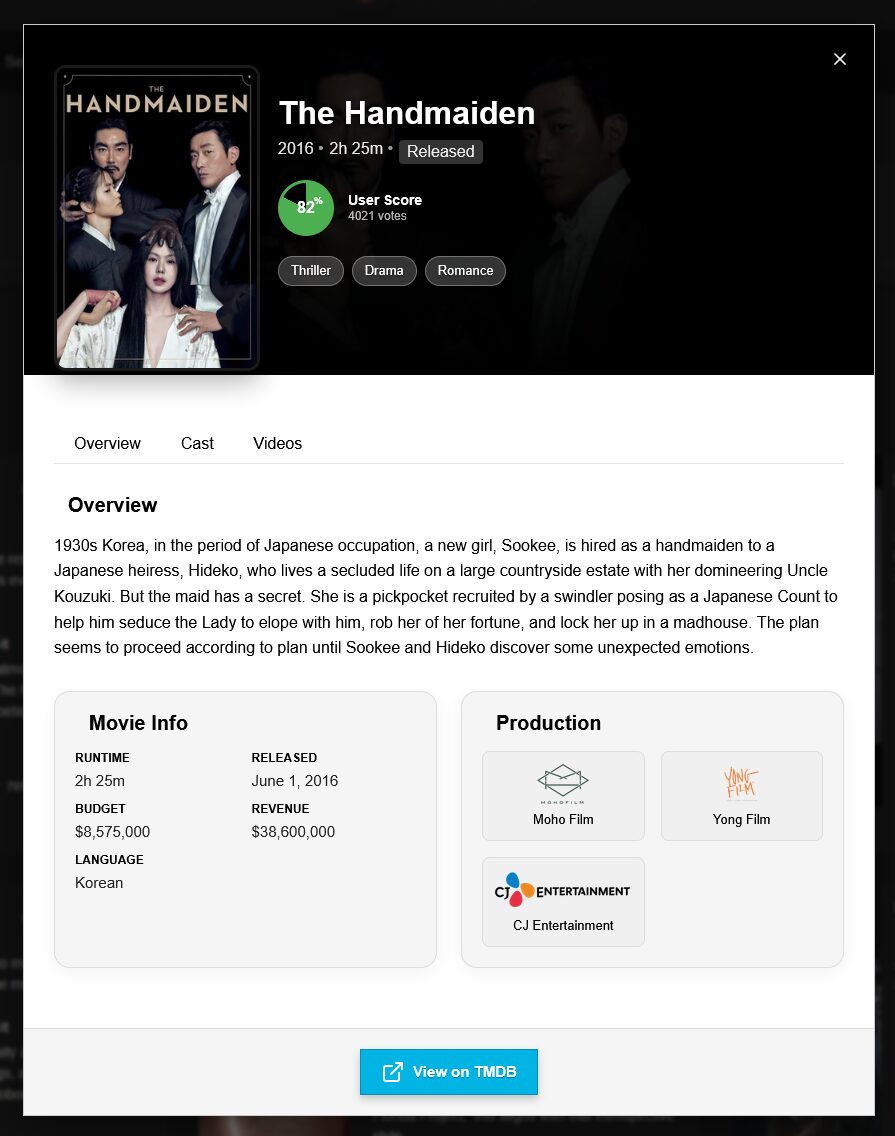
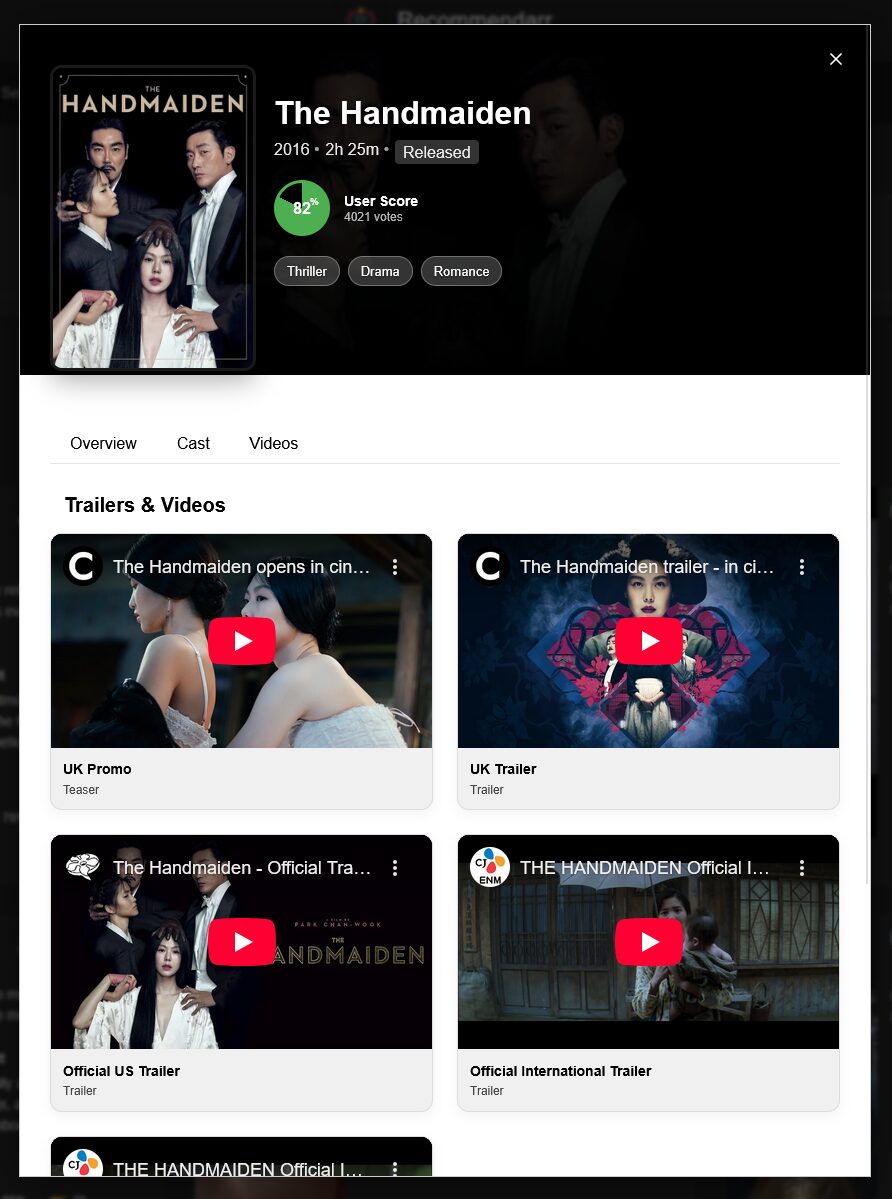
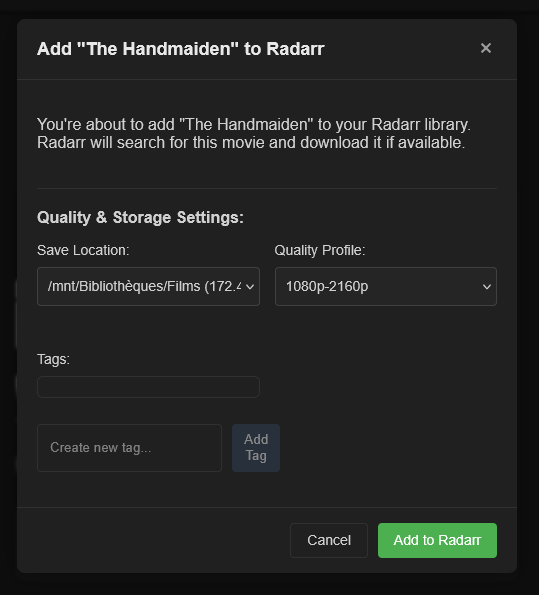
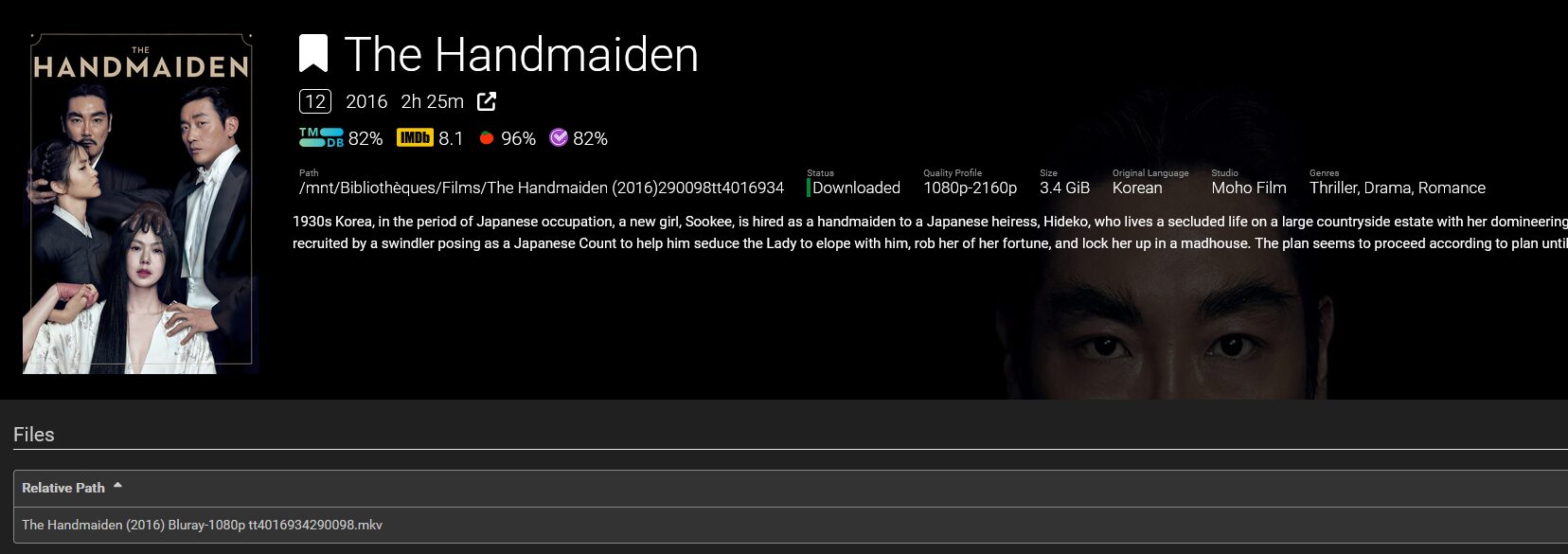
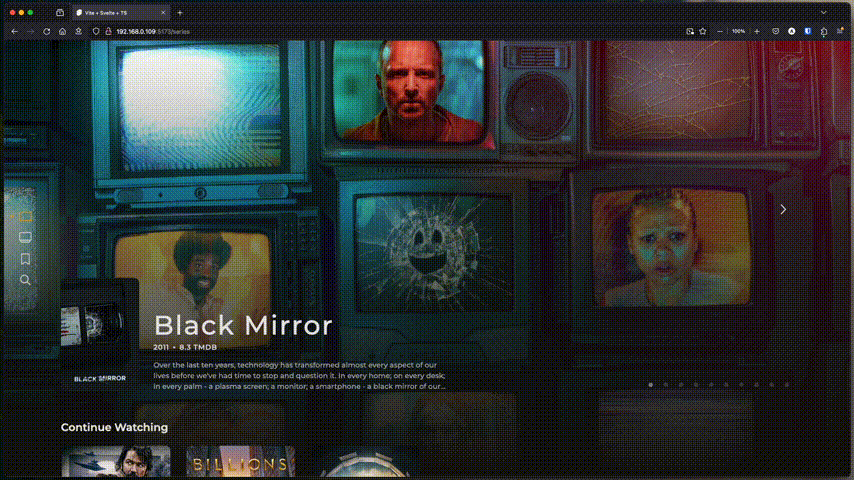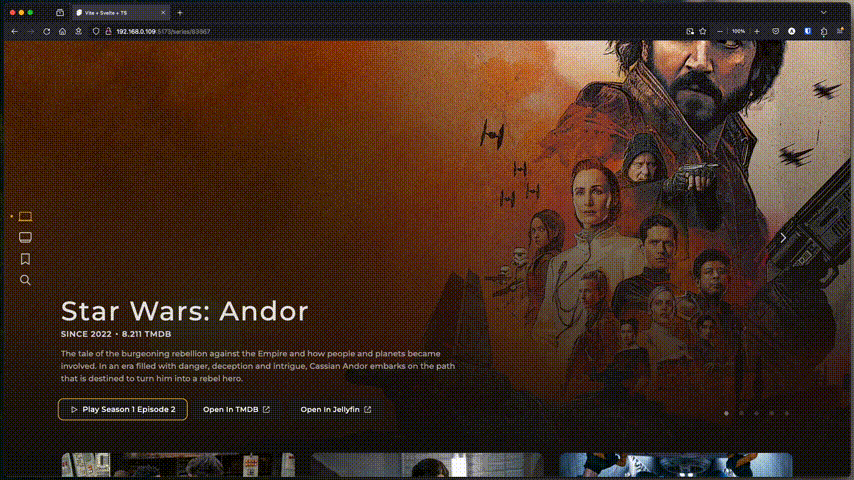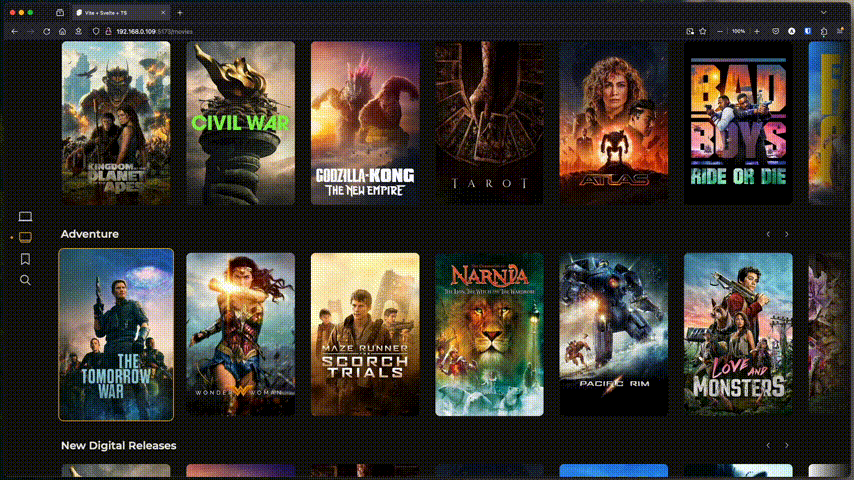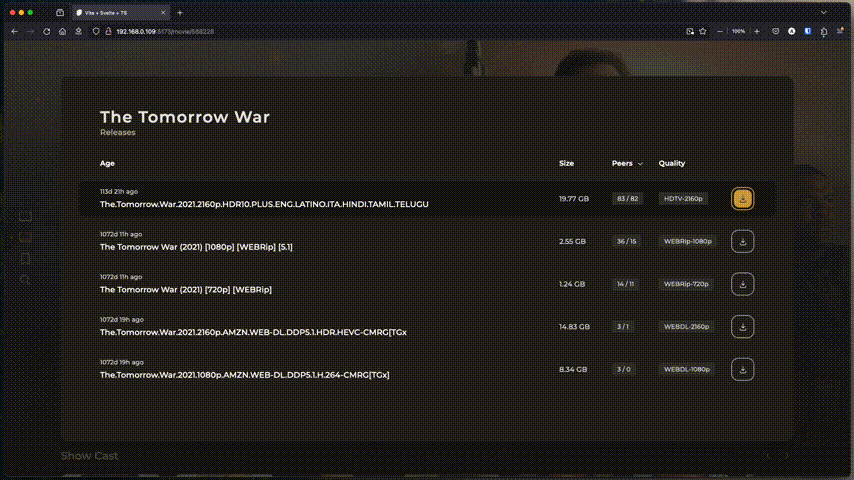
Dans le monde étrange de Little Nightmares III, les joueurs sont plongés dans une histoire de mystère et de survie. Avec la présence hantée de Nowhere rôdant à chaque coin, comment notre nouveau protagoniste, Low, navigue-t-il dans ce paysage sinistre ? Vous n’êtes pas seulement en quête de sursauts mais d’une histoire élaborée qui relie […]
Les *arrs c’est du « chinois » pour vous ? Vous n’avez pas de machine assez puissante pour les faire tourner en sus d’un lecteur ? Vous voulez faire simple ?
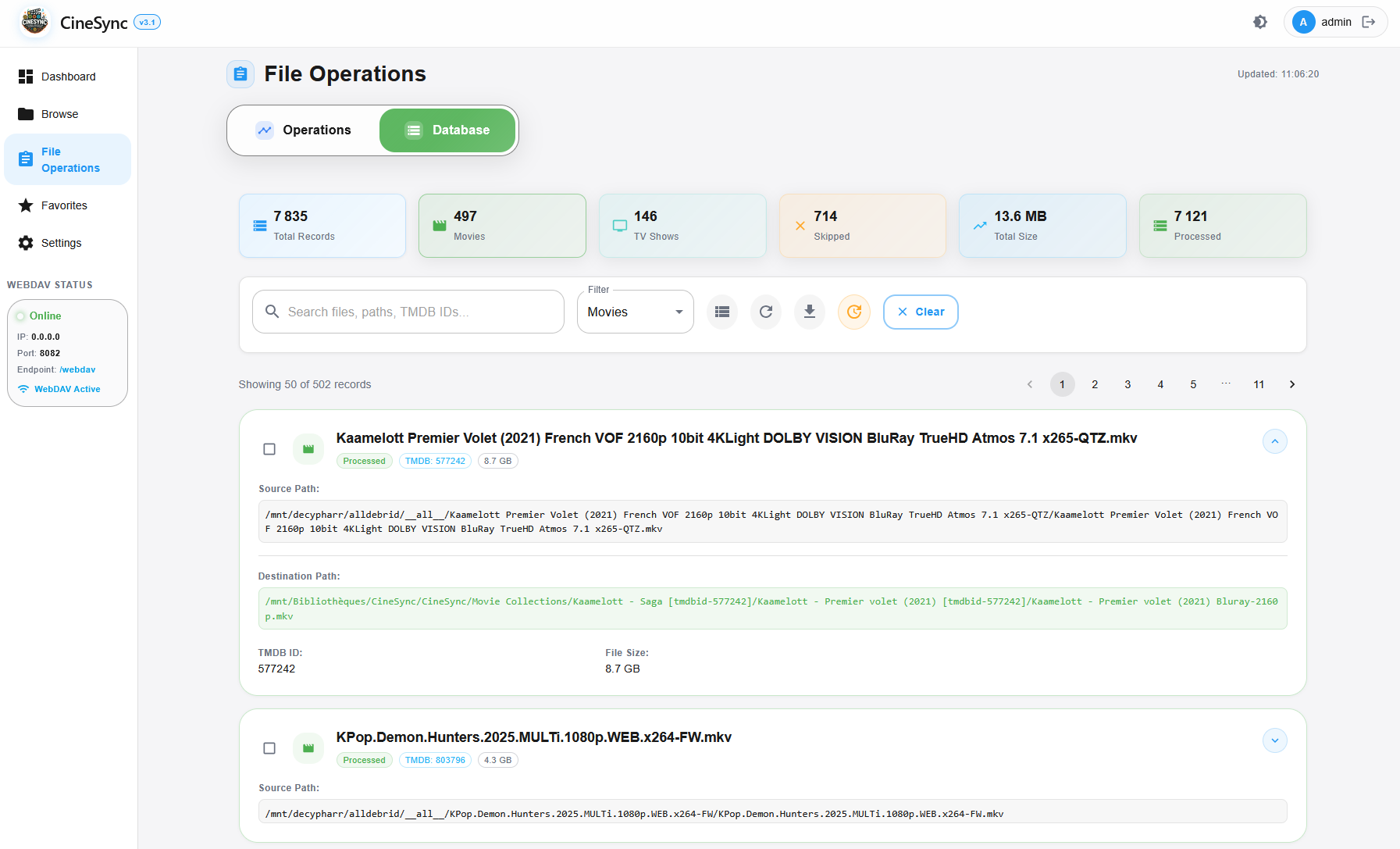
CineSync, qui s’installe en Docker et peut tourner sur des machines peu puissantes avec 1 core et 1GB de RAM, permet, via une clé API (gratuite) TMDB, d’indexer et trier un dossier de fichiers en vrac (films et séries uniquement). Ça trie et organise via des symlinks (liens qui ne prennent aucune place) pour pouvoir ensuite profiter de ça via Plex/Jellyfin/Emby/Kodi ou un lecteur type VLC. Ce n’est pas un lecteur, juste un organiseur.
Pratique si vous avez accès à un FTP, un remote rClone, des APIs RealDebrid, AllDebrid ou TorBox, un montage NFS/sshFS… enfin n’importe quel espace de stockage avec des films et séries.
EDIT 06.10.25 : DjNiklos insiste à juste titre sur le fait qu’on peut combiner les dossiers sources en les séparant par des ,
Monitoring manuel ou automatique évidemment.
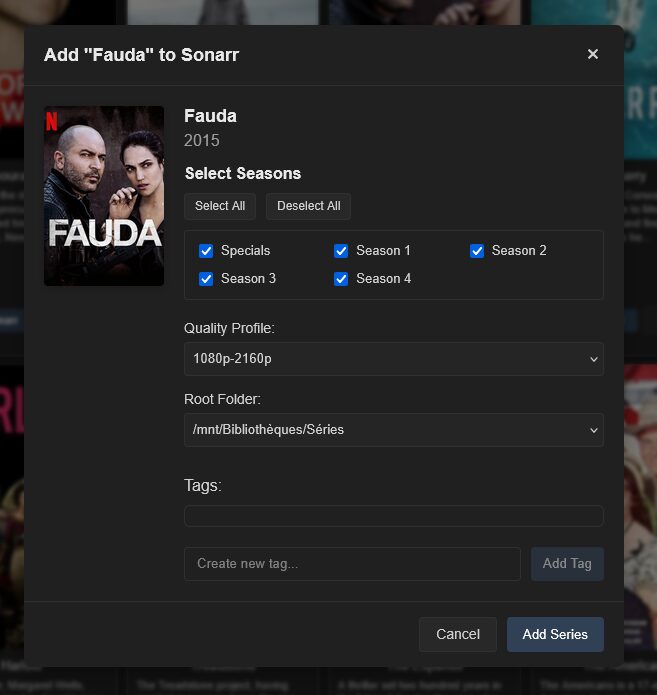
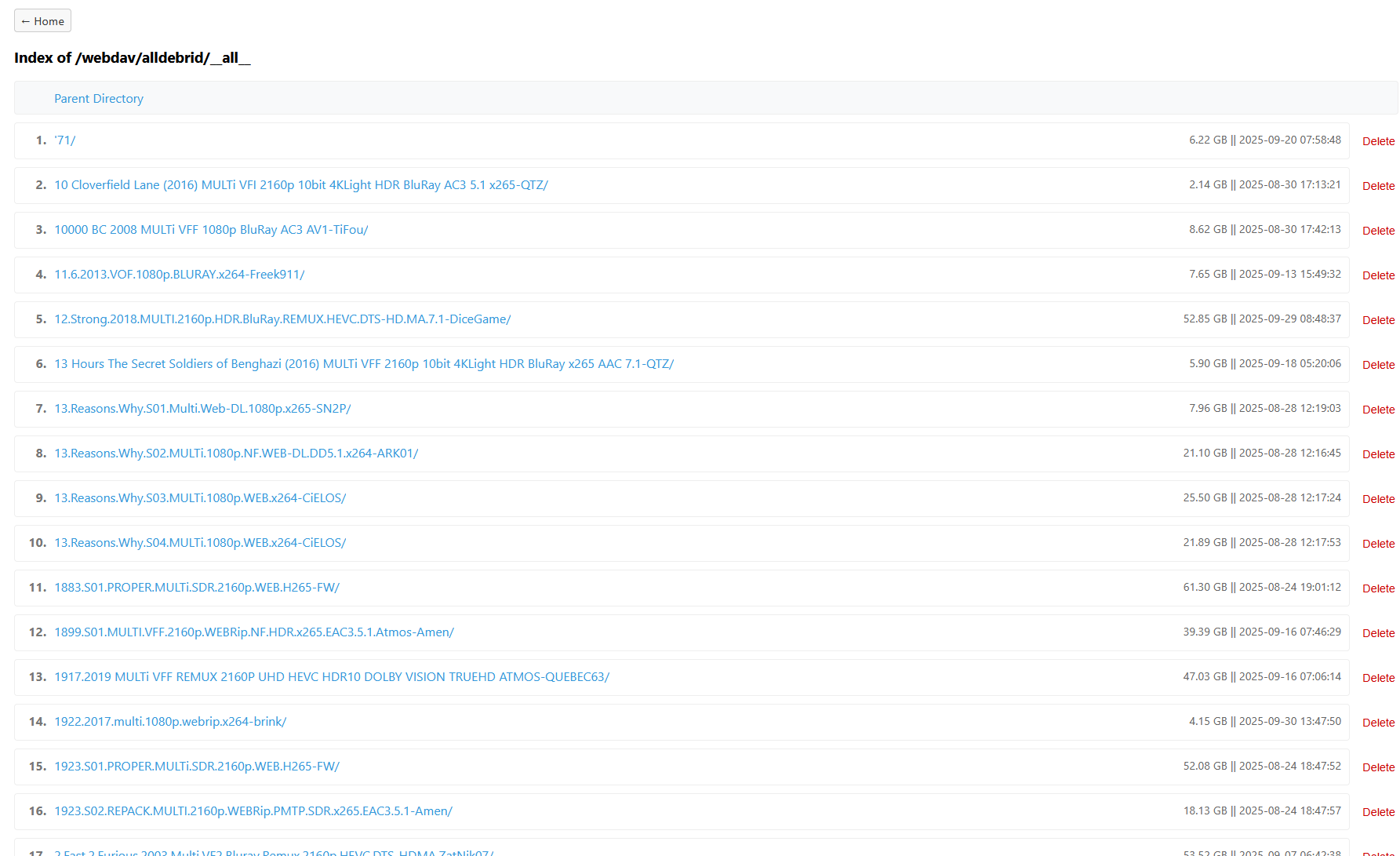
Je le teste avec mon montage AllDebrid de Decypharr, le dossier _ _ all _ _ où tous les fichiers sont en vrac. Le travail peut prendre un peu de temps selon la quantité de fichiers à traiter, les ressources allouées (cores/RAM) et les options demandées.
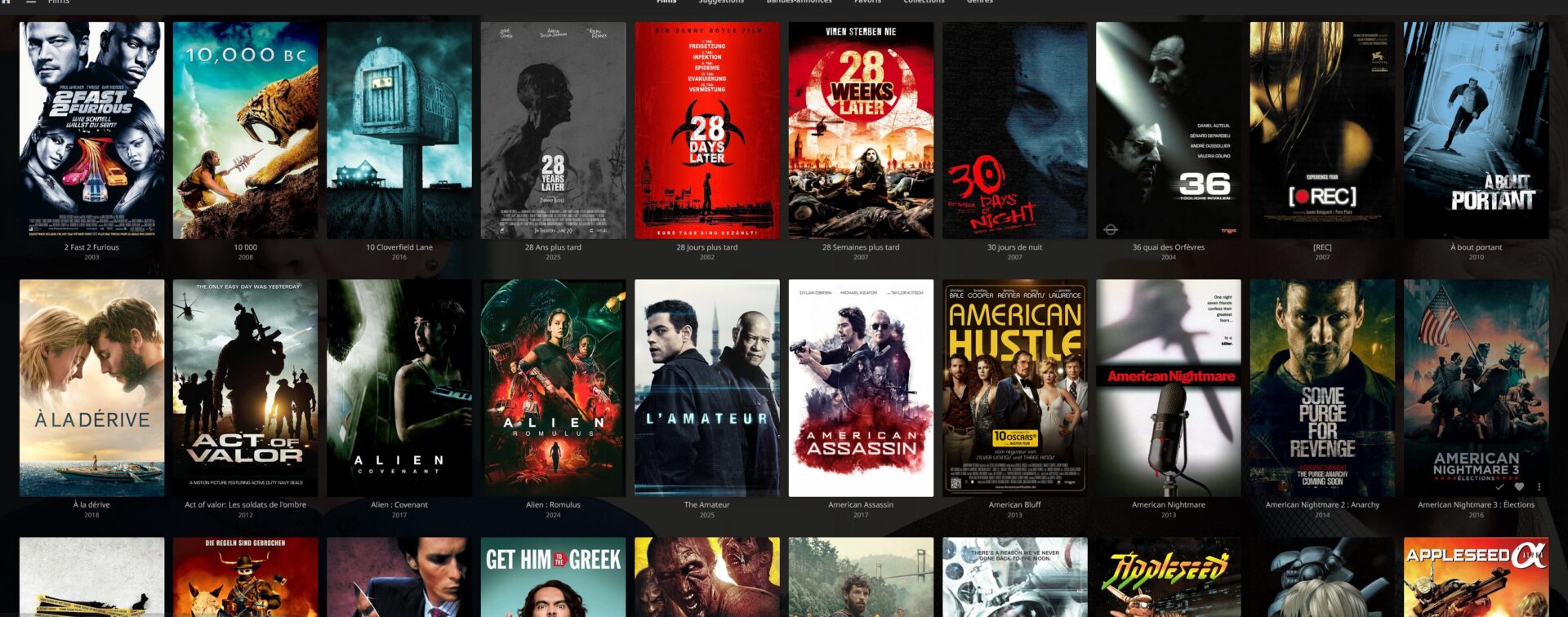
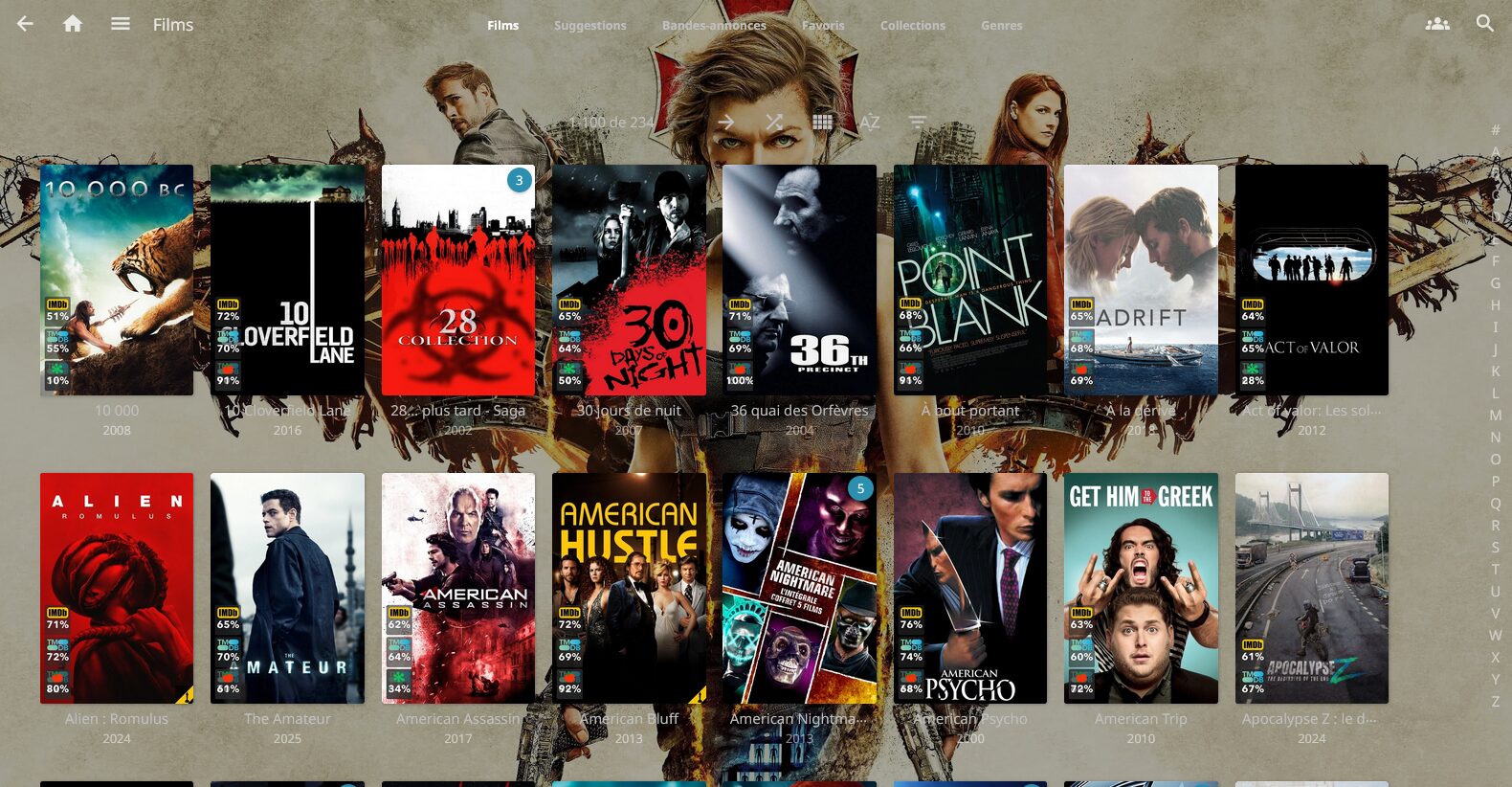
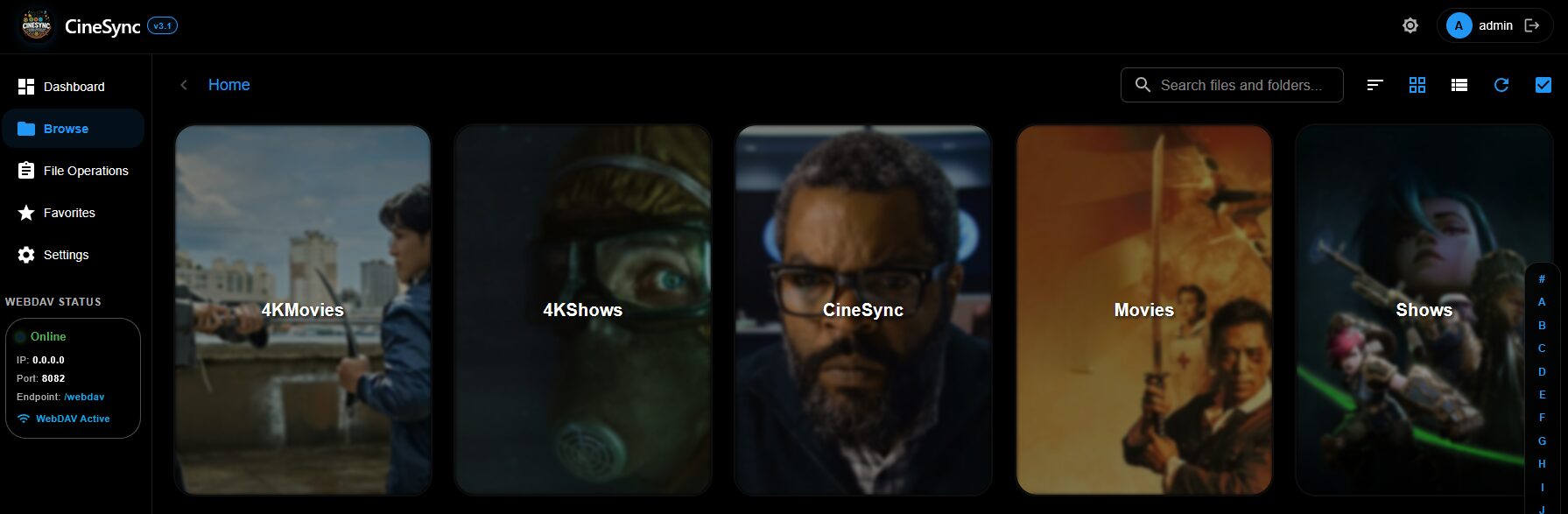
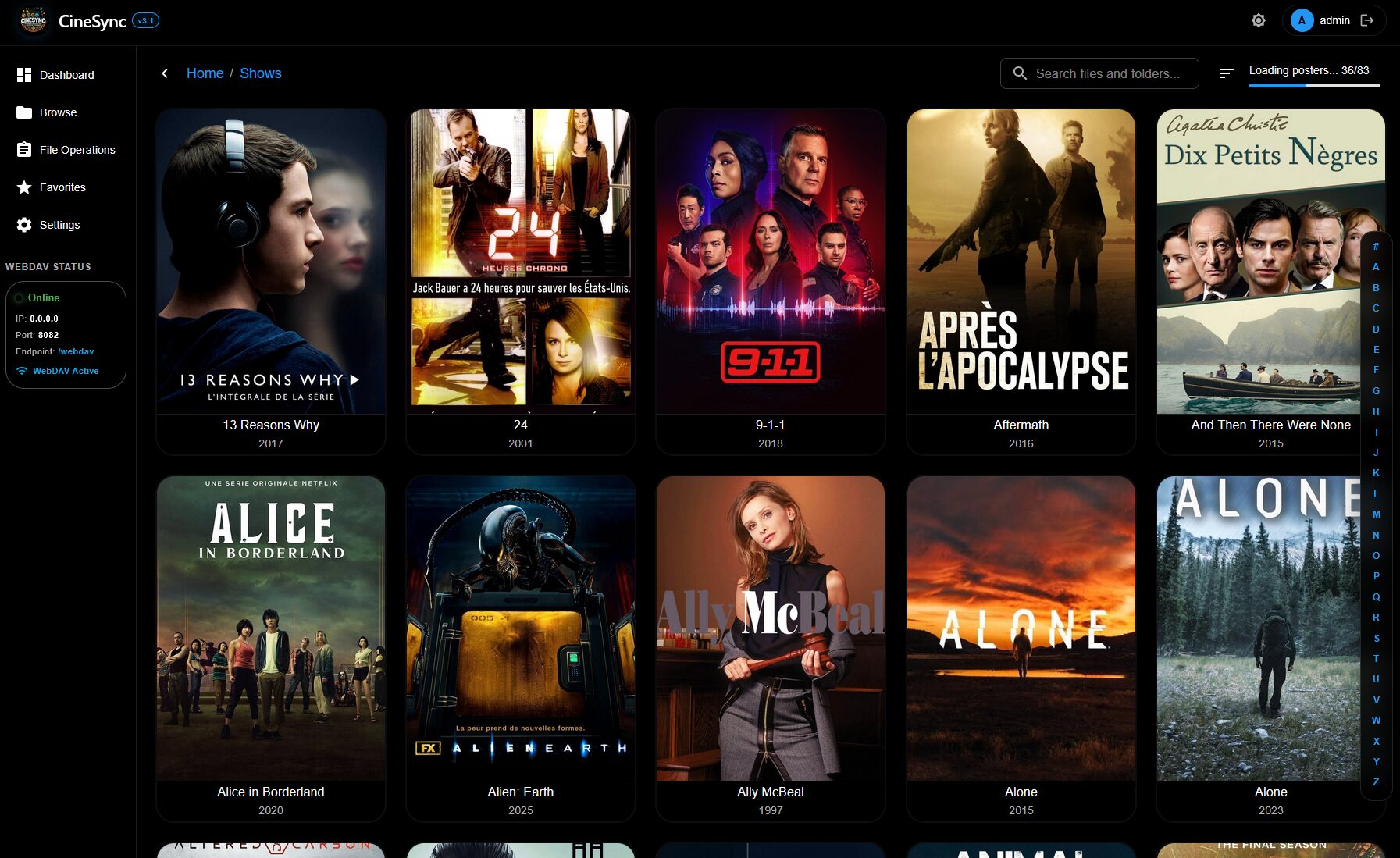
Et ça donne ce genre de tri (j’ai aucun contenu pour enfants mais ça les met à part également)
root@StreamBox:/mnt/Bibliothèques# ls CineSync/
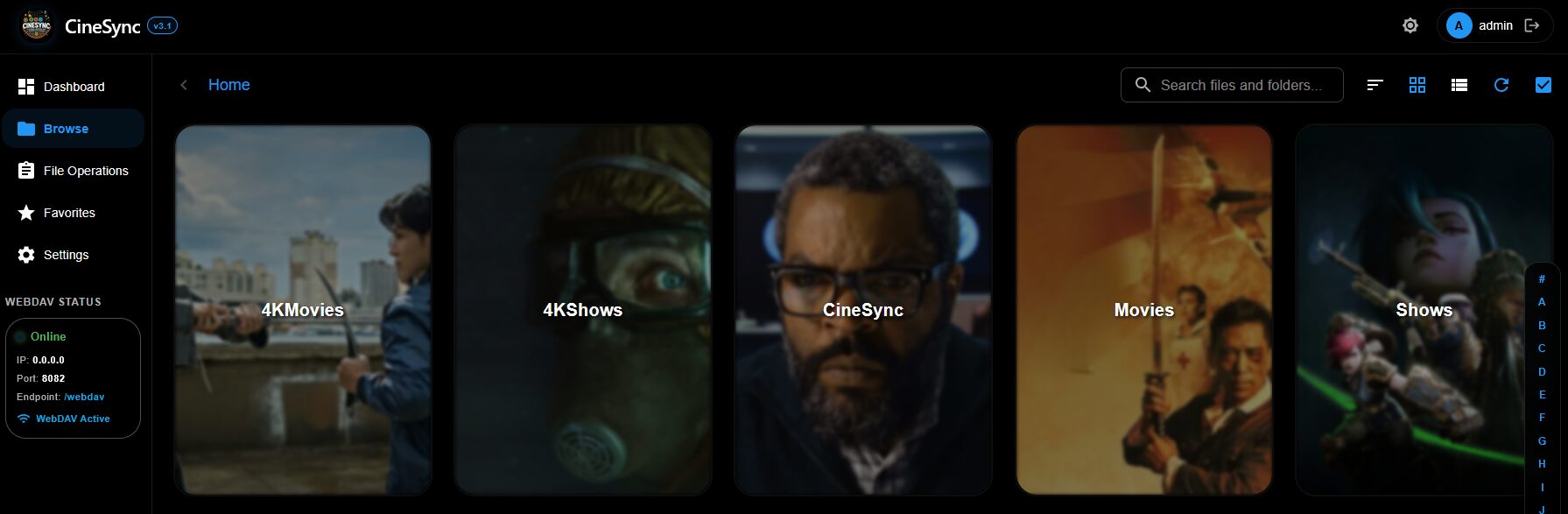
4KMovies 4KShows CineSync Movies Shows
Le dossier CineSync = Collections, quand on demande leur création
Y’a plus qu’à indexer ça avec son lecteur favoris ou y accéder avec VLC ou autre et c’est nickel !
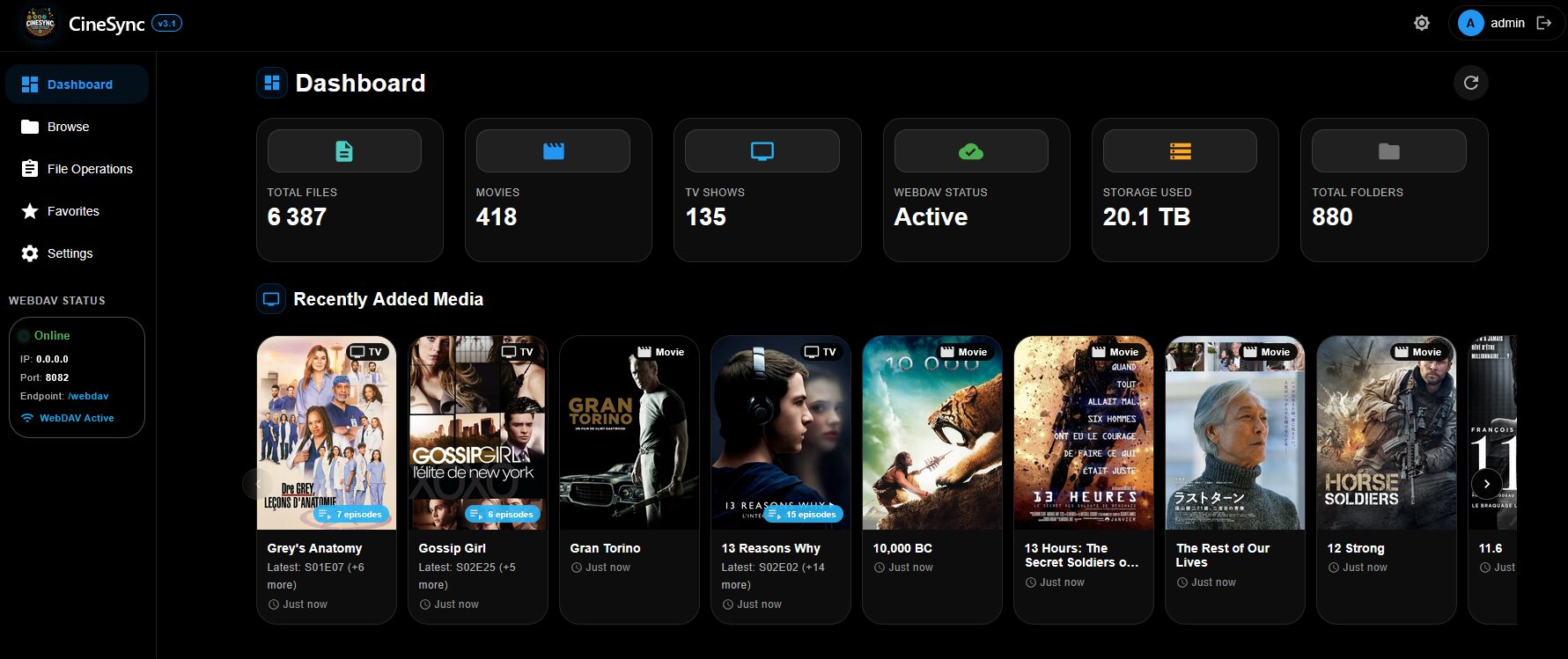
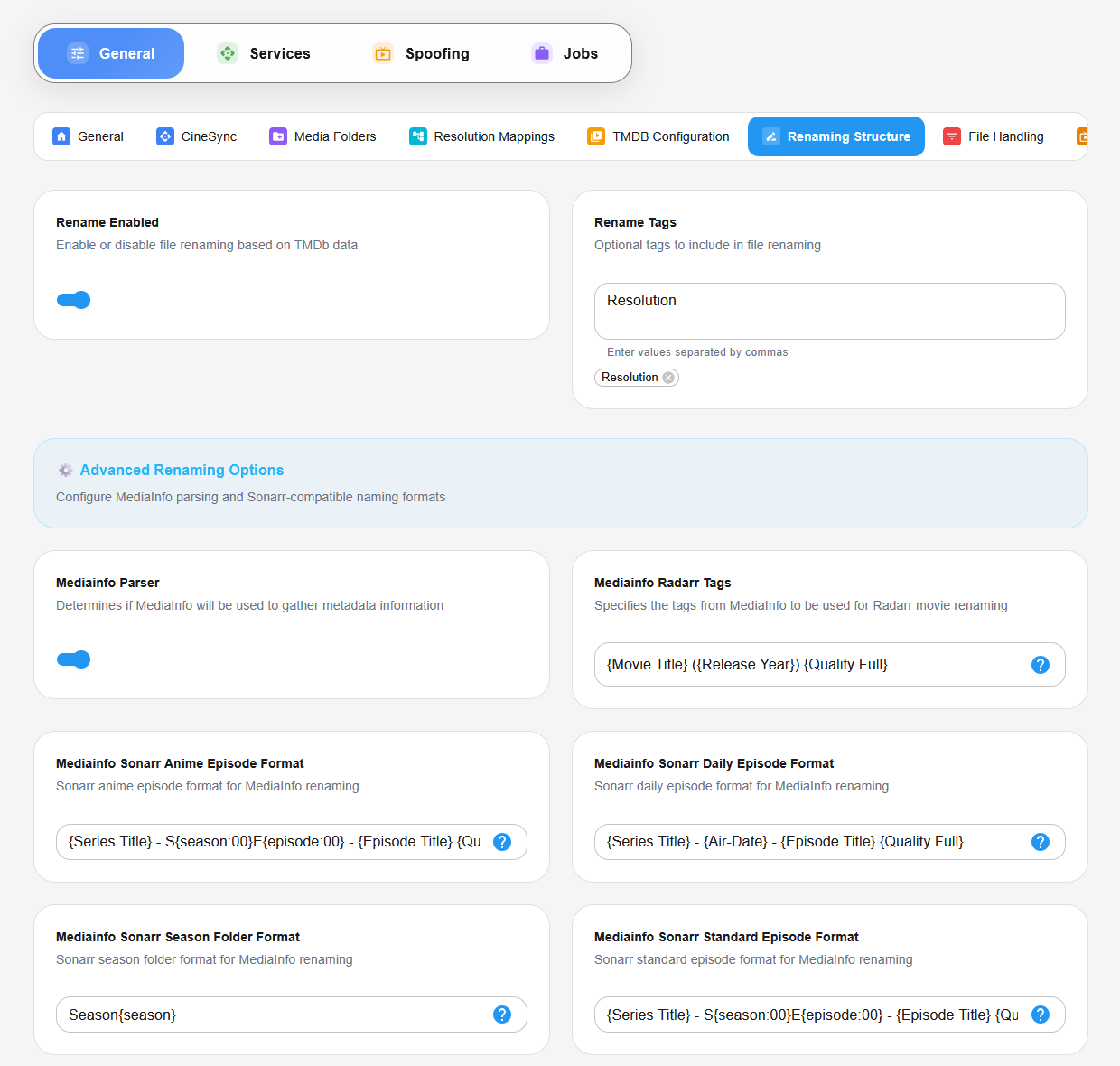
Supervision et automatisation en temps réel
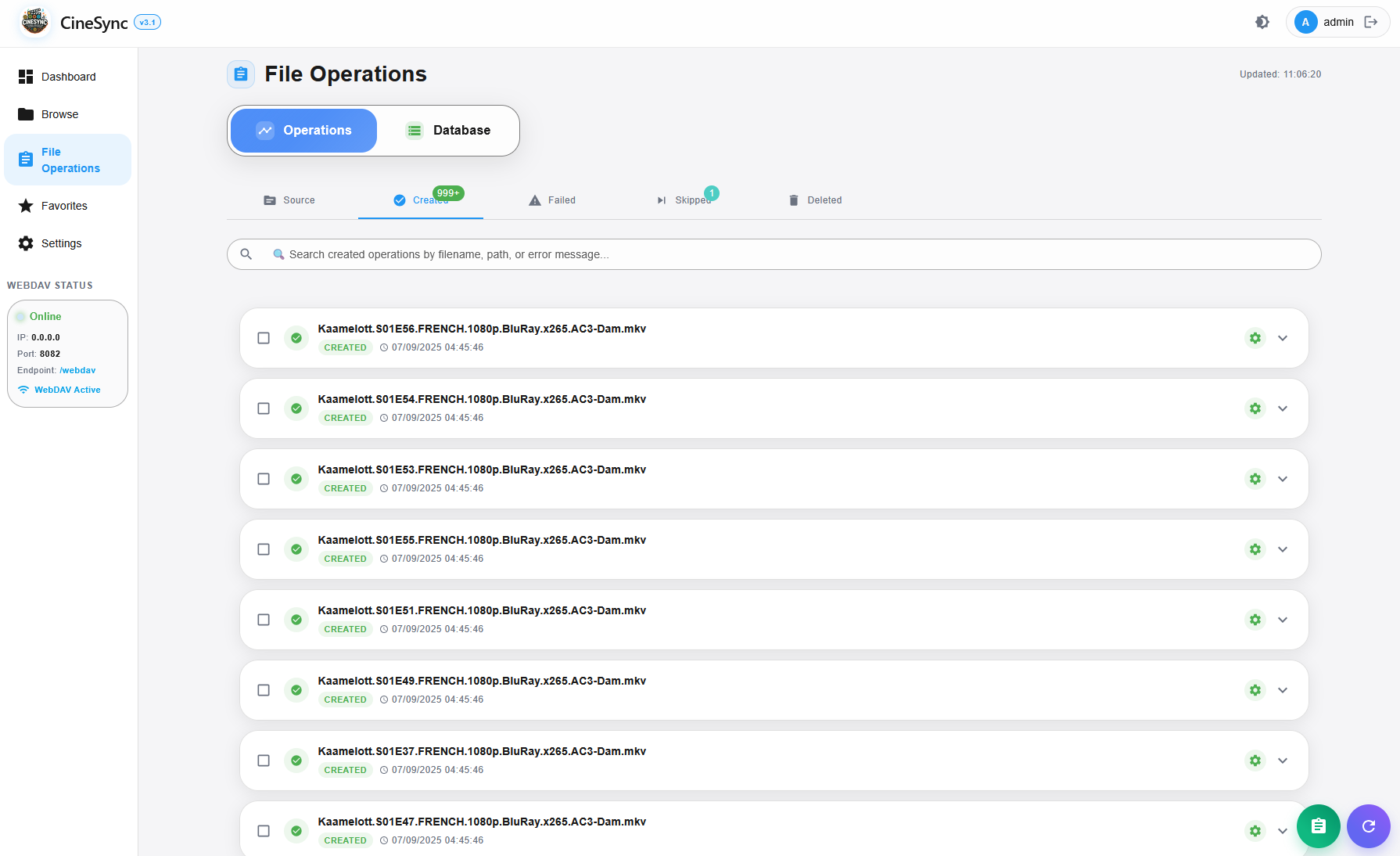
CineSync intègre des fonctions avancées de surveillance et d’automatisation en temps réel, assurant une bibliothèque multimédia toujours parfaitement organisée — sans aucune intervention manuelle. Son interface web moderne offre un contrôle complet sur les paramètres d’automatisation et la supervision en direct de toutes les activités de traitement.
Système de surveillance intelligent
Détection instantanée : des algorithmes avancés repèrent immédiatement les nouveaux fichiers via les événements du système de fichiers.
Mode auto-traitement : activez ou désactivez le traitement automatique directement depuis l’interface web, pour un fonctionnement totalement mains libres.
Intégration streaming : les serveurs multimédias (Plex, Jellyfin, Emby) sont mis à jour en temps réel pour des bibliothèques toujours à jour.
Prévention des doublons : le système évite intelligemment le retraitement des mêmes contenus.
Flux de travail automatisés
Analyse initiale intelligente : un scan complet et une réorganisation de la bibliothèque au démarrage.
Surveillance continue : détection en temps réel des nouveaux fichiers, avec intervalles configurables.
Traitement en lot : gestion efficace de multiples fichiers grâce au traitement parallèle.
Récupération automatique : nouvelle tentative sur les opérations échouées, avec temporisation exponentielle.
Tableau de bord en temps réel
Statistiques en direct : visualisez instantanément la progression et l’état de la bibliothèque.
Suivi des ajouts récents : traçabilité automatique des contenus récemment ajoutés.
File d’attente visible : surveillance graphique des opérations en cours et à venir.
La surveillance en temps réel de CineSync est désormais une fonctionnalité native des scripts et images Docker, assurant une intégration fluide dans votre flux de travail. Grâce à elle, la gestion de votre médiathèque devient automatique et sans effort.
Automatisation personnalisable
Planification flexible : configurez les intervalles de surveillance et les horaires de traitement.
Règles spécifiques par contenu : appliquez des logiques différentes pour les films, séries, animés ou contenus jeunesse.
Nettoyage intelligent : suppression automatique des liens symboliques cassés et des entrées orphelines dans la base de données.
Intégration avec les serveurs multimédias
Jellyfin / Emby : actualisation instantanée via des liens symboliques compatibles inotify.
Plex : mise à jour automatique des bibliothèques grâce à l’API Plex.
Streaming direct : accès en temps réel aux contenus organisés par plusieurs méthodes.
Le système d’automatisation de CineSync transforme la gestion des médias d’une corvée manuelle en un processus fluide, intelligent et permanent.
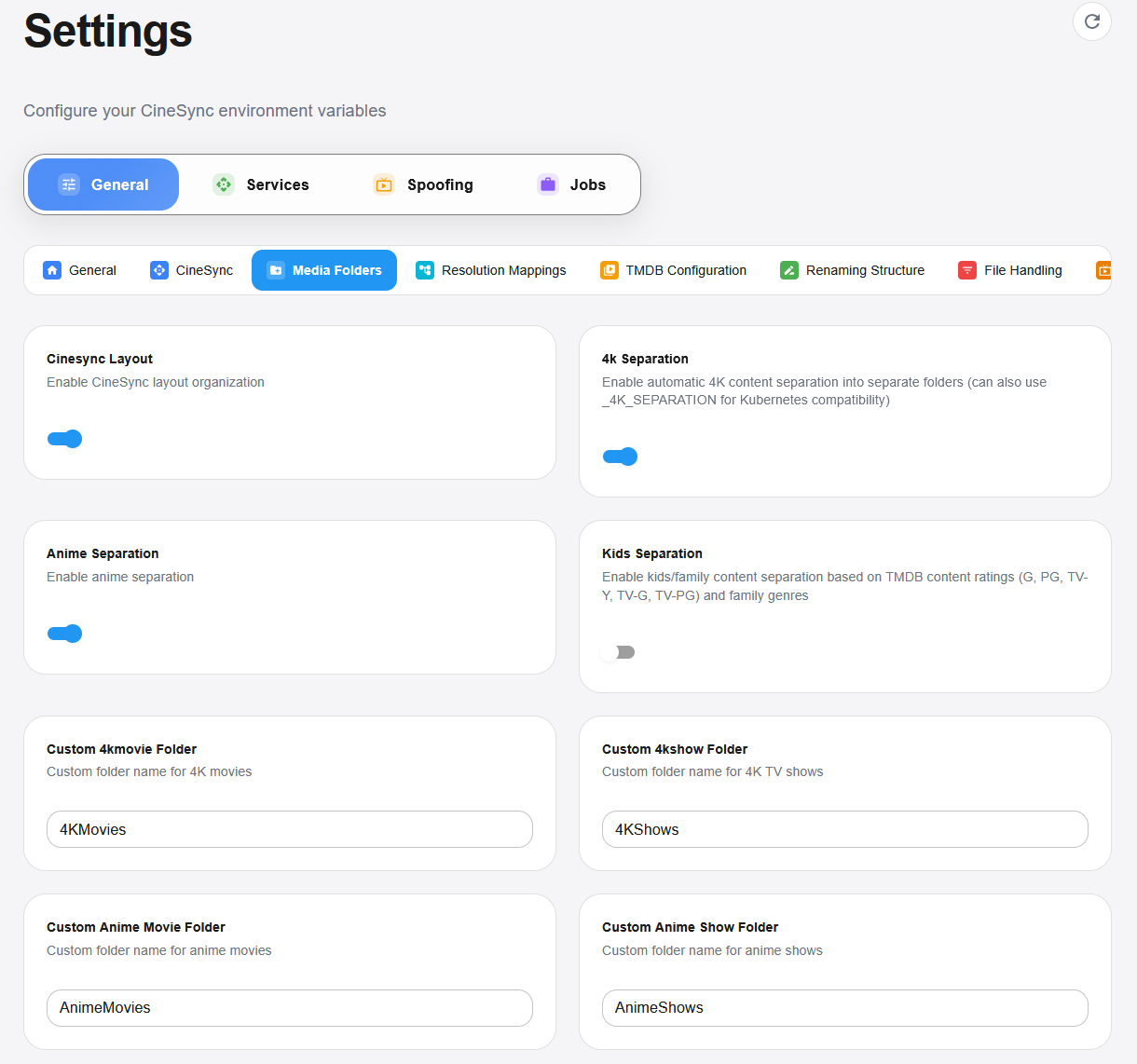
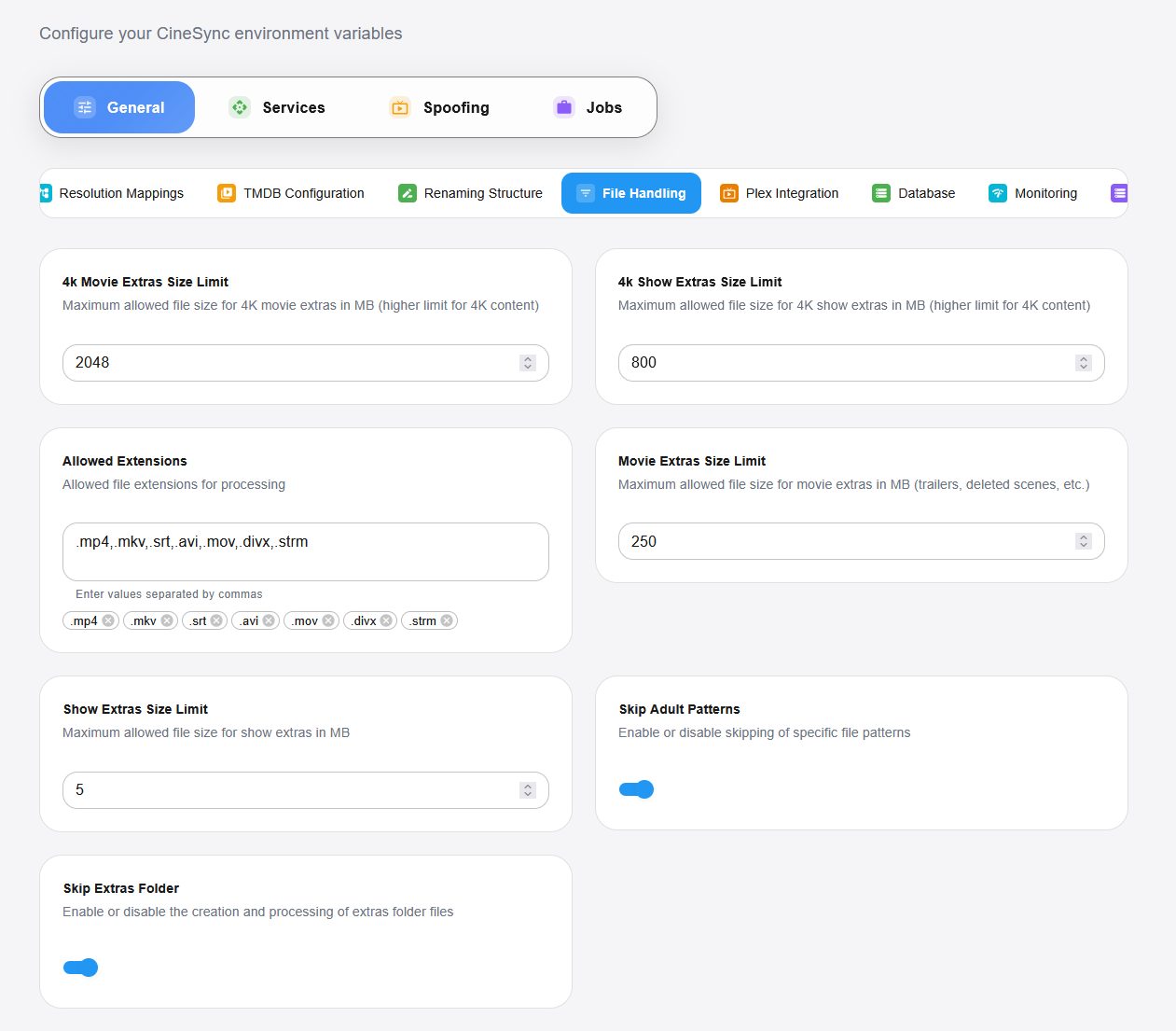
Séparation intelligente des contenus
Contenu jeunesse : détection automatique des médias familiaux via les classifications TMDB (G, PG, TV-Y, TV-G, TV-PG) et les genres familiaux.
Organisation 4K : détection et séparation automatique des contenus UHD dans des dossiers dédiés.
Classification animés : gestion spécifique pour les animés, avec tri distinct entre films et séries.
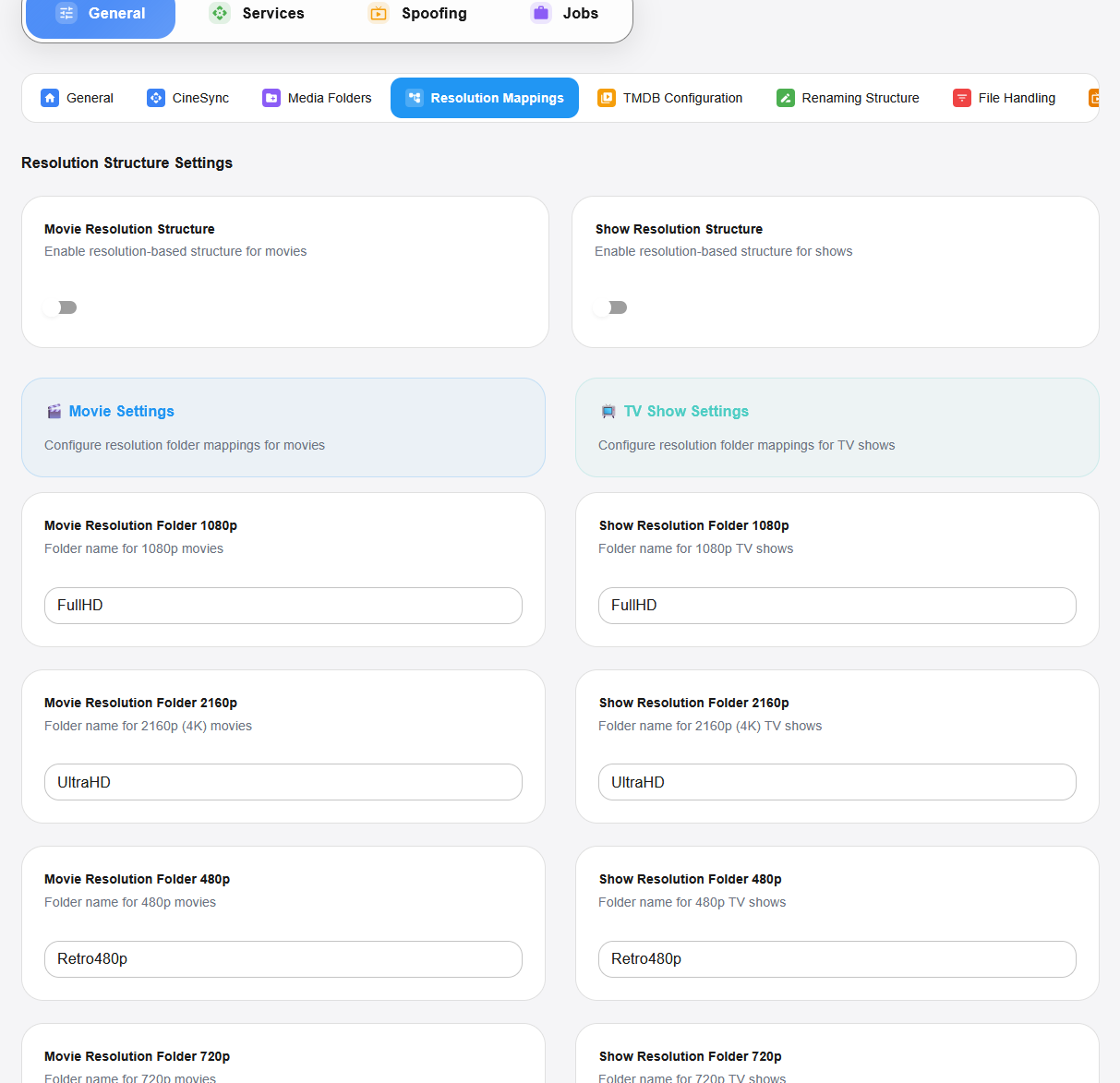
Tri par résolution : classement intelligent selon la qualité vidéo (720p, 1080p, 4K, etc.).
Options d’organisation flexibles
Structure CineSync : organisation simplifiée en dossiers Movies et Shows.
Préservation de la structure source : possibilité de conserver les arborescences d’origine.
Nommage personnalisé : configuration libre des noms de dossiers selon le type de contenu.
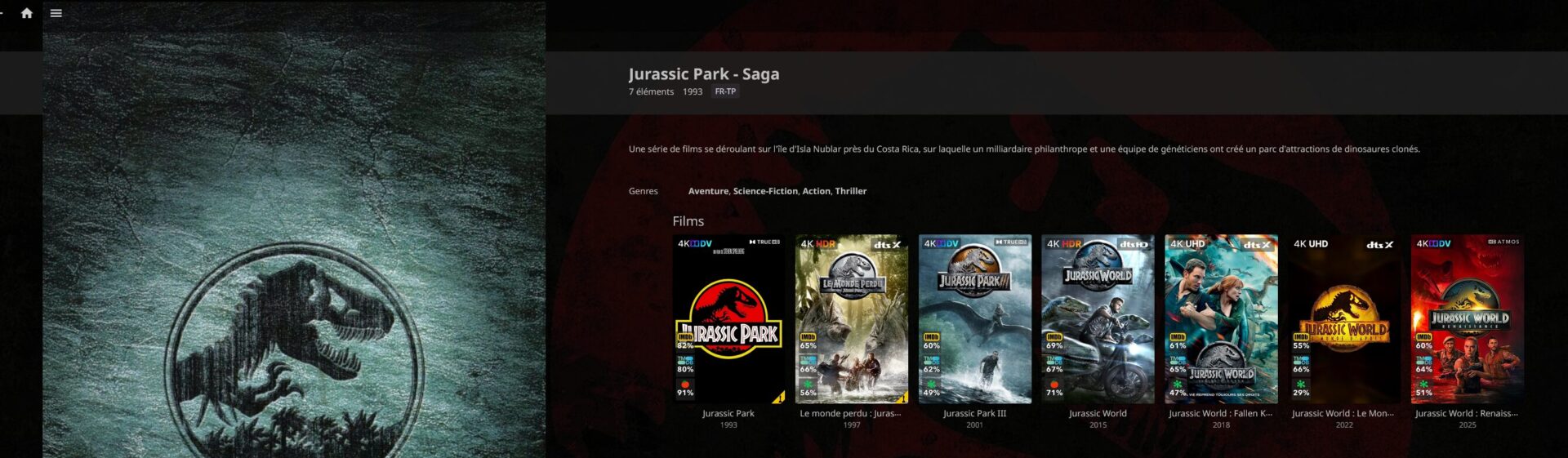
Regroupement par collections : organisation automatique des sagas et franchises dans des répertoires communs.
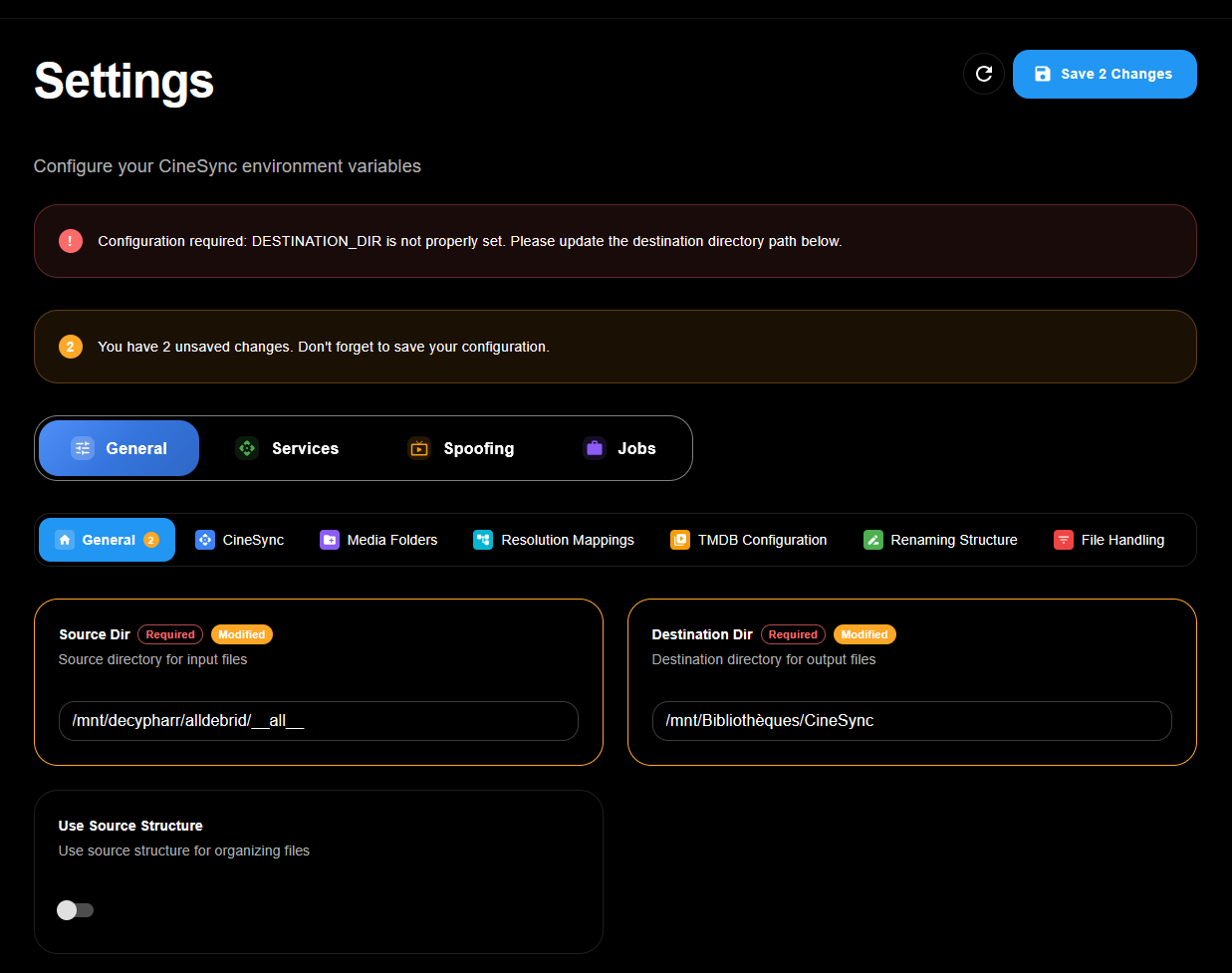
Plutôt que de tout configurer via l’interface Web, on peut y adjoindre un .env. Fichier à placer dans le dossier /home/aerya/docker/cinesync/db dans mon cas, le montage local de /app/db. Le fichier de base est ici et il faut surtout y configurer la clé API TMDB et les dossiers source/destination.
# Directory Paths
# ========================================
# Source directory for input files
SOURCE_DIR="/mnt/decypharr/alldebrid/__all__"
# Destination directory for output files
DESTINATION_DIR="/mnt/Bibliothèques/CineSync"
Comme les *arrs quand ils travaillent sur les fichiers hébergés chez AllDebrid, accessibles dans /mnt/decypharr/alldebrid/_ _ all _ _, CineSync va les organiser et structurer localement via des symlinks dans /mnt/Bibliothèques/CineSync où Plex/Jellyfin/whatever pourra les indexer et lire.
admin/admin si vous ne changez pas dans la config
si pas de .env, il faut tout configurer via la WebUI
Et il n’y qu’à le laisser travailler ensuite
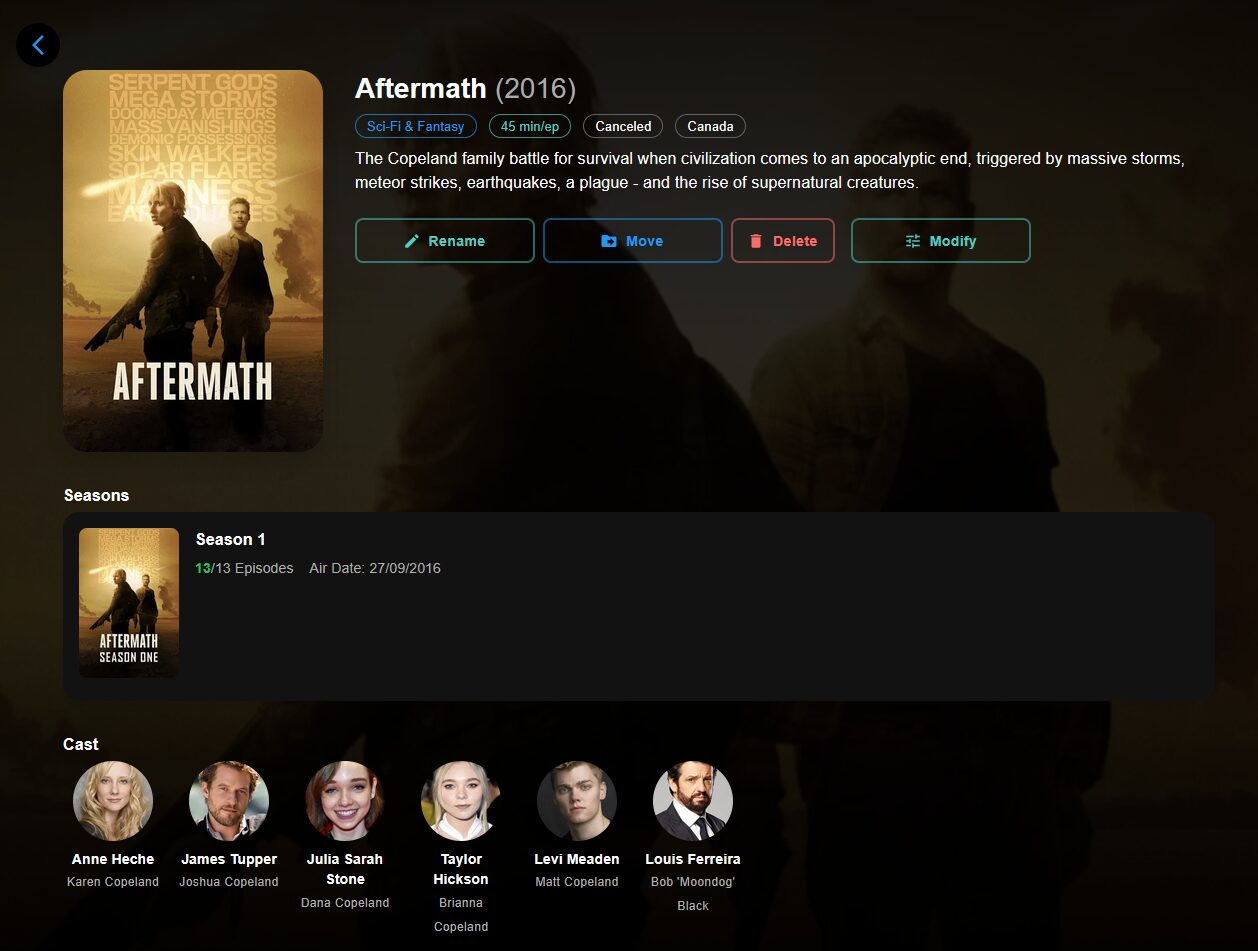
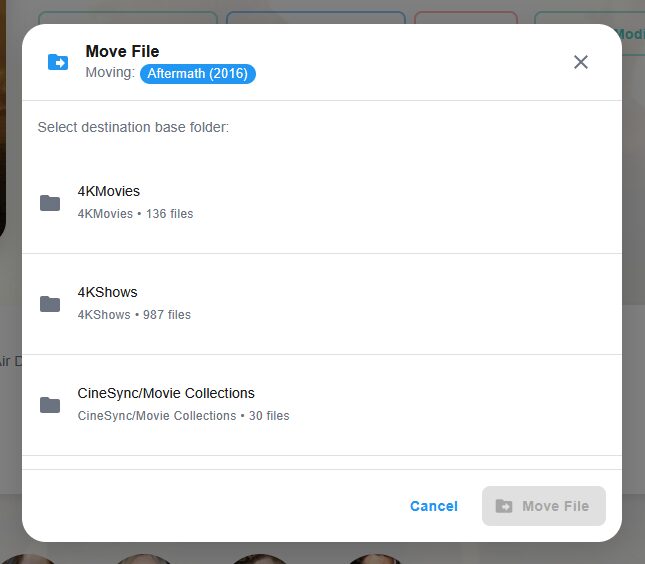
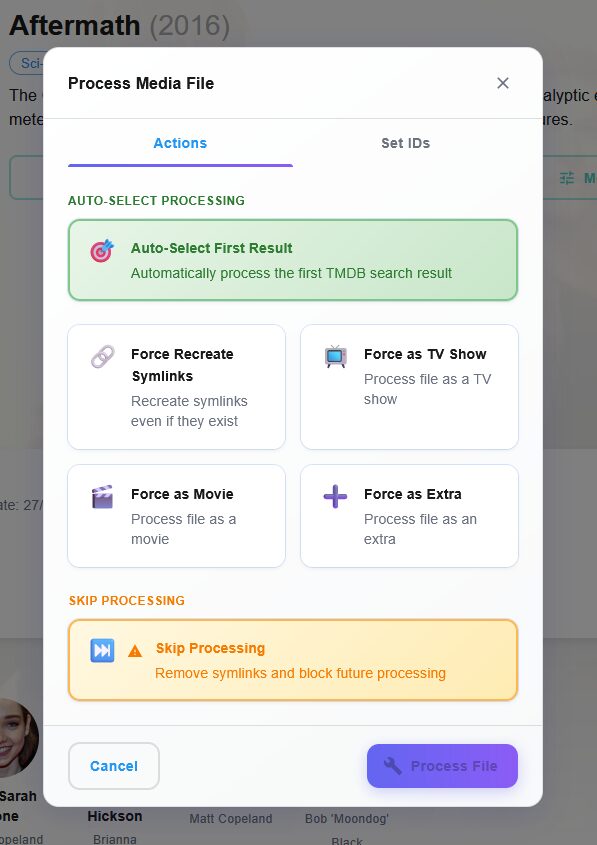
On peut éditer chaque fiche de contenu indexé pour déplacer vers un autre dossier selon l’orga de chacun (moi je laisse CineSync faire par défaut) et/ou éditer les informations d’un média.
On peut suivre et éditer/corriger l’indexation
La configuration est entièrement éditable via la WebUI
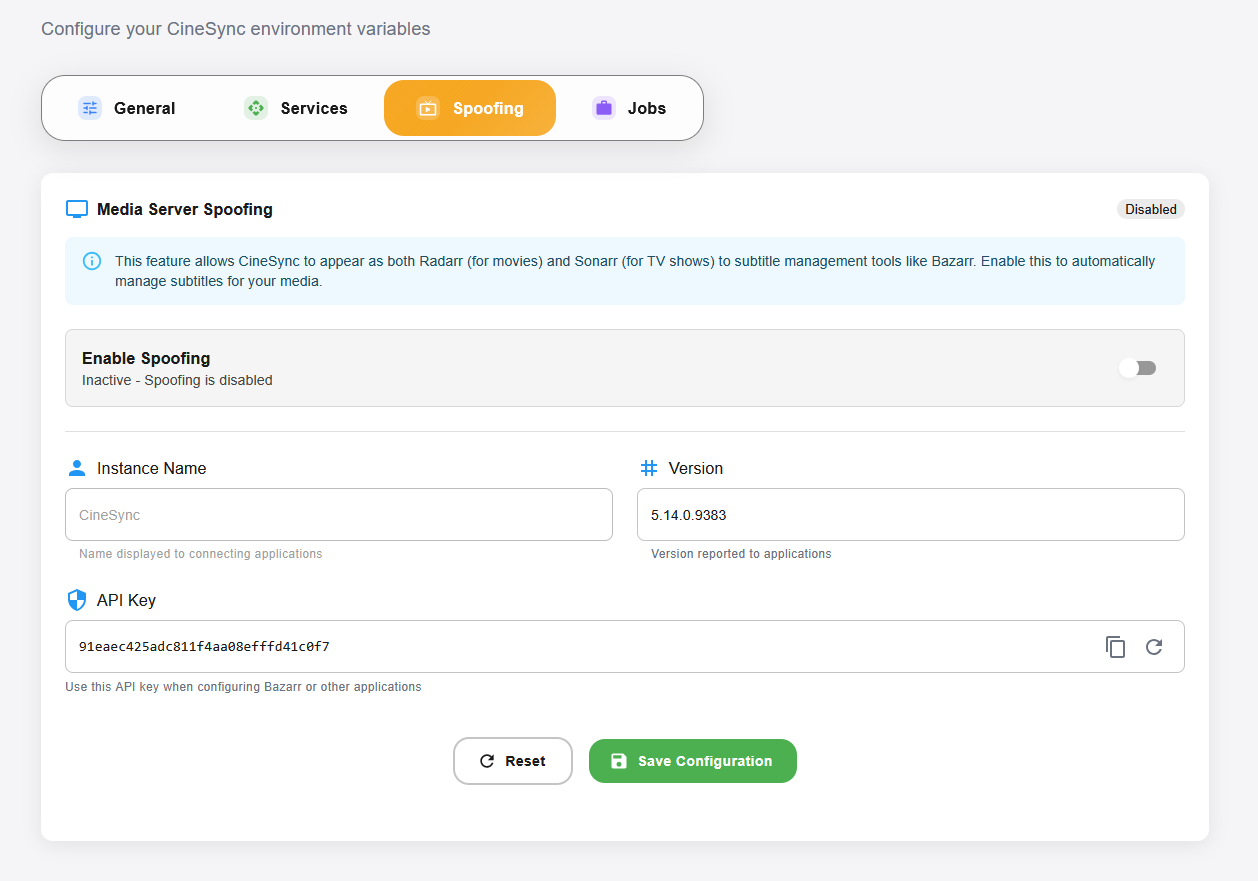
Et il peut même se faire passer pour Radarr et Sonarr auprès de Bazarr pour la gestion automatisée des sous-titres !
C’est vraiment super bien fait et très pratique quand on récupère « juste » un accès à une API ou un montage rClone dont on ne maitrise pas le contenu…
Le député de la 1ère circonscription de la Somme demeure une figure iconoclaste dans le paysage politique en général, il est également l’auteur de plusieurs documentaires dont le dernier a été projeté au théâtre « Les 3 Chênes » situé sur Le Quesnoy. A l’origine d’un micro parti politique « Picardie Debout », le 28 juin 2025 la démarche politique a franchi une étape avec le lancement d’un mouvement national, via une plateforme dédiée.
L’objectif est de peser sur tous les scrutins à venir et surtout de s’organiser par département, territoire et plus proche encore… Dans cette optique, après 8 ans au sein du parti LFI, Pierrick Colpin quitte celui-ci pour devenir, depuis le 08 septembre dernier, le référent départemental du mouvement « Debout », en l’occurrence l’entité « Nord Debout ».
« Il n’y a pas de prise en compte de la ruralité, des villes périurbaines et moyennes chez LFI », Pierrick Colpin
« La France insoumise concentre ses moyens uniquement sur la Métropole lilloise et parachute dans le reste du département des Lillois. Il n’y a pas de prise en compte de la ruralité, des villes périurbaines et moyennes chez LFI. Depuis des années, j’ai dénoncé auprès des instances lilloises ce problème majeur, mais je n’ai pas été écouté du tout. Je suis en désaccord avec la stratégie politique adoptée par LFI », déclare Pierrick Colpin. En contrepoint à cet appel d’une politique de proximité, Manuel Bompard lancerait la semaine prochaine la campagne des municipales 2026 pour LFI sur la commune de Maubeuge. Opération cosmétique ?
On rappelle que Pierrick Colpin était l’ancien candidat du NFP, aux législatives en 2024, avec un score significatif au 1er tour et un appel au Front républicain à succès. En effet, très distancée au 1er tour de cette législative, suite à une dissolution improbable, Valérie Létard a réussi à maintenir cette circonscription dans le bloc présidentiel grâce, en partie, à ce report massif de voix de gauche.
Ensuite, la motivation de Pierrick Colpin afin de rejoindre le mouvement initié par le député de la Somme est aussi « d’aller convaincre les convaincus. François Ruffin ouvre la porte à d’autres personnes que l’électorat de gauche. Ensuite, le militant n’est pas un simple colleur d’affiches, François Ruffin redonne également de la valeur aux militants (même sans être d’accord avec toute la ligne politique) », conclut-il.
En clair, la gauche est en quête d’une unité pour les grands rendez-vous avec le suffrage universel. Elle ne sera pas simple à trouver. Pour autant, l’exemple valenciennois d’une candidature d’union de la gauche pour ces municipales 2026, portée par Luce Troadec, pourrait être la preuve de proximité d’une entente possible à gauche. En effet, les dénominateurs communs sont plus nombreux que les points de tension, mais surtout le respect entre les actrices et les acteurs politiques est réel, l’essentiel en fait et pas le fruit d’une candidature plurielle opportuniste.
Comment ne pas citer l’écrivain Saint-Exupéry à cette occasion : « L’essentiel est invisible pour les yeux. »
Si Jellyfin peut créer en standard des collections de films et qu’on peut en constituer d’autres via des listes, je voulais un outil pour en faire selon mes goûts, avec mon contenu disponible, voire qu’elles rassemblent films et séries.
Le plugin original de johnpc permettait aux utilisateurs de :
Créer des collections basées sur les tags appliqués aux films et séries
Mettre à jour automatiquement les collections lorsque des éléments étaient tagués ou détagués
Configurer des noms de collections personnalisés pour chaque tag
Ce que fait cette version améliorée
Ce fork étend les fonctionnalités originales avec :
Deux modes de collections :
Collections simples : mise en place rapide avec un filtrage par critère unique
Collections avancées : filtrage complexe avec des expressions logiques booléennes
Multiples méthodes de correspondance : associer du contenu par titre, studio, genre, acteur, réalisateur, tags, et plus encore
Filtrage par type de média : limiter les collections aux films uniquement, aux séries uniquement, ou aux deux
Support des expressions avancées : créer des collections complexes avec des expressions booléennes (AND, OR, NOT)
Options de filtrage enrichies :
Filtrer par métadonnées du contenu (titre, genre, studio, acteur, réalisateur, tags)
Filtrer par évaluations (contrôle parental, notes de la communauté, notes de la critique)
Filtrer par lieux/pays de production
Filtrer par langue audio et langue des sous-titres
Filtrer par note personnalisée définie par l’utilisateur (champ CustomRating de Jellyfin)
Logique booléenne : combiner plusieurs critères avec les opérateurs AND, OR, NOT et des regroupements par parenthèses
Import/Export : sauvegarder et restaurer facilement les configurations de collections au format JSON
Contrôle de la casse : choisir si la correspondance doit être sensible à la casse ou non
Synchronisation planifiée : les collections se mettent automatiquement à jour selon un calendrier
Je passe sur l’installation du plugin, un B-A-BA de Jellyfin.
La configuration, en anglais, n’est pas compliqué. Y’a quelques exemples par défaut donc attendez-vous à devoir supprimer des collections si vous cliquez sur Sync avant de modifier la configuration.
Exemple concret : en me créant une collection de contenus dont le titre ou le studio est « Marvel », ça me liste bien films et séries disponibles dans la même collection.
On peut laisser libre cours à ses envies et préférences
Petit aparté : si vous n’avez pas peur d’ajouter plein de téléchargements à vos *arrs, vous pouvez jeter un œil à Auto Collections de ghomasHudson qui permet de créer des collections à partir de listes IMDB, TMDB, Trakt, MDBlist, Criterion, StevenLu etc. Testé, 987 films ajoutés à Radarr d’un coup. S’il pouvait communiquer, je suis certain qu’il aurait crié !
Petit utilitaire sympathique, même quand le serveur est personnel.
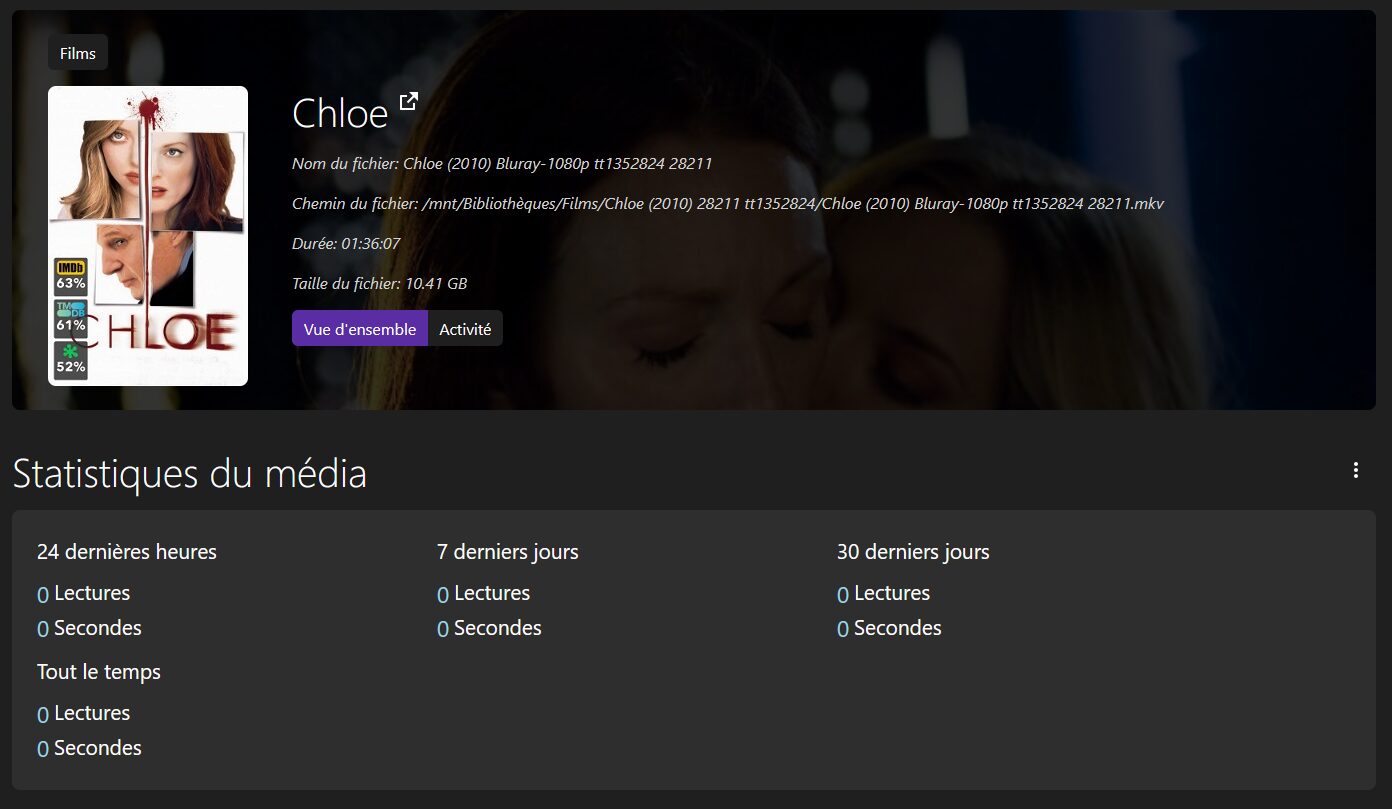
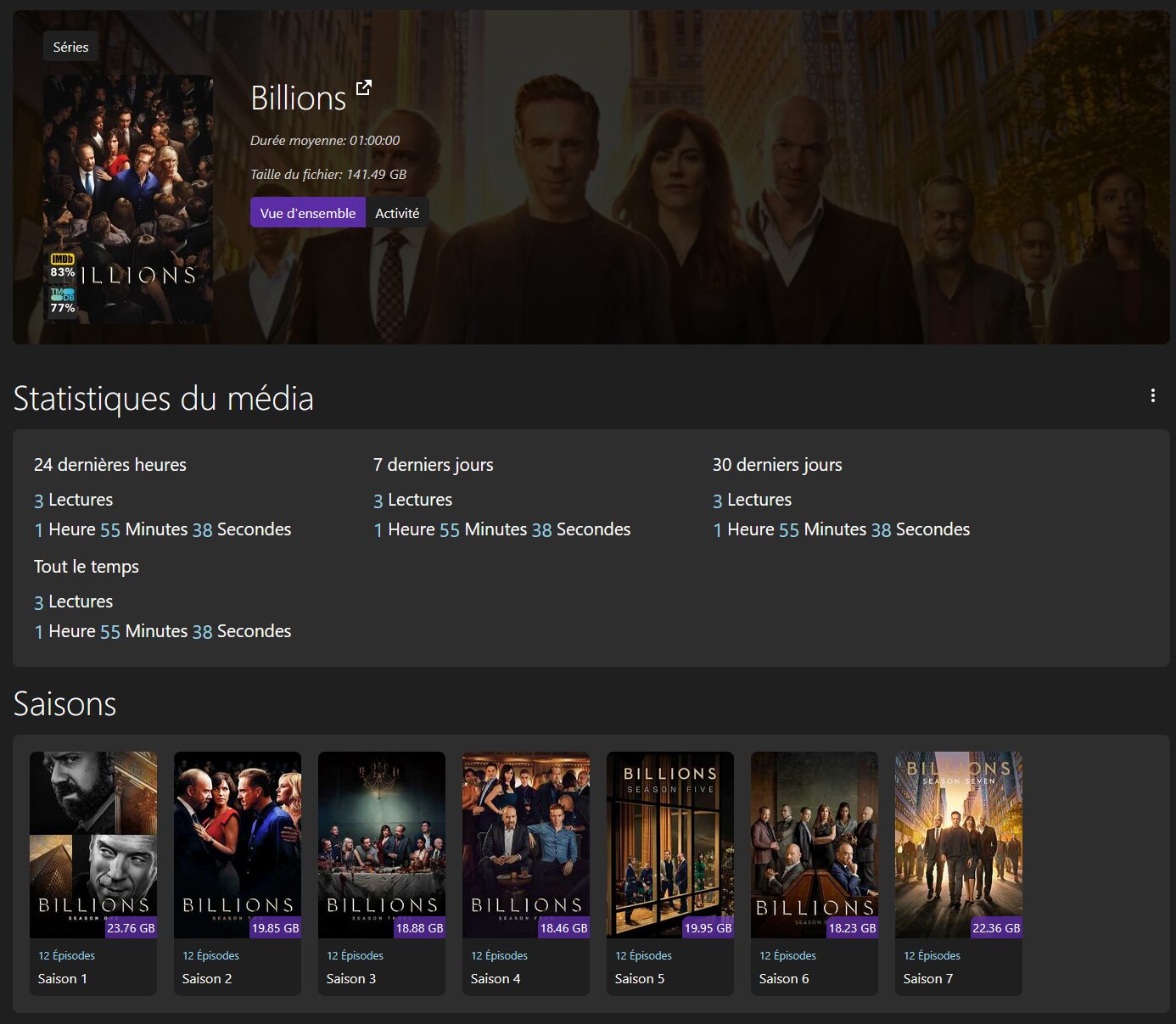
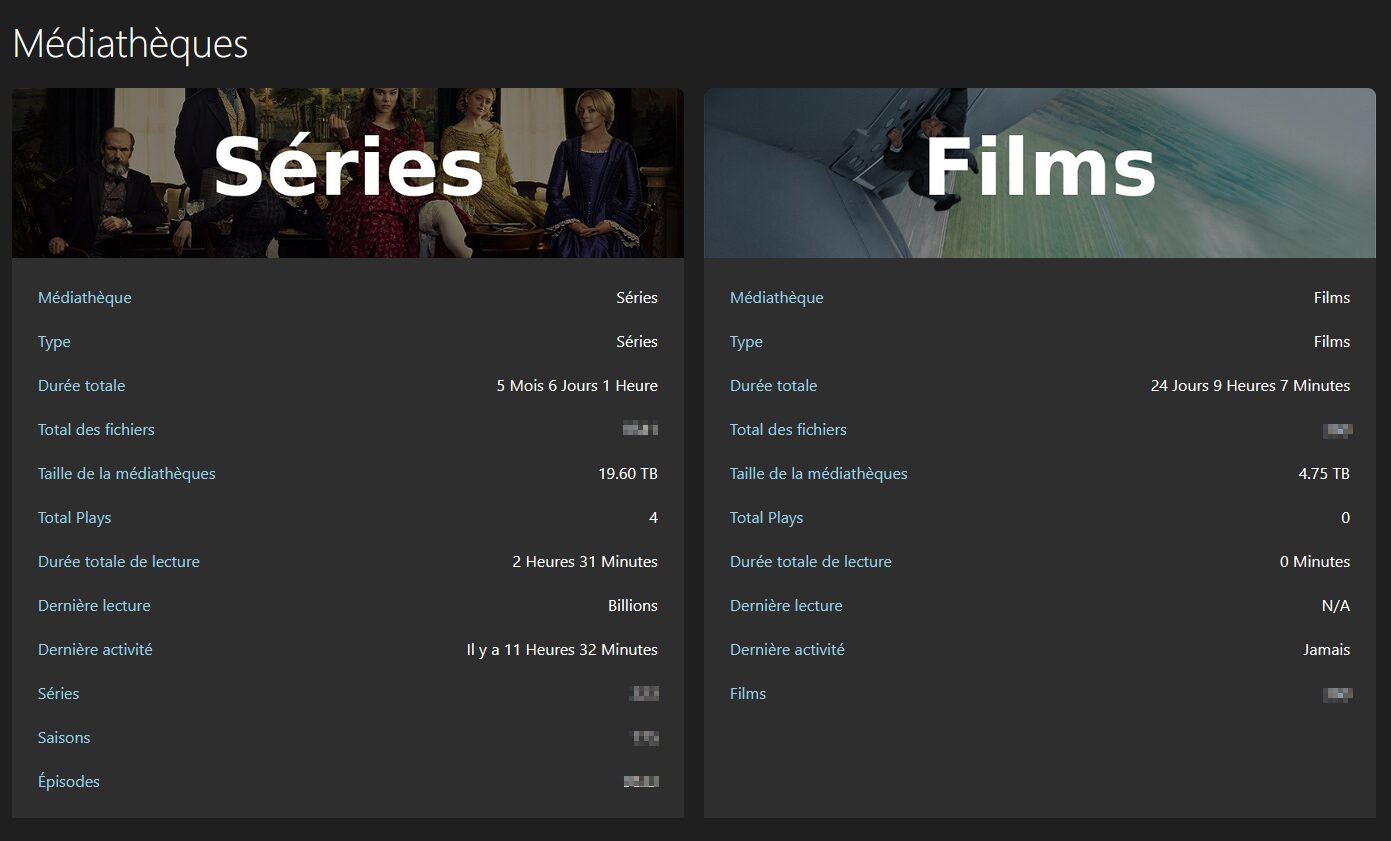
JellyStat de CyferShepard permet d’obtenir diverses statistiques de son serveur Jellyfin : taille des bibliothèques, contenus ajoutés, contenus lus, activité des utilisateurs… Mon serveur étant tout récent, mes screens révèlent très peu de stats pour l’instant ^^
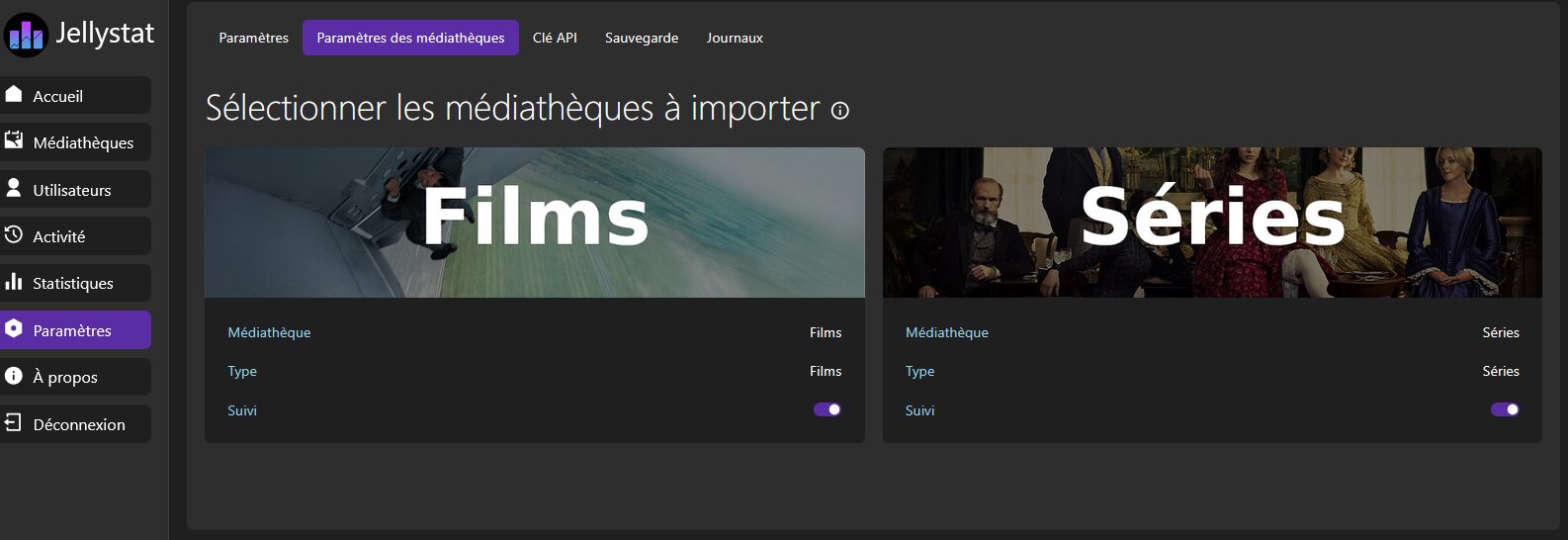
La recherche de Jellyfin fonctionne bien mais on peut la booster en termes de vitesse et de precision. Par exemple utile quand on commence à indexer des 100aines de To de contenus ou qu’on fait des fautes dans les noms de contenus, acteurs etc.
Meilisearch est un moteur de recherche ultra-rapide qui s’intègre sans effort dans des applications, sites Web et flux de travail.
Pour le coupler à Jellyfin il existe le projet JellySearch mais là je présente l’installation séparée de Meilisearch et l’utilisation du plugin d’arnesacnussem.
Pour commencer il faut installer Meilisearch. La master_key est une clé à définir soi-même.
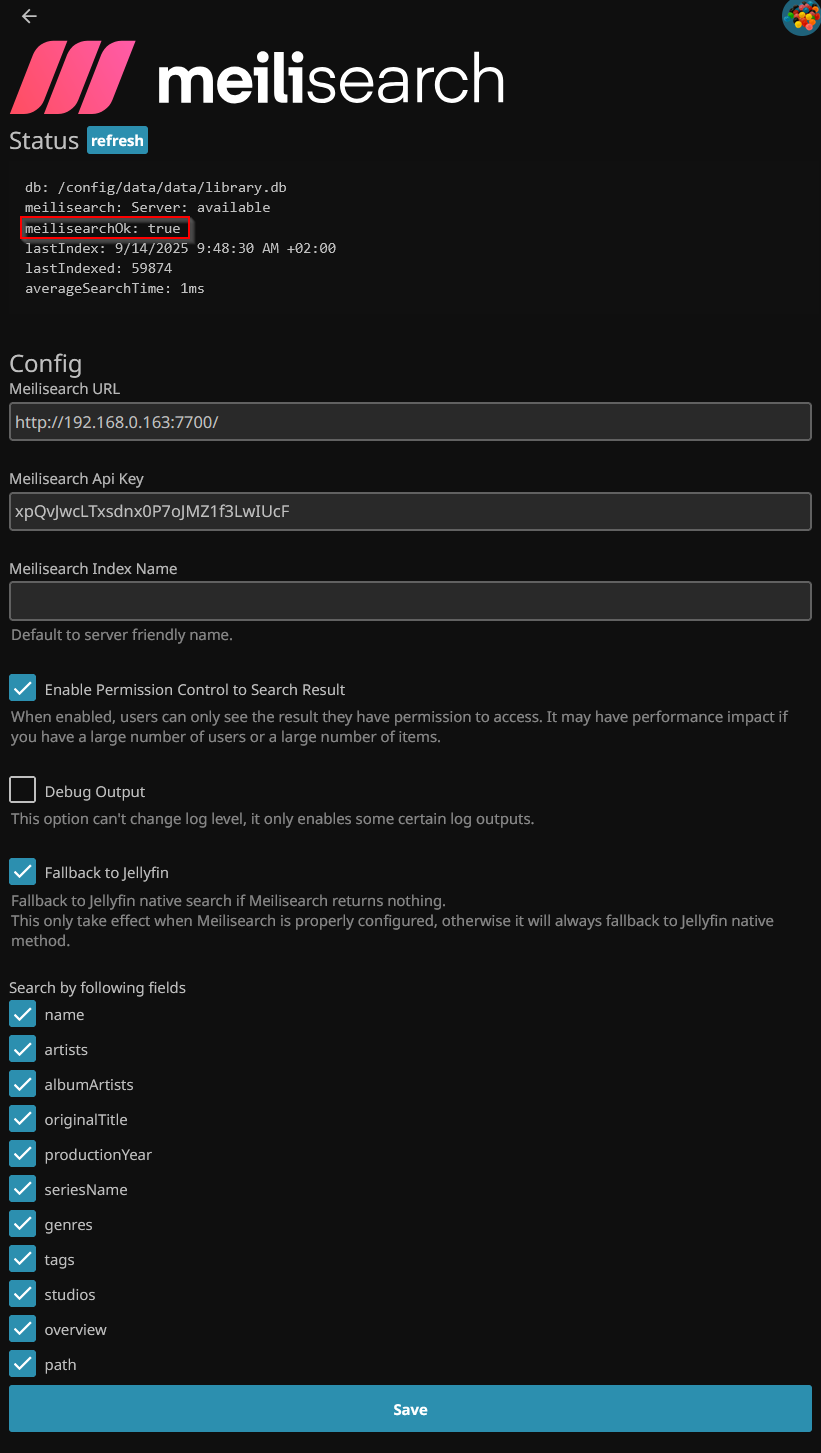
Après reboot on peut le configurer avec l’URL de Meilisearch, la master_key. Tout en haut, cliquer sur Connect et s’assurer que meilisearchOk passe bien en true, ce qui confirme la bonne connexion.
Et on utilise la recherche classique de Jellyfin, qui est plus complète et rapide.
Je zyeute MediUX depuis très longtemps mais le côté « Faut parcourir le site, télécharger le .zip, l’importer dans mon lecteur, l’appliquer » m’avait clairement rebuté dès les… 52 premières secondes.
L’équipe derrière MediUX propose l’outil Aura, encore en early stage donc on utilise tous une unique clé API de « test », qui permet de parcourir les sets liés à ses bibliothèques via une WebUI.
Ne reste qu’à choisir un set et l’appliquer de suite via un clic ou le prévoir pour une mise à jour automatique en cron. Et on peut en plus lui indiquer de surveiller les MàJ du set sélectionné pour les appliquer.
Si on peut l’intégrer à Kometa, en revanche pour Aphrodite il faut bien veiller à faire mouliner Aura puis ensuite Aphrodite pour les overlays. Comme vous le verrez plus bas, Aura se lance à minuit chaque jour alors qu’Aphrodite est lancé chaque heure. Au pire, il n’y a plus aucun overlay entre minuit et 1h du matin, « pas grave ».
Cet outil se destine aux amateurs de beaux visuels et de personnalisation. Malgré un maximum d’automatisation, rien ne pourra remplacer l’action de parcourir ses contenus et, pour chaque, de parcourir à leur tour les embellissements disponibles pour ensuite les appliquer.
Merci TiMac pour la belle découverte !
Compatibilité multi-serveurs : fonctionne avec Plex, Emby et Jellyfin.
Navigation visuelle : prévisualisez les visuels dans une interface claire et organisée.
Mises à jour automatiques : enregistrez les ensembles d’images choisis et gardez-les synchronisés automatiquement.
Stockage local : possibilité d’enregistrer les images à côté de vos fichiers multimédias pour un accès facile.
Support Docker : déploiement simple avec Docker ou docker-compose.
Le docker-compose est à récupérer localement et on peut l’éditer rapidement pour l’adapter
services:
aura:
image: ghcr.io/mediux-team/aura:latest
container_name: aura
restart: always
ports:
- 3064:3000 # Web UI PORT
- 8888:8888 # API PORT
volumes:
- /home/aerya/docker/aura:/config
- /mnt/Bibliothèques/:/data/media
labels:
- com.centurylinklabs.watchtower.enable=true
Avant de le lancer il convient de faire de même avec le fichier de configuration. Son remplissage est déterminant pour le fonctionnement d’Aura. Les paramètres ne sont en effet pour l’instant accessibles qu’en lecture seule via l’interface. Vous pouvez vous aider de la documentation mais c’est pas compliqué.
Voici le mien pour Jellyfin, avec 2 bibliothèques, SANS authentification (derrière Authelia chez moi), avec notifications Discord. Si vous voulez utiliser un mot de passe, il devra être hashé. Il faudra une clé API Jellyfin (ou un token Plex) et une clé API (pas le token) TMDB. Le cron servira pour la MàJ auto (si sélectionnée) des sets, on voit ça plus bas.
# Configuration Sample - aura
# For full documentation, see: https://mediux-team.github.io/AURA/config
# This file should be located in /config on the docker container
# Auth - Configuration for authentication
# This is used to configure the authentication for the application.
# Enable - Whether to enable authentication or not.
# Password - The Argon2id hashed password for the user.
Auth:
Enable: false
Password: $argon2id$v=19$m=12,t=3,p=1$Z3k1YnkwZzh5OTAwMDAwMA$lJDoyKZy1BMifB1Mb2SWFQ
# CacheImages - Whether to cache images or not. Caching images can improve performance but will use more disk space.
CacheImages: true
# SaveImageNextToContent - Whether to save images next to the Media Server content or not.
# If set to true, images will be saved in the same directory as the Media Server content.
# If set to false, images will still be updated on the Media Server but will not be saved next to the content.
# The benefit of this is that you have local images that are not dependent on the Media Server database in case of migration.
# If you are using Emby or Jellyfin, this option being set does not matter. This is determined by Emby or Jellyfin.
# If you are using Plex, this option will determine if the images are saved next to the content or not.
SaveImageNextToContent: false
# Logging - Configuration for logging
# Level - The level of logging. Can be one of: TRACE, DEBUG, INFO, WARNING, ERROR
Logging:
Level: DEBUG
# AutoDownload - Configuration for auto-downloading images
# Enabled - Whether to enable auto-downloading of images or not.
# You have the option when selecting a set to save it to the database.
# This will look for updates to the set and download them automatically.
# Cron - The cron schedule for auto-downloading images. This is a standard cron expression.
# For example, "0 0 * * *" means every day at midnight
AutoDownload:
Enabled: true
Cron: "0 0 * * *"
# Notifications - Configuration for notifications
# Enabled - Whether to enable notifications or not.
# Providers - A list of notification providers to use. Currently supported providers are:
# - Discord
# - Pushover
# You can set multiple providers at the same time. aura will send notifications to all. You also have the option to enable each provider. This gives you flexability to turn off the ones that you don't want to use.
# When provider is Discord, you must set the Webhook URL
# When provider is Pushover, you must set the Token and UserKey
# Sample:
# - Provider: "Pushover"
# Enabled: true
# Pushover:
# Token: your_pushover_token
# UserKey: your_pushover_user_key
# - Provider: "Discord"
# Enabled: true
# Discord:
# Webhook: your_discord_webhook_url
Notifications:
Enabled: true
Providers:
- Provider: "Discord"
Enabled: true
Discord:
Webhook: "https://canary.discord.com/api/webhooks/xxx"
- Provider: "Pushover"
Enabled: false
Pushover:
Token: your_pushover_api_token
UserKey: your_pushover_user_key
# MediaServer - Configuration for your Media Server
# Type - The type of Media Server. This can be one of: Plex, Jellyfin, Emby
# URL - The URL of the Media Server. This should be the IP:Port of the Media Server or your Media Server reverse proxy domain.
# Token - The token for the Media Server. This can be found in the Media Server web interface.
# Libraries - A list of libraries to scan for images. Each library should have the following fields:
# - Name: The name of the library to scan for content. Please note that this application will only work on Movies and Series libraries.
# SeasonNamingConvention - The season naming convention for Plex. This is a Plex exclusive requirement. This can be one of: 1 or 2. This will default to 2
# 1 - Season 1 (non-padded)
# 2 - Season 01 (padded)
MediaServer:
Type: "Jellyfin" # The type of Media Server. This can be one of: Plex, Jellyfin, Emby
URL: https://jelly.domaine.tld:443
Token: xxx
Libraries:
- Name: "Films"
- Name: "Séries"
# - Name: "4K Movies"
# - Name: "4K Series"
# SeasonNamingConvention: 1 # This is a Plex exclusive requirement. This is the season naming convention for Plex. This can be one of: 1 or 2
# Kometa - Configuration for Kometa
# RemoveLabels - Whether to remove labels or not. This will remove all specific labels from the Media Server Item.
# Labels - A list of labels to add to the Media Server Item. This will be used to identify the item in the Media Server.
# This is also a Plex exclusive requirement. This will only work on Plex.
Kometa:
RemoveLabels: false
Labels:
- "Overlay"
# TMDB - Configuration for TMDB (The Movie Database) This is not used yet.
# ApiKey - The API key for TMDB. This can be obtained by creating an account on TMDB and generating an API key.
TMDB:
ApiKey: xxx
# Mediux - Configuration for Mediux
# Token - The token for Mediux. This can be obtained by creating an account on Mediux and generating a static token.
# !!!! NOTE: This is not yet available to the public. It is currently in development and will be available in the future.
# If you would like to test this app, you will need a MedUX. You can contact us on Discord to get access.
# DownloadQuality: The quality of the images to download. Options are: "original" or "optimized"
Mediux:
Token: N_l1upAQrVJ05J6Fwjz89HEoo348l1u-
DownloadQuality: "optimized"
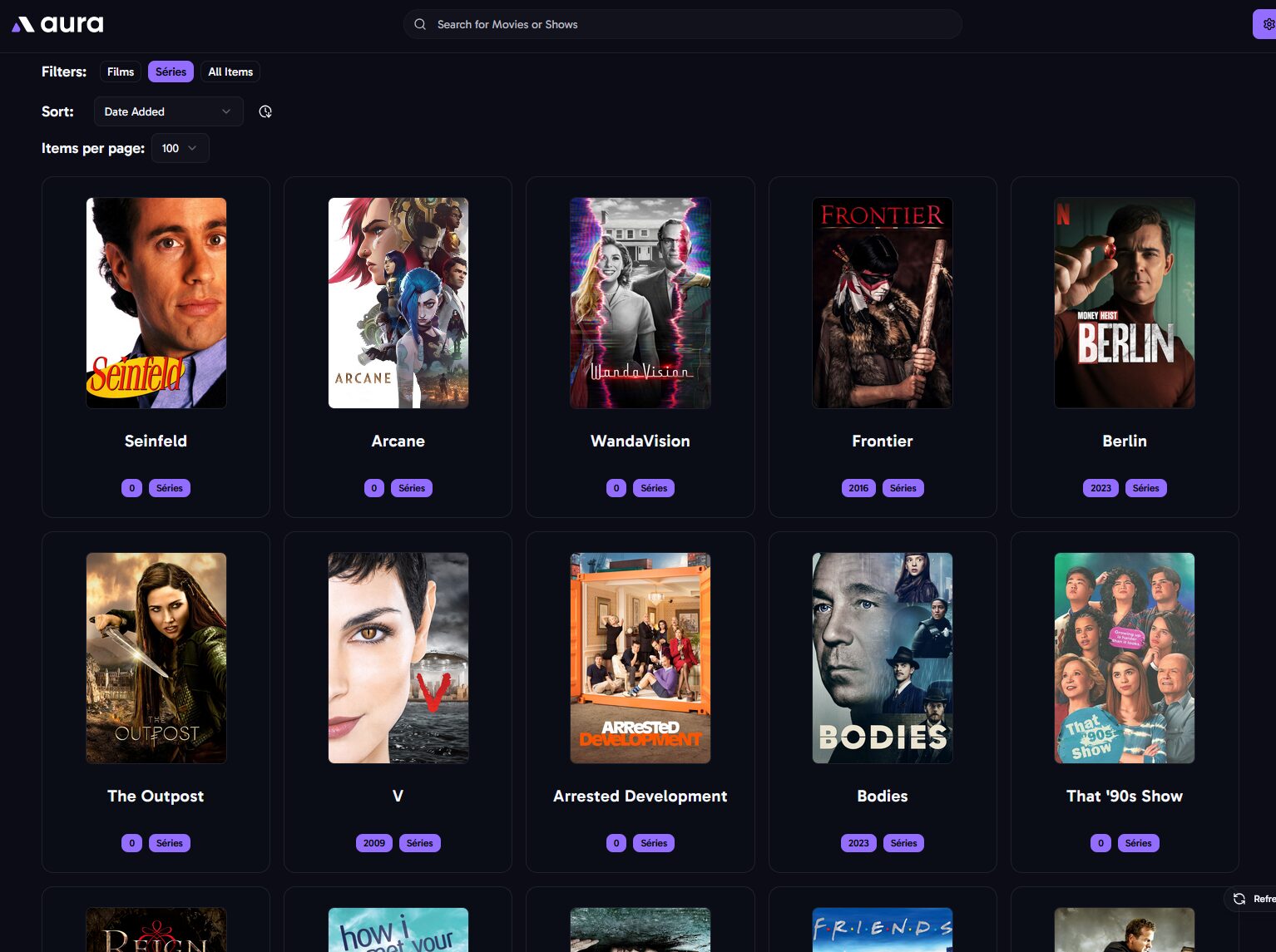
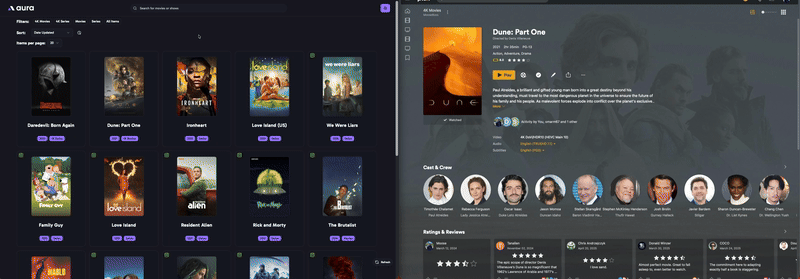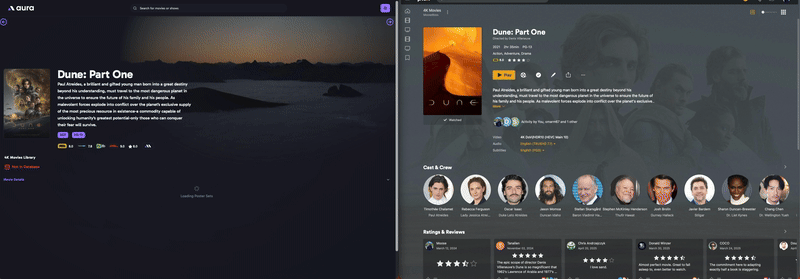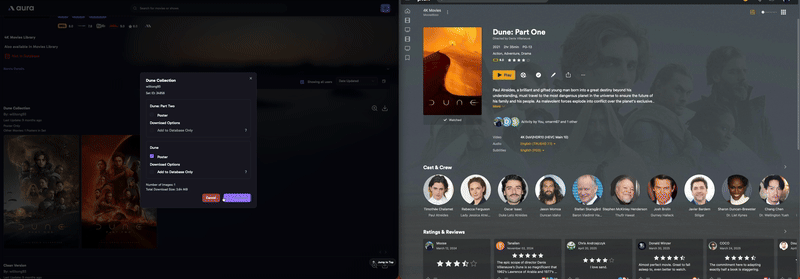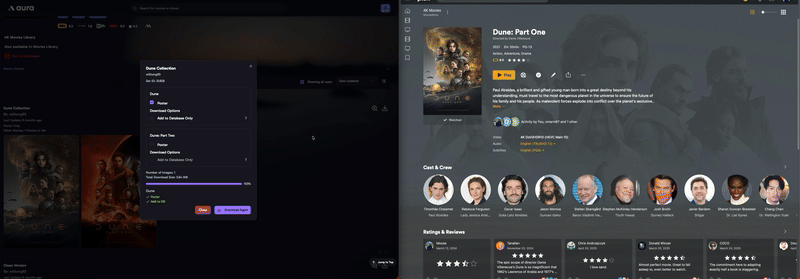
Une fois lancé ça indexe nos contenus globaux ou par bibliothèque, avec un minimum de tri. Et ça ffiche les posters actuels. Aphrodite n’est pas encore passé mettre des overlays.
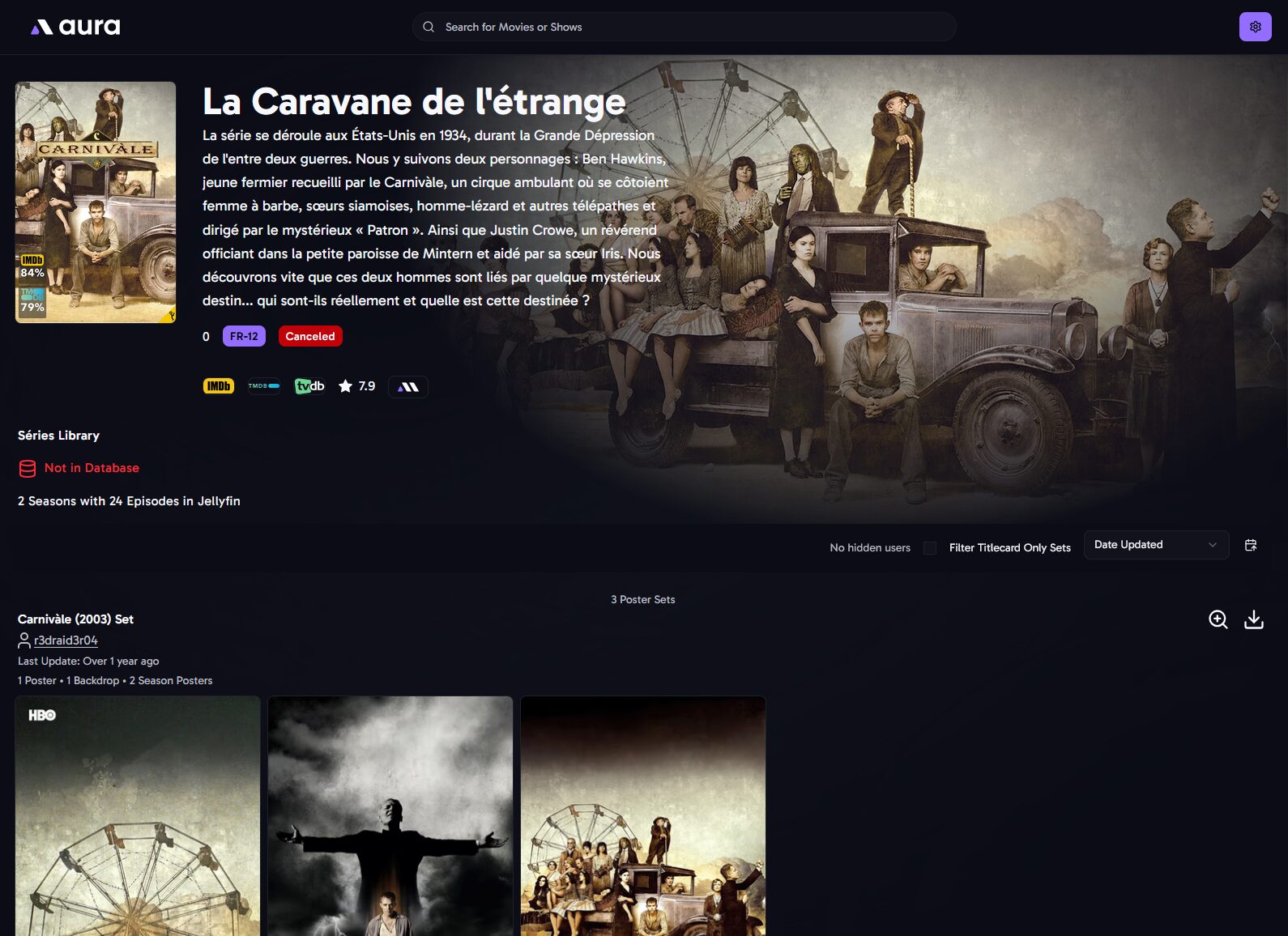
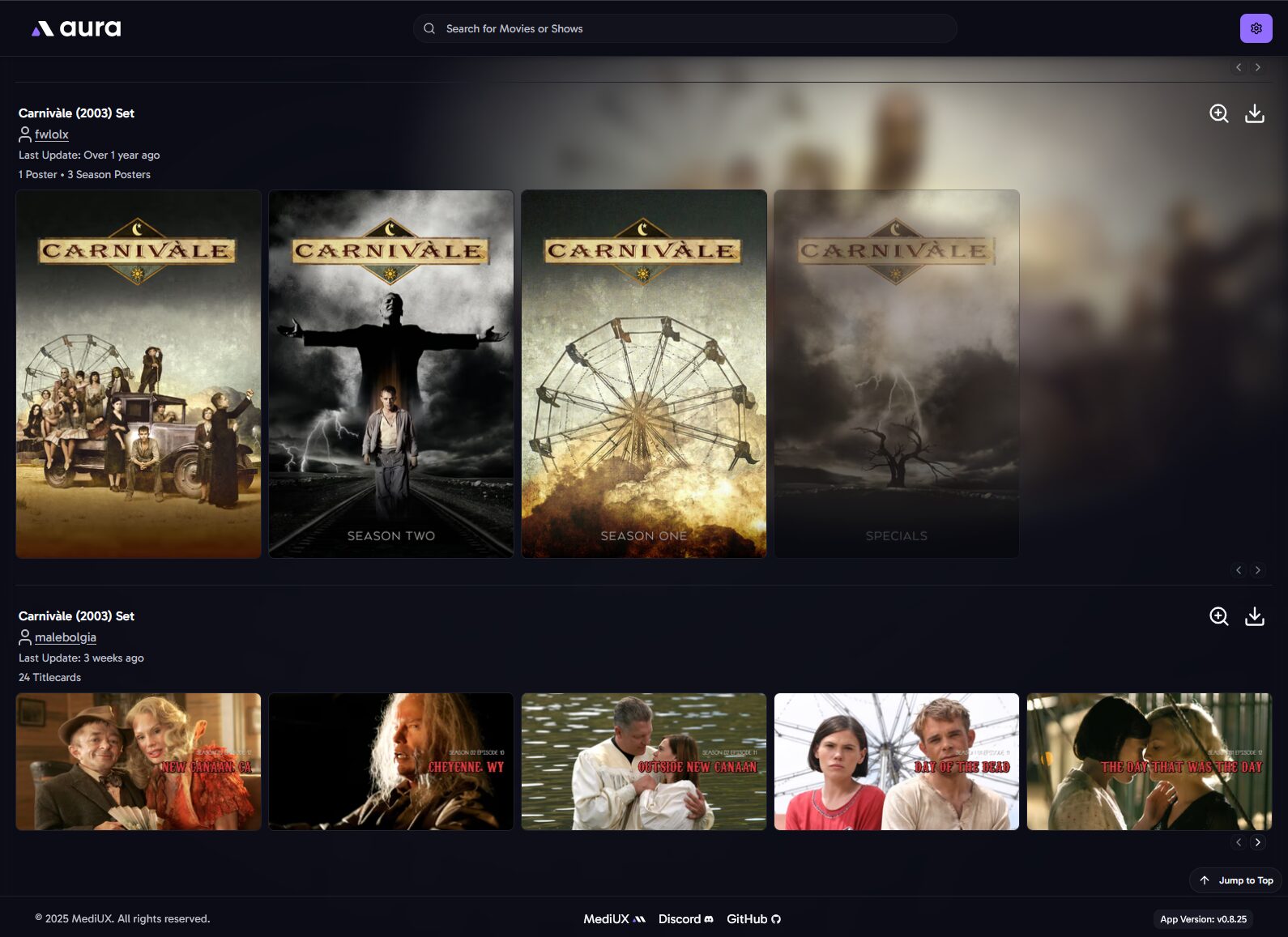
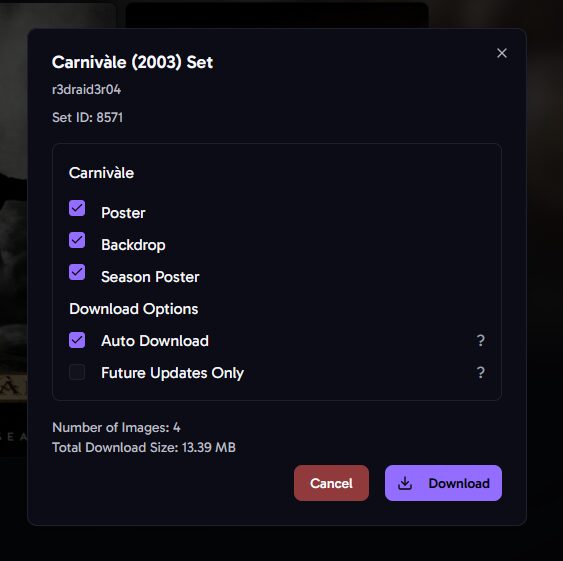
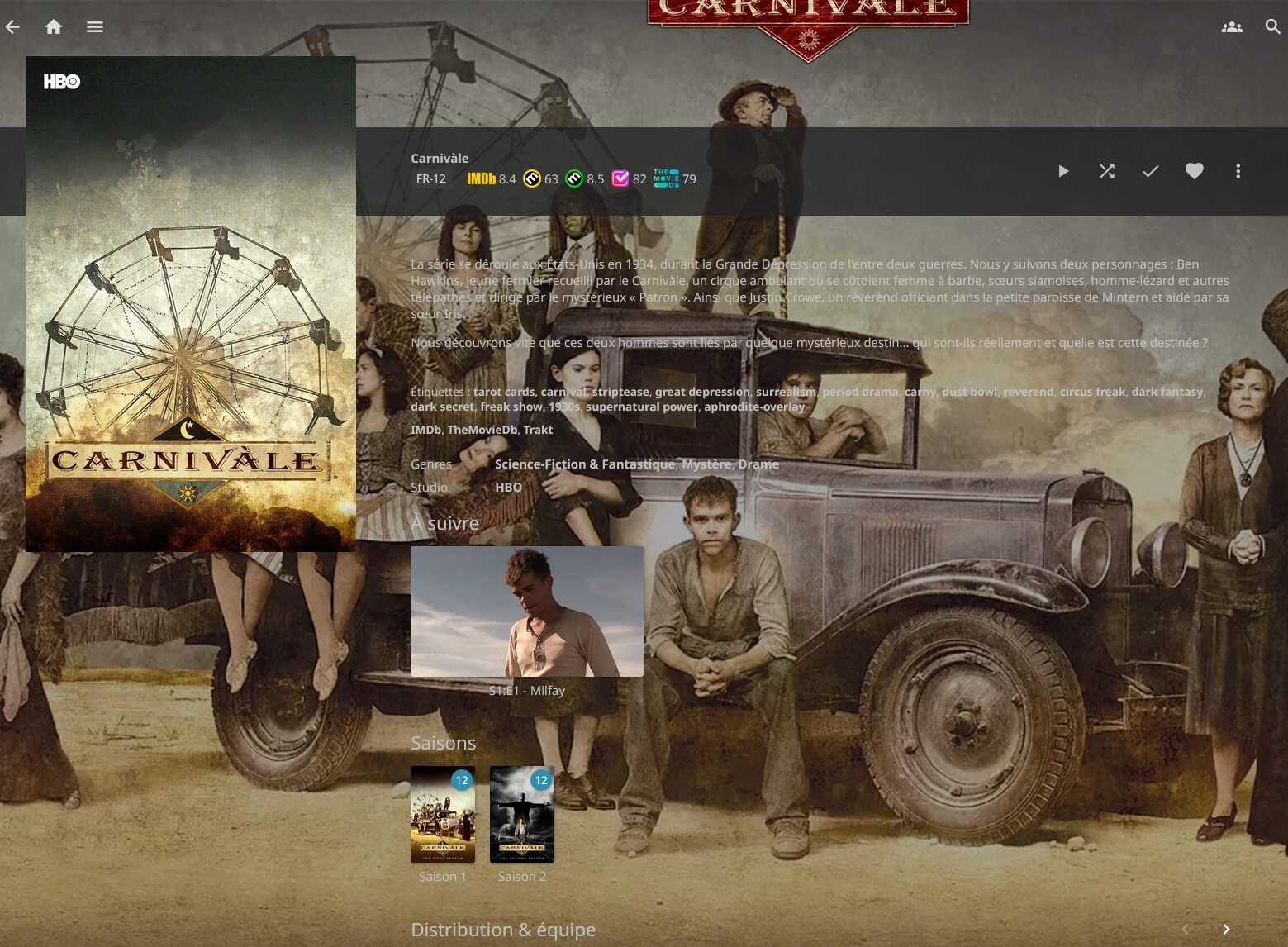
De là on peut sélectionner 1 film ou 1 série et parcourir les sets MediUX tout en visualisant le poster actuel. En l’occurrence, pour Carnivàle j’ai le choix entre 3 sets. C’est pas foufou MAIS des gens ont pris le temps de les réaliser et partager sur MediUX alors merci à eux.
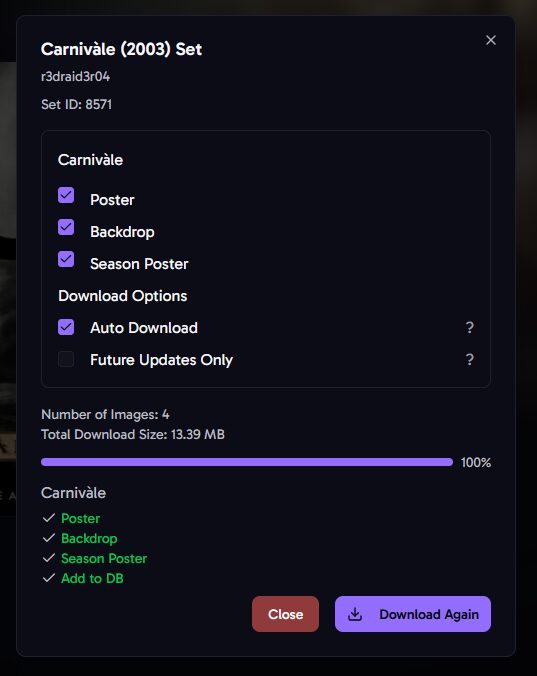
Aura indique si c’est ou non déjà en base de données
Tout est expliqué et détaillé dans la documentation (en anglais, mais on est en 2025, donc go les d’jeuns ! – je suis de 73- ).
La sélection d’un set de série offre plusieurs choix : – Poster : l’affiche de la série – Backdrop : l’image d’arrière plan si vous avez activé l’option dans Plex/.Jellyfin – Season poster : les affiches des saisons – Auto DL : vérifiera périodiquement les nouvelles mises à jour de cet ensemble. C’est utile si vous souhaitez télécharger et appliquer automatiquement les nouvelles titlecards ajoutées lors de futures mises à jour de cet ensemble. C’est à ça que cert le cron entré dans la configuration.
– Future updates ONLY : ne téléchargera rien pour le moment. C’est utile si vous avez déjà téléchargé l’ensemble et que vous souhaitez uniquement appliquer les mises à jour futures. Par exemple uniquement 1x par jour.
Notez qu’il n’y a pas toujours de backdrop de proposé.
Et je constate la mise à jour dans la foulée sur Jellyfin
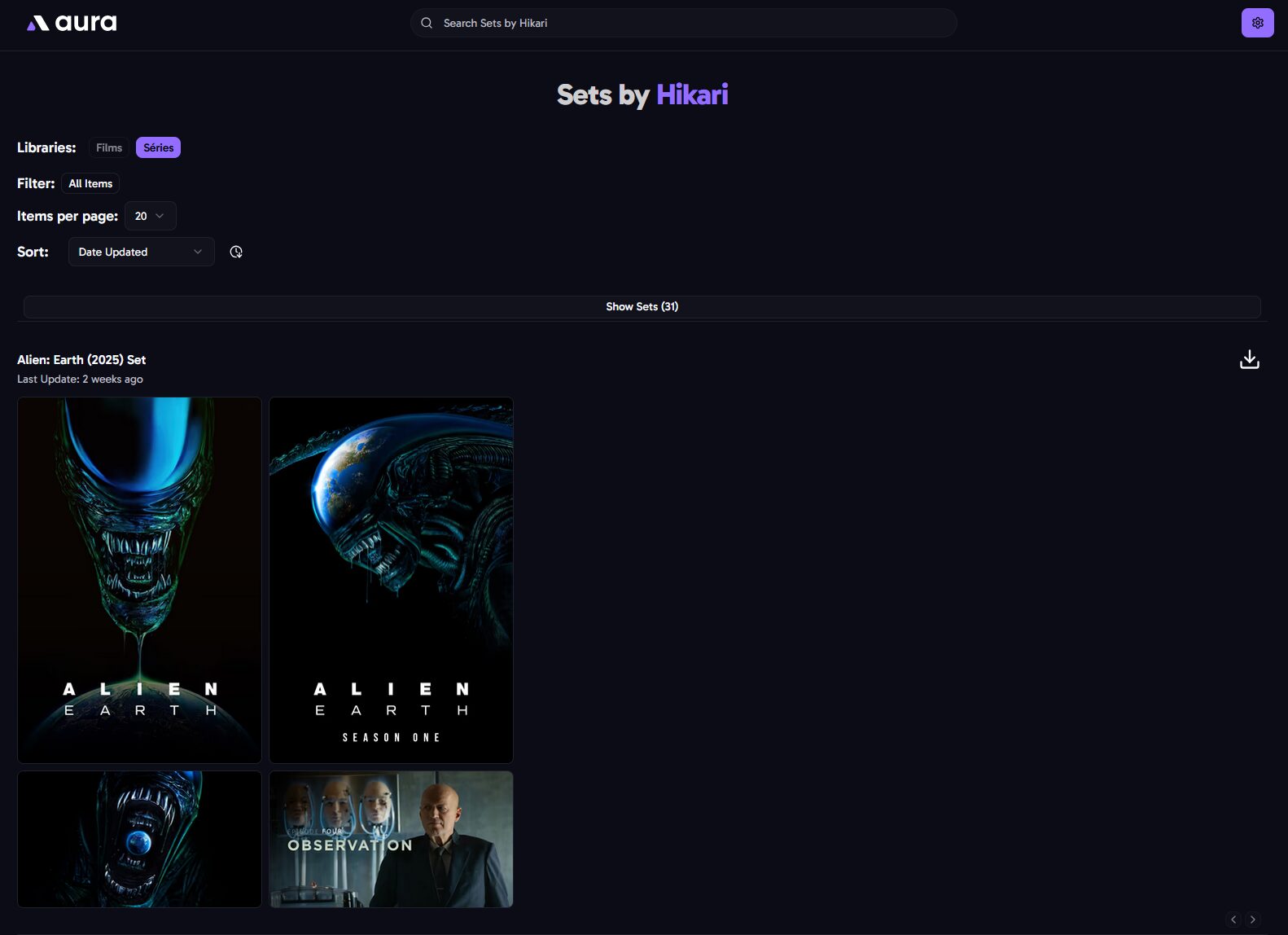
On peut parcourir les sets proposés par un utilisateur par rapport à nos contenus indexés par Aura, pratique si on apprécie son travail et qu’on veut en profiter pour d’autres séries ou films.
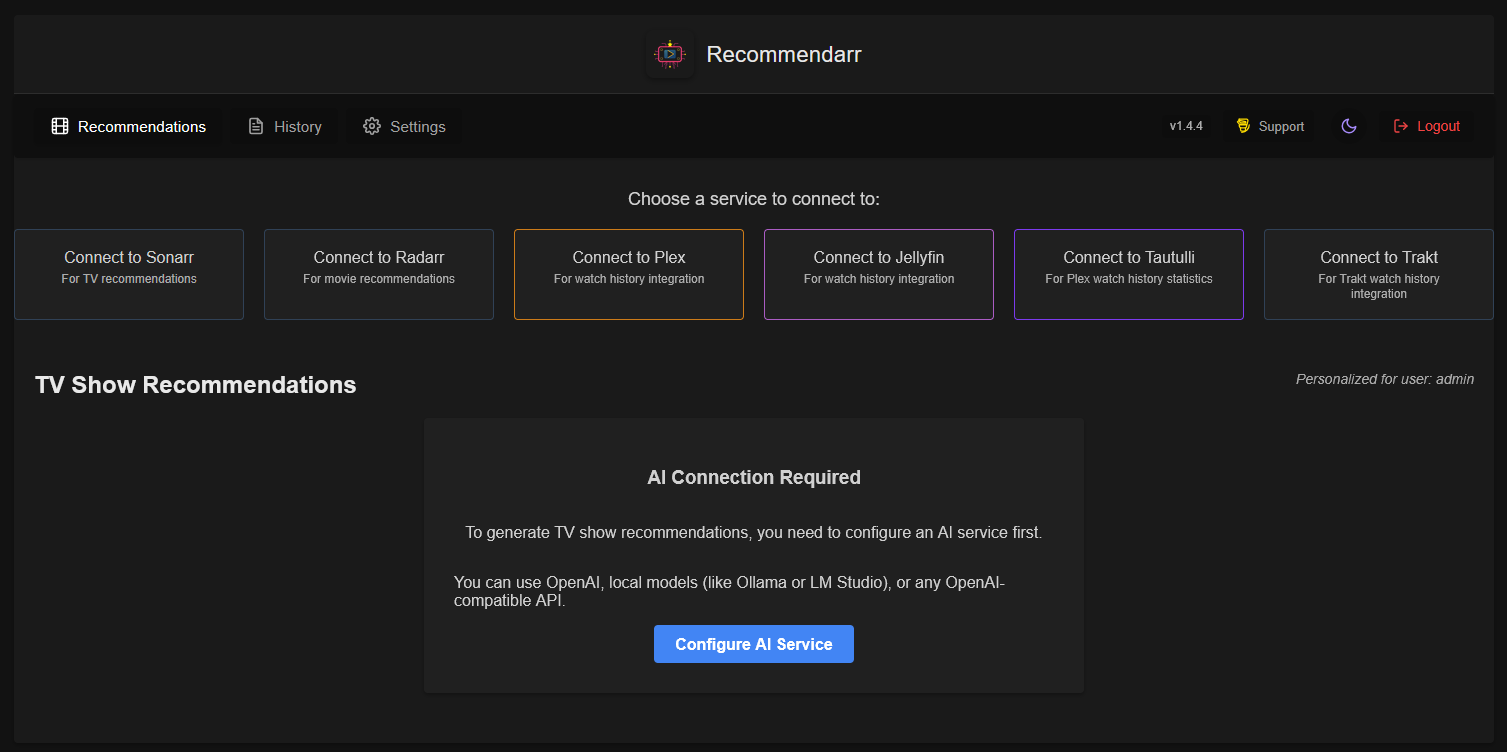
Ok, y’a déjà whatmille solutions de recommandations et découverte de contenus : les listes prises à droite à gauche et ajoutées aux arrs ou à ListSync, Overseerr/Jellyseerr, Suggestarr etc BAH EN VOICI UNE DE PLUS !
Recommendarr de fingerthief permet d’avoir des recommandations faites par une IA à partir des contenus vus sous Plex/Jellyfin, Trakt, Tautulli (eh non ! pas encore mort) et de ceux indexés par Radarr et Sonarr. Attention, tous les synopsis etc sont en anglais.
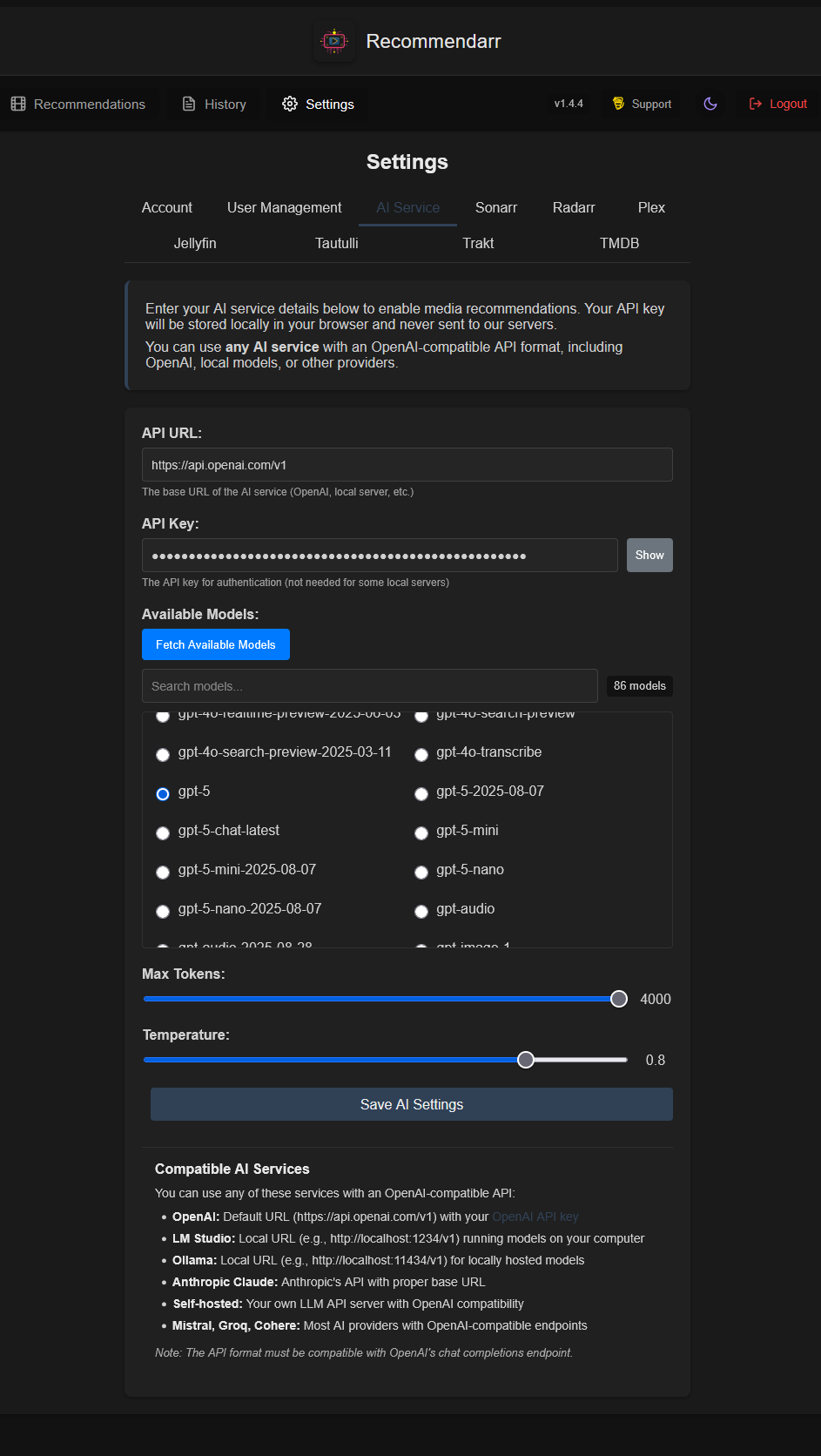
Quand je parle d’IA, c’est vaste et comprend l’autohébergé (j’ai testé avec OpenAI) :
Services d’IA compatibles
Vous pouvez utiliser n’importe lequel de ces services avec une API compatible OpenAI :
OpenAI : URL par défaut (https://api.openai.com/v1) avec votre clé API OpenAI
LM Studio : URL locale (ex. http://localhost:1234/v1) exécutant des modèles sur votre ordinateur
Ollama : URL locale (ex. http://localhost:11434/v1) pour des modèles hébergés en local
Anthropic Claude : API d’Anthropic avec l’URL de base appropriée
Auto-hébergé : votre propre serveur d’API LLM compatible avec OpenAI
Mistral, Groq, Cohere : la plupart des fournisseurs d’IA avec des endpoints compatibles OpenAI
Honnêtement, vu que je passe 90% de mon temps à tester des trucs plutôt qu’à profiter de mon setup, les recommandations que j’ai sont certes logiques (plus que celles de TMDB, en bas des fiches du moins) mais je ne sais pas si elles reflètent vraiment la qualité de cet outil. Ce dont je ne doute pas.
L’installation est simple puisque tout se configure via la WebUI
Et ensuite on peut connecter ses outils/comptes. Dans mon cas Trakt, TMDB, Jellyfin et Radarr/Sonarr. Je pense que ça venait de mon navigateur mais impossible d’accéder à la configuration en cliquant sur un autre bouton que Configure AI Service ou le menu des paramètres.
Pour l’IA j’ai utilisé mon compte OpenAI avec le modèle gpt-5-chat-latest (pas comme sur le screen). Choix complètement fait au pifomètre, je suis preneur de conseils.
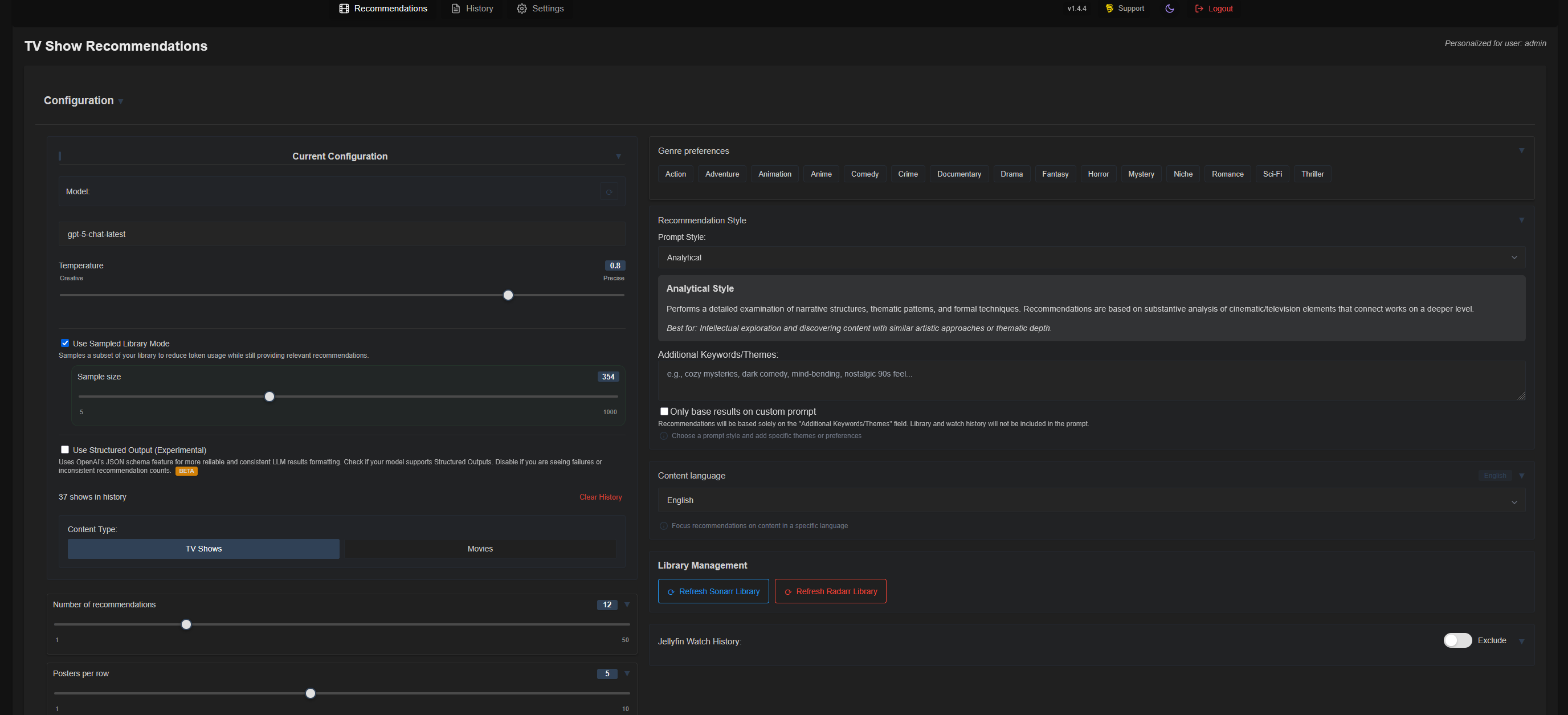
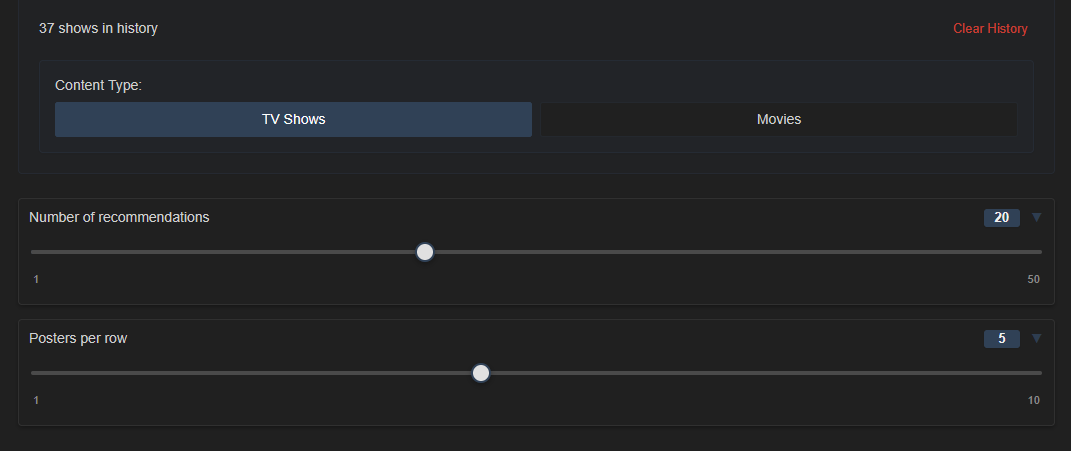
Et ensuite…. magie…. Ou presque. L’IA ne fera qu’aller chercher des contenus par rapport à notre demande. Il faut donc paramétrer la demande. Au moins le nombre de recommandations.
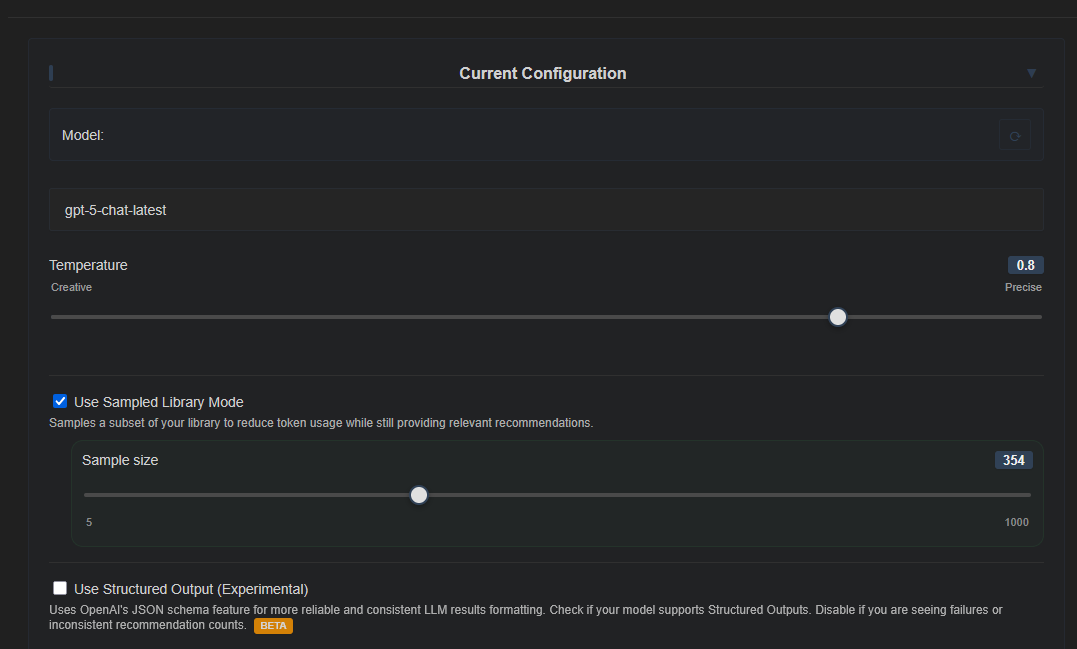
Dans la partie IA, en sus du modèle à choisir et son degré de précision, on peut demander à ce que Recommandarr utilise un sous-ensemble de la bibliothèque afin de réduire l’utilisation de jetons tout en fournissant des recommandations pertinentes.
On sélectionne la catégorie visée (films/séries) et le nombre de recommandations souhaitées.
Puis on peut affiner la recherche en sélectionnant des genres.
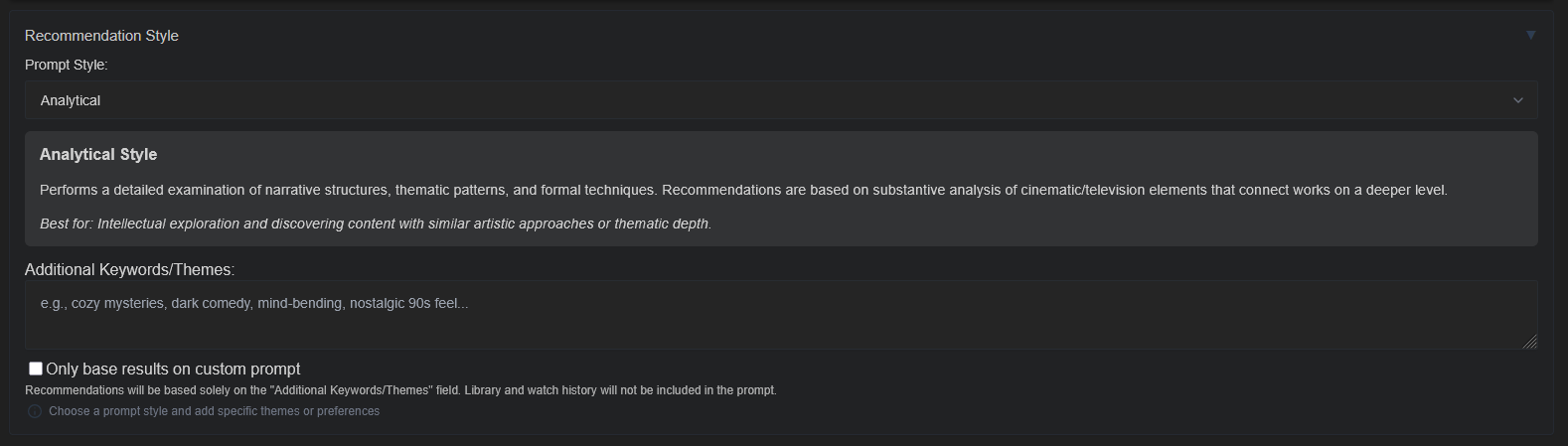
Puis sélectionner un prompt pré-défini ou en créer
Style « Vibe »
Se concentre sur l’atmosphère émotionnelle et l’expérience sensorielle du contenu de votre bibliothèque. Les recommandations privilégient la correspondance avec le ressenti et l’ambiance de vos films/séries préférés plutôt que le simple genre ou la similarité de l’intrigue. Idéal pour : Trouver du contenu qui évoque la même sensation, capturant des tons et atmosphères spécifiques.
Style analytique
Procède à une analyse détaillée des structures narratives, des motifs thématiques et des techniques formelles. Les recommandations reposent sur une analyse en profondeur des éléments cinématographiques et télévisuels qui relient les œuvres à un niveau plus substantiel. Idéal pour : Une exploration intellectuelle et la découverte de contenus partageant une approche artistique ou une profondeur thématique similaire.
Style créatif
Dépasse les catégorisations classiques pour trouver des liens inattendus entre les œuvres. Met en avant les parcours émotionnels, la vision artistique et les approches narratives originales. Idéal pour : Découvrir des recommandations surprenantes, qui peuvent sembler éloignées au premier abord mais partagent une même essence créative.
Style technique
Se focalise sur l’artisanat de la production, les techniques de réalisation et l’exécution technique. Analyse les méthodes de mise en scène, la cinématographie, les styles de montage et les éléments de production. Idéal pour : L’appréciation des aspects techniques et la recherche de contenus offrant une qualité de production ou une innovation technique similaire.
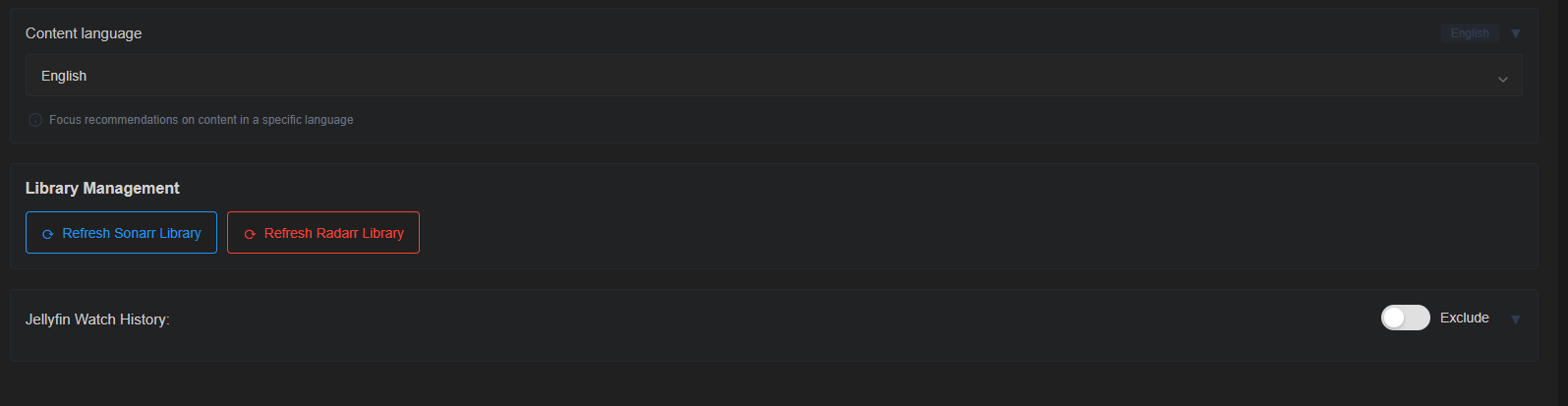
Comme souvent on peut sélectionner la langue préférée du contenu (séries plutôt en langue française etc). On pourra aussi de temps en temps rescanner les bibliothèques.
Et enfin, découvrir les reco. À noter qu’on ne peut pas les ajouter à Radarr/Sonarr directement, sans passer par Overseerr/Jellyseerr/whatever.
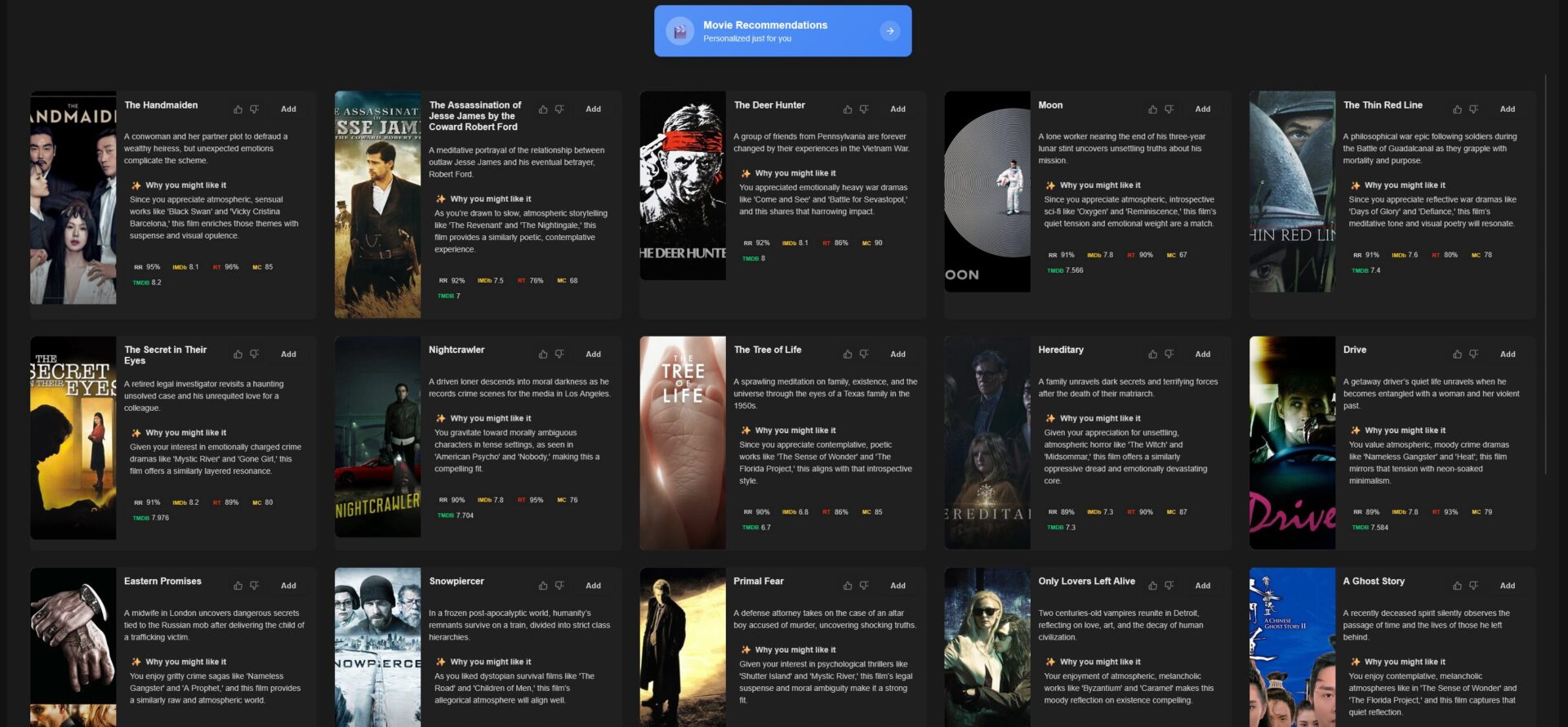
Voici par exemple pour les films
Évidemment, avec Decypharr, ça tombe en quelques secondes.
Et pour les séries, on peut évidemment sélectionner les saisons
C’est sympa à tester, on peut y créer plusieurs utilisateurs donc c’est intéressant mais avec un LLM autohébergé ça doit consommer pas mal de ressources. Avec OpenAI ça ne consomme en revanche rien que le serveur donc je vais le garder dans un coin mais je doute l’utiliser tous les jours, avec tout le reste…
L’idéal serait de couler ça à Overseerr/Jellyseerr…
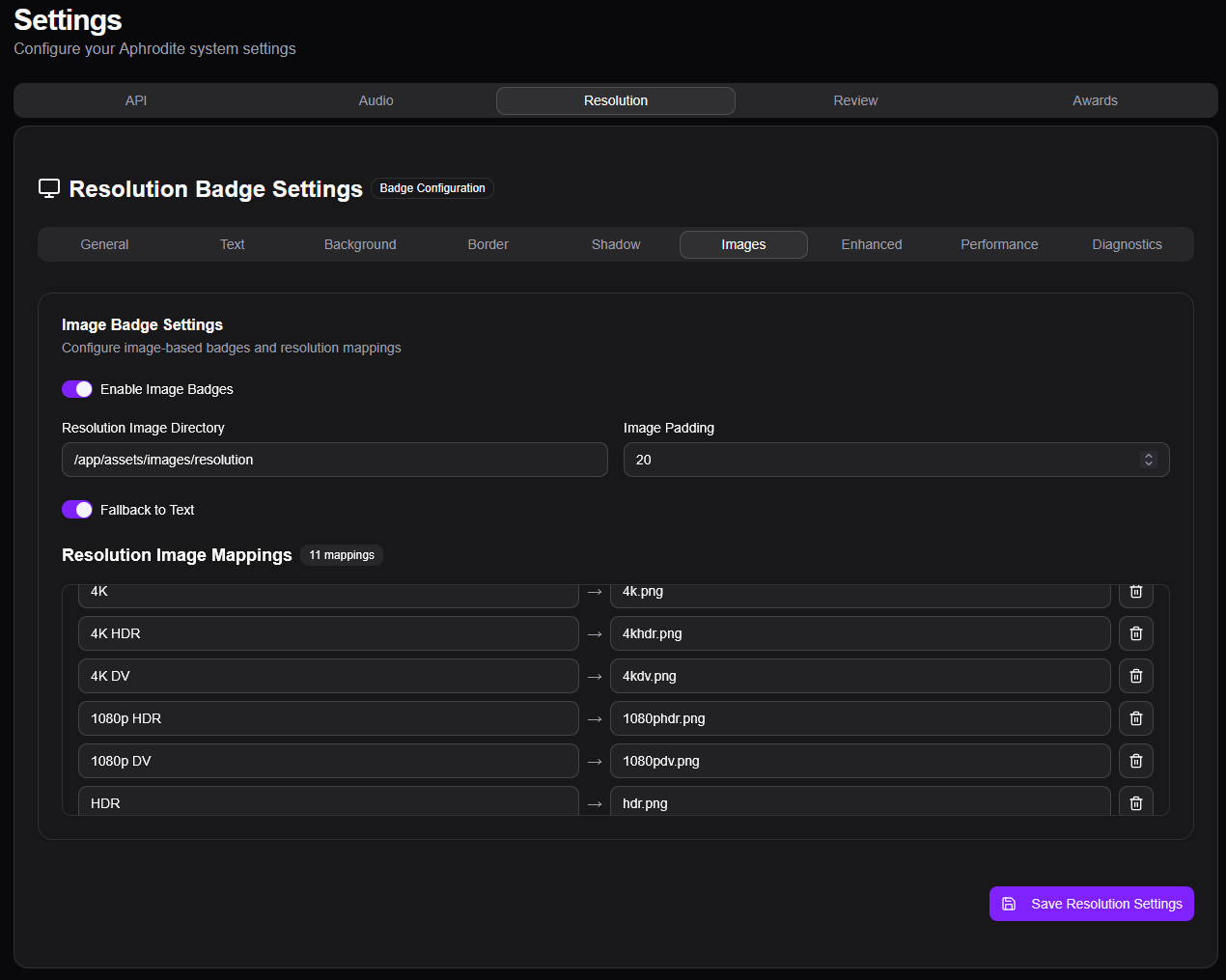
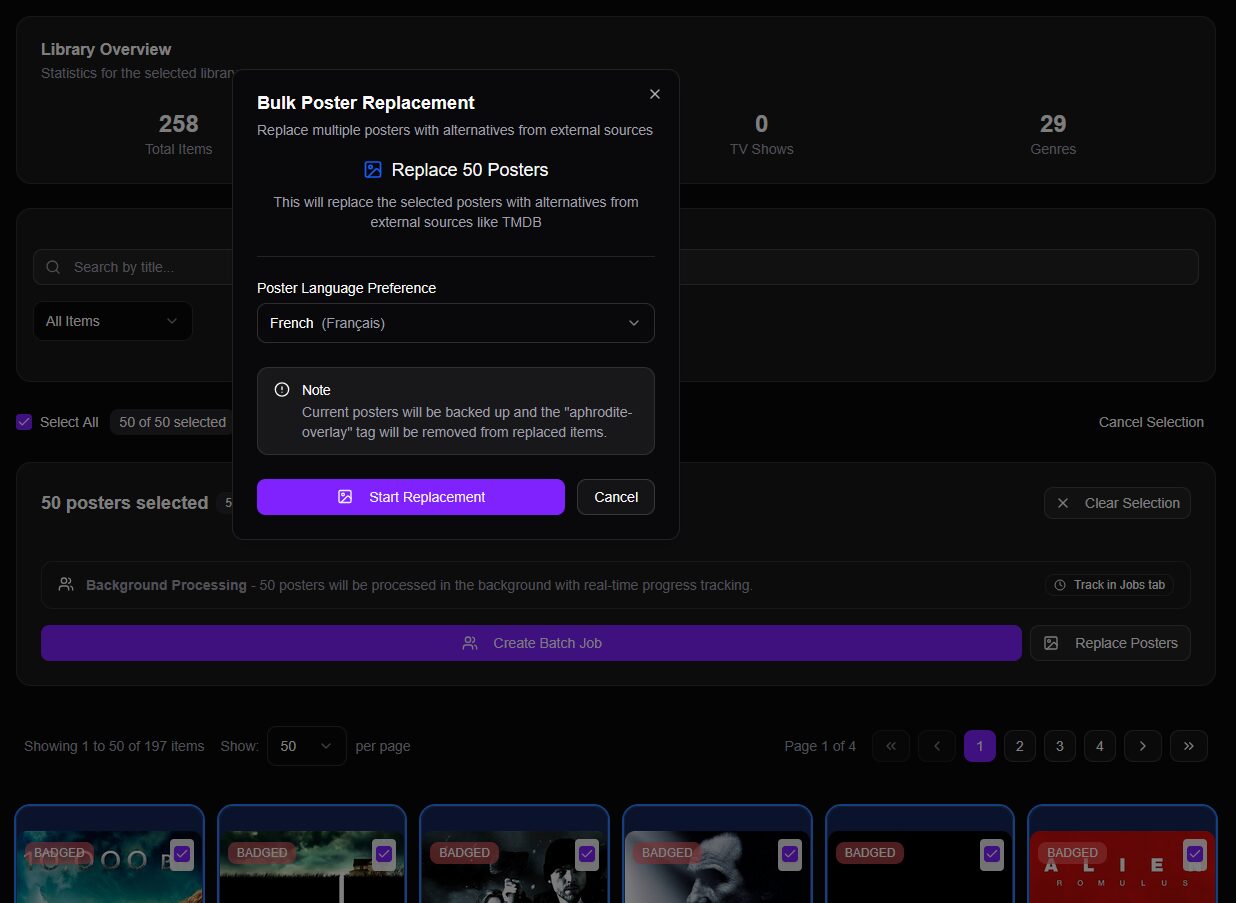
Pour nos bibliothèques Jellyfin on peut tout simplement changer les affiches (bases), configurer et ajouter tout ou au choix la résolution, l’audio, les notes et les récompenses.
Avec la totale, ça peut donner ceci.
Ça ne fonctionne évidemment pas sur les affiches des collections vu que ces badges concernent une vidéo donnée.
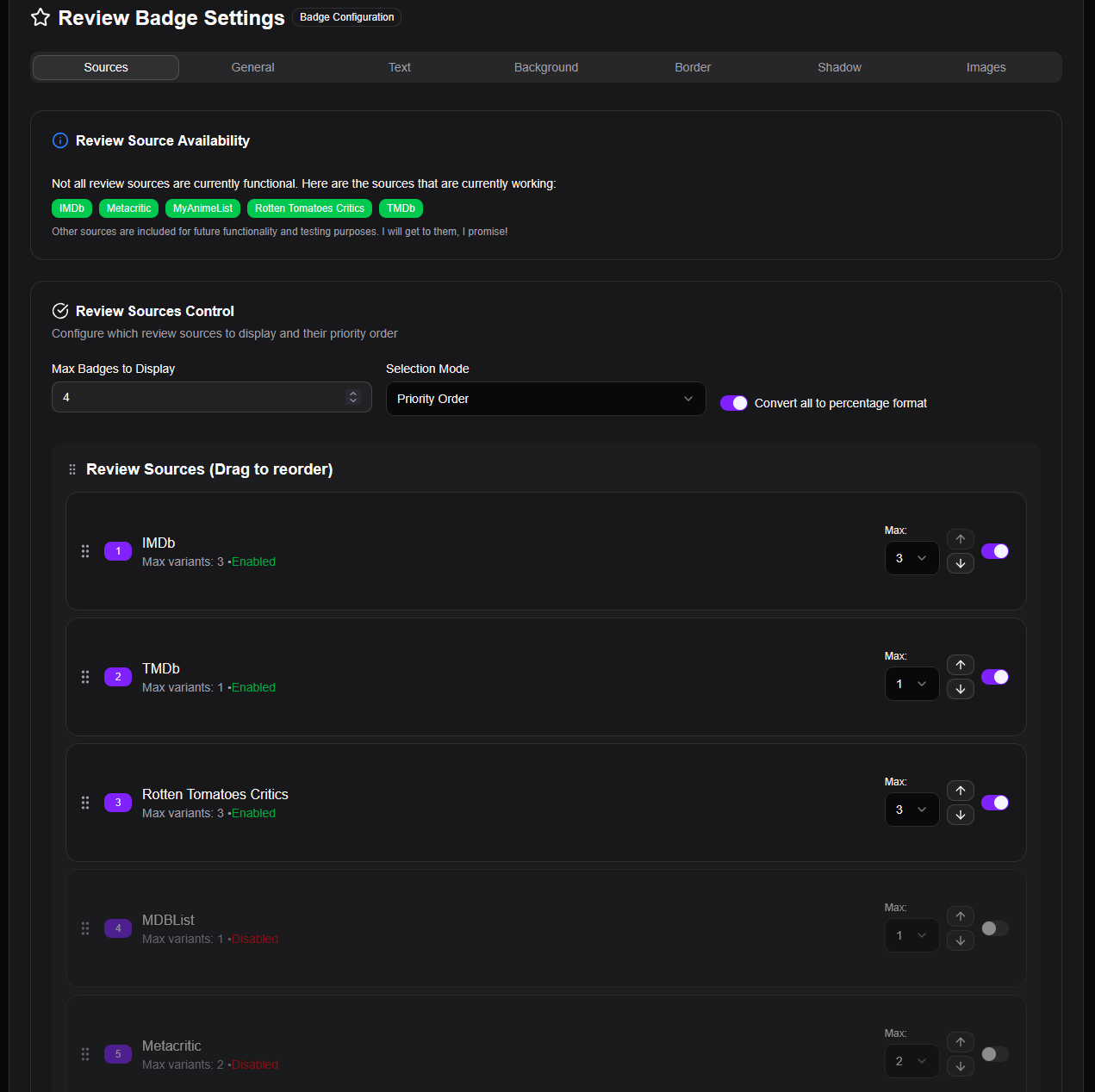
Pour répondre à nos besoins, sommaires vu que je connais mes règles Radarr/Sonarr, je n’affiche que les notes et récompenses.
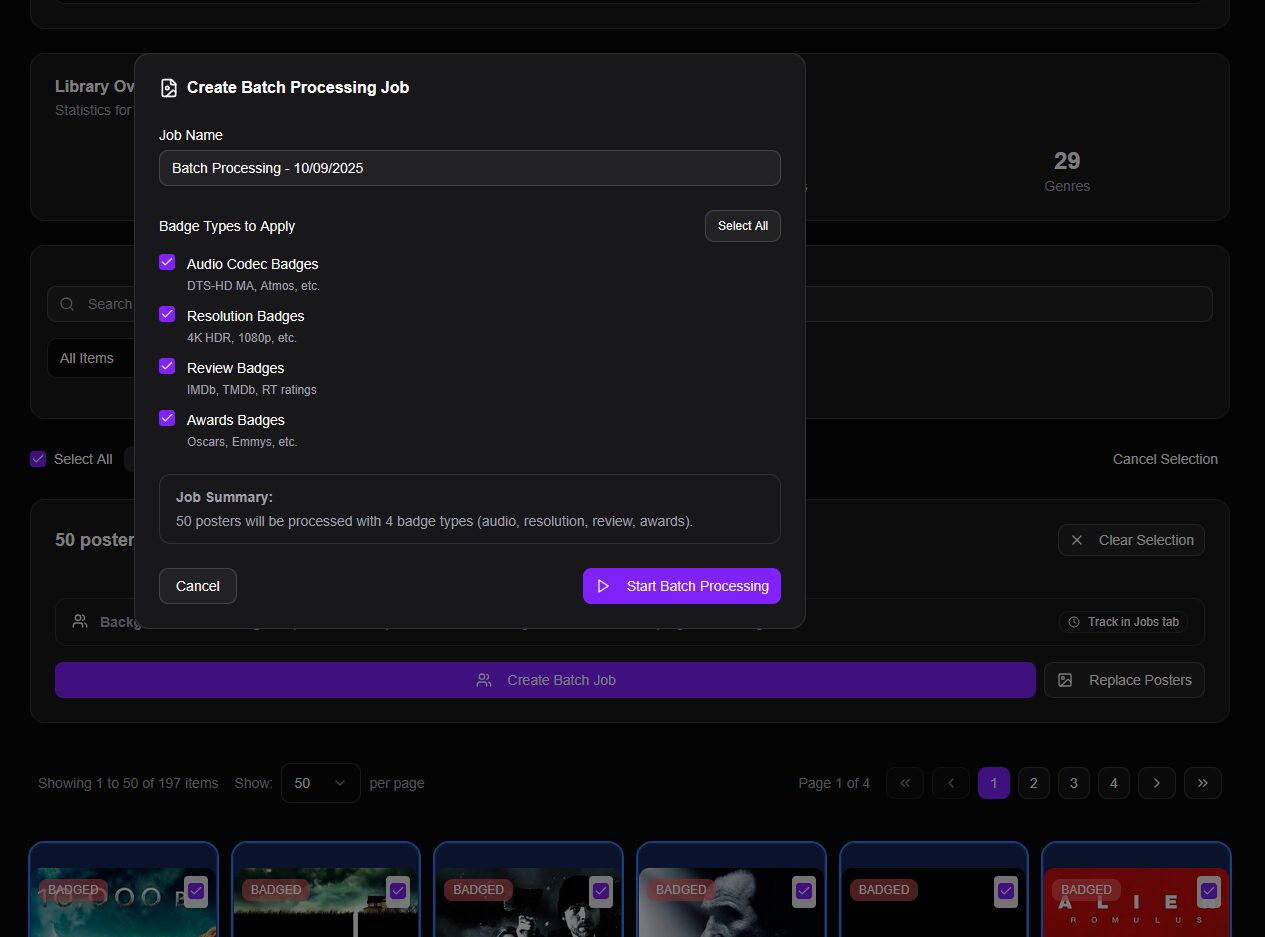
Via la WebUI on peut planifier des opérations (cron) pour appliquer tout ou partie des badges sur les bibliothèques sélectionnées. En reprenant ou non les éléments déjà traités. En revanche, pour la modification des affiches, c’est à faire manuellement, par grappes de 50 (ouais, léger…).
L’installation est relativement simple, j’ai cependant rencontré pas mal de soucis en ne configurant que via la WebUI pour Jellyfin. J’ai tout décommenté/renseigné dans le .env et ça roule.
Comme indiqué sur le GitHub, il faut télécharger le compose et son .env. Je mets ça dans /home/aerya/docker/aphrodite
# Créer le dossier entrer dedans
mkdir /home/aerya/docker/aphrodite && cd /home/aerya/docker/aphrodite
# Télécharger le docker-compose et le .env
curl -L https://github.com/jackkerouac/aphrodite/releases/latest/download/docker-compose.yml -o docker-compose.yml
curl -L https://github.com/jackkerouac/aphrodite/releases/latest/download/default.env.example -o .env
Et on passe à l’édition du compose. Par rapport au compose de base, j’ai juste modifié les volumes sur la base de /home/aerya/docker/aphrodite/…
Mis en always pour « restart » et ajouté la MàJ auto d’Aphrodite avec watchtower. Pas la peine pour Postgre et Redis vu que ça va chercher des versions précises. Tout le reste se modifie dans .env qui suit
Et le fameux .env. Comme expliqué plus haut, après plusieurs tests, il faut y paramétrer le serveur Jellyfin et également décommenter les informations liées à Postgre et Redis. J’ai passé les logs en DEBUG vu les soucis que je rencontrais au début.
Pour créer la SECRET_KEY : (en console) openssl rand -hex 64
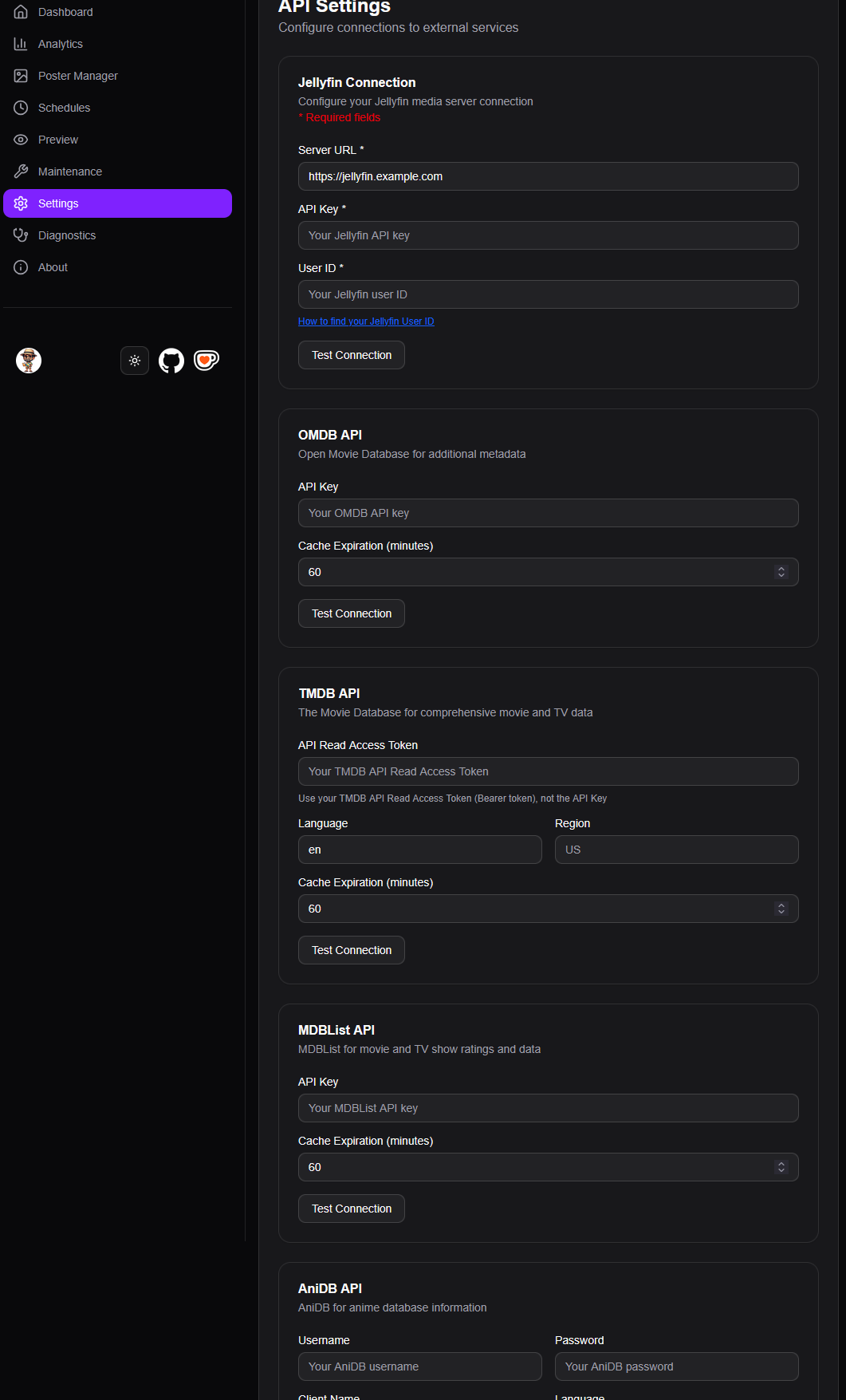
Et ne pas oublier de mettre le mot de passe POSTGRES_PASSWORD dans la partie DATABASE_URL Créer une clé API dans Jellyfin via le menu tout en bas du Tableau de bord
Et récupérer l’ID utilisateur qui sera utilisée pour connecter Aphrodite. Dans Tableau de bord/Utilisateurs, cliquer sur le user et l’ID est à la fin de l’URL
# =============================================================================
# Docker Image Configuration
# =============================================================================
# Leave blank to always pull the latest version from GitHub Container Registry
# APHRODITE_IMAGE=ghcr.io/jackkerouac/aphrodite:latest
# =============================================================================
# Database Configuration
# =============================================================================
# IMPORTANT: Change POSTGRES_PASSWORD to a secure password!
# This password will be used to create the database user
POSTGRES_DB=aphrodite
POSTGRES_USER=aphrodite
POSTGRES_PASSWORD=motdepassedelamortquitue
POSTGRES_PORT=5432
# =============================================================================
# Redis Configuration
# =============================================================================
REDIS_PORT=6379
# =============================================================================
# Security Configuration (REQUIRED)
# =============================================================================
SECRET_KEY=4c887cda6e10bac46eb61a961e38f4626609c9caeca08123ed1d6d876c6b14c20a11118cec534f26d5d5de4f5b6935fa07ff8887b91322058c20f95705025fa0
# =============================================================================
# Application Configuration
# =============================================================================
# Port to run Aphrodite on (default: 8000)
APHRODITE_PORT=8000
# API Configuration
API_HOST=0.0.0.0
API_PORT=8000
# Environment
ENVIRONMENT=production
# Logging level (debug, info, warning, error)
LOG_LEVEL=debug
DEBUG=true
# Network Configuration
ALLOWED_HOSTS=*
CORS_ORIGINS=*
# =============================================================================
# Background Jobs Configuration
# =============================================================================
ENABLE_BACKGROUND_JOBS=true
CELERY_BROKER_URL=redis://redis:6379/0
CELERY_RESULT_BACKEND=redis://redis:6379/1
# =============================================================================
# Database & Redis URLs (Advanced - Override defaults if needed)
# =============================================================================
DATABASE_URL=postgresql+asyncpg://aphrodite:motdepassedelamortquitue@postgres:5432/aphrodite
REDIS_URL=redis://redis:6379/0
# =============================================================================
# Jellyfin Integration (Optional - Configure via Web Interface)
# =============================================================================
# You can set these here or configure them in the web interface
JELLYFIN_URL=https://jelly.domaine.tld
JELLYFIN_API_KEY=xxx
JELLYFIN_USER_ID=xxx
On peut ensuite lancer la Docker et aller visiter les paramètres d’Aphrodite. Mon screen date de ma 1ère installation aussi je ne sais plus si les paramètres de Jellyfin sont déjà remplis par le biais du .env
Il faut aller récupérer (ou créer) ses clés API : – OMDB : version gratuite, clé dans le mail qu’on reçoit suite à l’inscription – TMDB : le token, pas la clé – MDBList : en bas de page – AniDB si vous avez des mangas : j’ai pas regardé plus que ça pour créer une clé API
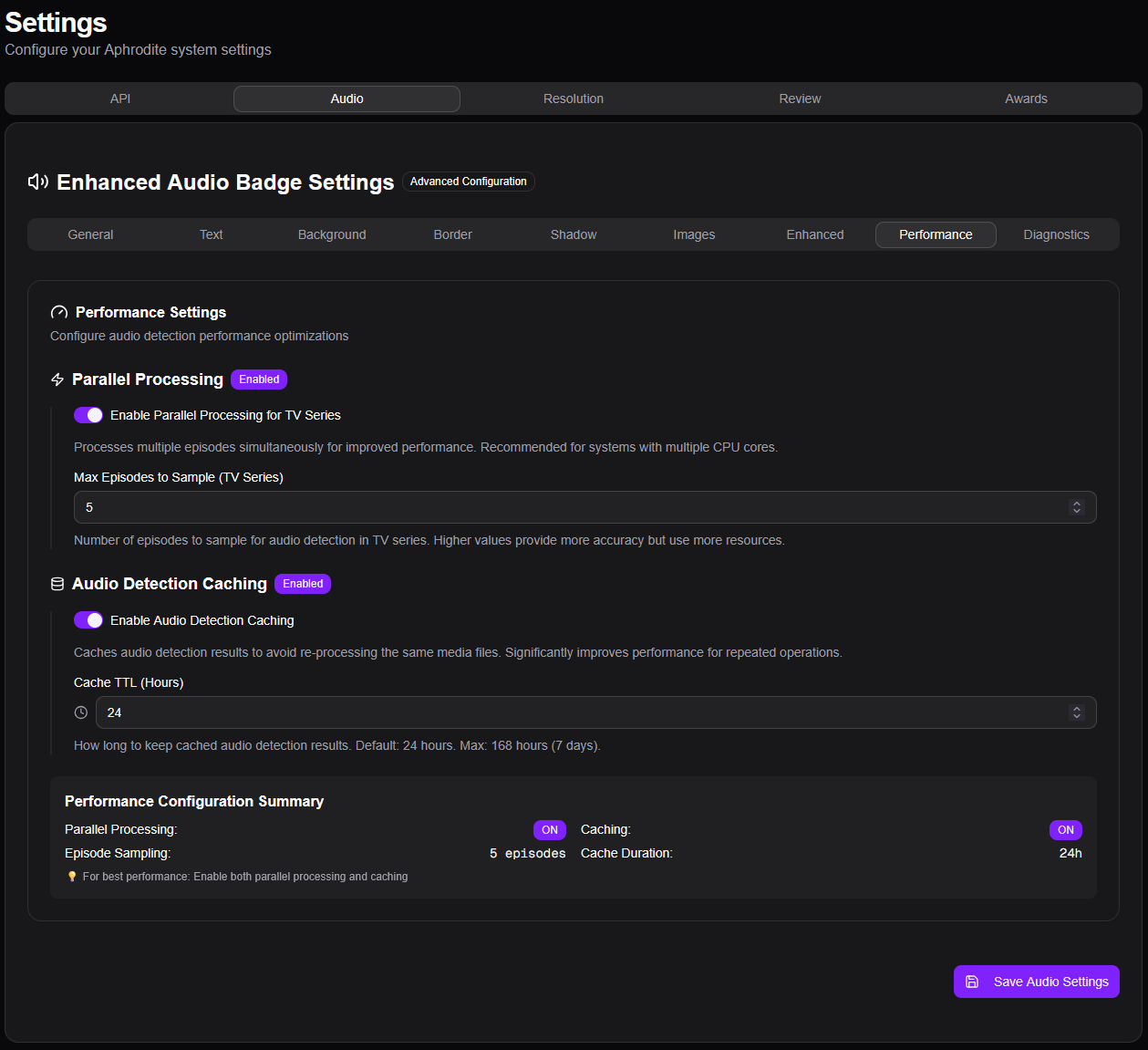
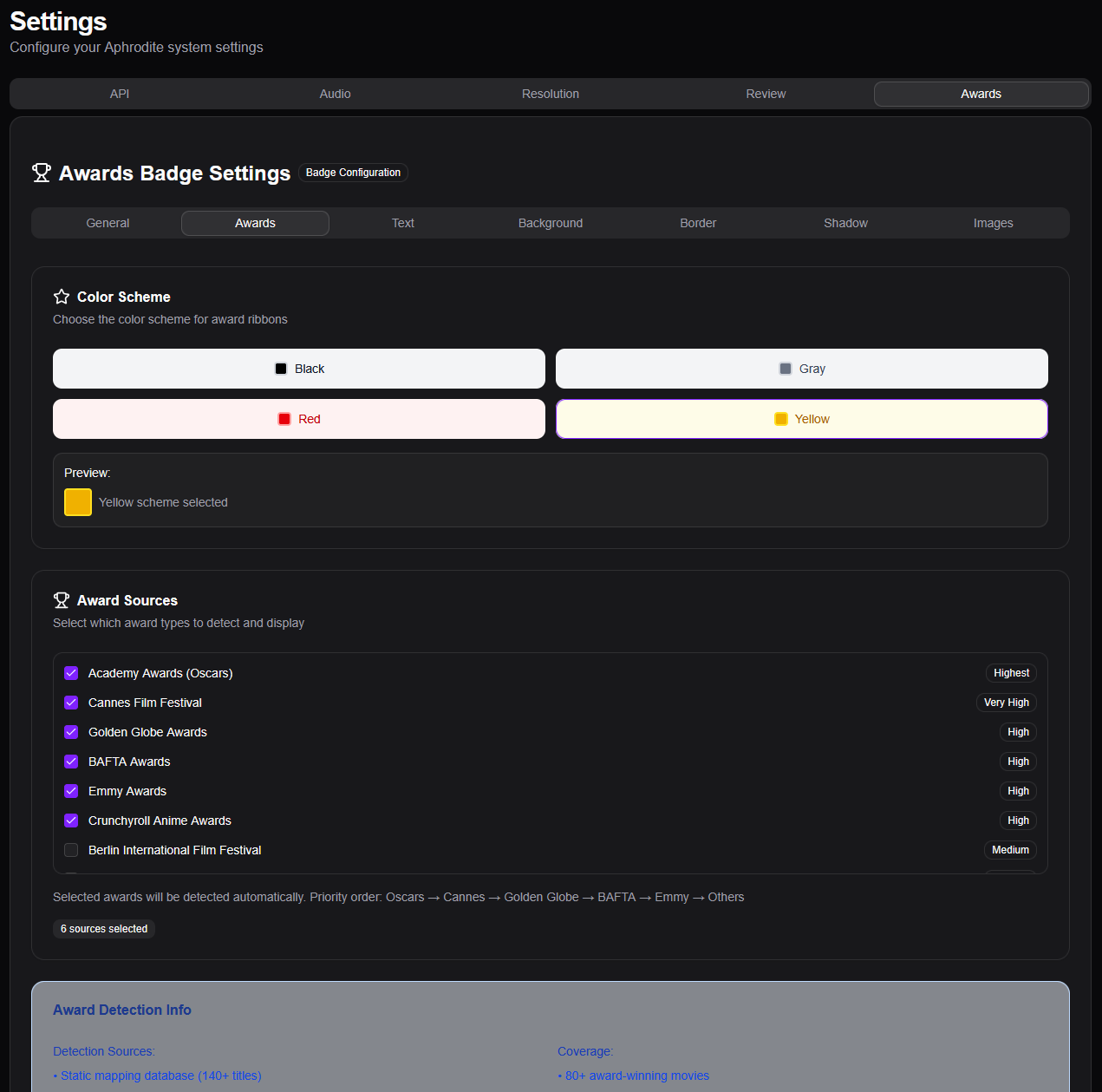
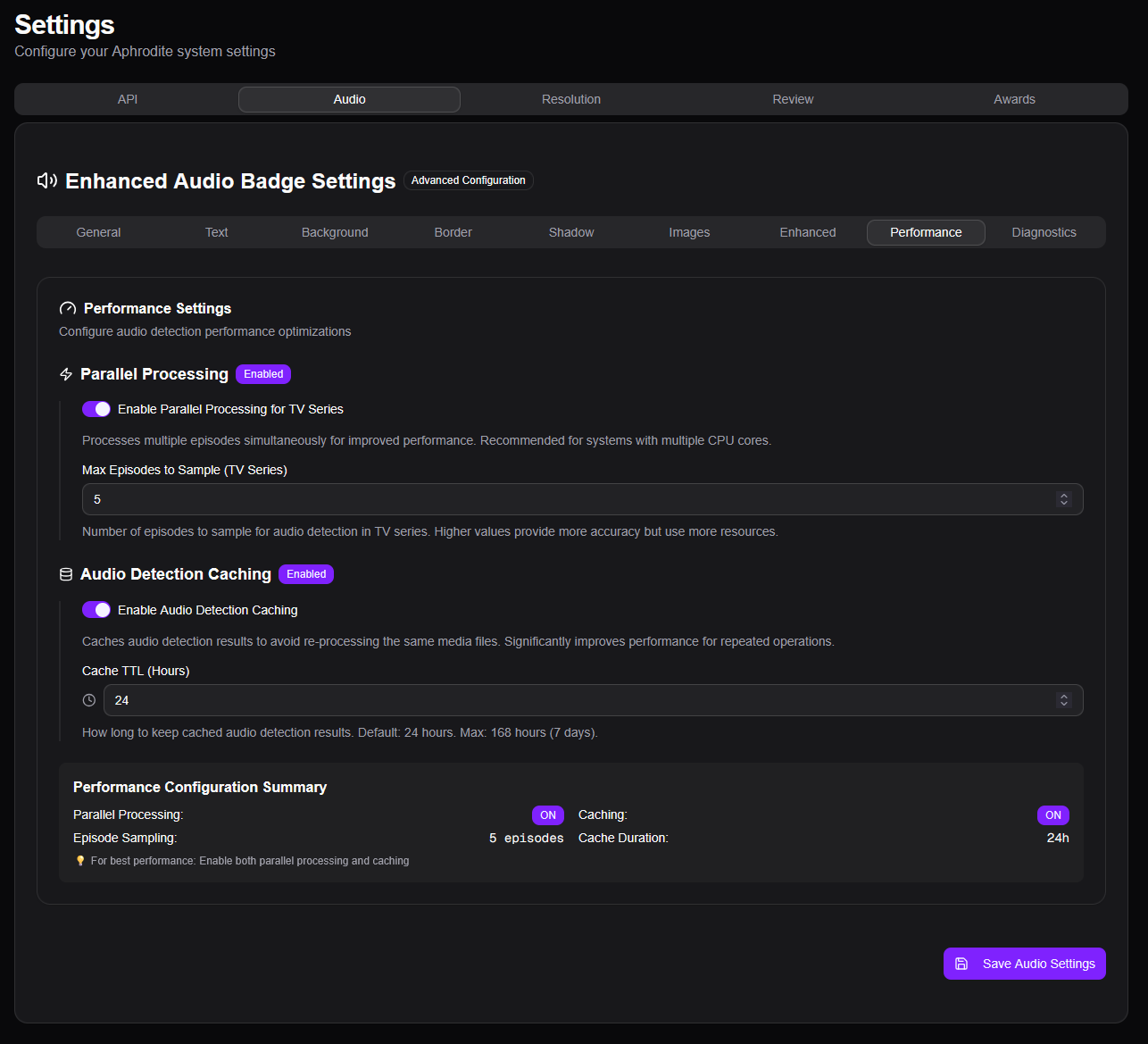
C’est par ailleurs dans cette partie qu’on peut configurer les badges à mettre en overlay sur les affiches. Je ne rentre pas dans les détails, il y a tellement de personnalisation possible que c’est propre à chacun. Aphrodite étant tout jeune, les notes ne sont pour l’instant disponibles qu’à partir d’IMDb, Metacritic, MyAnimeList, Rotten Tomatoes et TMDb. C’est déjà pas mal même si je suis impatient de voir Trakt arriver. TMDb et Trakt.tv ont maintenant un nombre d’utilisateurs suffisant pour avoir plusieurs centaines de votes et les rendre qualitatifs. Il n’y a évidemment pas AlloCiné, pardon pour ceux qui y bossent, mais c’est bien trop franco-nombriliste-français pour avoir une quelconque utilité dans la galaxie des *arrs et du streaming.
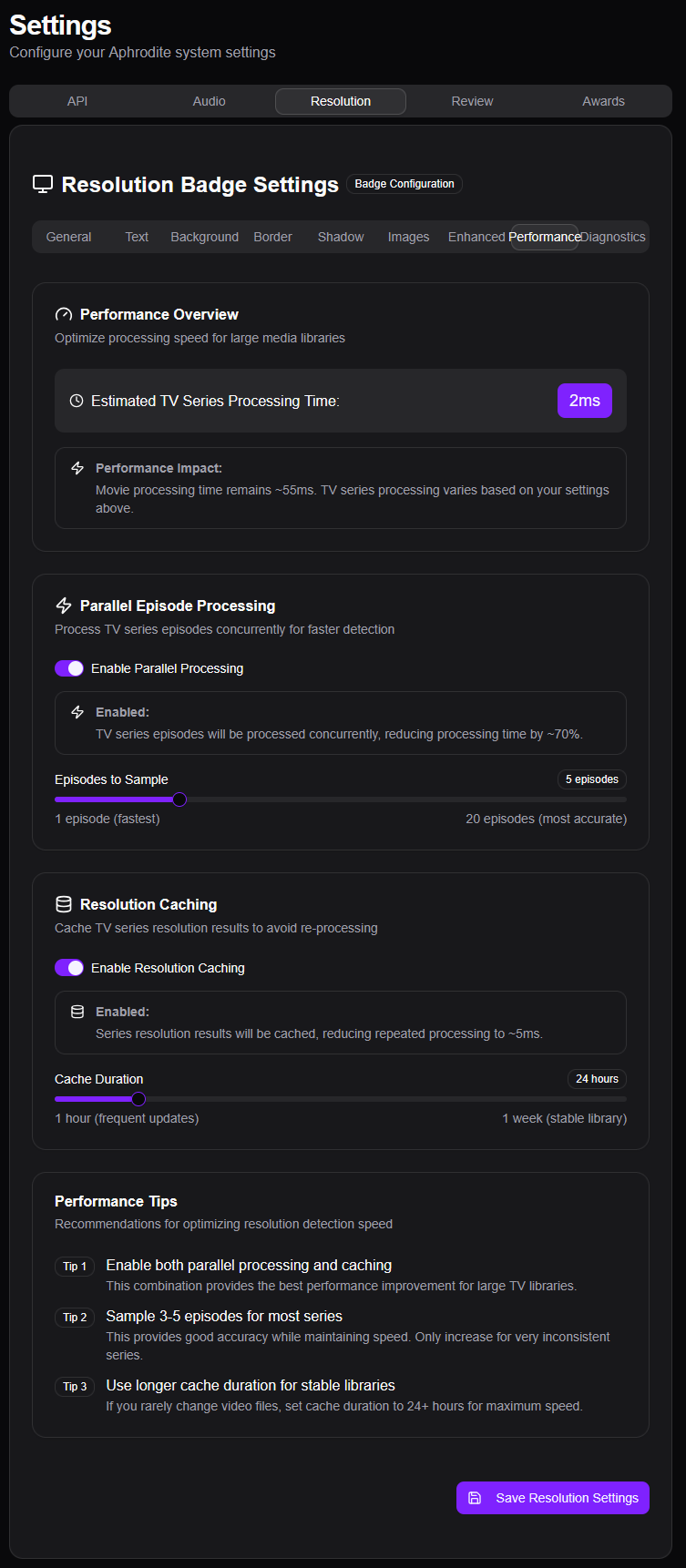
Pour l’audio et la vidéo, Aphrodite peut détecter les données via l’analyse des fichiers. Faut évidemment avoir la machine qui le permet sans que ça prenne des heures.
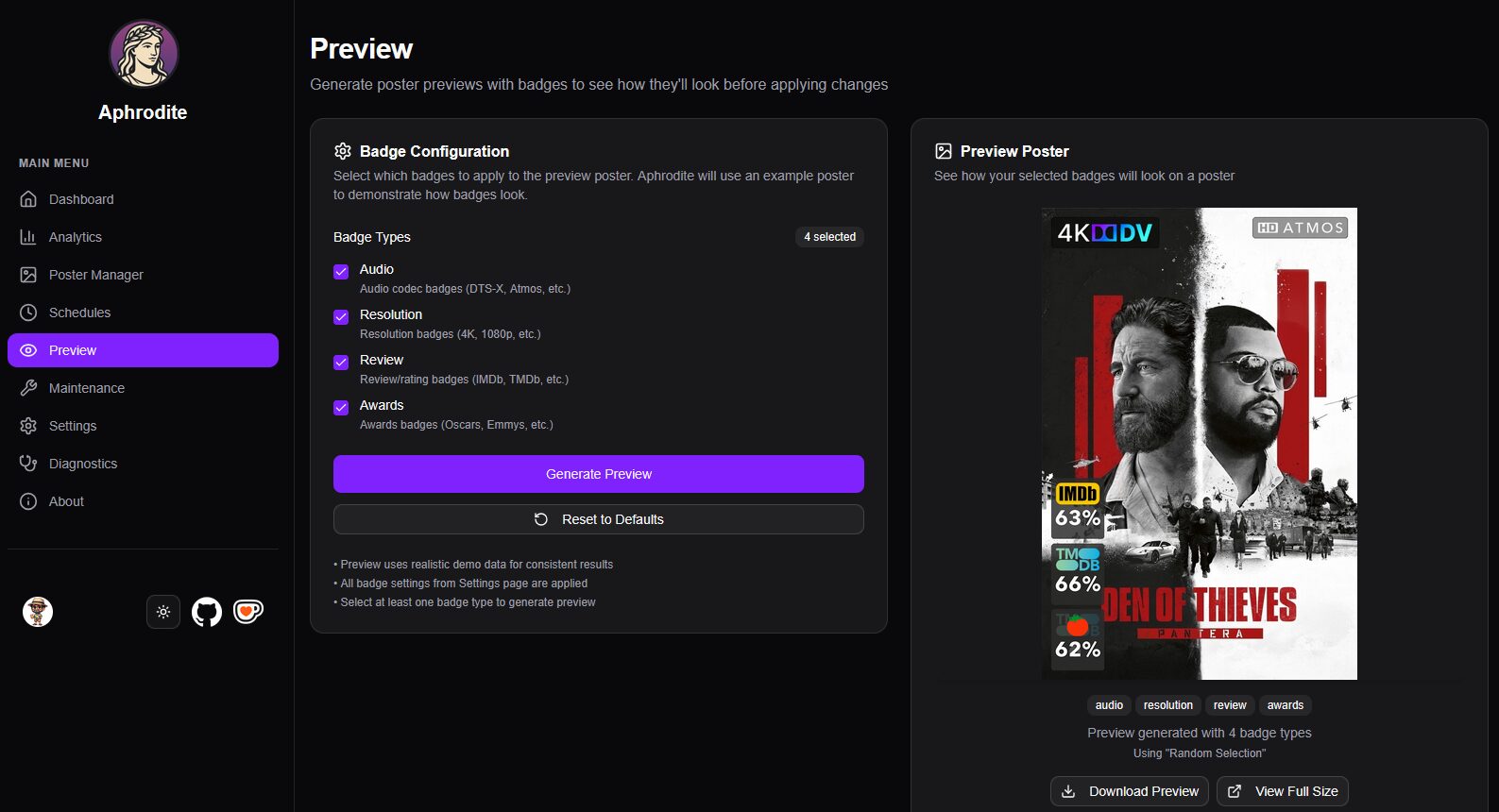
On peut générer un aperçu de sa configuration via le menu Preview
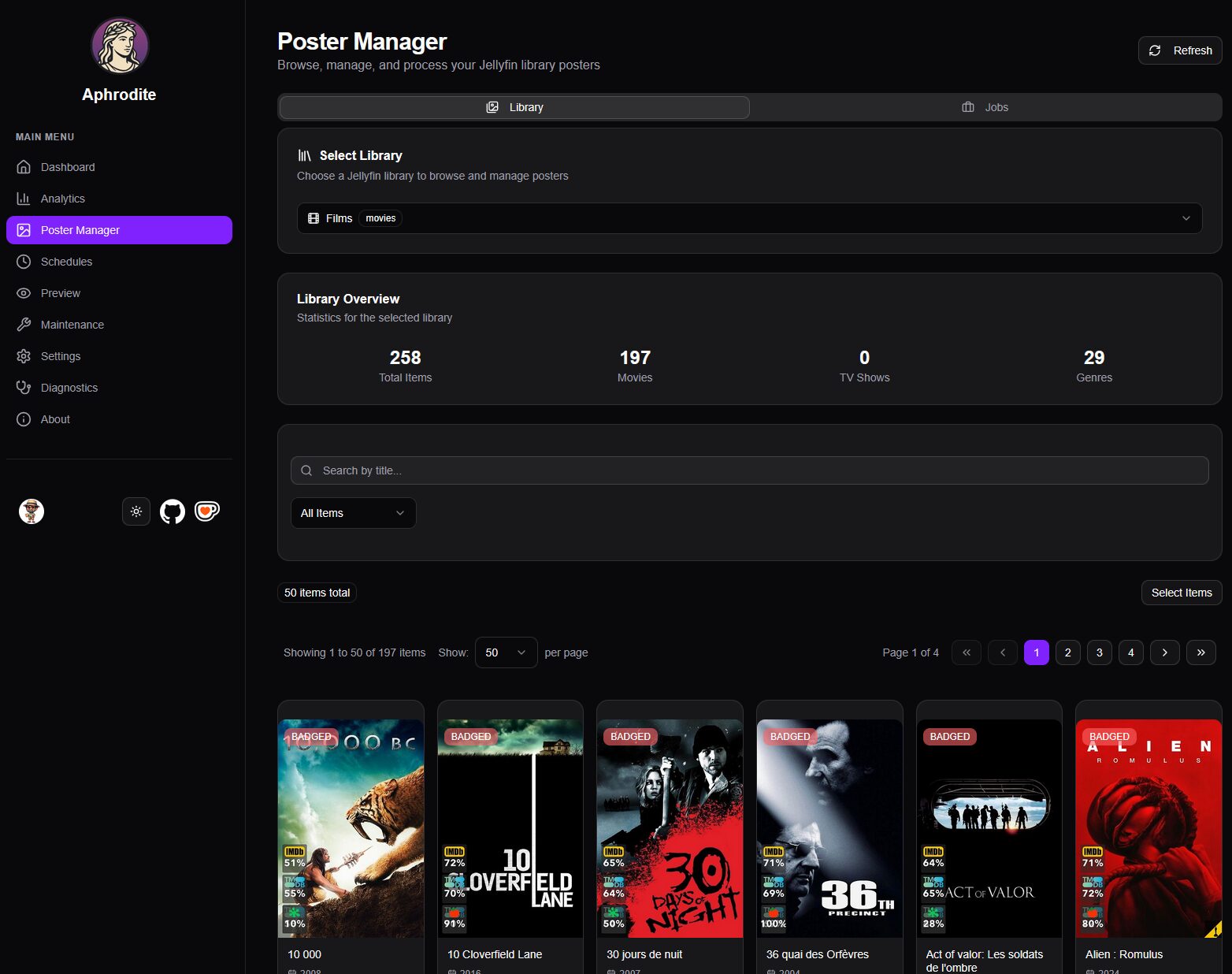
Avant d’aller plus loin, il faut prendre le temps de vérifier l’import des bibliothèques suite à la connexion avec Jellyfin, dans le menu Poster Manager. C’est ballot, j’ai pas pensé à faire de screen avant de modifier mes affiches…
Ici on peut modifier les affiches, par lots de 50 donc faut être patient… C’est sympa, ça change mais on ne peut pas faire de choix et, pour l’instant, il n’y a pas MediUX d’intégré. Mais le projet est jeune, ça a le temps de venir.
C’est également dans ce menu qu’on peut lancer à la demande l’application des badges, toujours par lots de 50 affiches. Ça peut être intéressant pour tester ou s’occuper des bibliothèques spécifiques avec peu de contenus.
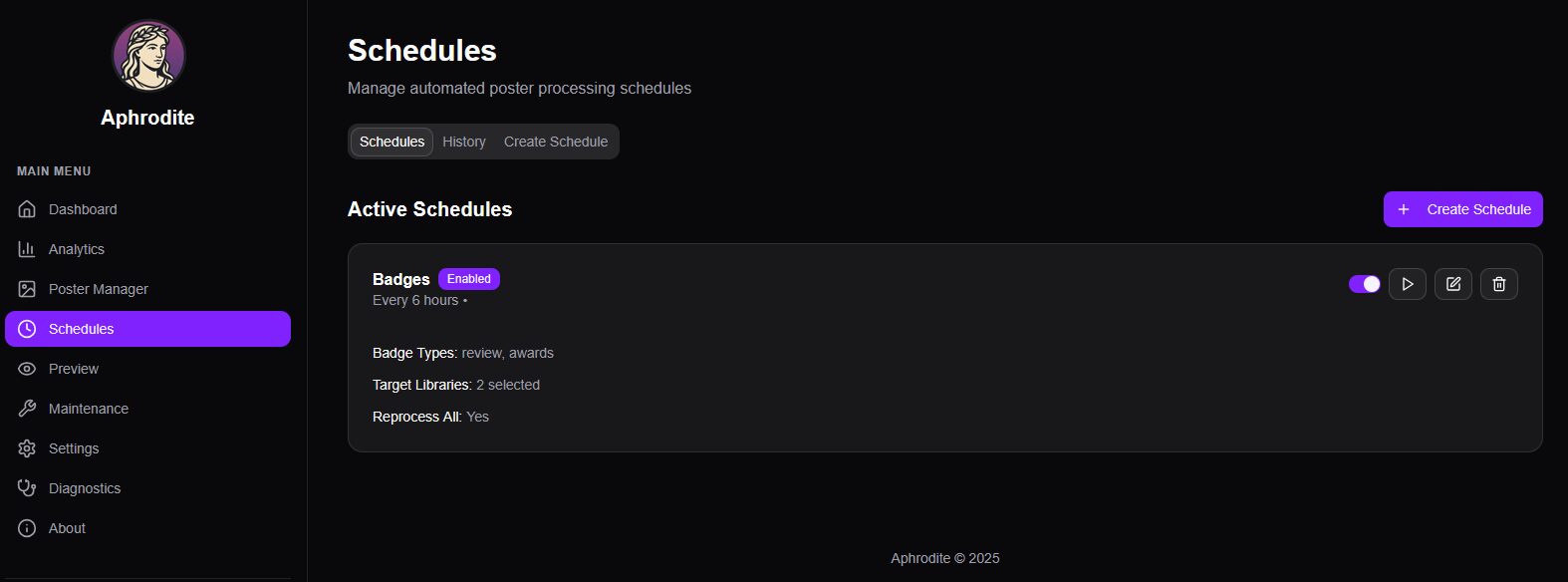
Et ensuite passer aux choses sérieuses avec la mise en place de tâches (ou d’une seule, c’est selon) via les Schedules
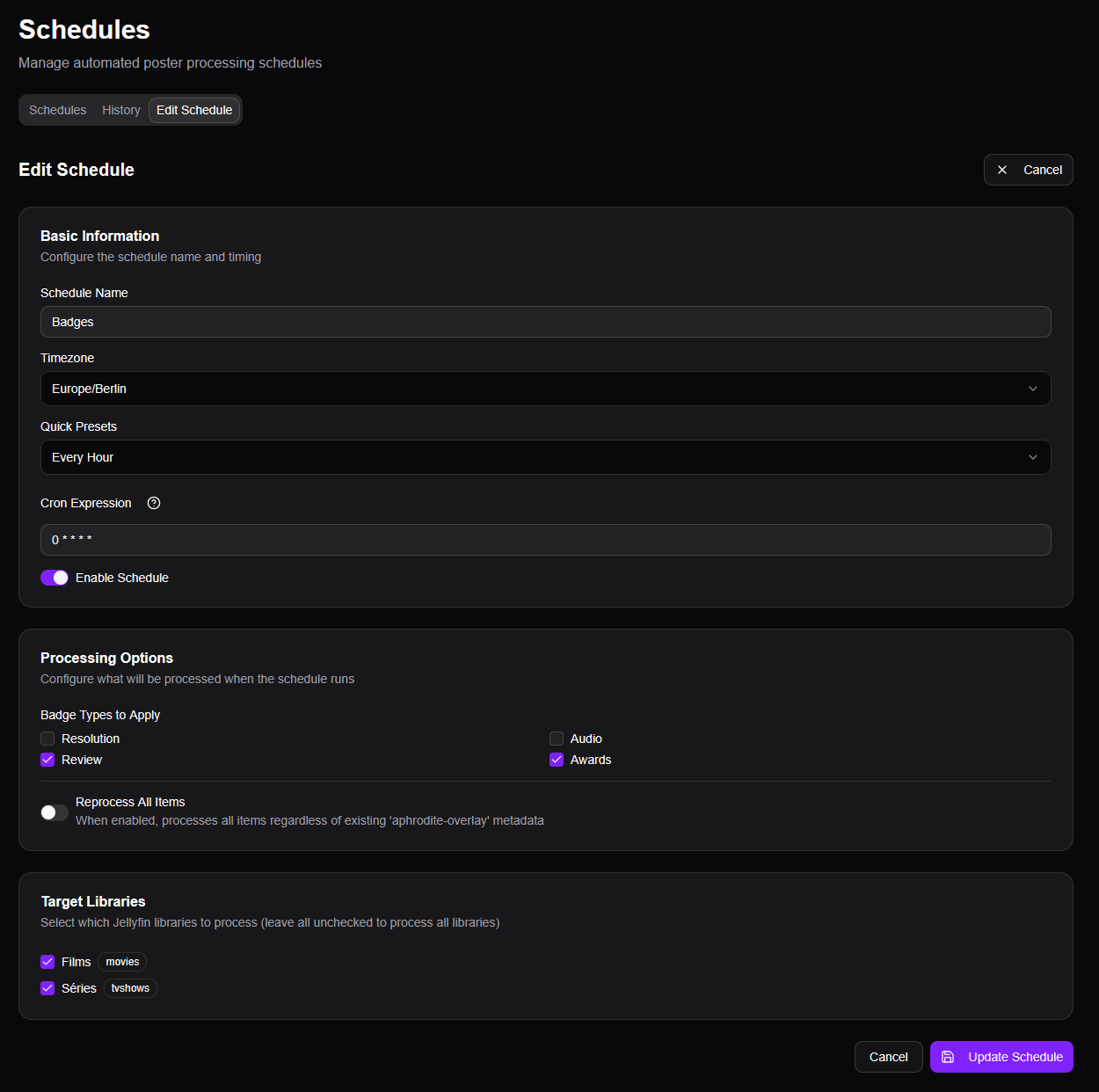
Après avoir testé plusieurs configurations, j’ai créé une tâche qui se répète toutes les heures pour mes 2 bibliothèques, pour les contenus non encore « badgés » et seulement les notes et récompenses, comme expliqué au début de mon article.
On peut déclencher le travail directement, sans attendre la prochaine planification et mes bibliothèques passent d’affiches simples
à des badgées selon mes préférences ! Il y a eu l’ajout de collections entre temps également, depuis Jellyfin.
Au final ça tourne très bien, il y a presque trop de réglages possibles quand on est comme moi un éternel insatisfait ^^’
Aphrodite est encore jeune et en sus de l’utiliser je suivrai assurément ses évolutions !
Apple confirme officiellement la tenue de son événement annuel consacré à la nouvelle génération d’iPhone pour le mardi 9 septembre. L’entreprise de Cupertino distribue déjà les invitations pour cette keynote qui se déroulera au Steve Jobs Theatre, débutant à 10 heures du matin (heure du Pacifique) soit 19 heures en France. L’annonce respecte la tradition calendaire établie l’année précédente, ... Lire plus
J’avais complètement zappé de présenter le fabuleux SugestArr il y a quelques mois, remédions à ça de suite !
On ajoute tous les contenus découverts sur le Web, sur IMDB, TMDB, Trakt, par des connaissances, via des forums, via Overseerr ou Jellyseerr…
Cet outil de guiseppe99barchetta devrait vous ravir puisqu’il permet d’avoir des recommandations personnalisées et est, je trouve, relativement complet :
Prise en charge multi-médias : compatible avec Jellyfin, Plex et Emby pour récupérer le contenu.
Intégration TMDb : recherche de films et séries similaires via TMDb.
Requêtes automatisées : envoie des demandes de téléchargement pour les contenus recommandés vers Jellyseer ou Overseerr.
Interface web : interface conviviale pour la configuration et la gestion.
Journaux en temps réel : visualiser et filtrer les logs en direct (ex. INFO, ERROR, DEBUG).
Sélection des utilisateurs : possibilité de choisir quels utilisateurs peuvent initier des requêtes, avec gestion et validation des contenus demandés automatiquement.
Gestion des tâches cron : modification du planning des cron jobs directement depuis l’interface web.
Pré-validation de configuration : vérifie automatiquement les clés API et les URLs lors de l’installation.
Filtrage de contenu : exclut les demandes de contenus déjà disponibles sur les plateformes de streaming dans votre pays.
Support de bases de données externes : possibilité d’utiliser PostgreSQL ou MySQL en plus de SQLite pour plus de performance et d’évolutivité.
Y’a pas d’application AndroidTV/smarthone mais c’est responsive et on peut automatiser les ajouts.
Pour l’utiliser il faut une clé API TMDB et évidemment une ou des instances Plex/Emby/Jellyfin et Oberseerr/Jellyseerr.
Une fois lancé, on se connecte avec notre lecteur favori, on ajoute une clé TMDB
Dans le cas de Plex, ça liste les serveurs disponibles (pour faire simple j’ai sélectionné un local) et ça en détaille les librairies et utilisateurs. On peut aussi mettre une URL directement
On enchaine avec Overseerr ou Jellyseerr
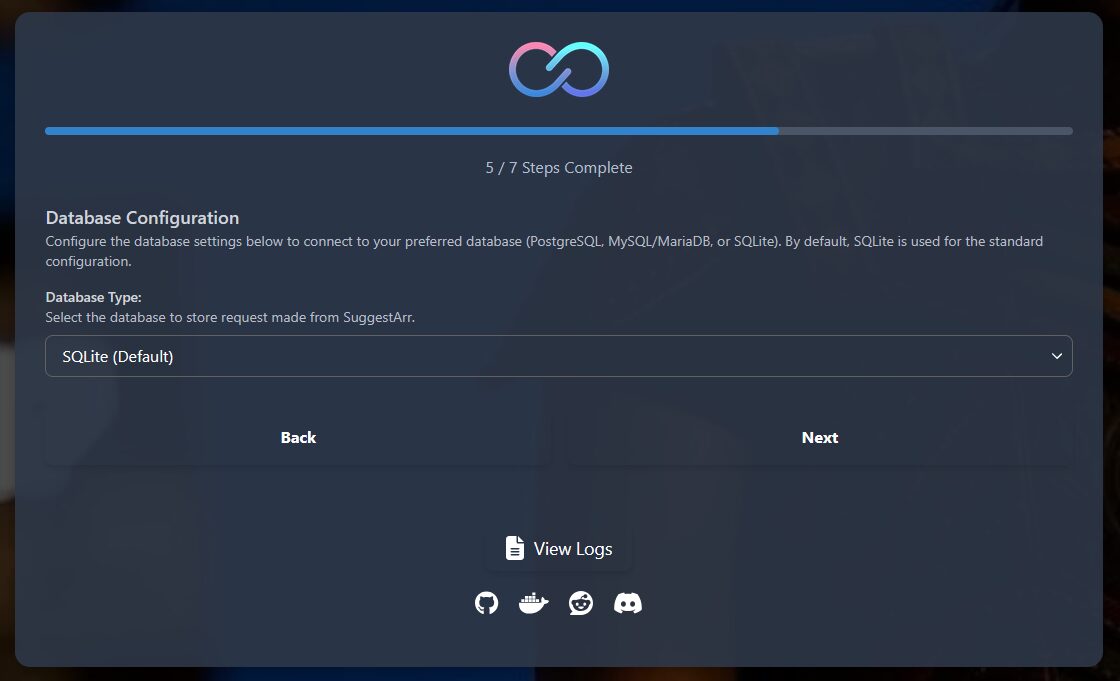
Je reste sur du SQLite. Si vous voulez une BDD robuste à part, il faut revoir le docker-compose pour l’ajouter
Configuration rapide :
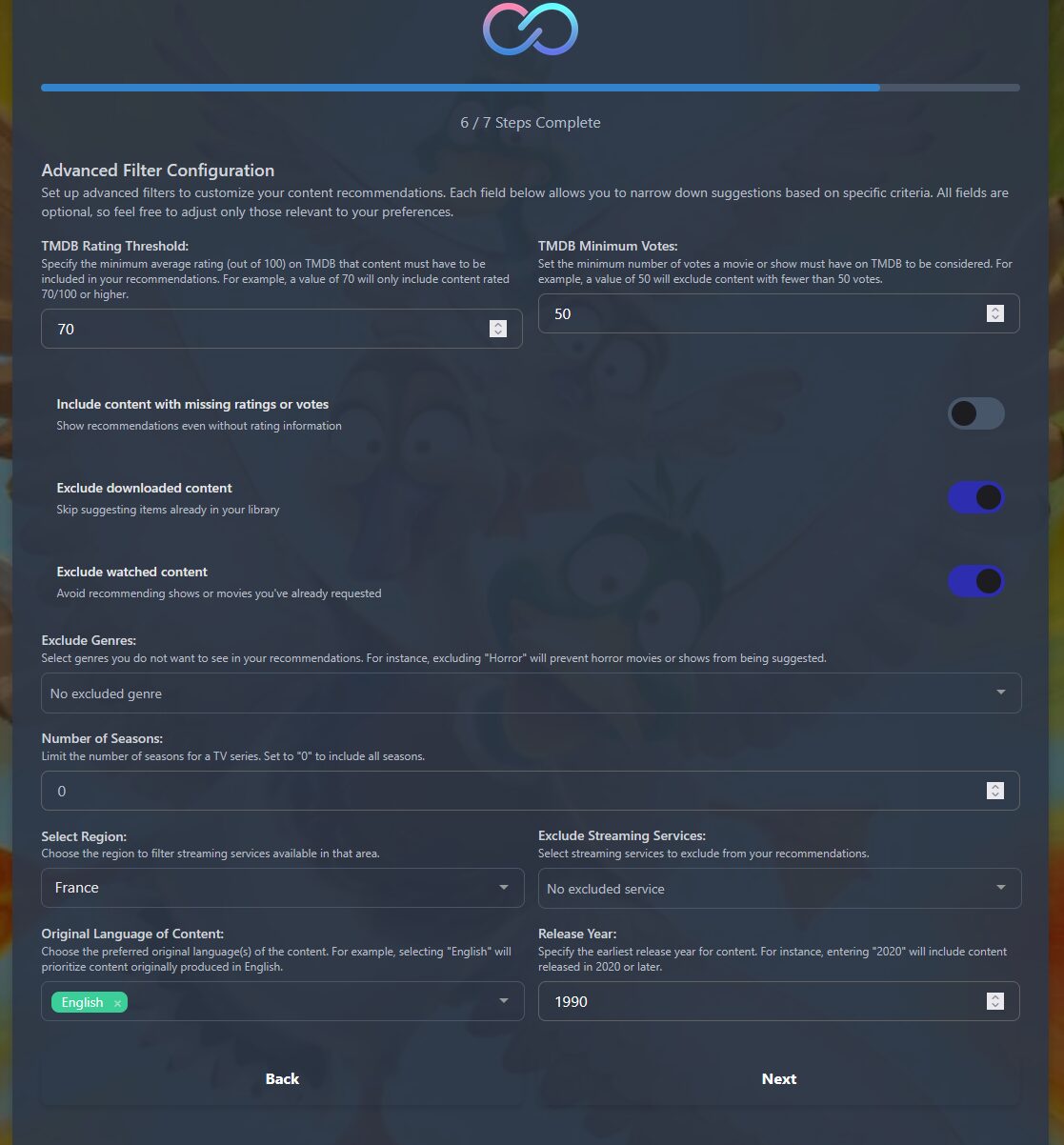
Note minimale sur TMDB et nombre minimum d’avis,
Je n’inclus pas le contenu sans note J’exclus le contenu déjà téléchargé et/ou vu
Je n’exclus aucun genre ni aucun service (Disney+, Netflix, Youtube, Canal+…)
Je sélectionne English pour la langue originale des contenus que je veux en recommandation. Je ne suis absolument pas fan de Plus belle la vie et autres trucs français. Je préfère les séries US notamment. Précision : ça ne limite pas aux contenus produits en langue anglais mais ça la priorise
Et je souhaite des recommandations de contenus produits à partir des années 90
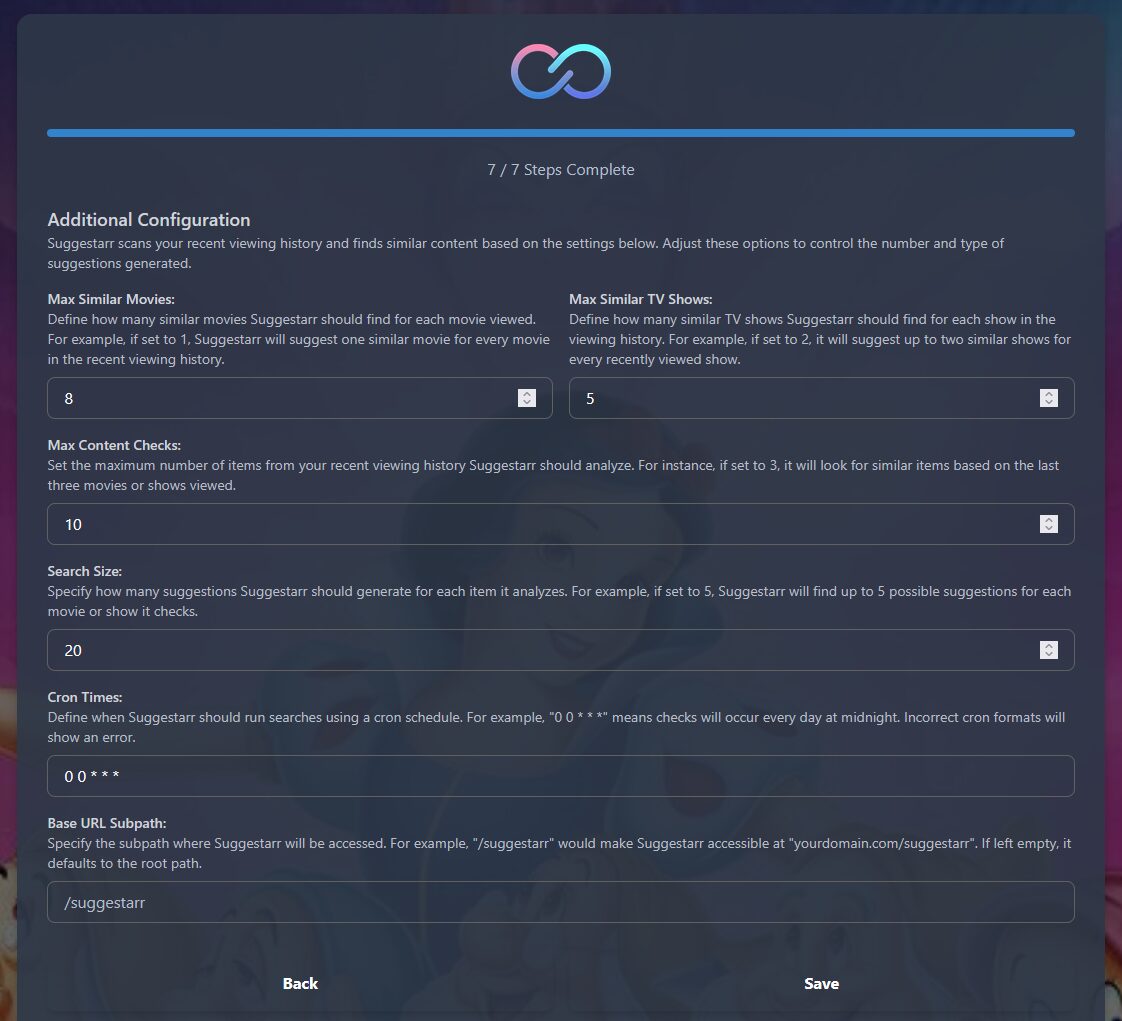
Pour chaque film en historique de lecture je veux 8 suggestions, 5 pour chaque série,
Suggestarr me fera des recommandations par rapport aux 5 derniers contenus lus,
Le Search Size définissant combien de suggestions en tout je demande (si j’ai bien pigé ?) Et le cron, pour l’exécution. J’ai changé après la capture, j’ai mis toutes les 6h (0 */6 * * *)
Et la récap de fin avant le 1er lancement
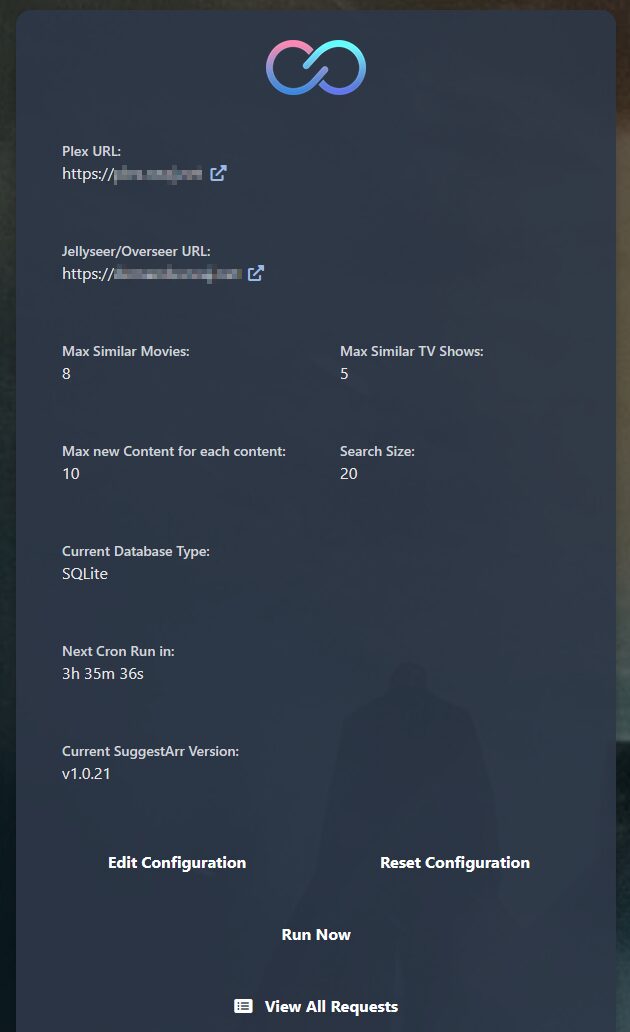
Et ça ajoute les recommandations dans Overseerr ou Jellyseerr selon votre configuration. Attention du coup si, comme moi, tout est automatiquement validé, ça peut vite accroître les bibliothèques ! Mon setup étant tout récent je n’ai hélas pas de screen à vous montrer mais vous pouvez voir ce que ça donne avec la fin de cette vidéo YouTube avec UNRAiD.
Découvrez ce qu’est un Chouffin, son origine sur les forums, ses traits caractéristiques, sa culture geek et son influence dans l’imaginaire collectif.
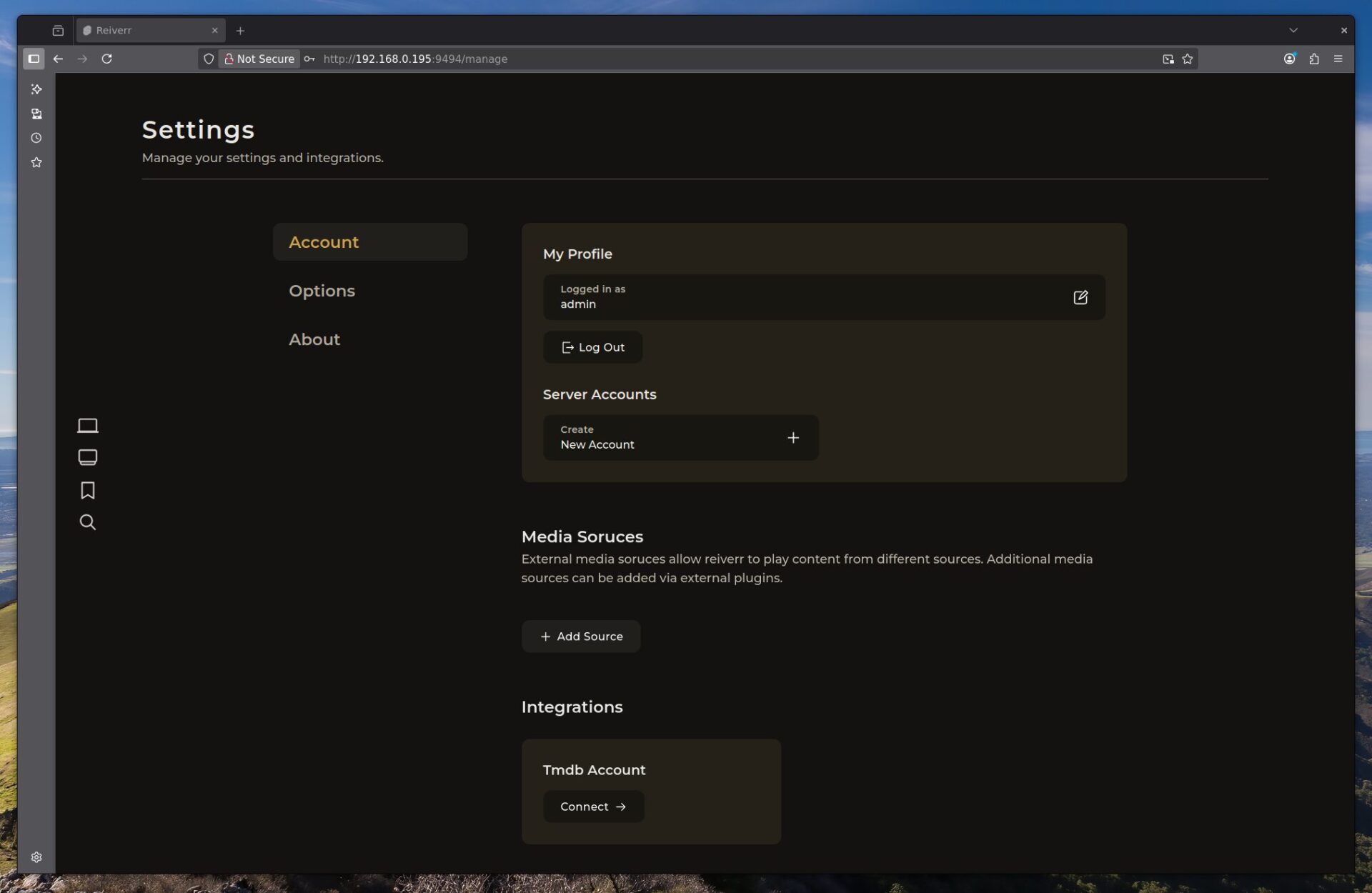
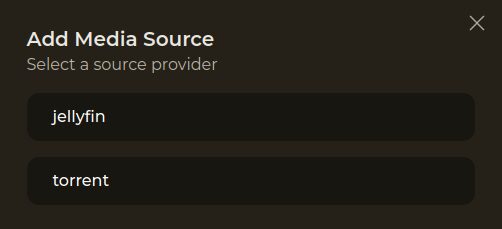
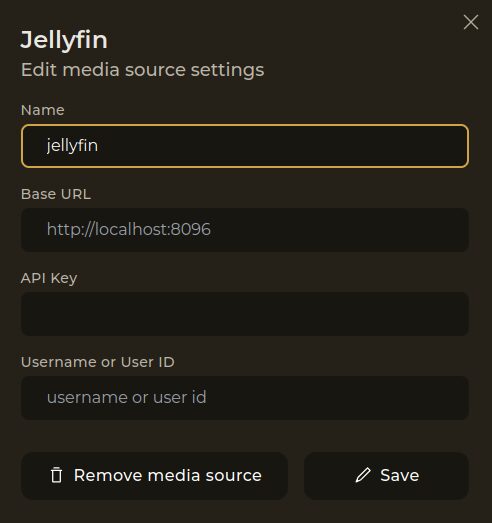
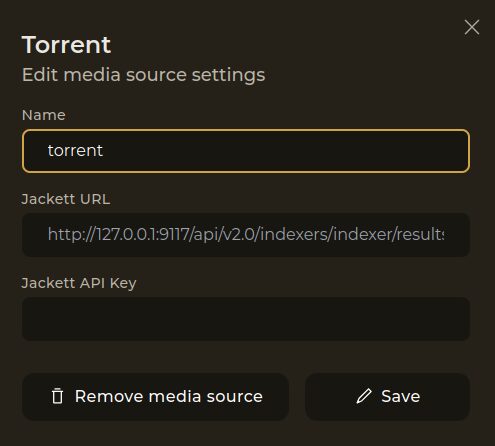
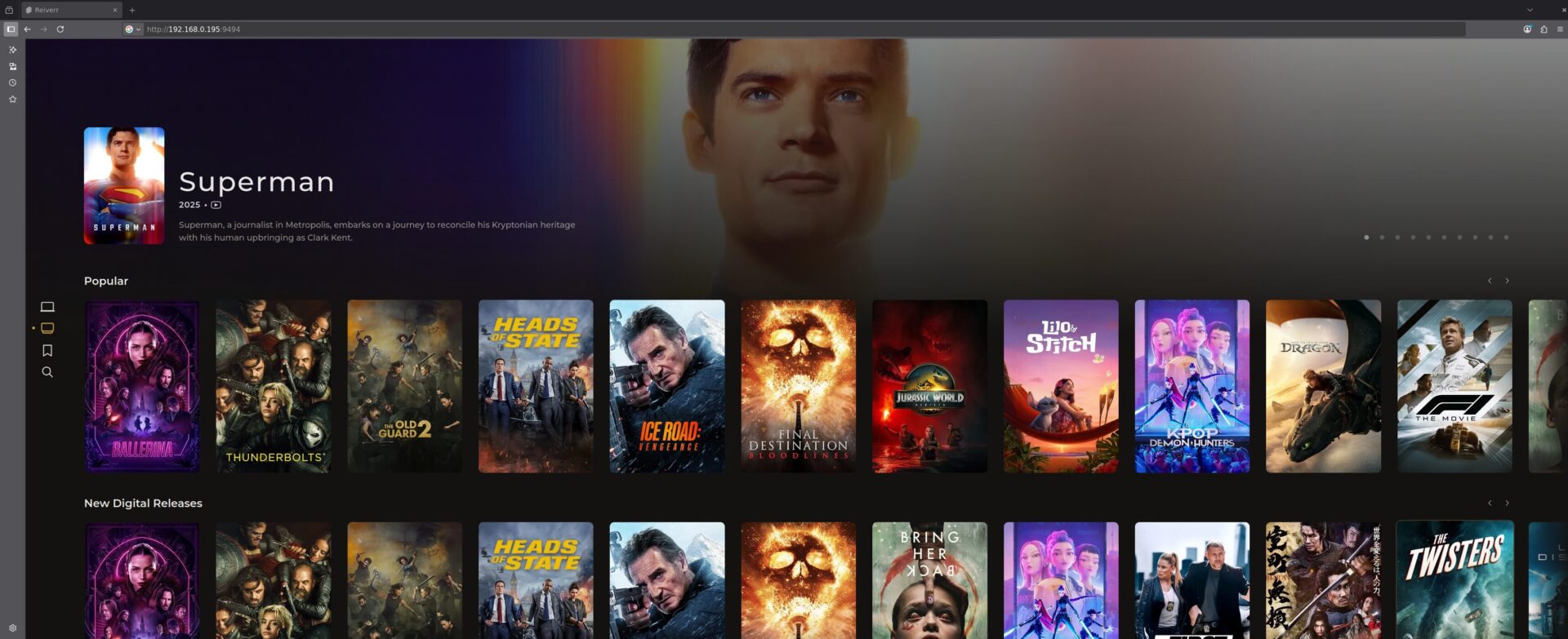
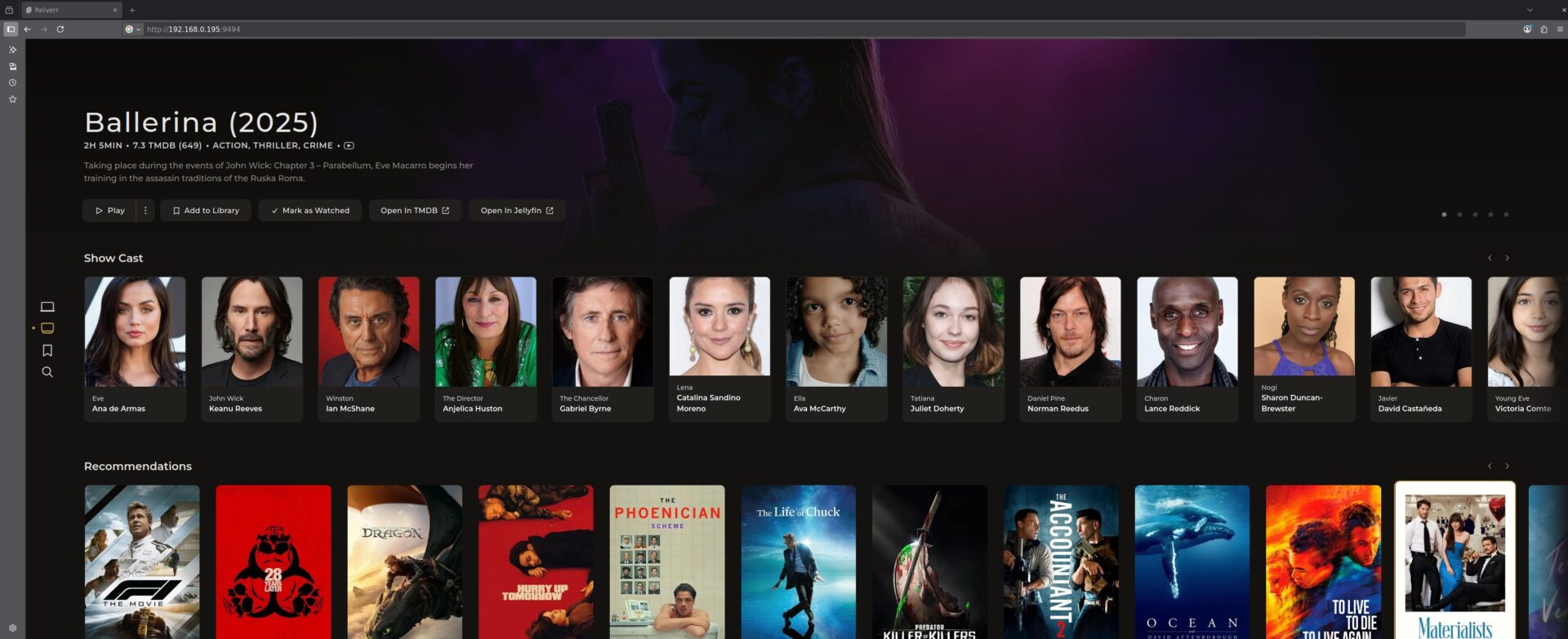
J’en avais parlé rapidement sur un forum il y a un peu plus d’un an, Reiverr se veut être une interface globale pour l’indexation et la recherche/découverte de contenus audio/vidéo.
C’est une alternative à Overseerr, qui englobe plusieurs fonctionnalités de parcours de librairies Jellyfin, recherche de contenus avec les *arrs, découverte via TMDB et qui permet la lecture directement via Jellyfin et en Torrent-Streaming (donc à faire passer par un VPN).
 Supervision et automatisation en temps réel
Supervision et automatisation en temps réel Système de surveillance intelligent
Système de surveillance intelligent Flux de travail automatisés
Flux de travail automatisés Tableau de bord en temps réel
Tableau de bord en temps réel Automatisation personnalisable
Automatisation personnalisable Intégration avec les serveurs multimédias
Intégration avec les serveurs multimédias Séparation intelligente des contenus
Séparation intelligente des contenus Options d’organisation flexibles
Options d’organisation flexibles















 Compatibilité multi-serveurs : fonctionne avec Plex, Emby et Jellyfin.
Compatibilité multi-serveurs : fonctionne avec Plex, Emby et Jellyfin. Navigation visuelle : prévisualisez les visuels dans une interface claire et organisée.
Navigation visuelle : prévisualisez les visuels dans une interface claire et organisée. Mises à jour automatiques : enregistrez les ensembles d’images choisis et gardez-les synchronisés automatiquement.
Mises à jour automatiques : enregistrez les ensembles d’images choisis et gardez-les synchronisés automatiquement. Stockage local : possibilité d’enregistrer les images à côté de vos fichiers multimédias pour un accès facile.
Stockage local : possibilité d’enregistrer les images à côté de vos fichiers multimédias pour un accès facile. Support Docker : déploiement simple avec Docker ou docker-compose.
Support Docker : déploiement simple avec Docker ou docker-compose.