Dernière mise à jour le 21 octobre 2025 Comment venir à bout du casse-tête de la recherche et de la gestion documentaire ? Entre les PDF éparpillés, les citations à retrouver et les notes à organiser,...
Une passionnante conférence à la DefCon 2025, à propos de la besa mafia et d'un site web permettant d'engager des tueurs à gage, dont la sécurité informatique était très mauvaise, et de l'enquête d'un collectif de hackers pour alerter les forces de police et les victimes à propos des contrats qui étaient passés sur ce site.
Dernière mise à jour le 15 octobre 2025 Entre les commentaires à rédiger pour chaque élève, les fiches de cours à fignoler, les dossiers à préparer et les comptes rendus à faire… franchement, nos...
Gemini 2.5 Computer Use est le nouveau modèle de Google dédié aux agents capables d’agir dans une interface web comme un humain. Il “voit” l’écran, comprend le contexte, puis décide où cliquer, quoi taper, et quand faire défiler. Cette approche vise tous les cas où l’on n’a pas d’API, mais où un navigateur suffit pour accomplir une tâche de bout en bout.
Ce que l’agent sait faire et pour quoi l’utiliser
Concrètement, l’agent exécute des actions UI standardisées : ouvrir une page, suivre un lien, remplir un formulaire, valider un paiement test, ou récupérer une information derrière un login. Grâce à la vision d’écran, il repère les éléments visuels même si leur code change légèrement. Dès lors, on automatise des parcours métiers côté web sans réécrire des scripts fragiles. Dans un premier temps, l’accent porte sur le navigateur. C’est un choix pragmatique : le web est l’interface universelle des services modernes. Par conséquent, on cible des scénarios à fort ROI comme l’e-commerce, le support client, la qualification de leads, les tests UI, ou la collecte d’informations structurées.
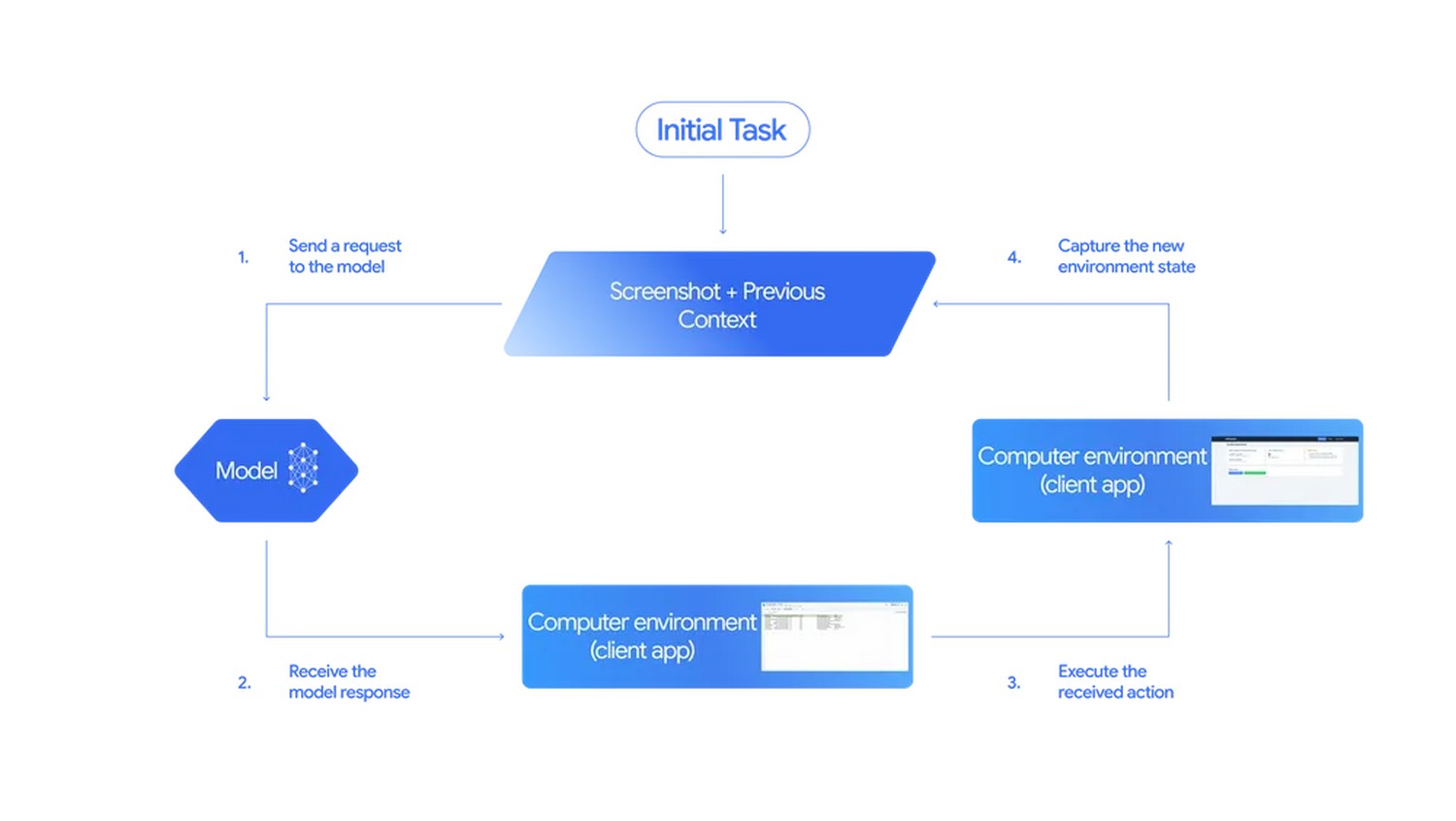
Comment fonctionne la boucle d’actions
Le fonctionnement suit un schéma simple et robuste. D’abord, votre application capture l’écran et passe l’historique des pas déjà effectués. Ensuite, Gemini 2.5 Computer Use propose la “prochaine meilleure action” sous forme d’instruction structurée : clic, saisie, scroll, raccourci clavier, ou navigation. Puis votre app exécute cette action via l’automatisation du navigateur et renvoie une nouvelle capture. Cette boucle de perception-action se répète jusqu’à réussite, blocage, ou attente d’une confirmation. Ainsi, l’agent reste explicable : chaque pas est loggé, rejouable et auditable. En outre, ce design facilite le “retry” ou l’adaptation à des variations d’interface, ce qui améliore la robustesse en production.
Benchmarks et premiers retours
Côté performance, les derniers benchmarks publics indiquent un taux de réussite élevé sur des suites de tâches du monde réel. Sur un test de navigation complexe, le modèle atteint 79,9 % de succès, devant des agents concurrents qui plafonnent plus bas. Sur d’autres évaluations multi-sites, il se classe également en tête, avec une latence en baisse et des coûts maîtrisés. Sur le terrain, les premiers pilotes rapportent des exécutions plus rapides que les alternatives, parfois jusqu’à 50 % selon les scénarios. Par ailleurs, l’orientation “web d’abord” simplifie l’adoption : les équipes peuvent brancher l’agent dans leurs pipelines QA, leurs assistants internes, ou leurs scripts d’automatisation sans refonte d’outillage.
Sécurité : confirmations et garde-fous par étape
Google a conçu une surcouche de sécurité qui analyse chaque étape avant exécution. Dès qu’une action présente un risque — par exemple cliquer sur “Acheter maintenant”, lire un document médical, ou envoyer un message sensible — l’agent doit demander une confirmation explicite. De plus, des politiques contrôlent l’accès aux données, les domaines autorisés, et les opérations critiques. Ce modèle de “permission granulaire” réduit les erreurs coûteuses et rassure les équipes conformité. Mieux, il favorise l’adoption dans des contextes réglementés, car les actions deviennent traçables et gouvernées. Ainsi, les responsables produit gardent la main, tout en déléguant l’exécution répétitive à l’IA.
Limites actuelles et feuille de route implicite
Aujourd’hui, le périmètre privilégié est le navigateur. L’agent n’a pas vocation, pour l’instant, à piloter l’intégralité d’un système d’exploitation. Toutefois, la boucle perception-action, la vision de l’écran, et l’outillage développeur laissent penser que l’extension à d’autres surfaces d’UI suivra. En attendant, les cas d’usage web couvrent déjà une large part des besoins opérationnels.
Comment démarrer
Pour tester rapidement, on passe par AI Studio ou par Vertex AI. On décrit la tâche, on donne les accès nécessaires, et on branche l’exécution du navigateur. Ensuite, on mesure la fiabilité sur vos parcours et on rajuste les “prompts d’agent”, les timeouts, et les règles de confirmation. Enfin, on industrialise via des files de jobs et de la télémétrie, afin d’observer les taux de succès dans le temps.
Gemini 2.5 Computer Use apporte un vrai saut pour les agents web. Il combine vision d’écran, planification d’actions, et garde-fous solides. Résultat : des workflows plus rapides, plus fiables et plus sûrs, sans dépendre d’intégrations API fragiles.
Dernière mise à jour le 11 octobre 2025 Comment enseigner à nos élèves à distinguer une image réelle, capturée par un objectif, d’une création d’un des multiples outils pour générer des images avec l’iA...
Décidément, j'adore ce podcast !
Ici, on parle de l'intelligence artificielle et des échecs. En mentionnant le titre d'un livre qui s'appelle Intelligence Artificielle versus Intelligence Humaine, il me vient la réflexion suivante.
L'intelligence artificielle est meilleure que l'homme pour résoudre des problèmes.
Tandis que l'intelligence humaine est meilleure que la machine pour énoncer les problèmes.
Dernière mise à jour le 9 octobre 2025 Et si vous pouviez lire une vidéo YouTube comme un article ? Pas un simple résumé automatique, mais un article structuré, fluide et cliquable. ClarifyTube transforme...
Qui n'a pas récemment entendu ni vraiment suivi l'énorme buzz sur la toile au sujet de la nouvelle création de OpenAI et plus précisément de l'algorithme GPT3 et son Chat grand public ChatGPT. Bluffant, incroyable, diabolique, complètement incompréhensible, magique ... capable de vous pondre des articles construits, des scripts voir des parties entière de code à partir de quelques phrases simples et suffisamment précises. Aujourd'hui c'est l'heure de faire un bilan bien sombre de mon activité de blogguer pro, alors ... c'est fini ? ... ou pas ?
le journalisme est mort depuis longtemps . les BFM et autres médias du même genre ne prennent pas la peine de vérifier les infos et se laissent embobiner par des experts autoproclamés... (Permalink)
Est-ce que qqn sait avec quelle IA et avec quel prompt cette vidéo a été faite ?
J'ai plein de vielle photo que mon père avait faite que j'aimerais bien ramener à la vie aussi ! (Permalink)
Oui bon là le titre est très putaclick.... L'IA a simplement lu un fichier stocké dans sharepoint...
Car bon l'utilisateur qui stocke ses mot de passe dans sharepoint, dans un fichier texte appelé password.txt, il mérite un peu de ce faire pirater, non ? (Permalink)