Top 7 outils de monitoring maison (NAS/serveur)
Installer et gérer son propre monitoring à la maison — pour un NAS, un serveur domestique, quelques VM ou un mini-lab — c’est un excellent moyen d’apprendre l’observabilité tout en gardant le contrôle des données. Dans cet article je te présente 7 solutions pour 2026, quand les choix sont pertinents je montre rapidement pour quel usage chaque outil est pertinent et comment l’installer en gros (astuces pratiques, snippets). Je me concentre sur des stacks “Grafana-like” (tableaux, séries temporelles) avec alerting natif ou via intégration — et je donne des pièges à éviter pour un usage maison.
Pourquoi un monitoring “maison” plutôt qu’un service cloud ?
Un monitoring local c’est intéressant si tu veux :
- garder toutes les métriques chez toi (confidentialité) ;
- éviter des coûts récurrents quand le nombre de métriques/stockage augmente ;
- personnaliser les dashboards et alertes pour équipement domestique (disques SMART, bruit/fan, UPS, etc.) ;
- expérimenter avec Prometheus/TSDB, stockage à long terme, ou exporter vers Grafana Cloud plus tard.
Un monitoring auto-hébergé implique quelques contraintes à connaître : les métriques s’accumulent avec le temps et occupent de l’espace disque, les interfaces web ne doivent pas être exposées sans protection, et certains outils peuvent être assez gourmands en mémoire ou en CPU.
Les 7 outils recommandés
| Outil | Meilleur pour | Alerting | Stockage TSDB | Facilité d’installation (maison) |
|---|---|---|---|---|
| Prometheus (avec Alertmanager) | Monitoring métriques, intégration exporters | Oui (Alertmanager) | TSDB native (local) | Docker/packaged; learning curve |
| Grafana | Dashboards (visual) front-end | Alarme via Grafana Alerts | UI front, s’appuie sur TSDB | Docker/apt ; quasi-standard |
| InfluxDB (+Telegraf) | Séries temporelles simple, IoT | Oui (Kapacitor/Flux ou alerts InfluxDB 3.x) | TSDB spécialisé | Docker ; simple pour petits setups |
| VictoriaMetrics | Stockage haute performance / remplacement long-term | Intégration avec Alertmanager / Grafana | TSDB performante, compacte | Très docker-friendly |
| Netdata | Monitoring temps-réel, faible config | Alarms légères ; forwarding | Time-series local + cloud option | Installation one-liner (très simple) |
| Zabbix | Supervision full-stack (alertes, inventaire) | Oui, système d’alerting mature | DB relationnelle (MySQL/Postgres) | Stable mais plus lourd |
| LibreNMS / Checkmk | Monitoring réseau & infra small/medium | Oui, templates d’alertes | SQL backend | Bon pour NAS réseaux, SNMP |
1) Prometheus + Alertmanager (le cœur métriques « classique »)
Cas d’usage : servir de collecte pour métriques d’OS (node_exporter), services (cAdvisor, MySQL exporter), NAS (SNMP exporter), VM. Prometheus scrappe périodiquement des endpoints HTTP exposant des métriques.
Pourquoi le choisir :
- modèle pull simple et puissant pour environnements locaux ;
- Rules + Alertmanager = alertes flexibles ;
- large écosystème d’exporters.
Astuce d’installation rapide (maison) :
- lancer Prometheus en Docker ou binaire ; ajouter
node_exportersur chaque machine. - exemple minimal
prometheus.yml(scrape node_exporter sur hôte local) :
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ['192.168.1.10:9100'] # ton NAS/serveur
- pour les alertes, configurer Alertmanager et une règle Prometheus :
groups:
- name: nodes
rules:
- alert: HostDown
expr: up == 0
for: 5m
labels:
severity: critical
annotations:
summary: "Hôte indisponible ({{ $labels.instance }})"
Piège courant : conserver la TSDB localement sans rotation = disque plein. Fixe --storage.tsdb.retention.time ou utilise une solution long-term (VictoriaMetrics/remote_write). (Voir doc Prometheus).
2) Grafana (front-end de dashboards, alerting intégré)
Cas d’usage : création de tableaux riches (graphs, heatmaps, logs si Loki), mode multi-datasource (Prometheus, InfluxDB, VictoriaMetrics).
Pourquoi le choisir :
- standard de facto pour dashboards ;
- Alerts améliorés (Grafana Alerts) et intégration avec contact points (Telegram, e-mail, Discord).
- version OSS robuste pour usage perso.
Astuce pratique :
- utilise Grafana pour visualiser Prometheus + node_exporter ; si tu veux logs, ajoute Grafana Loki.
- sécurise l’accès : reverse proxy + auth (let’s encrypt + oauth proxy) si tu ouvres internet.
3) InfluxDB + Telegraf (stack « simple » pour métriques et IoT)
Cas d’usage : capteurs IoT, métriques custom, séries avec écriture push (Telegraf, clients HTTP).
Pourquoi le choisir :
- flux d’écriture simple (push) via Telegraf ;
- langage Flux et alerting natif dans InfluxDB 3.x ;
- facile à configurer sur NAS/serveur.
Astuces :
- utiliser Telegraf sur chaque machine pour collecter CPU, disque, SMART, snmp.
- config de retention et downsampling natif dans InfluxDB pour éviter explosion de stockage.
4) VictoriaMetrics (TSDB haute performance)
Cas d’usage : si tu veux conserver un historique long sans trop consommer I/O/CPU — idéal comme remote_write pour Prometheus (long-term storage).
Pourquoi le choisir :
- conçu pour stockage efficace des métriques à long terme, très docker-friendly ;
- fonctionne bien sur hardware modeste et permet compression efficace. GitHub
Mise en œuvre rapide :
- Prometheus →
remote_writevers VictoriaMetrics ; Grafana se connecte directement pour dashboards. - vérifie paramètres de retention et snapshots pour backups.
5) Netdata (monitoring temps réel, install “one-liner”)
Cas d’usage : super pour visualiser en temps réel l’activité d’un NAS / serveur (io, network, processus), diagnostique rapide.
Pourquoi le choisir :
- installation très facile (
bash <(curl -Ss https://my-netdata.io/kickstart.sh)), UI instantanée ; - alerting simple et possibilité de forwarding vers Grafana/Prometheus. Netdata+1
Limite : pas conçu comme TSDB longue durée par défaut ; utile en complément (diagnostic) plutôt que stockage historique complet.
6) Zabbix (supervision complète, alerting & inventaire)
Cas d’usage : inventaire/monitoring d’un parc d’équipements (SNMP, agents), règles d’alerte avancées, escalation.
Pourquoi le choisir :
- mature en alerting, templates (NAS, routeurs, services) ; bonne GUI pour opérations. Zabbix
Astuce :
- utiliser Zabbix pour supervision réseau (SNMP) et Prometheus/Influx pour métriques fines : on combine les forces.
7) LibreNMS / Checkmk (monitoring réseau et infra simple)
Cas d’usage : découverte automatique réseau, SNMP pour switchs/NAS/routeurs, alertes sur perte d’interfaces/temps de réponse.
Pourquoi le choisir :
- LibreNMS : communauté, facile pour SNMP auto-discovery ;
- Checkmk : bonnes règles prêtes à l’emploi pour serveurs/NAS. LibreNMS Community+1
Astuce :
- active SNMP sur ton NAS (versions sécurisées v3) et laisse LibreNMS faire la découverte ; applique des alertes sur erreurs SMART et perte d’interface.
Tableau comparatif détaillé
| Outil | Type | Idéal pour | Alerting natif | Facilité Docker | Ressources |
|---|---|---|---|---|---|
| Prometheus | TSDB + scraping | métriques infra | Oui (Alertmanager) | Oui | Moyen |
| Grafana | UI | dashboards multi-source | Oui (alertes) | Oui | Faible-Moyen |
| InfluxDB | TSDB push | IoT, séries | Oui (Flux/alerts) | Oui | Moyen |
| VictoriaMetrics | TSDB long-term | stockage compressé | Intégration AM | Oui | Faible-Moyen |
| Netdata | Monitoring realtime | diag & live | Alerting léger | Oui | Faible |
| Zabbix | Supervision full | alerting & inventaire | Oui (avancé) | Oui (compose) | Moyen-Fort |
| LibreNMS | SNMP monitoring | réseau & NAS | Oui | Oui | Faible-Moyen |
Qu’est-ce que vous pouvez déployer sur votre NAS UGREEN ou Synology ?
Sur un NAS moderne, l’objectif n’est pas de transformer la machine en usine à gaz. Ce qu’on cherche, c’est un monitoring fiable, lisible et utile au quotidien, sans dégrader les performances du stockage.
 Le stack recommandé : Prometheus + Grafana (+ node_exporter)
Le stack recommandé : Prometheus + Grafana (+ node_exporter)
C’est aujourd’hui le meilleur compromis entre simplicité, efficacité et évolutivité sur un NAS.
Modèles compatibles (exemples concrets)
- UGREEN DXP4800 Plus (ou équivalent x86 avec Docker)
- Synology DS925+
Ces modèles disposent :
- d’un CPU x86 correct
- de Docker officiellement supporté
- de suffisamment de RAM pour faire tourner Prometheus sans impacter les services NAS
À quoi sert ce stack, concrètement ?
1⃣ Surveiller l’état réel de votre NAS
Avec node_exporter, vous récupérez automatiquement :
- charge CPU
- mémoire utilisée
- espace disque et IO
- réseau (débits, erreurs)
- uptime et reboot
- températures (selon support matériel)
 En clair : vous savez si votre NAS souffre, et pourquoi.
En clair : vous savez si votre NAS souffre, et pourquoi.
2⃣ Visualiser clairement ce qui se passe (Grafana)
Grafana sert d’interface graphique.
Vous obtenez :
- des dashboards lisibles (journée, semaine, mois)
- des graphiques compréhensibles même sans être admin système
- une vue globale de la santé du NAS
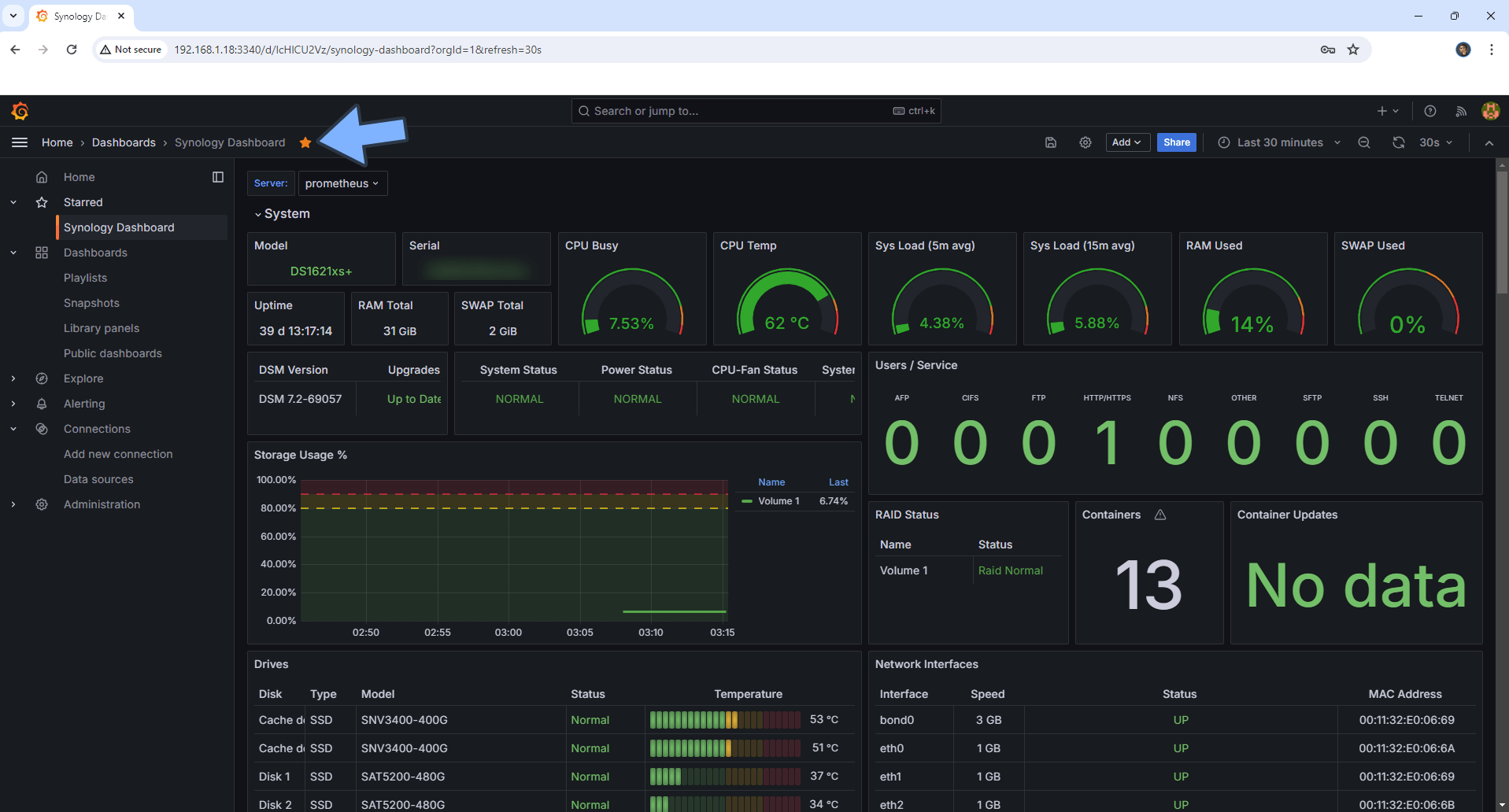
Exemple concret :
Vous voyez immédiatement si un disque devient lent, si la RAM est saturée ou si un conteneur consomme trop.
3⃣ Être alerté avant que ça casse (Prometheus)
Prometheus ne fait pas que stocker des métriques, il permet aussi de déclencher des alertes.
Cas d’usage très concrets :
- NAS inaccessible depuis 5 minutes
- espace disque < 10 %
- charge CPU anormale sur une longue durée
- swap utilisée en continu
- réseau saturé pendant les sauvegardes
Résultat : vous êtes prévenu avant le crash ou la panne visible.
4⃣ Garder un historique utile, sans surcharger le NAS
Sur un NAS, on reste pragmatique :
- rétention courte : 15 à 30 jours
- intervalle de collecte : 30 ou 60 secondes
- pas de métriques inutiles
Vous gardez suffisamment d’historique pour :
- comparer avant / après une mise à jour
- analyser un ralentissement
- comprendre un incident
Sans remplir le disque inutilement.
Pourquoi ce choix est pertinent sur NAS
 Stack open source, mature et maintenue
Stack open source, mature et maintenue- Compatible Docker (UGREEN & Synology)
- Ressources maîtrisées si bien configuré
- Évolutif (vous pouvez ajouter plus tard du long terme ou d’autres machines)
 Pas de base SQL lourde
Pas de base SQL lourde- Pas de configuration complexe au quotidien
C’est exactement ce qu’on attend d’un monitoring maison : utile, pas envahissant.
Cet article original intitulé Top 7 outils de monitoring maison (NAS/serveur) a été publié la première sur SysKB.



