Si vous utilisez GitHub Copilot ou ChatGPT pour coder plus vite, voici une nouvelle qui va peut-être vous refroidir un peu.
Une fintech a découvert
que des attaquants avaient extrait des données clients via un endpoint API qui n'était documenté nulle part. Personne dans l'équipe ne se souvenait l'avoir créé et après 3 semaines d'enquête, le verdict est tombé : c'est Copilot qui l'avait généré pendant une session de code nocturne.
Bienvenue dans l'ère des "phantom APIs" les amis !
J'avoue que le concept m'a fait marrer car on parle quand même d'endpoints qui existent en production mais dont personne n'a connaissance. Ahahaha... y'a pas de documentation, pas de tests, pas de validation de sécurité. C'est juste un peu de code généré par une IA qui a trouvé ça "logique" de créer un /api/v2/admin/debug-metrics qui balance du
PII
à quiconque tombe dessus par hasard.
J'ai vu le dernier rapport
Veracode GenAI Code Security
et les chiffres font un peu flipper c'est vrai ! Ils ont testé plus de 100 LLM sur 80 tâches de codage différentes, et le résultat fait mal puisque 45% du code généré par IA contient des vulnérabilités classées OWASP Top 10. En gros, presque une fois sur deux, votre assistant IA vous pond du code troué comme une passoire. Java est le grand gagnant avec 72% de taux d'échec, suivi par Python, JavaScript et C# qui tournent autour de 38-45%.
En effet, l'IA ne pense pas comme un dev qui s'est déjà fait hacker. Par exemple, quand un dev crée un endpoint, il réfléchit authentification, rate limiting, exposition de données, documentation. Alors que l'IA, elle, génère juste ce qui lui semble statistiquement logique vu son dataset d'entraînement, sans comprendre les implications sécurité ou les politiques de l'organisation.
D'ailleurs
une autre étude Apiiro
montre que les assistants IA ont multiplié par 10 les vulnérabilités introduites en seulement 6 mois dans les dépôts étudiés. Les chemins d'escalade de privilèges ont explosé tout comme les défauts architecturaux. Et le pire c'est que les développeurs qui utilisent l'IA exposent leurs credentials cloud (clés Azure, Storage Access Keys) deux fois plus souvent que les autres.
Y'a aussi le problème du "slopsquatting". Oui, encore un gros mot, je sais... En fait, l'IA peut vous recommander d'installer un package qui n'existe tout simplement pas. Genre elle hallucine un nom de librairie et un attaquant un peu moins con que les autres, peut enregistrer ce nom sur npm ou PyPI et y foutre du code malveillant.
Et là que ça devient vraiment problématique, c'est que les outils de sécurité traditionnels ne voient rien. L'analyse statique compare votre code à des specs documentées, sauf que les phantom APIs n'existent dans aucune spec. Les API gateways protègent les endpoints enregistrés mais laissent passer des routes non déclarées sans authentification.
Pour s'en sortir, certaines boîtes commencent donc à analyser le trafic en temps réel pour détecter les endpoints qui traînent. Y'a aussi l'audit de code spécifique IA pour repérer les patterns de génération algorithmique, et la comparaison continue entre les specs et ce qui tourne vraiment en production.
Bref, relisez votre code généré par IA comme si c'était un stagiaire collégien de 3e qui l'avait écrit, et si vous découvrez un endpoint bizarre dans votre base de code dont personne ne se souvient, y'a des chances que ce soit un "fantôme" laissé par votre copilote préféré...
Un nouveau standard ouvert pour décrire la façon de tester et appeler une API HTTP, très utile pour les clients HTTP type Postman.
Ce standard est proposé par Bruno, qui est un excellent client HTTP, offline-first et ouvert. Et cette initiative montre une volonté d'unir les nombreux clients HTTP sous un format commun et interopérable.
Ce format est complémentaire à OpenAPI.
L'idée à terme est de pouvoir stocker ces collections sous forme de fichiers YAML dans le même repo Git qui stocke le code de l'API elle-même.
Pour l'instant ce n'est évidemment supporté que par Bruno lui-même, mais j'espère que l'initiative va convaincre et être adoptée massivement.
Un nouveau standard ouvert pour décrire la façon de tester et appeler une API HTTP, très utile pour les clients HTTP type Postman.
Ce standard est proposé par Bruno, qui est un excellent client HTTP, offline-first et ouvert. Et cette initiative montre une volonté d'unir les nombreux clients HTTP sous un format commun et interopérable.
Ce format est complémentaire à OpenAPI.
L'idée à terme est de pouvoir stocker ces collections sous forme de fichiers YAML dans le même repo Git qui stocke le code de l'API elle-même.
Pour l'instant ce n'est évidemment supporté que par Bruno lui-même, mais j'espère que l'initiative va convaincre et être adoptée massivement.
Vous savez que depuis quelques années, des startups équipent les camions poubelle et les bus de caméras IA pour cartographier automatiquement l'état des routes ? Comme ça, pendant que le chauffeur fait sa tournée, une intelligence artificielle détecte les nids-de-poule, les fissures et autres joyeusetés routières en temps réel. Chaque défaut est géolocalisé, scoré par gravité, et hop, les équipes de maintenance savent exactement où intervenir.
Bon apparemment, là où j'habite, ils n'utilisent pas ça parce que les routes sont des champs de mines, mais si le Maire se chauffe en DIY, ce projet maintenu par un certain Peter va l'intéresser.
C'est sur GitHub et c'est un stack complet pour faire exactement la même chose que les startups spécialisées en nids de poule... un vrai projet end-to-end avec l'entraînement du modèle sur du GPU cloud, une API backend containerisée, et même une app mobile React Native pour scanner les routes depuis votre téléphone.
Le projet s'appelle
pothole-detection-yolo
et ça utilise YOLOv8, le modèle de détection d'objets qui fait fureur en ce moment dans le domaine de la vision par ordinateur. Concrètement, le modèle a été entraîné sur un dataset de nids-de-poule disponible sur HuggingFace, avec des images de 640x640 pixels. L'entraînement s'est fait sur Nebius Cloud avec des GPUs H100, donc du sérieux, pas du Colab gratuit qui timeout au bout de 20 minutes.
Ce qui est cool avec ce projet, c'est qu'il ne s'arrête pas au modèle. Y'a une API FastAPI complète qui expose deux endpoints : /detect pour envoyer une image et récupérer les bounding boxes avec les scores de confiance, et /health pour vérifier que le service tourne. Le tout est containerisé en Docker avec support GPU automatique. Et si vous avez pas de carte graphique, ça bascule sur CPU.
Et la cerise sur le gâteau, c'est l'app mobile Expo/React Native. Vous ouvrez l'app, vous prenez une photo d'une route avec votre smartphone, l'image est envoyée à l'API, et vous récupérez les détections en temps réel avec les rectangles dessinés autour des nids-de-poule et les pourcentages de confiance affichés. Bref, c'est exactement ce que font les boites tech à plusieurs millions, sauf que là c'est open source sous licence Apache 2.0.
YOLOv8 atteint facilement entre 93 et 99% de précision pour la détection de nids-de-poule selon les variantes utilisées et des chercheurs ont même combiné YOLOv8 avec des données de nuages de points 3D pour atteindre 95.8% de précision sur des tronçons de tests d'environ 5 km. Bref, c'est du solide et ça fonctionne .
Le truc intéressant pour les bricoleurs, c'est que le modèle entraîné est directement téléchargeable sur HuggingFace donc vous pouvez donc skip toute la partie entraînement si vous voulez juste tester le résultat. Une seule commande Docker pour lancer l'API, et vous êtes opérationnel. Pour les plus motivés qui veulent entraîner leur propre modèle avec des données locales de vos routes françaises pleines de cratères, le code d'entraînement est là aussi avec les configs Ultralytics.
Bref, si vous êtes une petite mairie qui veut cartographier l'état de vos routes sans claquer 50 000 euros dans une solution proprio, ou juste un dev curieux de voir comment fonctionne la stack derrière ces caméras intelligentes qu'on voit de plus en plus sur les véhicules de service, ce projet est une mine d'or.
Tout est là
, documenté, et ça fonctionne du feu de dieu.
Vous avez des tonnes de vieux documents papier qui traînent dans des cartons, des factures scannées à l'arrache, des formulaires remplis à la main, des tableaux Excel imprimés puis re-scannés par quelqu'un qui n'a visiblement jamais entendu parler du concept de "bien faire son boulot" ?
Considérez que ce problème est réglé puisque Mistral AI vient de sortir OCR 3, un modèle de reconnaissance de documents qui promet de transformer tout ça en données exploitables, et pour pas cher en plus.
Le modèle est capable de déchiffrer du cursif dégueulasse, des annotations griffonnées dans les marges, voire du texte manuscrit par-dessus des formulaires imprimés. Mistral montre même une démo avec une lettre au Père Noël écrite par un gamin et l'OCR arrive à en extraire le contenu structuré. Bon, c'est cool pour les lettres au Père Noël, mais surtout ça veut dire qu'il peut gérer vos ordonnances médicales ou les notes de réunion de votre collègue qui écrit comme un cochon.
Niveau performances, Mistral annonce un taux de victoire de 74% sur leur précédent modèle OCR 2 et sur les solutions concurrentes. Et comme c'est testé sur des cas réels d'entreprises avec des mesures de précision en fuzzy-match, on n'est pas dans du benchmarks théoriques bidon. Le modèle gère les scans pourris avec compression JPEG, les documents de travers, les faibles résolutions, le bruit de fond... Bref, tout ce qui fait que l'OCR traditionnel vous sort de la bouillie.
Et ce qui est vraiment intéressant, c'est surtout la reconstruction structurelle car contrairement aux OCR classiques qui vous crachent un bloc de texte en vrac, Mistral OCR 3 reconstruit la structure du document. Les tableaux complexes avec cellules fusionnées et hiérarchies de colonnes ressortent en HTML propre avec les colspan et rowspan préservés. Vous obtenez du markdown enrichi en sortie, directement exploitable par vos systèmes sans avoir à nettoyer le bordel derrière.
Côté tarifs, c'est 2 dollars pour 1000 pages et si vous passez par l'API Batch, c'est moitié moins cher à 1 dollar les 1000 pages. Pour un modèle qui se dit plus petit que la plupart des solutions concurrentes tout en étant plus précis, c'est plutôt compétitif. Le modèle peut traiter jusqu'à 2000 pages par minute sur un seul nœud, donc même si vous avez des millions de documents à numériser, ça devrait pas prendre des plombes.
Pour l'utiliser, vous avez deux options. Soit vous passez par l'API (mistral-ocr-2512), soit vous allez sur le
Document AI Playground
dans Mistral AI Studio où vous pouvez glisser-déposer vos PDF et images pour tester. C'est pratique pour voir ce que ça donne avant de l'intégrer dans vos workflows.
Bref, on est en train tout doucement de passer d'OCR qui "lisent du texte" à des modèles qui comprennent la structure des documents. Et ça, ça veut dire que vos archives papier vous pouvoir enfin devenir des données JSON exploitables par vos agents IA, vos systèmes de recherche ou vos bases de connaissances.
Voilà, si vous avez des projets de numérisation d'archives ou d'automatisation de traitement de documents, ça vaut le coup d'aller tester leur playground.
Si vous n’utilisez pas encore
n8n
pour automatiser vos tâches, c’est le moment de vous y mettre parce que c’est open source et c’est la meilleure alternative que vous pourrez trouver à Zapier et ce genre de services payants.
La boîte a levé 180 millions de dollars
récemment avec une valorisation à 2,5 milliards, et contrairement à Zapier qui facture à la tâche (et ça devient vite très cher), n8n facture à l’exécution ! Mais bien sûr, si vous aimez mettre les mains dans le cambouis c’est totalement gratuit !
Si vous connaissez pas encore n8n, c’est vraiment le genre d’outil qui peut vous changer la vie car ça vous permet de connecter vos apps entre elles avec une interface visuelle (genre des blocs qu’on relie), et vous pouvez automatiser à peu près n’importe quoi : synchroniser des données entre outils, envoyer des notifications, créer des pipelines de traitement… Et comme c’est open source et que vous pouvez l’héberger sur votre propre serveur, ce qui règle tous les problèmes de confidentialité des données.
Après, j’avoue que créer des workflows from scratch, c’est parfois un peu relou. Heureusement, y’a
ce super dépôt GitHub
qui contient plus de 4 300 workflows prêts à l’emploi que vous allez pouvoir utiliser pour vous !
La collection est organisée en 15 catégories : Marketing, Sales, DevOps, et tout ce que vous voulez ! Y’a même un système de recherche full-text qui répond en moins de 100ms, des filtres par niveau de complexité (Low, Medium, High), par type de trigger, par service… Bref, vous trouverez ce que vous cherchez en quelques secondes.
Pour l’utiliser, vous avez plusieurs options. Soit vous passez par
l’interface web
hébergée sur GitHub Pages, soit vous installez ça en local avec Python :
docker run -p 8000:8000 zie619/n8n-workflows:latest
Une fois lancé, vous avez accès à une API REST pour chercher et récupérer les workflows. Le endpoint /api/search pour les requêtes, /api/workflow/{id} pour récupérer le JSON d’un workflow spécifique, /api/categories pour la liste des catégories… Tout est documenté évidemment.
Ce truc utilise SQLite avec FTS5 (Full-Text Search) pour les recherches rapides, FastAPI pour le backend, et Tailwind CSS pour le frontend.
Bref, si vous cherchez de l’inspiration pour vos automatisations ou si vous ne voulez pas réinventer la roue à chaque fois, cette collection vaut vraiment le détour.
Bon, j’étais un petit peu occupé aujourd’hui parce que c’est mercredi et c’est le jour des enfants, mais je ne pouvais pas finir ma journée sans vous parler de cette histoire incroyable.
Si vous faites partie des gens qui utilisent des sites comme JSONFormatter ou CodeBeautify pour rendre votre JSON lisible ou reformater du code, et bien figurez-vous que des chercheurs en sécu viennent de découvrir que ces outils ont laissé fuiter des tonnes de données sensibles durant des années. Et quand je dis tonnes, c’est pas une figure de style puisque ce sont plus de 80 000 extraits de code contenant des credentials en clair qui ont fuité, soit plus de 5 Go de données.
En effet, les chercheurs de
WatchTowr
ont découvert que la fonction “Recent Links” de ces plateformes permettait d’accéder à tous les bouts de code collés par les utilisateurs. Les URLs suivaient un format prévisible, ce qui rendait le scraping automatique hyper fastoche pour n’importe qui, et c’est comme ça qu’on a découvert que JSONFormatter a exposé durant 5 ans de données les données de ses utilisateurs. Et du côté de CodeBeautify, ça a duré 1 an.
Les chercheurs ont mis la main sur des identifiants Active Directory, des identifiants de bases de données et services cloud, des clés privées de chiffrement, des tokens d’accès à des repos Git, des secrets de pipelines CI/CD, des clés de passerelles de paiement, des tokens API en pagaille, des enregistrements de sessions SSH, et même des données personnelles de type KYC. Bref, le jackpot pour un attaquant, quoi.
Et côté victimes, c’est un festival puisqu’on y retrouve des agences gouvernementales, des banques, des assurances, des boîtes d’aéronautique, des hôpitaux, des universités, des opérateurs télécom… et même une entreprise de cybersécurité. On a même retrouvé les credentials AWS d’une bourse internationale utilisés pour leur système Splunk, ainsi que des identifiants bancaires provenant de communications d’onboarding d’un MSSP (Managed Security Service Provider). C’est cocasse comme dirait Macron.
Et pour prouver que le problème était bien réel et exploitable, les chercheurs de WatchTowr ont utilisé un service appelé
Canarytokens
dont je vous ai déjà parlé. Ils ont implanté de faux identifiants AWS sur les plateformes et ont attendu de voir si quelqu’un y accédait…
Résultat, quelqu’un a tenté de les utiliser 48 heures après que les liens étaient censés avoir expiré, et 24 heures après leur suppression supposée. Les données restaient donc accessibles bien au-delà de ce que les utilisateurs pouvaient imaginer.
Et le pire dans tout ça c’est qu’au moment de la publication des articles, les liens “Recent Links” étaient toujours accessibles publiquement sur les deux plateformes. Bref, aucune correction n’a été déployée.
Donc, voilà, si vous avez utilisé ces outils par le passé et que vous y avez collé du code contenant des identifiants et autres clés API (même par inadvertance), c’est le moment de faire une petite rotation de vos secrets.
Et même si c’est une évidence, de manière générale, évitez de balancer du code sensible sur des outils en ligne dont vous ne maîtrisez pas la politique de conservation des données.
Hello les gens ! j'espère que tout le monde va bien. Aujourd'hui, on reste dans la pure technique avec un système que je suis en train d'évaluer chez nous, pour utiliser et dans la mesure du possible automatiser la mise à jours de certificats SSL publiques via Let's Encrypt et injecter ceux-ci dans nos load balancers F5/BigIP.
Pour la gestion des API, la tendance est à l’approvisionnement auprès de plusieurs fournisseurs.
Gartner avait fait la remarque l’an dernier dans le Magic Quadrant consacré à ce marché. Il va plus loin cette année : le sourcing multiple est devenu standard… en contrepartie d’un risque de fragmentation que peuvent toutefois atténuer les architectures fédérées.
Un autre mouvement s’est confirmé : une part croissante des utilisateurs de solutions de gestion des API sont des développeurs. Les stratégies marketing ont évolué en conséquence. Mais des offreurs gardent un déficit de visibilité auprès de ce public. Y compris quelques-uns de ceux que Gartner classe comme « leaders ». En l’occurrence, Axway, Boomi et, dans une certaine mesure, IBM.
17 fournisseurs, 7 « leaders »
En 2024, Boomi faisait partie des « acteurs de niche ». En un an, il a nettement progressé, tant en « exécution » (capacité à répondre effectivement à la demande du marché) qu’en « vision » (stratégies : sectorielle, géographique, commerciale, marketing, produit…). Axway et IBM étaient quant à eux déjà « leaders ». Même chose pour Google Cloud, Gravitee, Kong et Salesforce. On ne peut pas en dire autant de SmartBear, qui a rétrogradé chez les « visionnaires ».
Sur l’axe « exécution », la situation est la suivante :
Rang
Fournisseur
Évolution annuelle
1
Google
=
2
IBM
=
3
Salesforce
+ 2
4
Kong
+ 5
5
Boomi
+ 8
6
Axway
– 3
7
Gravitee
+ 3
8
WSO2
+ 6
9
Microsoft
– 5
10
SAP
– 3
11
AWS
– 5
12
Sensedia
+ 5
13
SmartBear
– 2
14
Tyk
– 6
15
Workato
nouvel entrant
16
Postman
– 1
17
Solo.io
– 1
Sur l’axe « vision » :
Rang
Fournisseur
Évolution annuelle
1
Kong
=
2
Boomi
+ 12
3
Gravitee
+ 3
4
Salesforce
+ 3
5
IBM
– 1
6
Google
– 4
7
Tyk
+ 4
8
Postman
– 5
9
Axway
– 4
10
SmartBear
– 2
11
Microsoft
+ 1
12
Workato
nouvel entrant
13
SAP
=
14
WSO2
– 5
15
Sensedia
=
16
Solo.io
– 6
17
AWS
=
Axway : avec le chantier iPaaS, moins d’agilité sur l’IA
Comme l’an dernier, Axway se distingue sur la gestion fédérée des API. Gartner salue de plus le lancement récent d’une brique iPaaS. Il apprécie aussi la manière dont les partenariats (Stoplight, Ping, Graylog, Traceable…) viennent renforcer le modèle économique, au même titre que les acquisitions (en particulier celle de Sopra Banking Software, dont la fusion avec Axway a donné 74Software). Bon point également pour la capacité d’internationalisation, entre documentation multilingue et UI localisées.
Également comme l’an dernier, la notoriété auprès des développeurs reste limitée. Axway est par ailleurs plus lent que la concurrence pour livrer des fonctionnalités IA « avancées » (le focus sur l’iPaaS l’explique en partie, comme la restructuration de sa stack autour de la notion d’événements). Gartner relève, en parallèle, une croissance des ventes bien inférieure à la moyenne du marché.
Boomi manque d’accroche auprès des développeurs
L’année écoulée aura marqué un tournant dans la vision de la gestion des API chez Boomi, de sorte que ce dernier dépend désormais moins du seul iPaaS pour se différencier. L’acquisition d’APIIDA et de TIBCO Mashery a accompagné la refonte de l’offre, assortie d’une feuille de route que Gartner salue. Dans le même temps, la présence commerciale de Boomi s’est étendue, tant du point de vue géographique qu’au travers du renforcement de partenariats (ServiceNow et AWS en particulier).
Sur la gestion des API, Boomi reste, relativement aux autres « leaders », un petit acteur en termes de revenus et de part de marché. Il n’a pas non plus la même empreinte auprès des développeurs (son marketing reste perçu comme axé sur les métiers et les décideurs IT). Vigilance également quant à l’intégration avec les passerelles tierces : elle peut s’avérer complexe.
Apigee « généreusement » poussé comme complément à GCP
Google Cloud se distingue sur le volet innovation, entre autres parce qu’il a greffé à Apigee de quoi favoriser la conception d’API par des agents (avec prise en charge des protocoles A2A et MCP). Gartner apprécie aussi les possibilités offerts en matière de monétisation du trafic IA et de détection des usages abusifs. Il y ajoute la stabilité du produit et sa capacité à remplir les cas d’usage les plus complexes… sous réserve de disposer de l’expertise adéquate.
Google Cloud continue néanmoins à positionner ses produits comme des compléments à GCP plutôt que comme des solutions autonomes. Des clients signalent, de surcroît, qu’on les incite à migrer. Le produit en lui-même est relativement complexe à exploiter. Et malgré des changements positifs sur la tarification, des clients de longue date expriment leur inquiétude quant au rapport coût/bénéfices.
Gravitee n’a toujours pas sectorialisé son offre
Outre un déploiement flexible, Gravitee a pour lui l’indépendance vis-à-vis de tout cloud, progiciel ou iPaaS. Gartner souligne qu’il a su rapidement proposer une passerelle IA gérant le protocole MCP (et destinée à s’ouvrir aux maillages agentiques). Bon point également pour la performance commerciale (CA déclaré en croissance de 70 % sur un an), doublée d’une tarification simple.
Par rapport aux autres « leaders », Gravitee manque de notoriété. Il n’a toujours pas « verticalisé » son approche. Et sa clientèle reste largement concentrée en Europe (les acheteurs sur d’autres plaques géographiques se poseront la question du service et du support).
IBM, peu pris en considération hors de son écosystème
IBM est crédité d’un bon point pour la couverture fonctionnelle de son offre. Il l’est aussi pour la flexibilité de déploiement et la livraison de fonctionnalités axées IA (gestion des prompts, routage LLM). Gartner salue également la diversité de sa clientèle (tailles, régions, secteurs) ainsi que de son réseau commercial et de support.
L’acquisition de webMethods a produit un doublon au catalogue (voire plus si on considère que Red Hat a sa propre offre de gestion d’API), qui demeure en l’état même si IBM a promis une convergence. Big Blue a par ailleurs tendance à toucher essentiellement les organisations qui sont ses clients sur d’autres segments (il est peu évalué sinon). Et sur l’année écoulée, ses ventes ont connu une croissance sous la moyenne du marché.
Kong : une tarification qui peut prêter à confusion
Kong se distingue par les fonctionnalités AI-driven qu’il a livrées dernièrement (génération d’API, de spécifications et de serveurs MCP). Il parvient par ailleurs à conserver une forte visibilité, à renfort d’événements, de partenariats et de présence sur les principales marketplaces. Gartner salue aussi le lancement des Serverless Gateways (passerelles « légères » sans serveur) et de l’Event Gateway (qui permet de gérer des flux Kafka), intégrée avec son maillage de services.
Comme chez Gravitee, pas de solutions sectorielles au catalogue. Attention aussi à la courbe d’apprentissage que supposent les solutions Kong, en plus de la confusion que peuvent susciter la tarification basée sur les services et les frais supplémentaires pour des éléments comme les portails, les tests et l’analytics. Gartner y ajoute une présence limitée en Amérique du Sud, au Moyen-Orient et en Afrique comparé aux autres « leaders ».
Salesforce reste un des fournisseurs les plus chers
En complément à la présence commerciale et au réseau de partenaires, Gartner note que Salesforce a réussi à s’étendre sur le segment SMB (small and medium business, entreprises de moins de 1000 employés), qui représente 30 % du business de MuleSoft. L’intégration avec le reste de son offre a contribué à attirer une grosse base de clientèle. Salesforce jouit globalement d’une grande notoriété de marque, y compris auprès des développeurs.
En plus de rester l’un des fournisseurs les plus chers, MuleSoft présente une structure de prix complexe susceptible d’entraîner des coûts imprévus. Il est par ailleurs perçu comme plus réactif qu’innovant, en particulier pour ce qui touche à l’IA. Et les capacités restent limitées sur la monétisation comme le test d’API, ainsi que la fédération de passerelles.
Découvrez ce qu’est une API, son fonctionnement et ses usages concrets. Comprenez comment les API transforment le web et facilitent la création d’applications.
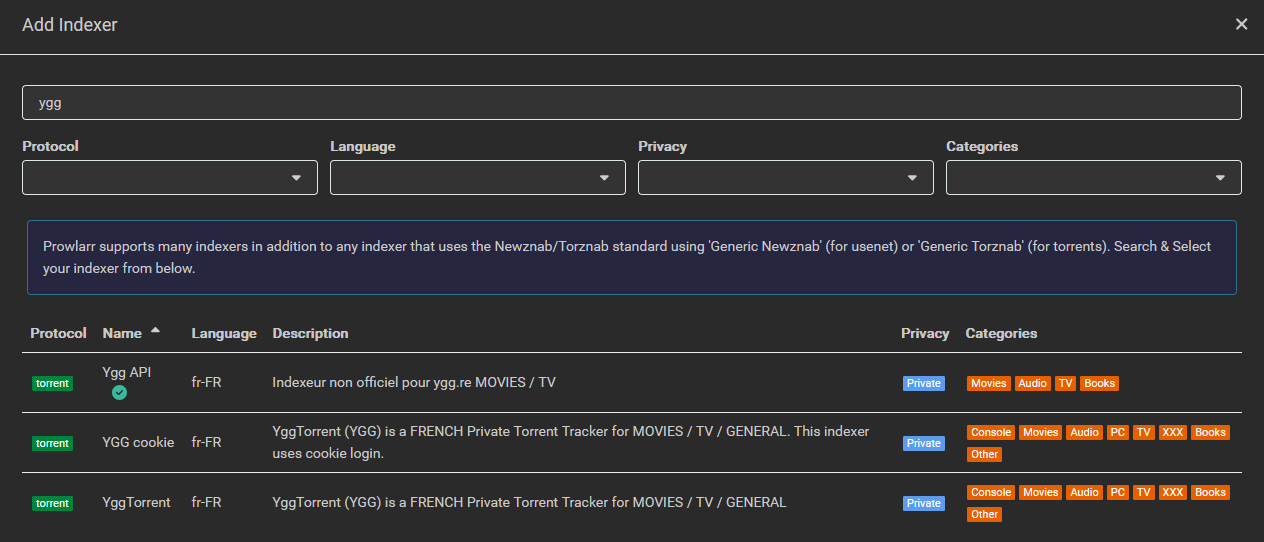
Prowlarr permet de mixer plusieurs indexeurs (BitTorrent/Usenet) pour faire des recherches et téléchargements. Il existe des indexeurs pour YGGtorrent mais ils sont souvent dans les choux du fait de la protection CloudFlare du site. Certes on trouve des outils annexes pour tenter de passer outre mais sinon on peut faire plus simple avec ygg-api (yggapi.eu dont le code n’est pas publié pour ne pas être contré).
Merci à Clemv95 pour le fichier de configuration. Je le poste aussi sur mon blog au cas où.
EDIT du 25.07.25 : Glira fait une remarque qu’il semble bon de transmettre aux néophytes ou à ceux pour qui YGG est quasi leur unique source. Je suppose cependant que la personne derrière ce site n’a absolument pas besoin de nos passkeys pour ce site où il est si facile de se faire un compte et du ratio (sans Joal), tout comme je présume qu’elle est sur les trackers privés francophones…
Attention ce pendant, cette solution envoie votre passkey sur le serveur de yggapi.eu. Et il est extrêmement facile pour lui de les enregistrer. Utilisez ce service que si vous êtes prêt à perdre votre compte ygg en cas d’exploitation de votre passkey. Ou renseignez une fausse passkey, et modifiez le fichier torrent après téléchargement.
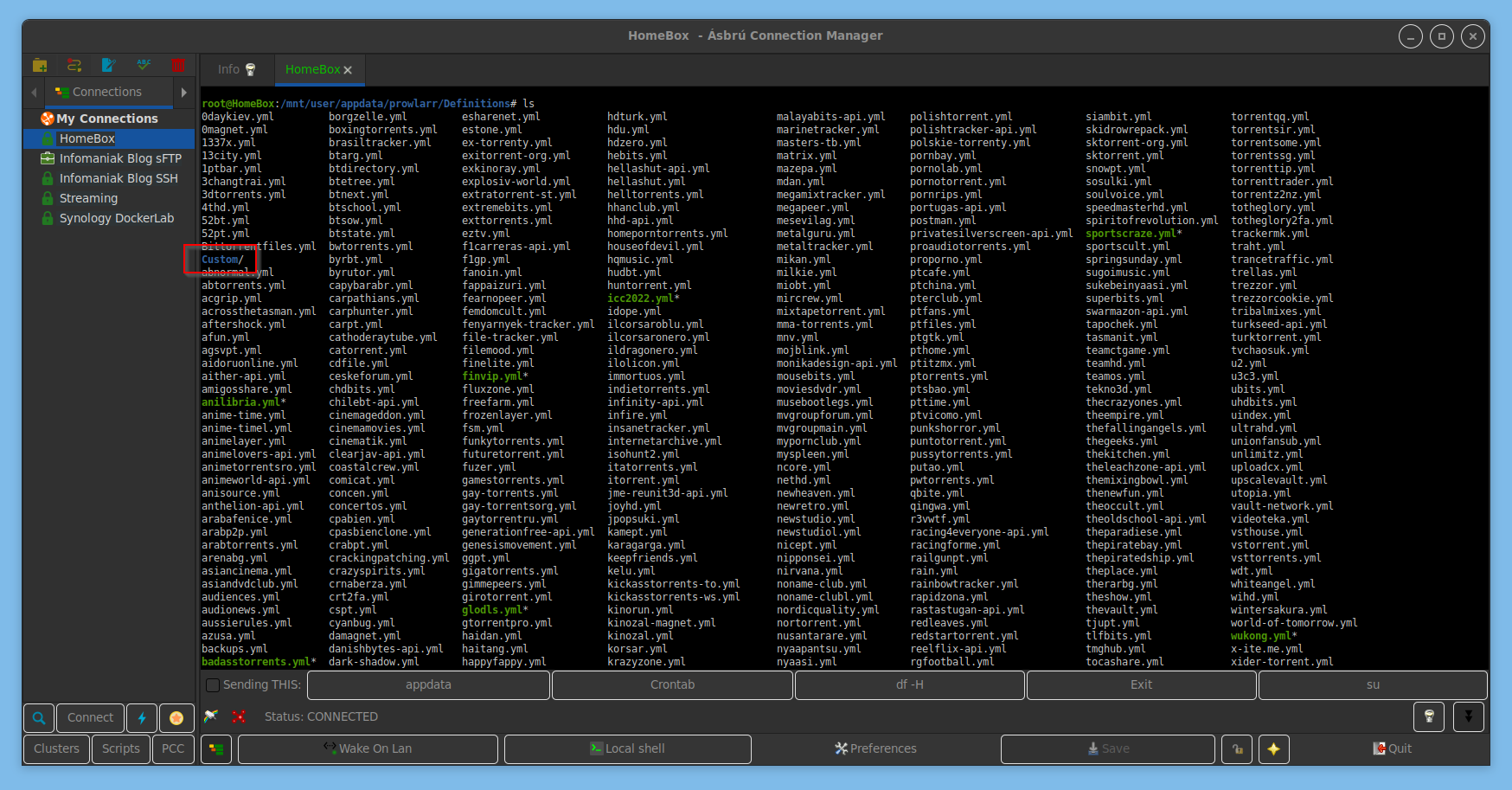
Dans l’installation de Prowlarr, aller dans le dossier Definitions et créer le dossier Custom.
Puis créer/mettre dedans le fichier ygg-api.yml et relancer Prowlarr. Ygg-API est maintenant disponible dans la liste des indexeurs.
Pour le configurer, il suffira d’ajouter une passkey. Trouvable sur son compte YGG ou dans l’URL d’annonce du tracker si vous avez déjà des .torrents de chargés.