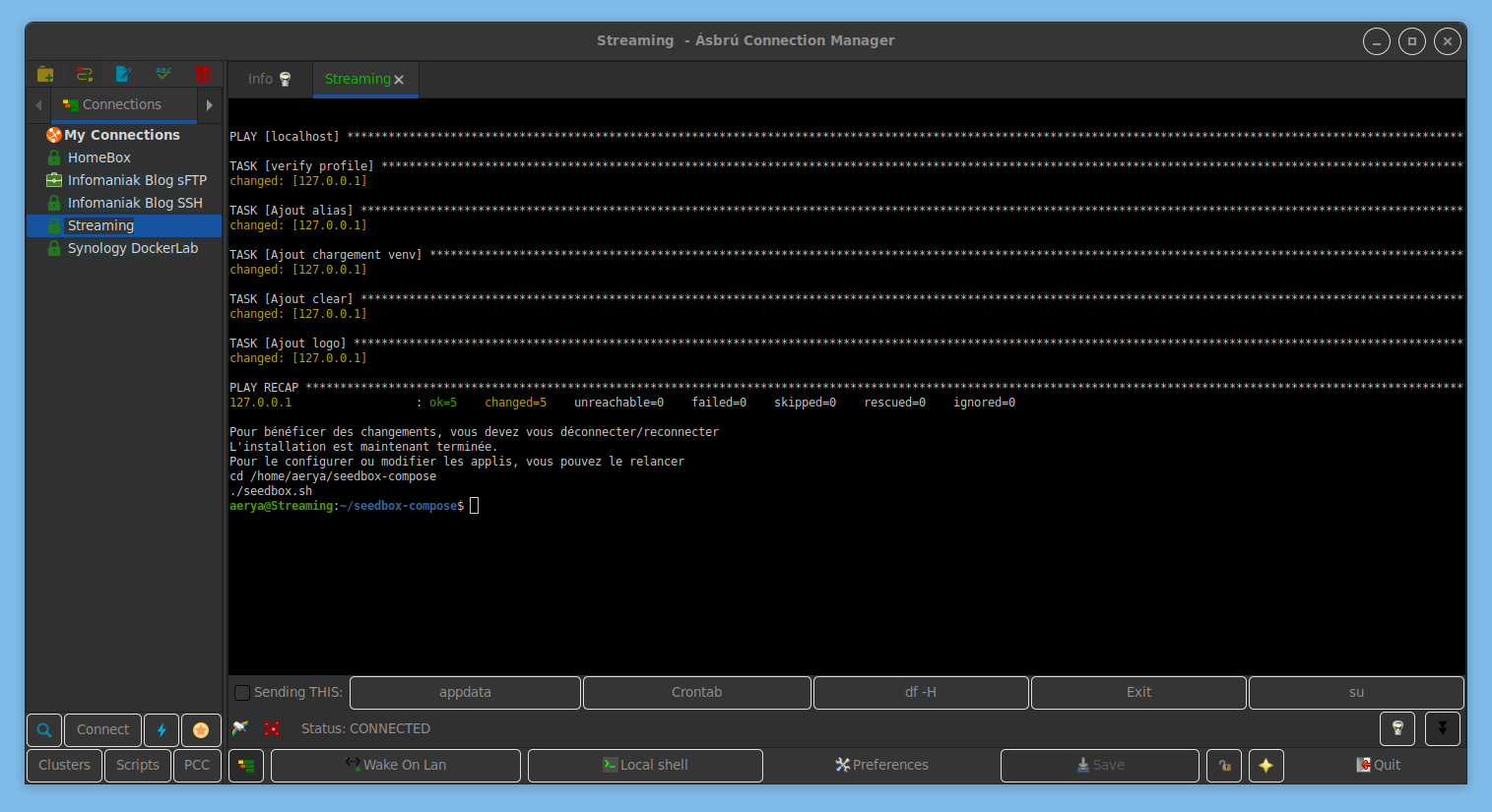
De là, on peut suivre les consignes puis de déco/reconnecter à son serveur et relancer le script.
Pour le configurer ou modifier les applis, vous pouvez le relancer
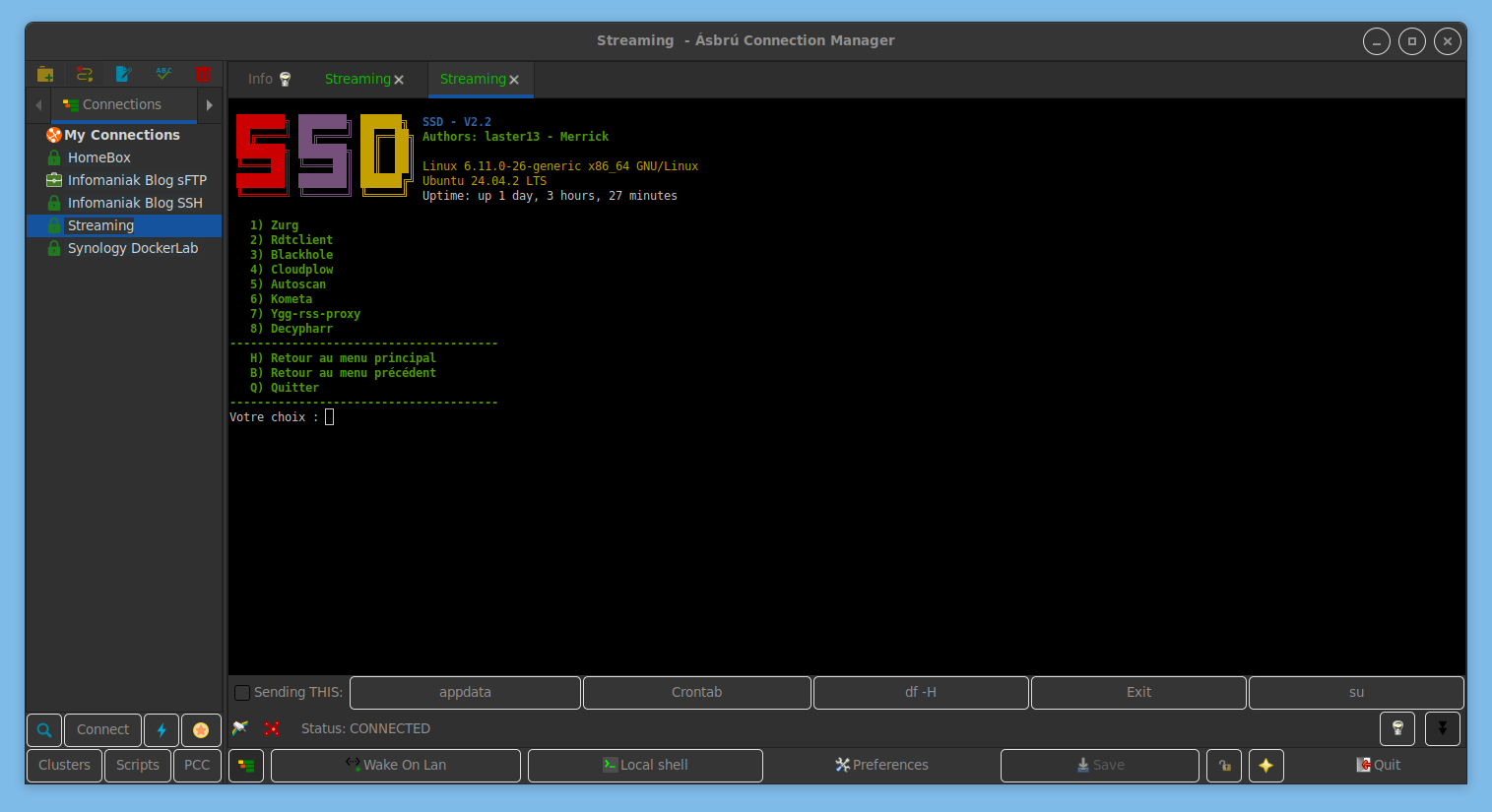
cd /home/aerya/seedbox-compose
./seedbox.sh
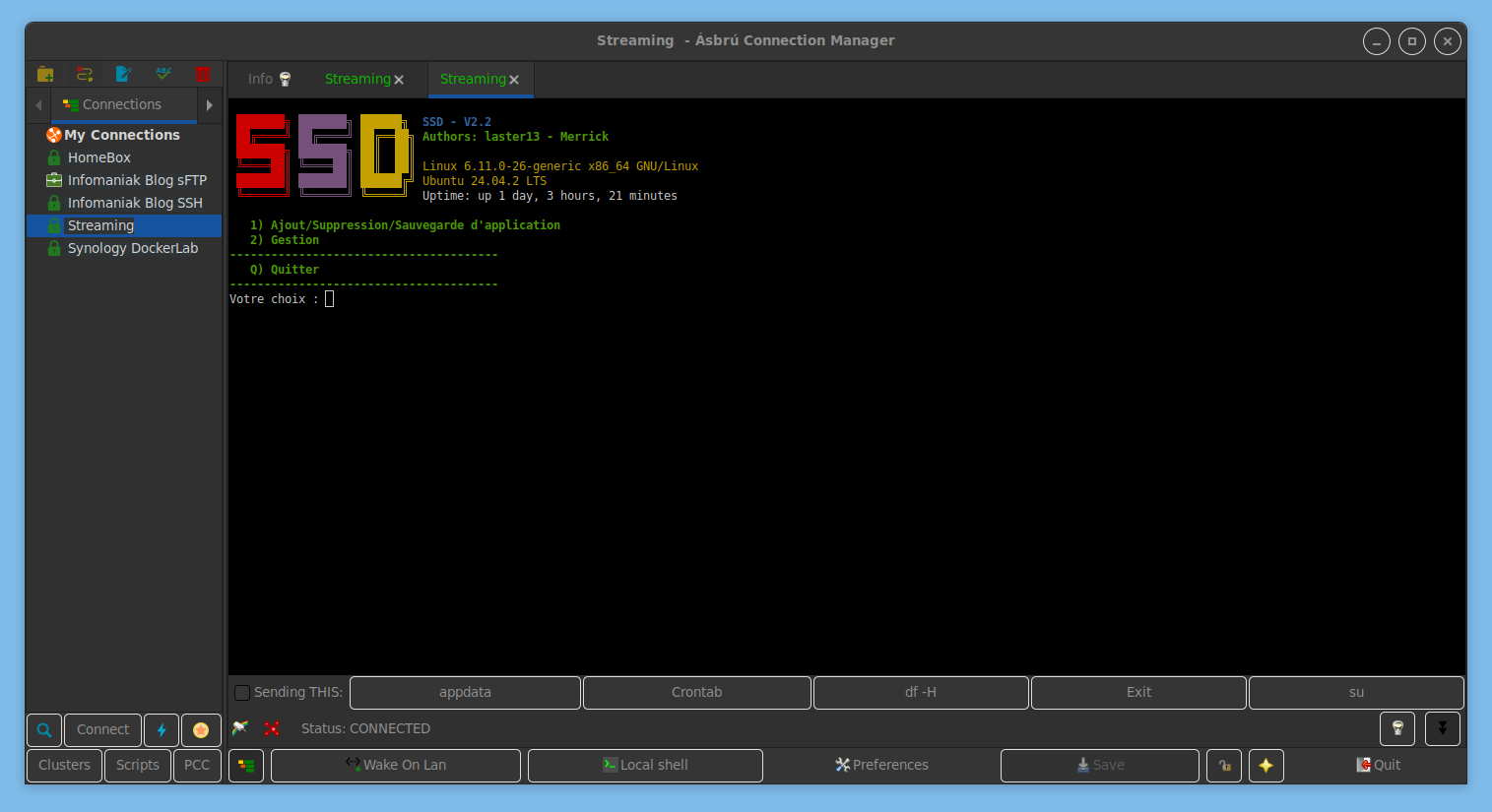
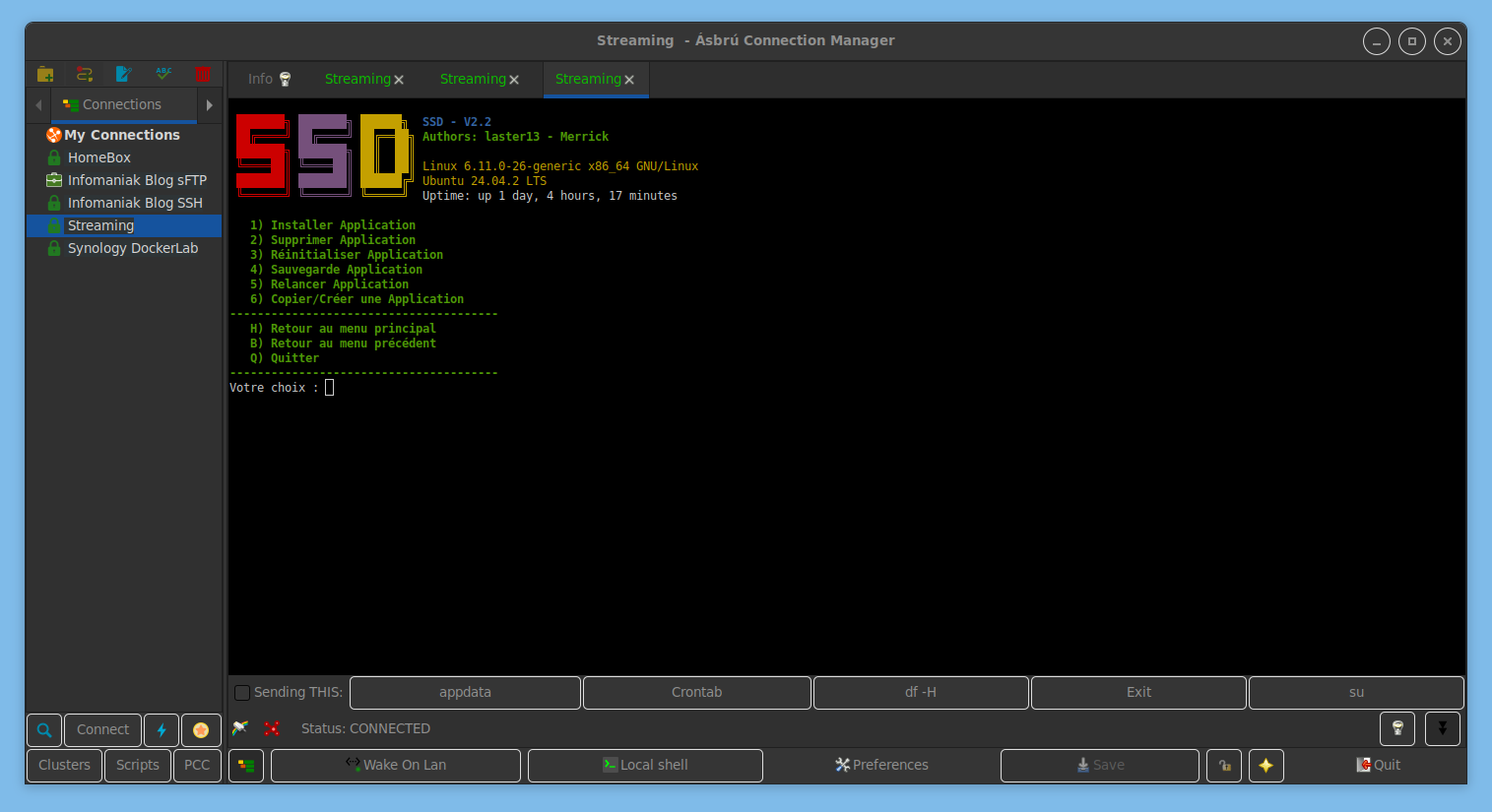
Le 1er choix permet d’installer des applications (ou les copier, sauvegarder, etc).
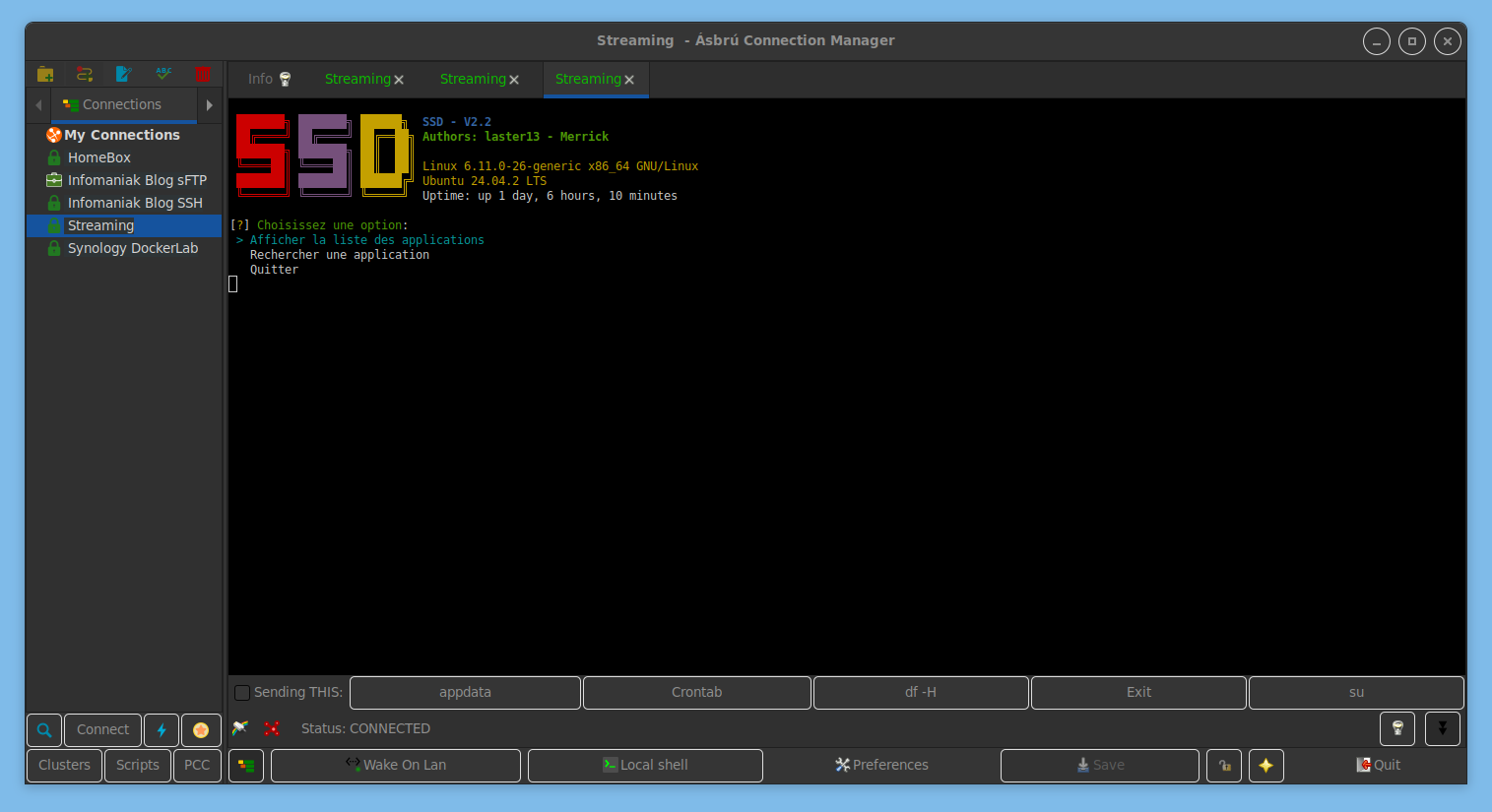
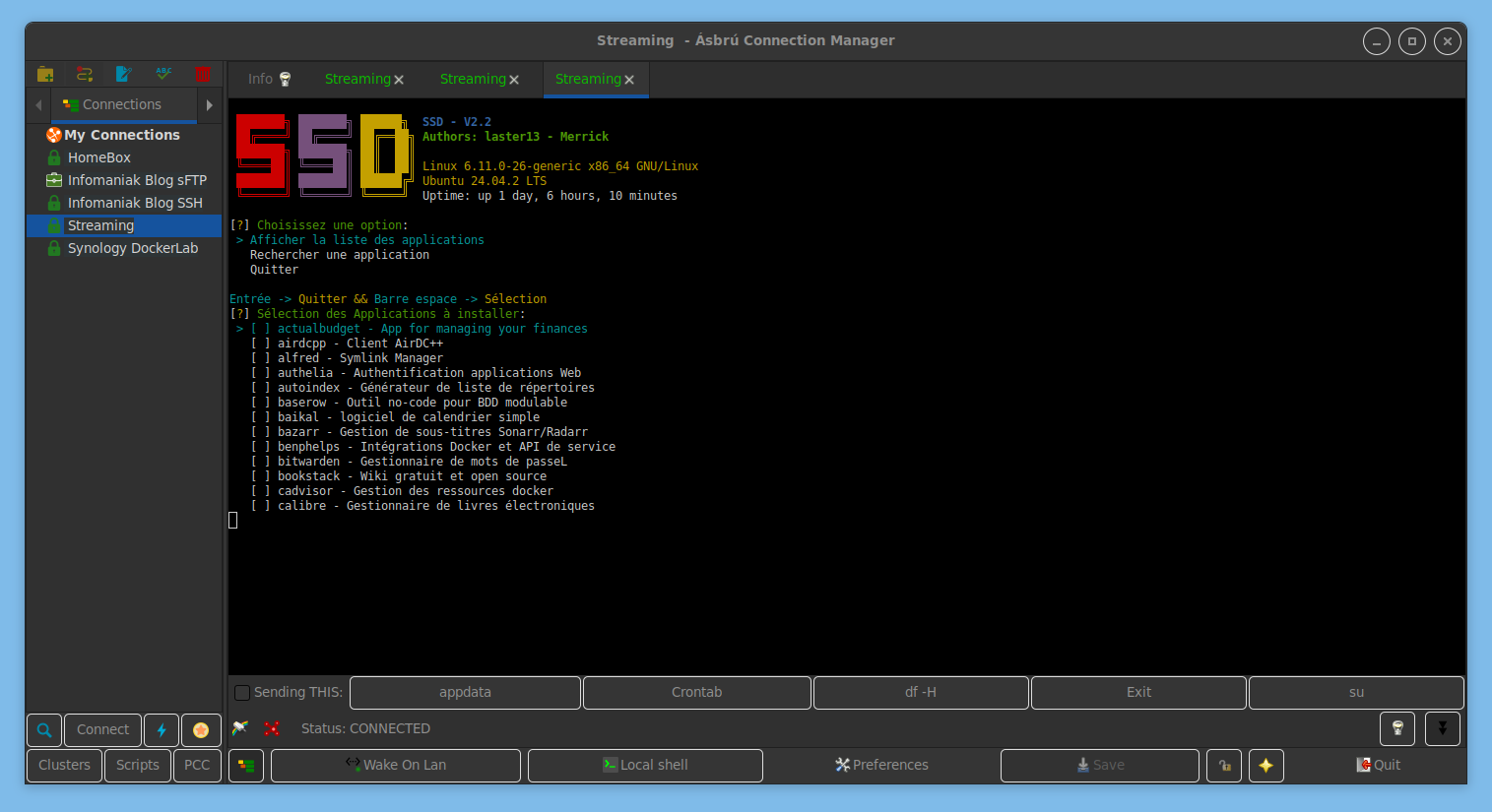
Pour parcourir/installer les applications disponibles dans le script, aller sur Installer / Applications seedbox et <entrée> puis utiliser les flèches haut/bas et la barre espace pour cocher les cases
Une fois le ou les choix fait.s, poursuivre en appuyant sur <entrée>
Dans ce test, je ne personnalise aucun nom de domaine (choix n => tout par défaut => application.domaine.com) et utilise Authelia pour les authentifications. J’aurais apprécié avoir une option pour sélectionner par défaut, pour l’installation en cours, les choix de sous-domaine et auth, pour ne pas avoir à rester devant le terminal et interagir pendant la suite du processus.
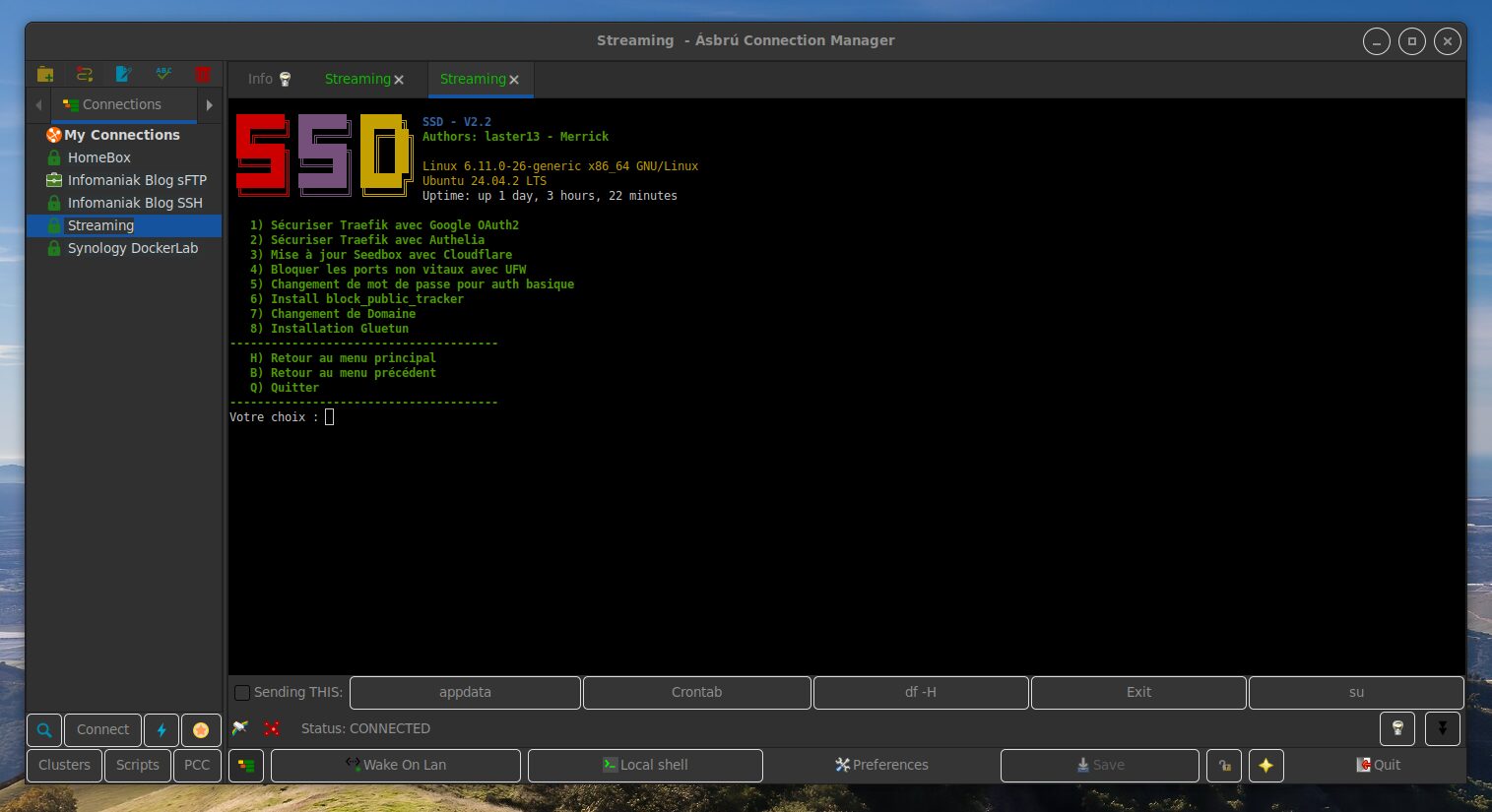
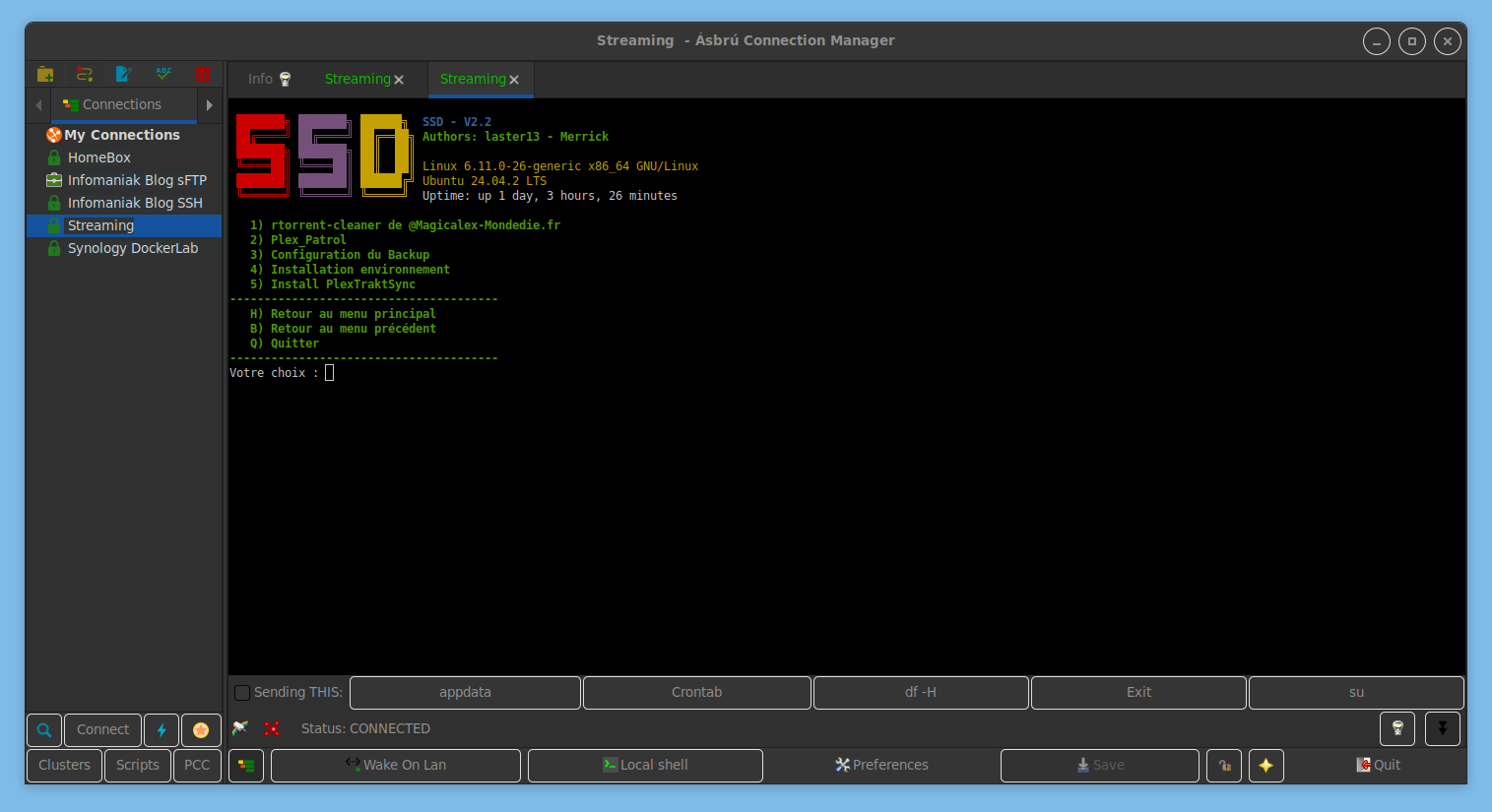
On peut gérer la seedbox via le choix 2 : sécurisation, changement de domaine, ajout d’un client VPN, de divers outils…
Il ne reste enfin qu’à configurer les outils installés. C’est propre à chacun et dépend de ses abonnements à des débrideurs, de ses comptes sur des sites « sources » et de ses goûts en termes de qualités et langues. Bref, bien trop compliqué de préparer des configurations prêtes à l’emploi. TRaSH-Guides propose des exemples et profils, par exemple pour les *arr.
Le petit bémol de SSDv2 est qu’il ne propose pas encore de dashboard récapitulatif des applications installées et des sous-domaines. Il semble que ce soit en projet, mais sans ETA. Vu le boulot qu’ils abattent à côté, on ne leur en veut pas
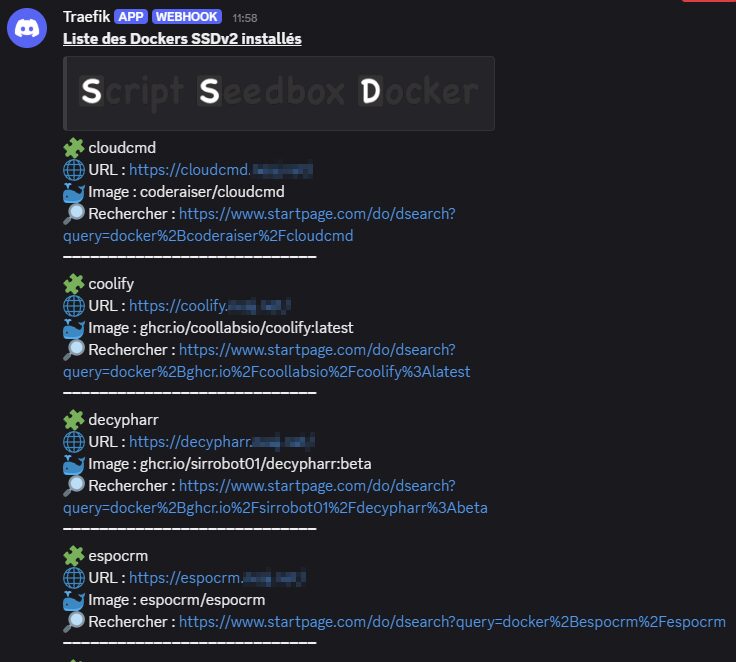
Du coup je me suis fait un petit script qui va chercher les sous-domaines de Traefik, les Dockers créés et mix tout ça dans une récap qui n’est sans doute pas la plus belle mais que je trouve bien pratique. J’ai publié ça sur mon GitHub.
Merci à laster13 pour sa dispo et sa bienveillance, depuis des années
Je navigue tout le temps sous VPN et il arrive que certains sites soient bloqués du fait de l’IP utilisée. C’est par exemple le cas de YouTube qui veut donc que je me connecte pour vérifier mon droit d’accès. SmartProxy est un plugin Firefox (tous OS, Android), Chrome & Edge (…) qui permet d’ajouter des proxies personnels ou via liste et surtout de créer des règles d’utilisation. Je le trouve plus simple (et « moderne ») que FoxyProxy que j’ai utilisé des années.
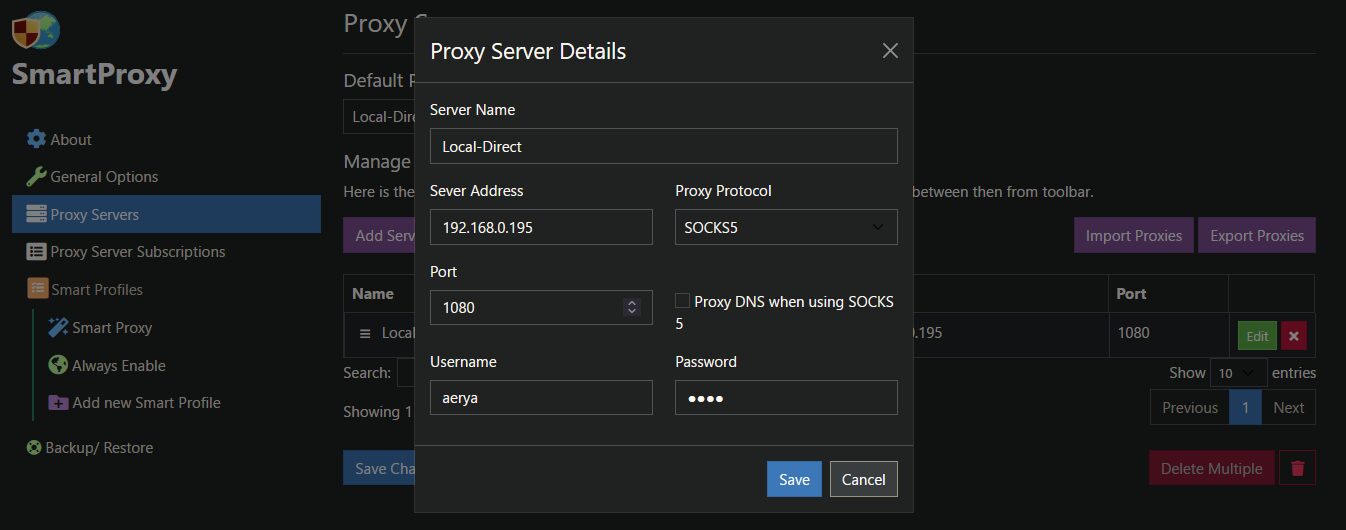
Dans mon cas, un simple serveur proxy (https/socks) installé sur mon serveur au garage suffit vu que je n’ai besoin que d’une IP française « propre ». Ceci dit rien n’interdit de lier ce serveur à un Docker VPN.
Et on peut soit activer un proxy par défaut soit via des règles















 Avantages d’Unbound avec la prélecture (prefetching) :
Avantages d’Unbound avec la prélecture (prefetching) : Avantages de l’utilisation de Redis :
Avantages de l’utilisation de Redis :




{kind=link}
{kind=link}