Enfin un cluster de Raspberry Pi 4 !
Depuis trop longtemps un brouillon de réflexion sur l’évolution de mon hébergement maison traîne sans que je prenne le temps de le terminer (avec derrière la réflexion sur le marché du matériel, que j’ai du remanier plusieurs fois sur la dernière année passée…). Moralité, les évènements se sont chargés de bousculer un planning déjà très peu défini, et le matériel de remplacement est déjà là. On va donc faire dans le très résumé pour savoir ce qu’il en est, même si c’est dans le titre.
Pour ceux qui auraient la flemme de déterrer les archives, j’utilisais donc en guise de microserveur une plateforme Pentium J4205 certes limitée en performances, mais au silence absolu et à la consommation très faible. Accompagnée de 8Go de RAM, avec un SSD SATA de 128, puis 256 puis 512Go de capacité, le tout fonctionnant avec Proxmox VE, l’environnement de virtualisation opensource qui continue son bonhomme de chemin sous la houlette de l’entreprise allemande Proxmox Server Solutions.
Globalement j’en ai été très content, mais j’ai toujours été conscient du manque de puissance à ma disposition. Une tentative pénible d’installation d’un Gitlab (remplacé par Gitea), puis plus tard un Jenkins (pas remplacé) m’en a convaincu, si j’avais encore des doutes. Le passage à un cluster Kubernetes avec k3s aussi. Avec ce dernier le manque de RAM s’est très vite fait sentir, les choix sur le stockage également avec Longhorn, dont je n’avais pas correctement anticipé la lourdeur. La réflexion se penchait donc en partie sur une augmentation de performances, de ressources de manière générale, mais pas seulement.
Longhorn avait déjà des soucis, certains pods se retrouvaient avec des volumes en lecture seule sans que j’en trouve l’explication. Je n’étais pas tout seul, d’autres aussi ont eu le souci avec des installations matérielles différentes, ce n’est donc pas juste un souci avec mon environnement particulier. Mais le problème a empiré quand c’est le matériel sous-jacent qui a commencé à avoir des soucis, avec des erreurs SATA qui foutaient les partitions du Proxmox en lecture seule, et donc toutes les VMs avec. Remplacer le matériel devenait donc plus urgent.
Du vrai clustering ?
Eh oui, expérimenter k3s m’a confirmé que oui, je pouvais avoir une installation Kubernetes chez moi qui ne demande pas 3000 balles de matos. Mais un des problèmes d’avoir une seule machine, est que certes j’avais trois nœuds « kube », mais tous finissaient dans le même état en même temps, à savoir HS. Et parfois, j’étais obligé de jouer du fsck pour faire repartir les machines virtuelles. J’avais donc envie de corriger cette situation, et si possible sans faire exploser le budget que j’avais commencé à fixer, à savoir autour des 400~500€.
Les Raspberry Pi sont prisés depuis plusieurs années pour leur tarif abordable et l’écosystème qui s’est construit autour. La dernière itération en date, le Pi 4, met la barre assez haut avec une compatibilité 64bit, jusqu’à 8Go de RAM, un vrai réseau Gigabit (en plus du Wifi et du Bluetooth), et quelques erreurs de jeunesse ont été corrigées (compatibilité USB-C, chauffe excessive du SoC) le rendant finalement tout à fait adapté aujourd’hui. Les ressources texte et vidéos sur ce type d’installation que j’ai pu voir défiler m’ont attiré de plus en plus. J’ai donc commencé à simuler un setup (archi, budget, etc). Et comme je suis dans l’urgence, j’ai même dérivé de ma vision initiale.
En effet, dans les évolutions liées au Raspberry Pi, il y a désormais la possibilité de démarrer sur un stockage externe, USB dans le cas présent, et j’envisageai de migrer de Longhorn à Rook pour le stockage à l’intérieur du cluster (spoiler, sur Raspbian c’est compliqué parce que pas de module noyau pour ceph pas défaut ![]() ). C’est quelque chose que j’ai pour l’instant laissé de côté, je me suis quand même tourné vers des cartes microSD performantes et spacieuses, et j’ai toujours le NAS qui va tout de même bosser dans l’urgence avec le provisioner NFS. Et tant pis pour la lenteur dudit NAS quand tout redémarre à froid. Puisque j’ai le matériel, à part un petit switch réseau Ethernet Gigabit pour accompagner ce cluster, je vais monter mes câbles réseau moi-même, parce que pourquoi pas, ça permet surtout de les faire à une longueur qui soit pas trop déconnante. Ça m’exerce aussi un peu, hein, on va pas se mentir.
). C’est quelque chose que j’ai pour l’instant laissé de côté, je me suis quand même tourné vers des cartes microSD performantes et spacieuses, et j’ai toujours le NAS qui va tout de même bosser dans l’urgence avec le provisioner NFS. Et tant pis pour la lenteur dudit NAS quand tout redémarre à froid. Puisque j’ai le matériel, à part un petit switch réseau Ethernet Gigabit pour accompagner ce cluster, je vais monter mes câbles réseau moi-même, parce que pourquoi pas, ça permet surtout de les faire à une longueur qui soit pas trop déconnante. Ça m’exerce aussi un peu, hein, on va pas se mentir.
L’expérience « sans Amazon » continue, avec Conrad cette fois (spoiler : c’est pas dingue)
C’est un futur ex-collègue (en fonction de la date de sortie, il aura déjà changé de crèmerie) qui s’est intéressé à ce site pour commander les éléments. Au-delà de l’idée d’éviter Amazon, une des problématiques qu’on envisageait différemment concernait l’alimentation. J’envisageais un « chargeur » grosse capacité avec plusieurs prises USB. Lui cherchait à se tourner vers une alim 5V « industrielle », dans l’optique d’alimenter les Pi via les ports GPIO. Après m’être un peu documenté, c’est tout à fait possible, mais pas recommandé car les ports GPIO ne disposent pas des mêmes protections électriques intégrées que le port USB-C. J’ai aussi évacué le HAT PoE(+) parce qu’il est ventilé et qu’en l’état il est toujours question d’une installation full fanless, sans parler de la chauffe qui accompagne encore la dernière révision du module, malgré les corrections, ou le coût doublé du switch associé. Mais malgré tout je suis resté sur le site et une fois le panier terminé, le tarif annoncé pour un cluster trois nœuds était dans mes « normes », aux alentours de 500€ tout de même, avec des Pi 4 en version 8Go, la seule version disponible à ce moment-là. Même avec la livraison, comme quoi, c’est possible.
Bon par contre, dire que l’expérience fut complètement agréable est un mensonge. La création du compte a été simple, mais passer commande fut beaucoup plus sportif. En effet, au niveau du panier, le bouton pour passer commande a commencé par me renvoyer… une erreur cryptique. Et c’est tout, il ne se passe rien. Il a fallu que je passe par les outils développeur du navigateur pour voir le vrai message, à savoir que l’un des produits, en l’occurrence le chargeur 72W, n’était pas disponible pour les particuliers. Un coup de remplacement du produit plus tard par un autre modèle équivalent qui passe, j’ai pu continuer la commande. Mais ça, c’était l’introduction.

Bon courage pour savoir à quoi ça correspond :/
J’ai de fait été déçu de voir qu’ils n’ont pas cherché à tout regrouper dans le même colis. Jugez plutôt, j’ai reçu les Pi, les cartes, le rack, les radiateurs, le switch, mais pas le chargeur ni les câbles d’alim qui vont avec; alors que tout était marqué en stock. Et en parlant de livraison, GLS… Comment dire que je suis confus par ce qui s’est passé. En gros, ils m’ont envoyé un SMS pour dire quand ils livraient. Pas de bol, c’est un des rares jours où je devais retourner au bureau (je sais pas si j’en parlerai un jour, j’arriverai pas à rester diplomatique je pense), et heureusement, ils proposent de pouvoir changer la date. Enfin, heureusement… le lien contenu dans le SMS est bien en HTTPS, avec un domaine qui peut aller, mais sur un port non standard. Perso je fais ça dans un environnement de dev, sur mon réseau local, mais pas pour des informations transmises à des clients, parce que ça, ça pue le phishing. La version mail de la notification, elle contient un bon lien, ce qui m’a permis de décaler la date de livraison, en donnant mon numéro au passage parce que la livraison chez moi, c’est pas trivial. En parallèle dans la journée de la livraison, je reçois un autre message pour dire qu’un nouveau colis est en route. En regardant le détail, ce ne sont que les câbles qui sont envoyés…
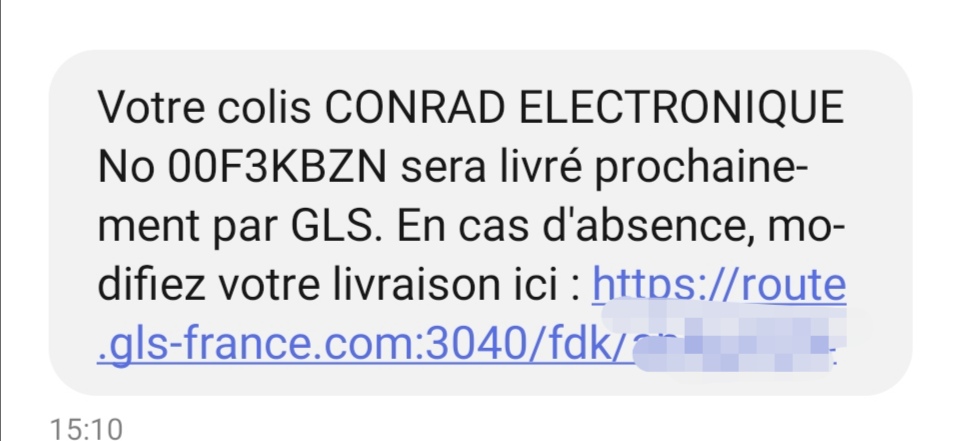
Non mais sérieux ? Faut croire, j’ai bien eu trois livraisons pour une seule commande pour des produits tous marqués en stock. C’est clairement pas le genre de chose qui donne envie de recommencer, surtout avec un transporteur dont les outils de suivis sont aussi incroyable d’amateurisme, pour être poli. Alors déjà le site Conrad, quand on clique sur les liens dans le mail, nous renvoie vers le site allemand pour le suivi, pas vraiment le truc le plus agréable du monde, j’ai déjà parlé des SMS, au final, en récupérant le numéro de colis on a plus vite fait d’aller sur la page d’accueil du site français pour faire soi-même la recherche dans la bonne langue.
Dernier point, il se trouve qu’en lisant les specs du chargeur reçu, deux semaines plus tard, je n’ai pas assez de puissance disponible sur les ports USB (le gros de la puissance est réservé à un port USB dit power delivery pour les ultra portables récents…), la procédure de rétractation retour de Conrad passe par… un PDF à remplir et renvoyer par mail. Oui, en 2021 toujours. Les remplaçants (j’ai pris des chargeurs individuels 3A) ont été commandés en 1min30 et livrés en 24h chrono, sur Amazon.
Et on se demande pourquoi le géant américain a autant de succès…
L’installation de k3s : on prend les mêmes…
Mon cluster d’origine avait été installé et maintenu avec Ansible, via un dépôt que j’avais partagé. S’il avance un peu au ralenti par rapport à un autre projet découvert par un autre de mes collègues de boulot, il est toujours fonctionnel. J’ai quand même mis à jour ma copie locale avant d’attaquer, histoire de m’assurer que le Raspberry Pi 4 soit bien pris en charge. Dans l’urgence et parce que je n’avais pas envie d’y passer tout le weekend, j’ai installé la même version 1.19 que j’avais déjà, à une patch release près. L’installation a pris même pas deux minutes, et moins de deux minutes encore plus tard, je pouvais voir les deux seuls containers du master déployé. Oui parce qu’historiquement je déploie Traefik à part pour des raisons de versions embarquées par k3s.
Et donc, pour le stockage, j’ai dans l’urgence utilisé le nfs provisioner, via Helm. Quand je dis qu’on prend les mêmes, ça vaut aussi pour mon niveau de compétences réseau. La configuration initiale semblait plus ou moins correcte (j’ai juste forcé la version du protocole NFS), mais le premier volume se faisait jeter avec une erreur 32. Quelques essais au niveau de l’OS me renvoient effectivement un Permission denied. Pourtant, j’ai bien vérifié que l’IP du Pi fait partie de celles que j’ai autorisé sur le NAS. Avant de découvrir que la méthode utilisée pour démarrer avec une IP fixe (via le fichier cmdline.txt), n’empêchait pas dhcpcd d’avoir fait son taf, malgré la désactivation de l’autoconfiguration. Mon Pi avait donc deux adresses, et surprise, utilisait celle fournie par le DHCP alors même qu’elle était déclarée en secondary… Vraiment, jusqu’à ma mort je pense que je continuerai à faire ce genre de conneries.
En parlant de Helm, j’ai failli l’utiliser également pour Traefik, parce que la migration des CRDs ne me motive pas plus que ça, mais finalement, j’ai réutilisé mes manifestes. Je suis en train de me débattre avec quelques petits bugs mineurs avec mon Gitea, mais à la fin, j’ai pu remettre en ligne le peu de services actifs que j’avais sur le cluster. Avec la perspective et les ressources pour cette fois pouvoir aller plus loin : rapatriement du lecteur de flux RSS (c’est déjà fait, dans l’urgence aussi et c’est tellement honteux que je vais pas vous dire pourquoi), déploiement de Bitwarden_rs (pardon, de Vaultwarden), d’un registry type Harbor, et d’autres services encore au gré de mes expérimentations. Genre Rook que j’ai déjà évoqué mais qui s’annonce compliqué, Nocodb, iperf3, rocket.chat, Drone, Argo-CD, un service mesh histoire de pas mourir idiot, que sais-je encore. Avec une grosse contrainte quand même : je suis désormais sur une architecture ARM 64bit, et tous les logiciels ne sont pas forcément disponibles pour celle-ci, une aventure de plus.
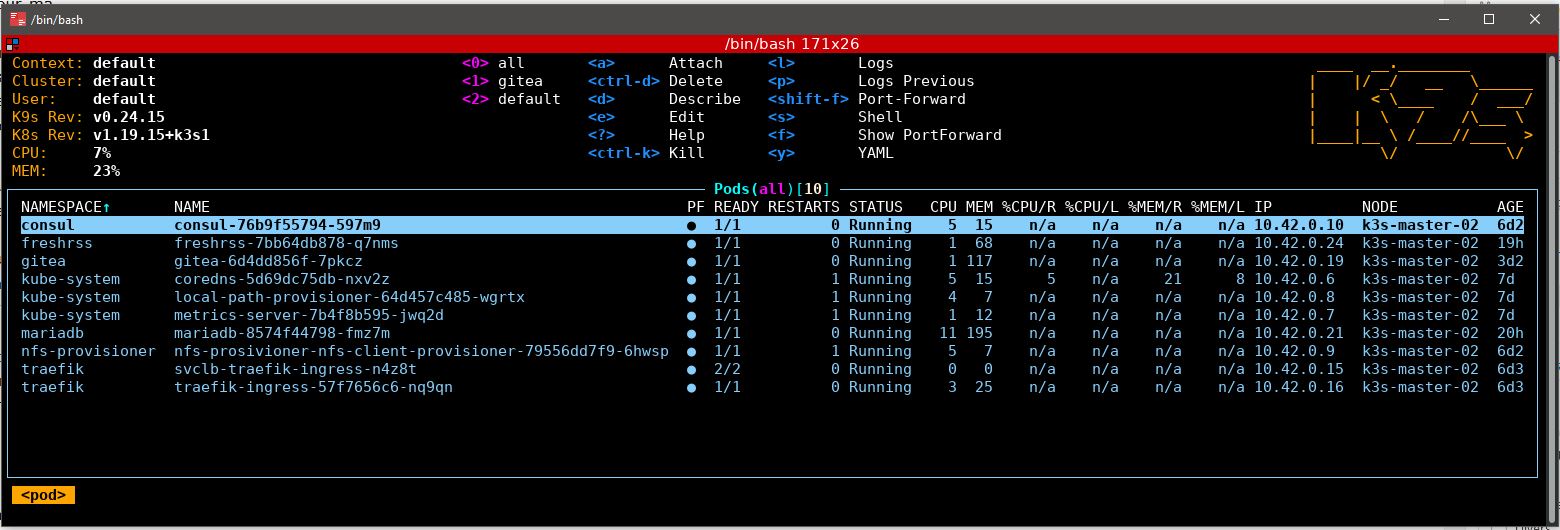
Et voilà, c’est tout debout et ça fonctionne bien ![]()
Une solution pas super élégante pour autant
Je m’explique : pour l’instant les Pi et le switch sont posés au fond du « meuble » TV, avec les câbles qui passent à l’arrache et un vieux T-shirt par dessus l’ensemble pour masquer les nombreuses diodes qui ne manquent pas de clignoter en permanence. Les éléments de montage en rack sont assez rudimentaires et ne concernent que les Pi, et il n’y a pas beaucoup de solutions commerciales qui joueraient la carte du tout-en-un; en tout cas le peu que je vois ne fait pas envie financièrement parlant. Il me semble que je vais devoir passer par la case fabrication maison pour espérer faire quelque chose de mieux intégré.
À moins de tomber sur quelque chose d’adaptable et adapté, mais bon, vu que la partie alimentation est spécifique, la partie réseau aussi, c’est compliqué je pense; on s’orienterait carrément vers une vraie armoire, ce qui s’annonce non neutre en termes de budget… Mais voilà, il y a enfin un vrai cluster au niveau matériel chez moi, une envie qui traînait depuis au moins deux/trois ans. Ce n’est pas encore aussi mature, propre, intégré que chez certains (il faut aussi de la place, une autre problématique à régler dans les prochains mois), mais ça fonctionne. Et c’est tout ce qui compte.