Streaming à la carte sans stockage local : Decypharr, débrideurs et torrenting
Je continue mon tour d’horizon des solutions de streaming à la carte, légales ou non selon les pays, et qui permet de se créer et maintenir une bibliothèque multimédia sans stockage local.
Je n’aborderai pas publiquement les solutions de streaming depuis des .nzb directement.
Sur le même principe que Stremio, Vortex, ou RDT-Client/Zurg, ou encore DebridMediaManager, on peut utiliser Decypharr pour simuler un client BitTorrent (qBittorrent) et streaming le contenu de .torrent depuis des débrideurs, dont TorBox.
Je vais détailler ici l’installation manuelle de Decypharr, Prowlarr et Radarr/Sonarr/Plex mais tout est notamment inclus dans le script SSDv2 (avec une grosse et belle nouveauté à venir).
J’en profite pour remercier Laster13 et Teal-C pour leurs réponses à mes questions.
La dernière mouture de Decypharr embarque rClone et sa configuration sera automatisée. Mes tests sont réalisés avec Prowlarr et des indexeurs FR publics dont YGG via « api.eu », le débrideur AllDebrid ; et je ne « tape » que dans le contenu en cache chez AD (donc aucun téléchargement).
Verdict : RàS pour les films, quelques saisons de séries manquantes uniquement dans le cache, OK avec le téléchargement.
Le plus important est de bien comprendre que si on demande aux *arrs d’organiser les bibliothèques dans /mnt/Bibliothèques, ils ne vont y mettre que des symlinks vers le montage rClone d’AllDebrid (/mnt/decypharr).
Les *arrs, pour traiter les fichiers, tout comme Plex (ou autre) pour leur lecture, doivent avoir accès à ce montage rClone.
C’est pourquoi il est impératif de monter ce dossier en volume pour chaque Docker devant y avoir accès.
Arborescence du test :
aerya@StreamBox:/$ tree -L 2 /mnt/
/mnt/
├── Bibliothèques
│ ├── Films
│ └── Séries
├── Data
│ ├── lost+found
│ ├── quotaless
│ └── rCloneCache
└── decypharr
├── alldebrid
└── qbit
├── radarr
└── sonarrBibliothèques : dossier racine pour les *arrs
Data/rCloneCache : j’avais déjà le dossier pour autre chose, j’utilise le même
decypharr/alldebrid : montage de mon compte AD
decypharr/qbit : dossier de téléchargement (simulé) des fichiers. Les sous-dossiers radarr/sonarr seront ajoutés automatiquement lors de la configuration de Decypharr (tags)
Il faut installer et lancer Decypharr avant le reste vu que tout dépend ensuite du montage du débrideur et des symlinks. Idem s’il faut relancer le Docker Decypharr, il faut relancer les autres ensuite.
services:
decypharr:
image: cy01/blackhole:latest
container_name: decypharr
restart: always
cap_add:
- SYS_ADMIN
security_opt:
- apparmor:unconfined
ports:
- 8282:8282
volumes:
- /mnt:/mnt:rshared
- /mnt/decypharr/qbit:/mnt/decypharr/qbit
- /home/aerya/docker/decypharr/configs/:/app
environment:
- TZ=Europe/Paris
- PUID=0
- PGID=0
devices:
- /dev/fuse:/dev/fuse:rwm
labels:
- com.centurylinklabs.watchtower.enable=true/mnt/decypharr/qbit devant être commun aux *arrs et Plex, on y montera /mnt:/mnt dans chaque ainsi que /mnt/decypharr/qbit:/mnt/decypharr/qbit dans les *arrs qui sauront directement où aller chercher les fichiers à traiter.
La configuration n’est pas vraiment expliquée dans la doc, la mienne n’est peut-être pas optimale mais fonctionne.
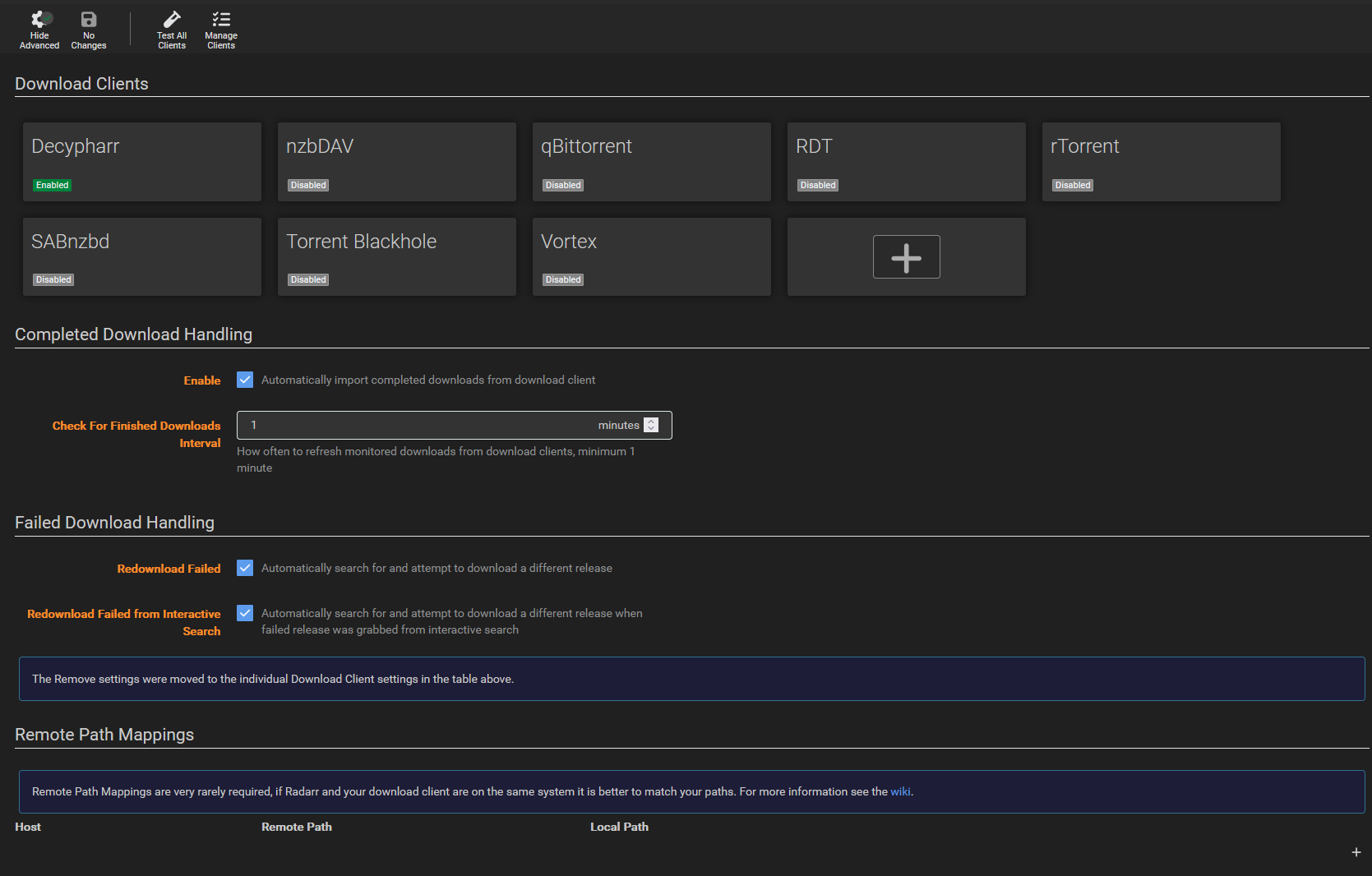
Je n’ai rien modifié dans l’onglet général. J’ai testé les notifications Discord (attention on voit la passkey des trackers utilisés) mais y’a vraiment pas d’intérêt si on ne fait qu’utilise le cache du débrideur (pas de téléchargement).
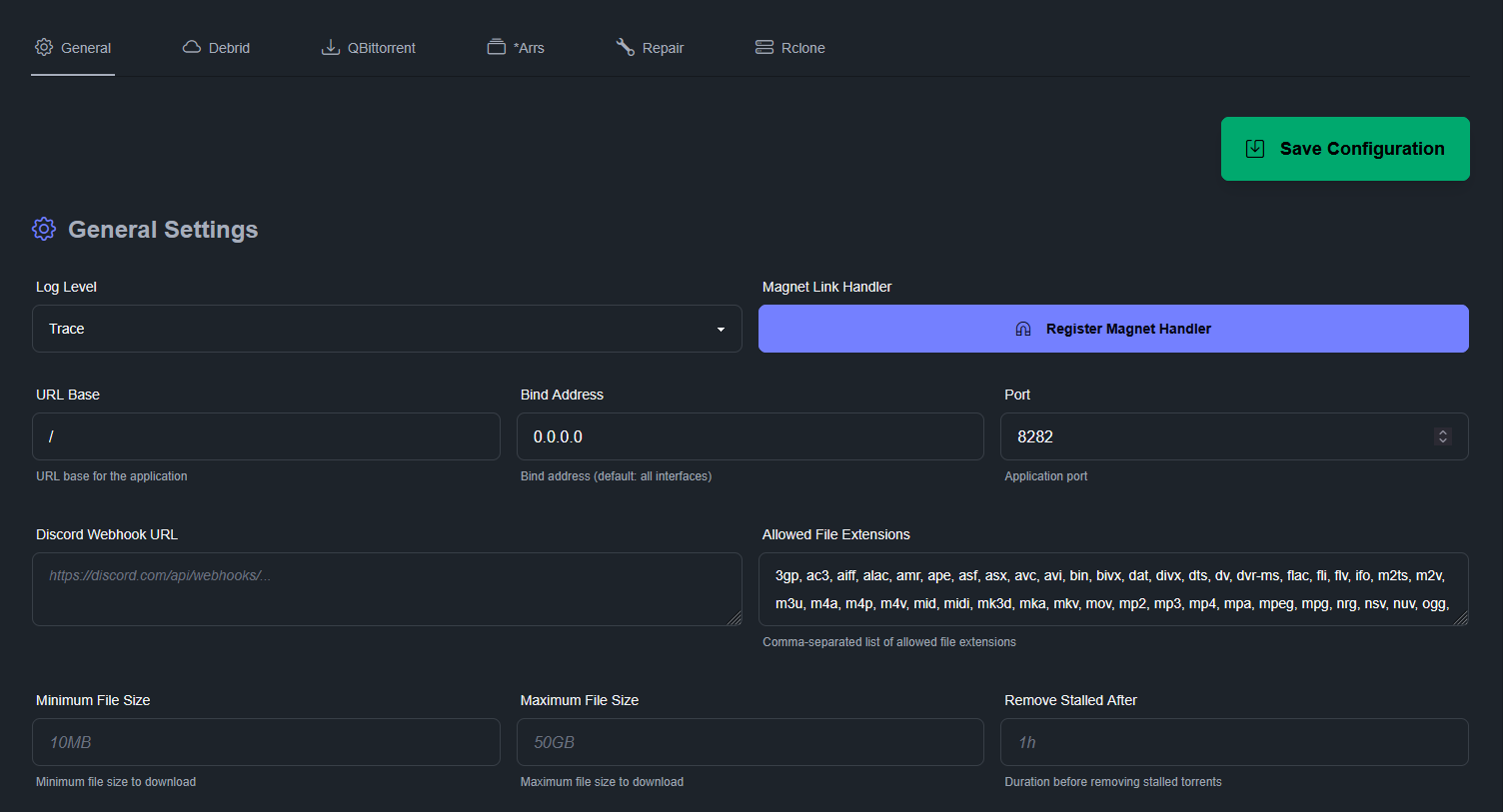
Pour la partie débrideur, on fait notre choix, on colle une clé API (ou plusieurs) et j’ai configuré le montage dans
/mnt/decypharr/alldebrid/__all__
On peut ajouter plusieurs débrideurs. On pourra les attribuer à un *arr lié à Decypharr et même les sélectionner lors de l’ajout manuel d’un .torrent
J’utilise le WebDav et je NE COCHE PAS la case Download Uncached pour qu’il ne télécharge aucun fichier (sur AD) mais n’utilise que son cache.
Je fais ça parce que je voulais tester le cache d’AD et ne voulais pas télécharger des fichiers sans les partager. On peut tout à fait faire les 2 mais attention, il n’y aura pas de seed (donc ratio 0). A ne pas faire chez les Tier 1 sous peine de voir son compte banni !
Certains ont créé des scripts qui captent les .torrent utilisés pour les mettre en seed depuis un client local ou sur un serveur. Dans ce cas, Decypharr est utilisable sans crainte sur les trackers privés.
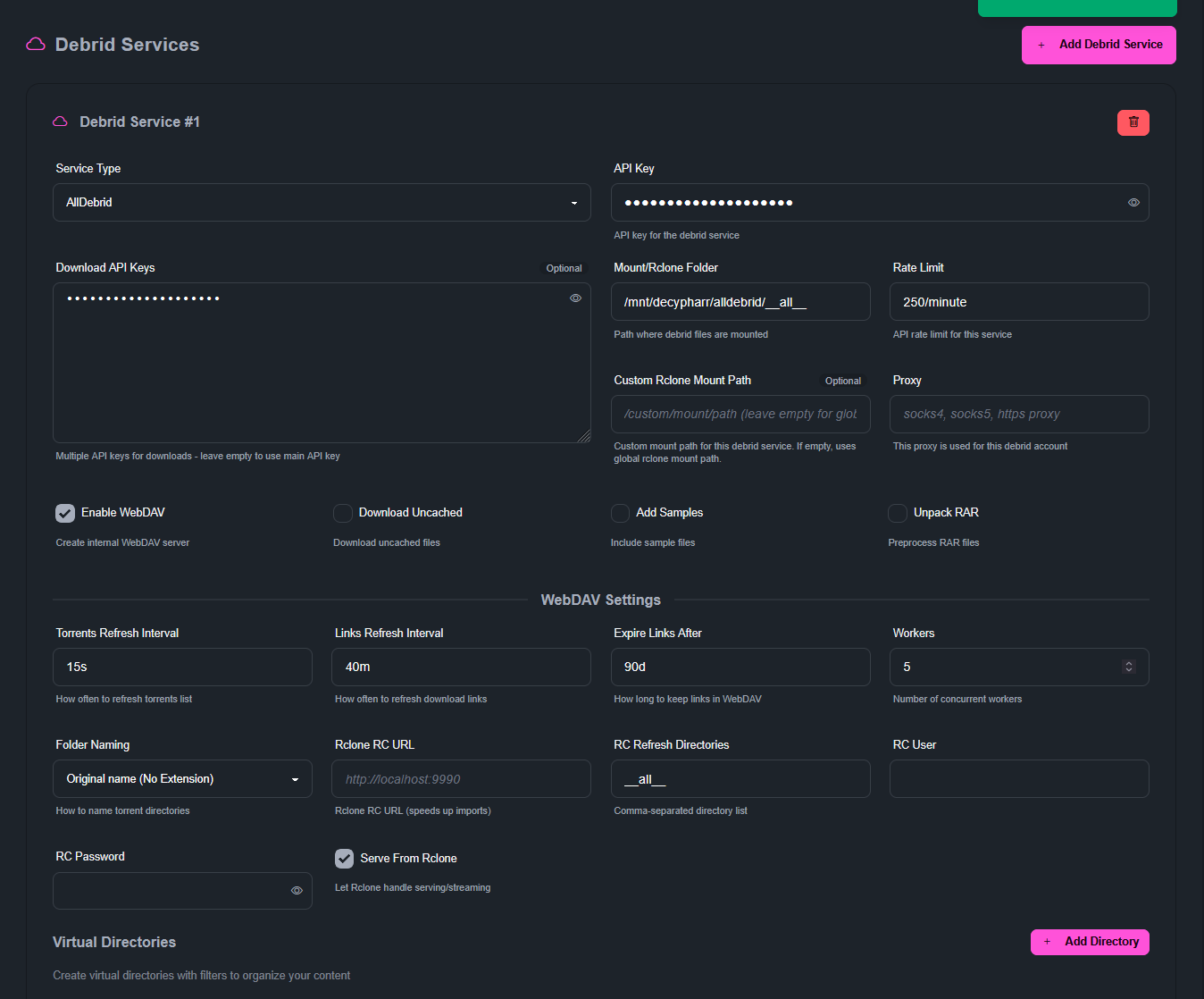
Configuration du client qBittorrent émulé. Je met le chemin qui correspond au volume local dont je parlais au début
/mnt/decypharr/qbit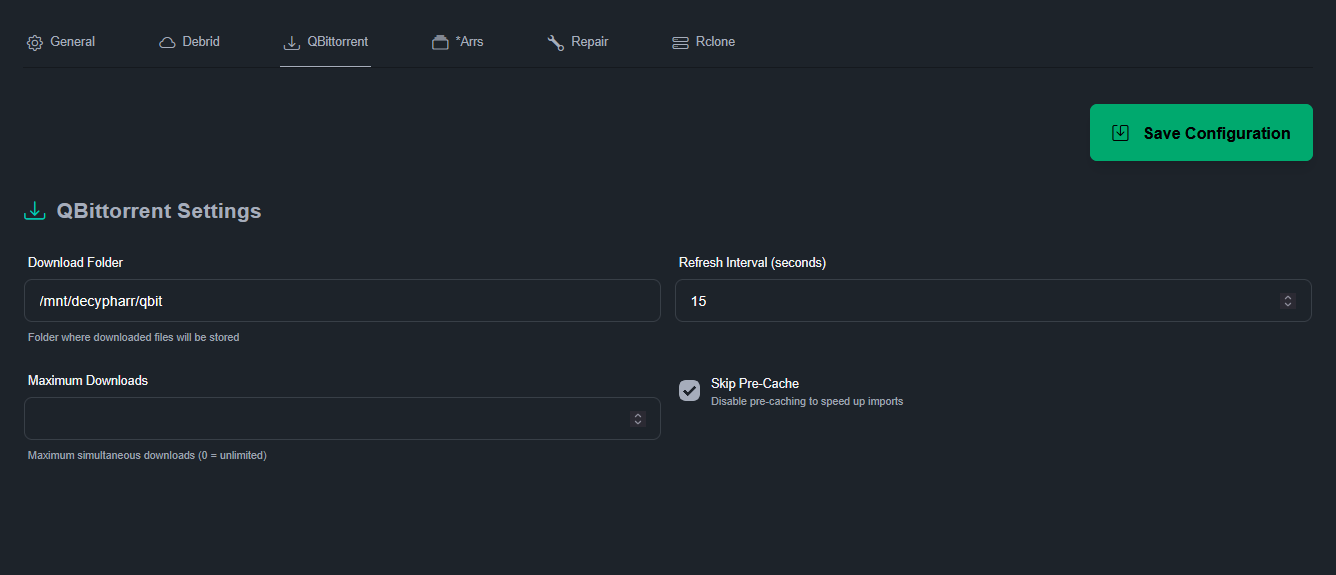
On peut ajouter les *arrs soit depuis Decypharr soit depuis les *arrs eux-mêmes. Je n’ai qu’AD en débrideur j’ai donc laissé la sélection auto mais on peut choisir.
Par exemple Radarr sur AD et Sonarr sur RD ou Sonarr4K sur TB etc. Selon les goût de chacun. Ce qui est certain, c’est que le cache de contenu MULTi/FRENCH est évidemment plus important sur AD et RD que sur TB, principalement utilisé par les anglophones pour Stremio.
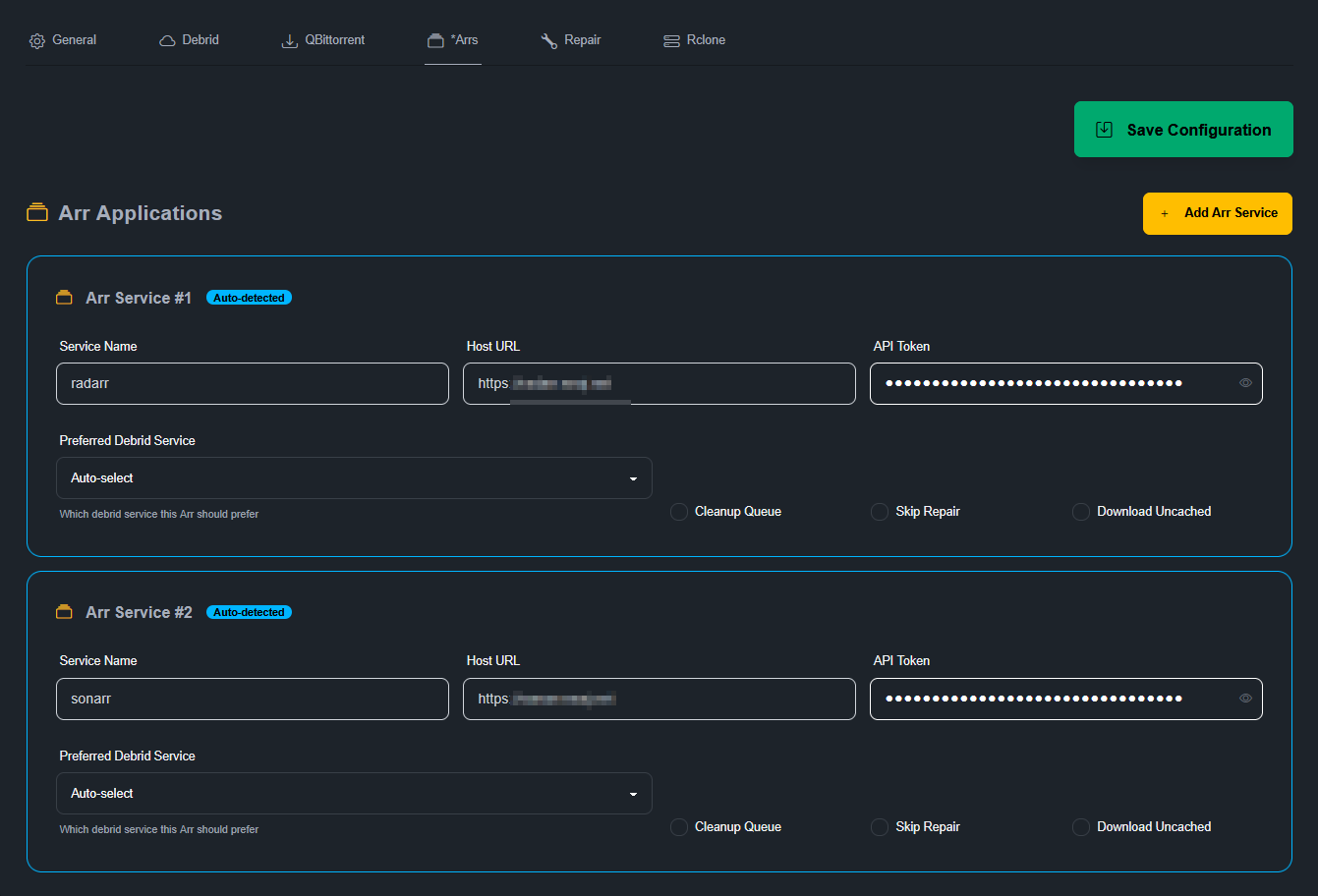
Le Repair est le contrôle et la réparation des symlinks. Qui peuvent être cassés si le contenu lié est effacé du débrideur. Dans ce cas, selon la config, ça peut soit rechercher sur le débrideur (si le fichier a été renommé, vu que ça fonctionne avec le hash et non le nom) soit ça ira chercher un autre .torrent via les *arrs.
Pour l’instant je laisse l’option par défaut à savoir « per torrent » mais il est peut-être préférable d’utiliser « per file ». Dans le cas d’un .torrent de saison complètement, que ça ne recherche que l’épisode manquant (du cache) plutôt que de tout relancer.
Je l’ai mis en autotmatique, toutes les 24h.
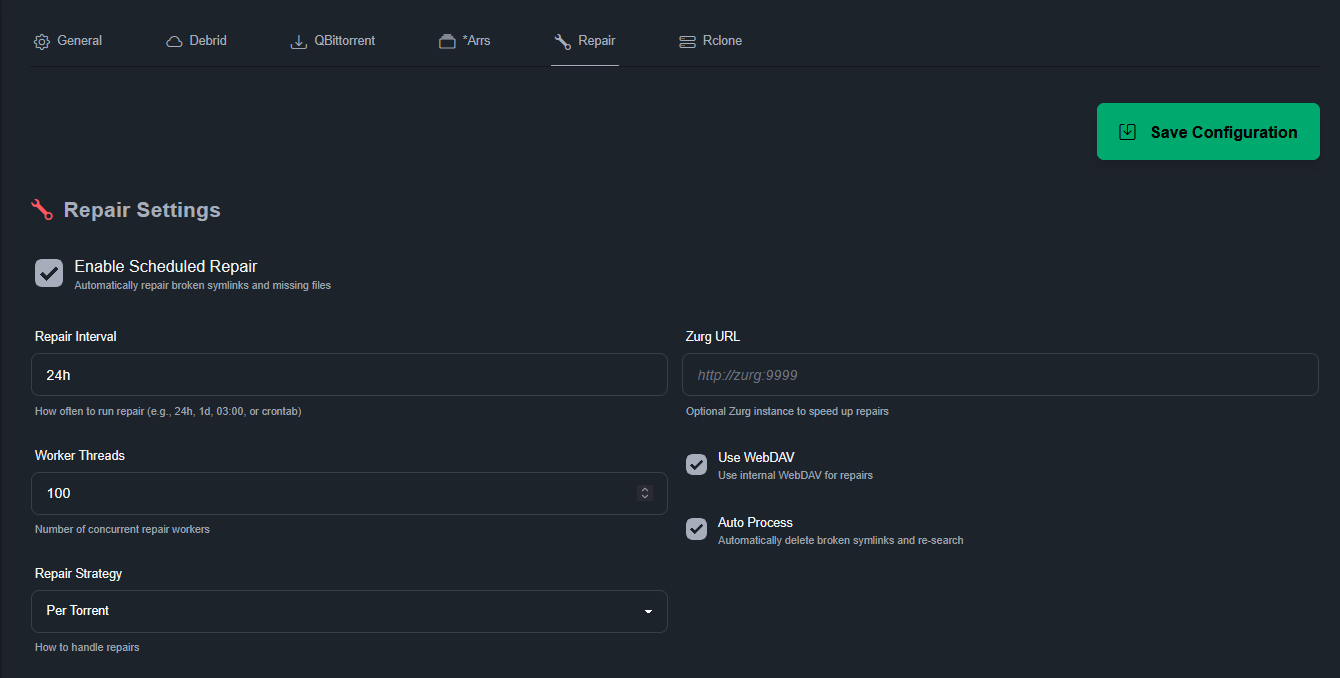
Et enfin la partie rClone. Le monte globalement dans /mnt/decypharr et souhaite utiliser un cache (100Go) dans un dossier (et disque) qui me sert déjà à ça : /mnt/Data/rCloneCache
On peut sans doute améliorer cette configuration mais Plex lit un fichier de 94Go sans broncher…
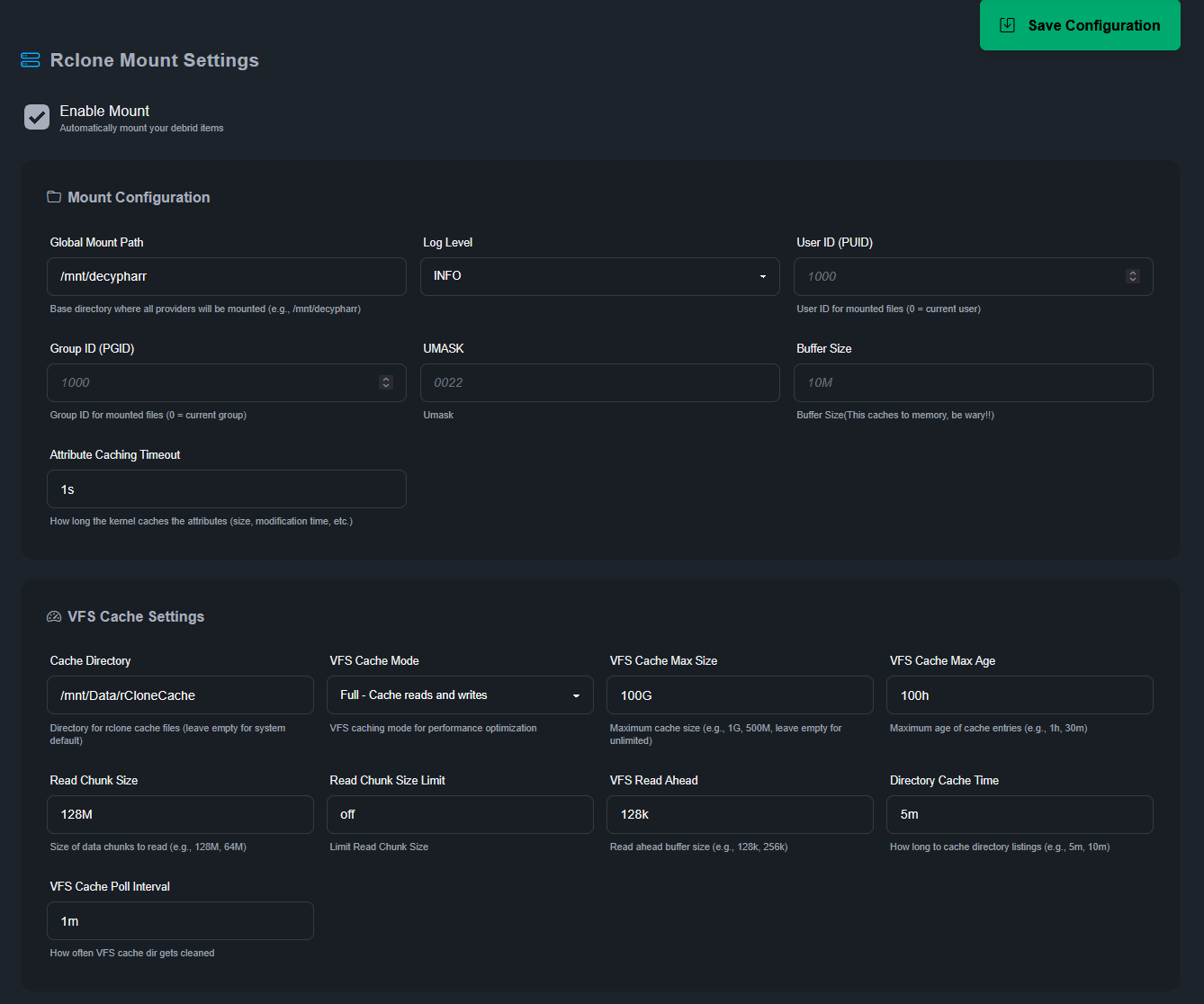
Avec le mode de téléchargement activé, voici le rendu. PausedUP signifie que le .torrent est complété (et de fait plus en seed).
Je ne montre que l’exemple de configuration de Radarr. Pour Sonarr c’est la même logique. Chez moi c’est derrière un VPN pour des interrogations de sources hors Prowlarr et NZBHydra, il n’y a donc pas de port de publié.
Je retire tous les volumes par défaut pour ne monter que /mnt/decypharr/qbit:/mnt/decypharr/qbit et /mnt:/mnt
services:
radarr:
container_name: radarr
restart: always
network_mode: container:gluetun-mullvad
environment:
- TZ=Europe/Paris
- PUID=0
- PGID=0
volumes:
- /home/aerya/docker/radarr:/config
- /mnt/decypharr/qbit:/mnt/decypharr/qbit
- /mnt:/mnt
labels:
- com.centurylinklabs.watchtower.enable=true
image: linuxserver/radarr:nightlyConfiguration du dossier racine : /mnt/Bibliothèques/Films

Configuration du client de téléchargement si on n’a pas ajouté Radarr depuis Decypharr. Il faut sélectionner qBittorrent
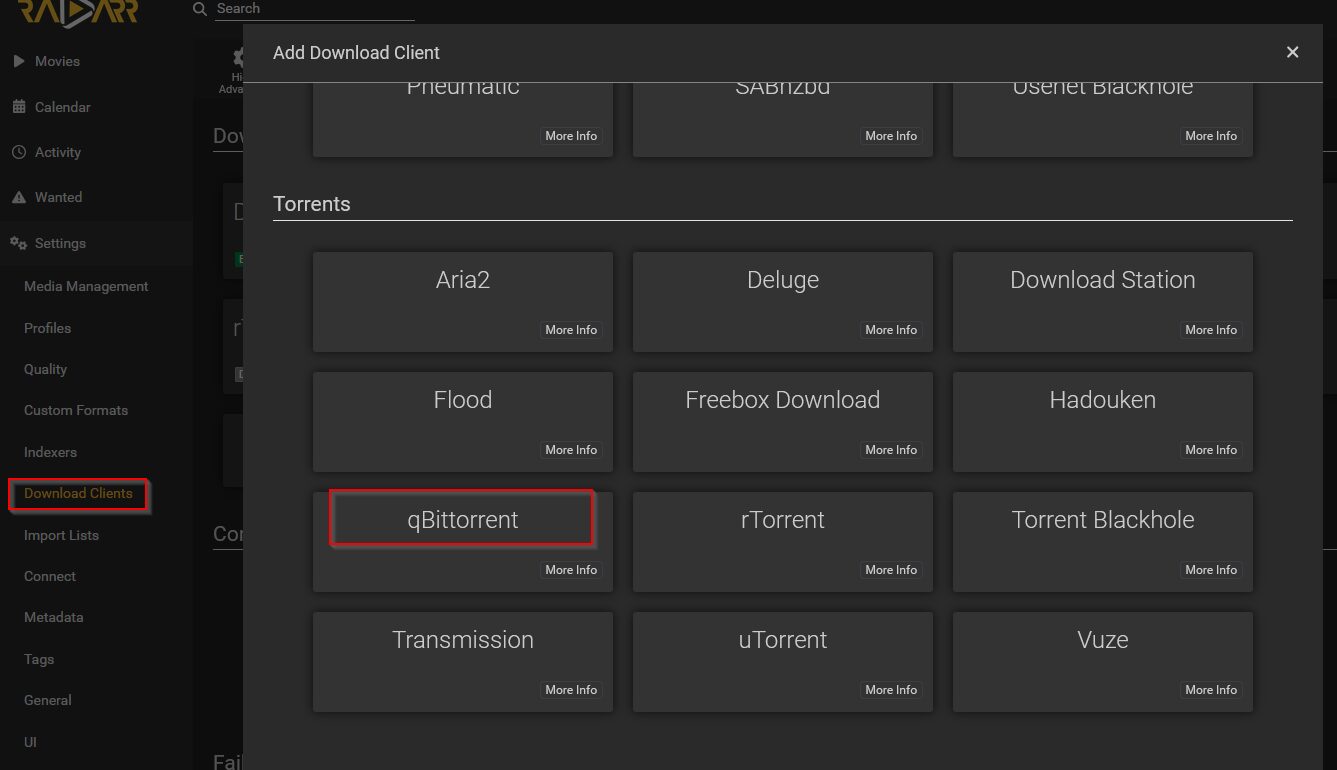
Et dans l’adresse il faut mettre l’URL (ou l’IP) de Decypharr et le port (et SSL si vous utilisez une URL et un reverse proxy).
Le nom d’utilisateur et le mot de passe sont l’URL de Radarr et sa clé API.
La catégorie : radarr (et donc sonarr pour Sonarr ofc!)
Ne surtout pas cocher la case Sequential Order (sinon ça DL localement)
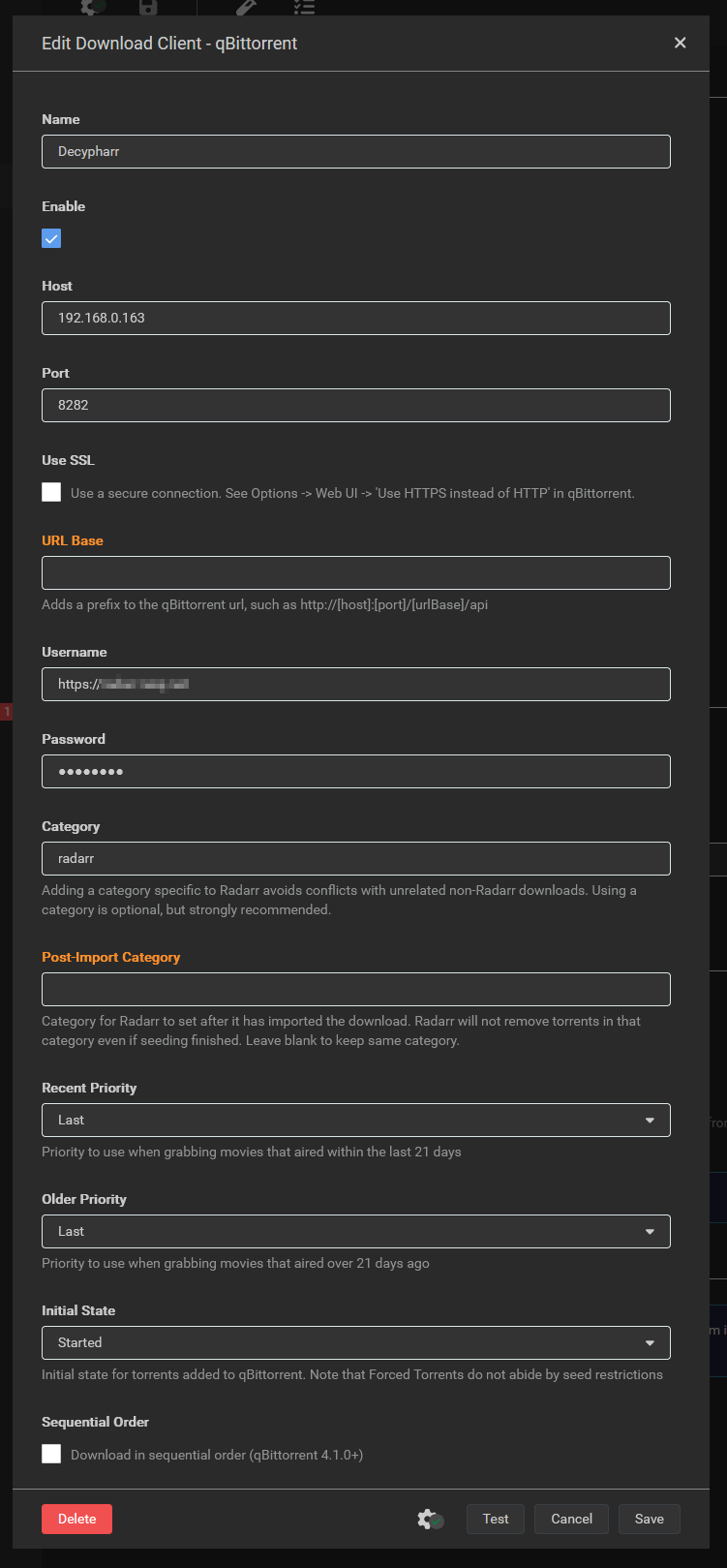
Et comme le même chemin/volume est monté dans chaque Docker, il n’y a aucun Remote Path Mapping à mettre
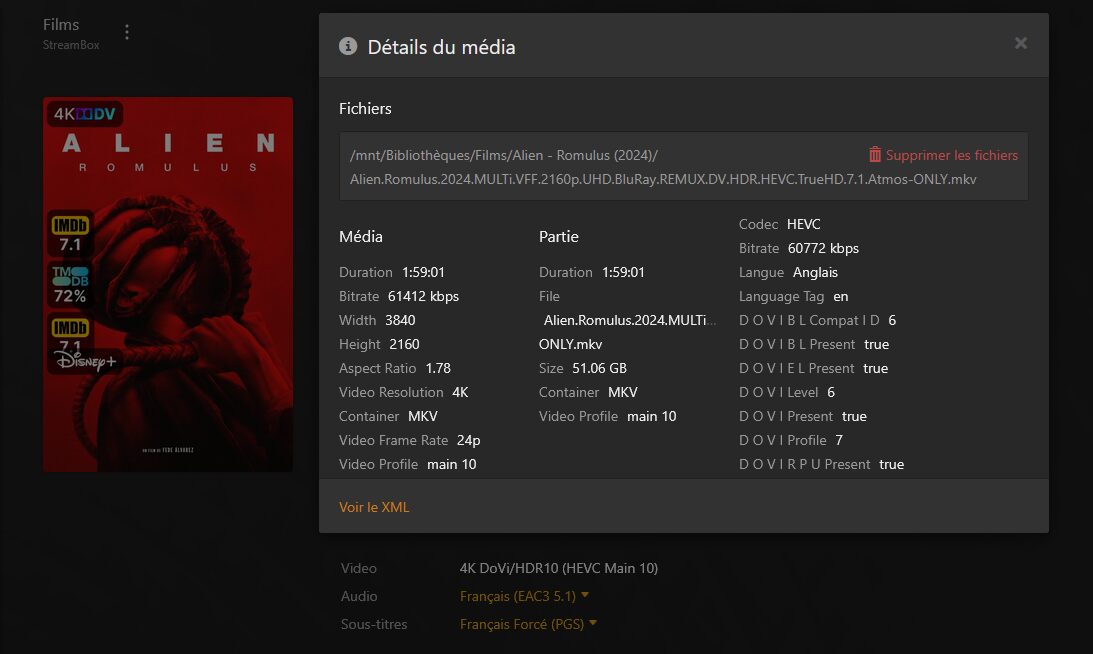
Lors de l’ajout d’un film, la complétion est quasi instantanée pour peu que le fichier cherché soit déjà dans le cache d’AllDebrid. Si vous activez le téléchargement des fichiers non encore en cache, ça peut prendre quelques minutes.
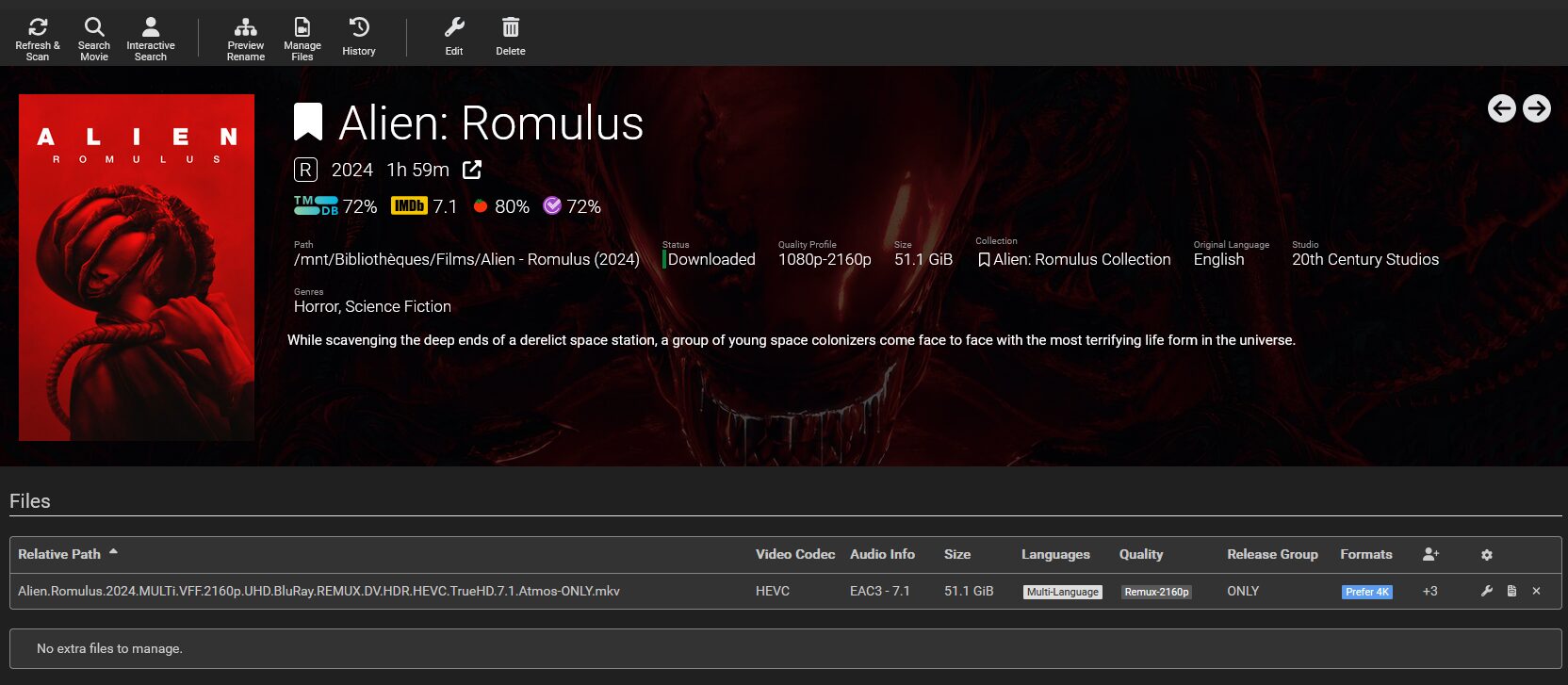
En regardant de plus près, on voit bien que c’est un symlink vers le cache d’AllDebrid
aerya@StreamBox:/mnt/Bibliothèques/Films$ ls -l Alien\ -\ Romulus\ \(2024\)/
total 4
lrwxrwxrwx 1 root root 208 Aug 25 18:55 Alien.Romulus.2024.MULTi.VFF.2160p.UHD.BluRay.REMUX.DV.HDR.HEVC.TrueHD.7.1.Atmos-ONLY.mkv -> /mnt/decypharr/alldebrid/__all__/Alien.Romulus.2024.MULTi.VFF.2160p.UHD.BluRay.REMUX.DV.HDR.HEVC.TrueHD.7.1.Atmos-ONLY/Alien.Romulus.2024.MULTi.VFF.2160p.UHD.BluRay.REMUX.DV.HDR.HEVC.TrueHD.7.1.Atmos-ONLY.mkvncdu 1.19 ~ Use the arrow keys to navigate, press ? for help
--- /mnt/Bibliothèques/Films/Alien - Romulus (2024)- ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
@ 4.0 KiB [###################################################] Alien.Romulus.2024.MULTi.VFF.2160p.UHD.BluRay.REMUX.DV.HDR.HEVC.TrueHD.7.1.Atmos-ONLY.mkv
Plus globalement, tous les fichiers sont bien chez AllDebrid, monté via WebDav/rClone et je n’ai localement que des symlinks qui ne prennent aucune place.
En théorie, on pourrait se faire cette installation sur une Carte MicroSD de quelques Go 
ncdu 1.19 ~ Use the arrow keys to navigate, press ? for help
--- /mnt ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
15.9 TiB [###################################################] /decypharr
4.0 MiB [ ] /BibliothèquesPour terminer, la configuration de Plex. Toujours avec /mnt:/mnt de monté pour garantir l’accès aux symlinks.
services:
pms-docker:
container_name: plex
restart: always
ports:
- 32400:32400/tcp
- 33401:33401/tcp
- 3005:3005/tcp
- 8324:8324/tcp
- 32469:32469/tcp
- 1900:1900/udp
- 32410:32410/udp
- 32412:32412/udp
- 32413:32413/udp
- 32414:32414/udp
environment:
- PLEX_UID=0
- PLEX_GID=0
- TZ=Europe/Paris
- PLEX_CLAIM=claim-xxx
- ADVERTISE_IP=http://192.168.0.163:32400/
hostname: plex.xxx.xxx
volumes:
- /home/aerya/docker/plex:/config
- /mnt:/mnt
- type: tmpfs
target: /transcode
tmpfs:
size: 4g
labels:
- com.centurylinklabs.watchtower.enable=true
image: plexinc/pms-docker:latest
![]()
 ) qu’au niveau perso, où mes propres expérimentations m’ont conduit à partager ma découverte et
) qu’au niveau perso, où mes propres expérimentations m’ont conduit à partager ma découverte et 





{kind=link}
{kind=link}
{kind=link}