Sortie du jeu Bim! en version 12
Bim! est un jeu libre (code AGPL3 et assets CC-by-sa 4.0) multijoueur de type dernier survivant, et qui se joue uniquement en ligne. Il n’est disponible que pour les systèmes Android.
Le jeu est développé depuis plus de deux ans. Jusque-là restreint à quelques pays sur le PlayStore, la sortie de la version 12 marque la mise à disposition de l’app à tous les pays en mode tests ouverts ; c’est-à-dire que vous pouvez installer l’app et même laisser des commentaires mais ceux-ci ne seront pas visibles dans le PlayStore.
En plus du PlayStore, le jeu est disponible sur GitHub, F-Droid, et d’autres magasins alternatifs.
La suite de la dépêche présente les nouveautés des versions publiées depuis la dernière communication en ces pages, soit les versions 11 et 12.

- lien nᵒ 1 : Téléchargement (PlayStore)
- lien nᵒ 2 : Téléchargement (F-Droid)
- lien nᵒ 3 : Code source
- lien nᵒ 4 : Communauté Discord
Sommaire
Bim! est un jeu « à la bomberman ». Deux à quatre joueurs sont dans une arène, le dernier survivant a gagné. Pour combattre, les joueurs posent des bombes dont ils peuvent augmenter la puissance en trouvant les améliorations disséminées dans l’arène. De plus, d’autres bonus peuvent être découverts pour faire varier l’expérience de jeu.
Un pilier dans la création de ce jeu est de proposer aux joueurs de partager un bon moment d’amusement avec d’autres personnes. C’est pourquoi il ne propose aucun mode hors-ligne ni de bots en guise d’adversaires.
Le jeu est disponible en allemand, anglais, brésilien, breton, français, portugais, et turc.
Historique du développement
Le développement du jeu a été régulièrement conté dans des journaux sur LinuxFr.org, au rythme d’un journal toutes les deux versions. J’en profite pour remercier profondément tous ceux qui ont testé ou commenté jusqu’ici :)
Le premier journal, dix mois après la création du dépôt, intitulé Bim! On parle de dev de jeu mobile, de gestion de projet, de dépendances, etc., présente le début du projet, les choix de technos, la mise en place d’outils de dev, et le chemin pour arriver à une première application et un environnement de dev robuste. Au final on obtient une application humble sur laquelle on va pouvoir construire, et bien qu’elle soit en mode texte le mode de jeu en réseau est déjà fonctionnel.
| Première version avec gameplay, dans un terminal | Première version de l’app graphique |
|---|---|
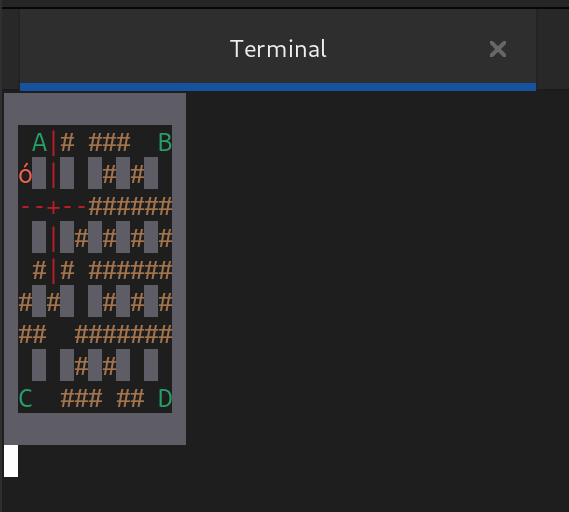 |
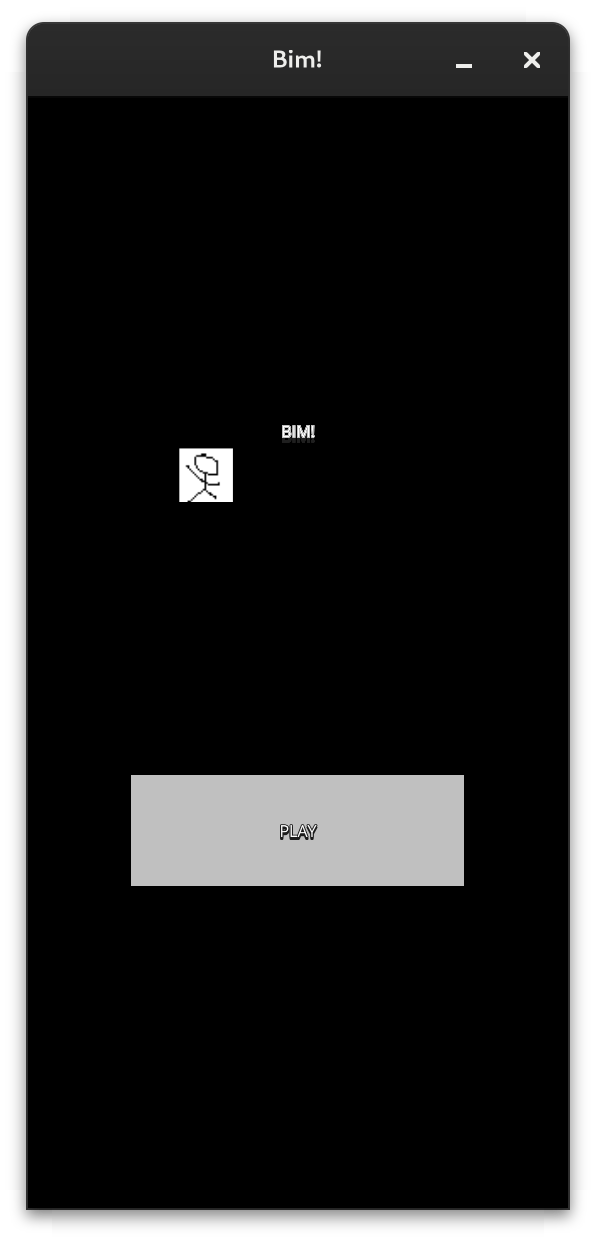 |
Dans le deuxième journal, Dev update du jeu Bim!, on présente les résultats d’une première version graphique, et des problèmes liés à la gestion de sticks logiciels. Des assets temporaires sont utilisés en attendant de valider le fonctionnel.
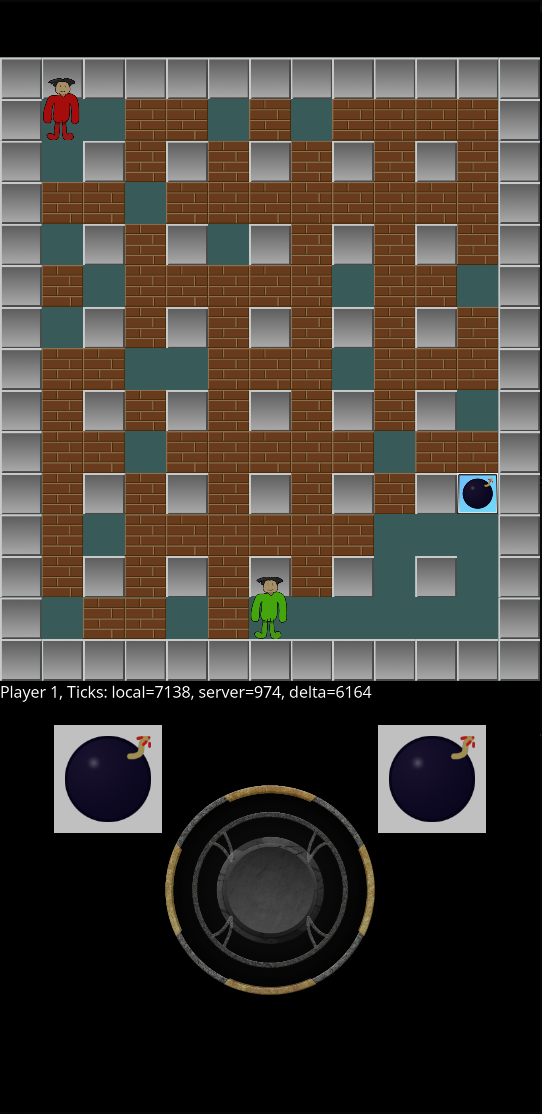
Le troisième journal, Bim! Ça joue là, marque la mise à disposition du premier APK. Les joueurs peu regardants sur l’esthétique du jeu peuvent faire des matchs.

Clique sur l’image pour voir une vidéo du jeu.
Le quatrième journal, Version 2 de Bim!, avec des menus, présente l’interface des premiers menus. L’interface du jeu lui-même est toujours à base de placeholders mais les menus s’approchent d’une esthétique convenable. On y parle aussi de réglages liés au jeu en réseau.

Dans le cinquième journal, Sortie de Bim! en version 3 pour les fêtes, on parle de l’arrivée de l’écran de paramétrage, ainsi que de réglages graphiques suite à des sessions de tests avec joueurs. C’est aussi dans cette version qu’est introduite l’enregistrement des parties sur le serveur afin d’aider à déboguer a posteriori.
| Écran des paramètres | Interface de visualisation des parties enregistrées |
|---|---|
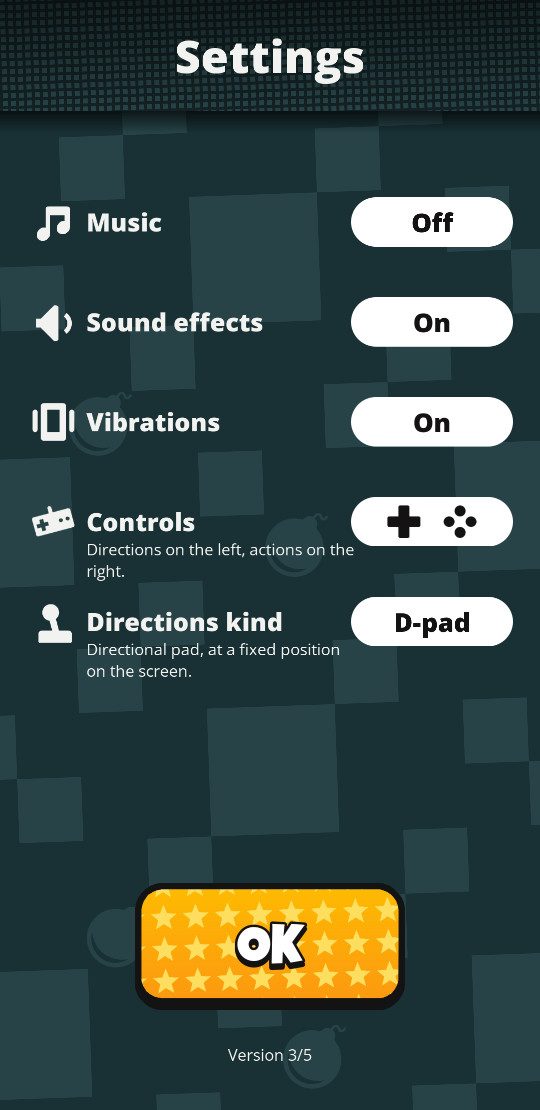 |
 |
Le sixième journal, De beaux graphismes dans la version 4 de Bim!, marque un tournant avec le remplacement des assets du jeu par des graphismes convenables. Ça change tout. L’avatar du joueur, la bombe, les flammes, et les caisses sont le résultat d’une commande à Aryeom. Pour le reste c’est de mon fait, parfois avec des ressources libres trouvées sur le web. On y parle aussi de conso mémoire, d’équité dans la répartition des bonus, et de recherche graphique.
| Capture d’une partie | Recherche d’adversaire |
|---|---|
 |
 |
La version présentée dans le septième journal, Sortie de Bim! en version 6, est la première à ne plus utiliser d’éléments graphiques provisoires. C’est aussi celle qui introduit le mode de jeu avec brouillard de guerre.

Clique sur l’image pour voir une vidéo du jeu.
Dans la version du huitième journal, Ça bouge dans Bim! en version 8, les joueurs sont enfin animés. C’est aussi une version qui contient des contributions externes, notamment le bonus d’invisibilité. Enfin, les joueurs gagnent maintenant des pièces en jouant, leur permettant d’acheter les modes de jeu supplémentaires.
| Animations du personnage | Vidéo du bonus d’invisibilité |
|---|---|
 |
 |
Enfin, le neuvième et dernier journal en date, Sortie de Bim! en version 10, avec un bouclier et des stats, marque l’arrivée du bonus « bouclier » ainsi que d’une refonte graphique des bonus. Cette version est aussi la première à proposer une boutique ainsi qu’à présenter les stats de jeu au joueur. Enfin, grâce à Weblate des contributeurs à travers le monde ont pu proposer de nouvelles traductions.
| Boutique | Statistiques | Bonus |
|---|---|---|
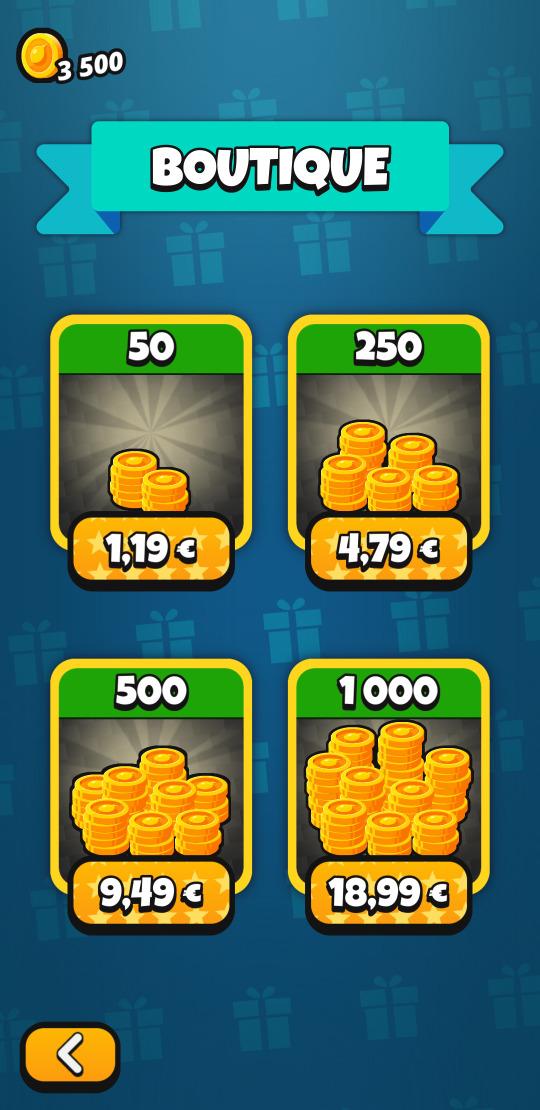 |
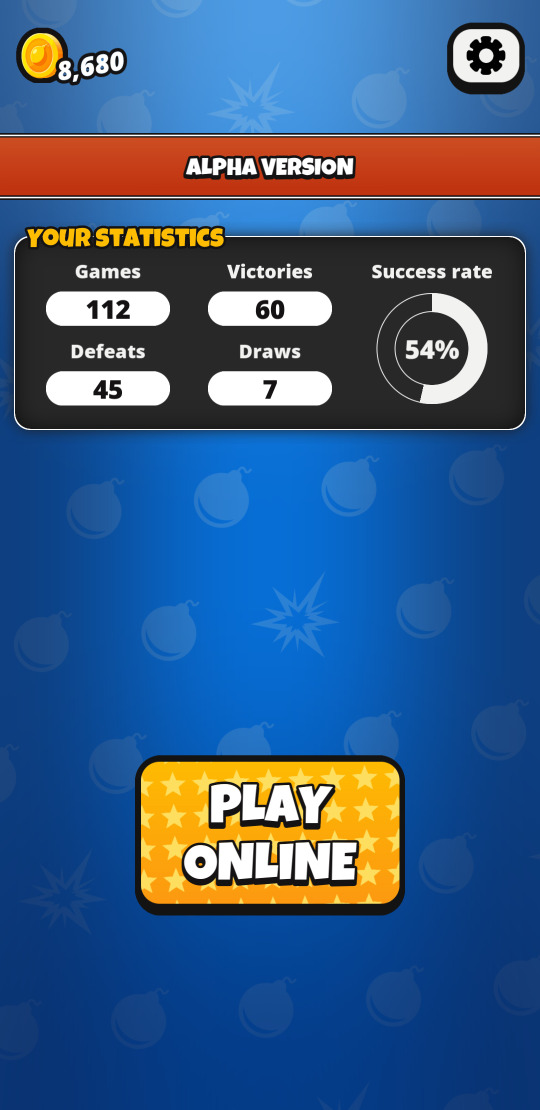 |
 |
Nouveautés des versions 11 et 12
Il n’y a qu’une nouveauté de gameplay dans ces versions, il s’agit d’une modification du comportement des flammes pour qu’elles puissent se croiser. Auparavant une flamme qui en rencontrait une autre était bloquée, ce qui réduisait de fait son pouvoir de destruction. Dorénavant elles s’étendront jusqu’au prochain obstacle solide. Cela rend les fins de parties et les mêlées vachement plus fun.

Du côté des outils j’ai intégré l’instrumentalisation avec Tracy, et j’ai commencé à faire quelques mesures de perf, pour voir où le jeu se situe. Très sympa comme outil, ça me permet de prendre des mesures par frame et de regarder comment l’application se comporte. Il y a aussi la possibilité de tracer des données personnalisées, ce dont je me sers pour suivre le trafic réseau.

Sur cette frame on a une petite pile d’appels (c’est moi qui indique manuellement quelles fonctions doivent être mesurées) qui correspond à l’update du jeu. En rouge on a l’étape de synchronisation avec le serveur, où on joue ce qu’il nous a envoyé pour ensuite simuler les itérations locales. En bleu on a la préparation de l’affichage. Tout cela est inclus dans la section « update », qui contient d’autres trucs non tracés et prend donc une milliseconde sur mon Pixel 3a. Sur la droite il y a une section « draw » qui n’a pas de pile d’appels. Il s’agit de l’affichage proprement dit, géré par Axmol. Ça prend donc 14 ms, ce qui est un peu trop à mon goût. Il faudra que je creuse.
Nouveautés sur le serveur
Le serveur de jeu maintient maintenant des statistiques d’activité sur une fenêtre glissante, à savoir le nombre de parties jouées et le nombre de joueurs connectés. Ces deux métriques sont disponibles en instantané, sur la dernière heure, les 24 dernières heures, et les 30 derniers jours. Ces statistiques sont disponibles dans les logs du serveur mais aussi à la demande des clients.
Ce travail est basé sur une contribution de HanevyN. Dans le cadre de l’utilisation de Bim! comme outil d’apprentissage du C++ présenté dans le journal sur la version 8, cette personne avait choisi la tâche d’intégrer des statistiques au serveur. Le problème à résoudre était mal spécifié, mais nous avons trouvé une reformulation plus réaliste qui a ensuite bien occupé ce contributeur. Lorsqu’il n’a plus pu se charger de ce développement j’ai pris la suite pour le finaliser et l’intégrer au dépôt.
Nouveautés sur le client.
Les transitions entre les écrans sont maintenant animées ! C’est vachement plus agréable. Avec l’arrivée d’animations dans les menus j’ai dû remettre le framerate à 60 dans ces derniers parce que sinon c’était trop saccadé.
Affichage de statistiques du serveur
Autre nouveauté sur le client, il affiche maintenant une statistique du serveur. À l’origine de cette fonctionnalité il y a une demande d’un utilisateur reçue par courriel :
Bim is such a great game, but sometimes I join for a casual match, and there is no one playing. Sometimes I sit in the lobby for 2 minutes to check if someone else's game ends and join them, but it would be even greater to have a games in progress count in the lobby.
Le problème de cette personne est qu’elle lance une recherche d’adversaire et la laisse tourner sans jamais voir de joueur la rejoindre. C’est très frustrant en effet. Cette personne propose d’avoir une indication sur l’écran principal de l’application du nombre de parties en cours.
C’est quelque chose que j’avais auparavant refusé de faire, car la plupart du temps cela affichera zéro, et si c’est zéro sans doute que les joueurs qui ouvrent l’app ne vont pas tenter de lancer un match, ce qui ne va pas aider à faire monter le compteur.
Cependant, suite à ce message, j’ai réfléchi à la possibilité de suggérer l’activité sur le serveur mais de manière toujours positive. L’idée est d’indiquer le nombre de parties en cours mais de se rabattre sur une indication du nombre de joueurs connectés s’il n’y a pas assez de matchs en cours. Et s’il n’y a pas trop de joueurs, alors on se rabat sur des mesures agrégées sur la dernière heure, puis les 24 dernières heures, puis les 30 derniers jours. Ça tombe bien, j’avais toutes ces mesures sur le serveur !
Ça me semble être un bon compromis. On ne voit pas qu’il n’y a personne, mais on voit que le jeu n’est pas à l’abandon.
Boutons pour la boutique et les stats sur le lobby.
J’ai fait pas mal d’UI dans ces versions à commencer par ajouter un bouton permettant d’accéder à la boutique et un autre pour afficher les statistiques du joueur. Auparavant on accédait à la première en cliquant sur le solde de pièces et les secondes étaient affichées directement sur l’écran principal.
Le plus simple pour moi, quand je dois faire ce genre de bouton, est de commencer par des croquis pour dégrossir les idées.

En haut à gauche on voit la base du bouton. L’icône est trop petite, et le libellé trop rigide ; je l’ai donc incliné (c’est une des lignes directrices que j’applique pour l’interface, d’avoir des inclinaisons, pour donner un sentiment de dynamisme). Pour l’icône je me suis posé plein de questions sur la taille du store, la forme de la porte, les proportions… D’où le lot de croquis.
Pour l’icône des statistiques c’était plus simple, il y avait moins de questions. Enfin, il y a surtout eu des questions de couleurs mais ça je ne le travaille pas sur le carnet.
Au final ça donne ça. J’ai peut-être fait un peu de zèle pour l’icône de la boutique, sans doute que je voulais impressionner mon enfant qui me regardait dessiner dans GIMP (ça a marché :)).

Intégration d’un outil d’analytics
L’application Android intègre maintenant une remontée de statistiques anonymes sur son utilisation. L’outil que j’ai choisi est PostHog, qui a le bon goût d’être libre, auto-hébergeable, de proposer le stockage des données en Europe, d’avoir une offre gratuite, et de permettre une remontée des statistiques sans identification de l’utilisateur.
Grâce à cet outil j’ai maintenant une idée de ce qu’il se passe sur le client ; notamment le nombre d’utilisateurs par jour, ou encore la proportion de joueurs qui cherchent et trouvent un adversaire.
Écran de sélection des fonctionnalités de jeu.
Le déblocage et la sélection des fonctionnalités de jeu se faisaient auparavant sur l’écran de recherche d’adversaire. Les joueurs pouvaient activer la chute de blocs, les boucliers, le brouillard, ou encore l’invisibilité depuis cet endroit. Dans la nouvelle version cette sélection se fait maintenant sur un écran dédié, accessible depuis le lobby. De plus, seules deux options peuvent être activées par joueur. Cela permettra d’avoir un peu plus de variété et de surprise dans les matchs en combinant les fonctionnalités activées par les uns et les autres.
Cet écran a été un très gros chantier, avec pas mal de code qui n’était pas prêt mais que je ne le savais pas et que donc j’ai dû m’interrompre plein de fois pour préparer ce code que j’aurais dû écrire en amont. Galère.
Déjà sur les croquis ont voit que ça n’allait pas être simple.

J’avais envisagé une vue grille (en haut à gauche) pour ensuite m’orienter sur une liste de fiches présentant chaque fonctionnalité (milieu gauche). J’avais besoin d’emplacements où poser les éléments sélectionnés par le joueur, que je mettais en haut sur les croquis, sans trop savoir s’ils allaient être en ligne ou en pyramide, inclinés ou horizontaux.
Étonnamment dès lors que j’ai ouvert GIMP pour faire une maquette j’ai abandonné l’idée des fiches en faveur de la grille. La longue liste de fiches m’a semblé soudain peu attrayante par rapport à une grande grille qui montrerait au premier coup d’œil la variété de l’offre.
J’ai ajouté une zone de présentation de chaque fonctionnalité ainsi qu’une petite notice explicative, et j’ai fait beaucoup d’essais pour déterminer la couleur des contours des boutons.

Et au final, quand j’ai mis ça dans l’application, eh bien j’ai jeté la petite explication pour la fusionner dans la nouvelle boîte de présentation des fonctionnalités ! On avance clairement à tâtons sur cet écran.

Il faut savoir qu’il y a aussi beaucoup d’animations liées aux interactions sur cet écran, mais évidemment ça ne se voit pas sur les images :)
Quelques statistiques
À chaque communication je présente quelques statistiques du jeu. Comme d’habitude je vais sortir des graphiques à partir des logs du serveur, mais cette fois j’ai aussi des mesures intégrées au client grâce à PostHog ; je vais donc pouvoir sortir quelques graphes supplémentaires. Commençons par le nombre de joueurs par jour :

On y voit clairement le déploiement des deux mises à jour. Dès lors que ça arrive sur F-Droid il y a plein de joueurs qui débarquent. Ensuite voici le nombre de parties par jour (logs serveur) :

Une chouette info que me donnent les mesures sur le client est la proportion de joueurs qui lancent une recherche d’adversaire et trouve effectivement quelqu’un :

Sur un autre graphe que je n’affiche pas ici, j’apprends que les joueurs restent en moyenne 17 secondes sur la recherche d’adversaire avant de laisser tomber.
En termes de répartition du nombre de joueurs par partie, cela donne :
| Nombre de joueurs | Nombre de parties |
|---|---|
| 2 | 708 |
| 3 | 182 |
| 4 | 42 |
Et enfin, pour la répartition des joueurs par pays, on a :

Ce sera tout pour cette fois. On se retrouve en match :)
Commentaires : voir le flux Atom ouvrir dans le navigateur


