Bonjour à tous,
Tout récemment, je voulais utiliser un module RFM69 sur un Compute Module 5 (autrement dit l'équivalent d'un Raspberry-Pi 5) faisant fonctionner un logiciel écrit Python.

Une API MicroPython sous Python
- Ajouter les déclarations d'encodage (nécessaire à Python)
- Créer machine.SPI
- Créer machine.Pin
- Créer micropython.const
- Ajouter ticks_ms, ticks_diff, sleep_ms, sleep_us au module time de Python.
Le module RFM69
L'image ci-dessous se présente le module RFM69HCW 433MHz . Ce module permet de transmettre des données sur un réseau numérique utilisant le ondes-radios comme medium de transfert. C'est un peu le protocole internet appliqué à la radio.
 |
| RFM69HCW 433MHz |
Comme le Pilote est développé sous le précepte "Plateform Agnostic Driver" de sorte à pouvoir fonctionner indépendamment de la plateforme MicroPython cible.
 |
| esp8266-upy - Plateform Agnostic Micrpython Driver |
Ce module se branche sur un bus SPI, il est donc possible de le connecter sur GPIO d'un Raspberry-Pi 5 (ou du Compute Module 5).
 |
| Source: Raspberry-pi.ovh |
Brancher RFM69 sur GPIO
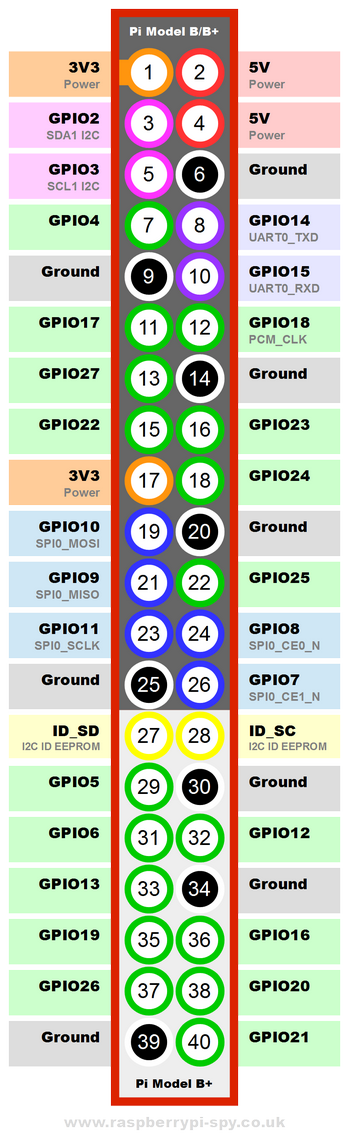
Les connexions suivantes sont établies entre le module RFM69 et le GPIO Raspberry-Pi.

La broche CS (chip select) est branchée sur le GPIO 25 alors qu'il existe les broches CE0 (GPIO8) et CE1 (GPIO7).
Le problème ici est que CE0 et CE1 sont automatiquement gérés par le système d'exploitation alors que sous MicroPython, c'est le code utilisateur qui gère l'état du signal CS.
Dans le cas présent, la gestion automatique de CE0 et CE1 empêche l'utilisation du burst_read sur le module RFM69 raison pour laquelle le GPIO25 est utilisé comme signal CS (ce signal étant contrôlé par le code utilisateur).
Prototype
Compatibilité avec Python
Commençons par récupérer la bibliothèque MicroPython du RFM69 depuis le dépôt esp8266-upy pour y ajouter l'encodage du fichier (important pour Python).
 |
| Ajout de l'encodage dans le bibliothèque RFM69 |
Récupérer l'exemple test_config.py utilisé pour tester la communication avec le module RFM69. Nous y ajoutons également l'information d'encodage dans le fichier.
Couche de compatibilité Python --> MicroPython
Création des fichiers machine.py et micropython.py pour accueillir les classes Pin & SPI ainsi que la déclaration de la fonction const()

Le script le plus intéressant est hack_time.py car celui-ci permet d'ajouter les fonctions MicroPython (ticks_ms, ticks_diff, sleep_ms, etc) manquantes dans Python.
#!/usr/bin/python # -*- coding: utf-8 -*- """ hack_time.py : mimic the MicroPython alike specific methods """ import time def _sleep_us( us ): time.sleep( us*0.000001 ) def _sleep_ms( ms ): time.sleep( ms*0.001 ) def _ticks_ms(): return int(time.time()*1000) def _ticks_diff( v1, v2 ): return v1-v2 time.sleep_us = _sleep_us time.sleep_ms = _sleep_ms time.ticks_ms = _ticks_ms time.ticks_diff = _ticks_diff
Il ne reste plus qu'a adapter le script d'exemple pour créer l'instance du bus SPI (sur le RPi) et passer le tout à la bibliothèque MicroPython originale.
#!/usr/bin/python # -*- coding: utf-8 -*- from machine import SPI, Pin import hack_time from rfm69 import RFM69 # Machine.py for Raspberry-Pi 5 spi = SPI( 0 ) nss = Pin( 25, Pin.OUT, value=True ) # Do not use the RPI CE0/CE1, it is not compatible with the Burst_Read of RFM69 rst = Pin( 18, Pin.OUT, value=False ) rfm = RFM69( spi=spi, nss=nss, reset=rst ) rfm.frequency_mhz = 433.1 ....
Le bus SPI est rattaché au bus matériel SPI0 & CE0.
Une broche Enabled (nss) alternative est utilisé avec le GPIO25 pour contrôler les transactions du bus SPI. La broche CE0 du GPIO est donc ignorée.
Enfin, le GPIO 10 est utilisé pour réinitialisé le module RFM69.
Au final, la création de l'instance RFM69 et le restant du code (y compris la bibliothèque RFM69) est identique entre MicroPython et Python (sur RPi5).
L'exécution de l'exemple sur le Raspberry-Pi 5 produit le résultat attendu (identique lorsqu'il est exécuté sur un Pico).
 |
| test_config.py : exécution de la bibliothèque MicroPython RFM69 sur Raspberry-Pi 5 |
Ressources
- MicroPython-API-for-Python experiment is published on GitHub.
![]()














{kind=link}