Statistiques 2025 du site LinuxFr.org
2025 est amené son lot de changements : un trafic en hausse principalement en raison des moteurs de recherche et d’IA et du spam, plus de contenus publiés mais moins de commentaires. Que cela ne nous empêche pas de revenir sur l’année passée, l’activité du site LinuxFr.org, les détails des changements en termes de trafic Web, de contenus créés, de commentaires déposés, de navigateurs utilisés, d’utilisation des fonctionnalités du site, de contribution au code, etc. Bref, quelles sont les tendances ?
Le site rend accessible un grand nombre de statistiques (faites‑vous plaisir si vous souhaitez vous plonger dedans, c’est fait pour) ; cette dépêche résume les variations constatées en 2025.
Nb: le podcast Projets Libres fournit aussi des statistiques publiques.
- lien nᵒ 1 : Ensemble des statistiques du site
- lien nᵒ 2 : Espace de rédaction collaborative
- lien nᵒ 3 : Dépêche sur les statistiques 2024 du site LinuxFr.org
- lien nᵒ 4 : Nouvelle année, vœux 2026, voyageons dans le temps
Sommaire
- Statistiques Web
- Contenus
- Modération
- Commentaires
- Notes
- Étiquettes (tags)
- Équipe de bénévoles
- Code et développement
- Comptes utilisateur
- Soucis divers
Statistiques Web
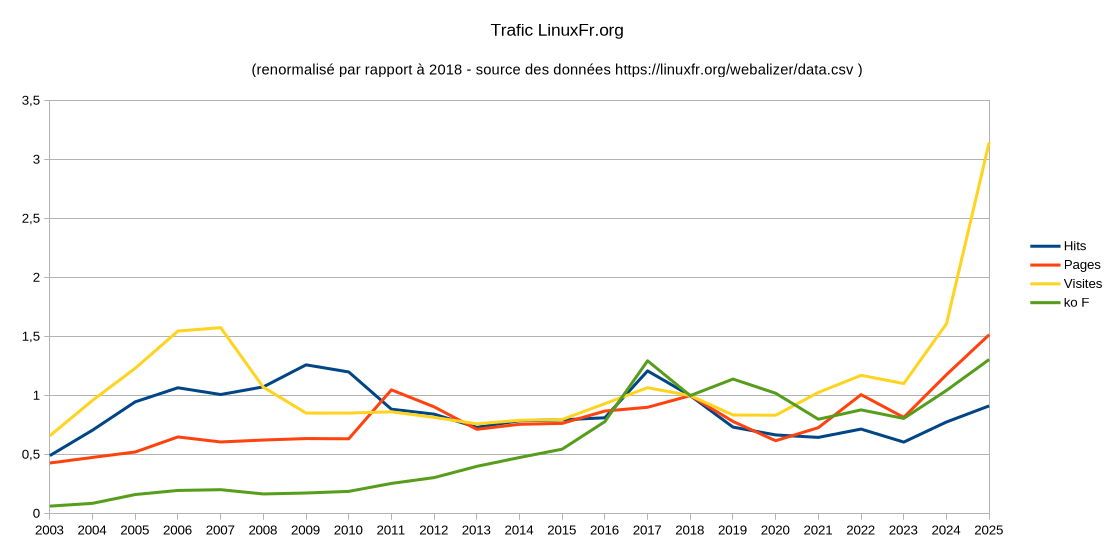
La comparaison des statistiques annuelles (voir 2024 et 2025, les deux comportant des effets de bots bourrins visiblement) montre un quasi doublement des visites, hausse des consultations (pages, fichiers) et des hits (notamment l’effet des bots pour l’intelligence artificielle), avec un passage à ~996 000 hits par jour et ~149 800 visites par jour, le tout pour ~1,77 Tio par mois.
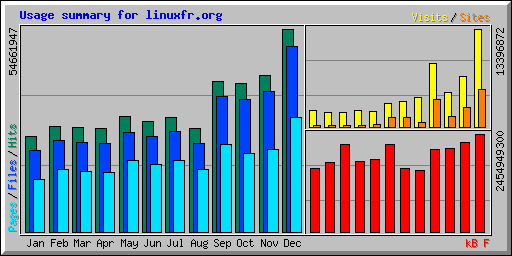
Le nombre de contenus publiés en un an augmente de 10 %. Le nombre de commentaires publiés en un an diminue cette année de 3%.
Contenus
Au 31 décembre 2025, le site comportait environ 123 820 contenus publiés répartis ainsi :
- 28 185 dépêches :
- 386 dépêches publiées en 2025 (➡️, 383 en 2024),
- la taille moyenne (en code Markdown, hors images donc) des dépêches a encore très nettement augmenté, battant le précédent record de 2019 ;
- 40 701 journaux (↗️, 409 en 2024 et 460 en 2025),
- 41 047 entrées de forums (↘️, 458 en 2024 et 406 en 2025),
- 11 140 liens (↗️,2050 en hausse par rapport aux 1714 en 2024),
- 475 sondages (10 en 2024 et 7 en 2025),
- 159 pages de wiki (5 en 2024 et 2 en 2025).
Pour la première année, le pic de publication des contenus se confirme le mercredi. Ce qui continue à différer désormais du pic de modération, voir la partie Modération plus bas).
Un jour de semaine compte 64 % de publications en plus qu’un jour de week-end.
La publication sous licence Creative Commons By-SA se fait par défaut depuis les dix ans de CC, fin 2012 pour les dépêches (permet explicitement une rédaction collaborative ou un renvoi en re‐rédaction) et les journaux (qui peuvent être convertis en dépêches) : tout naturellement, on retrouve 97 % de dépêches et 99 % des journaux sous cette licence au final (les autres étant notamment sous licence Art Libre ou autre, au choix de l’auteur).
Les dépêches collaboratives (et pas uniquement celles réattribuées à l’utilisateur Collectif) sur de multiples sujets sont toujours à compter parmi les vraies réussites du site ; nous sommes cependant toujours à la recherche de volontaires pour couvrir les nombreux sujets qui n’ont pu être abordés. Une liste des thèmes récurrents sur LinuxFr.org peut donner des idées de participation : si une dépêche n’a pas été créée dans les temps, tout inscrit peut la démarrer dans l’espace de rédaction.
Concernant la visibilité par contenu (analyse sur décembre 2023) : les journaux ont jusqu’à deux fois moins de visibilité que les dépêches (faites des dépêches…) et les liens ont beaucoup moins de visibilité que les journaux et les dépêches (préférez donc faire des dépêches ou des journaux, pour la visibilité).
Modération
Le temps moyen passé entre la création d’une dépêche (en rédaction ou directement envoyée en modération) et sa modération et publication est de 600 (!) heures (contre 309 h en 2023 et 337 h en 2024) ; la mesure du temps passé uniquement en modération n’est pas actuellement disponible (et la modération retient volontairement des dépêches non urgentes pour réguler la publication) ; le temps médian est descendu à 22 heures. Il y a des demandes de statistiques dans le suivi, envoyez les demandes d’intégration Git (pull‐requests). ;-)
Le jour préféré de modération a priori des contenus est toujours le mardi pour les dépêches et le lundi pour les sondages.
Commentaires
Au 31 décembre 2025, le site comporte 1,97 million de commentaires. Le nombre de commentaires publiés en un an baisse cette année de 3 % pour arriver à 31 011.
Il y a désormais, en moyenne, 24 commentaires par journal (29 en 2023 et 29 en 2024), 9 par dépêches (9 en 2023 et 9 en 2024), 47 par sondage (54 précédemment, mais très dépendant des sondages considérés), 9 par entrée de forum (7 en 2023 et 8 en 2024), 2 par entrée de suivi, 6 par lien (contre 7 en 2023 et 7 en 2024) et une poignée par page wiki.
Le jour préféré pour commenter reste le mercredi, et un jour de semaine compte deux fois plus de commentaires qu’un jour de week-end.
Notes
Il n’y a (toujours) pas de statistiques disponibles concernant les notes. Les entrées de suivi sur les statistiques n’ont pas avancé.
Néanmoins diverses statistiques concernant la notation sur les contenus et les commentaires ont été données en juin 2021, avec des graphes.
Étiquettes (tags)
Au 31 décembre 2025, le site comporte :
- 16 502 étiquettes, dont 13 594 étiquettes publiques (contre 12 867 fin 2024) ;
- 195 491 saisies d’étiquettes (étiquetées en moyenne treize fois pour les étiquettes publiques et cinq fois pour les étiquettes privées) ;
- les étiquettes sont réparties ainsi par contenu :
- 68 367 pour les dépêches,
- 54 720 pour les journaux,
- 31 732 pour les forums,
- 38 903 pour les liens,
- 835 pour les pages wiki,
- 397 pour les sondages,
- 537 pour le système de suivi des défauts et évolutions.
Plus de détails dans la dépêche de février 2022 À propos des étiquettes sur le site LinuxFr.org.
Depuis le début du site, on constate en moyenne 5 étiquettes par page wiki, 3,5 par lien, 2,4 par dépêche, 1,3 par journal, 0,8 par sondage, 0,8 par entrée de forum et 0,3 par entrée du suivi.
Le jour préféré pour apposer des étiquettes est le lundi (biais de la création initiale des étiquettes), suivi du samedi.
Il y a plusieurs biais concernant les étiquettes :
- beaucoup ont été et sont ajoutées automatiquement ;
- le thème mobile par défaut ne montre pas les étiquettes (sauf à basculer son Firefox en « Version ordinateur » ou équivalent sur un autre navigateur).
Équipe de bénévoles
Il y a actuellement 4 personnes pour l’administration du site, 11 pour la modération, 6 pour l’animation de l’espace de rédaction et 2 pour la maintenance qui font tourner ce site. Pour mémoire, il s’agit de bénévoles plus ou moins disponibles et donc absolument pas de 23 équivalents temps plein pour jargonner comme une entreprise. Merci pour le travail accompli.
Code et développement
Au 31 décembre 2025, le système de suivi de défauts et de demandes d’évolutions contient 285 entrées ouvertes (contre 269 en 2024). On voit assez rapidement un manque de développeurs apparaître. En 2025, il y a eu 34 entrées ouvertes (contre 54 en 2024) : 20 entrées encore ouvertes venant s’ajouter à celles datant d’avant, 12 corrigées et 2 déclarées invalides. On peut noter que ceux qui ouvrent le plus d’entrées sont des membres actuels ou anciens de l’équipe du site.
C’est Bruno qui garde le record de correction d’entrées. Merci aussi à Adrien Dorsaz. Le temps moyen de résolution est de 164 jours (contre 166 précédemment). La moitié des entrées fermées ont été traitées en moins de sept jours. On ressent donc toujours un besoin de nouveaux contributeurs côté code.
La charge moyenne sur le serveur est de 1,4 sur la machine actuelle (baptisée oups). La charge minimale a été de 0,8 et la maximale de 3,6.
La consommation mémoire est restée stable (en dépit de la perte d’une barrette de mémoire). Le trafic réseau sur la partie Web uniquement est en croissance à 9,1 Mbit/s sortants.
Comptes utilisateur
Au 31 décembre 2025, sur les 53 375 comptes utilisateur valides existants, 2 215 ont été utilisés au cours des trois derniers mois, dont 31 % (-2) ont déjà rédigé des dépêches, 41 % (-4) des journaux, 42 % (-3) des entrées de forums, 10 % (-1) des entrées dans le système de suivi, 17 % des liens (=) et 2 % une page de wiki ; 80 % (-7) ont écrit des commentaires et 48 % (-4) étiqueté des contenus ; 32 % (-1) ont contribué sur au moins une dépêche ; 24 % (-3) des comptes actifs ont indiqué un site personnel, 8 % (=) un identifiant XMPP, 6 % (+1) une adresse Mastodon, 28 % (-1) un avatar et 6 % (=) une signature.
Côté utilisation des fonctionnalités, 14 % (=) ont demandé à ne pas afficher les contenus avec une note négative, 8 % (-1) ont demandé le tri chronologique en page d’accueil, 5 % (-1) à ne pas voir les avatars, 4 % (-1) à afficher la tribune dans une boîte latérale et 3 % (=) à ne pas voir les signatures, et à peine quelques pourcents ont changé les contenus par défaut en page d’accueil (souvent pour retirer les sondages et ajouter les journaux). Peu de feuilles de style CSS du site sont utilisées : quatre visiteurs sur cinq utilisent celle par défaut ; il est facile d’en changer avec le lien Changer de style. En janvier 2024, il n’y avait pas de rupture générationnelle marquée entre les comptes 1999 et 2024 en termes d’utilisations des fonctionnalités.
Seuls huit comptes ont un karma négatif et zéro ont un karma nul, soit 0 % des visiteurs actifs ; 18 % des comptes actifs durant les trois derniers mois ont été créés en 2025 (+8 points, avec probablement un biais dû aux spammeurs).
32 % (+2) des visiteurs actifs ont une adresse de courriel GMail, 11 % (-1) chez Free, 3 % (-1) chez LaPoste, 3 % (=) chez Yahoo, 3 % (=) chez Hotmail ou Outlook et 2 % (=) chez Orange ou Wanadoo.
Les visiteurs actifs ont des adresses XMPP chez jabber.fr, gmail.com, im.apinc.org, jabber.org, movim.eu et chapril.org notamment. Et des adresses Mastodon chez mastodon.social, piaille.fr, mamot.fr, framapiaf.org, pouet.chapril.org et mastodon.tetaneutral.net notamment.
2025 correspond aussi au second anniversaire de la mise à place des nouvelles règles de pérennité des comptes LinuxFr.org et données à caractère personnel.
Soucis divers
Le compteur d’années sans mises en demeure reçues passe à quatre (après deux mises en demeure en 2019 et une en 2020, voir la dépêche sur la no 3 en attendant la publication d’informations sur les no 4 et 5). Mais un courriel d’avocat est néanmoins arrivé dans l’année 2025.
/ Only five formal notices in the default \
\ install, in a heck of a long time! /
-----------------------------------------
\
\
.--. / Ouep... \
|o_o | \ Euh coin /
|:_/ | ----------
// \ \ \
(| | ) \
/'\_ _/`\ \ >()_
\___)=(___/ (__)__ _
Depuis la création du site, statistiques liées au légal (dans les sens liés à la force publique ou à du juridique) :
- cinq mises en demeure reçues (pour zéro assignation) ;
- une réquisition judiciaire reçue (qui au final ne nous concernait pas, mais a donné l’occasion de discuter avec la police nationale) ;
- un cas d’usurpation d’identité et de harcèlement type « revenge porn » (discussion avec la gendarmerie nationale).
Commentaires : voir le flux Atom ouvrir dans le navigateur