Passé par Portainer, Komodo, Dockge et plus récemment Arcane, j’ai toujours pas trouvé LE gestionnaire de Docker qui me convienne : léger, permettant de gérer au moins 3 machines, intuitif tout en restant complet, qui gère les MàJ des Dockers, acceptant directement des compose, etc.
Depuis quelques jours maintenant j’utilise Dockhand (GitHub) et ça coche toutes les cases ; même plus puisqu’il a en option notamment des notifications différenciées et les outils Trivy et Grype pour scanner les dockers à la recherche de vulnérabilités. De mémoire j’avais présenté le 1er y’a des années sur le blog « perdu » effacé par un bon gros blaireau…
Pour le coup je le trouve très bien pensé, avec plus un œil de « geek » que de professionnel si je puis dire. Avec en prime une roadmap et un super Wiki qui va à l’essentiel.
J’ajoute l’environnement local via socket directement.
On peut ajouter des registres avec ses comptes comme DockerHub et GitHub
C’est tout bête mais j’aime bien la possibilité de choisir ses thèmes. Ça me rappelle un peu https://catppuccin.com/ports/
Puisque j’ai lié mon compte GitHub je peux importer mes repos, y compris les privés.
Comme souvent, on peut créer des templates d’installations Docker. J’ai jamais utilisé. Le seul cas, dans mon contexte, où ça pourrait éventuellement être potentiellement utile 2 ou 3 fois (na, pas du tout) ce serait pour créer une template pour les arrs/decypharr etc avec les volumes pré-définis. On est d’accord, j’en n’ai aucune utilité. Mais y’a l’option.
Pour les notifications, je me suis mis Discord. Et on verra après que je ne les utilise que dans le cas des MàJ pour l’instant. Je ne fais pas de MàJ auto pour tous mes Dockers, je suis du coup informé quand y’a une MàJ à faire ou quand celles en automatique ont été réalisées (ou ont échoué).
C’est uniquement en LAN chez moi, j’ai pas testé l’authentification.Idem pour l’ajout de serveurs (Syno et ZimaOS pour l’instant), j’ai utilisé Hawser vu que je suis sur mon réseau.
Et j’obtiens la vue d’ensemble de mes machines
Comme je le disais au début de l’article, j’ai été agréablement surpris de voir l’intégration de Trivy et Grype, sur option, qui permettent de scanner chaque image installée.
Ici l’exemple de mon serveur AdGuardHome que je voulais changer de machine : imthai/adguardhome-unbound-redis
Les vulnérabilités trouvées sont indiquées pour chaque agent avec le lien vers le CVE. Si l’option de scan est globalement activée alors les updates seront aussi scannées. Et on peut à tout moment lancer un scan depuis la liste des images via l’icône de bouclier.
Si tous les Dockers d’une machine seront reportés dans Dockhand, on ne pourra évidemment y éditer que ceux lancés via l’outil. Pour se faire on peut utiliser la méthode « guidée » où on pull une image et on la gère de manière guidée.
Ou bien on peut importer des stacks/compose depuis un serveur (bouton Adopt) mais j’ai pas testé.
Ou enfin, le plus simple dans mon cas, on peut ajouter son compose directement. On peut même importer son .env Désolé du caviardage mais j’ai réalisé après coup que je montrais un truc personnel.
Il est également possible d’importer des dépôts depuis les registres configurés
Dockhand permet bien sûr de créer et gérer tous les types de réseaux
Après ces tests, même si c’est toujours en gros développement, je trouve ça plus abouti qu’Arcane, plus simple que Komodo et ça répond plus à mes besoins que Portainer. C’est une belle découverte que je vais conserver.
Parfois on n’a pas les droits pour installer des utilitaires sur un OS (notamment sur TrueNAS). J’aime particulièrement ncdu qui me permet de rapidement visualiser des tailles de dossiers/montages/backups…
Et on peut donc biaiser en l’utilisant depuis rClone, sur un remote « local » qu’il convient d’ajouter dans rclone.conf
[local]
type = local
On peut cibler des dossiers comme on le ferait directement depuis l’OS
root@HomeBox[/mnt]# ls
Docker Fichiers Usenet
root@HomeBox[/mnt]# rclone ncdu local:Fichiers
rclone ncdu v1.70.2 - use the arrow keys to navigate, press ? for help
-- /mnt/Fichiers ----------------------------------------------------------------------------------------------------------------------------------------------
2.321Ti [##########] /qbittorrentvpn2
381.995Gi [## ] /qbittorrentvpn1
2.180Gi [ ] /metube
360Ki [ ] /seedarr
52Ki [ ] /grabb2rss
e 0 [ ] /books
e 0 [ ] /chaptarrdl
e 0 [ ] /decypharr
e 0 [ ] /rclonecache
e 0 [ ] /riven
Les versions :latest et :fenrir-xx embarquent une fonctionnalité qui interroge les débrideurs pour connaître le nombre de slots d’upload disponibles sur le compte utilisé. Problème : AllDebrid ne gère pas ça via son API. Second effet Kiss Cool : cette option ne peut pour l’instant pas être désactivée, donc AD en erreur d’upload quand un magnet/.torrent n’est pas en cache.
L’astuce consiste à revenir sur une version plus ancienne de Decypharr, la :beta fonctionnant.
Et j’en profite pour vous présenter l’excellent script de Bouby, lecteur du blog (\o/), qui permet de nettoyer les magnets liés à un compte AD. En effet, chez AD un compte est limité à 5000 liens. Il faut donc parfois faire un peu de ménage, surtout quand on fait des bibliothèques Plex/Jellyfin où il faut clairement plusieurs comptes AD. Vous les voyez sur l’onglet Magnets de votre compte ou via l’API
status "success"
data { magnets: (704)[…] }
Un lien est ajouté quand on envoie un magnet ou .torrent sur son compte AD (captain Obvious!) mais aussi à CHAQUE recherche de contenu dessus via les outils Decypharr, DMM, Vortex, les addons sources de Stremio etc. Même si un contenu est en cache, le fait de le chercher en ajoutant un magnet/.torrent crée un lien sur votre compte. Je n’ai pas cherché et ne sais absolument pas comment AD gère ça côté utilisateurs, si des liens vieux de plus de X mois/années/heures sont retirés ou non.
Quoi qu’il en soit voici le script Python de Bouby (encore merci !). J’ai augmenté les seuils en fonction de la limite de 5000 liens/compte.
#!/usr/bin/env python3
import requests
from datetime import datetime, timedelta
# ----------------------------------------
# CONFIGURATION DU SCRIPT (variables en dur)
# ----------------------------------------
# Clé API AllDebrid — obligatoire pour accéder aux magnets
API_KEY = "xxx"
# Dry-run : True = le script affiche ce qu’il ferait sans supprimer
# False = suppression réelle
DRY_RUN = False
# -----------------------------
# Seuils et limites pour la purge
# -----------------------------
THRESHOLD_HIGH = 4700 # déclenche la purge normale si nombre total de magnets > 900
THRESHOLD_LOW = 2700 # limite minimale après purge pour ne pas trop supprimer =700
MAX_DELETE = 2000 # nombre maximum de magnets à supprimer en mode normal
MIN_AGE_DAYS = 7 # ne supprimer que les magnets plus vieux que X jours (sauf urgence)
# -----------------------------
# Mode urgence
# -----------------------------
EMERGENCY_THRESHOLD = 4900 # si le nombre total de magnets > 950, on active la purge d'urgence
EMERGENCY_DELETE = 2000 # nombre de magnets à supprimer immédiatement en urgence, ignore l'âge minimum
# -----------------------------
# API endpoint AllDebrid
# -----------------------------
# v4.1 est le nouvel endpoint pour récupérer les magnets
BASE_URL = "https://api.alldebrid.com/v4.1/magnet/status"
HEADERS = {"Authorization": f"Bearer {API_KEY}"}
# -----------------------------
# Catégories de statut
# -----------------------------
# Ces statuts sont utilisés pour trier les magnets par priorité
FAILED = {"Error", "error"} # magnets ayant rencontré une erreur
IN_PROGRESS = {"Processing"} # magnets en cours de téléchargement
DONE = {"Finished", "Ready"} # magnets terminés
# ----------------------------------------
# Récupérer tous les magnets depuis l’API
# ----------------------------------------
def get_magnets():
"""
Récupère la liste des magnets depuis l’API AllDebrid.
Retourne une liste vide si erreur ou endpoint obsolète.
"""
try:
r = requests.get(BASE_URL, headers=HEADERS, timeout=30)
r.raise_for_status()
data = r.json()
# Vérifie que la réponse contient bien les magnets
if "data" not in data or "magnets" not in data["data"]:
print("❌ Réponse API inattendue :")
print(data)
return []
return data["data"]["magnets"]
except requests.RequestException as e:
print("❌ Erreur réseau ou API :", e)
return []
# ----------------------------------------
# Supprimer un magnet par son ID
# ----------------------------------------
def delete_magnet(magnet_id):
"""
Supprime un magnet via l’API.
Si DRY_RUN = True, n’effectue pas la suppression mais affiche l’action.
"""
delete_url = "https://api.alldebrid.com/v4/magnet/delete"
if DRY_RUN:
print(f"[DRY-RUN] DELETE {magnet_id}")
return
try:
# POST pour supprimer le magnet
r = requests.post(delete_url, headers=HEADERS, data={"id": magnet_id})
r.raise_for_status()
print(f"✅ Supprimé magnet {magnet_id}")
except Exception as e:
print(f"❌ Erreur suppression {magnet_id} :", e)
# ----------------------------------------
# Trier et filtrer les magnets
# ----------------------------------------
def bucketize(magnets, ignore_age=False):
"""
Trie les magnets par statut et filtre par âge.
ignore_age=True ignore la limite MIN_AGE_DAYS (mode urgence)
"""
# Date limite selon l'âge minimum
cutoff = datetime.utcnow() - timedelta(days=MIN_AGE_DAYS)
# Séparer les magnets par statut pour appliquer la priorité
failed, progress, done = [], [], []
for m in magnets:
status = m.get("status", "")
created = m.get("uploadDate") or m.get("completionDate") or 0
created_dt = datetime.utcfromtimestamp(created) if created else datetime.utcnow()
# Filtrer par âge sauf si mode urgence
if not ignore_age and created_dt > cutoff:
continue
# Trier par statut
if status in FAILED:
failed.append(m)
elif status in IN_PROGRESS:
progress.append(m)
elif status in DONE:
done.append(m)
# Trier chaque catégorie par date de création (anciens d’abord)
for lst in (failed, progress, done):
lst.sort(key=lambda x: x.get("uploadDate", 0))
# Retourner tous les magnets dans l'ordre priorité : failed → progress → done
return failed + progress + done
# ----------------------------------------
# Fonction principale
# ----------------------------------------
def main():
"""
Logique principale :
- Récupère tous les magnets
- Vérifie les seuils
- Applique le mode urgence si nécessaire
- Supprime les magnets selon les règles
"""
magnets = get_magnets()
total = len(magnets)
print(f"Total magnets : {total}, Dry-run : {DRY_RUN}")
# Mode urgence
if total > EMERGENCY_THRESHOLD:
print("🚨 MODE URGENCE activé")
ordered = bucketize(magnets, ignore_age=True)
to_delete = ordered[:EMERGENCY_DELETE]
# Mode normal
elif total > THRESHOLD_HIGH:
print("Mode normal")
ordered = bucketize(magnets, ignore_age=False)
max_deletions = min(MAX_DELETE, total - THRESHOLD_LOW)
to_delete = ordered[:max_deletions]
else:
print("Seuil non atteint → rien à faire.")
return
# Supprimer les magnets sélectionnés
for m in to_delete:
mid = m.get("id")
name = m.get("filename") or m.get("name") or ""
status = m.get("status")
print(f"→ Suppression {status} : {name} (id={mid})")
delete_magnet(mid)
print("✨ Purge terminée.")
# ----------------------------------------
# Exécution du script
# ----------------------------------------
if __name__ == "__main__":
main()
Comme il le suggère, je le fais tourner avec un Docker Alpine. Chaque nuit à 3h.
Après avoir mis de côté UNRAiD, dont je me suis lassé, j’ai passé le LincStation N1 sous TrueNAS. Cet OS ne m’apporte rien d’autre que la gestion simplifiée des RAIDs via une WebUI (parce que bon… mdadm… c’est chiant). Enfin je ne cherche pas à utiliser l’OS pour être précis, je ne peux donc pas dire qu’il est nul ou top. M’en tape.
Les autres machines, tout aussi peu puissantes que le N1 sont sous Archlinux et Ubuntu. Arch parce que j’aime bien me demander chaque jour si une MàJ va plomber le serveur et comment je vais m’en dépatouiller (et c’est accessoirement mon desktop). Ubuntu, pour changer de Debian, parce que j’ai quand même besoin d’un truc stable dans ma vie de geek. N’utilisant quasi plus de VM/LXC depuis l’avènement de Docker, je n’ai plus de ProxMox.
Du coup, je shunte Ubuntu au profit d’une distribution basée sur Debian : ZimaOS ! Jai passé hier l’ensemble de mes services « utiles » sur TrueNAS pour libérer cette machine pour ce test.
Avertissement : c’est asiat’. Alors pour les complotistes américains peureux bas du front (rayez ou non les mentions inutiles), n’allez pas plus loin. Je n’ai absolument pas fait de RE pour savoir s’ils ont mis des backdoors. « Mais » CVE-2026-21891 (non encore relayée sur GitHub) / discussion Reddit et si j’ai pas sniffé le trafic, mon DNS ne fait rien ressortir d’extraordinaire. La machine ping même pas Baidu, contrairement à la majorité des objets IoT qui s’assurent d’être connectés à Internet en pingant le de Google chinoix (oui, eux aussi ont leur GAFAMBATX).
J’ai découvert cet OS par hasard, quand je cherchais des infos sur des boards de serveurs. J’ai d’ailleurs commencé par découvrir CasaOS, dont j’étais pas fans. Ça faisait un peu Docker in Docker. Pour moi c’est plus à voir comme une alternative à YunoHost (très bon projet pour ceux qui sortent d’une grotte et ne connaissent pas). Même ressenti pour Cosmos d’ailleurs. ZimaOS est développé pour leurs NAS ZimaCube mais on peut l’installer partout.
Ils font eux-mêmes la comparaison entre ZimaOS et CasaOS, en gros :
C’est un UNRAiD like, avec une interface plus moderne (avis 100% subjectif), avec des clients à la Synology pour Windows, macOS, Linux (AUR), iOS et Android, avec une documentation bien faite sans tomber dans un Wikipedia comme on peut le voir chez certains concurrents, un GitHub et donc la possibilité d’ouvrir des issues (ce qui est bien plus pratique qu’un forum),
Ça s’installe en 2-2 avec une clé USB (iso de 1.3Go) créée avec Balena et se gère uniquement via la WebUI.
Et il faut activer le Mode Développeur notamment pour désactiver l’indexation du contenu avec leur « IA » (pour faciliter la recherche) et autoriser SSH.
Première vraie configuration à faire, mon stockage. De mémoire j’ai que 2 disques dans ce PC mais la version gratuite permet d’en gérer 4 en RAID. Et la version payante coûte 29$ (« à vie »).
Comme j’ai qu’un SSD en sus de celui de l’OS, je me contente de le formater et ça l’ajoute bien ensuite en stockage. Ce que je vois d’ailleurs avec le widget de la dashboard, qui passe à 718Go de stockage.
Et donc, en standard, ZimaOS intègre un explorateur de fichiers, un outil de backup (depuis ou vers le NAS), un gestionnaire de VM et un PairDrop (je vois la machine sous Windows mais pas mon Arch, faudra que je trouve pourquoi). Depuis un client (Linux/iOS), on peut parcourir les fichiers du serveur et faire du backup. Notamment de photos depuis l’iPhone (arrière plan ou non).
On peut ajouter des liens externes à la dashboard, ce qui est une très bonne idée et pourrait m’inciter à me passer de mon brave Heimdall qui m’accompagne depuis maintenant des années…
Et nous terminons évidemment avec le fameux AppStore et ses 372 applications (Docker) « prêtes à installer » au moment de cet article. Rien de comparable avec UNRAiD, je vous l’accorde. Mais ici, ça s’installe en 1 clic.
Et on peut ajouter des dépôts et doubler, au moins, le nombre d’applications du store.
Tout comme il est possible d’installer une app via la WebUI si on elle n’est pas dans le Store et qu’on n’est vraiment pas à l’aise en console.
On peut tout à fait utiliser Docker en console ou via Komodo, Arcane, Dockge, Portainer/what ever. Et ça marche « out of the box » dans ce cas, il n’y a rien à adapter pour l’OS.
À noter que par défaut, les applications installées via l’AppStore sont dans /DATA, sur le disque système.
Comme ça se voit au-dessus, j’ai installé Pi-Hole depuis l’AppStore pour tester. Faut juste cliquer pour installer.
Pratique : en cas d’ajout de disques, on peut migrer les données facilement
Même si ZimaOS est basé sur Debian, c’est propriétaire et on ne peut pas utiliser Apt pour y installer ce qu’on veut. C’est une sécurité également, histoire de ne pas mettre en vrac l’OS (ce qu’on est nombreux à avoir fait avec Proxmox hein… mentez pas !!). Ceci dit ils ont prévu le coup. Ceci dit, leur OS embarque déjà bon nombre d’utilitaires tels que ncdu, jq, rclone…
Dans l’idéal, j’aimerais un dash qui permet de mieux intégrer quelques applications comme le font Heimdall, Homarr, Organizr etc.
Aperçu du client iOS
Avec le recul de cet article, je perçois ZimaOS comme un DSM de Synology, enfin plutôt un Xpenology vu qu’on peut l’installer où on veut, avec un peu de combo d’UNRAiD et cousins.
Enfin tous ces OS se ressemblent mais ZimaOS serait un peu le « macOS » du groupe, à vouloir proposer une expérience très esthétique, complète (Docker natif ou magasin d’applications), pratique (outils intégrés, y compris pour périphériques) et répondant AMHA à la plupart des besoins. Bien que propriétaire, contrairement à CasaOS qui est open source mais n’est qu’une surcouche.
Je pense le faire tourner quelques temps en parallèle de TrueNAS voir remplacer ce dernier. Et j’avais oublié, ça embarque aussi Btop++ pour afficher des stats temps réel.
Comet est un addon de sources pour Stremio, comme StreamFusion que j’ai déjà présenté. Seulement là où SF cible le contenu francophone, Comet va ratisser large.
Le premier addon Stremio pour proxyfier les flux Debrid, permettant l’utilisation du service Debrid sur plusieurs IP en même temps avec le même compte !
Limite de connexion maximale basée sur l’IP
Tableau de bord d’administration avec gestion de la bande passante, statistiques et plus…
Il permet donc de lire des contenus depuis des débrideurs ou depuis du torrenting direct (avec VPN !).
Comet (GitHub | Discord) est présenté par g0ldy comme l’addon le plus rapide pour Stremio, tout simplement parce qu’il constitue un cash des métadonnées des .torrents à partir des sources configurées.
On me confirme que les stats des caches de débrideurs – By Service Provider – sont fluctuantes et non révélatrices, on peut en avoir des milliers comme quasi rien. Testé avec AD, RD, TB et Premiumize, mêmes soucis de stats dans tous les cas. Mais c’est qu’une statistique, en lecture sous Stremio le contenu est bien trouvé.
Certains en ont des 10aines de millions de .torrents en attente d’ajout en base de données. Je débute et relance souvent l’outil donc il ne bosse pas beaucoup et j’ai pas mis beaucoup de sources vu que c’est un test. Et accessoirement, indexer tout le contenu VO de la Terre ne m’intéresse pas (certains indexent un dump de RARBG de quelques Po).
Comet est un indexeur de liens (sources) depuis tous les scrapers indiqués dans la description. C’est un addon de sources pour Stremio, avec filtres de résolution et langues notamment.
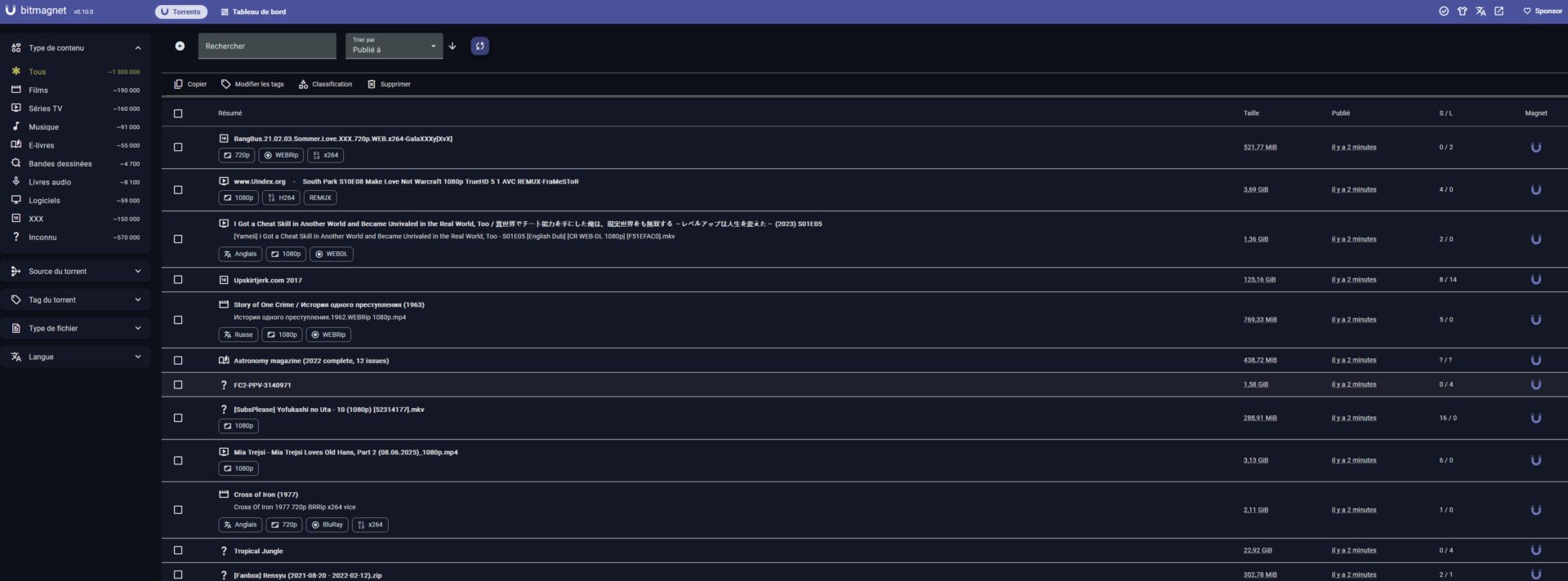
Et on peut multiplier les instances, j’ai par exemple un BitMagnet publique et mon instance (elle aussi relancée il y a peu donc pas encore beaucoup de contenu indexé).
Sans compter que mon pauvre Lincstation N1 se mange tout mon setup en ce moment vu que je réinstalle les autres machines. Il est bien brave avec son petit CPU ^^
Et comme g0dly trouvait qu’il ne gavait pas assez son Comet, il a décidé de lancer très récemment (encore en test dirons-nous) un réseau CometNet de partage de métadonnées entre instances (publiques et/ou privées).
Pour ne parler que de FRENCH/MULTi, Comet peut être un bon complément voire une alternative à StreamFusion, à condition d’avoir les bonnes sources. On peut aussi parier dessus, par exemple via BitMagnet, pour les trackers francophones qui disent vouloir publier leurs contenus en DHT. Dans ce cas, pas la peine d’indexer la planète. Si vous voulez du tout cuit : stremiofr.com propose une instance dédiée à la VF.
L’installation est simple, en Docker. Attention, mes paramètres CometNet (dans le .env) sont des tests et ils évoluent tous les jours en ce moment vu que c’est en plein développement/test. :beta pour les dernières MàJ de CometNet, :latest sinon
ADDON_ID=stremio.comet.fast
ADDON_NAME=Comet
FASTAPI_HOST=0.0.0.0
FASTAPI_PORT=8000
FASTAPI_WORKERS=1
USE_GUNICORN=True
GUNICORN_PRELOAD_APP=True
EXECUTOR_MAX_WORKERS=1
PUBLIC_BASE_URL=https://stremio-comet.xxx.xxx
ADMIN_DASHBOARD_PASSWORD=xxx
PUBLIC_METRICS_API=False
DATABASE_TYPE=postgresql
DATABASE_FORCE_IPV4_RESOLUTION=False
DATABASE_URL=comet:comet@postgres:5432/comet
DATABASE_PATH=data/comet.db
DATABASE_BATCH_SIZE=20000
DATABASE_STARTUP_CLEANUP_INTERVAL=3600
PROXY_DEBRID_STREAM=True
PROXY_DEBRID_STREAM_PASSWORD=xxx
METADATA_CACHE_TTL=2592000 # 30 days
TORRENT_CACHE_TTL=2592000 # 30 days
LIVE_TORRENT_CACHE_TTL=604800 # 7 days
DEBRID_CACHE_TTL=86400 # 1 day
DEBRID_CACHE_CHECK_RATIO=1 # Minimum ratio (0.5 = 5%) of cached torrents/total torrents required to skip re-checking availability on the debrid service.
METRICS_CACHE_TTL=60 # 1 minute
SCRAPE_LOCK_TTL=300 # 5 minutes - Duration for distributed scraping locks
SCRAPE_WAIT_TIMEOUT=30 # 30 seconds - Max time to wait for other instance to complete scraping
BACKGROUND_SCRAPER_ENABLED=True
BACKGROUND_SCRAPER_CONCURRENT_WORKERS=1 # Number of concurrent workers for scraping (adjust depending on whether you are often ratelimited by scrapers)
BACKGROUND_SCRAPER_INTERVAL=3600 # Interval between scraping cycles in seconds
BACKGROUND_SCRAPER_MAX_MOVIES_PER_RUN=100 # Maximum number of movies to scrape per run
BACKGROUND_SCRAPER_MAX_SERIES_PER_RUN=100 # Maximum number of series to scrape per run
CATALOG_TIMEOUT=30 # Max time to fetch catalog pages (seconds)
ANIME_MAPPING_ENABLED=True
ANIME_MAPPING_REFRESH_INTERVAL=432000 # Seconds between background anime mapping refreshes when using database cache (<=0 disables)
RATELIMIT_MAX_RETRIES=2 # Maximum number of retries for 429 Too Many Requests errors. Set to 0 to disable retries.
RATELIMIT_RETRY_BASE_DELAY=1.0 # Base delay in seconds for exponential backoff (e.g., 1.0 -> 1s, 2s, 4s, 8s...)
SCRAPE_PROWLARR=True
PROWLARR_URL=https://prowlarr.xxx.xxx
PROWLARR_API_KEY=xxx
PROWLARR_INDEXERS=[] # Leave empty to automatically use all configured/healthy indexers. Or specify a list of indexer IDs.
# Shared Settings
INDEXER_MANAGER_TIMEOUT=30 # Max time to get search results (seconds) - Shared by both
INDEXER_MANAGER_WAIT_TIMEOUT=30 # Max time to wait for the indexer manager to initialize (seconds)
INDEXER_MANAGER_UPDATE_INTERVAL=900 # Time in seconds between indexer updates (default: 900s / 15m)
# ============================== #
# Torrent Settings #
# ============================== #
GET_TORRENT_TIMEOUT=5 # Max time to download .torrent file (seconds)
DOWNLOAD_TORRENT_FILES=True # Enable torrent file retrieval from magnet link
MAGNET_RESOLVE_TIMEOUT=60 # Max time to resolve a magnet link (seconds)
DOWNLOAD_GENERIC_TRACKERS=False # Enable downloading generic trackers list at startup (for scraped torrents without trackers, doesn't work well most of the time)
# ============================== #
# Scraping Configuration #
# ============================== #
# Multi-Instance Scraping Support:
# - Single URL: Use a simple string for one instance (default behavior)
# - Multiple URLs: Use JSON array format for multiple instances
# - Example single: COMET_URL=https://comet.feels.legal
# - Example multi: COMET_URL='["https://comet1.example.com", "https://comet2.example.com"]'
#
# Scraper Context Modes:
# Each SCRAPE_* setting can control when scrapers are used:
# - true/both: Used for live scraping AND background scraping (default)
# - live: Only used for live scraping (when users request content)
# - background: Only used for background scraping (automatic content pre-caching)
# - false: Completely disabled
#
# Examples:
# SCRAPE_COMET=both # Used for both live and background scraping
# SCRAPE_TORRENTIO=live # Fast live scraping only
# SCRAPE_ZILEAN=background # Background cache building only
# SCRAPE_NYAA=false # Completely disabled
# SCRAPE_JACKETT=live # Jackett for live scraping only
# SCRAPE_PROWLARR=background # Prowlarr for background scraping only
SCRAPE_COMET=True
COMET_URL=["https://comet.feels.legal", "https://comet.stremiofr.com/"]
SCRAPE_ZILEAN=True
ZILEAN_URL=https://zileanfortheweebs.midnightignite.me
SCRAPE_STREMTHRU=True
STREMTHRU_SCRAPE_URL=https://stremthru.13377001.xyz
STREMTHRU_URL=https://stremthru.13377001.xyz
SCRAPE_BITMAGNET=True
#BITMAGNET_URL=https://bitmagnetfortheweebs.midnightignite.me
BITMAGNET_URL='["https://bitmagnetfortheweebs.midnightignite.me", "http://192.168.0.196:3333"]'
BITMAGNET_MAX_CONCURRENT_PAGES=5
BITMAGNET_MAX_OFFSET=15000 # Maximum number of entries to scrape
SCRAPE_TORRENTIO=True
TORRENTIO_URL=https://torrentio.strem.fun
SCRAPE_MEDIAFUSION=True
MEDIAFUSION_URL=https://mediafusion.elfhosted.com
MEDIAFUSION_API_PASSWORD= # API password for MediaFusion instances that require authentication
MEDIAFUSION_LIVE_SEARCH=True
SCRAPE_JACKETTIO=True
JACKETTIO_URL=https://jackettio.stremiofr.com/xxx
SCRAPE_NYAA=True
NYAA_ANIME_ONLY=True
NYAA_MAX_CONCURRENT_PAGES=5
SCRAPE_ANIMETOSHO=True
ANIMETOSHO_ANIME_ONLY=True
ANIMETOSHO_MAX_CONCURRENT_PAGES=8
SCRAPE_TORBOX=True
TORBOX_API_KEY=xxx
SCRAPE_TORRENTSDB=True
SCRAPE_PEERFLIX=True
DISABLE_TORRENT_STREAMS=False # When true, torrent-only requests return a friendly message instead of magnets
TORRENT_DISABLED_STREAM_NAME=[INFO] Comet # Stremio stream name shown when torrents are disabled
TORRENT_DISABLED_STREAM_DESCRIPTION=Pas de torrenting en direct # Description shown to users in Stremio
REMOVE_ADULT_CONTENT=False
RTN_FILTER_DEBUG=True # Set to True to log why torrents are excluded by RTN (debug only, verbose!)
DIGITAL_RELEASE_FILTER=False # Filter unreleased content
TMDB_READ_ACCESS_TOKEN=xxx
COMETNET_ENABLED=True
COMETNET_ADVERTISE_URL=wss://cometnet.xxx.xxx
COMETNET_KEYS_DIR=/data/cometnet/keys
COMETNET_POOLS_DIR=/data/cometnet/pools
# Network Discovery
COMETNET_BOOTSTRAP_NODES='["wss://cometnet-beta.feels.legal", "wss://cometnet.streamproxy.xyz", "wss://cometnet.selfhosting.sterzeck.com.br", "wss://https://cometnet.at16.co.uk/"]'
#COMETNET_BOOTSTRAP_NODES='["wss://cometnet-beta.feels.legal", "wss://cometnet.streamproxy.xyz"]'
COMETNET_MANUAL_PEERS=[] # JSON array: '["wss://friend.example.com:8765"]'
# Peer Management
COMETNET_MAX_PEERS=100
COMETNET_MIN_PEERS=3
# Contribution Mode: full (default) | consumer | source | leech
COMETNET_CONTRIBUTION_MODE=full
# Optional: Trust Pools (JSON array of pool IDs)
# COMETNET_TRUSTED_POOLS='["my-community"]'
# NAT Traversal (for home connections)
COMETNET_UPNP_ENABLED=True
# Gossip
COMETNET_GOSSIP_FANOUT=3
COMETNET_GOSSIP_INTERVAL=1.0
COMETNET_GOSSIP_MESSAGE_TTL=5
COMETNET_GOSSIP_MAX_TORRENTS_PER_MESSAGE=1000
COMETNET_GOSSIP_CACHE_TTL=300
COMETNET_GOSSIP_CACHE_SIZE=10000
# Validation
COMETNET_GOSSIP_VALIDATION_FUTURE_TOLERANCE=60
COMETNET_GOSSIP_VALIDATION_PAST_TOLERANCE=300
COMETNET_GOSSIP_TORRENT_MAX_AGE=604800
# Peer Discovery
COMETNET_PEX_BATCH_SIZE=20
COMETNET_PEER_CONNECT_BACKOFF_MAX=300
COMETNET_PEER_MAX_FAILURES=5
COMETNET_PEER_CLEANUP_AGE=604800
COMETNET_ALLOW_PRIVATE_PEX=False
COMETNET_SKIP_REACHABILITY_CHECK=False
COMETNET_REACHABILITY_RETRIES=5
COMETNET_REACHABILITY_RETRY_DELAY=10
COMETNET_REACHABILITY_TIMEOUT=10
# Transport
COMETNET_TRANSPORT_MAX_MESSAGE_SIZE=10485760
COMETNET_TRANSPORT_MAX_CONNECTIONS_PER_IP=3
COMETNET_TRANSPORT_PING_INTERVAL=30.0
COMETNET_TRANSPORT_CONNECTION_TIMEOUT=120.0
COMETNET_TRANSPORT_MAX_LATENCY_MS=10000.0
COMETNET_TRANSPORT_RATE_LIMIT_ENABLED=True
COMETNET_TRANSPORT_RATE_LIMIT_COUNT=20
COMETNET_TRANSPORT_RATE_LIMIT_WINDOW=1.0
# NAT Traversal
COMETNET_UPNP_ENABLED=False
COMETNET_UPNP_LEASE_DURATION=3600
# Reputation System
COMETNET_REPUTATION_INITIAL=100.0
COMETNET_REPUTATION_MIN=0.0
COMETNET_REPUTATION_MAX=10000.0
COMETNET_REPUTATION_THRESHOLD_TRUSTED=1000.0
COMETNET_REPUTATION_THRESHOLD_UNTRUSTED=50.0
COMETNET_REPUTATION_BONUS_VALID_CONTRIBUTION=0.001
COMETNET_REPUTATION_BONUS_PER_DAY_ANCIENNETY=10.0
COMETNET_REPUTATION_PENALTY_INVALID_CONTRIBUTION=50.0
COMETNET_REPUTATION_PENALTY_SPAM_DETECTED=100.0
COMETNET_REPUTATION_PENALTY_INVALID_SIGNATURE=500.0
Tous ces clients ne sont pas encore disponibles sur ATV, la plupart sont en beta cependant.Merci @beluchon qui m’a fait découvrir Aurora. Je teste d’ailleurs cette dernière sur Windows, la version ATV n’existant pas encore et n’ayant pas mis la main sur la version Linux. Vous avez le droit de me basher pour utiliser Windows, je mérite.
J’aime bien Stremio pour ce qu’il représente : la simplicité du streaming via une application selon ses sources ou des partagées. On peut tout auto-héberger en prime. C’est geek, je kiffe !
J’aime moins le logiciel Stremio, que ce soit sur PC ou ATV, parce qu’on ne peut pas vraiment le personnaliser et que c’est quand même un grand écart quand on vient de Plex/Jellyfin.
Stremio, pour rappel.
RealStream (Discord), peut s’installer via ce code à la rédaction de cet article : 7896559
Fun fact : même idée à la con que Netflix sur ATV, pour quitter faut aller dans les paramètres…
On peut lui ajouter tous les addons Stremio, testé avec Comet et StreamFusion. Il embarque déjà TMDB donc je n’ai pas testé avec AIOMedata.
Si on met l’interface en français, les synopsis changent évidemment de langue
La mise en forme change un peu de Stremio mais on reste sur les défauts, selon moi, de ces solutions de streaming à savoir que ça liste des contenus qui ne sont pas forcément disponibles dans la langue du client.
À date, RealStream, même s’il accepte les catalogues externes (via mon addon AIOMetadata), ne peut pas les afficher sur l’accueil. On y accède via le menu Discover uniquement comme ici pour les films.
Je suis une buse… Merci @zHaades
En ajoutant mes catalogues, via l’addon AIOMetadata, je peux les avoir en page de l’accueil en sélectionnant « addons » au lieu de TMDB dans les paramètres de RealStream.
Nuvio (GitHub officiel | Fork pour ATV), les codes sont sur la page des releases. C’est vraiment de la beta pour ATV pour l’instant. Chez moi ça plante dès que j’ajoute AIOMetadata, pour avoir mes catalogues.
On peut installer des addons via les URLs des manifestes tout comme on peut installer des instances publiques (shitHosted and co).
Aurora (Discord | site). C’est une beta fermée, les applications ne s’obtiennent que via un don ou une liste d’attente. J’ai mis la main sur une version Windows pour cet article. On m’a conseillé d’utiliser MPV pour lire les vidéos. Autant ça me claque d’avoir testé un truc sur Windows, autant c’est la meilleure alternative à Stremio que j’ai testée ^^
J’espère que la version ATV sera aussi bien finie.
ZorinOS est de ces Linux à la belle allure, qui se veut remplacer Windows et macOS (pour Monsieur et Madame Toutlemonde). C’est une bonne idée, ça permet d’avoir un truc clés en mains plutôt que de paramétrer un DE. C’est donc très pratique pour démocratiser l’usage de Linux (hors gaming en ligne, comme toujours, puisque les anticheats ne sont pas compatibles Linux).
Ils visent les pros et étudiants et vivent grâce aux dons, la vente de matériel embarquant leur OS ou encore en vendant une version Pro de Zorin. Zorin est basé sur Ubuntu et embarque Gnome comme environnement graphique et c’est open source, donc publié. Ils font un vrai travail de mises à jour, de suivi des drivers etc. Et ça peut tourner sur la dernière bête du marché comme le PC du grand-père.
Même si je comprends que tout ne peut pas être gratuit sur Internet et dans le monde de Linux, je trouve dommage de faire payer une version Pro qui n’est que de la cosmétique, open source et gratuite.
Que ce soit en version Core ou Pro, ça mange de la place sur le disque. Moi qui suit habitué à Archlinux, ici ça consomme quasi 25Go.
Je vais me l’installer sur un vieux laptop qwerty qui me sert en mobilité. C’est quand même plus simple de se trimballer avec une base Ubuntu que Arch.
Cet outil proposé sur GitHub permet de retirer des ou tous les éléments IA inclus dans Windows 11, d’en empêcher ou non la réinstallation et le tout avec la sécurité d’une sauvegarde.
Comme c’est fait pour des gens sous Windows, ça peut s’utiliser avec une interface. Mouahahahah (mais oui, mais quel c*nnard ce Aerya !)
J’ai vérifié et j’ai bien la version de Windows qui est dite embarquant de l’IA mais utilisant peu ce PC j’avoue que j’ai jamais vu d’IA dessus. Et donc je ne comprends honnêtement pas à quoi sert ce que je viens de montrer
Mais comme je peux réinstaller ce Windows à foison vu qu’il ne me sert qu’à jouer, ça permet de tester l’outil sans trop d’incidence.
Dans tous les cas, ça fera déjà ça de moins d’envoyé à Microsoft quand je lance un jeu… Vraiment dommage que le gaming en ligne soit impossible sous Linux du fait des anticheats…
Très habitué à utiliser Seerr (qui est toujours Jellyseerr pour l’instant) pour m’ajouter des contenus à voir sur Plex/Jellyfin via Radarr et Sonarr, c’est la fonctionnalité qu’il me manquait sur Stremio. Pour moi c’est vraiment plus simple que de passer par des listes, depuis smartphone notamment.
Du coup, j’ai créé SeerrCatalog : addon de catalogues films & séries pour Stremio qui émule Radarr, Sonarr et Jellyfin pour faire des demandes de contenus depuis Seerr.
Demande de film ou série dans Seerr -> selon sources et dispo, alors catalogues sous Stremio avec notification de disponibilité sur Seerr.
Une fois son compte Stremio ajouté à SeerrCatalog, les médias ajoutés sont recherchés via les addons liés au compte et les sources (avec filtres de langue et résolution) sont listées et l’information est remontée à Seerr qui catégorise donc la demande comme complétée.
Pour faire simple, vu qu’il n’y a aucun téléchargement mais juste une recherche de release compatible dans les addons de sources sous Stremio, les profils de recherche sous Seerr n’ont aucune importance, de même qu’ajouter une ou X saison.s d’une série. Dans ce dernier cas, seul le S01E01 est recherché, s’il est présent alors SerrCatalog considère la série comme « trouvée ». Je voulais que les contenus ajoutés soient marqués en Manquants ou Disponibles, comme on l’a avec de vraies instances de Radarr et Sonarr. (check toutes les 5 minutes, par défaut dans Seerr).
C’est multi-utilisateur, le 1er créé étant l’administrateur. Et c’est à peu près traduit en anglais.
Mon but était aussi de rendre Stremio un peu plus compatible avec les installations multimédia auto-hébergées, basées sur des stacks arrs. On est en 2026, l’automatisation est pratique en plus d’être passionnante et ça n’empêche heureusement pas de parcourir différents sites pour découvrir contenus et communautés.
Pour l’installer, le GitHub est à disposition. Il faut copier le compose et le .env
Ici il faudra changer le volume local pour les données de SeerrCatalog
# SeerrCatalog Configuration
# API Key for Radarr/Sonarr emulation, can be whatever you awnt
API_KEY=zblob1237
PORT=7000
HOST=0.0.0.0
# Set this to your public URL if behind a reverse proxy
BASE_URL=https://stremio-seerrcatalog.domain.tld
# https://www.themoviedb.org/settings/api / can also be filled from the WebUI
TMDB_API_KEY=xxx
Au lancement, le 1er utilisateur créé sera l’administrateur
Pour chaque utilisateur on trouve les paramètres adéquats pour lier SeerCatalog à une instance Serr.
Il faut ajouter un compte Stremio pour chaque utilisateur. Ceci listera la liste de tous les addons et SeerrCatalog se basera sur ces derniers pour la recherche de releases pour déclarer les contenus ajoutés en « Disponibles ».
Pour chaque utilisateur/compte Stremio on peut paramétrer un filtrage sommaire des releases pour que les contenus soient déclarés ou non Disponibles. Peu importe mes addons par exemple, ici SeerrCatalog ne marquera le contenu comme Disponible que s’il trouve des releases taggées avec FRENCH ou MULTI et de résolution 1080p et supérieures. C’est dans l’optique d’avoir un fonctionnement traditionnel de Seerr, indique normalement (y compris en notifications) si un contenu est disponible ou non. Pour pousser le raisonnement au bout, on peut imaginer la recherche et l’ajout de .torrents ou .nzb via divers addons liés à Stremio.
Du coup il faut aussi lier une instance Seerr à l’addon (ce qui peut se faire plus tard, après y avoir créé un compte à l’étape suivante). La clé TMDB sert à avoir les affiches dans l’addon mais aussi à identifier correctement les contenus demandés depuis Seerr.
Évidemment, il convient d’ajouter l’addon à Stremio, sinon ça perd de son intérêt ^^’
De là, on peut ajouter des instances Radarr et Sonarr sur Seerr où y créer au préalable un compte si on n’en a pas (via l’émulation Jellyfin).
Encore une fois, peu importe les profils de qualité, root folder etc
Et on peut du coup profiter de Seerr pour s’ajouter des contenus à voir sous Stremio
Toutes les demandes ajoutées et pour lesquelles SeerrCatalog trouve une source dans les addons du compte Stremio, selon les tags demandés, sont ajoutées dans les catalogues Films et Séries.
Et selon les notifications activées dans Seerr, on a l’info quand la demande est disponible.
Pour les médias où aucune source n’est trouvée, SeerrCatalog fait une recherche chaque 24h.
En théorie, Autobrr n’est plus à présenter, très bonne relève d’AutoDL-irssi et Flexget, fidèles compagnons du téléchargement notamment BitTorrent d’il y a… plusieurs années (ça met un ‘tit coup de vieux là).
Depuis quelque temps déjà, qBittorrent est plébiscité à ruTorrent/rTorrent dans les stacks de téléchargement. Interface moins vieillissante, plus de paramètres, qui se gèrent via la WebUI, meilleure stabilité avec les gros volumes de torrents (5000+), plus performant pour le racing etc.
Bref, tout client qui permet de télécharger et partager est par définition un bon client BitTorrent. Les goûts et les couleurs… j’utilise également toujours une instance de xxacielxx/rutorrent.
Je suis aussi de ceux qui montent une ou plusieurs instances de téléchargement par catégorie, par serveur, par VPN…
Qui permet donc de gérer plusieurs instances qBit dans une seule interface, de gérer le cross-seeding, d’ajouter des indexeurs (directement ou via Prowlarr/Jackett), d’ajouter des flux RSS, pour de la recherche automatisée et répartie sur les instances de son choix. Et on peut ajouter des proxies. Je vois que certains thèmes sont « Premium », sympa si on veut faire un don.
Je trouve l’outil pratique pour gérer mes instances depuis une seule WebUI mais il est évidemment plutôt taillé pour le cross-seeding. Bien que certains trackers voient ça d’un mauvais œil parce qu’ils arguent que c’est de la triche puisqu’on peut faire du ratio sans rien avoir téléchargé chez eux, on peut aussi prendre en compte l’intérêt de ne stocker qu’une seule fois des FullBD ou packs de séries de 150Go et les partager sur plusieurs sites plutôt que de devoir faire des choix dans le stockage/seed pour tel ou tel site. Je suis pas le dernier à faire des remarques de vieux c*n mais faut quand même vivre avec son temps. Si le ghost leeching (à la mode en ce moment) ne sert effectivement à personne sur un tracker BitTorrent, le cross-seeding permet de pérenniser un peu la durée de vie de certains gros fichiers. Plutôt intéressant dans un contexte de P2P non ?
J’avais déjà présenté Decypharr « normal » et Usenet il y a quelques mois.
La nouvelle mouture ajoute notamment :
Le support du streaming via Usenet (multi providers),
La possibilité d’utiliser plusieurs comptes d’un même débrideur (pratique pour AD vu qu’il y a une limite de 5000 torrents/compte)
Le support de montages rClone externes tout comme l’ajout d’un système de fichiers propre à Decypharr,
Une refonte du WebDAV (plus pratique à parcourir),
Lors de l’ajout manuel de .torrent/.nzb on peut maintenant choisir de créer du symlink (Plex), STRM (Jellyfin), télécharger localement ou aucun…
On n’oubliera pas mon outil DecypharrSeed qui permet de seeder tout ou partie des .torrents utilisés via Decypharr (qu’il faudrait que je traduise un jour en anglich pour qu’il ait plus de succès).
Pour l’installer, on peut reprendre le compose existant et simplement changer l’image (ça reprend sans risque la configuration existante) :
Je crois que j’ai ENFIN trouvé le lecteur de musique que j’aime !
J’ai jamais été consommateur de musique, de qualité lossless du moins (Rikito, si tu me lis), au point d’être un gros membre de WCD et ses successeurs où je ne suis d’ailleurs plus.
Mais en bon geek curieux, j’ai toujours eu un œil sur les solutions d’hébergement/téléchargement/streaming de musique. Je me contente d’ajouter des .torrent à Decypharr/AllDebrid, ne voulant plus stocker directement chez moi (hormis un peu de partage via DecypharsSeed) et ne supportant plus Lidarr (même en hébergeant mon instance pour les métadonnées).
Il m’a cependant été impossible de trouver un lecteur (Web et/ou iOS/Android) qui réponde à mes besoins : beau & moderne, simple, avec recherche par genres, artistes similaires, playlists et paroles notamment. En gros : une copie de Spotify.
J’ai relancé il y a quelques semaines mon Navidrome qui prenait la poussière dans un vieux reste de stack audio auto-hébergée. Après avoir des années utilisé Subsonic et dérivés, Plex ou encore Jellyfin pour jouer un peu de musique, j’étais passé sur Navidrome pour sa modularité et « bonne allure » de serveur de streaming dédié à ce type de médias. Comme je veux l’utiliser avec Decypharr/AD, j’ajuste les volumes en conséquence : – /mnt/:/mnt/:rshared – /mnt/Fichiers/decypharr/qbit/music:/music:ro
Et j’utilise toujours Spotify, en sus de Deezer, pour les métadonnées. Pour le reste des variables d’environnement, tout est expliqué dans la documentation. Pour cet article je n’ai mis que 3 albums en test.
services:
navidrome:
image: deluan/navidrome:latest
user: 1000:1000
ports:
- "4533:4533"
restart: always
environment:
- TZ=Europe/Paris
- ND_BASEURL=https/audio.domain.tld
- ND_AGENTS=spotify,deezer
- ND_DEEZER_ENABLED=true
- ND_ENABLEDOWNLOADS=false
- ND_ENABLEEXTERNALSERVICES=false
- ND_HTTPSECURITYHEADERS_CUSTOMFRAMEOPTIONSVALUE=SAMEORIGIN
- ND_IGNOREDARTICLES="The El La Los Las Le La Les Os As O A Du"
- ND_IMAGECACHESIZE=10GB
- ND_LASTFM_ENABLED=false
#- ND_LISTENBRAINZ_BASEURL=https://mb.domain.tld
- ND_LISTENBRAINZ_ENABLED=true
- ND_RECENTLYADDEDBYMODTIME=true
- ND_SCANNER_ENABLED=true
- ND_SCANNER_SCHEDULE="0 * * * *"
- ND_SCANNER_WATCHERWAIT="10s"
- ND_SCANNER_ARTISTJOINER= " | "
- ND_SCANNER_FOLLOWSYMLINKS=true
- ND_SCANNER_PURGEMISSING=always
- ND_SEARCHFULLSTRING=true
- ND_SPOTIFY_ID=xxx
- ND_SPOTIFY_SECRET=xxx
- ND_SUBSONIC_ARTISTPARTICIPATIONS=true
volumes:
- /mnt/:/mnt/:rshared
- /mnt/Docker/navidrome:/data
- /mnt/Fichiers/decypharr/qbit/music:/music:ro
Mais il me manquait encore surtout un tri par genres et… une WebUI plus moderne.
Je suis tombé sur Feishin qui est à la fois un client (desktop/Web) de streaming pour Navidrome, Jellyfin et Subsonic et un agrégateur de serveurs puisqu’on peut en ajouter plusieurs. On peut donc imaginer un partage de serveurs de musique Jellyfin entre amis.
Gavé d’options !
Attention, c’est avant-tout un client desktop (tous OS) et donc ne propose pas de système d’authentification. Ce qui fait que lorsque comme moi on l’installe en Docker pour en profiter hors LAN (via mon iPhone notamment), il faut ajouter un système d’authentification tel qu’Authelia ou bien « à l’ancienne », via Nginx proxy Manager dans mon cas :
Sur une machine Linux (ou dans un Docker), installer de quoi créer le mot de passe encoder à filer ensuite à NPM.
sudo apt install apache2-utils
Puis, créer un fichier htpasswd avec un utilisateur et un mot de passe dans un dossier auquel accède NPM
root@StreamBox:/home/aerya/docker/npm/data# htpasswd -c htpasswd aerya
New password:
Re-type new password:
Adding password for user aerya
Et on peut alors passer ça en paramètre dans NPM pour avoir le fameux pop-up d’identification quand on va sur l’URL concernée
Comme j’ai déjà Navidrome qui tourne sur https://audio.domain.tld, je mets Feishin sur https://music.domain.tld
Et le compose de Navidrome est très léger vu que ce n’est qu’une interface pour un autre outil
À la 1ère connexion il faut ajouter ton serveur. Il propose par défaut celui configuré dans le compose du dessus
Sur AndroidTV, j’utilise Symfonium de Tolriq, que j’ai bien connu dans une autre vie. Application payante (onetime 7-10€ selon frais) mais qui vaut le coup, jetez un œil à sa présentation sur le PlayStore.
Et sur iPhone, j’avais Amperfy et suis passé depuis peu sur Arpeggi, qui est en TestFlight (et closed source hélas…).
J’ai migré mon LincStation N1 d’UNRAiD à TrueNAS CE (ex TrueNAS Scale, ex FreeNAS), que je redécouvre avec grand plaisir.
EDIT : on peut passer l’interface en français dans les options, tout comme on peut choisir son shell (zsh de base, je suis repassé en Bash) EDIT2 : oui, mon titre est réducteur.
Très longtemps utilisateur de ProxMox, depuis l’avènement de Docker je me servais de moins en moins les VM/CT. Après l’avoir utilisé avec Docker (directement sur l’hôte), j’ai ensuite bifurqué sur du 100% Linux sans interface chez moi avec Debian, Ubuntu et ArchLinux. Ce dernier n’étant pas le plus stable pour un serveur, vu le principe de rolling release, il faut être à l’aise avec Arch dans ce contexte.
Trouvant OpenMediaVault inadapté à mes besoins, Xpenology (comme un hackintosh mais pour DSM de Synology) encore moins pour un serveur de prod, j’avais fait un passage par TrueNAS Scale à l’époque mais le trouvais là encore trop peu pratique dans mon cas (manquant de simplicité). En me rapprochant de SuperBoki, je m’étais acheté une licence Pro à vie d’UNRAiD puis un LincStation N1 à l’occasion de sa promotion sur le site d’UNRAiD. Petit serveur, aussi bien physiquement qu’en terme de ressources, ce petit NAS basse consommation répond toujours très bien à mes besoins (hors post sur Usenet, le pauvre CPU ayant morflé quelques fois…).
Au fil du temps, j’allais surtout sur UNRAiD pour parcourir le magasin d’applications et faire quelques découvertes, UNRAiD étant très populaire chez les hoarders et dans l’univers de l’auto-hébergement lié au P2P and co. Mais je n’y allais que pour ça. Au final, UNRAiD ne me servait qu’à avoir une gestion simplifiée et très user-friendly du stockage. Je gérais, quasi depuis le début, mes Dockers comme j’aime, donc pas via UNRAiD : en console, via Dockge voire Portainer ou plus récemment Arcane. Des outils qui, à mon sens, ne dépendant pas de l’OS, permettent une plus grande liberté d’actions, manipulations et migrations entre machines (j’en ai actuellement 3 au garage). Et en plus quand un truc tourne rond, je suis de ceux qui ne sont pas contents, je pense que c’est le lot des bidouilleurs.
J’ai récemment remisé dans un tiroir ma clé USB UNRAiD et décidé passer ce petit NAS sous TrueNAS CE, l’évolution de Scale (donc la version gratuite). Mon but cette fois-ci était précis : trouver un gestionnaire de stockage simple et efficace, qui me laisse beaucoup de liberté de gestion tout en me permettant de gérer mon stockage de manière très intuitive (autrement qu’en console via mdadm).
Je ne vais pas présenter l’OS vu que je ne m’y suis pas vraiment attardé autrement que pour la gestion des disques et partages. Il permet de créer VM, CT et mettre en place des Dockers. Il propose, comme UNRAiD mais bien moins fourni, un magasin d’applications (environ 300 pour l’instant, rien de comparable à UNRAiD donc et logiquement orientées pro/services plus que P2P etc).
J’utilise ZFS pour créer mes pools (des VDEVs) de stockage. Docker, RAID1 de 2 NVMe de 250Go. Ne remplace pas une sauvegarde régulière mais me permet la perte d’un disque pour reconstruire le RAID sans perdre les données.
Fichiers, en stripped (RAID0) de 2 SSD de 2To. Si un disque meurt, tout le pool est irrécupérable. Dédié à BitTorrent etc, que des données que je peux perdre.
Usenet, composé d’un seul disque NVMe d’1To. Parce que je ne savais vraiment pas quoi en faire… Il pourrait me servir à faire un peu de DL/Post pour Usenet.
Il me reste encore un disque d’inutilisé. Si je décide de remettre Plex/Jellyfin, il pourrait servir de cache. J’ai pas utilisé de chiffrement, il n’y a aucun service confidentiel dessus et en plus c’est stocké chez moi.
Je fais des backups de mes Dockers à l’ancienne via un script Bash pour l’instant (oui je sais, on arrive en 2026). Il va falloir que je me penche sur les options intégrées à TruenAS !
J’aime la gestion simplifiée des services
Idem pour les partages. On voit d’ailleurs que j’ai fait en sorte de pouvoir monter Fichiers sur mon Windows de jeu, vu que j’ai le temps de jouer en ce moment (…) pour récupérer mes jeux téléchargés.
Là encore, la gestion des utilisateurs est étonnante de simplicité et pourtant très complète
Je redécouvre cet OS avec grand plaisir, notamment avec le recul que j’ai pris à écrire cet article. Je le trouve bluffant de simplicité sans pour autant faire de concession sur la sécurité ou les options. Même si j’ai conscience de ne pas l’exploiter, j’ai enfin trouvé un OS qui répond à mes besoins du moment, se configure en 8 minutes et me laisse libre de l’utiliser comme bon me semble.
On peut gérer cron et systemd via ses options également.
Je pense que YGGapi n’est plus à présenter, enfin pour ceux qui s’intéressent un minimum au P2P/streaming, et on sait que son principal intérêt est aussi son principal défaut : la non-publication du code source.
Code non publié = impossibilité pour YGG de patcher/bloquer/freiner son utilisation. Code non publié = peur de certains de se faire usurper leur passkey (passkey de YGG… mouahahahahahah. Pardon.)
Bref, c’est là que UwUDev intervient en proposant Ygégé qui est, en un peu différent, un YGGapi à auto-héberger. Compatible avec Jackett et Prowlarr.
Résolution automatique du domaine actuel de YGG Torrent
Consommation mémoire faible (14.7Mo en mode release sur Linux)
Recherche de torrents très modulaire (par nom, seed, leech, commentaires, date de publication, etc.)
Recuperation des informations complémentaires sur les torrents (description, taille, nombre de seeders, leechers, etc.)
Pas de dépendances externes
Pas de drivers de navigateur
Documentation pour Docker et TMDB. J’ai pas constaté de différence flagrante vs l’utilisation de YGG dans Prowlarr via Flaresolver/Byparr mais on peut penser que ça viendra.
Voici mon installation via VPN. Parce que oui, c’est un accès à un site au contenu illicite, donc ça se fait via VPN comme pour tout ce genre de contenu (#mode vieux schnock, je sais).
Et ça s’intègre à Prowlarr comme d’habitude via une Custom Definition. Faut penser à changer l’URL d’accès si comme chez moi c’est hébergé sur une autre machine.
Ceux qui me côtoient savent que la préservation de ma vie privée m’importe, notamment la numérique : pas de réseau social, PC/tablettes et smartphones sous VPN ou proxy voire Tor, auto-hébergement autant que possible des services que j’utilise (ou de leurs alternatives), gestion de mes caméras et tout le toutim. Et j’utilise des navigateurs qui ne se paient pas sur mon dos, à savoir en ce moment Librewolf & Safari. Et à chaque page chargée, ils envoient l’info que j’utilise Windows, Linux, Android ou macOS, en anglais ou en français etc.
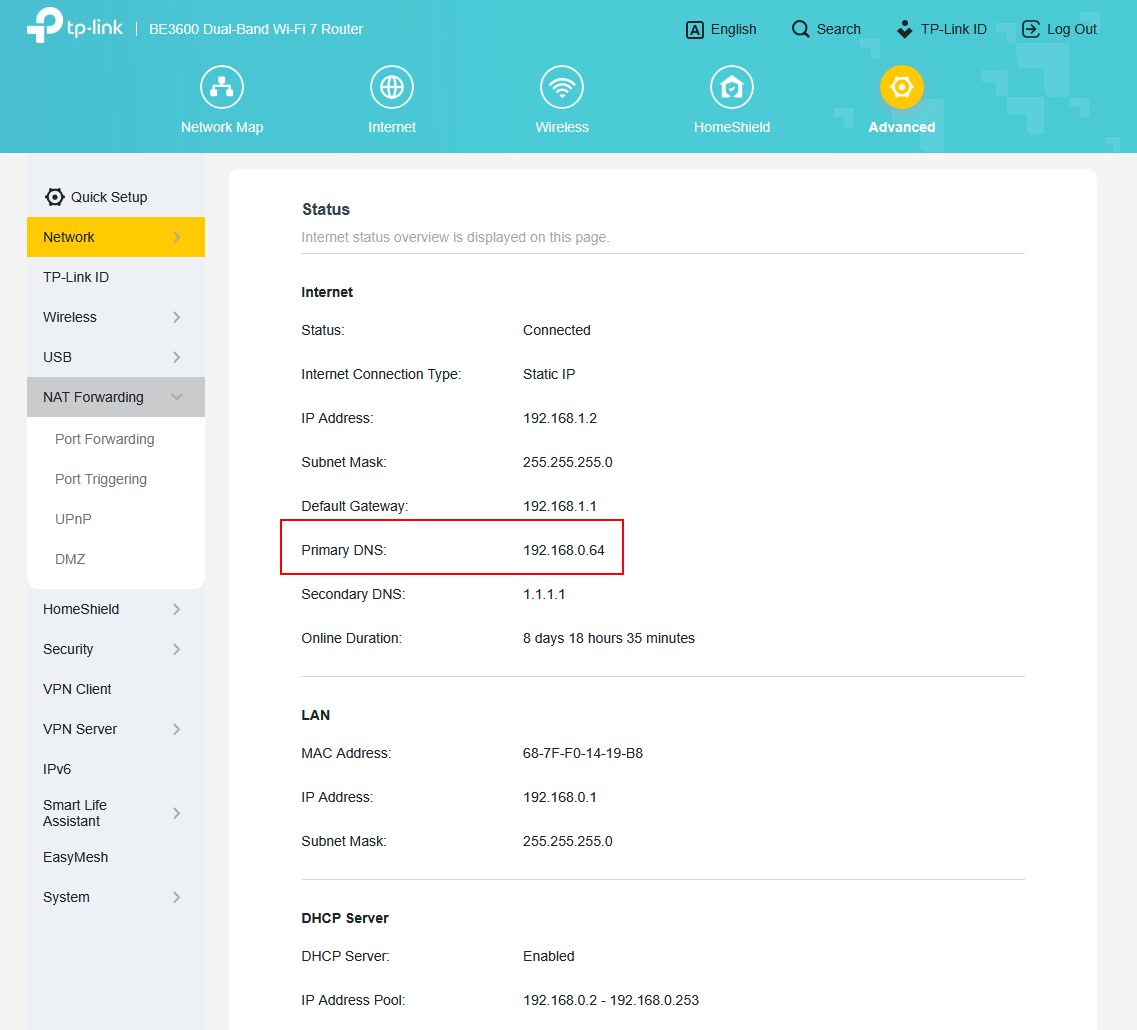
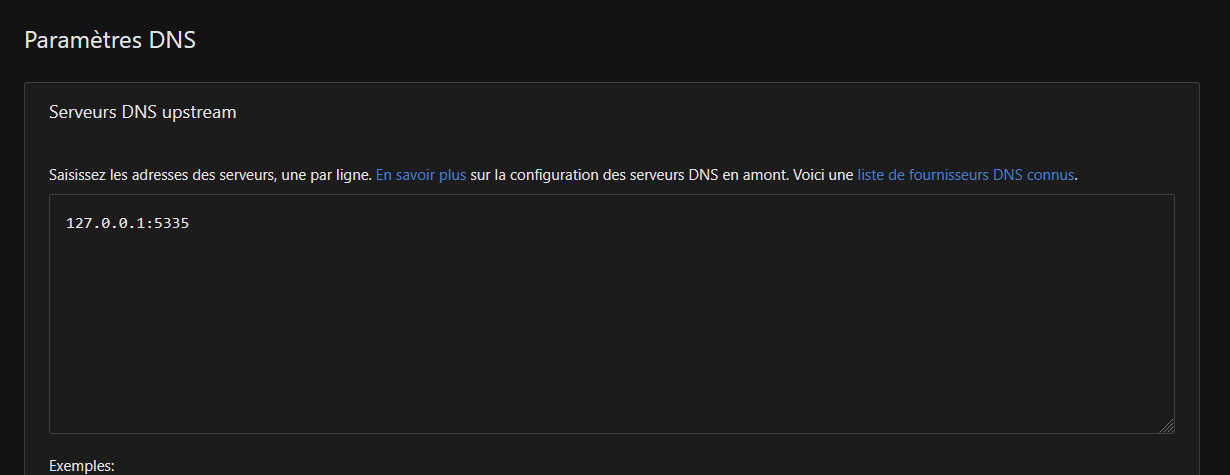
À la maison, c’est très simple, pour le WiFi/Ethernet : tout passe par mon serveur AdGuardHome, qui sert de serveur DNS et filtre les requêtes et réponses, qui lui-même passe par à Unbound, qui est un résolveur DNS avec un cache, le tout avec une petite couche de Redis, qui sert de cache.
Le but ? Améliorer la rapidité des réponses en les mettant en cache. Vu qu’on interroge très souvent les mêmes sites (joindre un moteur de recherche, consulter les emails, services de mises à jour etc), on gagne quelques millisecondes et ça fait moins travailler AGH, donc la machine qui l’héberge, puisqu’il trouve de suite ses réponses à nos requêtes DNS. Ce n’est que de la logique, exprimée par de la technique.
Alors c’est simple, si vous avez un minimum de connaissances en Linux ou envie de chercher/apprendre un peu, avez une machine sous Linux qui tourne 24/7 et souhaitez maîtriser votre Internet en bloquant pubs, traqueurs, porno, réseaux sociaux, etc.
Il faut d’abord une IP dédiée (192.168.0.64 chez moi) sur le réseau pour le résolveur DNS, qui sera ensuite à configurer sur tous les PCs, smartphones, tablettes, serveurs, consoles, TVs, etc ou, plus simple, à configurer sur la box FAI ou sur un routeur, de cette manière on évite de configurer chaque équipement de la maison. Chez Free je pouvais mettre ce DNS dans la box mais avec Orange, j’ai dû ajouter un routeur qui gère mon réseau…
Dans la configuration de base fournie avec ce Docker, vous pouvez par exemple commencer par décommenter les DNS de DNS4all, Quad9 et Yandex. IPv4 et/ou v6 selon l’Internet que vous avez chez vous.
Voici les stats depuis mon dernier reset de cet été.
Je ne vais pas détailler la configuration d’AdGuardHome puisqu’il suffit de lire. Voici les listes que j’utilise (qui se mettent dans le fichier de configuration AdGuardHome.yaml).
Quant aux smartphones, en ce moment nous sommes sur iPhone, on peut filtrer efficacement de 2 manières mais dans tous les cas en passant par un VPN. Soit en installant un serveur VPN à la maison, qui utilise le DNS local et en mettant le client sur smartphone soit en utilisant un VPN « commercial » qui permet de filtrer les DNS. Ayant un compte AirVPN (lien sponso) depuis des années je me contente d’utiliser ce dernier, avec ces filtres DNS (à configurer chez eux)
Pour l’utiliser il faut créer un profil Wireguard et l’installer/activer après avoir installé Wireguard.
Des clients me demandaient souvent comment filtrer le surf de leurs enfants. Si cette solution de serveur DNS hébergé permet de filtrer au mieux l’accès aux réseaux sociaux, porno etc, rien n’est 100% sécurisé ni fiable. On le sait tous, il n’y a rien de plus simple que d’accéder à du contenu porno par Internet : chats, messageries, forums, blogs, galeries etc. Sans compter que désactiver un VPN sur un smartphone n’est pas impossible même si des outils de contrôle parental peuvent le compliquer. Et on sait tous qu’en discutant à droite à gauche on a vite fait d’obtenir des infos pour passer outre les blocages.
J’informais mes clients que ces solutions sont seulement contraignantes mais absolument pas pérennes, selon l’âge et la maturité des bambins.
Bonus : quelques extensions Librewolf liées à cette thématique :
Sponsorblock pour bloquer pubs et passages de sponsoring sur YouTube
Du moins pour un indexeur Usenet privé, pour l’instant.
J’utilise Stremio en ce moment pour la VoD et comme j’adore un certain site lié à Usenet, je voulais pouvoir en profiter aussi comme ça.
UseFlow-Fr n’est pas un addon de stream. Il récupère les derniers référencements via un flux RSS et les arrange dans des catalogues pour Stremio.
Pour streamer ces contenus via BitTorrent/débrideurs j’utilise StreamFusion et pour Usenet je passe par le tout frais addon Usenet-Streamer qui utilise à son tour le fantastique NZBdav (cf le blog pour des tutos à ce sujet).
C’est un film d’ILLUSTRATION, je ne regarde PAS ça ! ^^’
Les catalogues sont aussi en Découverte
Et comme c’est mon kiff, j’ai ajouté les notifications Discord suite à une synchronisation, avec ou sans les affiches des derniers contenus répertoriés. Merci à ChatGPT qui m’a trouvé la solution pour créer le visuel des 5 affiches pour Discord.
Pour l’instant ça ne peut gérer, du moins testé à 100%, qu’un flux RSS précis que sans doute peu de lecteurs auront. Je prévois d’étendre le support de flux RSS personnalisés mais le parsing des flux est souvent problématique (à mon niveau de compétences) parce que souvent différent selon le site… Je vise à tout le moins l’ajout de contenus à mon catalogue de Documentaires, en étant un gros consommateur.
Je cherchais à découvrir une alternative à Portainer, qui me permette de gérer très simplement des Dockers (MàJ, add, remove, prune) sur un hôte comme des machines distantes (j’en ai déjà 3 au garage).
J’ai le plaisir d’être tombé sur Arcane de Kyle Mendell : open source, beau, complet sans tomber dans l’excès d’options, traduit en plusieurs langues, permet de visualiser les containers, images, volumes, réseaux, de les créer/retirer/mettre à jour (avec notifications), créer des stacks etc. On peut accéder à des templates de la communauté ou autres, parcourir les registres DockerHub, GitHub et compagnie. Et ça s’installe/configure très facilement en prime.
En bref : ça claque !
Suivre la documentation pour installer Arcane et celle pour ses agents. Pour ces derniers, le AGENT_BOOTSTRAP_TOKEN est juste un mot de passe de son choix (qui ne sert qu’au 1er lancement).
Exemples chez moi où je place le serveur sur un NAS Synology.
Je me suis récemment remis sur Stremio notamment en présentant les addons que j’utilise et pourquoi/comment avec leurs composes, sur GitHub, pour pouvoir le faire rapidement de votre côté soit en console soit via DockeGE ou équivalent. Je viens de publier un article sur NZBdav, que j’utilise depuis des semaines, qui permet de streamer du contenu depuis Usenet. Donc, en toute logique, voici comment lier les 2
Grâce au boulot de Sanket qui a créé UsenetStreamer, on peut ajouter NZBdav comme source de flux à Stremio, comme StreamFusion, Comet etc. Il suffit d’avoir également un moteur de recherche de .nzb (logique) tel que Prowlarr ou NZBhydra, je préfère ce dernier.
ATTENTION si vous gérez vos flux avec un cache, tel que Stream Prefetchers comme moi, ça va appeler un bon nombre de .nzb qui seront chargés dans NZBdav, parfois en échec car incompatibles avec du coup une nouvelle recherche. Ce qui induit un grand nombre de hits et/ou téléchargements via Prowlarr/NZBHydra auprès des indexeurs Usenet dont les limites sont fonctions des dons ou abonnements. Il y a un risque de consommer inutilement ces quotas simplement du fait de la mise en cache des contenus des catalogues.
Quand on ouvre la page d’un film ou d’un épisode de série, tout comme StreamFusion lance la recherche du média chez AllDebrid (dans ma config), UsenetStreamer va la lancer sur NZBhydra et afficher le retour sur Stremio. Je passe StreamFusion et UsenetStreamer dans AIOStreamers pour modifier le rendu de la liste des releases ET filtrer l’affichage des rlz : 1080/1440/2160p, FRENCH/MULTI, j’exclus les mots complete.bluray et bluray (pour éviter d’avoir des .iso depuis mes indexeurs Usenet) et je tente de trouver le bon combo de filtre du nombre de résultats par addon et résolution pour avoir une liste courte de releases à lancer (sinon j’en ai par exemple eu 64 tout à l’heure ce qui est complètement inutile). – c’est encore perfectible –
On lance le film, ici depuis Usenet, NZBdav charge le .nzb et ça stream de suite dans Stremio. Il faut pour ça un .nzb compatible : sans archive (donc fichier posté sans compression). NZBdav prend en charge les mots de passe.
Et si on tombe sur un .nzb non compatible, il suffit de changer de release puisqu’on en liste quelques-unes de différentes sources. On remarque au passage que cette vidéo est faite par l’IA…
EDIT 18.11.25 : Usenet-Streamer intègre maintenant parfaitement NZBHydra et permet également de trier les résultats par qualité puis taille ou langue puis qualité puis taille. On peut également filtrer sa langue préférée (1 seule) et définir -ou non- une taille maximale de release.
Pour l’installer il faut suivre les recommandations du GitHub, voici à titre d’exemple mon setup avec NZBHydra. Je l’ai ajouté à ma stack sur GitHub.
services:
stremio-usenetstreamer:
container_name: stremio-usenetstreamer
restart: always
ports:
- 32867:7000
environment:
INDEXER_MANAGER: nzbhydra
INDEXER_MANAGER_URL: http://192.168.0.163:5076
INDEXER_MANAGER_API_KEY: NBFQU9ECCN9PIBE6ES00HI1901
# INDEXER_MANAGER_INDEXERS: xxx
# ne fonctionne pas chez moi, du coup je n'ai activé que l'indexeur que je sais le plus compatible avec NZBdav
ADDON_SHARED_SECRET: blahbluhbloh
NZBDAV_URL: http://192.168.0.163:3029
NZBDAV_API_KEY: 8bc33968842a4257891521d29ba0fb36
NZBDAV_WEBDAV_URL: http://192.168.0.163:3029
NZBDAV_WEBDAV_USER: xxx
NZBDAV_WEBDAV_PASS: xxx
NZBDAV_CATEGORY: Stremio
ADDON_BASE_URL: https://stremio-usenetstreamer.xxx.xxx
image: ghcr.io/sanket9225/usenetstreamer:latest
labels:
- com.centurylinklabs.watchtower.enable=true
nzbhydra2:
image: lscr.io/linuxserver/nzbhydra2:dev
container_name: nzbhydra2
restart: always
network_mode: container:gluetun-airvpn
environment:
TZ: Europe/Paris
PUID: 0
PGID: 0
volumes:
- /home/aerya/docker/nzbhydra2/data:/config
labels:
- com.centurylinklabs.watchtower.enable=true
L’URL de mon addon pour l’ajouter à Stremio sera donc https://stremio-usenetstreamer.xxx.xxx/blahbluhbloh/manifest.json
Bon… j’ai commencé la rédaction ce matin, il est 16h, et entre temps il a publié une version :dev, qui n’a rien à voir ^^ Exit la configuration via les variables, c’est passé en format WebUI ! C’est bogué pour utiliser NZBHydra, il faut passer par Prowlarr, voici le nouveau compose
Je n’active pas le health check, NZBdav s’en occupant déjà avec sa fonction Repair.
Pour vous donner une idée, voici les médias que j’ai lancés dans Stremio pour ce test
Et les stats de NZBHydra pour l’unique indexeur utilisé
Il me semble dangereux d’utiliser une mise en cache pour UsenetStreamers. Étant seul, ou au pire 2 avec Madame, sur Stremio, je peux aisément me passer du cache. Si vous faites de la revente du partage en famille ou entre amis, ça peut être plus compliqué. Et pourtant je pense qu’en terme de qualité de service, le cache peut avoir son intérêt. À creuser !
Déjà fan du streaming dans Plex/Jellyfin depuis des .torrents via Decypharr (pour lequel je propose le compagnon de seed DecypharrSeed), j’avais à l’époque testé Decypharr-Usenet qui donnait des résultats corrects. Le streaming depuis Usenet est prégnant depuis plusieurs mois, divers projets se succèdent et, pour moi, le plus abouti est NZBdav (trouvant AltMount trop… instable).
Il faut évidemment un accès à Usenet via un FAU (je suis chez Eweka, lien sans sponsoring) et un indexeur de .nzbs qui référence des .nzb compatibles (sans archive).
Il agit comme un client de téléchargement SABnzbd pour les *arrs, à la manière de Decypharr, et s’il tombe sur un .nzb non compatible, il remonte alors le fichier en erreur à Radarr/Sonarr qui cherche une source alternative.
Ça s’installe en 2-2 avec Docker, voici mon exemple de compose avec le montage rClone dans lequel peuvent aller lire Plex/Emby/Jellyfin/Radarr/Sonarr/whatever.
Sur l’accueil sont listés les derniers .nzb chargés, leur état et leur catégorie (« Stremio » c’est pour un artricle à venir). Pour Radarr et Sonarr on verra leurs catégories Movies et Shows.
On peut parcourir le WEBdav qui est monté par rClone, selon ma configuration, dans /mnt/nzbdav
Les arrs (ou CineSync) viennent taper dans /mnt/nzbdav/content/xxx pour organiser/copier/symlinker les fichiers dans des bibliothèques lisibles dans Plex/Jellyfin.
NZBdav possède également une option de réparation (quand c’est possible, via les .par2)
Après ma première salve d’articles sur Stremio puis m’être concentré sur Jellyfin, j’y suis revenu quand j’ai testé le plugin Gelato pour Jellyfin. Il permet d’importer des catalogues Stremio dans les bibliothèques Jellyfin. Concrètement, ça le rempli des films et séries qu’on trouve sous Stremio selon la configuration utilisée (FRENCH/MULTI chez moi), le principe étant d’utiliser du streaming depuis des débrideurs pour lire les fichiers (principe de Decypharr, Stremio, un peu nzbdav and co). Par rapport à mon setup avec Decypharr/AllDebrid, l’intérêt est de limiter justement le nombre de liens activés dans Decypharr (limite de 5000/compte AllDebrid par exemple et ça va vite à atteindre dans « notre milieu »). En effet, avec Stremio/Gelato, les liens AD ne sont activés que lors de la recherche/lecture d’un fichier et non lors de l’ajout de celui-ci à une bibliothèque Jellyfin/Plex. C’est du moins ma compréhension de Decypharr et Gelato. Et si je me trompe, c’est nouveau et geek, donc fallait que je teste !
Après plusieurs jours sur le sujet, j’ai préféré laisser de côté Gelato, n’étant pas parvenu à avoir des bibliothèques aussi qualitatives qu’espéré : malgré des 10aines de tests d’addons et configs, j’avais toujours 15/20% des fichiers « vides », sans lien de streaming (soit encore au cinéma, soit aucune VF) et ce n’est pas ce que j’attends d’un setup Plex/Hellyfin.
Mais ça m’a remis le pied à l’étrier pour Stremio !
Pour rappel, ou info, Stremio est un lecteur de flux vidéos qui fonctionne avec des plugins, au moins 3 : – 1 de métadonnées pour avoir les synopsis etc, – 1 de catalogues pour lister des contenus (films, séries, Netflix, Apple, Canal, listes MDBList, IMDB, Trakt…), – 1 de recherche de flux vidéos liés à ces contenus.
les catalogues de vidéos peuvent être positionnés sur l’accueil ou uniquement dans le menu Découverte
Après avoir utilisé des instances publiques mises à disposition par certains dont la team de stremiofr.com (Discord), j’ai décidé d’auto-héberger un maximum d’outils (tout sauf Stremio Web, pour l’instant).
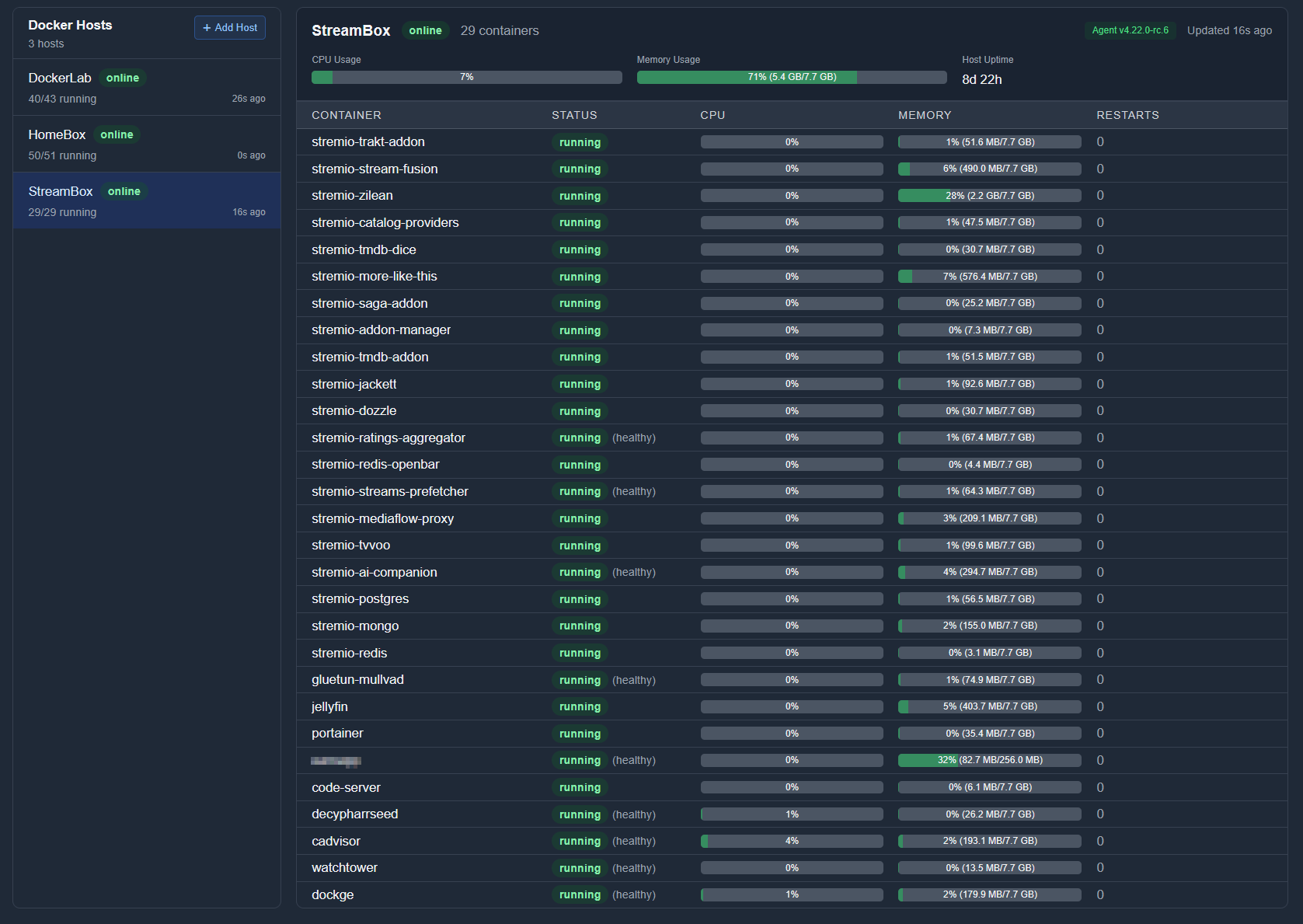
Outre ma passion pour le self-hosting,un grand nombre des outils publics sont hébergés sur des VPS gratuits Oracle, pas toujours capables de supporter la charge des clients connectés. D’où le fréquent down d’instances TMDB, par exemple, pourtant indispensable au fonctionnement de Stremio. Je mets ça au garage, sur le petit PC de streaming sous Ubuntu. Ça tape un peu dedans au lancement avec notamment la mise en cache de Zilean mais ensuite c’est peu consommateur de ressources et c’est sans surprise SQL qui mange le plus.
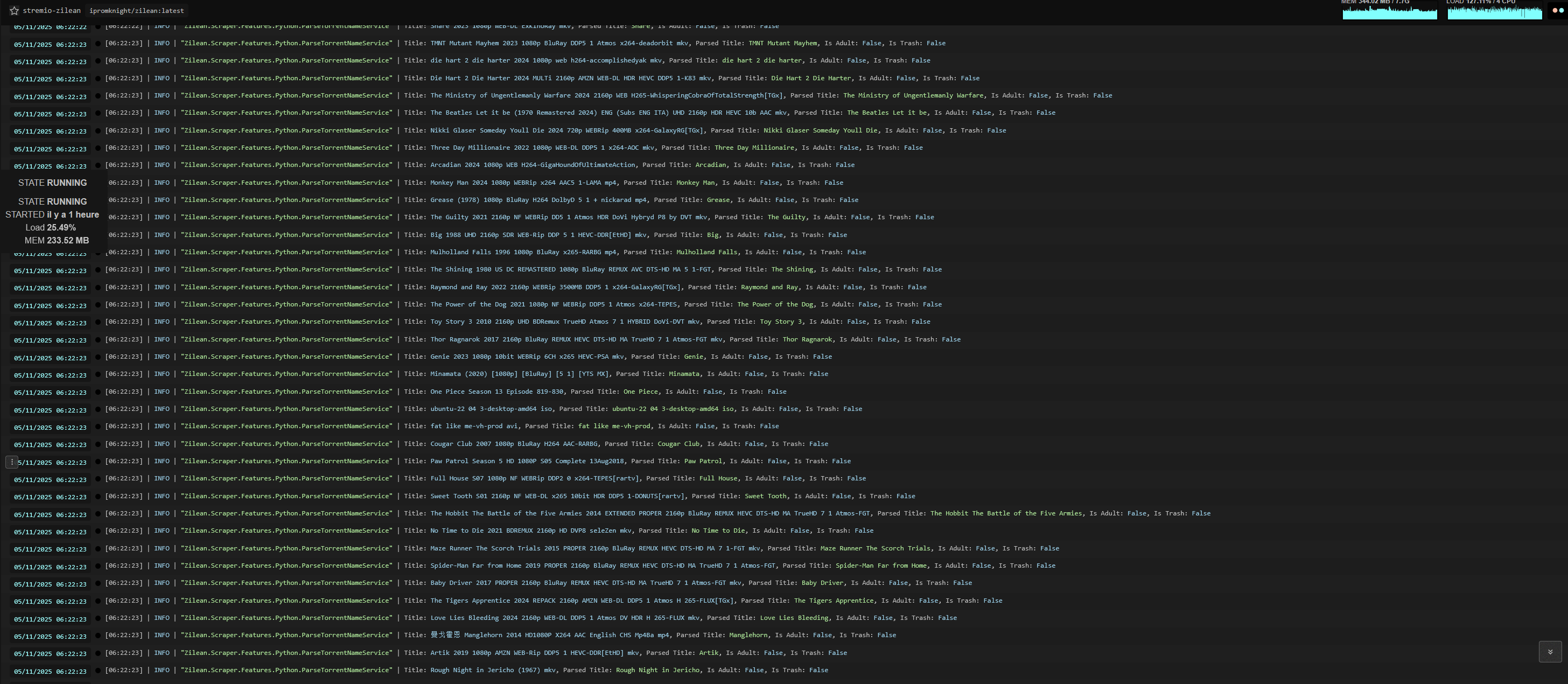
l’éclair devant la rlz indique qu’elle est déjà en cache chez le débrideur
J’ai posté sur GitHub l’ensemble des outils que j’utilise, les compose.yml sont automatiquement tenus à jour et font appel soit aux dépôts d’origine, soit à mes forks (qui créent et maintiennent des images Docker, ce qui me semble plus logique). Puisque j’héberge ça chez moi il n’y a aucun proxy pour les débrideurs, ces derniers limitant souvent à 1 IP/compte, voire bannissant celles des hébergeurs de serveurs (d’où le fait que certains passent par Warp pour masquer les différentes IPs).
pour éviter les spoilers, les thumbnails d’épisodes non lus sont floutées
Ici je liste les outils que j’utilise ou ai testés en les décrivant brièvement. Je ne mettrai pas de lien d’instance publique, libre à chacun de chercher s’il y en a, la plupart sont indiquées sur GitHub.
Stremio-Community et Stremio- Enhanced : je place ça là… Le 1er est un lecteur de bureau modifié mais qui n’existe hélas pas encore sur Linux, donc pas testé et le 2nd est la même chose mais pour Linux notamment, donc testé ! Très sympa (pas mal de plugins sur GitHub). Le seul bémol de ces outils c’est qu’ici on regarde films et séries sur une télé (j’ai pas d’écran PC 4K de 55″ encore) et hélas l’application AndroidTV n’est pas modifiable. Dans un monde idéal, faudrait que je regarde comment utiliser Stremio-Web en app ATV… « un jour ».
AIOMetadata : addon de métadonnées regroupées (TMDB, TVDB, IMDB, MAL) et bien plus puisqu’il permet d’ajouter des listes et filtres
Je ne l’avais pas précisé mais quand on utilise AIOMetadata, ses catalogues intégrés sont forcément en 1er sur l’accueil puisque c’est le 1er addon chargé dans Stremio. Si on souhaite pousser d’autres catalogues en haut de liste, par exemple YGGFlix et YGG depuis StreamFusion, il suffit d’ajouter le manifeste de SF à AIOMetadata et de mettre les catalogues en 1er.
Catalogues : ajoute des catalogues tels que Netflix, Apple, Prime, Canal+ etc mais peut aussi lister des recommandations ou contenu similaires. En partie redondant avec d’autres addons de catalogues/listes si on active leurs options, j’utilise d’ailleurs plutôt AIOMetadata à la fin de la rédaction de cet article…
Saga : affiche les sagas telles que proposées sur TMDB
Stream-Fusion : addon de streaming privilégié pour le contenu francophone en embarquant de base YGG et SW. Il permet de lier les films/séries listés dans Stremio avec un ou des débrideurs, avec ou sans cache, avec ou sans Jackett. Bref, très complet, très simple, très efficace. Après l’avoir installé, il faut se rendre sur /api/admin pour générer la clé API à utiliser lors de la configuration. Notez qu’il existe un fork de beluchon, remanié pour TorBox
Le principe est presque toujours le même : je clique sur FilmAAA, ça recherche FilmAAA sur YGG et/ou SW et/ou Jackett et une fois FilmAAA.torrent trouvé, ça regarde chez le/les débrideur.s s’il est déjà en cache, si oui ça lit, si non ça télécharge et lit ensuite
Zilean : un cache global permettant ici à Stream-Fusion de savoir plus vite FilmAAA est déjà en cache chez un débrideur (plutôt pour les contenu VO). Au 1er lancement ça indexe le cache, j’ai pas constaté de différence de vitesse de listing à mon faible niveau d’utilisation de Stremio
Jackett : pour la recherche en direct de contenu sur des trackers BitTorrent en lien avec Stream-Fusion. Je suis passé depuis longtemps sur Prowlarr mais il n’est pas compatible. Un truc à modifier, un jour (ou alors utiliser AIOStreams). Je n’ai pas configuré Jackett, trouvant tout directement sur les débrideurs, jusqu’à maintenant
Addon-Manager : (une version parmi d’autres) incontournable pour gérer ses addons, placer l’addon de métadonnées en haut de la liste, retirer Cinemeta, renommer (why?! oO) ou changer l’ordre des addons. D’une manière générale il faut placer les addons de recherche de flux tout en bas de la liste. J’ai créé un fork sur GitHub pour construire une image Docker pour simplifier l’installation…
WAStream : (testé mais pas conservé) Dhylio a pondu ce bel addon pour streamer, via débrideurs, du contenu de sites de DDL, suis pas fan de DDL hormis Usenet mais ça peut dépanner si YGG est down (#humour)
MediaFlow Proxy : à utiliser avec TvVoo (en-dessous) pour proxifier les streams (sinon sur l’instance publique faut refresh toutes les heures pour une nouvelle clé). Je l’ai également forké pour faire un package à installer…
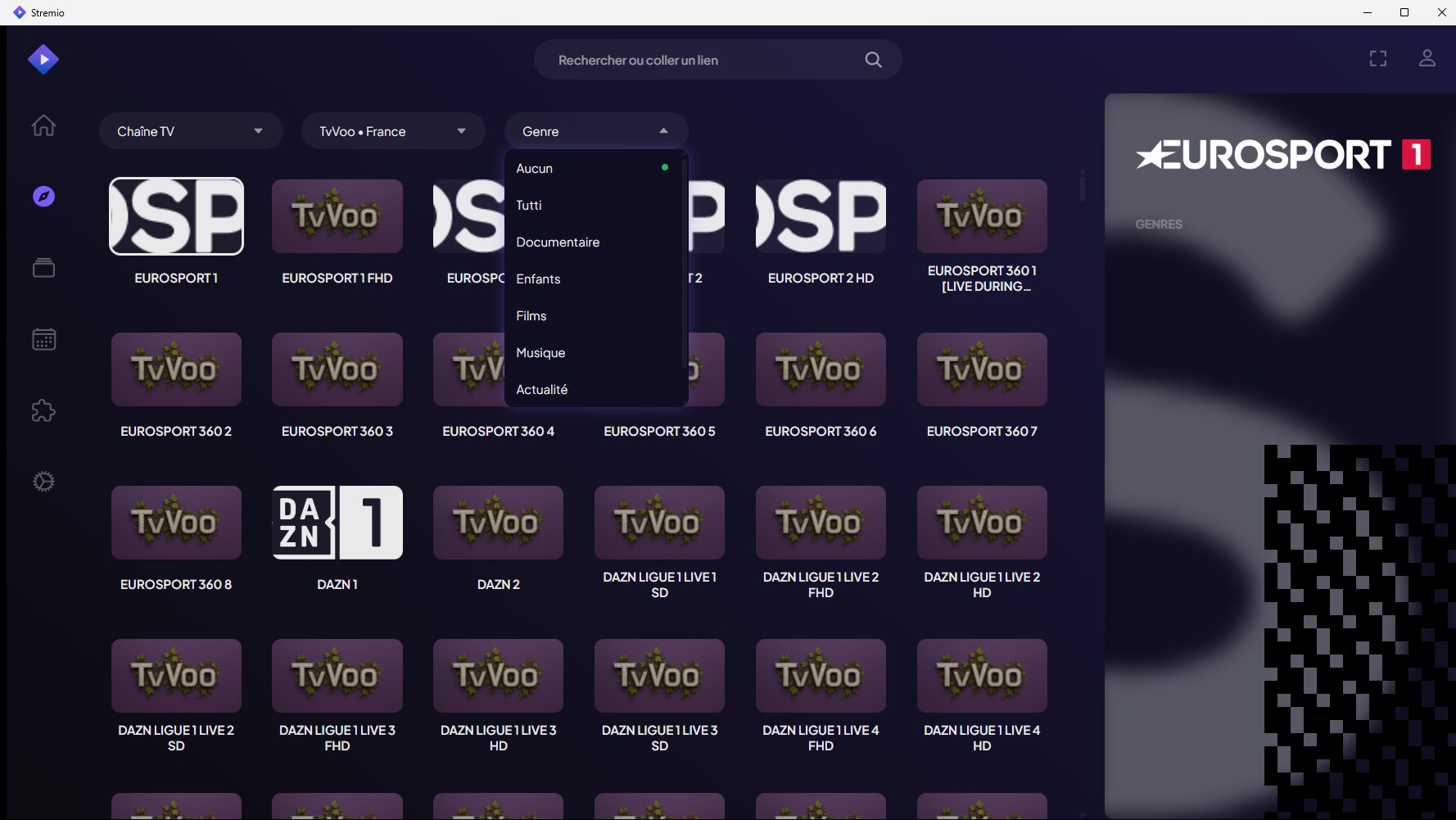
TvVoo : IPTV gratuite (sans flux m3u ou autre) sur Stremio. Tous les flux « habituels » de l’IPTV avec les chaînes payantes, triées en catégories qui plus est et fonctionne via la recherche sous Stremio. S’appuie sur vavoo.to et vavoo.tv, pensez à les débloquer dans AdGuardHome si nécessaire (chez moi pour le .tv fallait). J’ai pas trouvé d’EPG, non plus pris la peine de tester un autre addon IPTV comme celui-ci pour lequel il faut cependant une source (nous avons TiviMate sur la TV), une prochaine fois…
Rating Aggregator : pour ceux qui ont lu au sujet d’Aphrodite ou Kometa, vous savez que j’aime bien voir les notes avant de choisir un média. Cet addon permet d’obtenir quasi la même chose que cette instance publique (dont le code ne semble pas être publié ?). Encore une fois, pas de package, du coup je fork…
AI-Companion : lié à une IA (payante, mais on est fin 2025, c’est comme de parler anglais, c’est normal quand on est geek…) pour faire des découvertes de contenus selon nos demandes. Attention quand le développeur évoque la clé API TMDB dans le compose il s’agit en fait du token. J’en profite pour tester Gemini. La recherche que je montre en exemple sur l’addon est la même dans Stremio
Streams Prefetcher : outil de cache global. Il va mettre en cache les contenus des addons qu’on lui ajoute (ceux de Stremio) afin d’accélérer les recherches et lectures. Très complet : avec ou sans limite de films/séries globalement ou par catalogue, proxy, regex, durée du cache, cron… Pas forcément très utile dans mon contexte d’utilisation (que mon foyer, avec la fibre 8/8GBps) mais j’adore le concept et le boulot de Deejay !
More Like This : (testé mais pas conservé) sur une page de média, recommande des contenus similaires depuis TMDB, Gemini et d’autres sources. Pareil, forké pour faire une image Docker… Le hic c’est que c’est prévu pour Stremio Web, pas pour l’application ATV
AIOStreams : dernier addon de cette présentation, mais pas des moindres, il permet de regrouper tous les addons Stremio en un seul et il embarque surtout un paquet d’options que je vous laisse découvrir sur la page du GitHub : tri des rlz selon des critères prédéfinis ou libres ou via regex (si vous voulez du MULTI HDR mais pas DoVi ou les rlz de Pierre mais pas celles de Paul etc), modification du rendu de la liste des rlz, Attention, le compose que j’utilise est personnel donc sans restriction et je n’ai conservé que les options/services qui m’intéressent. J’utilise AIOStreams pour des tests, dans le cas d’une utilisation solo il ne me semble pas utile SAUF pour filtrer les contenus par regex et/ou modifier le rendu de la liste des rlz.
WARP : un proxy qui route le trafic via Cloudflare. Ce n’est pas un VPN, juste de quoi masquer mon IP quand AIOStreams interroge des services que je n’héberge pas.
Voici le rendu actuel de ma stack et l’ordre des addons. StreamFusion est ajouté à AIOStreams pour pouvoir modifier l’apparence de la liste des releases. Ratings => releases (StreamFusion) => Autres médias de la saga (sortis ou à venir)
TvVoo sert vraiment pas à grand chose quand on a un abonnement IPTV (de qualité) et un vrai lecteur type TiviMate mais c’est sympa pour avoir la météo en bruit de fond
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}