L’État veut généraliser « Visio », l’outil de webconf de La Suite Numérique d’ici 2027 - Next
C'est top ! \o/ Une vraie solution souveraine.
(Permalink)
(Permalink)
A very detailed & insightful explanation of Stack Overflow surprising architecture, from their lead architect in 2016.
Il y a des combats comme cela auxquels pas grand monde ne pense et qui pourtant sont très importants. Je parle évidemment de la lutte contre le chaos du texte non structuré. Si vous avez déjà essayé d'extraire des données propres d'un tas de PDF (après OCR), de rapports ou de notes griffonnées, vous voyez de quoi je parle : c'est l'enfer ! (oui j'aime me faire du mal en tentant des regex impossibles).
Heureusement, Google a lâché début janvier 2026 une petite pépite en open source (même si c'est pas un produit "officiel") qui s'appelle LangExtract . C'est une bibliothèque Python qui utilise la puissance des LLM pour transformer vos documents textuels en données JSON bien rangées.

Exemple d'extraction sur le texte de Roméo et Juliette ( Source )
Ce qui fait que LangExtract sort du lot par rapport à d'autres outils comme Sparrow , c'est surtout son système de Source Grounding. En gros, chaque info extraite est directement liée à sa position exacte dans le texte source. Ça facilite énormément la vérification et la traçabilité puisque vous pouvez voir visuellement d'où vient la donnée grâce à un système de surlignage automatique.
Sous le capot, l'outil est optimisé pour les documents à rallonge (le fameux problème de l'aiguille dans une botte de foin). Il utilise des stratégies de découpage de texte et de passes multiples pour améliorer le rappel et s'assurer que le maximum d'infos soit capturé.

La visualisation interactive permet de valider les données en un clin d'œil ( Source )
Et cerise sur le gâteau, il permet de générer un fichier HTML interactif pour visualiser les milliers d'entités extraites dans leur contexte original. À la cool !
Côté installation, c'est hyper fastoche :
pip install langextract
Pour faire le job, vous avez le choix des armes : les modèles cloud de Google (Gemini 2.5 Flash/Pro), ceux d'OpenAI (via pip install langextract[openai]), ou carrément du local avec
Ollama
. Pas besoin de passer des heures à fine-tuner un modèle, il suffit de fournir quelques exemples structurés via le paramètre examples et hop, c'est parti mon kiki.
Voici à quoi ça ressemble sous le capot pour lancer une machine à extraire :
import langextract as lx
# 1. On définit les règles du jeu
prompt = "Extraire les noms de personnages et leurs émotions."
# 2. On donne un exemple (few-shot) pour guider le modèle
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light...",
extractions=[lx.data.Extraction(extraction_class="character", extraction_text="ROMEO", attributes={"emotion": "wonder"})]
)
]
# 3. On lance l'extraction (nécessite une clé API ou Ollama)
results = lx.extract(
text_or_documents="votre_texte_brut_ici",
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash"
)
# 4. On sauvegarde et on génère la visualisation HTML
lx.io.save_annotated_documents(results, output_name="results.jsonl")
html_content = lx.visualize("results.jsonl")
with open("view.html", "w") as f:
f.write(html_content)
Honnêtement, je ne sais pas si ça va remplacer les solutions industrielles de RPA , mais pour un dev qui veut structurer du texte sans se prendre la tête, c'est vraiment impressionnant. Que vous fassiez du Grist ou de l'analyse de données pure, cet outil mérite clairement que vous y jetiez un œil !

Jensen Huang annonce officiellement la disponibilité de Vera Rubin lors du CES. Le dirigeant du fabricant californien qualifie sa nouvelle architecture de pointe absolue en matière de matériel dédié à l’intelligence artificielle. Déjà en production, le système devrait monter en puissance durant le second semestre. Une accélération remarquable compte tenu des besoins exponentiels de puissance ... Lire plus
L'article L’architecture Rubin propulse Nvidia dans une nouvelle ère de calcul IA est apparu en premier sur Fredzone.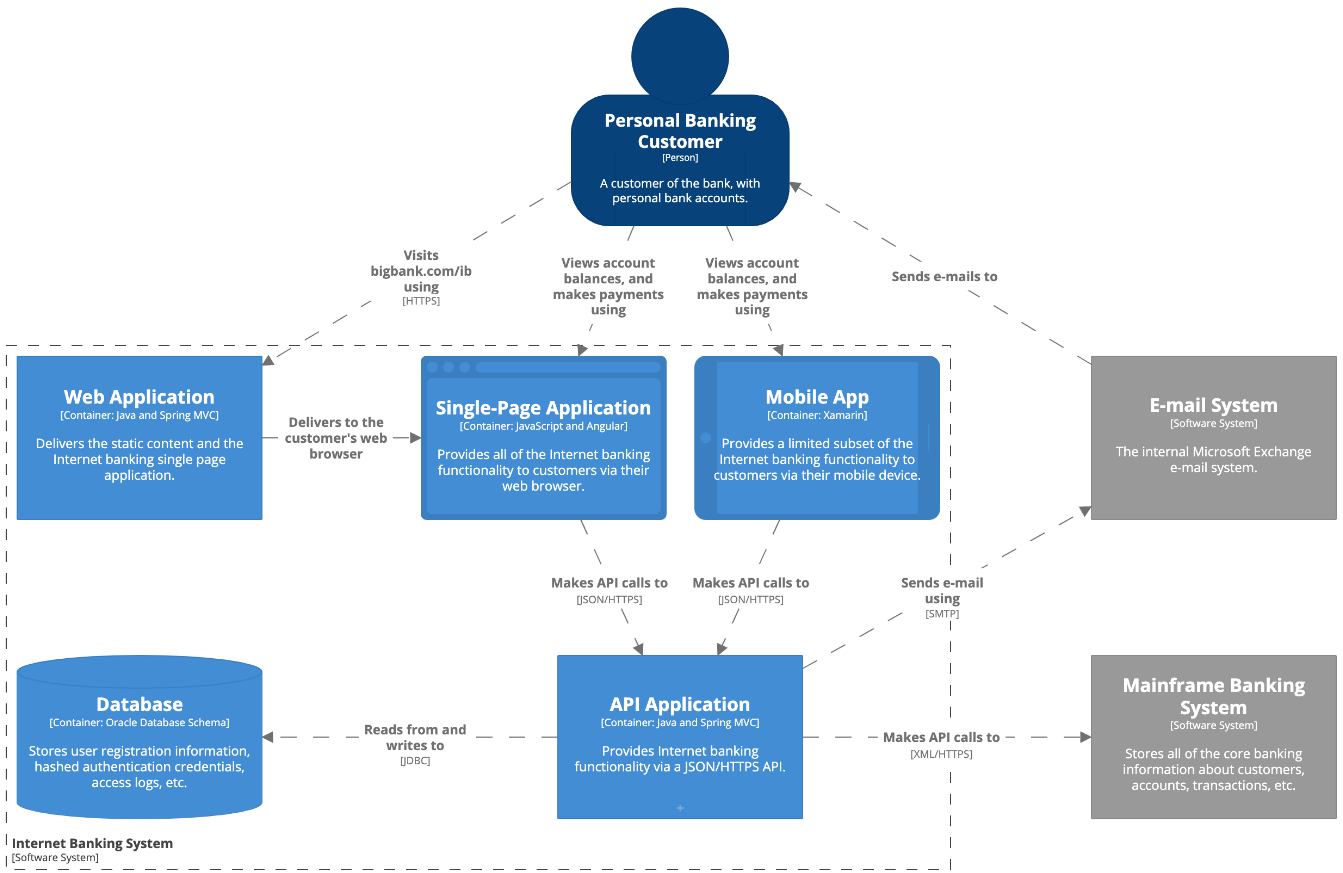
J’ai découvert il y a quelques temps le C4 model. C’est une méthodologie permettant de modéliser et documenter l’architecture logicielle d’un système logiciel. Cela m’a tout de suite intrigué et pourra intéresser ceux qui connaissent un peu l’état de l’art sur ce sujet.